Go并发编程实战
基本并发原语
Mutex:如何解决资源并发访问问题?
临界区就是一个被共享的资源,或者说是一个整体的一组共享资源,比如对数据库的访问、对某一个共享数据结构的操作、对一个 I/O 设备的使用、对一个连接池中的连接的调用,等等
如果很多线程同步访问临界区,就会造成访问或操作错误,这当然不是我们希望看到的结果。所以,我们可以使用互斥锁,限定临界区只能同时由一个线程持有
Mutex 是使用最广泛的同步原语(Synchronization primitives,有人也叫做并发原语)
互斥锁 Mutex、读写锁 RWMutex、并发编排 WaitGroup、条件变量 Cond、Channel 等同步原语
同步原语的适用场景:
- 共享资源。并发地读写共享资源,会出现数据竞争(data race)的问题,所以需要 Mutex、RWMutex 这样的并发原语来保护。
- 任务编排。需要 goroutine 按照一定的规律执行,而 goroutine 之间有相互等待或者依赖的顺序关系,我们常常使用 WaitGroup 或者 Channel 来实现。
- 消息传递。信息交流以及不同的 goroutine 之间的线程安全的数据交流,常常使用 Channel 来实现。
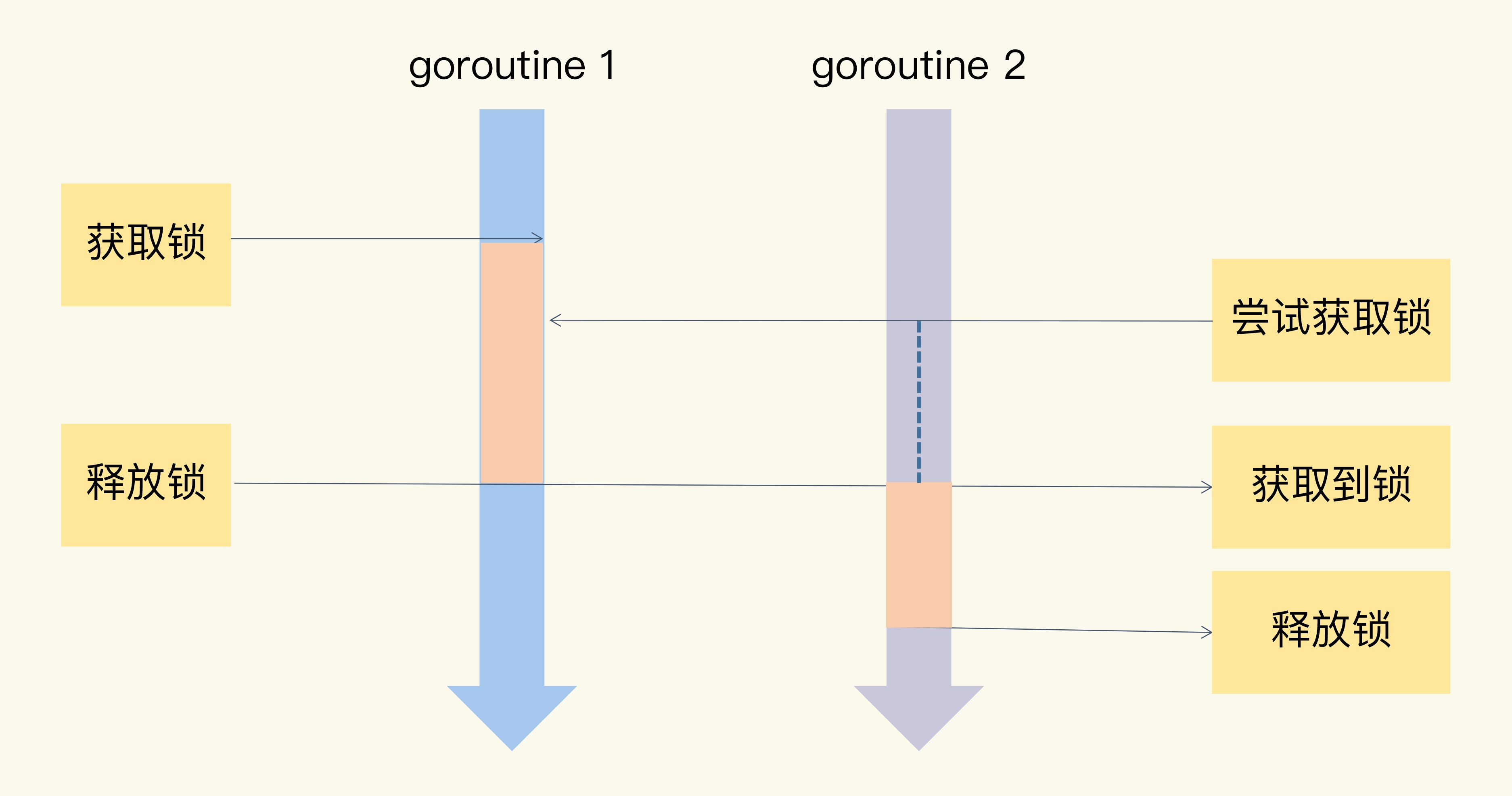
互斥锁 Mutex 就提供两个方法 Lock 和 Unlock:进入临界区之前调用 Lock 方法,退出临界区的时候调用 Unlock 方法
当一个 goroutine 通过调用 Lock 方法获得了这个锁的拥有权后, 其它请求锁的 goroutine 就会阻塞在 Lock 方法的调用上,直到锁被释放并且自己获取到了这个锁的拥有权。
在编译(compile)、测试(test)或者运行(run)Go 代码的时候,加上 race 参数,就有可能发现并发问题。
go run -race counter.go
func main() {
count := 0
var wg sync.WaitGroup
var mu sync.Mutex
for i := 0; i < 10; i++ {
wg.Add(1)
go func() {
defer wg.Done()
for j := 0; j < 1000; j++ {
mu.Lock()
count++
mu.Unlock()
}
}()
}
wg.Wait()
fmt.Println("Count:", count)
}
通过嵌入字段,可以在这个 struct 上直接调用 Lock/Unlock 方法。
type Counter struct {
mu sync.Mutex
Count uint64
}
func main() {
var counter Counter
var wg sync.WaitGroup
wg.Add(10)
for i := 0; i < 10; i++ {
go func() {
defer wg.Done()
for j := 0; j < 100000; j++ {
counter.Lock()
counter.Count++
counter.Unlock()
}
}()
}
wg.Wait()
fmt.Println(counter.Count)
}
type Counter struct {
sync.Mutex
Count uint64
}
把获取锁、释放锁、计数加一的逻辑封装成一个方法,对外不需要暴露锁等逻辑
func main() {
// 封装好的计数器
var counter Counter
var wg sync.WaitGroup
wg.Add(10)
// 启动10个goroutine
for i := 0; i < 10; i++ {
go func() {
defer wg.Done()
// 执行10万次累加
for j := 0; j < 100000; j++ {
counter.Incr() // 受到锁保护的方法
}
}()
}
wg.Wait()
fmt.Println(counter.Count())
}
// 线程安全的计数器类型
type Counter struct {
CounterType int
Name string
mu sync.Mutex
count uint64
}
// 加1的方法,内部使用互斥锁保护
func (c *Counter) Incr() {
c.mu.Lock()
c.count++
c.mu.Unlock()
}
// 得到计数器的值,也需要锁保护
func (c *Counter) Count() uint64 {
c.mu.Lock()
defer c.mu.Unlock()
return c.count
}
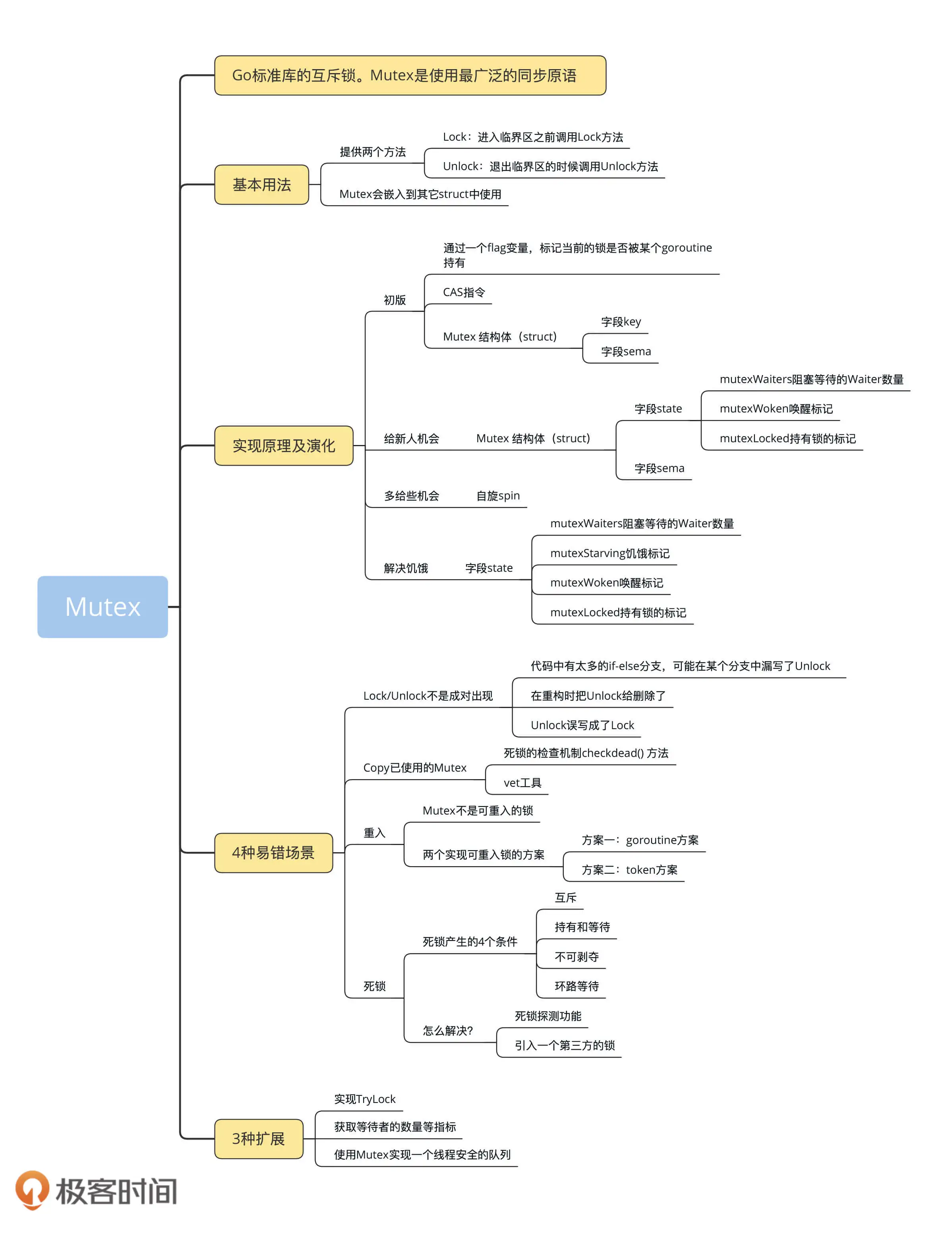
Mutex:庖丁解牛看实现
Mutex:4种易错场景大盘点
使用 Mutex 常见的错误场景有 4 类,分别是 Lock/Unlock 不是成对出现、Copy 已使用的 Mutex、重入和死锁
Lock/Unlock 不是成对出现
Copy 已使用的 Mutex
Mutex 是一个有状态的对象,它的 state 字段记录这个锁的状态。
你肯定不想运行的时候才发现这个因为复制 Mutex 导致的死锁问题,那么你怎么能够及时发现问题呢?可以使用 vet 工具,把检查写在 Makefile 文件中,在持续集成的时候跑一跑,这样可以及时发现问题,及时修复。我们可以使用 go vet 检查这个 Go 文件:
重入
当一个线程获取锁时,如果没有其它线程拥有这个锁,那么,这个线程就成功获取到这个锁。之后,如果其它线程再请求这个锁,就会处于阻塞等待的状态。但是,如果拥有这把锁的线程再请求这把锁的话,不会阻塞,而是成功返回,所以叫可重入锁(有时候也叫做递归锁)。只要你拥有这把锁,你可以可着劲儿地调用,比如通过递归实现一些算法,调用者不会阻塞或者死锁。
Mutex 不是可重入的锁
误用 Mutex 的重入例子: ```go func foo(l sync.Locker) { fmt.Println(“in foo”) l.Lock() bar(l) l.Unlock() }
func bar(l sync.Locker) { l.Lock() fmt.Println(“in bar”) l.Unlock() }
func main() { l := &sync.Mutex{} foo(l) }
