写在前面
sharding jdbc 提供了多种接入方式。我这里只介绍两种接入方式:
- 引入sharding-jdbc的springboot starter包,通过application.yml进行配置(当前文章的主要介绍内容)
- 通过java代码的硬编码方式接入(比较推荐,下一篇文章详细介绍)
分库分表工具介绍:ShardingSphere
这里我就不过多赘述,直接贴上ShardingSphere的官网地址,想深入了解的小伙伴可以自行查阅
https://shardingsphere.apache.org/document/current/cn/overview/
ps:(小声逼逼一句)我觉得这个官方文档,只适合看看介绍,如果真的要实战操作,根据这个官方文档写的,真的会让人头大的
此demo的介绍
我原本做的是一个停车场的系统,现在由于数据量过多,需要将订单表拆分,而我这里的拆分逻辑是根据停车场id进行拆分,例如200个停车场就是200张订单表。
总的来说
分库逻辑:
按照创建时间的年份分库
分表逻辑:
按照停车场id进行分表
准备工作
数据库脚本
由于我们不是所有的表都要分表,所以数据库就有默认库,默认库是存放除了分表以外其他表的数据,具体配置见下面的详细步骤中的设置默认库
默认库:sharding2020
/*Navicat MySQL Data TransferSource Server : 开发数据库 4.71Source Server Version : 50730Source Host : 192.168.4.71:3307Source Database : sharding2020Target Server Type : MYSQLTarget Server Version : 50730File Encoding : 65001Date: 2020-05-08 11:05:41*/SET FOREIGN_KEY_CHECKS=0;-- ------------------------------ Table structure for t_car_park-- ----------------------------DROP TABLE IF EXISTS `t_car_park`;CREATE TABLE `t_car_park` (`id` varchar(64) NOT NULL,`name` varchar(100) DEFAULT NULL COMMENT '名称',`create_time` datetime DEFAULT NULL COMMENT '创建时间',PRIMARY KEY (`id`)) ENGINE=InnoDB DEFAULT CHARSET=utf8 COMMENT='停车场表';-- ------------------------------ Table structure for t_order_0-- ----------------------------DROP TABLE IF EXISTS `t_order_0`;CREATE TABLE `t_order_0` (`id` varchar(64) NOT NULL,`name` varchar(100) DEFAULT NULL COMMENT '名称',`car_park_id` varchar(64) DEFAULT NULL COMMENT '停车场id',`no` varchar(100) DEFAULT NULL COMMENT '订单号',`create_time` datetime DEFAULT NULL COMMENT '创建时间',PRIMARY KEY (`id`)) ENGINE=InnoDB DEFAULT CHARSET=utf8 COMMENT='测试分表';-- ------------------------------ Table structure for t_order_1-- ----------------------------DROP TABLE IF EXISTS `t_order_1`;CREATE TABLE `t_order_1` (`id` varchar(64) NOT NULL,`name` varchar(100) DEFAULT NULL COMMENT '名称',`car_park_id` varchar(64) DEFAULT NULL COMMENT '停车场id',`no` varchar(100) DEFAULT NULL COMMENT '订单号',`create_time` datetime DEFAULT NULL COMMENT '创建时间',PRIMARY KEY (`id`)) ENGINE=InnoDB DEFAULT CHARSET=utf8 COMMENT='测试分表';
其中t_car_park就是停车场表,属于不用分表的业务表
第二个库:sharding2019
/*Navicat MySQL Data TransferSource Server : 开发数据库 4.71Source Server Version : 50730Source Host : 192.168.4.71:3307Source Database : sharding2019Target Server Type : MYSQLTarget Server Version : 50730File Encoding : 65001Date: 2020-05-08 11:06:06*/SET FOREIGN_KEY_CHECKS=0;-- ------------------------------ Table structure for t_order_0-- ----------------------------DROP TABLE IF EXISTS `t_order_0`;CREATE TABLE `t_order_0` (`id` varchar(64) NOT NULL,`name` varchar(100) DEFAULT NULL COMMENT '名称',`car_park_id` varchar(64) DEFAULT NULL COMMENT '停车场id',`no` varchar(100) DEFAULT NULL COMMENT '订单号',`create_time` datetime DEFAULT NULL COMMENT '创建时间',PRIMARY KEY (`id`)) ENGINE=InnoDB DEFAULT CHARSET=utf8 COMMENT='测试分表';-- ------------------------------ Table structure for t_order_1-- ----------------------------DROP TABLE IF EXISTS `t_order_1`;CREATE TABLE `t_order_1` (`id` varchar(64) NOT NULL,`name` varchar(100) DEFAULT NULL COMMENT '名称',`car_park_id` varchar(64) DEFAULT NULL COMMENT '停车场id',`no` varchar(100) DEFAULT NULL COMMENT '订单号',`create_time` datetime DEFAULT NULL COMMENT '创建时间',PRIMARY KEY (`id`)) ENGINE=InnoDB DEFAULT CHARSET=utf8 COMMENT='测试分表';
注意
这里有一个限制,如果配置了分库,则两个库以torder为开头的表,在两个库中的表结构表数量一定要是一样的,不然查询的时候shardingjdbc就会报错!!!
