文 @nikkyoya 2021.1.13
背景
文章:显卡,显卡驱动,nvcc, cuda driver,cudatoolkit,cudnn到底是什么?
CPU 和 GPU
GPU(图像处理器,Graphics Processing Unit,通常称显卡)和CPU(中央处理器,Central Processing Unit)在设计上的主要差异在于GPU有更多的运算单元,而Control和Cache单元不如CPU多,这是因为GPU在进行并行计算的时候每个运算单元都是执行相同的程序,而不需要太多的控制。Cache单元是用来做数据缓存的,CPU可以通过Cache来减少存取主内存的次数,也就是减少内存延迟(memory latency)。GPU中Cache很小或者没有,因为GPU可以通过并行计算的方式来减少内存延迟。因此CPU的Cahce设计主要是实现低延迟,Control主要是通用性,复杂的逻辑控制单元可以保证CPU高效分发任务和指令。所以CPU擅长逻辑控制,是串行计算,而GPU擅长高强度计算,是并行计算。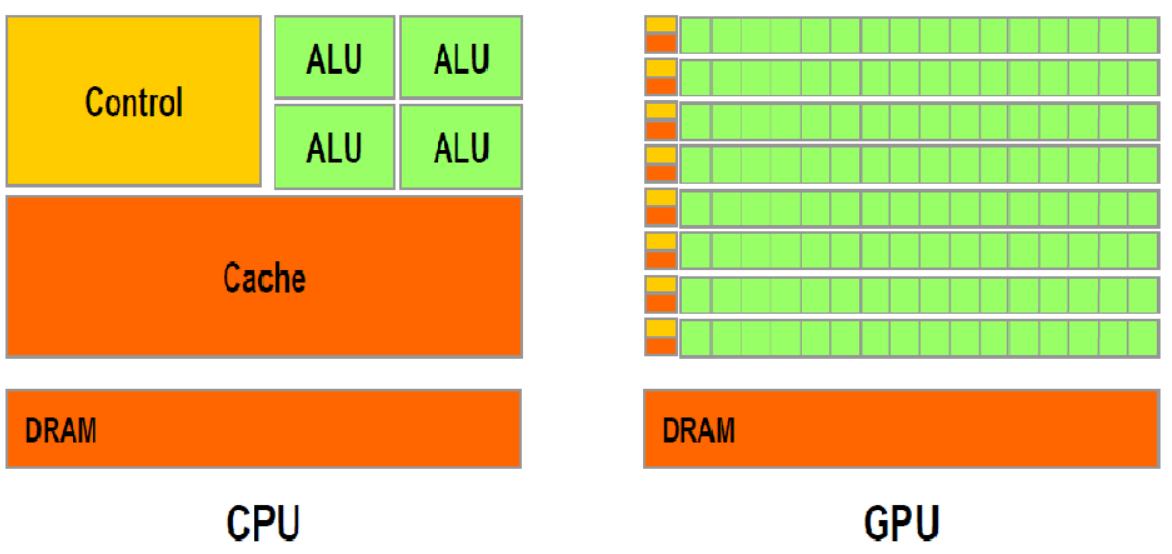
CPU和GPU的内部结构
打个比方,GPU就像成千上万的苦力,每个人干的都是类似的苦力活,相互之间没有依赖,都是独立的,简单的人多力量大;CPU就像包工头,虽然也能干苦力的活,但是人少,所以一般负责任务分配,人员调度等工作。
可以看出GPU加速是通过大量线程并行实现的,因此对于不能高度并行化的工作而言,GPU就没什么效果了。而CPU则是串行操作,需要很强的通用性,主要起到统管和分配任务的作用。
CUDA**
CUDA(Compute Unified Device Architecture,统一计算设备架构),是显卡厂商NVIDIA推出的运算平台。 CUDA只能在NVIDIA的GPU(NVIDIA支持CUDA的GPU)上运行,与之相区别的是通用框架OpenCL。
CUDA™是一种由NVIDIA推出的通用并行计算架构,该架构使GPU能够解决复杂的计算问题。
CUDA™包含了CUDA指令集架构(ISA)以及GPU内部的并 行计算引擎。 开发人员可以使用C语言来为CUDA™架构编写程序,C语言是应用最广泛的一种高级编程语言,所编写出的程序可以在支持CUDA™的处理器上以超高性能运行。
cuDNN