<br />程序一直在请求锁,但是一直没有办法获取到锁,结果就是 Go 运行时发现死锁了,没有其它地方能够释放锁让程序运行下去,你通过下面的错误堆栈信息就能定位到哪一行阻塞请求锁:
<br />
<br />虽然标准库 Mutex 不是可重入锁,但是如果我就是想要实现一个可重入锁
-
方案一:通过 hacker 的方式获取到 goroutine id,记录下获取锁的 goroutine id,它可以实现 Locker 接口。
- 简单方式,就是通过 runtime.Stack 方法获取栈帧信息,栈帧信息里包含 goroutine id。你可以看看上面 panic 时候的贴图,goroutine id 明明白白地显示在那里。runtime.Stack 方法可以获取当前的 goroutine 信息,第二个参数为 true 会输出所有的 goroutine 信息,
```go
func GoID() int {
var buf [64]byte
n := runtime.Stack(buf[:], false)
// 得到id字符串
idField := strings.Fields(strings.TrimPrefix(string(buf[:n]), "goroutine "))[0]
id, err := strconv.Atoi(idField)
if err != nil {
panic(fmt.Sprintf("cannot get goroutine id: %v", err))
}
return id
}
- hacker方式
// RecursiveMutex 包装一个Mutex,实现可重入
type RecursiveMutex struct {
sync.Mutex
owner int64 // 当前持有锁的goroutine id
recursion int32 // 这个goroutine 重入的次数
}
func (m *RecursiveMutex) Lock() {
gid := goid.Get()
// 如果当前持有锁的goroutine就是这次调用的goroutine,说明是重入
if atomic.LoadInt64(&m.owner) == gid {
m.recursion++
return
}
m.Mutex.Lock()
// 获得锁的goroutine第一次调用,记录下它的goroutine id,调用次数加1
atomic.StoreInt64(&m.owner, gid)
m.recursion = 1
}
func (m *RecursiveMutex) Unlock() {
gid := goid.Get()
// 非持有锁的goroutine尝试释放锁,错误的使用
if atomic.LoadInt64(&m.owner) != gid {
panic(fmt.Sprintf("wrong the owner(%d): %d!", m.owner, gid))
}
// 调用次数减1
m.recursion--
if m.recursion != 0 { // 如果这个goroutine还没有完全释放,则直接返回
return
}
// 此goroutine最后一次调用,需要释放锁
atomic.StoreInt64(&m.owner, -1)
m.Mutex.Unlock()
}
- 方案二:调用 Lock/Unlock 方法时,由 goroutine 提供一个 token,用来标识它自己,而不是我们通过 hacker 的方式获取到 goroutine id,但是,这样一来,就不满足 Locker 接口了。
// Token方式的递归锁
type TokenRecursiveMutex struct {
sync.Mutex
token int64
recursion int32
}
// 请求锁,需要传入token
func (m *TokenRecursiveMutex) Lock(token int64) {
if atomic.LoadInt64(&m.token) == token { //如果传入的token和持有锁的token一致,说明是递归调用
m.recursion++
return
}
m.Mutex.Lock() // 传入的token不一致,说明不是递归调用
// 抢到锁之后记录这个token
atomic.StoreInt64(&m.token, token)
m.recursion = 1
}
// 释放锁
func (m *TokenRecursiveMutex) Unlock(token int64) {
if atomic.LoadInt64(&m.token) != token { // 释放其它token持有的锁
panic(fmt.Sprintf("wrong the owner(%d): %d!", m.token, token))
}
m.recursion-- // 当前持有这个锁的token释放锁
if m.recursion != 0 { // 还没有回退到最初的递归调用
return
}
atomic.StoreInt64(&m.token, 0) // 没有递归调用了,释放锁
m.Mutex.Unlock()
}
死锁
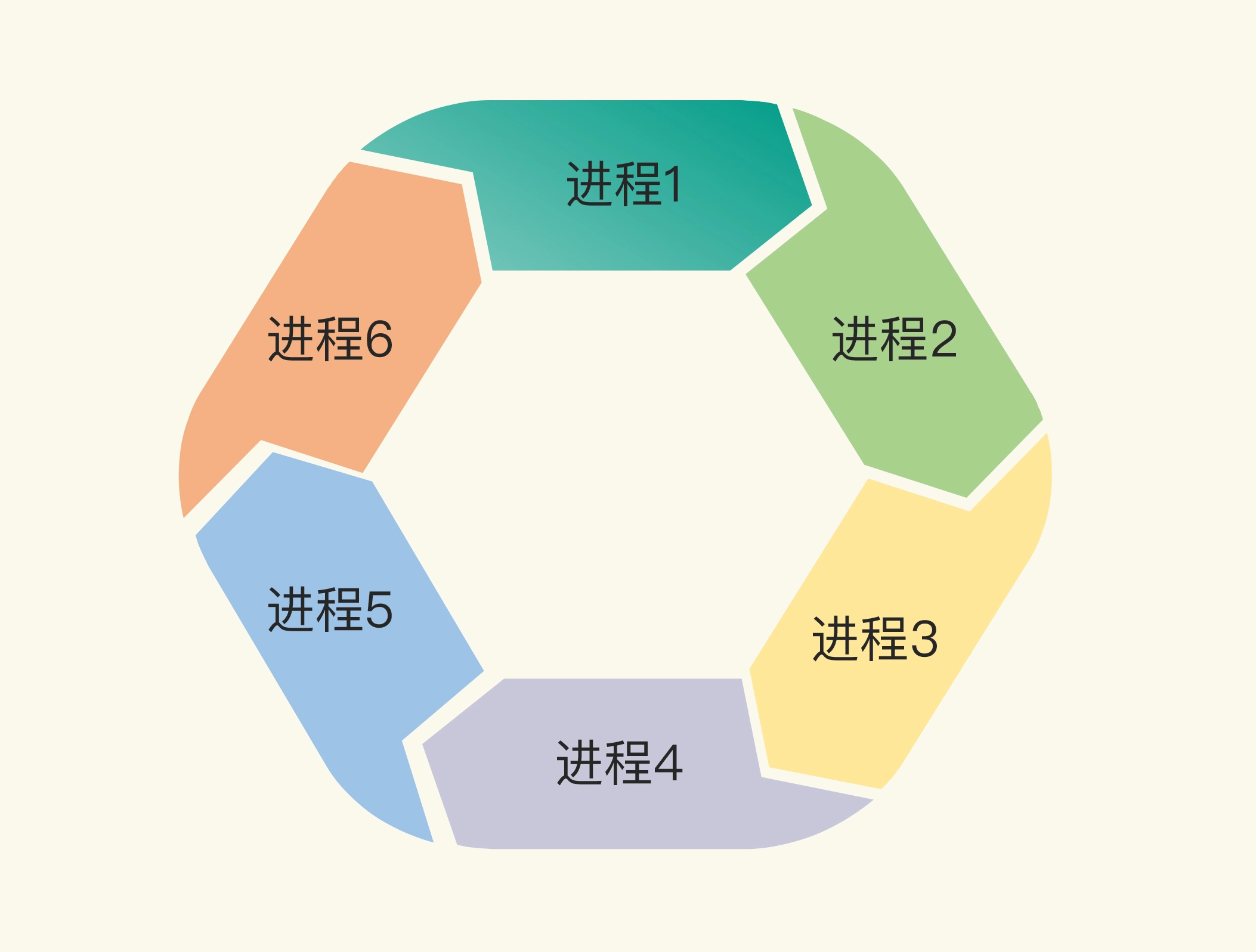
两个或两个以上的进程(或线程,goroutine)在执行过程中,因争夺共享资源而处于一种互相等待的状态,如果没有外部干涉,它们都将无法推进下去,此时,我们称系统处于死锁状态或系统产生了死锁
我们来分析一下死锁产生的必要条件。如果你想避免死锁,只要破坏这四个条件中的一个或者几个,就可以了。互斥: 至少一个资源是被排他性独享的,其他线程必须处于等待状态,直到资源被释放。
持有和等:goroutine 持有一个资源,并且还在请求其它 goroutine 持有的资源,也就是咱们常说的“吃着碗里,看着锅里”的意思。
不可剥夺:资源只能由持有它的 goroutine 来释放。
环路等待:一般来说,存在一组等待进程,P={P1,P2,…,PN},P1 等待 P2 持有的资源,P2 等待 P3 持有的资源,依此类推,最后是 PN 等待 P1 持有的资源,这就形成了一个环路等待的死结。
package main
import (
"fmt"
"sync"
"time"
)
func main() {
