1.es介绍及作用?
elasticsearch是一款非常强大的开源搜索引擎,具备非常多强大功能,可以帮助我们从海量数据中快速找到需要的内容.
2.es和lucene的关系?
- elasticsearch底层是基于lucene来实现的。
Lucene是一个Java语言的搜索引擎类库,是Apache公司的顶级项目,
3.倒排索引介绍?
创建倒排索引是对正向索引的一种特殊处理,流程如下:
将每一个文档的数据利用算法分词,得到一个个词条
- 创建表,每行数据包括词条、词条所在文档id、位置等信息
- 因为词条唯一性,可以给词条创建索引,例如hash表结构索引
倒排索引的搜索流程如下(以搜索”华为手机”为例):
1)用户输入条件”华为手机”进行搜索。
2)对用户输入内容分词,得到词条:华为、手机。
3)拿着词条在倒排索引中查找,可以得到包含词条的文档id:1、2、3。
4)拿着文档id到正向索引中查找具体文档。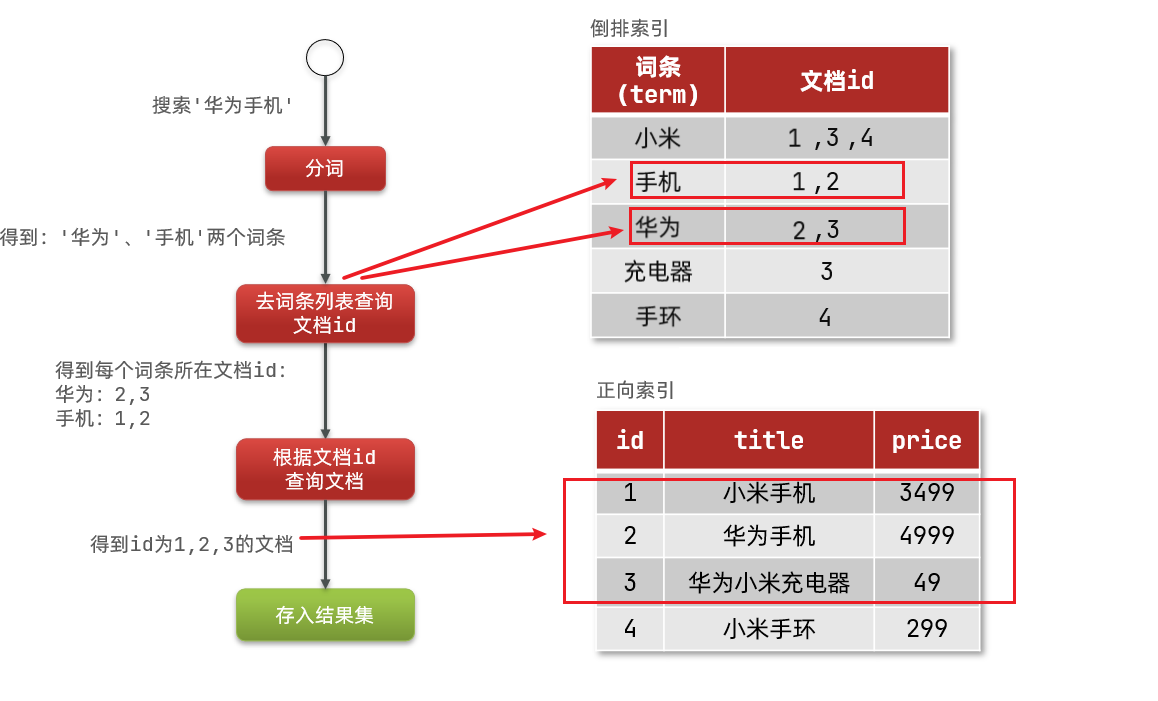
4.中文分词器介绍?
IKAnalyzer是一个开源的,基于java语言开发的轻量级的中文分词工具包,采用了特有的”正向迭代最细粒度切分算法”具有60万字/秒的高速处理能力。优化的词典存储,更小的内存占用。支持用户词典扩展定义
5.如何扩展新词 如何忽略停顿词?