pom文件
<dependencies><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-web</artifactId></dependency><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-test</artifactId><scope>test</scope><exclusions><exclusion><groupId>org.junit.vintage</groupId><artifactId>junit-vintage-engine</artifactId></exclusion></exclusions></dependency><!--mybatisplus--><dependency><groupId>com.baomidou</groupId><artifactId>mybatis-plus-boot-starter</artifactId><version>3.2.0</version></dependency><!--lombok--><dependency><groupId>org.projectlombok</groupId><artifactId>lombok</artifactId><scope>provided</scope></dependency><!--fastjson--><dependency><groupId>com.alibaba</groupId><artifactId>fastjson</artifactId><version>1.2.60</version></dependency><!--mysql--><dependency><groupId>mysql</groupId><artifactId>mysql-connector-java</artifactId><version>5.1.44</version></dependency><!--druid--><dependency><groupId>com.alibaba</groupId><artifactId>druid</artifactId><version>1.1.20</version></dependency><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-log4j2</artifactId></dependency><!--sharding jdbc springboot--><dependency><groupId>org.apache.shardingsphere</groupId><artifactId>sharding-jdbc-spring-boot-starter</artifactId><version>4.0.0-RC2</version></dependency><dependency><groupId>org.apache.shardingsphere</groupId><artifactId>sharding-jdbc-spring-namespace</artifactId><version>4.0.0-RC2</version></dependency></dependencies>
pom文件需要注意的问题:
- sharding-jdbc-spring-boot-starter以及sharding-jdbc-spring-namespace这里的版本用的是4.0.0-RC2,其他版本我也没试过,不知道有没有问题。
- 如果引用了sharingjdbc starter包,那么druid的包不能是starter的,只能是普通版本的
- 目前这个版本sharingjdbc包的版本好像和mybatisplus的版本有冲突,问题会在分页的时候出现,那就是分页的时候,汇总字段,会出现long类型转int的错误,经过测试,mybatis plus 版本选择3.3.1.tmp,sharding的版本选择4.0.0就不会出现这样的问题
application.yml
spring:shardingsphere:datasource:# 数据库名称,可自定义,可以为多个,以逗号隔开,每个在这里定义的库,都要在下面定义连接属性names: ds2019,ds2020#年份为2019年的库ds2019:# 采用的数据库连接池,druidtype: com.alibaba.druid.pool.DruidDataSourcedriver-class-name: com.mysql.jdbc.Driverurl: jdbc:mysql://192.168.4.71:3307/sharding2019?useUnicode=true&characterEncoding=UTF-8&useSSL=false&serverTimezone=Asia/Shanghaiusername: rootpassword: 123456maxActive: 20initialSize: 5maxWait: 60000minIdle: 5timeBetweenEvictionRunsMillis: 60000minEvictableIdleTimeMillis: 300000validationQuery: SELECT 1 FROM DUALtestWhileIdle: truetestOnBorrow: falsetestOnReturn: false#是否缓存preparedStatement,也就是PSCache。在mysql下建议关闭。 PSCache对支持游标的数据库性能提升巨大,比如说oracle。