JAVASE
IDEA快捷键
1)删除当前行,默认是ctrl+Y自己配置ctrl+ d2)复制当前行,自己配置 ctrl+ alt+向下光标3)补全代码alt +/4)添加注释和取消注释ctrl+/【第一次是添加注释,第二次是取消注释】5)导入该行需要的类先配置 auto import,然后使用alt+enter即可6)快速格式化代码ctrl+ alt+L7)快速运行程序自己定义alt+R8)生成构造器等alt + insert[提高开发效率]9)查看一个类的层级关系 ctrl+H[学习继承后,非常有用]10)将光标放在一个方法上,输入 cturl+B,可以定位到方法[学继承后,非常有用]11)自动的分配变量名,通过在后面假.var[老师最喜欢的]
基础语法

- 整型常量默认为int,声明long型常量后面要加L/I
- boolean,一字节,只允许取值true/false
类型转换
- 自动类型转换
- 小转大

int a = 'c';//truedouble d = 80; //false

- 强制类型转换
- 大转小
- 基本数据类型和Sting类型的转换
- 基本类型值+“ ”
- 基本类型包装类的parseXX方法

运算符
算数运算符
%本质:// % 取模 ,取余// 在 % 的本质 看一个公式!!!! a % b = a - a / b * b// -10 % 3 => -10 - (-10) / 3 * 3 = -10 + 9 = -1
int i = 1;//i->1i = i++; //规则使用临时变量: (1) temp = i; (2) i = i + 1; (3) i = temp;System.out.println(i); // 1int j = 1;j = ++j; //规则使用临时变量: (1) j = j + 1; (2) temp = j; (3) j = temp;System.out.println(j); //2

关系运算符(比较运算符)

逻辑运算符

- &
逻辑与:不管第一个条件是否为 false,第二个条件都要判断,效率低
- &&
短路与:如果第一个条件为 false,则第二个条件不会判断,最终结果为 false,效率高
| - | 逻辑或:不管第一个条件是否为 true,第二个条件都要判断,效率低 |
|---|---|
如果第一个条件为 true,则第二个条件不会判断,最终结果为 true,效率高
- ^
- !
赋值运算符
= 、 += ,-= ,*= , /= ,%=等
复合赋值运算符会进行类型转换
byte b = 3;b += 2;// == b = (byte)(b+2);b++; //b = (byte)(b+1);
优先级

键盘录入
- Scanner sc = new Scanner(System.in);
String name = sc.next();//录入的值作为字符串返回
随机数产生
- Random r = new Random();
int a = r.nextInt(10)+1;//+1代表0-10,要不是0-9。
数组
数组概念
数组就是存储数据长度固定的容器,保证多个数据的数据类型要一致。
数组初始化
数组的两种常见初始化方式:
- 动态初始化(指定长度)
- 静态初始化(指定内容)
方式一:动态初始化
- 格式:
数组存储的数据类型[ ] 数组名字 = new 数组存储的数据类型[数组长度];
数组存储的数据类型 数组名字[ ] = new 数组存储的数据类型[数组长度];
- 数组定义格式详解:
- 数组存储的数据类型: 创建的数组容器可以存储什么数据类型。
- [] : 表示数组。
- 数组名字:为定义的数组起个变量名,满足标识符规范,可以使用名字操作数组。
- new:关键字,创建数组使用的关键字。
- 数组存储的数据类型: 创建的数组容器可以存储什么数据类型。
- [长度]:数组的长度,表示数组容器中可以存储多少个元素。
- 注意:数组有定长特性,长度一旦指定,不可更改。
- 和水杯道理相同,买了一个2升的水杯,总容量就是2升,不能多也不能少。
- 举例:
定义可以存储3个整数的数组容器,代码如下:int[] arr = new int[3];int arr[] = new int[3];// 可以拆分int[] arr;arr = new int[3];12345
方式二: 静态初始化
- 格式:
数据类型[] 数组名 = new 数据类型[]{元素1,元素2,元素3…};
- 举例: 定义存储1,2,3,4,5整数的数组容器。
int[] arr = new int[]{1,2,3,4,5};// 可以拆分int[] arr;arr = new int[]{1,2,3,4,5};1234
方式三 :静态初始化省略格式(不能拆分)
- 格式:
数据类型[] 数组名 = {元素1,元素2,元素3…};
- 举例:
定义存储1,2,3,4,5整数的数组容器int[] arr = {1,2,3,4,5};1
@扩展方法: Arrays.fill快速初始化,填充一个数组
java中的数组初始值都为零,若快速填充一个其他值的数组,即将数组批量填充相同的值,可以用 Arrays.fill 方法,但只能填充一个一维数组,多维数组还得用循环。
举例:
import java.util.Arrays;public class HelloWorld {public static void main(String[] args) {int[] arr = new int[5];Arrays.fill(arr, 1);System.out.println(Arrays.toString(arr)); // [1, 1, 1, 1, 1]}}12345678910
虽然Arrays.fill方法不能填充二维数组,不过在下面这种情况下,还是可以用一下的:
int[][] map=new int[4][5];int[] row={1,2,6,3,6,1,7};Arrays.fill(map,row);123
当row中的数值不固定,也不一定有规律时,可以用Arrays.fill()来填充二维数组,使其每一行都是{1,2,6,3,6,1,7}
数组的访问
- 索引: 每一个存储到数组的元素,都会自动的拥有一个编号,从0开始,这个自动编号称为