cuDNN(CUDA Deep Neural Network library)是NVIDIA推出的用于深度神经网络的GPU加速库。它强调性能、易用性和低内存开销。NVIDIA cuDNN可以集成到更高级别的机器学习框架中,如谷歌的Tensorflow、加州大学伯克利分校的流行caffe软件。简单的插入式设计可以让开发人员专注于设计和实现神经网络模型,而不是简单调整性能,同时还可以在GPU上实现高性能现代并行计算。
用GPU训练模型cuDNN不是必须的,但是一般会采用这个加速库。
可以把CUDA看作是一个工作台,上面配有很多工具,如锤子、螺丝刀等。cuDNN是基于CUDA的深度学习GPU加速库,有了它才能在GPU上完成深度学习的计算。它就相当于工作的工具,比如它就是个扳手。但是CUDA这个工作台买来的时候,并没有送扳手。想要在CUDA上运行深度神经网络,就要安装cuDNN,就像你想要拧个螺帽就要把扳手买回来。这样才能使GPU进行深度神经网络的工作,工作速度相较CPU快很多。
| CPU | 适合串行计算,擅长逻辑控制 |
|---|---|
| GPU | 擅长并行高强度并行计算,适用于AI算法的训练学习 |
| CUDA | NVIDIA专门负责管理分配运算单元的框架 |
| cuDNN | NVIDIA用于深层神经网络的GPU加速库 |
配置需求:windows10操作系统下,希望基于Anaconda在Pycharm上搭建Tensorflow的GPU训练环境。
电脑配置
| 显卡 | NVIDIA RTX 2060(Notebook) |
|---|---|
| 操作系统 | Window10 家庭中文版 |
| python版本 | python 3.8.5(Anaconda虚拟环境) |
| python IDE | Pycharm professional 2020.3 |
| CUDA版本 | cuda 11.1.1(windows) |
| cuDNN版本 | cudnn v8.0.4(for cuda 11.1 windows) |
| tensorflow | tensorflow 2.4.0 |
本文所用CUDA和cuDNN版本文件百度网盘下载(提取码:fkma )
主要流程
注意:
默认已装有Pycharm和Anaconda。安装较为简单,分别从Anaconda官网和Pycharm官网下载即可,其中Anaconda可从清华镜像源下载,然后为Anaconda配置环境变量:
