链表初识
从底层的数据结构辨析链表和数组
数组:底层是连续的内存片段 当我们申请100m的存储空间 哪怕是能够装下数组 但是如果没连续的内存空间也不可
链表:底层不是连续的片段 是通过指针叫片段联系
单链表

头结点:记录链表基位置 可以通过其遍历整个列表
尾节点:指向null表示此为链表的结尾
链表的增删
在数组中因为是连续的内存片段需要搬运内存
而链表不是 所以增删比较快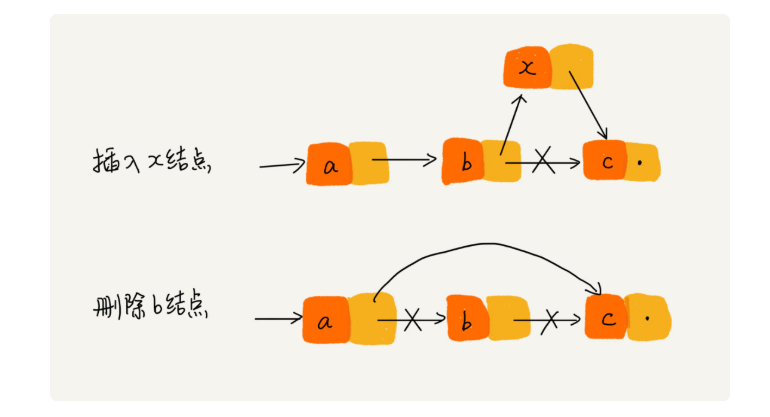 O(1)
O(1)
链表查询
因为不是连续的内存空间 不能像数组根据首地址和下标根据寻址地址计算 必须从头开始依次寻找
O(n) 的时间复杂
循环链表
 尾节点连接头结点
尾节点连接头结点
什么时候用循环链表?
双向链表
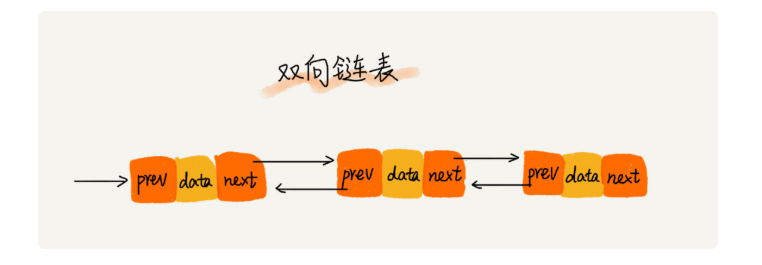
- 如果存储同样多的数据,双向链表要比单链表占用更多的内存空间
-
在某些情况下增删操作比同位O(1)的单链表更快速
删除
删除结点中“值等于某个给定值”的结点
- 无论是单向链表还是双向链表都需要先遍历再删除
- 遍历O(1)删除O(n) 根据加法法则 时间复杂度为o(n)
- 删除给定指针指向的结点。
- 单链表不能知道前面所指向的链表 所以需要先遍历O(n)
- 双向链表可以直接删除O(1)
用空间换时间的设计思路
为了提高代码的速度 空间复杂度相对较高、但时间复杂度相对很低的算法或者数据结构
而如果内存紧张 则反之亦然
双向循环列表

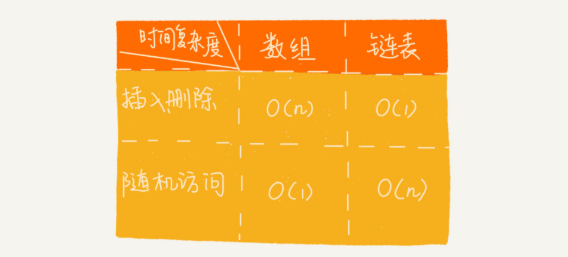
链表 VS 数组性能大比拼
LRU缓存淘汰算法
缓存是一种提高数据读取性能的技术。而缓存的内存大小有限,当缓存的内存达到上限,哪些数据应该清理,哪些应该保留呢?
- 先进先出FIFO
- 最少使用LFU
- 最近最少使用LRU
LRU
维护一个单向链表 随着时间推靠近尾部的节点是最初访问的 随着新数据的添加将会从头遍历新的链表
在我们访问数据的时候
- 如果这个数据已经被存储过 访问链表 获得节点 置于开头
- 如果没有存储过
- 缓存已满 删除尾节点 将数据置于头节点
- 缓存未满 直接数据插入头节点
-
如何写出链表
①理解指针或引用的含义
存储所指对象的内存地址
将某个变量赋值给指针,实际上就是将这个变量的地址赋值给指针,或者反过来说,指针中存储了这个变量的内存地址,指向了这个变量,通过指针就能找到这个变量。p->next=q表示p节点的后继指针存储了q节点的内存地址。p->next=p->next->nextp节点的next指针存储着p节点的下一个节点的下一个节点的内存地址
②警惕指针丢失和内存泄漏
③利用哨兵简化难度
在p节点后加入新节点
new_node>next = p->next; p->next=new_node空链表加入第一个节点
if(head == null){ head = new_node }删除节点p的后节点
p->next = p->next->next删除链表最后一个节点
if(head->next ==null){ head=null; }由此引用哨兵对边界进行处理

引入哨兵节点 无论临安表是否为空 head指针都指向哨兵节点
哨兵节点一直存在 不存储数据
- 单链表反转
- 链表中环检测
- 两个有序链表的合并
- 删除链表倒数第n节点
- 求链表中间节点

若有收获,就点个赞吧
0 人点赞