数组索引 (index),可以通过数组的索引访问到数组中的元素。 - 格式:
数组名[索引]
- 数组的长度属性: 每个数组都具有长度,而且是固定的,Java中赋予了数组的一个属性,可以获取到数组的长度,语句为:
数组名.length,属性length的执行结果是数组的长度,int类型结果。由次可以推断出,数组的最大索引值为数组名.length-1。public static void main(String[] args) {int[] arr = new int[]{1,2,3,4,5};//打印数组的属性,输出结果是5System.out.println(arr.length);}12345
- 索引访问数组中的元素:
- 数组名[索引] = 数值,为数组中的元素赋值
- 变量 = 数组名[索引],获取出数组中的元素
public static void main(String[] args) {//定义存储int类型数组,赋值元素1,2,3,4,5int[] arr = {1,2,3,4,5};//为0索引元素赋值为6arr[0] = 6;//获取数组0索引上的元素int i = arr[0];System.out.println(i);//直接输出数组0索引元素System.out.println(arr[0]);}1234567891011
二维数组操作
二维数组初始化
同一维数组一样,共有4总不同形式的定义方法:
int[][] array1 = new int[10][10];int array2[][] = new int[10][10];int array3[][] = { { 1, 1, 1 }, { 2, 2, 2 } };int array4[][] = new int[][] { { 1, 1, 1 }, { 2, 2, 2 } };1234
不定长二维数组
int[][] array = new int[3][];array[0] = new int[1];array[1] = new int[2];array[2] = new int[3];1234
获取二维数组的长度
int length1 = array.length;int length2 = array[0].length;// 获取二维数组的第一维长度(3)System.out.println(length1);// 获取二维数组的第一维的第一个数组长度(1)System.out.println(length2);123456
数组原理内存图
内存概述
内存是计算机中的重要原件,临时存储区域,作用是运行程序。我们编写的程序是存放在硬盘中的,在硬盘中的程序是不会运行的,必须放进内存中才能运行,运行完毕后会清空内存。 Java虚拟机要运行程序,必须要对内存进行空间的分配和管理。
Java虚拟机的内存划分
为了提高运算效率,就对空间进行了不同区域的划分,因为每一片区域都有特定的处理数据方式和内存管理方式。
- JVM的内存划分 | 区域名称 | 作用 | | —- | —- | | 寄存器 | 给CPU使用,和我们开发无关。 | | 本地方法栈 | JVM在使用操作系统功能的时候使用,和我们开发无关。 | | 方法区 | 存储可以运行的class文件。 | | 堆内存 | 存储对象或者数组,new来创建的,都存储在堆内存。 | | 方法栈 | 方法运行时使用的内存,比如main方法运行,进入方法栈中执行。 |

数组在内存中的存储
1. 一个数组内存图
public static void main(String[] args) {int[] arr = new int[3];System.out.println(arr); // [I@5f150435}1234
以上方法执行,输出的结果是[I@5f150435,这个是什么呢?是数组在内存中的地址。new出来的内容,都是在堆 内存中存储的,而方法中的变量arr保存的是数组的地址。
输出arr[0],就会输出arr保存的内存地址中数组中0索引上的元素
实例: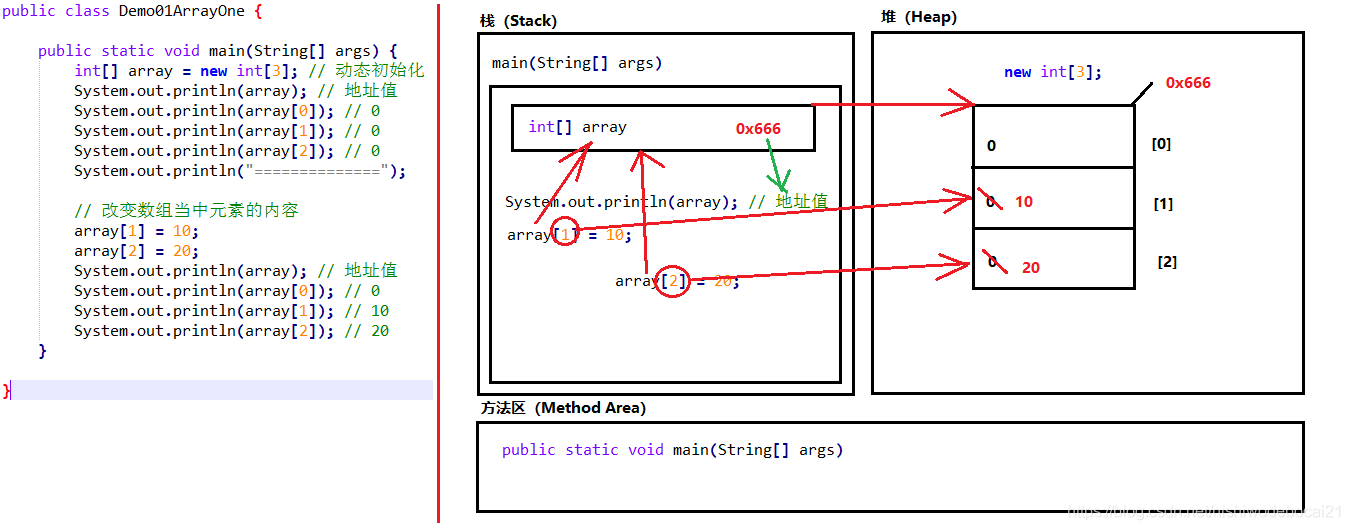
程序执行流程:
- main方法进入方法栈执行
- 创建数组,JVM会在堆内存中开辟空间,存储数组
- 数组在内存中会有自己的内存地址,以十六进制数表示
- 数组中有3个元素,默认值为0
- JVM将数组的内存地址赋值给引用类型变量array
- 变量array保存的是数组内存中的地址,而不是一个具体数值,因此称为引用数据类型。
2. 两个数组内存图
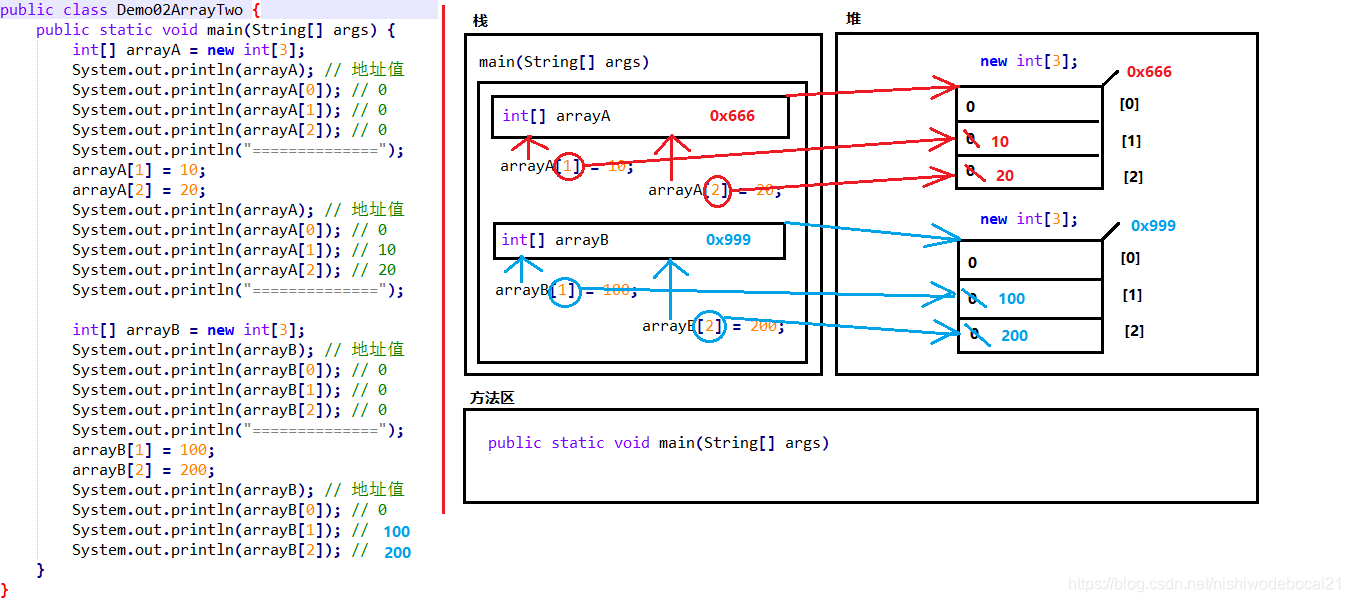
3. 两个变量指向一个数组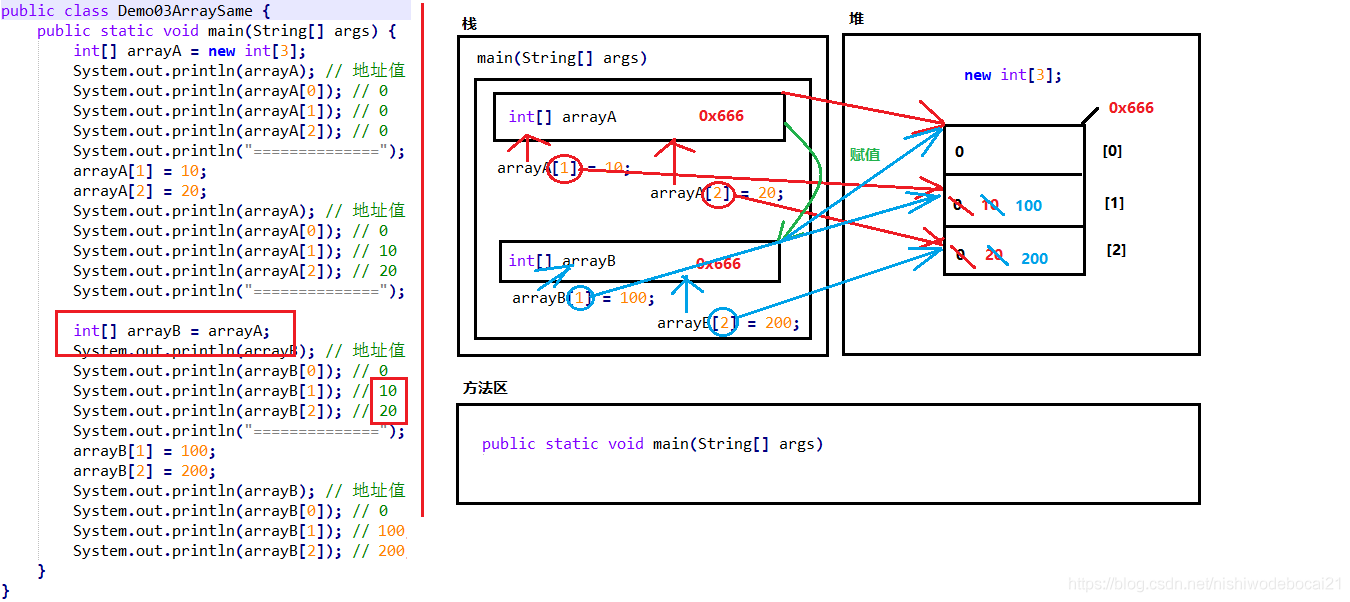
数组遍历
数组遍历: 就是将数组中的每个元素分别获取出来,就是遍历。遍历也是数组操作中的基石。
public static void main(String[] args) {int[] arr = { 1, 2, 3, 4, 5 };System.out.println(arr[0]);System.out.println(arr[1]);System.out.println(arr[2]);System.out.println(arr[3]);System.out.println(arr[4]);}12345678
以上代码是可以将数组中每个元素全部遍历出来,但是如果数组元素非常多,这种写法肯定不行,因此我们需要改造成循环的写法。数组的索引是 0 到 lenght-1 ,可以作为循环的条件出现。for循环遍历方式
public static void main(String[] args) {int[] arr = { 1, 2, 3, 4, 5 };for (int i = 0; i < arr.length; i++) {System.out.println(arr[i]);}}123456
- foreach遍历方式
public static void main(String[] args) {int[] arr = { 1, 2, 3, 4, 5 };for (int i : arr) {System.out.println(i);}}123456
数组常见异常
数组越界异常
观察一下代码,运行后会出现什么结果?
