Java Heap、Off-Heap
Java Advanced Runtime Options
java进程的内存分类:
- heap,堆内内存,受GC管理。参数有 Xmx Xms Xmn等。
- Off-Heap,堆外内存
- jvm运行需要的堆外内存
如JVM Metaspace、JVM OverHead(thread stacks, code cache, garbage collection space等) - 业务可以使用的堆外内存
- jvm运行需要的堆外内存

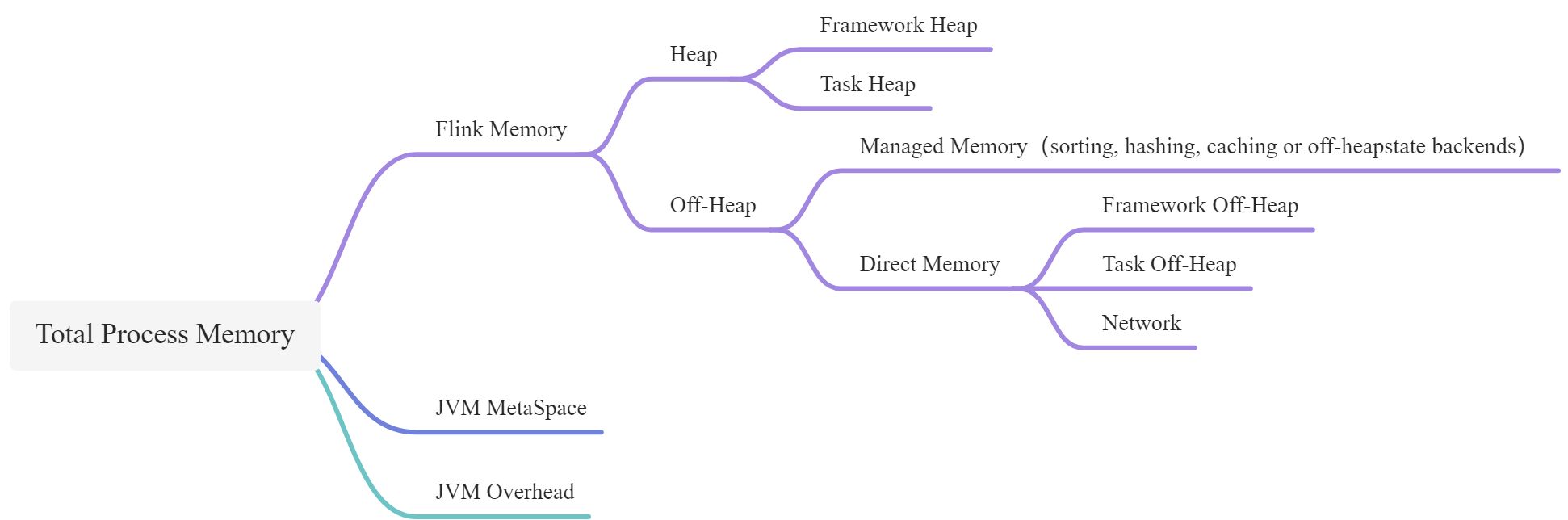
| Component | Configuration options | Description |
|---|---|---|
| Framework Heap Memory | taskmanager.memory.framework.heap.size | JVM Heap memory dedicated to Flink framework (advanced option) |
| Task Heap Memory | taskmanager.memory.task.heap.size | JVM Heap memory dedicated to Flink application to run operators and user code |
| Managed memory | taskmanager.memory.managed.size |
taskmanager.memory.managed.fraction | Native memory managed by Flink, reserved for sorting, hash tables, caching of intermediate results and RocksDB state backend |
| Framework Off-heap Memory | taskmanager.memory.framework.off-heap.size | Off-heap direct (or native) memory
dedicated to Flink framework (advanced option) |
| Task Off-heap Memory | taskmanager.memory.task.off-heap.size | Off-heap direct (or native) memory
dedicated to Flink application to run operators |
| Network Memory | taskmanager.memory.network.min
taskmanager.memory.network.max
taskmanager.memory.network.fraction | Direct memory reserved for data record exchange between tasks (e.g. buffering for the transfer over the network), is a capped fractionated component
of the total Flink memory
. This memory is used for allocation of network buffers |
| JVM metaspace | taskmanager.memory.jvm-metaspace.size | Metaspace size of the Flink JVM process |
| JVM Overhead | taskmanager.memory.jvm-overhead.min
taskmanager.memory.jvm-overhead.max
taskmanager.memory.jvm-overhead.fraction | Native memory reserved for other JVM overhead: e.g. thread stacks, code cache, garbage collection space etc, it is a capped fractionated component
of the total process memory |
MemorySegment
Flink内存管理的基本单元,底层存储结构分heap和off-heap。
- heap:byte数组
- off-heap:direct(用于network)和unsafe(用于managed memory)
MemorySegmentFactory
所有的MemorSegment都是通过MemorySegmentFactory创建的。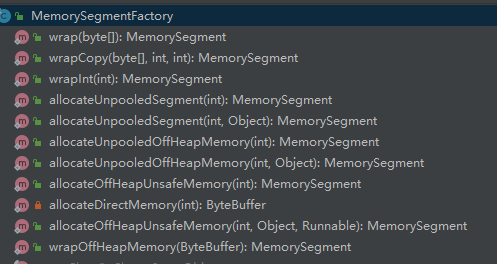
Network Off-Heap
Network缓冲区底层使用的是DirectByteBuffer,并且保证了永远不会超出Network Memory大小限制。
NetworkBufferPool
- TM级别的全局固定大小的pool,代表了TM整个Network buffer。
其大小networkMemSize=totalNumberOfMemorySegments*memorySegmentSize,
在TM启动初始化shuffle(NettyShuffleEnvironment)的时候创建的。 其主要两个作用
写:ResultPartition级别pool
