运行时数据区域

- 堆(Heap):
- 特点:
- 存储的是我们new来的对象,不存放基本类型和对象引用
- 由于创建了大量的对象,垃圾回收器主要工作在这块区域
- 线程共享区域,因此是线程不安全的
- 能够发生OutOfMemoryError(内存溢出异常)
- 结构:
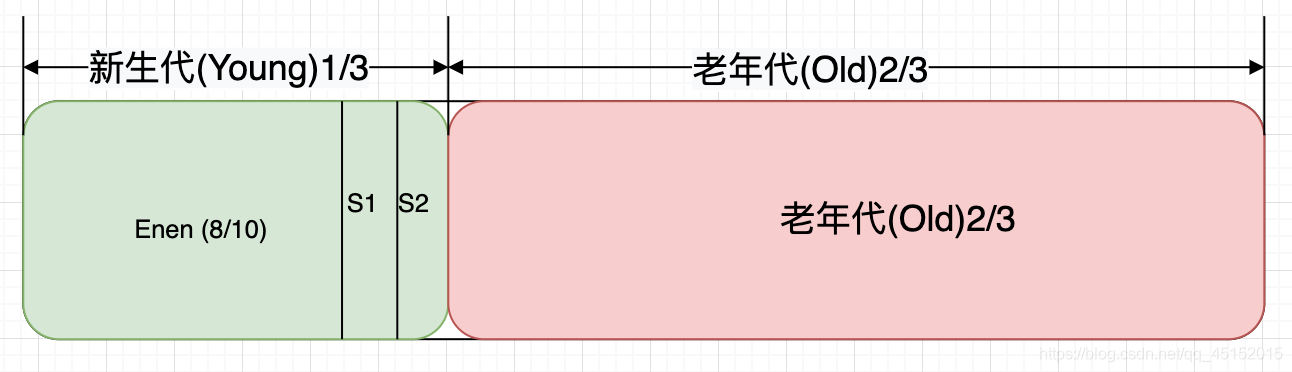
- 新生代:Eden区、Survivor 1区、Survivor 2区
- 老年代
- 虚拟机栈(VM Stack)
- 特点:
- 线程私有区域,每一个线程都有独享一个虚拟机栈,因此这是线程安全的区域
- 存放基本数据类型以及对象的引用
- 每一个方法执行的时候会在虚拟机栈中创建一个相应栈帧,方法执行完毕后该栈帧就会被销毁。方法栈帧是以先进后出的方式虚拟机栈的
- 每一个栈帧又可以划分为局部变量表、操作数栈、动态链接、方法出口以及额外的附加信息
- 这个区域可能有两种异常:StackOverflowError异常(栈溢出)、OutOfMemoryError异常(内存溢出)
- 本地方法栈(Native Method Stack)
- 概念:本地方法栈是Java程序在调用本地方法的时候创建栈帧的地方
- 方法区(Method Area)
- 概念:方法区是Java虚拟机规范中的定义,是一种规范,永久代是一种实现,Java 8 后元空间取代了永久代
- 特点:
- 线程共享区域,因此这是线程不安全的区域
- 方法区也是一个可能会发生OutOfMemoryError的区域
- 方法区存储的是从Class文件加载进来的静态变量、类信息、常量池以及编译器编译后的代码
- 常量池:常量池可以分为Class文件常量池以及运行时常量池,Java程序运行后,Class文件中的信息被字节码执行引擎加载到了方法区,从而形成了运行时常量池
- 程序计数器
- 作用:记录当前线程所执行的位置。
- 相关知识:进程是资源分配的最小单位,线程是CPU调度的最小单位,一个进程可以包含多个线程, Java线程通过抢占的方法获得CPU的执行权
- 特点:
- 线程私有,每一个线程都有一个程序计数器,因此它是线程安全的
- 唯一一块不存在OutOfMemoryError的区域
对象的创建与访问
- 对象的创建
- 过程:当虚拟机遇到字节码new指令时,就会去运行时常量池寻找该实例化对象相对应的类是否被加载、解析和初始化。如果没有被加载,就会先加载该类的信息,否则就为新生对象分配内存
- 分配内存的两种方法:
- 指针碰撞:通过一个类似于指针的东西为对象分配内存,前提是堆空间是相对规整的
- 空闲列表:堆空间不规整,使用一个列表记录了哪些空间是空闲的,分配内存的时候会更新列表
- 对象的内存布局
- 布局:
- 对象头
- 第一类信息:存储对象自身的运行时数据,例如哈希码、GC分代年龄、锁状态标志等等
- 第二类信息:指针类型,Java虚拟机通过这个指针来确定该对象是那个类的实例
- 实例数据:对象真正存储的有效信息
- 对齐填充:没有实际的意义,起着占位符的作用
- 对象头
- 对象的访问定位
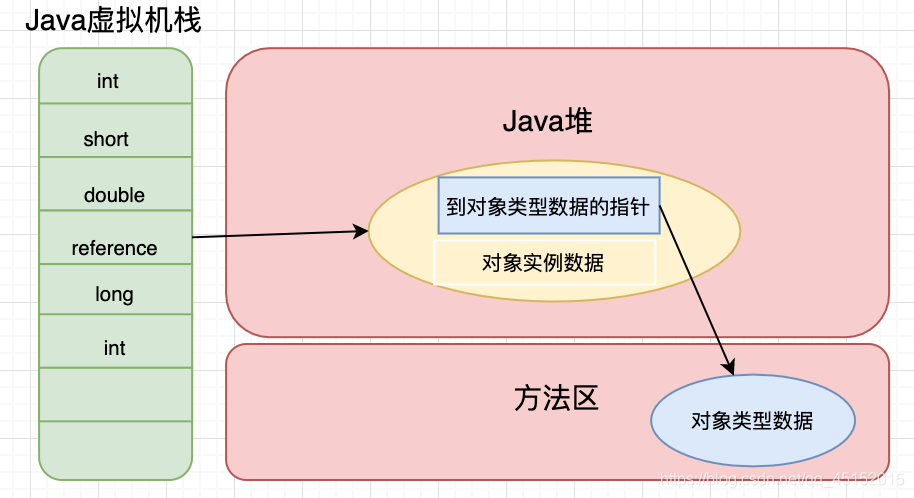
- 对象引用储存在虚拟机栈中,而对象创建却在堆中创建,如何实现对象访问?
- 访问方式:
- 使用句柄访问,通常会在Java堆中划分一块句柄池

