科大讯飞AI营销算法比赛
--------**用户广告点击率预测**
目录
科大讯飞AI营销算法比赛 1
【一】项目情况介绍 3
1.1项目背景: 3
1.2 数据说明 3
1.3 评估指标分析: 4
【二】数据探索 4
2.1正负样本比例情况 4
2.2 特征分布情况 5
2.3 数据分析 5
【三】数据预处理 5
3.1缺失值情况 5
3.2 无效特征过滤 7
3.3 数异常值处理 8
3.4 特征共线性处理 8
【四】特征工程 8
3.1 时间特征 8
3.2 计数特征 9
3.3 比例特征 9
3.4 文本特征 10
3.5 地理特征 11
3.6 OneHot-Encoding处理(分类型数据) 11
3.7数据标准化(数值型数据) 12
3.8特征选择 12
【五】模型训练与评估 12
4.1、模型设计 12
4.2、模型评估和调参 13
【六】项目总结 14
【一】项目情况介绍
1.1项目背景:
讯飞AI营销云在高速发展的同时,积累了海量的广告数据和用户数据,如何有效利用这些数据去预测用户的广告点击概率,是大数据应用在精准营销中的关键问题,也是所有智能营销平台必须具备的核心技术。
本次大赛提供了讯飞AI营销云的海量广告投放数据,参赛选手通过人工智能技术构建预测模型预估用户的广告点击概率,即给定广告点击相关的广告、媒体、用户、上下文内容等信息的条件下预测广告点击概率。希望通过本次大赛挖掘AI营销算法领域的顶尖人才,共同推动AI营销的技术革新。
1.2 数据说明
- 数据来源:科大讯飞AI营销云广告投放数据
- 分析目标:有效利用各维度数据来预测用户的广告点击概率
- 训练集(带标签):1001650个样本。每一行数据为一个样本,可分为5类数据,包含基础广告投放数据、广告素材信息、媒体信息、用户信息和上下文信息,共1001650条数据。其中‘click’字段为要预测的标签,其它34个字段为特征字段。
- 测试集:40024个样本。测试集共40024条数据,与训练集文件相比,测试集文件无‘click’字段,其它字段同训练集。
- 补充说明:
1.advertindustry_inner字段数据样例为102400_102401,“102400(前者)”表示广告主一级行业标签id,“102401(后者)”表示广告主二级行业id,如“教育培训”