- 扩展词词典
- 打开IK分词器config目录:
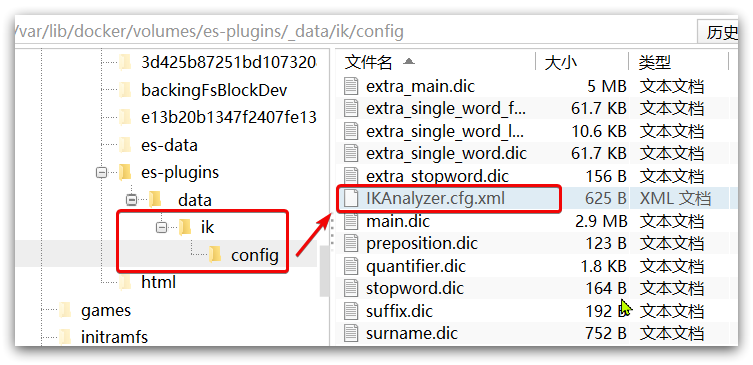
- 在IKAnalyzer.cfg.xml配置文件内容添加:
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE properties SYSTEM "http://java.sun.com/dtd/properties.dtd">
<properties>
<comment>IK Analyzer 扩展配置</comment>
<!--用户可以在这里配置自己的扩展字典 *** 添加扩展词典-->
<entry key="ext_dict">ext.dic</entry>
</properties>
- 新建一个 ext.dic,可以参考config目录下复制一个配置文件进行修改,在文档里编写自定义拓展词典.
- 重启elasticsearch
停用词词典
1)IKAnalyzer.cfg.xml配置文件内容添加:
<?xml version="1.0" encoding="UTF-8"?> <!DOCTYPE properties SYSTEM "http://java.sun.com/dtd/properties.dtd"> <properties> <comment>IK Analyzer 扩展配置</comment> <!--用户可以在这里配置自己的扩展字典 *** 添加扩展词典--> <entry key="ext_dict">ext.dic</entry> <!--用户可以在这里配置自己的扩展停止词字典 *** 添加停用词词典--> <entry key="ext_stopwords">stopword.dic</entry> </properties>在 stopword.dic 添加停用词
- 重启elasticsearch
6.mysql和es 对比?
es 更关注的是海量数据的搜索,对事务,并发处理一致性的问题没有严格性的要求数据建模也不严格(后续可以随意添加列),mysql对事务,并发处理一致性的问题要求较高,数据的管理放在mysql中管理,负责增删改,需要查询时再将数据存一份到es中,搜索时就无须再访问mysql,如果mysql数据更新,可以使用mq进行监听并同步.7.java中如何操作es?
索引库相关请求需要加Index,文档不需要
索引库的操作
统一的第一步:初始化客户端
@BeforeEach void setUp() { client = new RestHighLevelClient(RestClient.builder( HttpHost.create("http://192.168.200.129:9200") )); }创建索引库
@Test
void testCreateIndex() throws IOException {
// 1. 创建对应操作的请求对象 CreateIndexRequest
CreateIndexRequest request = new CreateIndexRequest("hotel"); // 索引库名称
// 设置请求参数
request.source(HotelConstants.MAPPING_TEMPLATE, XContentType.JSON);
// 2. 调用client执行对应请求方法
CreateIndexResponse response = client.indices().create(request, RequestOptions.DEFAULT);
// 3. 解析响应结果
System.out.println(response.isAcknowledged());
}
取得索引库(判断索引库是否存在)
@Test void testExistsIndex() throws IOException { // 1. 创建对应操作的请求对象 GetIndexRequest request = new GetIndexRequest("hotel"); // 设置请求参数 // 2. 调用client执行对应请求方法 boolean exists = client.indices().exists(request, RequestOptions.DEFAULT); // 3. 解析响应结果 System.out.println(exists ? "索引库已经存在":"索引库不存在"); }删除索引库
@Test public void deleteIndex() throws IOException { // 1. 创建对应操作的请求对象 DeleteIndexRequest request = new DeleteIndexRequest("hotel"); // 设置请求参数 // 2. 调用client执行对应请求方法 AcknowledgedResponse response = client.indices().delete(request, RequestOptions.DEFAULT); // 3. 解析响应结果 System.out.println(response.isAcknowledged()); }统一最后一步:关闭连接
/** * 关闭客户端 */ @AfterEach public void closeClient(){ try { client.close(); } catch (IOException e) { e.printStackTrace(); } }
文档的操作
统一的第一步:初始化客户端
@BeforeEach void setUp() { client = new RestHighLevelClient(RestClient.builder( HttpHost.create("http://192.168.200.129:9200") )); }添加文档(获取对象后一定转换成json数据)