// 派出所证明
var psCertificate sync.Mutex
// 物业证明
var propertyCertificate sync.Mutex
var wg sync.WaitGroup
wg.Add(2) // 需要派出所和物业都处理
// 派出所处理goroutine
go func() {
defer wg.Done() // 派出所处理完成
psCertificate.Lock()
defer psCertificate.Unlock()
// 检查材料
time.Sleep(5 * time.Second)
// 请求物业的证明
propertyCertificate.Lock()
propertyCertificate.Unlock()
}()
// 物业处理goroutine
go func() {
defer wg.Done() // 物业处理完成
propertyCertificate.Lock()
defer propertyCertificate.Unlock()
// 检查材料
time.Sleep(5 * time.Second)
// 请求派出所的证明
psCertificate.Lock()
psCertificate.Unlock()
}()
wg.Wait()
fmt.Println("成功完成")
}
 保证 Lock/Unlock 成对出现,尽可能采用 defer mutex.Unlock 的方式,把它们成对、紧凑地写在一起。
保证 Lock/Unlock 成对出现,尽可能采用 defer mutex.Unlock 的方式,把它们成对、紧凑地写在一起。
手误和重入导致的死锁,是最常见的使用 Mutex 的 Bug。
Go 死锁探测工具只能探测整个程序是否因为死锁而冻结了,不能检测出一组 goroutine 死锁导致的某一块业务冻结的情况。你还可以通过 Go 运行时自带的死锁检测工具,或者是第三方的工具(比如go-deadlock、go-tools)进行检查,这样可以尽早发现一些死锁的问题。不过,有些时候,死锁在某些特定情况下才会被触发,所以,如果你的测试或者短时间的运行没问题,不代表程序一定不会有死锁问题。
并发程序最难跟踪调试的就是很难重现,因为并发问题不是按照我们指定的顺序执行的,由于计算机调度的问题和事件触发的时机不同,死锁的 Bug 可能会在极端的情况下出现。通过搜索日志、查看日志,我们能够知道程序有异常了,比如某个流程一直没有结束。这个时候,可以通过 Go pprof 工具分析,它提供了一个 block profiler 监控阻塞的 goroutine。除此之外,我们还可以查看全部的 goroutine 的堆栈信息,通过它,你可以查看阻塞的 groutine 究竟阻塞在哪一行哪一个对象上了。
Mutex:骇客编程,如何拓展额外功能?
锁是性能下降的“罪魁祸首”之一,所以,有效地降低锁的竞争,就能够很好地提高性能。因此,监控关键互斥锁上等待的 goroutine 的数量,是我们分析锁竞争的激烈程度的一个重要指标。
实际上,不论是不希望锁的 goroutine 继续等待,还是想监控锁,我们都可以基于标准库中 Mutex 的实现,通过 Hacker 的方式,为 Mutex 增加一些额外的功能。这节课,我就来教你实现几个扩展功能,包括实现 TryLock,获取等待者的数量等指标,以及实现一个线程安全的队列。
TryLock
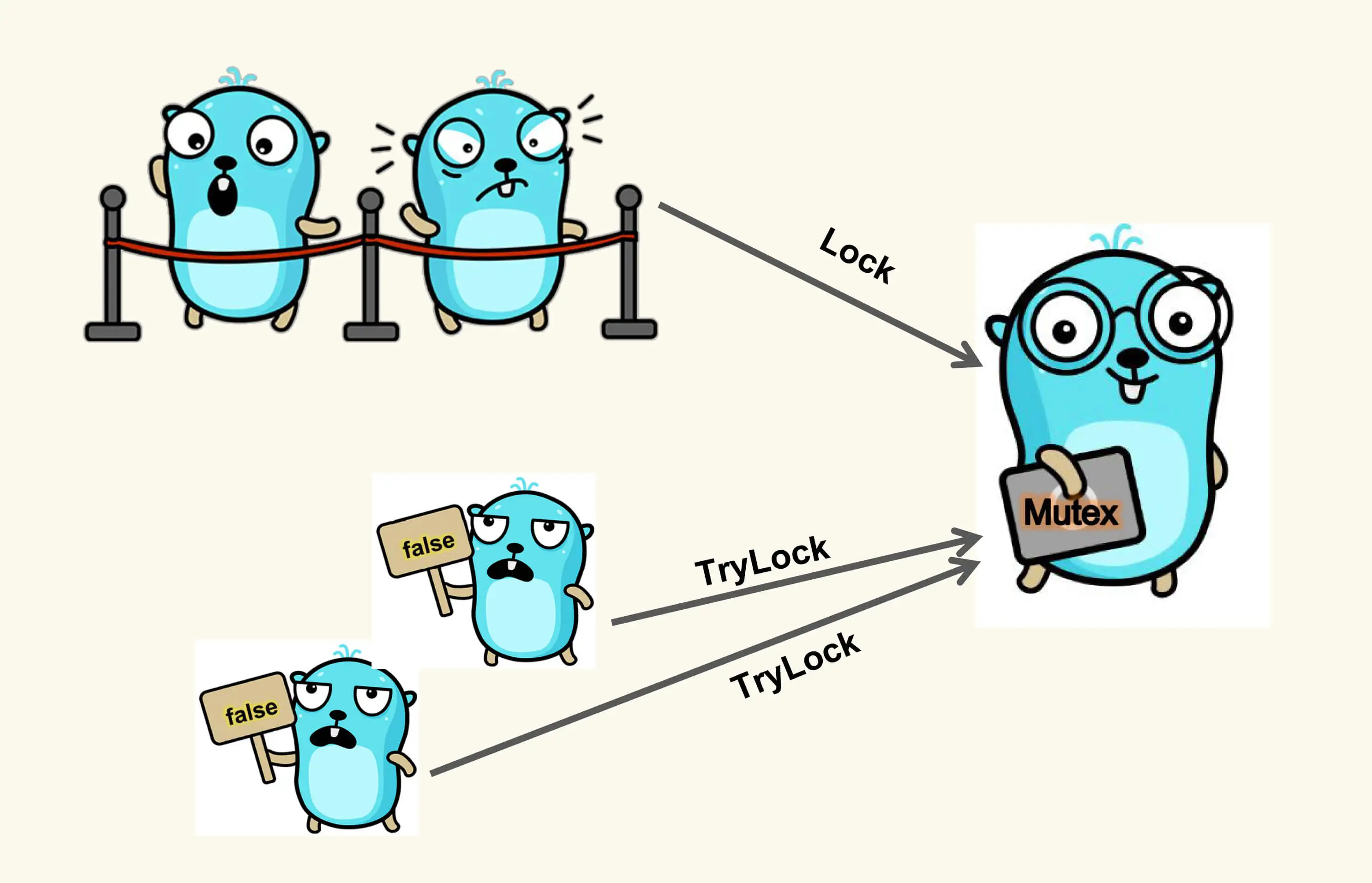
我们可以为 Mutex 添加一个 TryLock 的方法,也就是尝试获取排外锁。
这个方法具体是什么意思呢?我来解释一下这里的逻辑。当一个 goroutine 调用这个 TryLock 方法请求锁的时候,如果这把锁没有被其他 goroutine 所持有,那么,这个 goroutine 就持有了这把锁,并返回 true;如果这把锁已经被其他 goroutine 所持有,或者是正在准备交给某个被唤醒的 goroutine,那么,这个请求锁的 goroutine 就直接返回 false,不会阻塞在方法调用上。
实现一个扩展 TryLock 方法的 Mutex
// 复制Mutex定义的常量
const (
mutexLocked = 1 << iota // 加锁标识位置
mutexWoken // 唤醒标识位置
mutexStarving // 锁饥饿标识位置
mutexWaiterShift = iota // 标识waiter的起始bit位置
)
// 扩展一个Mutex结构
type Mutex struct {
sync.Mutex
}
// 尝试获取锁
func (m *Mutex) TryLock() bool {
// 如果能成功抢到锁
if atomic.CompareAndSwapInt32((*int32)(unsafe.Pointer(&m.Mutex)), 0, mutexLocked) {
return true
}
// 如果处于唤醒、加锁或者饥饿状态,这次请求就不参与竞争了,返回false
old := atomic.LoadInt32((*int32)(unsafe.Pointer(&m.Mutex)))
if old&(mutexLocked|mutexStarving|mutexWoken) != 0 {
return false
}
// 尝试在竞争的状态下请求锁
new := old | mutexLocked
return atomic.CompareAndSwapInt32((*int32)(unsafe.Pointer(&m.Mutex)), old, new)
}
写一个简单的测试程序,来测试我们的 TryLock 的机制是否工作
func try() {
var mu Mutex
go func() { // 启动一个goroutine持有一段时间的锁
mu.Lock()
time.Sleep(time.Duration(rand.Intn(2)) * time.Second)
mu.Unlock()
}()
time.Sleep(time.Second)
ok := mu.TryLock() // 尝试获取到锁
if ok { // 获取成功
fmt.Println("got the lock")
// do something
mu.Unlock()
return
}
// 没有获取到