(Python需要) \Scripts(conda自带脚本) \Library\mingw-w64\bin(使用C with python的时候) \Library\bin(jupyter notebook动态库) \Library\usr\bin 默认显卡支持CUDA
可在NVDIA官网查看,选择自己的系列类型。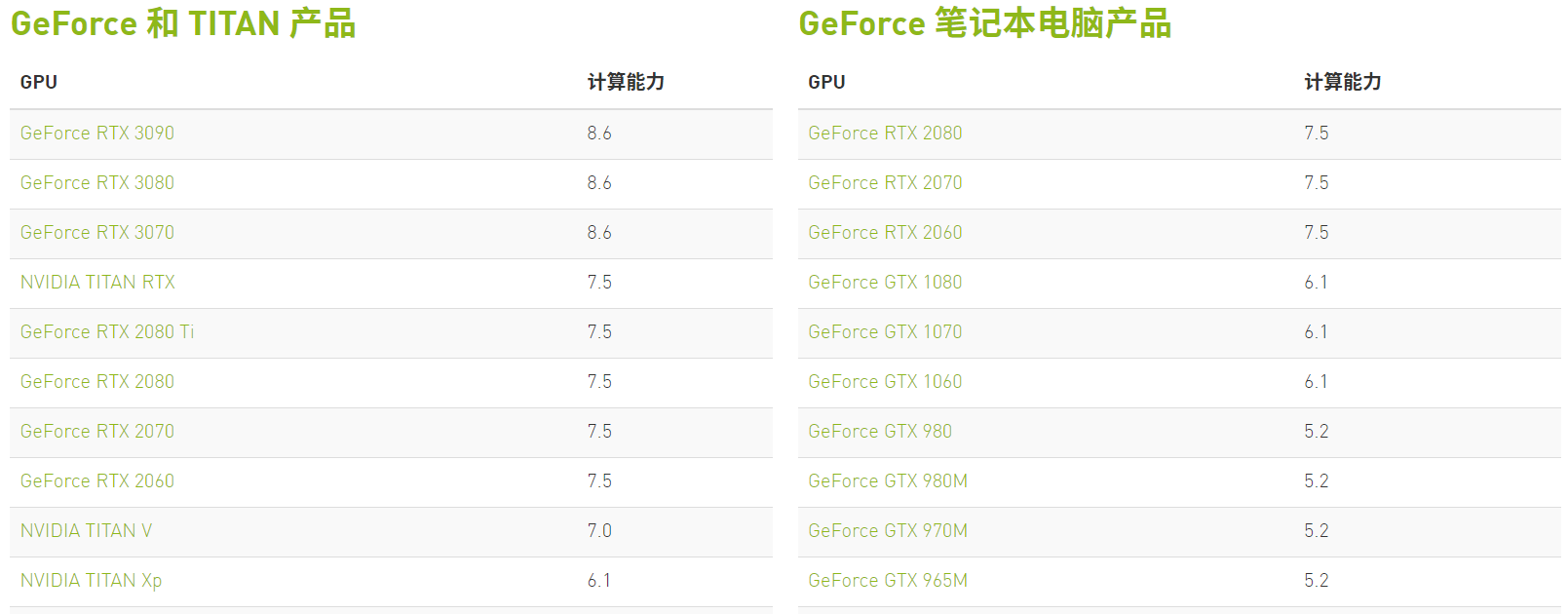
部分支持CUDA的NVIDIA产品
一、检查显卡驱动
检查显卡驱动有两个任务:(1)推断可供安装的CUDA版本;(2)判断是否需要更新驱动(新机驱动不要升级!尽量不要升级!)。
- 打开NVIDIA控制面板
一般通过桌面的【右键快捷菜单】即可打开。
右键菜单
NVDIA 控制面板
- 【控制面板】菜单【帮助】>【系统信息】

【控制面板】>【帮助】>【系统信息】
- 关注两个参数,【显示】>【驱动程序版本】和【组件】>NVCUDA64.DLL【产品名称】
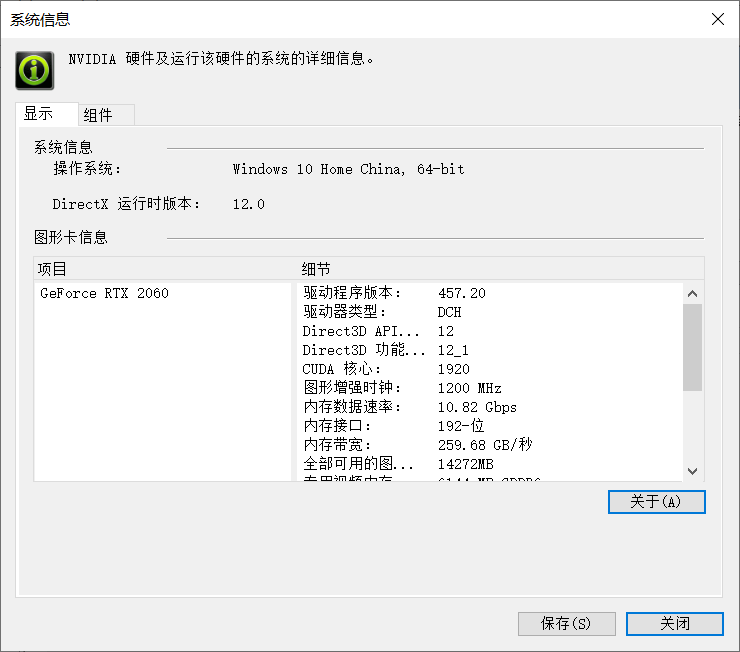
【系统信息】>【显示】>【驱动程序版本】
【系统信息】>【组件】>NVCUDA64.DLL【产品名称】
- 本机的显卡【驱动程序版本】为457.20,对照NVIDIA官网CUDA文档中给出的兼容版本,可知本机当前显卡驱动可兼容CUDA 11.1.1及以下的CUDA版本。
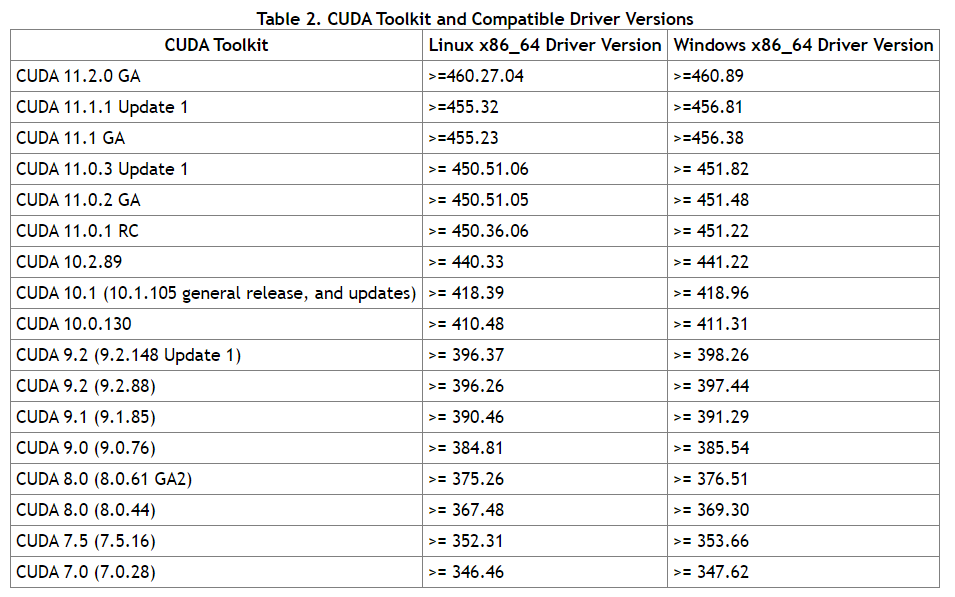
CUDA版本与显卡驱动版本的兼容关系
- 本机显卡驱动的NVCUDA版本为11.1.114,这是目前所能支持的最高CUDA版本。显卡驱动升级是可选项,在本文本中不对现有驱动进行升级。
- 但查看tensorflow官网给出的GPU版配置构建,发现提供的配置版本CUDA最新只到10.1,而没有11的配置。
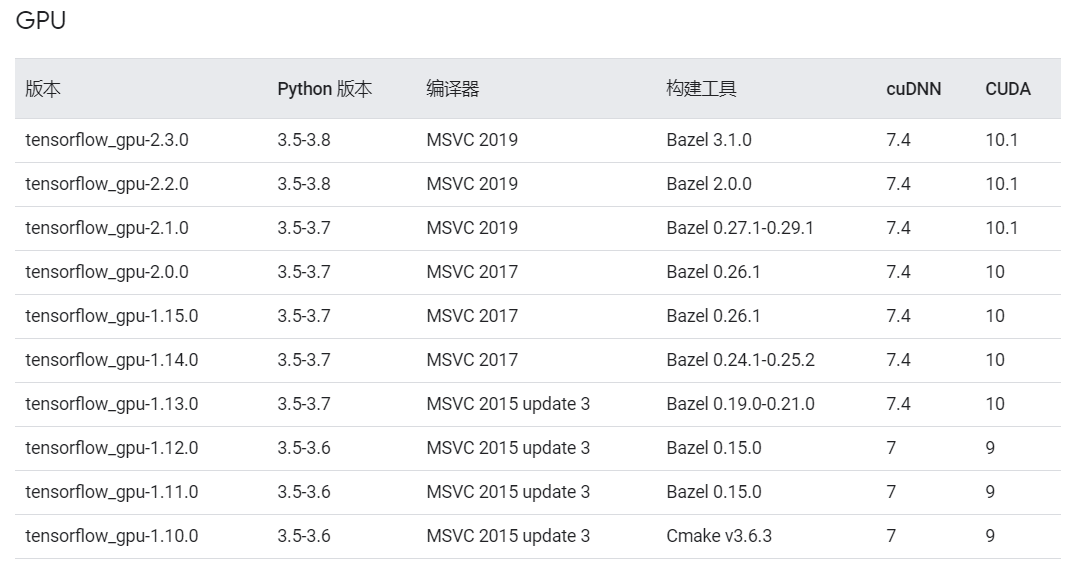
Tensorflow已测试的配置构建(Windows)
这给配置版本的选择带来了问题:CUDA的版本非常重要,CUDA的版本决定了cuDNN的版本,而又需要匹配Tensorflow的版本。但TensorFlow官网没有接近本机CUDA11的推荐配置匹配;而CUDA10的版本则可能与本机的显卡情况产生冲突。
配置中的版本依赖关系