@Test public void addDocument() throws IOException { // 1. 从数据库中 根据id查询一条酒店数据 Hotel Hotel hotel = hotelService.getById(38812); // 2. 将Hotel转为HotelDoc HotelDoc hotelDoc = new HotelDoc(hotel); // 3. 将数据添加到索引库 // 3.1 创建请求对象 IndexRequest IndexRequest request = new IndexRequest("hotel"); // 设置请求参数 id 文档json内容 request.id(String.valueOf(hotelDoc.getId())); // 文档json字符串 指定参数类型json request.source(JSON.toJSONString(hotelDoc),XContentType.JSON); // 3.2 调用client执行对应的方法 index IndexResponse response = client.index(request, RequestOptions.DEFAULT); // 3.3 得到响应结果 System.out.println(response.getResult()); }获取文档
@Test public void getDocumentById() throws IOException { // 1. 创建请求 GetRequest request = new GetRequest("hotel","38812"); // 2. 执行请求 GetResponse response = client.get(request, RequestOptions.DEFAULT); // 3. 解析响应 String jsonStr = response.getSourceAsString(); HotelDoc hotelDoc = JSON.parseObject(jsonStr, HotelDoc.class); System.out.println(hotelDoc); }修改文档(修改某一个属性,修改全属性使用index方法)
@Test public void updateDocumentById() throws IOException { // 1. 创建请求 UpdateRequest updateRequest = new UpdateRequest("hotel","38812"); updateRequest.doc("price","698"); // 2. 执行请求 UpdateResponse response = client.update(updateRequest, RequestOptions.DEFAULT); // 3. 解析响应 System.out.println(response.getResult()); }删除文档
@Test public void deleteDocumentById() throws IOException { // 1. 创建请求 DeleteRequest request = new DeleteRequest("hotel","38812"); // 2. 执行请求 DeleteResponse response = client.delete(request, RequestOptions.DEFAULT); // 3. 解析响应 System.out.println(response.getResult()); }批量导入(IndexRequest对象不支持复用,需要放在循环里,否则会被覆盖)
@Test public void bulkAddDocuments() throws IOException { // 1. 查询出数据库中所有的酒店数据 list集合 List<Hotel> list = hotelService.list(); // 2. 创建批处理对象 BulkRequest BulkRequest request = new BulkRequest("hotel"); // 3. 遍历集合 for (Hotel hotel : list) { // 3.1 集合中的每一个Hotel对象 转成 HotelDoc HotelDoc hotelDoc = new HotelDoc(hotel); // 3.2 创建文档添加请求 IndexRequest IndexRequest indexRequest = new IndexRequest(); indexRequest.id(String.valueOf(hotelDoc.getId())); indexRequest.source(JSON.toJSONString(hotelDoc),XContentType.JSON); // 3.3 将添加请求 添加到批处理请求中 request.add(indexRequest); } // 4. 调用client执行bulk批处理方法 BulkResponse bulk = client.bulk(request, RequestOptions.DEFAULT); // 5. 得到响应结果 System.out.println(bulk.status()); }统一最后一步:关闭连接
/** * 关闭客户端 */ @AfterEach public void closeClient(){ try { client.close(); } catch (IOException e) { e.printStackTrace(); } }

若有收获,就点个赞吧
0 人点赞
