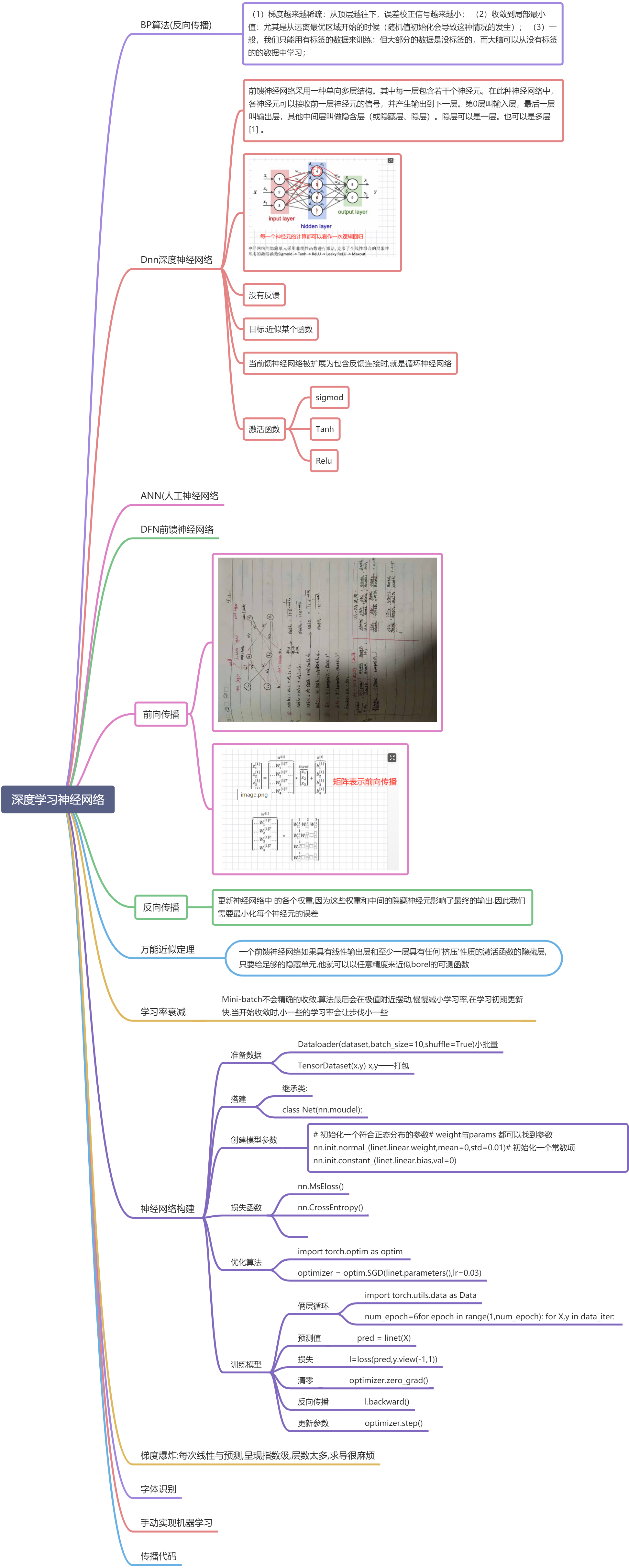
 前向传播:
前向传播:
y=torch.mul(w,x) #等价于w*x
y=torch.mm(w,x)
z=torch.add(y,b) #等价于y+b
#定义输入张量xx = torch.tensor(2.0, requires_grad=True)# 初始化权重参数W,偏移量b、并设置require_grad属性为True,自动跟踪历史导数w=torch.randn(1,requires_grad=True) # torch.rand(2,2,requires_grad=True)b=torch.randn(1,requires_grad=True)# 实现前向传播y=torch.mul(w,x) #等价于w*xz=torch.add(y,b) #等价于y+b#查看x,w,b页子节点的requite_grad属性# requires_grad(自动获取梯度)设置为Trueprint("x,w,b的require_grad属性分别为:{},{},{}".format(x.requires_grad,w.requires_grad,b.requires_grad))print(x)print("w",w)print('b',b)print('y',y)print('z',z)
反向传播:
y3.backward()
手动实现机器学习:
import torchfrom IPython import displayfrom matplotlib import pyplot as pltimport numpy as npimport random%matplotlib inline



构建神经网络:
定义模型 类创建,CLASS Net(父类:nn.moudle)
初始化函数: 参数-n_feature 特征个数
继承:super(Net,self).__init—(), 初始化父类
初始化自己:self.linear=nn.linear(输入特征维度,输出维度,偏置=True默认)
遍历 for item in self.linear.params:
参数出来了
初始化参数: nn.init.normul(item,m=,)
定义前向传播
y = self.linear(x)
return y
实例化对象
import numpy as npimport torchfrom torch import nn
初始化模型参数
损失函数:
优化算法:
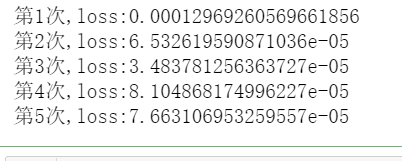
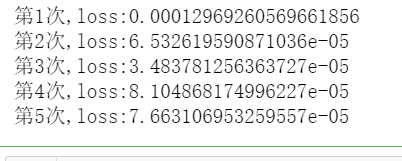
训练模型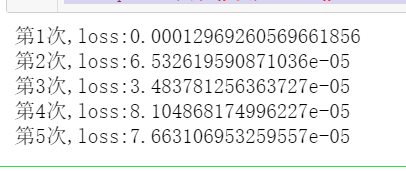
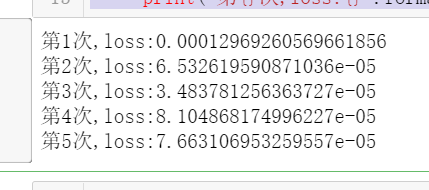
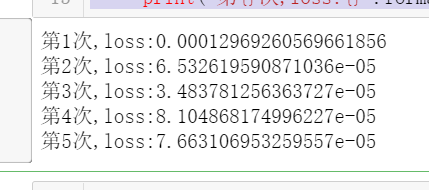
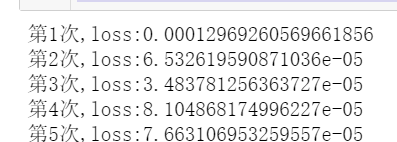
class Net(nn.Module):"""使用sequential构建网络,Sequential()函数的功能是将网络的层组合到一起"""#indim 输入维度. n_hidden 隐藏层个数def __init__(self, in_dim, n_hidden_1, n_hidden_2, out_dim):#继承父类属性super(Net, self).__init__()#定义自己每一层,Sequential,拼接每一层方法(第一步线性连接nn.linear(输入,输出),第二归一化处理nn.BatchNorm1d(n_hidden_1))self.layer1 = nn.Sequential(nn.Linear(in_dim, n_hidden_1),nn.BatchNorm1d(n_hidden_1))self.layer2 = nn.Sequential(nn.Linear(n_hidden_1, n_hidden_2),nn.BatchNorm1d(n_hidden_2))self.layer3 = nn.Sequential(nn.Linear(n_hidden_2, out_dim))def forward(self, z):#z = F.relu(self.layer1(z))z = F.relu(self.layer2(z))z = self.layer3(z)return zmodel = Net(28 * 28, 300, 100, 10)