在实际配置中,我尝试了CUDA10.1(依据tf官网的配置)和CUDA11.1(网上有类似情况的帖子,但显卡以RTX30系为主)两种配置方法,前者测试失败(tf.test.is_gpu_available()的值为FALSE,经过一定调试认为是版本关系),而后者测试成功。Tensorflow2.4和CUDA11推出的时间都不长,特别是前者,网上的资料并不多,能配置成功有一定偶然性,并且为什么之前会失败的原因尚不清楚(可能是将Tensorflow从2.3换成2.4正式版,以及CUDA从10升到11的原因,我这里的本机驱动初始就是11,和网上的一些2060的情况并太一样)。
以下是踩坑记录:
(1)CUDA10.1
.243(Update 2)+cuDNN7.6.5.32+TensorFlow2.3.0(失败) 虽然TensorFlow官方推荐的是CUDA10.1+cuDNN7.4,但是NVIDIA方面给CUDA10.1推荐的都是cuDNN7.5及以上的版本,因此在第一次配置中,我选用了cuDNN8版本以下最高的cuDNN7.6.5(For CUDA10.1)版本。虽然安装过程顺利,但在Pycharm上测试失败。 (2)CUDA11.1.1+cuDNN8.0.4.30+TensorFlow2.4(RC0)网络编译版(失败) 更换了CUDA和cuDNN(不同版本CUDA可以共存),使用了一篇帖子的whl文件安装TensorFlow,但grpcio和h5py两个依赖出错(Failed building wheel for grpcio/h5py),安装失败。 (3)CUDA11.1.1+cuDNN8.0.4.30+TensorFlow2.4.0(成功) 在(2)基础上,重建虚拟环境,安装TensorFlow2.4.0,测试成功。
二、更新显卡驱动(可选)
去NVDIA driver search page搜索本机显卡所需的驱动型号并下载即可。此处略。
三、下载和安装CUDA(CUDA11.1.1)
对于CUDA和cuDNN的关系,此文有解释。

本文CUDA11.1.1的安装版本
下载的CUDA文件如下:
下载好的CUDA文件
对于CUDA ToolKit的安装,在该文有具体说明如下:
我们可以选择两种安装方式,一种是在线安装(我还没用过),一中离线安装(我采用的)即本地安装, 当我们选择离线安装,当我们选定相对应的版本之后,下载的时候发现这个地方的文件大小大概在2G左右,Linux系统下面我们选择