Task new时创建ResultPartitionWriter,每个ResultPartitionWriter持有一个LocalBufferPool,在setup时创建。- 读:InputGate级别pool。
Task new时创建InputGate,每个InputGate持有一个LocalBufferPool,在setup时创建。Network Buffer在数据发送层的作用
BufferBuilder
- 两个成员变量,
- memorySegment,LocalBufferPool#toBufferBuilder申请到后,传入的。
- buffer,
this.buffer = new NetworkBuffer(memorySegment, recycler);封装了segment
- 作用
- 用来向Segment写入内容,append方法。
- 创建BufferConsumer。
在flink数据流动中,我们提到ResultPartitionWriter emitRecord方法从数据流动的角度讲主要是向BufferBuild append record。
从内存的角度,emitRecord会去LocalBufferPool申请BufferBuild,如果buffer不足,则会block。
@Overridepublic void emitRecord(ByteBuffer record, int targetSubpartition) throws IOException {totalWrittenBytes += record.remaining();//append record to subPartitionBufferBuilder buffer = appendUnicastDataForNewRecord(record, targetSubpartition);while (record.hasRemaining()) {// full buffer, partial recordfinishUnicastBufferBuilder(targetSubpartition);buffer = appendUnicastDataForRecordContinuation(record, targetSubpartition);}if (buffer.isFull()) {// full buffer, full recordfinishUnicastBufferBuilder(targetSubpartition);}// partial buffer, full record}private BufferBuilder appendUnicastDataForNewRecord(final ByteBuffer record, final int targetSubpartition) throws IOException {if (targetSubpartition < 0 || targetSubpartition > unicastBufferBuilders.length) {throw new ArrayIndexOutOfBoundsException(targetSubpartition);}BufferBuilder buffer = unicastBufferBuilders[targetSubpartition];if (buffer == null) {//如果subPartition对应的BufferBuilder不存在,申请新的buffer = requestNewUnicastBufferBuilder(targetSubpartition);//新申请的BufferBuilder添加到subpartition中的BufferConsumer队列buffers,//以使读取时能读到addToSubpartition(buffer, targetSubpartition, 0, record.remaining());}//具体往buffer写数据buffer.appendAndCommit(record);return buffer;}private BufferBuilder requestNewUnicastBufferBuilder(int targetSubpartition)throws IOException {checkInProduceState();ensureUnicastMode();final BufferBuilder bufferBuilder = requestNewBufferBuilderFromPool(targetSubpartition);unicastBufferBuilders[targetSubpartition] = bufferBuilder;return bufferBuilder;}private BufferBuilder requestNewBufferBuilderFromPool(int targetSubpartition)throws IOException {//LocalBufferPool去申请bufferBufferBuilder bufferBuilder = bufferPool.requestBufferBuilder(targetSubpartition);if (bufferBuilder != null) {return bufferBuilder;}hardBackPressuredTimeMsPerSecond.markStart();try {//如果申请buffer的为null则阻塞直到申请成功。bufferBuilder = bufferPool.requestBufferBuilderBlocking(targetSubpartition);hardBackPressuredTimeMsPerSecond.markEnd();return bufferBuilder;} catch (InterruptedException e) {throw new IOException("Interrupted while waiting for buffer");}}
