一.算法的优劣
算法就是对特定问题求解的步骤描述。我自己的理解就是算法就是优化。咱们看一个程序来求序列之和。
题目:写一个算法,求序列之和-1,1,-1,1,……(-1)^n.
int sum1(int n){int sum = 0;for(int i=1;i<=n;i++)sum+=pow(-1,i);//表示(-1)^nreturn sum;}
int sum2(int n)
{
int sum = 0;
if(n%2==0)
sum = 0;
else
sum = -1;
return sum;
}
假设n=10^8,运行两个程序,比价运行效果和时间如下:
#include<bits/stdc++.h>
using namespace std;
int sum1(int n)
{
int sum = 0;
for(int i=1;i<=n;i++)
sum+=pow(-1,i);//表示(-1)^n
return sum;
}
int sum2(int n)
{
int sum = 0;
if(n%2==0)
sum = 0;
else
sum = -1;
return sum;
}
int main()
{
int time_test=0,time1 = 0,time2 = 0,num = 100000000;
time1=clock();
sum1(num);
time2=clock();
time_test = time2 - time1;
cout<<"sum1花费时间为"<<time_test<<"毫秒"<<endl;
time1=clock();
sum2(num);
time2=clock();
time_test = time2 - time1;
cout<<"sum2花费时间为"<<time_test<<"毫秒"<<endl;
system("pause");
return 0;
}
运行结果:
显然算法sum2的运行时间远小于sum1,运行速度更快。
当我们重复运行某个程序时,哪怕是同一台机器,每次的运行时间都可能不同,更不必说在不同的机器上运行了。因此计算算法时间复杂度并非真的在计算时间。
好的算法有以下衡量标准:
1.正确性:就是指你的代码可以满足需求且平滑运行,无错误。
2.易读性:指算法遵循标识符命名规则,简洁易懂,注释适量,方便阅读,便于后期调试和修改。
3.健壮性:就是指对各种各样正常的奇怪的数据都能较好地反应和处理,在oj中的体现就是通过各个测试数据点。
4.高效性:其实就是时间复杂度低,消耗的时间短,效率更高。现代计算机一秒能进行数亿次计算,因此不能用秒来计算算法消耗时间,所以我们用算法的基本执行次数作为时间复杂度的衡量标准。
5.低存储型:这就是空间复杂度了,指算法所需空间少。尤其像手机,pad这样的嵌入式设备,如果算法占用空间过大,就会无法运行,算法占用的空间大小就称为空间复杂度。
二:算法复杂度的计算方法
1.时间复杂度的计算
时间复杂度指算法运行的时间。我们一般将算法的基本执行次数作为时间复杂度的度量标准。下面以一个程序实例演示计算。
int sum(int n)
{
int sum = 0; //1次
for(int i-1;i<=n;i++) //n+1次
sum += i; //n次
return sum; //1次
}
每条语句进行运算的次数写在注释了,求和得到总执行次数为2n-3次。以一个函数表达为T(n)=2n+3,显然该时间复杂度为一次函数,即随着数据量的增大,所需时间会越来越长。
在函数表达式中,由于算法运行时间主要取决于最高项,也就是2n,那个加三在数据量足够大的时候可以忽略不计,举个例子,你告诉朋友买车花了50万4千3百零2块钱,大家都会记住你花了50万,没人关心后面的尾数。同理,在表达时舍去小项和系数,只看最高项就可以了。如果用时间复杂度的渐进上界O表示,那么该算法的时间复杂度就是O(n)。
岔开一句:时间复杂度有多种计算和表达的方式,也有各种记法,那些内容到了数据结构与算法再细节展开讲,在这说了也很难理解,为了入门,我们仅以最常见的大O记法进行讲解。
在实际计算中,我们没必要把每一步都计算为运行次数,我们只需要计算语句频数最多的语句。在代码中,循环内层的语句往往是运行次数最多的,对运算时间消耗最大。以下面这段代码举例:
sum = 0; //1
total = 0; //1
for(i=1;i<=n;i++) //n+1
{
sum = sum + i; //n