fmt.Println("can't get the lock")
}
获取等待者的数量等指标
Mutex 结构中的 state 字段有很多个含义,通过 state 字段,你可以知道锁是否已经被某个 goroutine 持有、当前是否处于饥饿状态、是否有等待的 goroutine 被唤醒、等待者的数量等信息。但是,state 这个字段并没有暴露出来,所以,我们需要想办法获取到这个字段,并进行解析。
const (
mutexLocked = 1 << iota // mutex is locked
mutexWoken
mutexStarving
mutexWaiterShift = iota
)
type Mutex struct {
sync.Mutex
}
func (m *Mutex) Count() int {
// 获取state字段的值
v := atomic.LoadInt32((*int32)(unsafe.Pointer(&m.Mutex)))
v = v >> mutexWaiterShift //得到等待者的数值
v = v + (v & mutexLocked) //再加上锁持有者的数量,0或者1
return int(v)
}
state 这个字段的第一位是用来标记锁是否被持有,第二位用来标记是否已经唤醒了一个等待者,第三位标记锁是否处于饥饿状态,通过分析这个 state 字段我们就可以得到这些状态信息。
// 锁是否被持有
func (m *Mutex) IsLocked() bool {
state := atomic.LoadInt32((*int32)(unsafe.Pointer(&m.Mutex)))
return state&mutexLocked == mutexLocked
}
// 是否有等待者被唤醒
func (m *Mutex) IsWoken() bool {
state := atomic.LoadInt32((*int32)(unsafe.Pointer(&m.Mutex)))
return state&mutexWoken == mutexWoken
}
// 锁是否处于饥饿状态
func (m *Mutex) IsStarving() bool {
state := atomic.LoadInt32((*int32)(unsafe.Pointer(&m.Mutex)))
return state&mutexStarving == mutexStarving
}
我们可以写一个程序测试一下,比如,在 1000 个 goroutine 并发访问的情况下,我们可以把锁的状态信息输出出来:
func count() {
var mu Mutex
for i := 0; i < 1000; i++ { // 启动1000个goroutine
go func() {
mu.Lock()
time.Sleep(time.Second)
mu.Unlock()
}()
}
time.Sleep(time.Second)
// 输出锁的信息
fmt.Printf("waitings: %d, isLocked: %t, woken: %t, starving: %t\n", mu.Count(), mu.IsLocked(), mu.IsWoken(), mu.IsStarving())
}
有一点你需要注意一下,在获取 state 字段的时候,并没有通过 Lock 获取这把锁,所以获取的这个 state 的值是一个瞬态的值,可能在你解析出这个字段之后,锁的状态已经发生了变化。不过没关系,因为你查看的就是调用的那一时刻的锁的状态。
使用 Mutex 实现一个线程安全的队列
为什么要讨论这个话题呢?因为 Mutex 经常会和其他非线程安全(对于 Go 来说,我们其实指的是 goroutine 安全)的数据结构一起,组合成一个线程安全的数据结构。新数据结构的业务逻辑由原来的数据结构提供,而 Mutex 提供了锁的机制,来保证线程安全。
比如队列,我们可以通过 Slice 来实现,但是通过 Slice 实现的队列不是线程安全的,出队(Dequeue)和入队(Enqueue)会有 data race 的问题。这个时候,Mutex 就要隆重出场了,通过它,我们可以在出队和入队的时候加上锁的保护。
type SliceQueue struct {
data []interface{}
mu sync.Mutex
}
func NewSliceQueue(n int) (q *SliceQueue) {
return &SliceQueue{data: make([]interface{}, 0, n)}
}
// Enqueue 把值放在队尾
func (q *SliceQueue) Enqueue(v interface{}) {
q.mu.Lock()
q.data = append(q.data, v)
q.mu.Unlock()
}
// Dequeue 移去队头并返回
func (q *SliceQueue) Dequeue() interface{} {
q.mu.Lock()
if len(q.data) == 0 {
q.mu.Unlock()
return nil
}
v := q.data[0]
q.data = q.data[1:]
q.mu.Unlock()
return v
}
因为标准库中没有线程安全的队列数据结构的实现,所以,你可以通过 Mutex 实现一个简单的队列。通过 Mutex 我们就可以为一个非线程安全的 data interface{}实现线程安全的访问。
Mutex 知识图
RWMutex:读写锁的实现原理及避坑指南
如果某个读操作的 goroutine 持有了锁,在这种情况下,其它读操作的 goroutine 就不必一直傻傻地等待了,而是可以并发地访问共享变量,这样我们就可以将串行的读变成并行读,提高读操作的性能。当写操作的 goroutine 持有锁的时候,它就是一个排外锁,其它的写操作和读操作的 goroutine,需要阻塞等待持有这个锁的 goroutine 释放锁。
这一类并发读写问题叫作readers-writers 问题,意思就是,同时可能有多个读或者多个写,但是只要有一个线程在执行写操作,其它的线程都不能执行读写操作。
Go 标准库中的 RWMutex(读写锁)就是用来解决这类 readers-writers 问题的
什么是 RWMutex?