runfile(local)完整安装包从本地安装,或者是选择windows的本地安装。CUDA Toolkit本地安装包时内含特定版本Nvidia显卡驱动的,所以只选择下载CUDA Toolkit就足够了,如果想安装其他版本的显卡驱动就下载相应版本即可。 所以,NVIDIA显卡驱动和CUDA工具包本身是不具有捆绑关系的,也不是一一对应的关系,只不过是离线安装的CUDA工具包会默认携带与之匹配的最新的驱动程序。 注意事项:NVIDIA的显卡驱动器与CUDA并不是一一对应的,CUDA本质上只是一个工具包而已,所以我可以在同一个设备上安装很多个不同版本的CUDA工具包,比如我的电脑上同时安装了 CUDA 9.0、CUDA 9.2、CUDA 10.0三个版本。一般情况下,我只需要安装最新版本的显卡驱动,然后根据自己的选择选择不同CUDA工具包就可以了,但是由于使用离线的CUDA总是会捆绑CUDA和驱动程序,所以在使用多个CUDA的时候就不要选择离线安装的CUDA了,否则每次都会安装不同的显卡驱动,这不太好,我们直接安装一个最新版的显卡驱动,然后在线安装不同版本的CUDA即可。
- 安装CUDA
启动exe文件(cuda_11.1.1_456.81_win10.exe)进行安装。
注意C盘需要预留一定空间给临时文件(不够也可以改成其他盘路径),【安装选项】选【精简(推荐)】即可(将安装在C盘,更改安装路径需要将【安装选项】改为【自定义(高级)】)。
安装CUDA时的临时路径
- 检查
在cmd中输入 nvcc -V,可以查看到自己安装的版本。
nvcc -V

CUDA安装版本
四、下载和安装cuDNN(cuDNN8.0.4)
- 从NVIDIA-cuDNN Archive下载cuDNN8.0.4。注意一定要与CUDA版本匹配。

下载的cuDNN如下:
下载好的cuDNN文件
- 安装cuDNN(参见官网文档)
- 解压cudnn压缩包
- 将解压文件夹cuda下的三个文件夹(
bin、include和lib)复制到CUDA安装目录下(默认安装路径为C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v11.1)
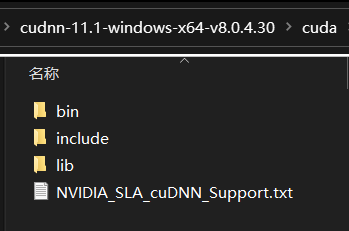

cuDNN插入式安装
五、配置CUDA环境变量
- 控制面板>系统>高级系统设置>环境变量>用户变量>PATH
添加环境变量