字体识别
import numpy as npimport torch# 导入 pytorch 内置的 mnist 数据from torchvision.datasets import mnist#导入预处理模块import torchvision.transforms as transformsfrom torch.utils.data import DataLoader#导入nn及优化器import torch.nn.functional as Fimport torch.optim as optimfrom torch import nnimport matplotlib.pyplot as plt%matplotlib inlin
说明
①transforms.Compose可以把一些转换函数组合在一起;
②Normalize([0.5], [0.5])对张量进行归一化,这里两个0.5分别表示对张量进行归一化的全局平均值和方差。因图像是灰色的只有一个通道,如果有多个通道,需要有多个数字,如三个通道,应该是Normalize([m1,m2,m3], [n1,n2,n3])
③download参数控制是否需要下载,如果./data目录下已有MNIST,可选择False。
④用DataLoader得到生成器,这可节省内存。
train_batch_size = 64test_batch_size = 128learning_rate = 0.01num_epoches = 20lr = 0.01momentum = 0.5
#定义预处理函数,这些预处理依次放在Compose函数中。transform = transforms.Compose([transforms.ToTensor(),transforms.Normalize([0.5], [0.5])])#下载数据,并对数据进行预处理train_dataset = mnist.MNIST('./data', train=True, transform=transform, download=True)test_dataset = mnist.MNIST('./data', train=False, transform=transform)#dataloader是一个可迭代对象,可以使用迭代器一样使用。train_loader = DataLoader(train_dataset, batch_size=train_batch_size, shuffle=True)test_loader = DataLoader(test_dataset, batch_size=test_batch_size, shuffle=False)examples = enumerate(test_loader)batch_idx, (example_data, example_targets) = next(examples)fig = plt.figure()for i in range(6):plt.subplot(2,3,i+1)plt.tight_layout()# example_data[i][0] 这个操作是拿出plt.imshow(example_data[i][0], cmap='summer', interpolation='none')plt.title("Ground Truth: {}".format(example_targets[i]))
创建神经网络预测:
class Net(nn.Module):"""使用sequential构建网络,Sequential()函数的功能是将网络的层组合到一起"""def __init__(self, in_dim, n_hidden_1, n_hidden_2, out_dim):super(Net, self).__init__()self.layer1 = nn.Sequential(nn.Linear(in_dim, n_hidden_1),nn.BatchNorm1d(n_hidden_1))self.layer2 = nn.Sequential(nn.Linear(n_hidden_1, n_hidden_2),nn.BatchNorm1d(n_hidden_2))self.layer3 = nn.Sequential(nn.Linear(n_hidden_2, out_dim))def forward(self, z):z = F.relu(self.layer1(z))z = F.relu(self.layer2(z))z = self.layer3(z)return z