- 使用直接指针,这样Java虚拟机栈中存储的就是该对象在堆中的地址
- 对比:
- 使用直接指针进行访问,就可以直接定位到对象,减小了一次指针定位的时间开销(使用句柄的话会通过句柄池的指针二次定位对象),最大的好处就是速度更快。但是使用句柄的话,就是当对象发生移动的时候,可以不用改变栈中存储的reference,只需要改变句柄池中实例数据的指针
垃圾收集算法
- 论对象已死?
- 对象判断是否被销毁的两种方法
- 引用计数算法: 为对象添加一个引用计数器,每当对象在一个地方被引用,则该计数器加1;每当对象引用失效时,计数器减1。但计数器为0的时候,就表明该对象没有被引用
- 可达性分析算法:通过一系列被称之为“GC Roots”的根节点开始,沿着引用链进行搜索,凡是在引用链上的对象都不会被回收
- 列举可以作为GC Roots的对象
- Java虚拟机栈中被引用的对象,各个线程调用的参数、局部变量、临时变量等
- 方法区中类静态属性引用的对象,比如引用类型的静态变量
- 方法区中常量引用的对象
- 本地方法栈中所引用的对象
- Java虚拟机内部的引用,基本数据类型对应的Class对象,一些常驻的异常对象
- 被同步锁(synchronized)持有的对象
- 收集算法
- 标记—清除算法

特点
垃圾回收之后,堆空间有大量的碎片
- 复制算法

特点:堆空间使用率降低
- GC的分类:
- Minor GC/Young GC:针对新生代的垃圾收集
- Major GC/Old GC:针对老年代的垃圾收集
- Full GC:针对整个Java堆以及方法区的垃圾收集
- GC流程
- 初次被创建的对象存放在新生代的Eden区,当第一次触发Minor GC,Eden区存活的对象被转移到Survivor区的某一块区域。以后再次触发Minor GC的时候,Eden区的对象连同一块Survivor区的对象一起,被转移到了另一块Survivor区。可以看到,这两块Survivor区我们每一次只使用其中的一块,这样也仅仅是浪费了一块Survivor区
- 每经历过一次垃圾回收的对象,它的分代年龄就加1,当分代年龄达到15以后,就直接被存放到老年代中
- 大对象就会直接进入老年代
- 标记—整理算法