(C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v11.1) \bin \lib\x64 \libnvvp \include 重启生效
六、在虚拟环境中安装TensorFlow(TensorFlow2.4.0)
默认已装有Anaconda
在anaconda prompt中创建虚拟环境tensorflow-gpu
conda create --n tensorflow-gpu python=3.8.5切换到虚拟环境,安装TensorFlow2.4.0
conda activate tensorflow-gpu pip install tensorflow==2.4.0注:可以配置国内镜像源加快安装速度,使用说明见Anaconda镜像(清华源),PYPI镜像(清华源)等。本机环境均配置过清华镜像源。
附国内常用源镜像地址: 清华:https://pypi.tuna.tsinghua.edu.cn/simple 阿里云:http://mirrors.aliyun.com/pypi/simple/ 中国科技大学 https://pypi.mirrors.ustc.edu.cn/simple/ 华中理工大学:http://pypi.hustunique.com/ 山东理工大学:http://pypi.sdutlinux.org/ 豆瓣:http://pypi.douban.com/simple/
七、在Pycharm中配置环境和测试
默认已装有Pycharm
- 在Pycharm中创建实验项目
tf_test。 - 将Settings>Project:tf_test>Python Interpreter修改为tensorflow-gpu下的python解释器。

设置项目解释器
- 测试
import tensorflow as tf print(tf.__version__) print(tf.test.is_gpu_available()) print(tf.test.is_built_with_cuda()) print(tf.config.list_physical_devices('GPU'))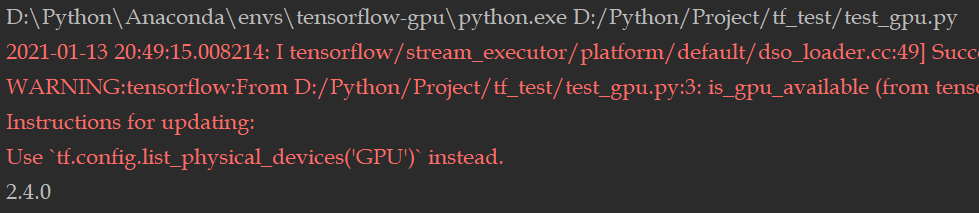

运行结果1 ```python import tensorflow as tf
print(tf.version)
x = tf.constant(0.) y = tf.constant(1.)