标准库中的 RWMutex 是一个 reader/writer 互斥锁。RWMutex 在某一时刻只能由任意数量的 reader 持有,或者是只被单个的 writer 持有。
- Lock/Unlock:写操作时调用的方法。如果锁已经被 reader 或者 writer 持有,那么,Lock 方法会一直阻塞,直到能获取到锁;Unlock 则是配对的释放锁的方法。
- RLock/RUnlock:读操作时调用的方法。如果锁已经被 writer 持有的话,RLock 方法会一直阻塞,直到能获取到锁,否则就直接返回;而 RUnlock 是 reader 释放锁的方法。
- RLocker:这个方法的作用是为读操作返回一个 Locker 接口的对象。它的 Lock 方法会调用 RWMutex 的 RLock 方法,它的 Unlock 方法会调用 RWMutex 的 RUnlock 方法。
RWMutex 的零值是未加锁的状态,所以,当你使用 RWMutex 的时候,无论是声明变量,还是嵌入到其它 struct 中,都不必显式地初始化。
我以计数器为例,来说明一下,如何使用 RWMutex 保护共享资源。计数器的 count++操作是写操作,而获取 count 的值是读操作,这个场景非常适合读写锁,因为读操作可以并行执行,写操作时只允许一个线程执行,这正是 readers-writers 问题。
func main() {
var counter Counter
for i := 0; i < 10; i++ { // 10个reader
go func() {
for {
counter.Count() // 计数器读操作
time.Sleep(time.Millisecond)
}
}()
}
for { // 一个writer
counter.Incr() // 计数器写操作
time.Sleep(time.Second)
}
}
// 一个线程安全的计数器
type Counter struct {
mu sync.RWMutex
count uint64
}
// 使用写锁保护
func (c *Counter) Incr() {
c.mu.Lock()
c.count++
c.mu.Unlock()
}
// 使用读锁保护
func (c *Counter) Count() uint64 {
c.mu.RLock()
defer c.mu.RUnlock()
return c.count
}
如果你遇到可以明确区分 reader 和 writer goroutine 的场景,且有大量的并发读、少量的并发写,并且有强烈的性能需求,你就可以考虑使用读写锁 RWMutex 替换 Mutex。
RWMutex 的实现原理
RWMutex 是很常见的并发原语,很多编程语言的库都提供了类似的并发类型。RWMutex 一般都是基于互斥锁、条件变量(condition variables)或者信号量(semaphores)等并发原语来实现。Go 标准库中的 RWMutex 是基于 Mutex 实现的。
readers-writers 问题一般有三类,基于对读和写操作的优先级,读写锁的设计和实现也分成三类。
- Read-preferring:读优先的设计可以提供很高的并发性,但是,在竞争激烈的情况下可能会导致写饥饿。这是因为,如果有大量的读,这种设计会导致只有所有的读都释放了锁之后,写才可能获取到锁。
- Write-preferring:写优先的设计意味着,如果已经有一个 writer 在等待请求锁的话,它会阻止新来的请求锁的 reader 获取到锁,所以优先保障 writer。当然,如果有一些 reader 已经请求了锁的话,新请求的 writer 也会等待已经存在的 reader 都释放锁之后才能获取。所以,写优先级设计中的优先权是针对新来的请求而言的。这种设计主要避免了 writer 的饥饿问题。
- 不指定优先级:这种设计比较简单,不区分 reader 和 writer 优先级,某些场景下这种不指定优先级的设计反而更有效,因为第一类优先级会导致写饥饿,第二类优先级可能会导致读饥饿,这种不指定优先级的访问不再区分读写,大家都是同一个优先级,解决了饥饿的问题
Go 标准库中的 RWMutex 设计是 Write-preferring 方案。一个正在阻塞的 Lock 调用会排除新的 reader 请求到锁。
RWMutex 包含一个 Mutex,以及四个辅助字段 writerSem、readerSem、readerCount 和 readerWait:
type RWMutex struct {
w Mutex // 互斥锁解决多个writer的竞争
writerSem uint32 // writer信号量
readerSem uint32 // reader信号量
readerCount int32 // reader的数量
readerWait int32 // writer等待完成的reader的数量
}
const rwmutexMaxReaders = 1 << 30
- 字段 w:为 writer 的竞争锁而设计;
- 字段 readerCount:记录当前 reader 的数量(以及是否有 writer 竞争锁);
- readerWait:记录 writer 请求锁时需要等待 read 完成的 reader 的数量;
- writerSem 和 readerSem:都是为了阻塞设计的信号量。
RLock/RUnlock 的实现
func (rw *RWMutex) RLock() {
if atomic.AddInt32(&rw.readerCount, 1) < 0 {
// rw.readerCount是负值的时候,意味着此时有writer等待请求锁,因为writer优先级高,所以把后来的reader阻塞休眠
runtime_SemacquireMutex(&rw.readerSem, false, 0)
}
}
func (rw *RWMutex) RUnlock() {
if r := atomic.AddInt32(&rw.readerCount, -1); r < 0 {
rw.rUnlockSlow(r) // 有等待的writer
}
}
func (rw *RWMutex) rUnlockSlow(r int32) {
if atomic.AddInt32(&rw.readerWait, -1) == 0 {
// 最后一个reader了,writer终于有机会获得锁了
runtime_Semrelease(&rw.writerSem, false, 1)
}
}