- 步骤:进行标记之后,存活的对象会移动到堆的一端,然后直接清理存活对象以外的区域就可以了
- 缺点:每次进行垃圾回收的时候,都要暂停所有的用户线程,特别是对老年代的对象回收,则需要更长的回收时间
HotSpot的算法细节
- 根节点枚举
描述:就是找出可以作为GC Roots的对象,HotSpot虚拟机通过一个叫做OopMap的数据结构,可以知道哪些地方存储了对象引用
- 安全点
描述:是线程能够中断的点,GC Roots遍历的时候,是一定要让用户线程停下来的,为了使得线程到达最近的安全点停下来,有两种思路:
- 抢先式中断:暂停所有的用户线程,如果哪条线程没有在安全点,就恢复这条线程执行,直到它跑到安全点上在中断。不过没有Java虚拟机采用这种思路
- 主动式中断: 不对线程进行操作,仅仅设置一个简单的标志位,线程执行的时候不断去轮询这个标志位,当这个标志位为真的时候,线程就在离自己最近的安全点挂起
经典的垃圾收集器
- Serial 收集器
进行垃圾收集的时候会暂停所有的工作线程,直到完成垃圾收集过程
- ParNew 收集器
实则是Serial 垃圾收集器的多线程版本,这个多线程在于ParNew垃圾收集器可以使用多条线程进行垃圾回收
- Parallel Scavenge 收集器
基于标记—复制算法实现的,它最大的特点是可以控制吞吐量。
- CMS 收集器
追求最短停顿时间的垃圾收集器,基于标记—清除算法实现的
- 过程:
- 初始标记: 需要Stop The World,这里仅仅标记GC Roots能够直接关联的对象,所以速度很快。
- 并发标记: 从关联对象遍历整个GC Roots的引用链,这个过程耗时最长,但是却可以和用户线程并发运行。
- 重新标记: 修正并发时间,因为用户线程可能会导致标记产生变动,同样需要Stop The World。
- 并发清除: 清除已经死亡的对象。

- G1 收集器
将堆的整个内存布局做了修改,在G1中整个堆划分为多个大小相等的独立区域Region,虽然在逻辑上还保留了新生代和老年代,但是物理上已经隔离了
- 如何选择收集器
- 串行收集器:Serial和Serial Old单线程收集,适用于内存较小的嵌入式设备。
- 并行收集器【吞吐量优先】:Parallel Scanvage+Parallel Old,适用于科学计算、后台处理等场景。
- 并行收集器【GC停顿时间优先】:CMS和G1,适用于对时间有要求的场景,例如Web应用。
JVM调优
- JVM参数
- 标准参数: 以”-“开头的参数称为标准参数
- -X参数:以-X开头的参数是在特定版本HotSpot支持的命令
- -XX参数:-XX是不稳定的参数,也是主要参数,分为Boolean类型和非Boolean类型
- Boolean型:-XX:[+-]
:+或-表示启用或者禁用name属性 - 非Boolean型:-XX
= :name表示属性,value表示属性对应的值
- Boolean型:-XX:[+-]
- 其他参数
- 常用参数 | 设置 | 说明 | | —- | —- | | -XX:ClCompilerCount=3 | 最大并行编译数,大于1时可以提高编译速度,但会影响系统稳定性 | | -XX:InitialHeapSize=100m | 初始堆大小,可以简写为-Xms100 | | -XX:MaxHeapSize | 最大堆大小,可以简写为-Xmx100 | | -XX:NewSize=20m | 设置年轻代大小 | | -XX:MaxNewSize | 设置年轻代最大值 | | -XX:OldSize=50m | 设置老年代大小 | | -XX:MetaspaceSize=50m | 设置方法区大小,jdk1.8才有,用元空间代替方法区 | | -XX:+UseParallelGC | 设置Parallel Scanvage作为新生代收集器,系统默认会选择Parallel Old作为老年代收集器 | | -XX:NewRatio | 新生代和老年代的比值,比如 -XX:NewRatio=4表示新生代:老年代=1:4 | | -XX:SurvivorRatio | 表示两个S区和Eden区的比值,比如-XX:SurvivorRatio=8表示(S0+S1):Eden=2:8 |

若有收获,就点个赞吧
0 人点赞