2.time字段脱敏后为有序排列,且时间间隔和与真实时间对应。
特征详情如下图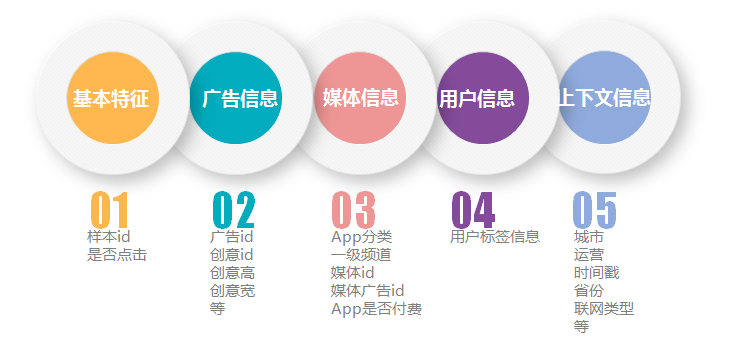
1.3 评估指标分析:
本项目通过logarithmic loss(记为logloss)评估模型效果,logloss越小越好,公式如下:
其中N表示测试集样本数,yi表示测试集中第i个样本的真实标签,pi表示第i个样本的预估点击率。
【二】数据探索
2.1正负样本比例情况
广告点击正负样本比例约为1:4
标签样本类别均匀,无需作类型不平衡处理: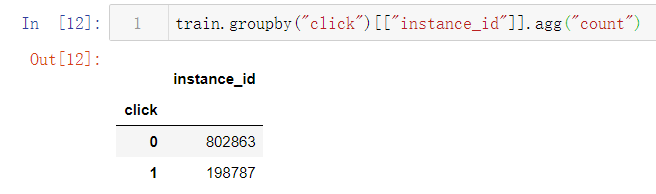
2.2 特征分布情况
基础特征共34维(最后一维为Label点击情况)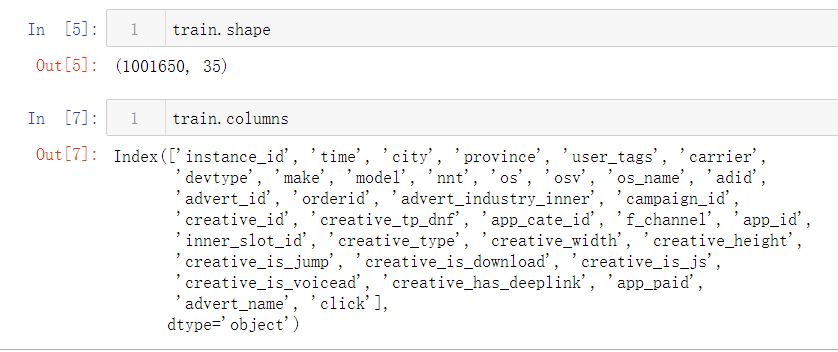
包含 布尔型变量,数值型变量 和 分类型变量
布尔型变量包含:是否为收费类软件 app_paid,是否是语音广告creative_is_voicead等
分类型变量包含:城市city, 省份province, 用户标签user_tags, 运营商carrier等
数值型变量包含:时间time,物料宽度creative_width,物料高度creative_height等
2.3 数据分析
【三】数据预处理
3.1缺失值情况
一级频道f_channel,用户标签user_tags,手机品牌make,操作系统版本osv等特征均存在一定比例的缺失值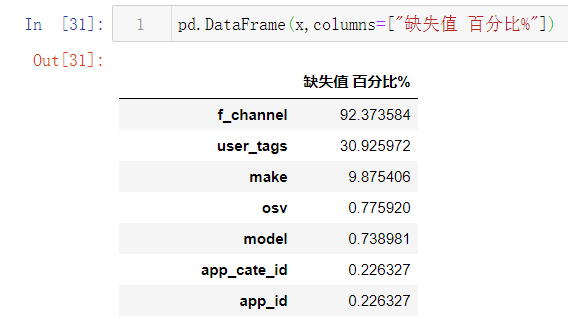
f_channel缺失比例过大(90%以上),直接删除
user_tags此类特征(经后期探索发现),较为复杂且重要,在特征工程部分进行文本处理
make,osv等特征缺失比例较小,将首先根据关联特征进行互补(如make和model存在一定重复关键词),接下来仍然缺失的部分,采用ffill进行填充处理,保持该特征的数据分布。
例:Make & Model:由于手机品牌make和手机型号model间存在关联词,故将两者缺失值进行互为补充,剩余缺失值,剩余缺失值使用ffill进行填充