调用 RUnlock 的时候,我们需要将 Reader 的计数减去 1(第 8 行),因为 reader 的数量减少了一个。但是,第 8 行的 AddInt32 的返回值还有另外一个含义。如果它是负值,就表示当前有 writer 竞争锁,在这种情况下,还会调用 rUnlockSlow 方法,检查是不是 reader 都释放读锁了,如果读锁都释放了,那么可以唤醒请求写锁的 writer 了。
当一个或者多个 reader 持有锁的时候,竞争锁的 writer 会等待这些 reader 释放完,才可能持有这把锁。打个比方,在房地产行业中有条规矩叫做“买卖不破租赁”,意思是说,就算房东把房子卖了,新业主也不能把当前的租户赶走,而是要等到租约结束后,才能接管房子。这和 RWMutex 的设计是一样的。当 writer 请求锁的时候,是无法改变既有的 reader 持有锁的现实的,也不会强制这些 reader 释放锁,它的优先权只是限定后来的 reader 不要和它抢。
所以,rUnlockSlow 将持有锁的 reader 计数减少 1 的时候,会检查既有的 reader 是不是都已经释放了锁,如果都释放了锁,就会唤醒 writer,让 writer 持有锁。
Lock
RWMutex 是一个多 writer 多 reader 的读写锁,所以同时可能有多个 writer 和 reader。那么,为了避免 writer 之间的竞争,RWMutex 就会使用一个 Mutex 来保证 writer 的互斥。
func (rw *RWMutex) Lock() {
// 首先解决其他writer竞争问题
rw.w.Lock()
// 反转readerCount,告诉reader有writer竞争锁
r := atomic.AddInt32(&rw.readerCount, -rwmutexMaxReaders) + rwmutexMaxReaders
// 如果当前有reader持有锁,那么需要等待
if r != 0 && atomic.AddInt32(&rw.readerWait, r) != 0 {
runtime_SemacquireMutex(&rw.writerSem, false, 0)
}
}
Unlock
当一个 writer 释放锁的时候,它会再次反转 readerCount 字段。可以肯定的是,因为当前锁由 writer 持有,所以,readerCount 字段是反转过的,并且减去了 rwmutexMaxReaders 这个常数,变成了负数。所以,这里的反转方法就是给它增加 rwmutexMaxReaders 这个常数值。
既然 writer 要释放锁了,那么就需要唤醒之后新来的 reader,不必再阻塞它们了,让它们开开心心地继续执行就好了。
在 RWMutex 的 Unlock 返回之前,需要把内部的互斥锁释放。释放完毕后,其他的 writer 才可以继续竞争这把锁。
func (rw *RWMutex) Unlock() {
// 告诉reader没有活跃的writer了
r := atomic.AddInt32(&rw.readerCount, rwmutexMaxReaders)
// 唤醒阻塞的reader们
for i := 0; i < int(r); i++ {
runtime_Semrelease(&rw.readerSem, false, 0)
}
// 释放内部的互斥锁
rw.w.Unlock()
}
RWMutex 的 3 个踩坑点
坑点 1:不可复制
坑点 2:重入导致死锁
坑点 3:释放未加锁的 RWMutex
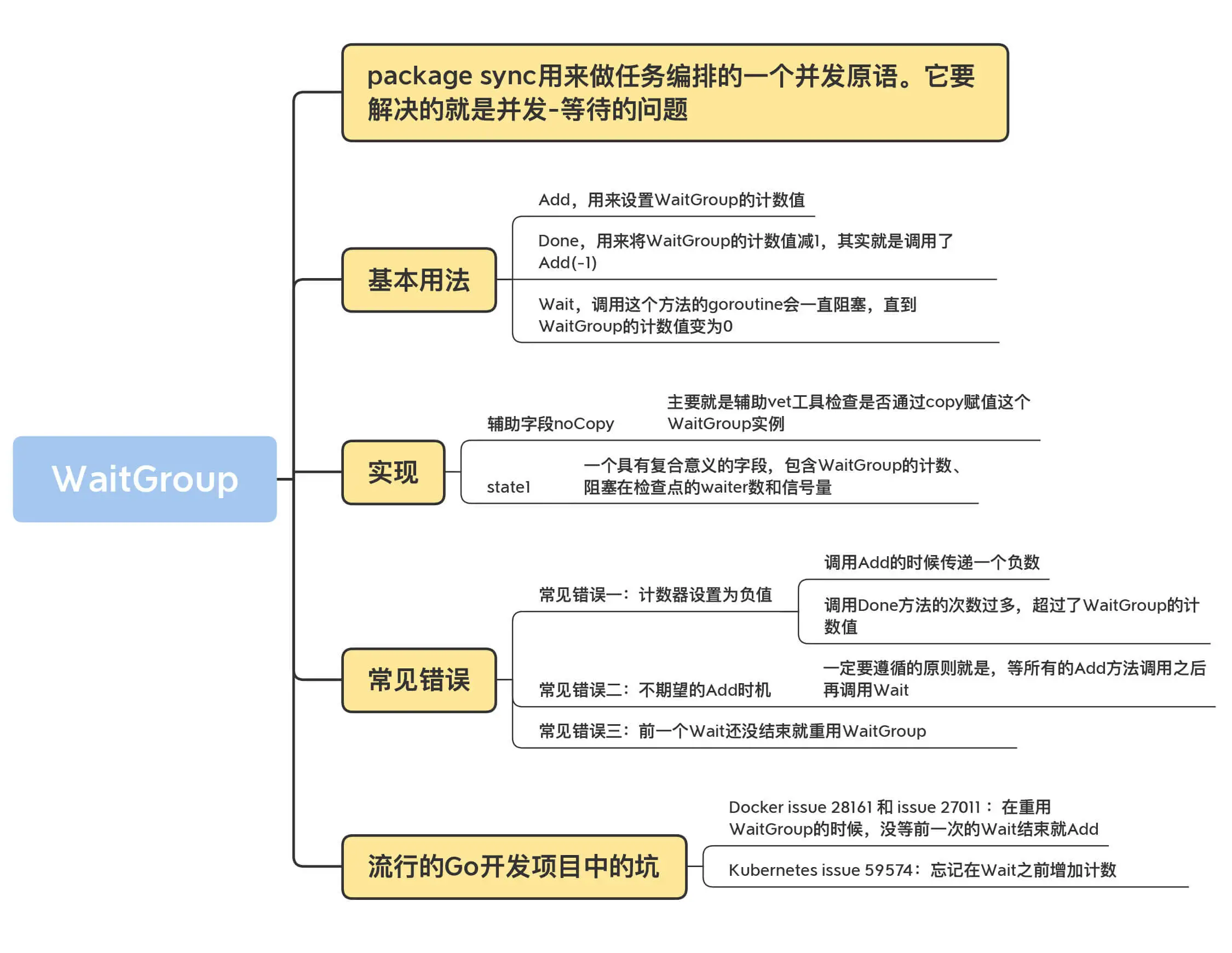
WaitGroup:协同等待,任务编排利器
WaitGroup,我们以前都多多少少学习过,或者是使用过。其实,WaitGroup 很简单,就是 package sync 用来做任务编排的一个并发原语。它要解决的就是并发 - 等待的问题:现在有一个 goroutine A 在检查点(checkpoint)等待一组 goroutine 全部完成,如果在执行任务的这些 goroutine 还没全部完成,那么 goroutine A 就会阻塞在检查点,直到所有 goroutine 都完成后才能继续执行。
WaitGroup 的基本用法
- Add,用来设置 WaitGroup 的计数值;
- Done,用来将 WaitGroup 的计数值减 1,其实就是调用了 Add(-1);
- Wait,调用这个方法的 goroutine 会一直阻塞,直到 WaitGroup 的计数值变为 0。
在这个例子中,我们使用了以前实现的计数器 struct。我们启动了 10 个 worker,分别对计数值加一,10 个 worker 都完成后,我们期望输出计数器的值。
// 线程安全的计数器
type Counter struct {
mu sync.Mutex
count uint64
}
// 对计数值加一
func (c *Counter) Incr() {
c.mu.Lock()
c.count++
c.mu.Unlock()
}
// 获取当前的计数值
func (c *Counter) Count() uint64 {
c.mu.Lock()
defer c.mu.Unlock()
return c.count
}
// sleep 1秒,然后计数值加1
func worker(c *Counter, wg *sync.WaitGroup) {
defer wg.Done()
time.Sleep(time.Second)
c.Incr()
}
func main() {
var counter Counter
var wg sync.WaitGroup
wg.Add(10) // WaitGroup的值设置为10
for i := 0; i < 10; i++ { // 启动10个goroutine执行加1任务
go worker(&counter, &wg)
}
// 检查点,等待goroutine都完成任务
wg.Wait()
// 输出当前计数器的值
fmt.Println(counter.Count())
}
WaitGroup 的实现
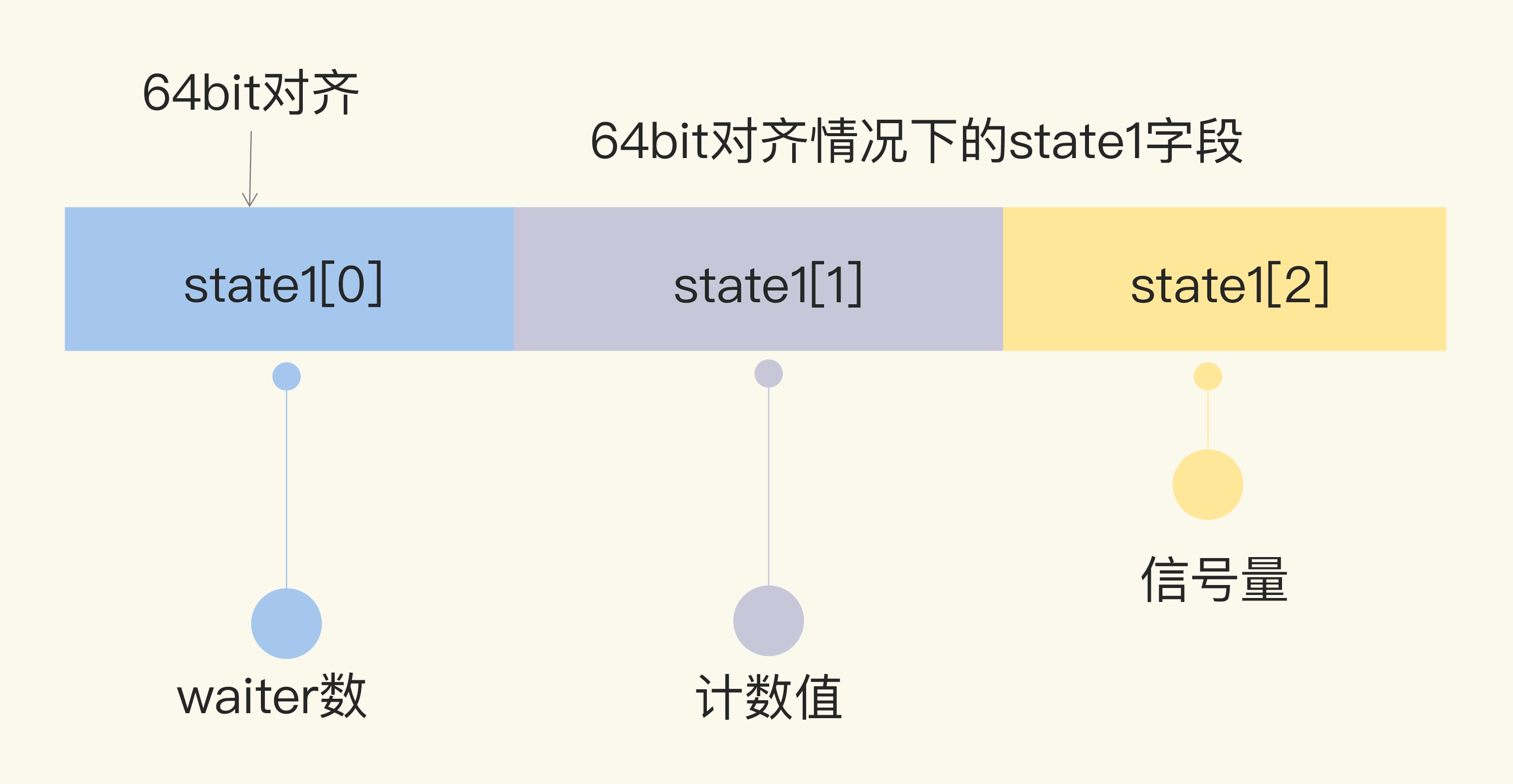
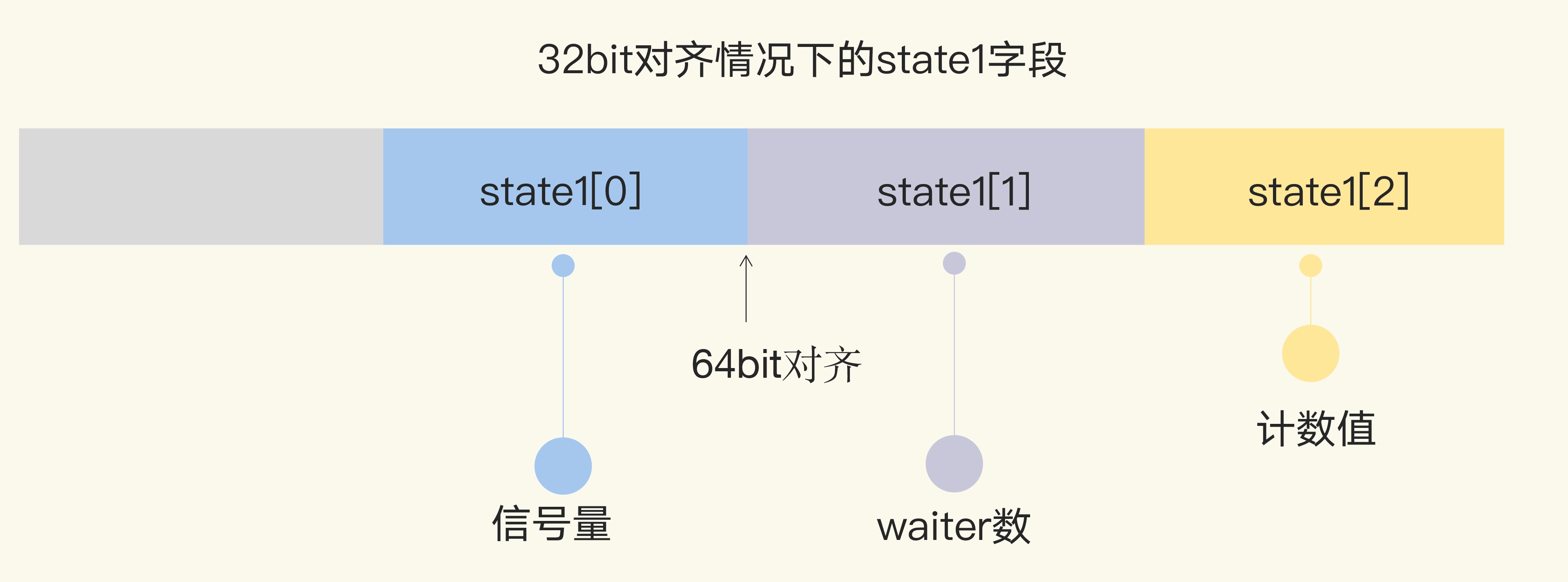
首先,我们看看 WaitGroup 的数据结构。它包括了一个 noCopy 的辅助字段,一个 state1 记录 WaitGroup 状态的数组。
- noCopy 的辅助字段,主要就是辅助 vet 工具检查是否通过 copy 赋值这个 WaitGroup 实例。我会在后面和你详细分析这个字段;
- state1,一个具有复合意义的字段,包含 WaitGroup 的计数、阻塞在检查点的 waiter 数和信号量。
type WaitGroup struct {