public static void main(String[] args) {int[] arr = {1,2,3};System.out.println(arr[3])}1234
创建数组,赋值3个元素,数组的索引就是0,1,2,没有3索引,因此我们不能访问数组中不存在的索引,程序运行后,将会抛出 ArrayIndexOutOfBoundsException 数组越界异常。在开发中,数组的越界异常是不能出现的,一 旦出现了,就必须要修改我们编写的代码。
数组空指针异常
观察一下代码,运行后会出现什么结果。
public static void main(String[] args) {int[] arr = {1,2,3};arr = null;System.out.println(arr[0]);}12345
arr = null 这行代码,意味着变量arr将不会在保存数组的内存地址,也就不允许再操作数组了,因此运行的时候 会抛出 NullPointerException 空指针异常。在开发中,数组的空指针异常是不能出现的,一旦出现了,就必须要修改我们编写的代码。
空指针异常内存图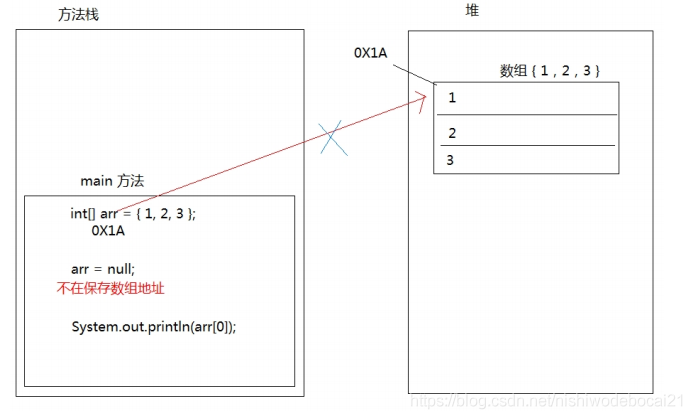
数组常见操作
数组反转
数组的反转: 数组中的元素颠倒顺序,例如原始数组为1,2,3,4,5,反转后的数组为5,4,3,2,1
实现思想: 对称位置的元素交换
- 实现反转,就需要将数组对称元素位置交换
- 定义两个变量,保存数组的最小索引和最大索引
- 两个索引上的元素交换位置
最小索引++,最大索引--,再次交换位置 - 最小索引超过了最大索引,数组反转操作结束
实现思路:
- 把数组最小索引元素和数组的最大索引元素交换
- 把数组次小索引元素和数组索引次大索引元素交换
- …
- 定义两个索引,一个指向最小索引,一个指向最大索引
int min = 0; int max = arr.length - 1; - 遍历数组,让两个索引变化
min++,max–, 交换条件 min < max; - 交换最小索引元素 和最大索引元素
需要定义三方变量
int temp = arr[min];
arr[min] = arr[max];
arr[max] = temp;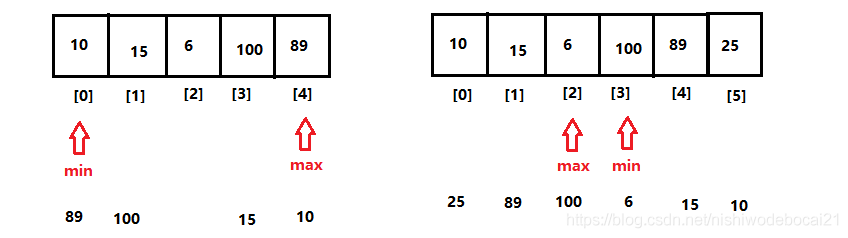
代码实现:public static void main(String[] args) {int[] arr = { 1, 2, 3, 4, 5 };/*循环中定义变量min=0最小索引 max=arr.length‐1最大索引min++,max‐‐*/for (int min = 0, max = arr.length ‐ 1; min <= max; min++, max‐‐) {//利用第三方变量完成数组中的元素交换int temp = arr[min];arr[min] = arr[max];arr[max] = temp; }// 反转后,遍历数组for (int i = 0; i < arr.length; i++) {System.out.println(arr[i]);}}1234567891011121314
数组获取最大元素
最大值获取:从数组的所有元素中找出最大值。
实现思路:
- 定义变量 max,保存数组0索引上的元素
- 遍历数组,获取出数组中的每个元素
- 将遍历到的元素和保存数组0索引上值的max变量进行比较
- 如果数组元素的值大于了变量的值,变量记录住新的值
- 数组循环遍历结束,变量保存的就是数组中的最大值
public static void main(String[] args) {int[] arr = { 5, 15, 2000, 10000, 100, 4000 }; //定义变量,保存数组中0索引的元素int max = arr[0]; //遍历数组,取出每个元素for (int i = 0; i < arr.length; i++) {//遍历到的元素和变量max比较//如果数组元素大于maxif (arr[i] > max) {//max记录住大值 max = arr[i];}}System.out.println("数组最大值是: " + max);}123456789101112
数组排序
public static void main(String[] args) {int[] array = { 3, 2, 1, 4, 5 };Arrays.sort(array);System.out.println(Arrays.toString(array)); // [1, 2, 3, 4, 5]}123456
Java常用API
输出数组 Arrays.toString()
int[] array = { 1, 2, 3 };System.out.println(Arrays.toString(array));12
数组转List Arrays.asList()
String[] array2 = {"a", "b", "c", "d"};System.out.println(array2); // [Ljava.lang.String;@13b6d03List list = new ArrayList(Arrays.asList(array2));System.out.println(list); // [a, b, c, d]list.add("GG");System.out.println(list); // [a, b, c, d, GG]123456
数组转Set Arrays.asList()
String[] array = { "a", "b", "c", "d", "e" };Set set = new HashSet(Arrays.asList(array));System.out.println(set);123
List转数组 toArray()
List list = new ArrayList();list.add("a");list.add("b");list.add("c");String[] array = new String[list.size()];list.toArray(array);for (String s : array)System.out.println(s);12345678
数组中是否包含某个值
String[] array = { "a", "b", "c", "d", "e" };boolean isEle = Arrays.asList(array).contains("a");System.out.println(isEle);123
数组复制
int array[] = new int[] { 1, 2, 3, 4 };int array1[] = new int[array.length];System.arraycopy(array, 0, array1, 0, array.length);123
数组合并
int[] array1 = { 1, 2, 3, 4, 5 };int[] array2 = { 6, 7, 8, 9, 10 };int[] array = org.apache.commons.lang.ArrayUtils.addAll(array1, array2);System.out.println(Arrays.toString(array));String数组转字符串(使用指定字符拼接)String[] array = { "a", "b", "c" };String str = org.apache.commons.lang.StringUtils.join(array, ", ");System.out.println(str);12345678
数组逆序
int[] array = { 1, 2, 3, 4, 5 };org.apache.commons.lang.ArrayUtils.reverse(array);System.out.println(Arrays.toString(array));123
数组元素移除
int[] array = { 1, 2, 3, 4, 5 };int[] removed = org.apache.commons.lang.ArrayUtils.removeElement(array, 3);System.out.println(Arrays.toString(removed));123
数组作为方法参数和返回值
7.1. 数组作为方法参数
以前的方法中我们所了解的方法的参数和返回值都是使用的基本数据类型。那么作为引用类型的数组能否作为方法的参数进行传递呢,当然是可以的。 数组作为方法参数传递,传递的参数是数组内存的地址。
public static void main(String[] args) {int[] arr = { 1, 3, 5, 7, 9 };//调用方法,传递数组printArray(arr);}/* 创建方法,方法接收数组类型的参数 进行数组的遍历 */public static void printArray(int[] arr) {for (int i = 0; i < arr.length; i++) {System.out.println(arr[i]);}}1234567891011
内存图示例: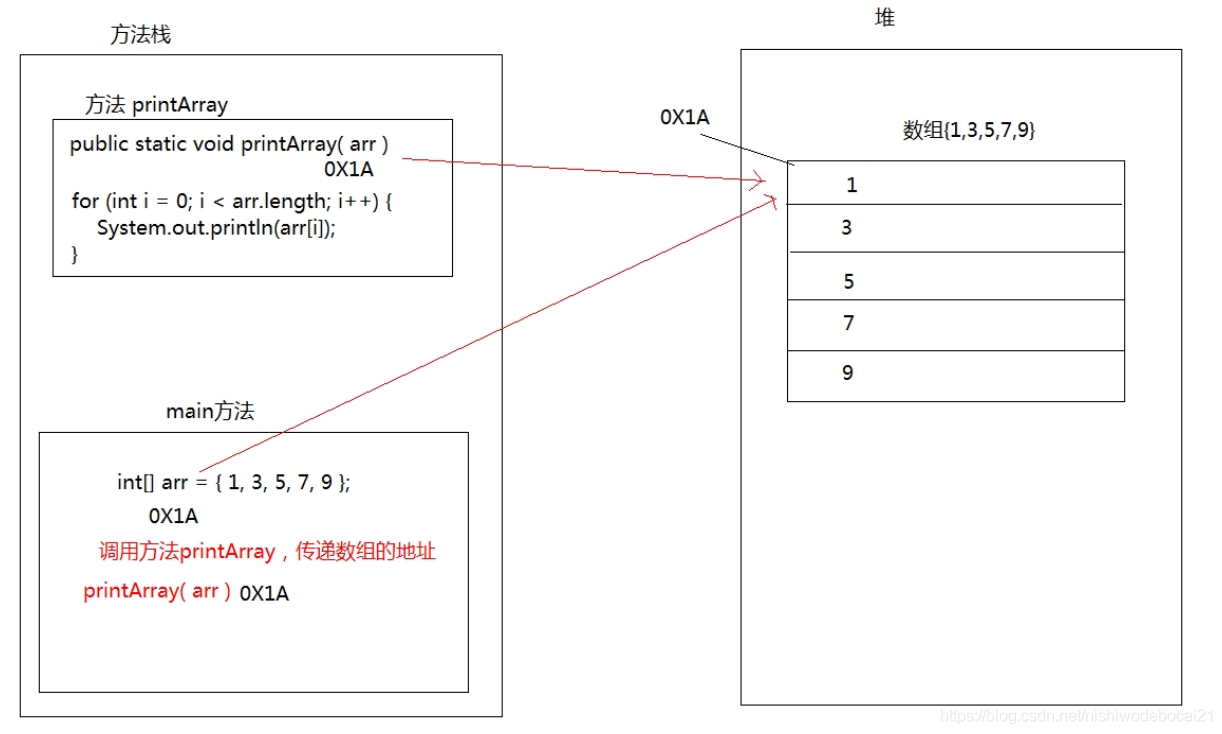
7.2. 数组作为方法返回值
数组作为方法的返回值,返回的是数组的内存地址
public static void main(String[] args) {//调用方法,接收数组的返回值//接收到的是数组的内存地址int[] arr = getArray();for (int i = 0; i < arr.length; i++) {System.out.println(arr[i]);}}/* 创建方法,返回值是数组类型创建方法,返回值是数组类型 return返回数组的地址 */public static int[] getArray() {int[] arr = { 1, 3, 5, 7, 9 };//返回数组的地址,返回到调用者return arr;}12345678910111213141516
内存图: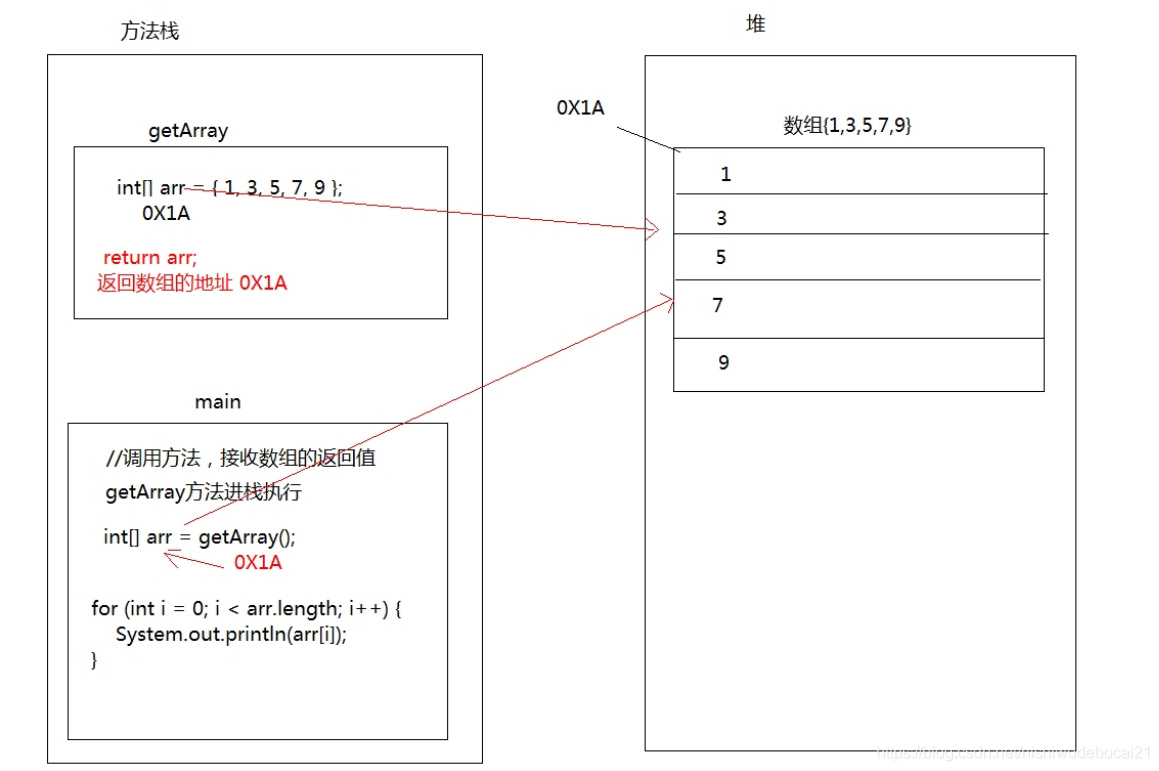
7.3. 方法的参数类型区别
代码分析
1.分析下列程序代码,计算输出结果。
public static void main(String[] args) {int a = 1;int b = 2;System.out.println(a); // 1System.out.println(b); // 2change(a, b);System.out.println(a); // 1System.out.println(b); // 2}public static void change(int a, int b) {a = a + b;b = b + a;}
2.分析下列程序代码,计算输出结果。
public static void main(String[] args) {int[] arr = {1,3,5};System.out.println(arr[0]); // 1change(arr);System.out.println(arr[0]); // 200}public static void change(int[] arr) {arr[0] = 200;}
总结: 方法的参数为基本类型时,传递的是数据值. 方法的参数为引用类型时,传递的是地址值.