for(j=1;j<=n;j++) //n*(n+1)
total = total + i * j; //n*n
}
在上面的程序中,我们最重要的语句是total = total + i * j; 因此只计算该语句的运行次数即可。显然,该算法的时间复杂度为O(n^2)。
并非每种算法都可以直接计算运行次数,像排序,查找,插入等,可以分别按最好,最坏和平均情况去求算法的渐进复杂度(数据结构那再讲)。但在考察一个算法时,我们通常考查最坏的情况是怎样的,而不是最好的情况,最坏的情况对于衡量算法的好坏具有实际意义。
2.空间复杂度的计算
空间复杂度指算法在运行时占用了多少存储空间。算法占用的存储空间包括:输入输出数据,算法本身,额外需要的辅助空间。
输入输出数据占用的空间是必需的,算法本身占用的空间可通过精简算法来缩减,但这个压缩的量很小,可以忽略不计。而在运行时使用的辅助变量所占用的空间,即辅助空间,是衡量空间复杂度的关键因素(比如上一章那个递归用栈的辅助空间)。我们一般把算法的辅助空间作为衡量空间复杂度的标准。
以交换两个数为例
swap(int x,int y)
{
int temp;
temp = x;
x = y;
y = temp;
}
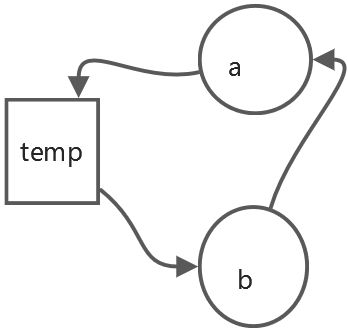
在这个程序中,a和b就是输入输出数据的占用空间,算法就是交换,不计算,空间复杂度就是我们申请的这个用于存放temp的这个临时变量,所以空间复杂度为O(1)。
我们还是以上一章所讲的递归算法来举例,依旧是求n的阶乘。递归算法的每次递推都需要一个辅助空间来保存调用记录,因此计算空间复杂度时要计算递归栈的辅助空间。
#include<iostream>
using namespace std;
long long fac(int n){
if(n==0||n==1)
return 1;
else
return n*fac(n-1);
}
int main(){
int n;
cin>>n;
cout<<fac(n);
return 0;
}
还记得我上次画的递归过程吧,那个东西叫递归树,也就是栈空间的大小。显然,空间复杂度就是O(n)。
3.列举一下常见的时间复杂度
(1)常数阶:算法运行的次数为一个常数,比如5次,20次,100次,通常用O(1)表示。
(2)对数阶:时间复杂度运行效率较高,常见的有O(logn),O(nlogn)等。
(3)多项式阶:也就是开篇举得例子,也是大部分算法的时间复杂度,常见的有O(n),O(n^2),O(n^3)等。
(4)指数阶:很差的时间复杂度,一般属于没办法了只能去打点得分的时候用,常见的有O(2^n),O(n!),O(n^n)等。
通过我们对函数图像的想象不难排序(你们也可以画个图,我是不知道咋贴过来),随着数据量(x轴)的增加,指数阶增量急剧上升,而对数阶增长缓慢。简单排序如下:O(1)
三:贪心算法
贪心算法就是总是做出最优的选择,期望通过局部最优解来达到全局最优解的解决方案,从问题的初始解开始,一步步做出最优的选择,逐步逼近问题目标,尽可能达到最优解。即使得不到最优解,也能得到最优的近似解。
贪心本质:(什么时候使用贪心算法)
两个特性:(1)贪心选择性质(2)最优子结构性质
(1)贪心选择性质
贪心选择性质指原问题的整体最优解可以通过一系列的局部最优解得到。应用同一规则,将原问题变成一个相似的,但规模更小的子问题,而后每一步都是当前最优的选择。这种选择的体现在于他只依赖与上一步的选择,而不同的选择对应的下一步选择不同。也就是说程序在运行中不能存在回溯过程。
(2)最优子结构性质
当一个问题的最优解包含其子问题的最优解时,称此问题具有最优子结构性质。问题的最优子结构性质是该问题能否用贪心算法求解的关键。这个比较难理解,我们稍后用例题来解释。
贪心算法的求解步骤如下:
(1)贪心策略:指确定贪心策略,选择看上去最好的一个,比如你要最红的苹果还是最大的苹果。根据求解目标的不同,贪心策略也就对应的不同。
(2)局部最优解:指根据贪心策略一步步确定局部最优解,比如每次挑选个最大的,记作a[0]……
(3)全局最优解:也就是把所有的局部最优解都优化成原问题的一个最优解{a0,a1,a2……}。
例题:最优装载问题
任务描述
有一天,海盗截获了一艘装满各种各样古董的货船,每一件古董都价值连城,一但打碎就失去了价值,虽然海盗船足够大,但载重量为C,每件古董的重量为Wi,海盗们如何把尽量多的宝贝装上海盗船呢?