例:OS_name和OSV :与make&model情况类似,由于操作系统os_name只有ios和android两种,可根据手机品牌是否为iphone判断操作系统是ios还是android,进而填充os_name中的缺失值和unknow,填充替换后发现os_name不再有unknown和缺失值;清洗osv的数据,统一版本号数字连接符和格式,把版本号前的操作系统名称用os_name中的字段填补替代。
3.2 无效特征过滤
app_paid(是否为付费软件),creative_is_voicead(是否为语音物料)和creative_is_js(是否为JS格式物料)三维特征的内容唯一,属于无效特征,直接过滤删除 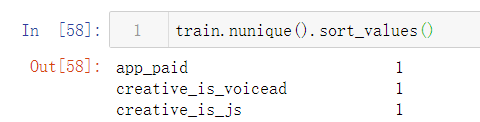
3.3 数异常值处理
一般情况下,需要根据数值型特征的数据分布判断是否存在异常值,将数值大于平均值五个标准差以外的数据作为异常值,用平均值替代。但结合对于业务的理解,本次的数值型特征(物料长度,物料宽度,时间等维度)并不存在异常值情况,故删去此步骤。
3.4 特征共线性处理
对于共线性大的特征,进行删除,发现os和os_name相关性为1,两者代表意义相同,删除os。
3.5 布尔型数据处理
将布尔型数据转换为数值型数据
【四】特征工程
3.1 时间特征

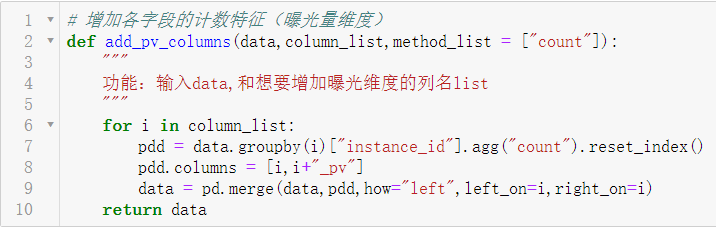
3.2 计数特征
根据广告曝光量,对大部分维度进行了曝光量的统计处理
3.3 比例特征
生成类别变量比例特征(如appid为1并且city为北京的点击量 / city为北京的点击量)
3.4 文本特征
根据业务理解user_tags代表用户标签,该维度较为重要,但操作时发现tags标签过多,如果将单标签提出作为维度特征将产生维度灾难。经探索后,使用sklearn中的CountVectorizer对词频进行统计,生成1010维稀疏矩阵,同时结合卡方检验进行特征筛选。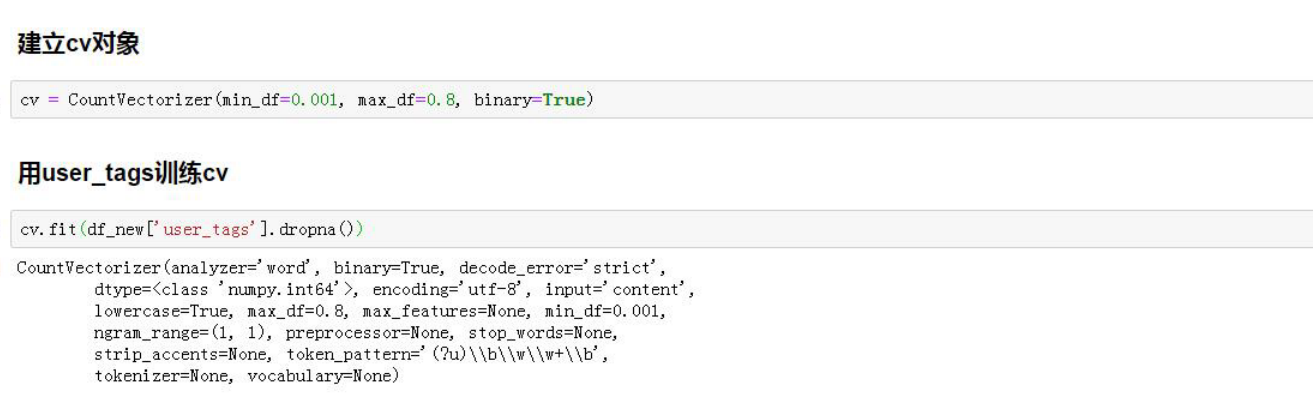

3.5 地理特征
经过反复对比发现,数据集中City字段的中间6位数,分别代表省份,城市和地区,对此进行切分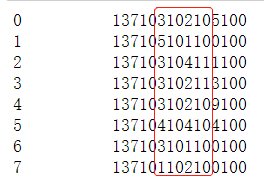