方法
- 不能嵌套调用
- 方法重载
- 多个方法在同一个类中
- 多个方法具有相同的方法名
- 多个方法的参数不相同,类型不同或者数量不同
总结性小案例
- 买飞机票
- 找素数
- 生成随机验证码
- 复制数组
- 评委打分计算
- 数字加密
- 红包抽奖
- 彩票兑奖
面向对象
初识
- 构造器
- 有参
- 无参
- this关键字
- 封装
- getter
- setter
- javaBean
static
- 静态成员变量
〈有static修饰,属于类,内存中加载一次) - 实例成员变量
〈无static修饰,存在于每个对象中) - 访问方法/变量
- 类名.静态
- 实例.成员
- 工具类
:一是方便调用,二是提高了代码复用- 构造器私有
- 代码块
- 静态~
- static{} 随着类的加载而加载,并且自动触发、只执行一次;常用作一些静态数据的初始化操作,以便后续使用。
- 构造~
- {} 每次创建对象,调用构造器执行时,都会执行该代码块中的代码,并且在构造器执行前执行。 初始化实例成员
- 静态~
- 单例模式
- 饿汉~
- 实现
- 懒汉~
- 实现
- 饿汉~
继承
子类们相同特征(共性属性,共性方法)放在父类中定义,子类独有的的属性和行为应该定义在子类自己里面
- 内存图
- 特点
- 单继承
- 所有类是Object子类
- 构造器不继承
- 成员变量/方法寻找链
- 子类局部->子类成员->父类成员
- 子父类重名
- 子类优先
- super可指定父类
- 方法重写
- @override
- 私有方法、父类静态方法不可
- 名称、参数一致
- 重写父类方法权限>=ta
- 子类构造器
- 特点
- 先访问父类的(默认无参),默认第一句super()
- super(…)调用有参
- 利用this调用自己对象的构造器
public Student(String name) {
// 借用兄弟构造器!
this(name, “黑马培训中心”);
}
public Student(String name, String schoolName) {
this.name = name;
this.schoolName = schoolName;
}
- 特点
包
- 定义
- 建包
- 导包
- 若有两个同名类,默认只导一个,另一个带包名访问
权限修饰符
- private
- 缺省
- protected
- public
- 自己定义类的一般要求
成员变量一般私有。
方法一般公开。
如果该成员只希望本类访问,使用private修饰
如果该成员只希望本类,同一个包下的其他类和子类访问,使用protected修饰。
final关键字
final关键字的作用:
final关键字修饰类, 修饰字段, 修饰方法,修饰局部变量,修饰方法的形参
final修饰类,表示最终类, 不能被继承,不能作为父类存在
final修饰字段,在定义时必须显示初始化, 不能被修改, 一般与static同时使用,所有字母都大写,称为final常量
final修饰方法,不能被覆盖(重写)
final修饰局部变量, 一旦初始化就不能再修改, 注意final修饰引用类型变量,是指这个变量不能再指向 其他对象 , 可以修改它的字段值
final修饰方法形参, 在方法体中不能修改final参数的值
常量
- public static final修饰
- 命名规范
- 执行原理
枚举
- 是什么,作用
- 格式
- 反编译后特征
l 枚举类都是继承了枚举类型:java.lang.Enum
l 枚举都是最终类,不可以被继承。
l 构造器都是私有的,枚举对外不能创建对象。
l 枚举类的第一行默认都是罗列枚举对象的名称的。
l 枚举类相当于是多例模式。 - 使用场景
抽象类
- 由来,作用
- 抽象方法
- 注意点
Ø 类有的成员(成员变量、方法、构造器)抽象类都具备
Ø 抽象类中不一定有抽象方法,有抽象方法的类一定是抽象类.
Ø 一个类继承了抽象类必须重写完抽象类的全部抽象方法,否则这个类也必须定义成抽象类。.
Ø 不能用abstract修饰变量、代码块、构造器。 - 模板方法(final)
- 把功能定义成一个所谓的模板方法,放在抽象类中,模板方法中只定义通用且能确定的代码。
- 模板方法中不能决定的功能定义成抽象方法让具体子类去实现。
接口
一个类实现接口,必须重写完全部接口的全部抽象方法,否则这个类需要定义成抽象类。
- 格式
- 实现
- 多继承
- 新增方法
- 默认
- 静态
- 私有
- 注意事项
- 1、接口不能创建对象
- 2、一个类实现多个接口,多个接口中有同样的静态方法不冲突。
- 3、一个类继承了父类,同时又实现了接口,父类中和接口中有同名方法,默认用父类的。
- 4、一个类实现了多个接口,多个接口中存在同名的默认方法,不冲突,这个类重写该方法即可。
- 5、一个接口继承多个接口,是没有问题的,如果多个接口中存在规范冲突则不能多继承。
接口中的默认方法与静态方法(java8)
Java 8中允许接口中包含具有具体实现的方法,该方法称为 “默认方法” ,默认方法使用 default 关键字修饰。
例如

接口默认方法的”类优先”原则
若一个接口中定义了一个默认方法,而另外一个父类或接口中 又定义了一个同名的方法时
⚫ 选择父类中的方法。如果一个父类提供了具体的实现,那么 接口中具有相同名称和参数的默认方法会被忽略。
⚫ 接口冲突。如果一个父接口提供一个默认方法,而另一个接 口也提供了一个具有相同名称和参数列表的方法(不管方法 是否是默认方法),那么必须覆盖该方法来解决冲突

接口中的静态方法

Optional
简介
java8中新引入了optional特性,官方说法是更优雅的处理空指针异常,用来表示一个变量的值可以为空也可以不为空,此处引用java 8实战里面的描述:
在你的代码中始终如一地使用Optional,能非常清晰地界定出变量值的缺失是结构上的问
题,还是你算法上的缺陷,抑或是你数据中的问题。另外,我们还想特别强调,引入Optional
类的意图并非要消除每一个null引用。与此相反,它的目标是帮助你更好地设计出普适的API,
让程序员看到方法签名,就能了解它是否接受一个Optional的值。这种强制会让你更积极地将
变量从Optional中解包出来,直面缺失的变量值
所以,optional的作用是显示的表达变量的状态,而不是为了完全消灭NPE。
Option之前
talk is cheap,show me the code:
//根据客户信息获取车辆保险公司的名称public String getCarInsuranceName(Person person) {//对客户判空if (person == null) {return "Unknown";}//对车辆判空Car car = person.getCar();if (car == null) {return "Unknown";}//对保险公司判空Insurance insurance = car.getInsurance();if (insurance == null) {return "Unknown";}return insurance.getName();}12345678910111213141516171819
以上代码,可能是我日常开发经常遇到的,过多的NullPointerException检查,影响到了代码的可读性以及优雅性,而且存在潜在的风险,假设其中某个环节未做空指针的检查,则会看到我们熟悉而又讨厌的NullPointerException;
Option特性
创建Optional对象
- 声明一个空的Optional对象
Optional<Car> optCar = Optional.empty();123
- 依据一个非空值创建Optional
Optional<Car> optCar = Optional.of(car);12
Optional.of为静态工厂方法,参数为非控制,如果为空,则会直接抛出个NullPointerException
- 可接受null的Optional
Optional<Car> optCar = Optional.ofNullable(car);1
Optional.ofNullable同样为静态方法,只是参与可为空,如上代码,如果car为null,则会直接返回一个空的Optional对象
Optional对象相关操作方法
get()
Optional对象调用该方法,可以直接获取内容,但是前提是,Optional对象不能为空,否则会抛出NoSuchElementException异常;所以这种方法只有在确定Optional对象非空的情况下调用才是安全的。其实我们只需判断Optional是有值即可,这里官方的api也提供了相关方法,isPresent()返回布尔值来表明Optional对象是否为空
Optional<String> optional= Optional.of("test");if (optional.isPresent()){String value = optional1.get();//test}1234
orElse(T other)
它允许你在Optional对象不包含值时提供一个默认值,如下:
String nullName = null;String name=Optional.ofNullable(nullName).orElse("otherName");12
- orElseGet(Supplier<? extends T> other)
orElseGet是orElse的延伸版,supplier方法只有在optional对象为空的时候才会执行
String name = Optional.ofNullable(nullName).orElseGet(() -> "otherName");1
ifPresent(Consumer<? super T>)
顾名思义,就是当Optional值存在的时候,执行consume函数方法
Optional<String> optional = Optional.of("test");optional.ifPresent(s -> System.out.println(s));123
orElseThrow(Supplier<? extends X> exceptionSupplier)
当Optional值不存的时候,我们也可以抛出异常,异常可以自定义
其他
Optional对象也可以使用java8中的steam闲逛的方法,比如map、flatMap、filter这三种函数,引用java8实战中的样例,如下:
找出年龄大于或者等于minAge参数的Person所对应的保险公司列表。
public String getCarInsuranceName(Optional<Person> person, int minAge) {return person.filter(p -> p.getAge() >= minAge).flatMap(Person::getCar).flatMap(Car::getInsurance).map(Insurance::getName).orElse("Unknown");}12345678
注:当Optional对象为空时,则后面的map、flatMap、filter都不会继续执行
Optional实践
用于封装可能为null的值
Object value = map.get("key");1
此时,map.get(“key”)可能为空,这里可用使用Optional进行良好的封装处理,如下:
Optional<Object> value = Optional.ofNullable(map.get("key"));1
这样一来,只要看到这段代码,后面的人就知道该处的value值可能为空,很好的传达了程序处理的合理性,如果像上面那样,可能直接被当成存在对象使用,而引发空指针异常。
尽量不用于域模型中的某些类型
Optional的设计者并没有考虑将其作为类的字段使用,所以并没有实现Serializable接口,当使用到关于序列化的相关需求时,可能会引发的程序错误。如果确实有需求,可以采用以下方法作为替代方案:
public class Person {private Car car;public Optional<Car> getCarAsOptional() {return Optional.ofNullable(car);}}123456
总结
Optional主要是通过类型系统让你的域模型中隐藏的知识显式地体现在你的代码中,换句话说,你永远都不应该忘记语言的首要功能就是沟通,即使对程序设计语言而言也没有什么不同。声明方法接受一个Optional参数,或者将结果作为Optional类型返回,让你的同事或者未来你方法的使用者,很清楚地知道它可以接受空值,或者它可能返回一个空值。
多态
- 常见形式
- 父类类型 对象名称 = new 子类构造器;
- 接口 对象名称 = new 实现类构造器;
- 访问特点
- 方法调用
- 变量调用
- 前提条件
- 类型转换
- 自动(子到父)
- 强制(父到子)
- 实现调用子类独有功能
- instanceof
内部类
内部类就是定义在一个类里面的类,里面的类可以理解成(寄生),外部类可以理解成(宿主)。
- 静态内部类
- 成员内部类
- 局部内部类
- 匿名内部类
- 特点
- 匿名内部类是一个没有名字的内部类。
- 匿名内部类写出来就会产生一个匿名内部类的对象。
- 匿名内部类的对象类型相当于是当前new的那个的类型的子类类型
- 特点
- 格式
- 匿名内部类可以作为方法的实际参数进行传输。
String类
在Java语言中,所有类似“ABC”的字面值,都是String类的实例;String类位于java.lang包下,是Java语言的核心类,提供了字符串的比较、查找、截取、大小写转换等操作;Java语言为“+”连接符(字符串连接符)以及对象转换为字符串提供了特殊的支持,字符串对象可以使用“+”连接其他对象。String类的部分源码如下
public final class Stringimplements java.io.Serializable, Comparable<String>, CharSequence {/** The value is used for character storage. */private final char value[];/** Cache the hash code for the string */private int hash; // Default to 0...}
从上面可以看出
1)String类被final关键字修饰,意味着String类不能被继承,并且它的成员方法都默认为final方法;字符串一旦创建就不能再修改。
2)String类实现了Serializable、CharSequence、 Comparable接口。
3)String实例的值是通过字符数组实现字符串存储的。
为什么是不可变类型
在面向对象及函数编程y语言中,不可变对象是一种对象,在被创造之后,它的状态就不可以被改变。
我们可理解为:
一个对象创建完成之后,它的状态就不能再改变,包括的对象里面的成员变量,基本数据类型的值都不能改变,这样就叫做不可变对象
理解定义不叫简单,但是实际情况下我们总会混淆引用与对象,进而以为String可变,比如下面代码:
输出:
那么是String类型的s发生变化了才将abc改变成了123吗?
显然不是的,s只是一个引用,真正的对象是后面的abc和123,所以在内存中的关系这样的
abc对象并没有改变,而是将引用重新指向了一个新的对象123.
我们再从源码的角度看
我们点进String类,可以看到String类是被final修饰的。
我们看到final修饰了类就不能被继承,就是最终类了,它的方法不能被继承重写
String类型其实使用char类型的数组存放的,而这个数组也被final关键字修饰了
在整个String类中并没有一个用来修改对象值的方法
综上我们说java 中的String是不可变的
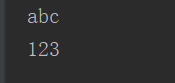
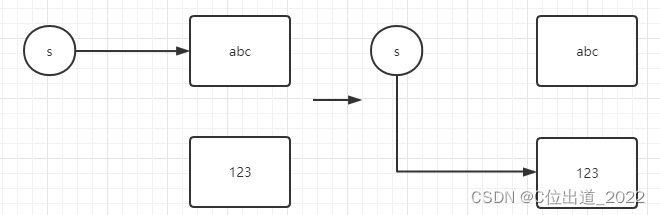
String s = "abc";System.out.println(s);s = "123";System.out.println(s);
常用方法
| equals(String other): | 判断字符串与other的值是否相等,相等返回true,不同返回flase。 |
|---|---|
| equalsIgnoreCase(String other): | 判断字符串值是否相等(忽略大小写) |
| startsWith(String prefix) | 判断字符串是否以prefix开头,是返回true,不是返回flase |
| endsWith(String prefix) | 判断字符串是否以prefix结尾,是返回true,不是返回false |
| indexof(String str) | 判断字符串是否包含str,如果包含,返回str的数组下标,如果不包含,返回-1 |
| charAt(int index) | 返回字符串中的第index个字符 |
|---|---|
| substring(int beginindex) | 返回一个新的字符串,包含从beginindex到串尾。 |
| substring(int beginindex,int endindex) | 返回一个新的字符串,包含从beginindex到endindex-1的内容。 |
| toLowerCase() | 返回一个新的字符串,将该串中的字母全部改成小写 |
|---|---|
| toUpperCase() | 返回一个新的字符串,将该串中的字母全部改成大写 |
| replace(char oldChar,char newChar) | 返回一个新的字符串,将串中的oldChar替换为newChar |
| trim() | 返回一个新的字符串,删除原串开头和结尾的空格。 |
构造方法
/** 关于String类中的构造方法:* 1、String s = new String("");* 2、String s = ""; //最常用* 3、String s = new String(char数组);* 4、String s = new String(char数组,起始下标,长度);* 5、String s = new String(byte数组);* 6、String s = new String(byte数组,起始下标,长度);*/public class StringTest01 {public static void main(String[] args) {byte [] bytes = {97,98,99}; //abc//String(字节数组,数组元素下标的起始位置,长度)String s1 = new String(bytes,1,2); //可将byte数组中一部分元素转为字符串String s2 = new String(bytes); //将byte数组全部转为字符串System.out.println(s1); //输出bcSystem.out.println(s2); //输出abcchar[] chars ={'你','好','啊'};String s3 = new String(chars);String s4 = new String(chars,0,1);System.out.println("s3:"+ s3 + "s4:"+s4);}}
- 赋值创建和构造方法创建区别
- ==比较
- 基本类型
- 引用类型
“+”连接符
“+”连接符的实现原理
Java语言为“+”连接符以及对象转换为字符串提供了特殊的支持,字符串对象可以使用“+”连接其他对象。
其中字符串连接是通过 StringBuilder(或 StringBuffer)类及其append 方法实现的
对象转换为字符串是通过 toString 方法实现的,该方法由 Object 类定义,并可被 Java 中的所有类继承。
我们可以通过反编译验证一下
/*** 测试代码*/public class Test {public static void main(String[] args) {int i = 10;String s = "abc";System.out.println(s + i);}}/*** 反编译后*/public class Test {public static void main(String args[]) { //删除了默认构造函数和字节码byte byte0 = 10;String s = "abc";System.out.println((new StringBuilder()).append(s).append(byte0).toString());}}
由上可以看出,Java中使用”+”连接字符串对象时,会创建一个StringBuilder()对象,并调用append()方法将数据拼接,最后调用toString()方法返回拼接好的字符串。由于append()方法的各种重载形式会调用String.valueOf方法,所以我们可以认为:
//以下两者是等价的s = i + ""s = String.valueOf(i);//以下两者也是等价的s = "abc" + i;s = new StringBuilder("abc").append(i).toString();1234567
“+”连接符的效率
使用“+”连接符时,JVM会隐式创建StringBuilder对象,这种方式在大部分情况下并不会造成效率的损失,不过在进行大量循环拼接字符串时则需要注意。
String s = "abc";for (int i=0; i<10000; i++) {s += "abc";}/*** 反编译后*/String s = "abc";for(int i = 0; i < 1000; i++) {s = (new StringBuilder()).append(s).append("abc").toString();}
这样由于大量StringBuilder创建在堆内存中,肯定会造成效率的损失,所以在这种情况下建议在循环体外创建一个StringBuilder对象调用append()方法手动拼接(如上面例子如果使用手动拼接运行时间将缩小到1/200左右)。
/*** 循环中使用StringBuilder代替“+”连接符*/StringBuilder sb = new StringBuilder("abc");for (int i = 0; i < 1000; i++) {sb.append("abc");}sb.toString();
与此之外还有一种特殊情况,也就是当”+”两端均为编译期确定的字符串常量时,编译器会进行相应的优化,直接将两个字符串常量拼接好,例如:
System.out.println("Hello" + "World");/*** 反编译后*/System.out.println("HelloWorld");/*** 编译期确定* 对于final修饰的变量,它在编译时被解析为常量值的一个本地拷贝存储到自己的常量池中或嵌入到它的字节码流中。* 所以此时的"a" + s1和"a" + "b"效果是一样的。故结果为true。*/String s0 = "ab";final String s1 = "b";String s2 = "a" + s1;System.out.println((s0 == s2)); //result = true/*** 编译期无法确定* 这里面虽然将s1用final修饰了,但是由于其赋值是通过方法调用返回的,那么它的值只能在运行期间确定* 因此s0和s2指向的不是同一个对象,故上面程序的结果为false。*/String s0 = "ab";final String s1 = getS1();String s2 = "a" + s1;System.out.println((s0 == s2)); //result = falsepublic String getS1() {return "b";}