NetworkBuffer
作用
NetworkBuffer继承自AbstractReferenceCountedByteBuf。
是在FLINK-7315引入的,避免了传递给netty ByteBuf时不必要的内存拷贝。
封装了MemorySegment,MemorySegment底层是ByteBuffer。
NetworkBuffer会作为BufferResponse的成员变量,在BufferResponse序列化时直接write NetworkBuffer,不用重新申请netty的ByteBuf,减少了内存拷贝。
整个数据发送的过程,在用户态只会在BufferBuilder#append时,把record序列化的数据copy到MemorySegment里去。 在发送侧,netty直接发送flink buffer的数据,不需要再次copy到netty buffer。
ByteBufAllocator(NettyBufferPool)
NettyBufferPool#NettyBufferPool控制PooledByteBufAllocator
BufferConsumer
生成NetworkBuffer,包含BufferBuilder写入数据。
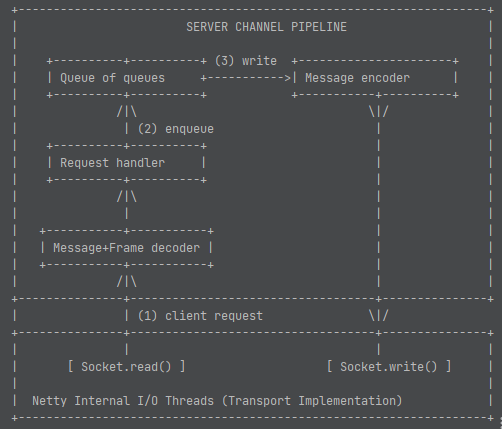
在flink数据流动,我们提到在writeAndFlushNextMessageIfPossible中 NettyServer发送BufferResponse消息给下游。poll到有数据的reader,reader读数据的具体逻辑在next = reader.getNextBuffer();。
最后的逻辑其实就是BufferConsumer build出来最终的NetworkBuffer。
public BufferAndAvailability getNextBuffer() throws IOException {BufferAndBacklog next = subpartitionView.getNextBuffer();···return new BufferAndAvailability(next.buffer(), nextDataType, next.buffersInBacklog(), next.getSequenceNumber());···}public BufferAndBacklog getNextBuffer() {return parent.pollBuffer();}BufferAndBacklog pollBuffer() {···while (!buffers.isEmpty()) {BufferConsumerWithPartialRecordLength bufferConsumerWithPartialRecordLength =buffers.peek();BufferConsumer bufferConsumer =bufferConsumerWithPartialRecordLength.getBufferConsumer();buffer = buildSliceBuffer(bufferConsumerWithPartialRecordLength);···return new BufferAndBacklog(buffer,getBuffersInBacklogUnsafe(),isDataAvailableUnsafe() ? getNextBufferTypeUnsafe() : Buffer.DataType.NONE,sequenceNumber++);}}Buffer buildSliceBuffer(BufferConsumerWithPartialRecordLength buffer) {return buffer.build();}
线程模型
两个线程
- Task运行线程。处理一条数据后最终通过BufferBuild写入Buffer。
netty EventLoop线程,处理PartitionRequest请求,availableReaders.poll(),通过ViewReader读buffer。
线程同步
ViewReader层
通过Netty fireUserEventTriggered事件通知的方式,最终在eventloop线程中向PartitionRequestQueue添加reader。
在eventloop线程中poll reader,读buffer写数据。
buffer层
PipelinedSubpartition有个buffers变量
final PrioritizedDeque<BufferConsumerWithPartialRecordLength> buffers = new PrioritizedDeque<>();- Task运行线程写数据申请新的buffer(BufferConsumer的形式)都要add到buffers queue里去。PipelinedSubpartition#add(org.apache.flink.runtime.io.network.buffer.BufferConsumer, int, boolean)过程对buffers 加锁。