for iteration in range(50): x = x + y y = y / 2
print(x.numpy())
_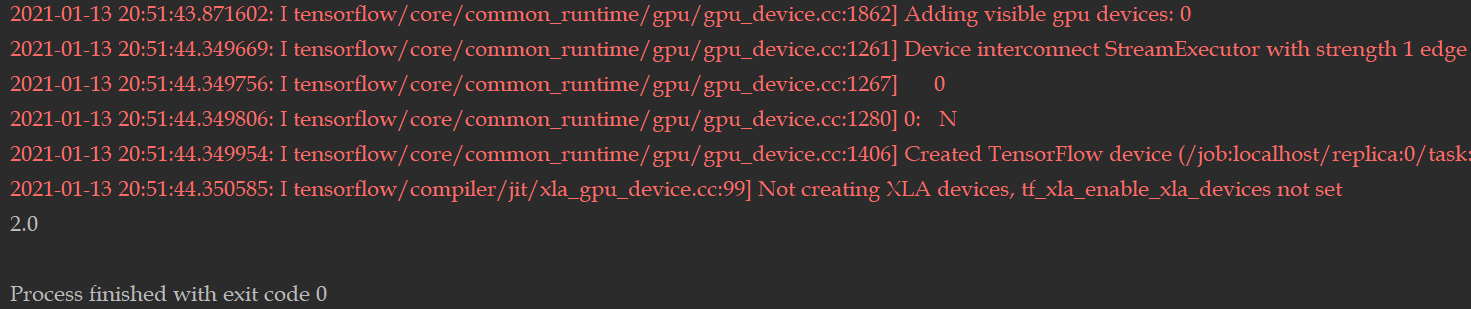_<br />运行结果2
<a name="TlkVu"></a>
#### 八、在Jupyter Notebook中配置环境
由于本文的配置方式是利用Anaconda来管理虚拟环境,所以除了Pycharm外,配置好的虚拟环境也能应用在其他的开发平台上。本文除在Pycharm上配置外,也对Jupyter Notebook进行了配置,方法非常简单。
1. 在conda的**base环境**中安装nb_conda_kernals
目的是为了在创建的conda env上运行jupyter notebook。<br />在未安装该包以前,通常无法在jupyter notebook上使用配置好的conda env运行代码。
```powershell
conda install nb_conda_kernels
安装后,在base环境中启动notebook,可在kernel>change kernel中切换到指定的虚拟环境。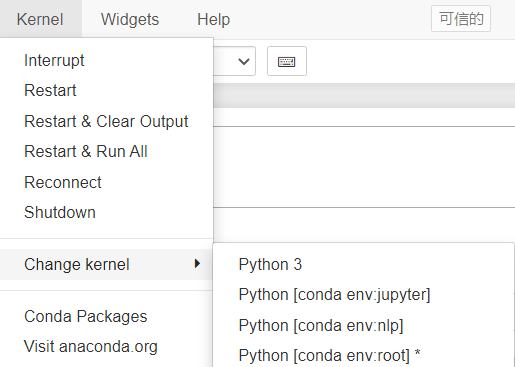
nb_conda不同kernal切换
- 切换到tensorflow-gpu虚拟环境,安装ipykernel
如果该虚拟环境是在base安装nb_conda之后才建立的,那很有可能会出现notebook的change kernel中找不到新建虚拟环境的情况,原因是该虚拟环境下缺少kernel.json文件。
解决方法:切换到tensorflow-gpu虚拟环境,再安装ipykernel即可。
conda activate tensorflow-gpu
conda install ipykernel
参考
GPU, CUDA,cuDNN三者的关系总结
【深度学习】CUDA 与 CUDNN
win10下安装pycharm和tensorflow-gpu版本
令人窒息的tensorflow-gpu
Tensorflow-GPU安装总结
NVIDIA显卡驱动版本,CUDA版本,cudnn版本之间关系及如何选择
另附官方文档

若有收获,就点个赞吧
0 人点赞