输入格式
第一行输入n,c,代表有n个古董和船的重量
第二行输入n个数,代表每个古董的重量。
数据范围
输出格式
输入样例
输出样例
5
解答的问题分析,算法设计,图解和算法实现算法分析请看视频,此处仅贴出实现代码。
代码
#include<iostream>
#include<algorithm>
#include<cstdlib>
using namespace std;
int w[100000+5]={};
int main()
{
int n,c;
cin>>n>>c;
for(int i = 0;i < n;i++)
{
cin>>w[i];
}
sort(w,w+n);
int tmp=0,ans=0;
for(int j = 0;j < n;j++)
{
tmp += w[j];
if(tmp<=c)
ans++;
else
break;
}
cout<<ans<<endl;
system("pause");
return 0;
}
四:分治算法
分治算法本质:将一个大规模的问题分解成若干规模较小的问题,分而治之。
1.使用条件:
(1)原问题可被分为若干规模较小的子问题;
(2)子问题相互独立。
(3)子问题的解可合并为原问题的解。
2.分治算法的求解步骤如下:
(1)分解:将原问题分解为规模较小,相互独立且与原问题形式相同的子问题。
(2)治理:求解各个子问题。由于各子问题与原问题形式相同,只是规模较小,因而划分越小就可以用越简单的方法解决。
(3)合并:按原问题的要求,将子问题的解逐层合并为原问题的解。
典型用法:递归。
3.合并排序:
合并排序就是采取分治策略,将一个大问题分成很多小问题,由于排序问题给定的是一个无序序列,所以先将待排序元素分成大致相等的子序列,若不易解决则继续分解,直至成为只有一个元素的序列,此刻进行合并。
合并排序的算法步骤如下:
(1)分解:将待排序元素分成大致相等的两个子序列。
(2)治理:对两个子序列进行合并排序。
(3)合并,将排好序的有序子序列进行合并,得到最终的有序序列。
我们以一段代码配合画图在实例中视频讲解。算法实现代码如下:
void merge_sort(int a[],int low,int high)
{
if(low<high)
{
int mid = (low + high)/2;
merge_sort(a,low,mid);
merge_sort(a,mid+1,high);
merge(a,low,mid,high);
}
}
void merge(int a[],int low,int mid,int high)
{
int *b = new int [high - low + 1];
int i = low,j = mid + 1,k = 0;
while(i <= mid && j <= high)
{
if(a[i]<=a[j])
b[k++]=a[i++];
else
b[k++]=a[j++];
}
while(i <= mid)
{
b[k++] = a[i++];
}
while(j <= high)
{
b[k++] = a[j++];
}
for(i=low,k=0;i<high;i++)
{
a[i] = b[k++];
}
delete [] b;
}
4.快速排序
常见排序算法比较图(引用网络)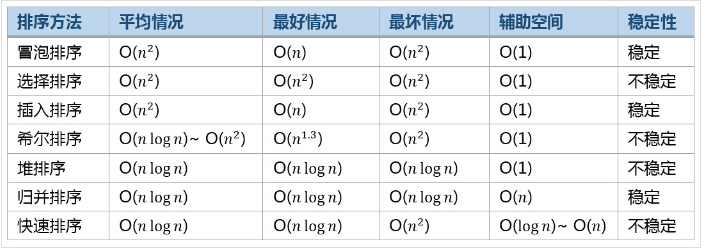
还有一个用不同数据规模(10,100,1k,10k……)测试各种排序的运行速度,对极大地数据进行排序,冒泡需要几千毫秒,而快速排序只要几毫秒,但找不到那个图。
快排的基本思想是通过一趟排序将要排序的数据分成两部分,其中一部分的所有数据比另一部分的所有数据小,然后按照此方法对两部分数据分别快速排序,整个过程可以递归进行,之后达到数据排序的目的。
快排的算法思想:
(1)分解:先从数列中取出一个元素作为基准元素。以基准元素为标准,将问题分解成两个子序列,使小于或等于基准元素的子序列在左侧,使大于基准元素的子序列在右侧。
(2)治理:对于两个子序列进行快速排序。
(3)合并:将排好序的两个子序列合并到一起,得到原问题的解。
在快速排序中取基准元素很重要,选的不好的话,快速排序就会退化为冒泡排序。
算法实现代码如下:
int partition(int r[],int low,int high)
{
int i = low,j = high,pivot = r[low];
while(i<j)
{
while(i<j&&r[j]>pivot)
{
j--;
}
if(i<j)
swap(r[i++],r[j]);
while(i<j&&r[i]<=pivot)
{
i++;
}
if(i<j)
swap(r[i],r[j--]);
}
return i;
}
void quicksort(int r[],int low,int high)
{
if(low<high)
{
int mid = partition(r,low,high);
quicksort(r,low,mid-1);
quicksort(r,mid+1,high);
}
}
算法分析:
最好情况:时间复杂度O(nlogn),空间复杂度O(logn)。
最坏情况:时间复杂度O(n^2),空间复杂度O(n)。
快排的优化:
分两段快排,减少交换次数。
代码实现:
int partition2(int r,int low,int high)
{
int i=low,j=high,pivot = r[low];
while(i<j)
{
while(i<j&&r[j]>pivot)
j--;
while(i<j&&r[i]<=pivot)
i++;
if(i<j)
swap(r[i++],r[j--]);
}
if(r[i]>pivot)
{
swap(r[i-1],r[low]);
return i-1;
}
swap(r[i],r[low]);
return i;
}
五:STL应用
这段视频我想配合题目讲,待我想想。先做洛谷题单二的练习,这个视频我找好题再录。

若有收获,就点个赞吧
0 人点赞
