基于Policy Gradient的算法是Policy Optimization算法的一个重要分支,本篇文章主要梳理该类算法的原理及其演进脉络。如下图所示,Policy Gradient相关算法和属于Actor-Critic算法的思维导图。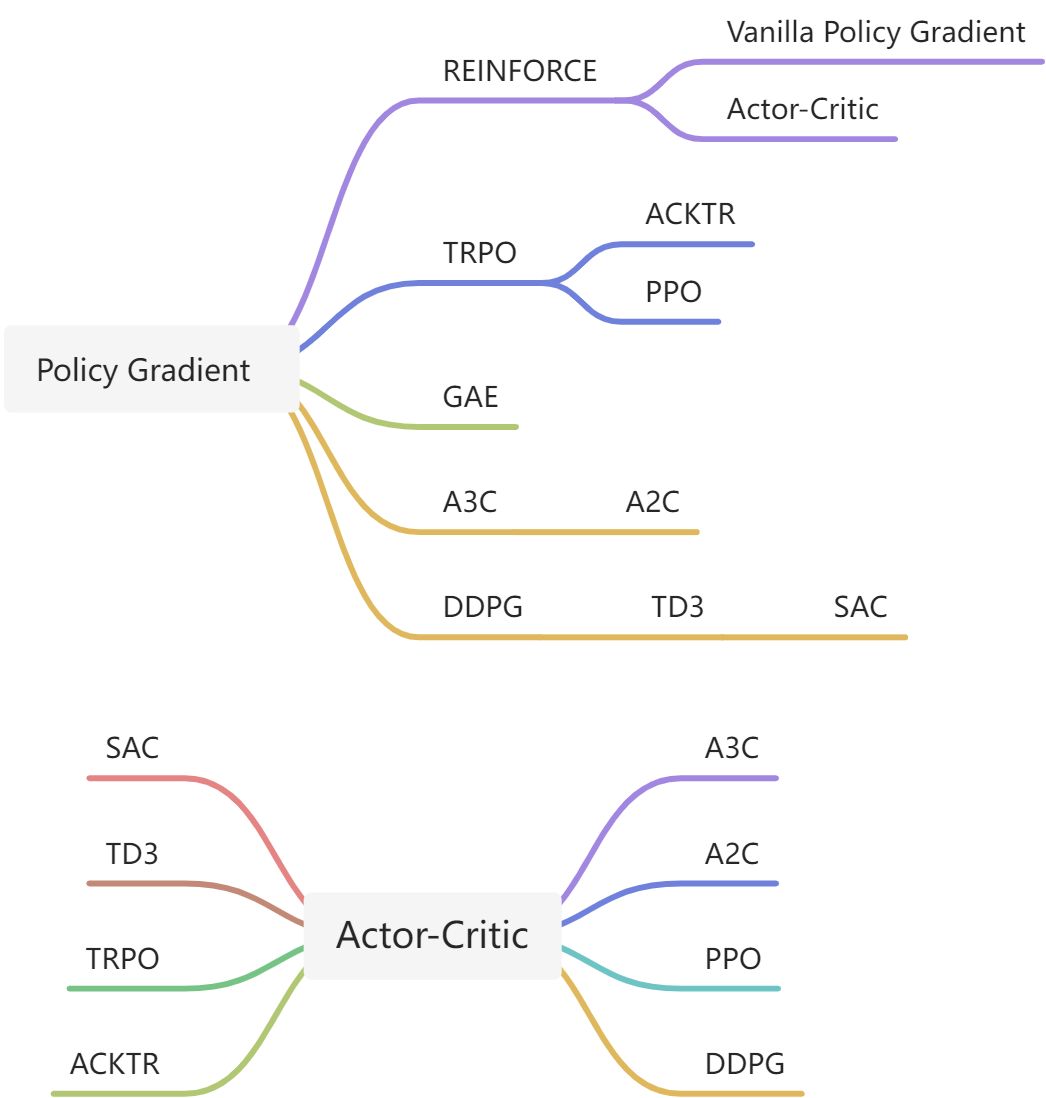
关于Policy Gradient的计算原理,请参见文件:
Policy Gradient的计算原理
REINFORCE
REINFORCE算法是一个基于蒙特卡洛的策略梯度算法。其中,使用如下公式(1)进行梯度更新。 (1)
(1)
具体伪代码如下图1所示:
图1 REINFORCE伪代码(图片来自强化学习纲要)
对于REINFORCE算法,可以通过减去一个Baseline( 函数与action无关)的方式降低方差且不会改变该算法的bias。最佳的Baseline为状态
函数与action无关)的方式降低方差且不会改变该算法的bias。最佳的Baseline为状态 的价值,如公式(2)所示:
的价值,如公式(2)所示: (2)
(2)
Actor-Critic
Actor-Critic本质上是在REINFORCE算法中,使用价值函数作为奖励。因此,不仅仅要学习策略函数 ,还要学习动作-状态价值函数
,还要学习动作-状态价值函数 。具体伪代码如下图2所示:
。具体伪代码如下图2所示:
图2 Actor-Critic算法伪代码(图片来自文献1)
注解:
- 降低方差的算法中,TD error中的Q函数也可以全部换为价值函数V,即对于Critic只需要学习价值函数。
- 降低方差的算法中,Actor-Critic算法也可以视作Vanilla Policy Gradient算法的特例。其中,Vanilla Policy Gradient算法是对REINFORCE算法改进版的泛化形式。
最后,对于REINFORCE和actor-critic算法之间的关系,可以进行如下总结:
TRPO
TRPO算法主要是为了解决Policy_Gradient类算法采样效率低和训练不平稳的问题。对于以上两种问题分别采取了两种方法进行解决,分别是:
- Trust region and natural policy gradient的办法解决训练不平稳的问题。
- Importance sampling解决采样效率低的问题。
Trust region and natural policy gradient核心思想:使用KL-divergence限定策略函数更新的幅度,从而降低训练的不稳定性。其中,Natural Gradient是基于KL-divergence距离寻找最优方向和距离;而norm-gradient是基于欧氏距离寻找方向和距离,该方法容易受到初始化参数的影响。
Importance sampling核心思想:使用off-policy的方法训练Policy函数。
具体伪代码如下图3所示:
图3 TRPO伪代码(图片来自强化学习纲要)
ACKTR
ACKTR算法主要为了解决TRPO算法中Fisher Information Matrix(用于近似KL-divergence的协方差矩阵)逆求解复杂度较高以及由此带来的采样效率低的问题。
该算法使用Kronecker-factored近似Fisher matrix,进而有效的近似natrual gradient updates.对于Fisher matrix矩阵的近似可以参见公式(3),对于natrual gradient updates的近似可以参见公式(4)。 (3)
(3)
 (4)
(4)
 (5)
(5) (6)
(6)
PPO
PPO算法的提出是为了进一步提高RL算法在可扩展性、数据采样效率以及强健性方面的性能。该算法提出了两种损失函数,分别是Clipped Surrogate Objective和Adaptive KL Penalty Coefficient,具体公式如下式(7)和公式(8)。 (7)
(7)
Adaptive KL Penalty Coefficient:
- 优化KL-penalized 目标函数
 (8)
(8)
- 计算