// 避免复制使用的一个技巧,可以告诉vet工具违反了复制使用的规则
noCopy noCopy
// 64bit(8bytes)的值分成两段,高32bit是计数值,低32bit是waiter的计数
// 另外32bit是用作信号量的
// 因为64bit值的原子操作需要64bit对齐,但是32bit编译器不支持,所以数组中的元素在不同的架构中不一样,具体处理看下面的方法
// 总之,会找到对齐的那64bit作为state,其余的32bit做信号量
state1 [3]uint32
}
// 得到state的地址和信号量的地址
func (wg *WaitGroup) state() (statep *uint64, semap *uint32) {
if uintptr(unsafe.Pointer(&wg.state1))%8 == 0 {
// 如果地址是64bit对齐的,数组前两个元素做state,后一个元素做信号量
return (*uint64)(unsafe.Pointer(&wg.state1)), &wg.state1[2]
} else {
// 如果地址是32bit对齐的,数组后两个元素用来做state,它可以用来做64bit的原子操作,第一个元素32bit用来做信号量
return (*uint64)(unsafe.Pointer(&wg.state1[1])), &wg.state1[0]
}
}
Add 方法主要操作的是 state 的计数部分。你可以为计数值增加一个 delta 值,内部通过原子操作把这个值加到计数值上。需要注意的是,这个 delta 也可以是个负数,相当于为计数值减去一个值,Done 方法内部其实就是通过 Add(-1) 实现的。
func (wg *WaitGroup) Add(delta int) {
statep, semap := wg.state()
// 高32bit是计数值v,所以把delta左移32,增加到计数上
state := atomic.AddUint64(statep, uint64(delta)<<32)
v := int32(state >> 32) // 当前计数值
w := uint32(state) // waiter count
if v > 0 || w == 0 {
return
}
// 如果计数值v为0并且waiter的数量w不为0,那么state的值就是waiter的数量
// 将waiter的数量设置为0,因为计数值v也是0,所以它们俩的组合*statep直接设置为0即可。此时需要并唤醒所有的waiter
*statep = 0
for ; w != 0; w-- {
runtime_Semrelease(semap, false, 0)
}
}
// Done方法实际就是计数器减1
func (wg *WaitGroup) Done() {
wg.Add(-1)
}
Wait 方法的实现逻辑是:不断检查 state 的值。如果其中的计数值变为了 0,那么说明所有的任务已完成,调用者不必再等待,直接返回。如果计数值大于 0,说明此时还有任务没完成,那么调用者就变成了等待者,需要加入 waiter 队列,并且阻塞住自己。
func (wg *WaitGroup) Wait() {
statep, semap := wg.state()
for {
state := atomic.LoadUint64(statep)
v := int32(state >> 32) // 当前计数值
w := uint32(state) // waiter的数量
if v == 0 {
// 如果计数值为0, 调用这个方法的goroutine不必再等待,继续执行它后面的逻辑即可
return
}
// 否则把waiter数量加1。期间可能有并发调用Wait的情况,所以最外层使用了一个for循环
if atomic.CompareAndSwapUint64(statep, state, state+1) {
// 阻塞休眠等待
runtime_Semacquire(semap)
// 被唤醒,不再阻塞,返回
return
}
}
}
使用 WaitGroup 时的常见错误
常见问题一:计数器设置为负值
- 第一种方法是:调用 Add 的时候传递一个负数。
- 第二个方法是:调用 Done 方法的次数过多,超过了 WaitGroup 的计数值。
使用 WaitGroup 的正确姿势是,预先确定好 WaitGroup 的计数值,然后调用相同次数的 Done 完成相应的任务。
常见问题二:不期望的 Add 时机
在使用 WaitGroup 的时候,你一定要遵循的原则就是,等所有的 Add 方法调用之后再调用 Wait,否则就可能导致 panic 或者不期望的结果。
常见问题三:前一个 Wait 还没结束就重用 WaitGroup
WaitGroup 等一组比赛的所有选手都跑完后 5 分钟,才开始下一组比赛。下一组比赛还可以使用这个 WaitGroup 来控制,因为 WaitGroup 是可以重用的
noCopy:辅助 vet 检查
如何避免错误使用 WaitGroup 的情况,我们只需要尽量保证下面 5 点就可以了:
- 不重用 WaitGroup。新建一个 WaitGroup 不会带来多大的资源开销,重用反而更容易出错。
- 保证所有的 Add 方法调用都在 Wait 之前。
- 不传递负数给 Add 方法,只通过 Done 来给计数值减 1。
- 不做多余的 Done 方法调用,保证 Add 的计数值和 Done 方法调用的数量是一样的。
- 不遗漏 Done 方法的调用,否则会导致 Wait hang 住无法返回。
WaitGroup 的知识图
Cond:条件变量的实现机制及避坑指南
在 Go 中,也可以实现一个类似的限定容量的队列,而且实现起来也比较简单,只要用条件变量(Cond)并发原语就可以。Cond 并发原语相对来说不是那么常用,但是在特定的场景使用会事半功倍,比如你需要在唤醒一个或者所有的等待者做一些检查操作的时候。
Go 标准库的 Cond
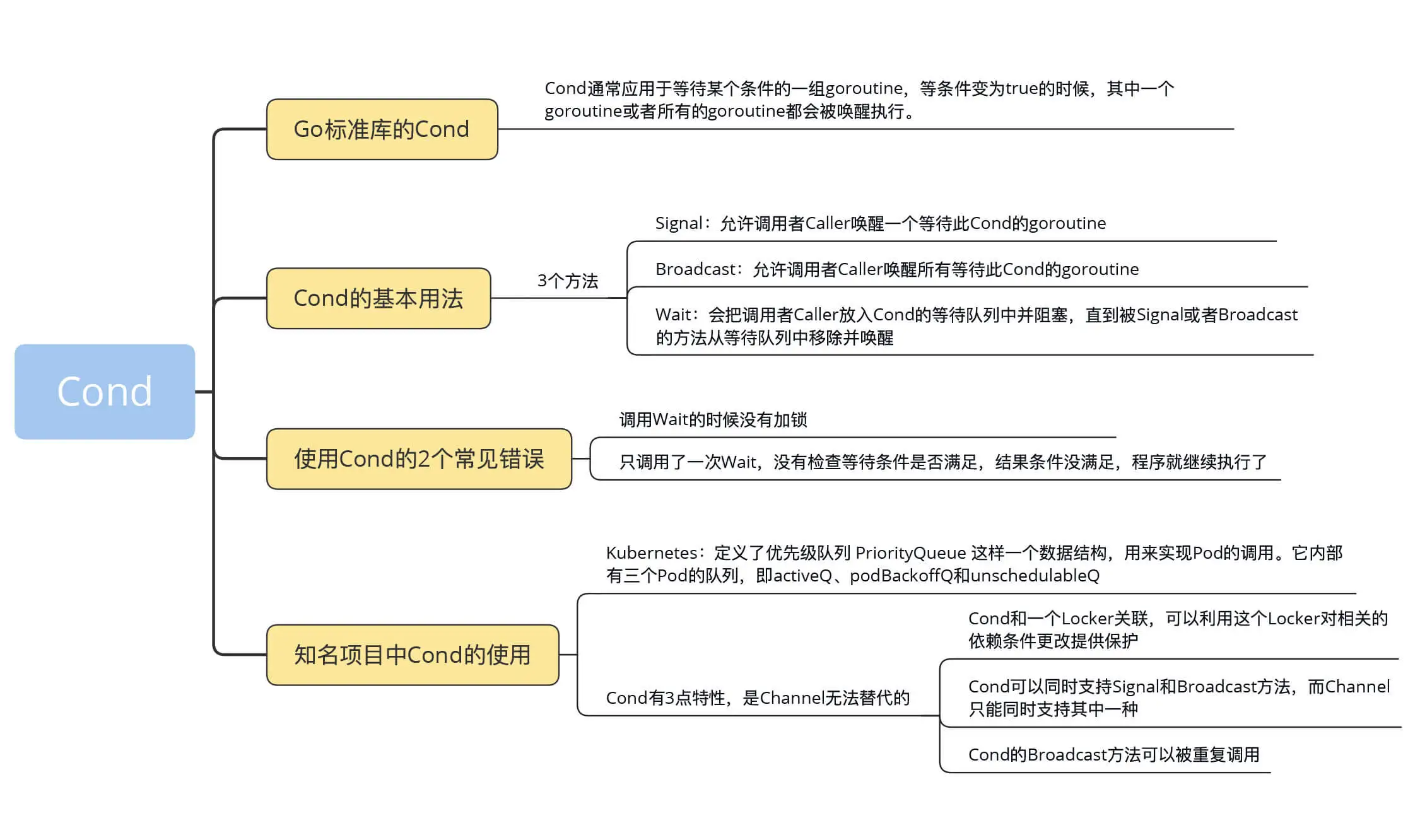
Go 标准库提供 Cond 原语的目的是,为等待 / 通知场景下的并发问题提供支持。Cond 通常应用于等待某个条件的一组 goroutine,等条件变为 true 的时候,其中一个 goroutine 或者所有的 goroutine 都会被唤醒执行。
从开发实践上,我们真正使用 Cond 的场景比较少,因为一旦遇到需要使用 Cond 的场景,我们更多地会使用 Channel 的方式(我会在第 12 和第 13 讲展开 Channel 的用法)去实现
Cond 的基本用法