综上,“+”连接符对于直接相加的字符串常量效率很高,因为在编译期间便确定了它的值,也就是说形如”I”+“love”+“java”; 的字符串相加,在编译期间便被优化成了”Ilovejava”。对于间接相加(即包含字符串引用,且编译期无法确定值的),形如s1+s2+s3; 效率要比直接相加低,因为在编译器不会对引用变量进行优化。
字符串常量池
在Java的内存分配中,总共3种常量池,分别是Class常量池、运行时常量池、字符串常量池。
字符串的分配和其他对象分配一样,是需要消耗高昂的时间和空间的,而且字符串使用的非常多。JVM为了提高性能和减少内存的开销,在实例化字符串的时候进行了一些优化:使用字符串常量池。每当创建字符串常量时,JVM会首先检查字符串常量池,如果该字符串已经存在常量池中,那么就直接返回常量池中的实例引用。如果字符串不存在常量池中,就会实例化该字符串并且将其放到常量池中。由于String字符串的不可变性,常量池中一定不存在两个相同的字符串。
/*** 字符串常量池中的字符串只存在一份!* 运行结果为true*/String s1 = "hello world!";String s2 = "hello world!";System.out.println(s1 == s2);
内存区域
在HotSpot VM中字符串常量池是通过一个StringTable类实现的,它是一个Hash表,默认值大小长度是1009;这个StringTable在每个HotSpot VM的实例中只有一份,被所有的类共享;字符串常量由一个一个字符组成,放在了StringTable上。要注意的是,如果放进String Pool的String非常多,就会造成Hash冲突严重,从而导致链表会很长,而链表长了后直接会造成的影响就是当调用String.intern时性能会大幅下降(因为要一个一个找)。
在JDK6及之前版本,字符串常量池是放在Perm Gen区(也就是方法区)中的,StringTable的长度是固定的1009;在JDK7版本中,字符串常量池被移到了堆中,StringTable的长度可以通过-XX:StringTableSize=66666参数指定。至于JDK7为什么把常量池移动到堆上实现,原因可能是由于方法区的内存空间太小且不方便扩展,而堆的内存空间比较大且扩展方便。
存放的内容
在JDK6及之前版本中,String Pool里放的都是字符串常量;在JDK7.0中,由于String.intern()发生了改变,因此String Pool中也可以存放放于堆内的字符串对象的引用。
/*** 运行结果为true false*/String s1 = "AB";String s2 = "AB";String s3 = new String("AB");System.out.println(s1 == s2);System.out.println(s1 == s3);
由于常量池中不存在两个相同的对象,所以s1和s2都是指向JVM字符串常量池中的”AB”对象。new关键字一定会产生一个对象,并且这个对象存储在堆中。所以String s3 = new String(“AB”);产生了两个对象:保存在栈中的s3和保存堆中的String对象。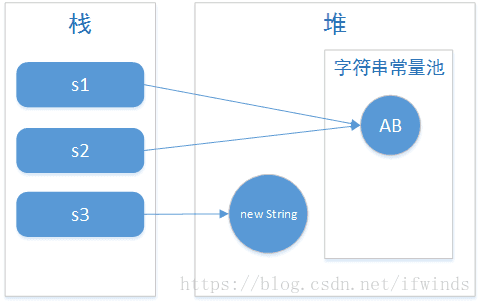
当执行String s1 = “AB”时,JVM首先会去字符串常量池中检查是否存在”AB”对象,如果不存在,则在字符串常量池中创建”AB”对象,并将”AB”对象的地址返回给s1;如果存在,则不创建任何对象,直接将字符串常量池中”AB”对象的地址返回给s1。
intern方法*
直接使用双引号声明出来的String对象会直接存储在字符串常量池中,如果不是用双引号声明的String对象,可以使用String提供的intern方法。intern 方法是一个native方法,intern方法会从字符串常量池中查询当前字符串是否存在,如果存在,就直接返回当前字符串;如果不存在就会将当前字符串放入常量池中,之后再返回。
JDK1.7的改动:
- 将String常量池 从 Perm 区移动到了 Java Heap区
- String.intern() 方法时,如果存在堆中的对象,会直接保存对象的引用,而不会重新创建对象。
/*** Returns a canonical representation for the string object.* <p>* A pool of strings, initially empty, is maintained privately by the* class {@code String}.* <p>* When the intern method is invoked, if the pool already contains a* string equal to this {@code String} object as determined by* the {@link #equals(Object)} method, then the string from the pool is* returned. Otherwise, this {@code String} object is added to the* pool and a reference to this {@code String} object is returned.* <p>* It follows that for any two strings {@code s} and {@code t},* {@code s.intern() == t.intern()} is {@code true}* if and only if {@code s.equals(t)} is {@code true}.* <p>* All literal strings and string-valued constant expressions are* interned. String literals are defined in section 3.10.5 of the* <cite>The Java™ Language Specification</cite>.** @return a string that has the same contents as this string, but is* guaranteed to be from a pool of unique strings.*/public native String intern();
intern的用法
static final int MAX = 1000 * 10000;static final String[] arr = new String[MAX];public static void main(String[] args) throws Exception {Integer[] DB_DATA = new Integer[10];Random random = new Random(10 * 10000);for (int i = 0; i < DB_DATA.length; i++) {DB_DATA[i] = random.nextInt();}long t = System.currentTimeMillis();for (int i = 0; i < MAX; i++) {//arr[i] = new String(String.valueOf(DB_DATA[i % DB_DATA.length]));arr[i] = new String(String.valueOf(DB_DATA[i % DB_DATA.length])).intern();}System.out.println((System.currentTimeMillis() - t) + "ms");System.gc();}
运行的参数是:-Xmx2g -Xms2g -Xmn1500M 上述代码是一个演示代码,其中有两条语句不一样,一条是未使用 intern,一条是使用 intern。结果如下图
未使用intern,耗时826ms: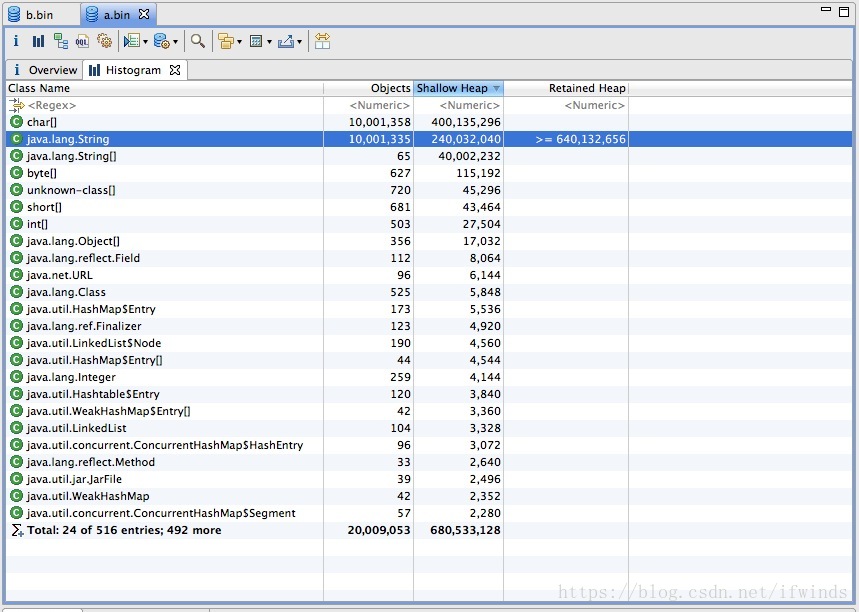
使用intern,耗时2160ms: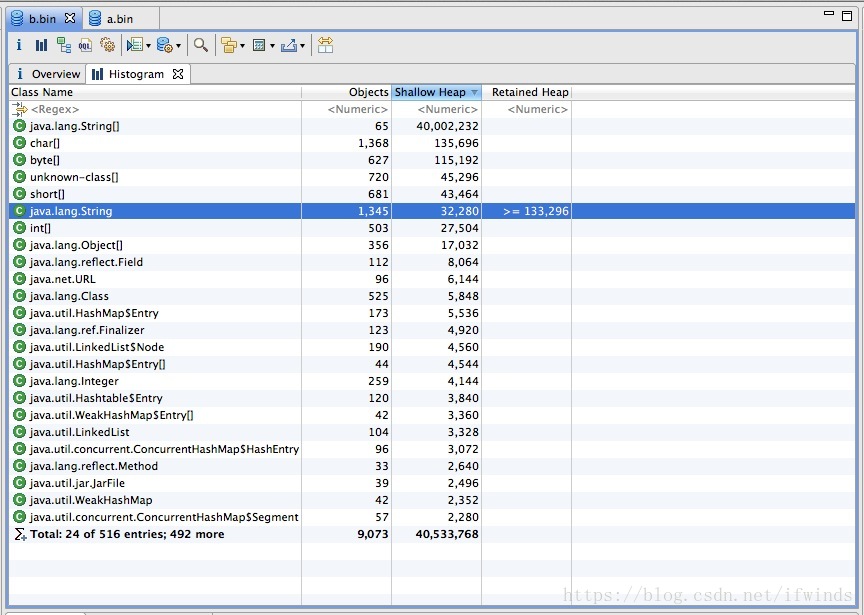
通过上述结果,我们发现不使用 intern 的代码生成了1000w 个字符串,占用了大约640m 空间。 使用了 intern 的代码生成了1345个字符串,占用总空间 133k 左右。其实通过观察程序中只是用到了10个字符串,所以准确计算后应该是正好相差100w 倍。虽然例子有些极端,但确实能准确反应出 intern 使用后产生的巨大空间节省。
细心的同学会发现使用了 intern 方法后时间上有了一些增长。这是因为程序中每次都是用了 new String 后,然后又进行 intern 操作的耗时时间,这一点如果在内存空间充足的情况下确实是无法避免的,但我们平时使用时,内存空间肯定不是无限大的,不使用 intern 占用空间导致 jvm 垃圾回收的时间是要远远大于这点时间的。 毕竟这里使用了1000w次intern 才多出来1秒钟多的时间。
String、StringBuilder和StringBuffer
继承结构
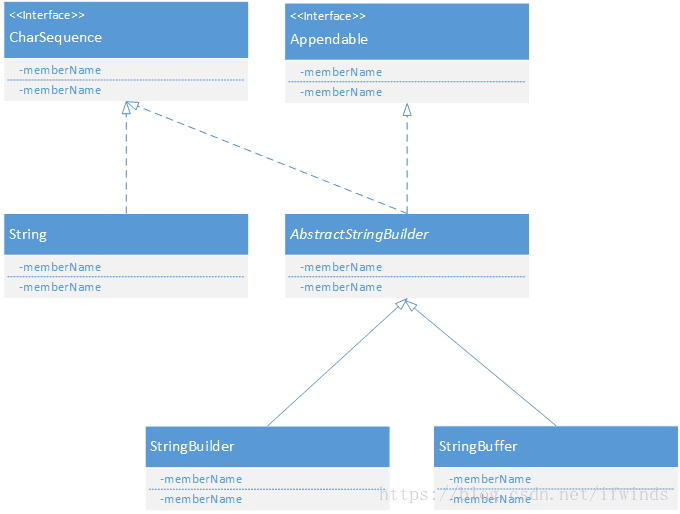
主要区别
1)String是不可变字符序列,StringBuilder和StringBuffer是可变字符序列。
2)执行速度StringBuilder > StringBuffer > String。
3)StringBuilder是非线程安全的,StringBuffer是线程安全的。
线程安全
首先就是:什么是线程 指路
StringBuffer:线程安全,StringBuilder:线程不安全。
因为 StringBuffer 的所有公开方法都是 synchronized 修饰的,而 StringBuilder 并没有 synchronized 修饰。
StringBuffer代码片段:@Overridepublic synchronized StringBuffer append(String str) {toStringCache = null;super.append(str);return this;}123456
关于两者的线程安全上的问题的具体原因可以参考这里
针对Synchronized关键字的原理可以参考这里:个人总结起来是这样的:通过对象监视器(monitor)基于底层操作系统的互斥锁(Mutex Lock)来实现了对方法、同步块的同步。缓冲区
StringBulider代码片段:private transient char[] toStringCache;@Overridepublic synchronized String toString() {if (toStringCache == null) {toStringCache = Arrays.copyOfRange(value, 0, count);}return new String(toStringCache, true);}12345678
StringBuilder代码片段
可以看出,StringBuffer 每次获取 toString 都会直接使用缓存区的 toStringCache 值来构造一个字符串。
而 StringBuilder 则每次都需要复制一次字符数组,再构造一个字符串。
所以,缓存冲这也是对 StringBuffer 的一个优化吧,不过 StringBuffer 的这个toString 方法仍然是同步的。性能
既然StringBuffer是线程安全的,他的所有公开方法都是同步的,StringBuilder是没有对方法加锁同步的,所以毫无疑问,StringBuilder的性能要远大于StringBuffer。
所以:
String:适用于少量的字符串操作的情况