- If

- If

- If
如下图4所示,PPO算法的伪代码:
图4 PPO算法的伪代码
GAE
GAE算法提出了一个Advantage函数的估计方法,以及使用KL-divergence优化价值函数近似时发生过拟合问题的方法。
DDPG
DDPG算法是一个基于actor-critic架构,可以运用在连续动作空间的算法。该算法的理论基础是确定性策略梯度理论,且具有以下特点:
- 继承了DQN算法的targte network和replay buffer
- 对于动作进行了随机过程扰动的采样
- target network进行了软更新
具体算法伪代码如下图6所示
图6 DDPG算法伪代码
A3C
A3C算法是Asynchronous RL Framework的一个实现版本,该类算法基于并行异步actor-learners的方法可以代替replay-memory的方法实现降低数据之间耦合。并行学习的方法有以下好处:
- 数据之间的相关性降低了很多。
- 训练时间大大减少。
- 可以使用online-policy的RL算法代码。
如下图7所示,A3C算法的伪代码。
图7 A3C算法伪代码
由上图7可得,异步并行的方法更新算法主要技术点分别是梯度累计和parallel actor-learners。
A2C
A2C是A3C算法针对训练不一致性提出的改进版本,相较于A3C,该算法会等待所有actor学习玩之后,进行策略函数和价值函数的更新。
TD3
为了解决deep Q-learning相关算法,对价值高估和高方差问题,提出了TD3算法。其中,高方差主要是由每步的时序差分算法累计造成的,且off-policy和时序差分均会对价值高估产生影响。
该算法具有以下特点:
- clipped Double-Q Learning
- “Delayed” Policy Updates
- Target Policy Smoothing
该算法的具体伪代码如下图8所示:
图8 TD3算法的伪代码
SAC
SAC算法的提出是为了解决 actor-critic算法训练不平稳和采样效率不高的问题。该算法提出了Soft Policy Evaluation,Soft Policy Improvement,Soft Policy Iteration理论,并对其进行了证明。与TD3时序差分更新Q函数相比,SAC使用了Bellman方程更新Q函数,且只有价值函数有target network。具体算法伪代码如下图9所示。
图9 SAC算法的伪代码
参考文献
- Policy Gradient Algorithms
- Richard S. Sutton and Andrew G. Barto. Reinforcement Learning: An Introduction; 2nd Edition. 2017.
- Policy Gradient的计算原理
- John Schulman, et al. “Trust region policy optimization.” ICML. 2015.
- Natural Gradient Descent
- Fisher Information Matrix
- 强化学习纲要
- OpenAI Baselines: ACKTR & A2C
- Advanced Policy Gradient Methods
- Advanced Policy Gradient Methods PPT

若有收获,就点个赞吧
0 人点赞