EventLoop线程通过reader执行PipelinedSubpartition#pollBuffer,也会对buffers加锁。
Segment层
这一层使用了无锁设计。核心点是用PositionMarker里volatile变量position,记录buffer当前写入数据的offset。
static class SettablePositionMarker implements PositionMarker {private volatile int position = 0;}
Task运行线程BufferBuilder#appendAndCommit,commit更新position。
- EventLoop线程在BufferConsumer#build一个buffer时,先BufferConsumer.CachedPositionMarker#update读取position的值,使只读buffer里position之前的数据。
Network Buffer在数据接收层的作用
接收过程
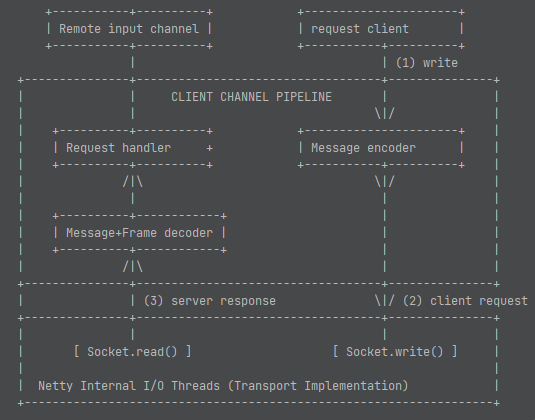
在Flink数据流动一节,回顾一下数据接收的流程:
- 下游task先向上游发送PartitionRequest
- 在CreditBasedPartitionRequestClientHandler保存subPartition对应的RemoteInputChannel
CreditBasedPartitionRequestClientHandler channelRead在读取到message时,获取message对应的RemoteInputChannel。
通过RemoteInputChannel#onBuffer把数据写入到RemoteInputChannel#receivedBuffers队列,并InputChannel#notifyPriorityEvent 通知SingleInputGate当前channel有数据,并存入SingleInputGate#inputChannelsWithData队列。消息格式
Decoder实现
在上面三步中,我们少了一步是把数据从netty buffer decode成Flink buffer。实现主要在FLINK-10742。
decoder包括从flink buffer申请内存的逻辑在NettyMessageClientDecoderDelegate。
现在实现并没有减少从netty buffer copy到flink buffer。具体在这个pr的这个位置。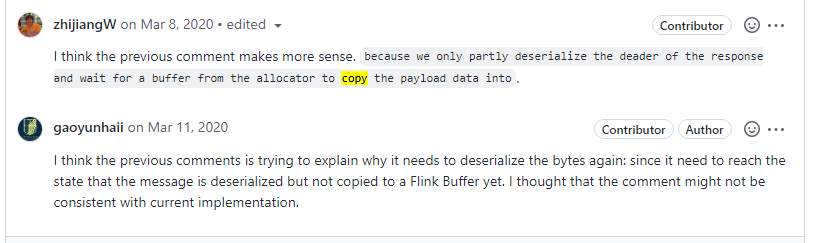
NettyMessageClientDecoderDelegate
frame结构| FRAME LENGTH (4) | MAGIC NUMBER (4) | ID (1) |
负责解析frame header,根据msgId代理到具体decoder。 ```java public void channelRead(ChannelHandlerContext ctx, Object msg) throws Exception { if (!(msg instanceof ByteBuf)) {ctx.fireChannelRead(msg);return;
}
ByteBuf data = (ByteBuf) msg; try {
while (data.isReadable()) {if (currentDecoder != null) {//header解析得到了currentDecoder,把decode交给具体的DecoderNettyMessageDecoder.DecodingResult result = currentDecoder.onChannelRead(data);if (!result.isFinished()) {break;}ctx.fireChannelRead(result.getMessage());currentDecoder = null;frameHeaderBuffer.clear();}//解析header,设置currentDecoderdecodeFrameHeader(data);}checkState(!data.isReadable(), "Not all data of the received buffer consumed.");
} finally {
data.release();
} }

<a name="rcxzz"></a>#### BufferResponseDecoderMessageHeader<br />//receiver ID (16), sequence number (4), backlog (4), dataType (1), isCompressed (1), buffer size (4)1. 根据message header,创建BufferResponse对象。此时通过NetworkBufferAllocator向Flink申请buffer。具体申请在inputChannel.requestBuffer()。