#检测是否有可用的GPU,否则使用CPU# device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")#实例化网络,定义隐藏层个数model = Net(28 * 28, 300, 100, 10)# model.to(device)# 定义损失函数和优化器# 定义交叉熵损失criterion = nn.CrossEntropyLoss()# 梯度下降model.parameters() 所有参数,矩阵optimizer = optim.SGD(model.parameters(), lr=lr, momentum=momentum)
训练模型
# 开始训练losses = [] #训练acces = []eval_losses = [] #评估eval_acces = []for epoch in range(num_epoches):train_loss = 0train_acc = 0# 训练模式model.train()#动态修改参数学习率if epoch%5==0:optimizer.param_groups[0]['lr']*=0.1# 做训练for img, label in train_loader:# img=img.to(device)# label = label.to(device)# n行一列img = img.view(img.size(0), -1)# 前向传播out = model(img)# 计算损失loss = criterion(out, label)# 反向传播optimizer.zero_grad()loss.backward()# 参数更新optimizer.step()# 记录误差train_loss += loss.item() #python# 计算分类的准确率_, pred = out.max(1)num_correct = (pred == label).sum().item()acc = num_correct / img.shape[0]train_acc += acclosses.append(train_loss / len(train_loader))acces.append(train_acc / len(train_loader))# 在测试集上检验效果eval_loss = 0eval_acc = 0# 将模型改为预测模式model.eval()for img, label in test_loader:img=img.to(device)label = label.to(device)img = img.view(img.size(0), -1)out = model(img)loss = criterion(out, label)# 记录误差# .item() 转化为python可以识别的类型eval_loss += loss.item()# 记录准确率_, pred = out.max(1)#判断布尔索引是否相等,求和num_correct = (pred == label).sum().item()acc = num_correct / img.shape[0]# 每一层循环的损失都累加一次,eval_acc += acceval_losses.append(eval_loss / len(test_loader))eval_acces.append(eval_acc / len(test_loader))print('epoch: {}, Train Loss: {:.4f}, Train Acc: {:.4f}, Test Loss: {:.4f}, Test Acc: {:.4f}'.format(epoch, train_loss / len(train_loader), train_acc / len(train_loader),eval_loss / len(test_loader), eval_acc / len(test_loader)))

若有收获,就点个赞吧
0 人点赞