StringBuilder:适用于单线程下在字符缓冲区进行大量操作的情况
StringBuffer:适用多线程下在字符缓冲区进行大量操作的情况
常用方法
StringBuffer s = new StringBuffer();
这样初始化出的StringBuffer对象是一个空的对象,
StringBuffer sb1=new StringBuffer(512);
分配了长度512字节的字符缓冲区。
StringBuffer sb2=new StringBuffer(“how are you?”)
创建带有内容的StringBuffer对象,在字符缓冲区中存放字符串“how are you?”
1、append方法
public StringBuffer append(boolean b)//该方法的作用是追加内容到当前StringBuffer对象的末尾,类似于字符串的连接,调用该方法以后,StringBuffer对象的内容也发生改 变,例如:StringBuffer sb = new StringBuffer(“abc”);sb.append(true);//则对象sb的值将变成”abctrue”//使用该方法进行字符串的连接,将比String更加节约内容,经常应用于数据库SQL语句的连接。
2、deleteCharAt方法
public StringBuffer deleteCharAt(int index)//该方法的作用是删除指定位置的字符,然后将剩余的内容形成新的字符串。例如:StringBuffer sb = new StringBuffer(“KMing”);sb. deleteCharAt(1);//该代码的作用删除字符串对象sb中索引值为1的字符,也就是删除第二个字符,剩余的内容组成一个新的字符串。所以对象sb的值变 为”King”。//还存在一个功能类似的delete方法:public StringBuffer delete(int start,int end)//该方法的作用是删除指定区间以内的所有字符,包含start,不包含end索引值的区间。例如:StringBuffer sb = new StringBuffer(“TestString”);sb. delete (1,4);//该代码的作用是删除索引值1(包括)到索引值4(不包括)之间的所有字符,剩余的字符形成新的字符串。则对象sb的值是”TString”。
3、insert方法
public StringBuffer insert(int offset, boolean b),//该方法的作用是在StringBuffer对象中插入内容,然后形成新的字符串。例如:StringBuffer sb = new StringBuffer(“TestString”);sb.insert(4,false);//该示例代码的作用是在对象sb的索引值4的位置插入false值,形成新的字符串,则执行以后对象sb的值是”TestfalseString”。
4、reverse方法
public StringBuffer reverse()//该方法的作用是将StringBuffer对象中的内容反转,然后形成新的字符串。例如:StringBuffer sb = new StringBuffer(“abc”);sb.reverse();//经过反转以后,对象sb中的内容将变为”cba”。
5、setCharAt方法
public void setCharAt(int index, char ch)该方法的作用是修改对象中索引值为index位置的字符为新的字符ch。例如:StringBuffer sb = new StringBuffer(“abc”);sb.setCharAt(1,’D’);则对象sb的值将变成”aDc”。
6、trimToSize方法
public void trimToSize()该方法的作用是将StringBuffer对象的中存储空间缩小到和字符串长度一样的长度,减少空间的浪费,和String的trim()是一样的作用
7、length方法
该方法的作用是获取字符串长度
8、setlength方法
//该方法的作用是设置字符串缓冲区大小。StringBuffer sb=new StringBuffer();sb.setlength(100);//如果用小于当前字符串长度的值调用setlength()方法,则新长度后面的字符将丢失。
9、sb.capacity方法
//该方法的作用是获取字符串的容量。StringBuffer sb=new StringBuffer(“string”);int i=sb.capacity();
10、ensureCapacity方法
该方法的作用是重新设置字符串容量的大小。StringBuffer sb=new StringBuffer();sb.ensureCapacity(32); //预先设置sb的容量为32
11、getChars方法
该方法的作用是将字符串的子字符串复制给数组。getChars(int start,int end,char chars[],int charStart);StringBuffer sb = new StringBuffer(“I love You”);int begin = 0;int end = 5;//注意ch字符数组的长度一定要大于等于begin到end之间字符的长度//小于的话会报ArrayIndexOutOfBoundsException//如果大于的话,大于的字符会以空格补齐char[] ch = new char[end-begin];sb.getChars(begin, end, ch, 0);System.out.println(ch);结果:I lov
总结
String类是我们使用频率最高的类之一,也是面试官经常考察的题目,下面是一个小测验。
public static void main(String[] args) {String s1 = "AB";String s2 = new String("AB");String s3 = "A";String s4 = "B";String s5 = "A" + "B";String s6 = s3 + s4;System.out.println(s1 == s2);System.out.println(s1 == s5);System.out.println(s1 == s6);System.out.println(s1 == s6.intern());System.out.println(s2 == s2.intern());}
运行结果:
解析:真正理解此题目需要清楚以下三点
1)直接使用双引号声明出来的String对象会直接存储在常量池中;
2)String对象的intern方法会得到字符串对象在常量池中对应的引用,如果常量池中没有对应的字符串,则该字符串将被添加到常量池中,然后返回常量池中字符串的引用;
3) 字符串的+操作其本质是创建了StringBuilder对象进行append操作,然后将拼接后的StringBuilder对象用toString方法处理成String对象,这一点可以用javap -c命令获得class文件对应的JVM字节码指令就可以看出来。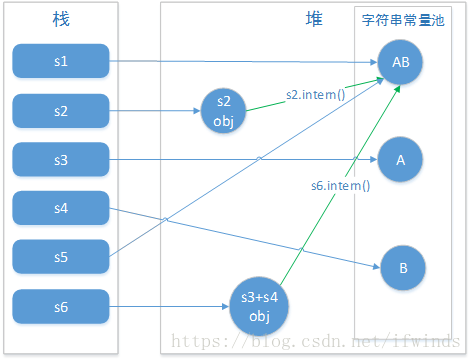
ATM系统
常用API
Object
- toString
- equals
Objects
- equals
- isNull
Math
- public static int abs (int a) 获取参数绝对值
- public static double ceil (double a) 向上取整
- public static double floor (double a) 向下取整
- public static int round (float a) 四舍五入
- public static int max (int a,int b) 获取两个int值中的较大值
- public static double pow (double a,double b) 返回a的b次幂的值
- public static double random () 返回值为double的随机值,范围[0.0,1.0)
System
- public static void exit(int status) 终止当前运行的Java虚拟机,非零表示异常终止
- public static long currentTimeMillis() 返回当前系统的时间毫秒值形式
- public static void arraycopy(数据源数组, 起始索引, 目的地数组, 起始索引, 拷贝个数)
BigDecimal
- 作用
- 获取对象
- BigDecimal b1 = BigDecimal.valueOf(0.1)
- 方法
- public BigDecimal add(BigDecimal b)
- public BigDecimal subtract(BigDecimal b)
- public BigDecimal multiply(BigDecimal b)
- public BigDecimal divide(BigDecimal b)
- public BigDecimal divide (另一个BigDecimal对象,精确几位,舍入模式) 除法
日期与时间
date
public static void main(String[] args) {// 1、创建一个Date类的对象:代表系统此刻日期时间对象Date d = new Date();System.out.println(d);// 2、获取时间毫秒值long time = d.getTime();System.out.println(time);System.out.println("----------------------------");// 1、得到当前时间Date d1 = new Date();System.out.println(d1);// 2、当前时间往后走 1小时 121slong time2 = System.currentTimeMillis();time2 += (60 * 60 + 121) * 1000;// 3、把时间毫秒值转换成对应的日期对象。// Date d2 = new Date(time2);// System.out.println(d2);Date d3 = new Date();d3.setTime(time2);System.out.println(d3);}
- SimpleDate ```java SimpleDateFormat函数的继承关系:
java.lang.Object | +——java.text.Format | +——java.text.DateFormat | +——java.text.SimpleDateFormat
下面一个小例子:
import java.text.*; import java.util.Date;
/** SimpleDateFormat函数语法:
G 年代标志符 y 年 M 月 d 日 h 时 在上午或下午 (1~12) H 时 在一天中 (0~23) m 分 s 秒 S 毫秒 E 星期 D 一年中的第几天 F 一月中第几个星期几 w 一年中第几个星期 W 一月中第几个星期 a 上午 / 下午 标记符 k 时 在一天中 (1~24) K 时 在上午或下午 (0~11) z 时区 */ public class FormatDateTime {