poolPreparedStatements: false#要启用PSCache,-1为关闭 必须配置大于0,当大于0时,poolPreparedStatements自动触发修改为true 可以把这个数值配置大一些,比如说100maxOpenPreparedStatements: -1#配置监控统计拦截的filters,去掉后监控界面sql无法统计,'wall'用于防火墙filters: stat,wall,log4j2#通过connectProperties属性来打开mergeSql功能;慢SQL记录connectionProperties: druid.stat.mergeSql=true;druid.stat.slowSqlMillis=5000#合并多个DruidDataSource的监控数据useGlobalDataSourceStat: trueloginUsername: druidloginPassword: druid#年份为2020年的库ds2020:type: com.alibaba.druid.pool.DruidDataSourcedriver-class-name: com.mysql.jdbc.Driverurl: jdbc:mysql://192.168.4.71:3307/sharding2020?useUnicode=true&characterEncoding=UTF-8&useSSL=false&serverTimezone=Asia/Shanghaiusername: rootpassword: 123456maxActive: 20initialSize: 5maxWait: 60000minIdle: 5timeBetweenEvictionRunsMillis: 60000minEvictableIdleTimeMillis: 300000validationQuery: SELECT 1 FROM DUALtestWhileIdle: truetestOnBorrow: falsetestOnReturn: false#是否缓存preparedStatement,也就是PSCache。在mysql下建议关闭。 PSCache对支持游标的数据库性能提升巨大,比如说oracle。poolPreparedStatements: false#要启用PSCache,-1为关闭 必须配置大于0,当大于0时,poolPreparedStatements自动触发修改为true 可以把这个数值配置大一些,比如说100maxOpenPreparedStatements: -1#配置监控统计拦截的filters,去掉后监控界面sql无法统计,'wall'用于防火墙filters: stat,wall,log4j2#通过connectProperties属性来打开mergeSql功能;慢SQL记录connectionProperties: druid.stat.mergeSql=true;druid.stat.slowSqlMillis=5000#合并多个DruidDataSource的监控数据useGlobalDataSourceStat: trueloginUsername: druidloginPassword: druidsharding:default-data-source-name: ds2020#需要拆分的表,可以设置多个tables:#需要进行分表的逻辑表名,用MyBatis或者MyBatis-Plus操作数据库时只需要操作逻辑表即可,xml文件也只需要配置逻辑表t_order:#实际的表结点,下面代表的是ds2019.t_order_0、ds2019.t_order_1、ds2020.t_order_0、ds2020.t_order_1 这几张表actual-data-nodes: ds$->{2019..2020}.t_order_$->{0..1}#分库策略,按照创建时间的年份分库,如果不用分库的,直接注释掉分库相关的代码database-strategy:standard:sharding-column: create_timeprecise-algorithm-class-name: com.example.demo.config.sharding.CreateTimeShardingDatabaseAlgorithmtable-strategy:# 分表策略,根据自己的需要写的分表策略,这里我是根据car_park_id这个字段的值作为后缀,来确定放到哪张表standard:sharding-column: car_park_idprecise-algorithm-class-name: com.example.demo.config.sharding.CarParkShardingTableAlgorithmprops:# 是否打印逻辑SQL语句和实际SQL语句,建议调试时打印,在生产环境关闭sql:show: true#是否输出Mybatis-Plus代执行的SQL语句logging:level:com.example.demo.module.dao: traceserver:port: 8888
这里需要注意的问题
- database-strategy: 这个的意思是自定义分库策略,同样的table-strategy:这个代表的是自定义分表策略。而这和官方文档提供的分表分片策略有所不同,官方文档提供的是
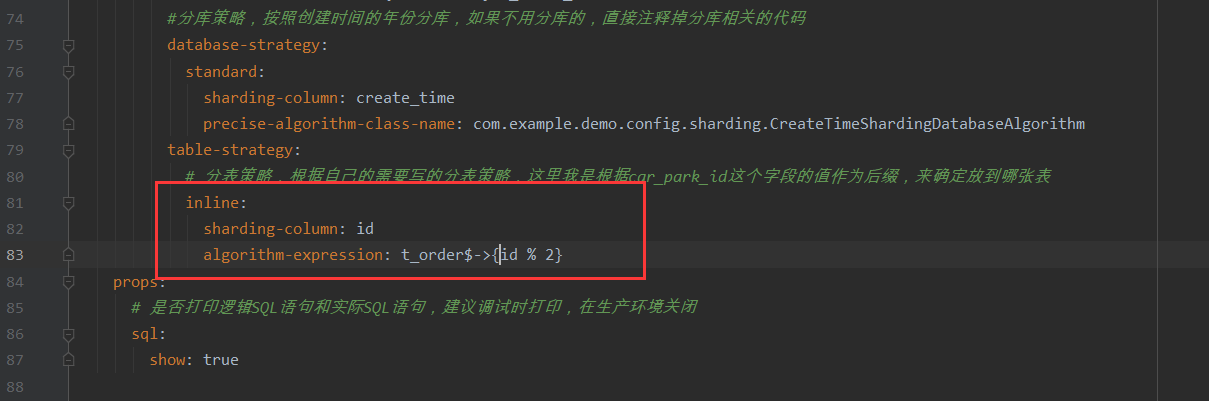
这个的意思是直接通过id取模分表,比如id为3,3%2 = 1,所以这条数据会被分配到t_order_1这种表中,这样的好处就是不用自己写配置类,比较方便,但是这种形式不够灵活,因为自己写分表配置类,也可以实现上面所说的功能。