```java//BufferResponseDecoder#onChannelReadpublic DecodingResult onChannelRead(ByteBuf data) throws Exception {if (bufferResponse == null) {decodeMessageHeader(data);}···}static BufferResponse readFrom(ByteBuf messageHeader, NetworkBufferAllocator bufferAllocator) {InputChannelID receiverId = InputChannelID.fromByteBuf(messageHeader);int sequenceNumber = messageHeader.readInt();int backlog = messageHeader.readInt();Buffer.DataType dataType = Buffer.DataType.values()[messageHeader.readByte()];boolean isCompressed = messageHeader.readBoolean();int size = messageHeader.readInt();Buffer dataBuffer;if (dataType.isBuffer()) {dataBuffer = bufferAllocator.allocatePooledNetworkBuffer(receiverId);} else {dataBuffer = bufferAllocator.allocateUnPooledNetworkBuffer(size, dataType);}if (size == 0 && dataBuffer != null) {// recycle the empty buffer directly, we must allocate a buffer for// the empty data to release the credit already allocated for itdataBuffer.recycleBuffer();dataBuffer = null;}if (dataBuffer != null) {dataBuffer.setCompressed(isCompressed);}return new BufferResponse(dataBuffer, dataType, isCompressed, sequenceNumber, receiverId, backlog, size);}Buffer allocatePooledNetworkBuffer(InputChannelID receiverId) {Buffer buffer = null;RemoteInputChannel inputChannel = networkClientHandler.getInputChannel(receiverId);// If the input channel has been released, we cannot allocate buffer and the received// message// will be discarded.if (inputChannel != null) {buffer = inputChannel.requestBuffer();}return buffer;}
copy nettybuffer里的数据到flink buffer。
bufferResponse.getBuffer().asByteBuf().writeBytes(data, actualBytesToDecode);public DecodingResult onChannelRead(ByteBuf data) throws Exception {if (bufferResponse == null) {decodeMessageHeader(data);}if (bufferResponse != null) {int remainingBufferSize = bufferResponse.bufferSize - decodedDataBufferSize;int actualBytesToDecode = Math.min(data.readableBytes(), remainingBufferSize);// For the case of data buffer really exists in BufferResponse now.if (actualBytesToDecode > 0) {// For the case of released input channel, the respective data buffer part would be// discarded from the received buffer.if (bufferResponse.getBuffer() == null) {data.readerIndex(data.readerIndex() + actualBytesToDecode);} else {bufferResponse.getBuffer().asByteBuf().writeBytes(data, actualBytesToDecode);}decodedDataBufferSize += actualBytesToDecode;}if (decodedDataBufferSize == bufferResponse.bufferSize) {BufferResponse result = bufferResponse;clearState();return DecodingResult.fullMessage(result);}}return DecodingResult.NOT_FINISHED;}
Managed Memory
TODO

若有收获,就点个赞吧
0 人点赞