3.6 OneHot-Encoding处理(分类型数据)
针对分类型特征进行了OneHot-Encoding
操作过程中,类别较多的特征,把其长尾部分归为其他类,避免维度灾难

注:对相互之间并非完全独立,有大小,级别关系的类别型特征,可采取了Labelencoding,来体现出他们之间的关系,避免信息损失。
3.7数据标准化(数值型数据)
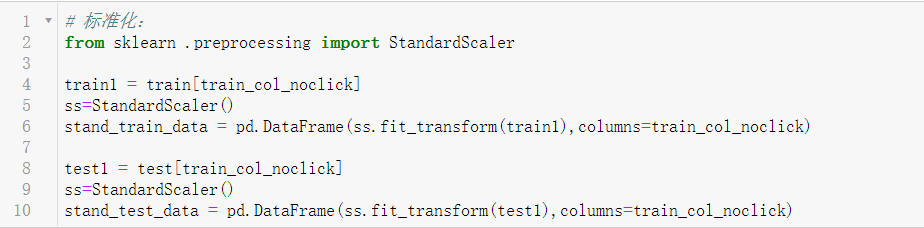
3.8特征选择


【五】模型训练与评估
4.1、模型设计
根据目前学习的机器学习知识,该广告点击预测的情况属于分类问题,故选择了逻辑回归LR和随机森林RF进行训练,并使用GridSearchCV进行交叉验证,防止过拟合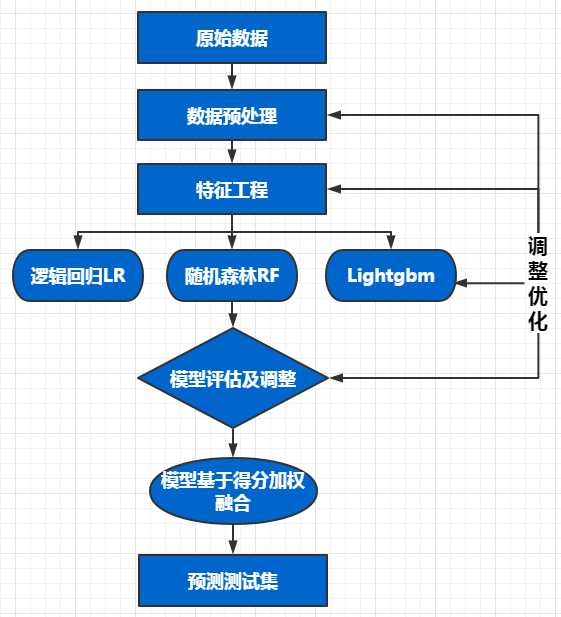
4.2、模型评估和调参
模型调参归根于两个重点:
- 防止模型欠拟合
- 避免模型过拟合
采用网络搜索(grid_searchcv)的方法进行自动化调参,具体代码如下:
同步借助学习曲线,对过拟合情况进行辅助检验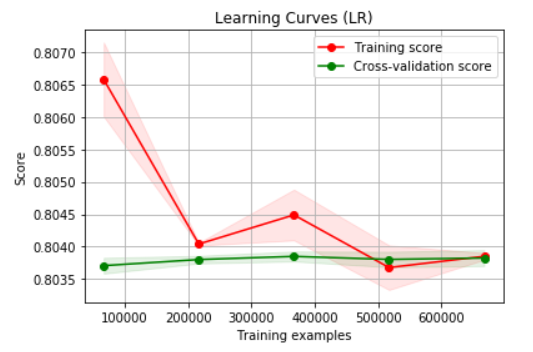
调参小结:
- 逻辑回归的max_iter与C两个参数十分重要,max_iter过大,迭代太多容易引起过拟合,而C太小,惩罚力度太大,模型偏差越大
- 随机森林n_estimators与max_depth两参数对过拟合的影响方向是一致的,可以同时采用网络搜索去进行调参
- 模型融合时,各模型的系数相当于一个超参
-
【六】项目总结
要尽可能地把特征工程做好,特征工程决定模型的上限,而模型调参只是尽可能地逼近模型性能的上限(如项目中的user_tags特征,起到了重要的作用)
- 对业务的理解,可以进一步优化特征处理
- 项目中使用的是两款经典的分类模型,缺乏差异性和创新性,随着之后能力的提升,要多运用更多的模型和方法,进一步提升能力
- 另外,在项目中学到以下几点增加效率:
- 处理重复操作时,务必以函数形式进行,提升数据处理的速度和准确性
- 及时保存文件,避免因软件崩溃重头再来
- 控制好项目的节奏,尽量白天处理数据,晚上跑模型

若有收获,就点个赞吧
0 人点赞