Signal 方法 ,允许调用者 Caller 唤醒一个等待此 Cond 的 goroutine。如果此时没有等待的 goroutine,显然无需通知 waiter;如果 Cond 等待队列中有一个或者多个等待的 goroutine,则需要从等待队列中移除第一个 goroutine 并把它唤醒。在其他编程语言中,比如 Java 语言中,Signal 方法也被叫做 notify 方法。
调用 Signal 方法时,不强求你一定要持有 c.L 的锁。
Broadcast 方法 ,允许调用者 Caller 唤醒所有等待此 Cond 的 goroutine。如果此时没有等待的 goroutine,显然无需通知 waiter;如果 Cond 等待队列中有一个或者多个等待的 goroutine,则清空所有等待的 goroutine,并全部唤醒。在其他编程语言中,比如 Java 语言中,Broadcast 方法也被叫做 notifyAll 方法。
同样地,调用 Broadcast 方法时,也不强求你一定持有 c.L 的锁。
Wait 方法 ,会把调用者 Caller 放入 Cond 的等待队列中并阻塞,直到被 Signal 或者 Broadcast 的方法从等待队列中移除并唤醒。
调用 Wait 方法时必须要持有 c.L 的锁。
知道了 Cond 提供的三个方法后,我们再通过一个百米赛跑开始时的例子,来学习下 Cond 的使用方法。 10 个运动员进入赛场之后需要先做拉伸活动活动筋骨,向观众和粉丝招手致敬,在自己的赛道上做好准备;等所有的运动员都准备好之后,裁判员才会打响发令枪。
func main() {
c := sync.NewCond(&sync.Mutex{})
var ready int
for i := 0; i < 10; i++ {
go func(i int) {
time.Sleep(time.Duration(rand.Int63n(10)) * time.Second)
// 加锁更改等待条件
c.L.Lock()
ready++
c.L.Unlock()
log.Printf("运动员#%d 已准备就绪\n", i)
// 关闭唤醒所有的等待者
c.Broadcast()
}(i)
}
c.L.Lock()
for ready != 10 {
c.Wait()
log.Println("裁判员被唤醒一次")
}
c.L.Unlock()
//所有的运动员是否就绪
log.Println("所有运动员都准备就绪。比赛开始,3,2,1, ......")
}
Cond 的使用其实没那么简单。它的复杂在于:
- 一,这段代码有时候需要加锁,有时候可以不加;
- 二,Wait 唤醒后需要检查条件;
- 三,条件变量的更改,其实是需要原子操作或者互斥锁保护的。所以,有的开发者会认为,Cond 是唯一难以掌握的 Go 并发原语。
Cond 的实现原理
type Cond struct {
noCopy noCopy
// 当观察或者修改等待条件的时候需要加锁
L Locker
// 等待队列
notify notifyList
checker copyChecker
}
func NewCond(l Locker) *Cond {
return &Cond{L: l}
}
func (c *Cond) Wait() {
c.checker.check()
// 增加到等待队列中
t := runtime_notifyListAdd(&c.notify)
c.L.Unlock()
// 阻塞休眠直到被唤醒
runtime_notifyListWait(&c.notify, t)
c.L.Lock()
}
func (c *Cond) Signal() {
c.checker.check()
runtime_notifyListNotifyOne(&c.notify)
}
func (c *Cond) Broadcast() {
c.checker.check()
runtime_notifyListNotifyAll(&c.notify)
}
使用 Cond 的 2 个常见错误
我们先看 Cond 最常见的使用错误,也就是调用 Wait 的时候没有加锁 。
使用 Cond 的另一个常见错误是,只调用了一次 Wait,没有检查等待条件是否满足,结果条件没满足,程序就继续执行了。出现这个问题的原因在于,误以为 Cond 的使用,就像 WaitGroup 那样调用一下 Wait 方法等待那么简单。
我们一定要记住 ,waiter goroutine 被唤醒不得 于等待条件被满足,只是有 goroutine 把它唤醒了而已,等待条件有可能已经满足了,也有可能不满足,我们需要进一步检查。你也可以理解为,等待者被唤醒,只是得到了一次检查的机会而已。
如果你想在使用 Cond 的时候避免犯错,只要时刻记住调用 cond.Wait 方法之前一定要加锁,以及 waiter goroutine 被唤醒不得于等待条件被满足这两个知识点。
我在这一讲开头提到,Cond 的使用场景很少。先前的标准库内部有几个地方使用了 Cond,比如 io/pipe.go 等,后来都被其他的并发原语(比如 Channel)替换了,sync.Cond 的路越走越窄。但是,还是有一批忠实的“粉丝”坚持在使用 Cond,原因在于 Cond 有三点特性是 Channel 无法替代的:
- Cond 和一个 Locker 关联,可以利用这个 Locker 对相关的依赖条件更改提供保护。
- Cond 可以同时支持 Signal 和 Broadcast 方法,而 Channel 只能同时支持其中一种。
- Cond 的 Broadcast 方法可以被重复调用。等待条件再次变成不满足的状态后,我们又可以调用 Broadcast 再次唤醒等待的 goroutine。这也是 Channel 不能支持的,Channel 被 close 掉了之后不支持再 open。
总结
Cond 是为等待 / 通知场景下的并发问题提供支持的。它提供了条件变量的三个基本方法 Signal、Broadcast 和 Wait,为并发的 goroutine 提供等待 / 通知机制。
在实践中,处理等待 / 通知的场景时,我们常常会使用 Channel 替换 Cond,因为 Channel 类型使用起来更简洁,而且不容易出错。但是对于需要重复调用 Broadcast 的场景,比如上面 Kubernetes 的例子,每次往队列中成功增加了元素后就需要调用 Broadcast 通知所有的等待者,使用 Cond 就再合适不过了。
使用 Cond 之所以容易出错,就是 Wait 调用需要加锁,以及被唤醒后一定要检查条件是否真的已经满足。你需要牢记这两点。
原子操作
Channel
扩展并发原语
分布式并发原语

若有收获,就点个赞吧
0 人点赞