官方提供的分片策略有很多,可以支持自己定义,很灵活。
可以参考:
https://shardingsphere.apache.org/document/current/cn/features/sharding/concept/sharding/
这里一定要记住关键字的区别:
standard 代表自定义分表策略,需要配合precise-algorithm-class-name属性指定自定义分表策略所在的类
inline 代表的是行表达式分片策略,可以通过简单的算法表达式直接进行分表
设置默认库
分了多个库,必须设置默认数据库!!!必须!!!不然普通业务表shardingjdbc不知道去哪个库取。
配置方式参考配置文件中的default-data-source-name: sharding2020
这里面填的数据库名字和上面配置的names必须是一样的
分库策略类
package com.example.demo.config.sharding;import org.apache.shardingsphere.api.sharding.standard.PreciseShardingAlgorithm;import org.apache.shardingsphere.api.sharding.standard.PreciseShardingValue;import java.text.SimpleDateFormat;import java.util.Collection;import java.util.Date;/*** @title: CarParkShardingTableAlgorithm* @projectName shardingdemo* @description: 按创建时间分库* @author zhy* @date 2020/5/611:25*/public class CreateTimeShardingDatabaseAlgorithm implements PreciseShardingAlgorithm<Date> {@Overridepublic String doSharding(Collection<String> collection, PreciseShardingValue<Date> preciseShardingValue) {Date value = preciseShardingValue.getValue();SimpleDateFormat sdf = new SimpleDateFormat("yyyy");StringBuilder sb = new StringBuilder();sb.append("ds").append(sdf.format(value));return sb.toString();}}
分表策略类
package com.example.demo.config.sharding;import org.apache.shardingsphere.api.sharding.standard.PreciseShardingAlgorithm;import org.apache.shardingsphere.api.sharding.standard.PreciseShardingValue;import java.util.Collection;/*** @title: CarParkShardingTableAlgorithm* @projectName shardingdemo* @description: 按停车场id分表* @author zhy* @date 2020/5/611:25*/public class CarParkShardingTableAlgorithm implements PreciseShardingAlgorithm<String> {@Overridepublic String doSharding(Collection<String> collection, PreciseShardingValue<String> preciseShardingValue) {StringBuilder sb = new StringBuilder();String value = preciseShardingValue.getValue();//获取设置的虚拟表名称,这里获取到的logicTableName=t_orderString logicTableName = preciseShardingValue.getLogicTableName();//拼接实际的表名称,value为carParkId字段的值sb.append(logicTableName).append("_").append(value);return sb.toString();}}
最后贴上源码地址,可以直接跑起来,看看效果,记得修改自己的数据库地址哦
https://github.com/zhyhuayong/shardingSpringbootDemo
存在的问题
这种方式适合表结构一定的方案,例如按月分表,每个月的表结构都能确定下来,也就是application.yml中的actual-data-nodes这个配置能确定下来,项目启动之后就不变,可以一直使用。但是问题来了,我这边的分表逻辑是按停车场id分表,停车场的是可以增删的,那么我现在分表的actual-data-nodes这个也要随着我停车场的改变而改变,所以这个问题困扰了我很久,最后我通过sharding-jdbc基于java的配置,加上ShardingSphere的服务编排治理,实现了在项目运行中动态的改变actual-data-nodes。详情请参考下一篇文章

若有收获,就点个赞吧
0 人点赞