public static void main(String[] args) {SimpleDateFormat myFmt=new SimpleDateFormat("yyyy年MM月dd日 HH时mm分ss秒");SimpleDateFormat myFmt1=new SimpleDateFormat("yy/MM/dd HH:mm");SimpleDateFormat myFmt2=new SimpleDateFormat("yyyy-MM-dd HH:mm:ss");//等价于now.toLocaleString()SimpleDateFormat myFmt3=new SimpleDateFormat("yyyy年MM月dd日 HH时mm分ss秒 E ");SimpleDateFormat myFmt4=new SimpleDateFormat("一年中的第 D 天 一年中第w个星期 一月中第W个星期 在一天中k时 z时区");Date now=new Date();System.out.println(myFmt.format(now));System.out.println(myFmt1.format(now));System.out.println(myFmt2.format(now));System.out.println(myFmt3.format(now));System.out.println(myFmt4.format(now));System.out.println(now.toGMTString());System.out.println(now.toLocaleString());System.out.println(now.toString());}
}
效果: 2017年10月17日 20时57分00秒 17/10/17 20:57 2017-10-17 20:57:00 2017年10月17日 20时57分00秒 星期二 一年中的第 290 天 一年中第42个星期 一月中第3个星期 在一天中20时 CST时区 17 Oct 2017 12:57:00 GMT 2017-10-17 20:57:00 Tue Oct 17 20:57:00 CST 2017
- Calendar```java/**目标:日历类Calendar的使用,可以得到更加丰富的信息。Calendar代表了系统此刻日期对应的日历对象。Calendar是一个抽象类,不能直接创建对象。Calendar日历类创建日历对象的语法:Calendar rightNow = Calendar.getInstance();Calendar的方法:1.public static Calendar getInstance(): 返回一个日历类的对象。2.public int get(int field):取日期中的某个字段信息。3.public void set(int field,int value):修改日历的某个字段信息。4.public void add(int field,int amount):为某个字段增加/减少指定的值5.public final Date getTime(): 拿到此刻日期对象。6.public long getTimeInMillis(): 拿到此刻时间毫秒值小结:记住。*/public class CalendarDemo{public static void main(String[] args) {// 1、拿到系统此刻日历对象Calendar cal = Calendar.getInstance();System.out.println(cal);// 2、获取日历的信息:public int get(int field):取日期中的某个字段信息。int year = cal.get(Calendar.YEAR);System.out.println(year);int mm = cal.get(Calendar.MONTH) + 1;System.out.println(mm);int days = cal.get(Calendar.DAY_OF_YEAR) ;System.out.println(days);// 3、public void set(int field,int value):修改日历的某个字段信息。// cal.set(Calendar.HOUR , 12);// System.out.println(cal);// 4.public void add(int field,int amount):为某个字段增加/减少指定的值// 请问64天后是什么时间cal.add(Calendar.DAY_OF_YEAR , 64);cal.add(Calendar.MINUTE , 59);// 5.public final Date getTime(): 拿到此刻日期对象。Date d = cal.getTime();System.out.println(d);// 6.public long getTimeInMillis(): 拿到此刻时间毫秒值long time = cal.getTimeInMillis();System.out.println(time);}}
UTC
协调世界时(Coordinated Universal Time)又称世界统一时间、世界标准时间,由于英文(CUT)和法文(TUC)的缩写不同,作为妥协,简称UTC。
时区
由于世界各国家与地区经度不同,地方时也有所不同,因此会划分为不同的时区
地球是自西向东自转,东边比西边先看到太阳,东边的时间也比西边的早。东边时刻与西边时刻的差值不仅要以时计,而且还要以分和秒来计算,这给人们带来不便
为了克服时间上的混乱,1884年在华盛顿召开的一次国际经度会议(又称国际子午线会议)上,规定将全球划分为24个时区(东、西各12个时区)。规定英国(格林尼治天文台旧址)为中时区(零时区)、东1—12区,西1—12区。每个时区横跨经度15度,时间正好是1小时。最后的东、西第12区各跨经度7.5度,以东、西经180度为界。每个时区的中央经线上的时间就是这个时区内统一采用的时间,称为区时,相邻两个时区的时间相差1小时 《摘自百度百科》
因为北京属于东8区,所以需要在世界统一时间(UTC)的基础上加8小时
java.time包简介
java.time包主要提供了日期、时间、瞬间、持续时间的api
主要的日期时间概念,包括时刻,持续时间,日期,时间,时区和时段。 基于ISO日历系统,所有的类都是不可变的,线程安全的
按类型主要分为:
- 日期和时间
- Instant本质上是一个数字时间戳。
- LocalDate存储没有时间的日期,如2010-07-09
- LocalTime 存储没有日期的时间,如22:18
- LocalDateTime 存储日期和时间。如2020-07-09T22:18
- ZonedDateTime 存储带时区的日期和时间
- 期限
- Duration 存储期间和持续时间。以纳秒为单位的时间线的简单测量
- 附加的类型
- Month 存储一个月。如“十一月”
- DayOfWeek 存储一周中的一天,如“Tuesday”
- Year 存储年,如“2020”
- YearMonth 存储年和月,如“2020-10”,可用于信用卡上的到期
- MonthDay 存储月和日,如“12-14”,可用于存储生日
- OffsetTime 存储与UTC没有日期的时间和偏移量
- OffsetDateTime存储与UTC的日期时间和偏移量
下面来分别看一下各自的用法
Instant
Instant表示的是时间线上的瞬间点,本质上就是时间戳
Instant instant = Instant.now();//默认时间比北京时间相差8小时System.out.println(instant);// 2020-07-10T12:52:56.053Z//设置时区后,显示正常时间System.out.println(instant.atZone(ZoneId.systemDefault()));//2020-07-10T20:52:56.053+08:00[Asia/Shanghai]//获取当前时间戳的秒数System.out.println(instant.getEpochSecond());//获取当前时间戳的毫秒System.out.println(instant.toEpochMilli());//Date类型转换为InstantInstant instant1 = Instant.ofEpochMilli(new Date().getTime());System.out.println(instant1);//将字符串转换成InstantInstant instant2 = Instant.parse("2020-07-10T12:52:56.053Z");System.out.println(instant2);//将Clock转换成InstantInstant instant3 = Instant.now(Clock.systemUTC());System.out.println(instant3);//加3小时,注意加操作对instant对象本身来说没有影响System.out.println(instant.plus(3, ChronoUnit.HOURS)); //2020-07-10T16:32:16.570ZSystem.out.println(instant);//2020-07-10T13:32:16.570ZInstant ins1 = Instant.parse("2020-07-10T12:52:56.053Z");Instant ins2 = Instant.parse("2020-07-10T12:52:46.034Z");//时间戳比较System.out.println(ins1.isAfter(ins2));System.out.println(ins1.isBefore(ins2));12345678910111213141516171819202122232425262728293031
LocalDate
LocalDate是一个不可变的日期时间对象,存储没有时间的日期
LocalDate localDate = LocalDate.now();System.out.println(localDate); //2020-07-10//Clock转换成LocalDateLocalDate localDate1 = LocalDate.now(Clock.systemDefaultZone());System.out.println(localDate1); //2020-07-10//指定年月日的LocalDateLocalDate localDate2 = LocalDate.of(2020,5,1);System.out.println(localDate2); //2020-05-01//字符串转换成LocalDateLocalDate localDate3 = LocalDate.parse("2020-05-04");System.out.println(localDate3); //2020-05-04//指定格式化规则的转换LocalDate localDate4 = LocalDate.parse("20200205",DateTimeFormatter.ofPattern("yyyyMMdd"));System.out.println(localDate4); //2020-02-05//2020年的第100天LocalDate localDate5 = LocalDate.ofYearDay(2020,100);System.out.println(localDate5); //2020-04-09//加4天System.out.println(localDate.plusDays(4)); // 2020-07-14System.out.println(localDate.plus(4,ChronoUnit.DAYS)); // 2020-07-14//两周后System.out.println(localDate.plusWeeks(2)); //2020-07-24//两月后System.out.println(localDate.plusMonths(2)); //2020-09-10//两年后System.out.println(localDate.plusYears(2)); //2022-07-10//3天前System.out.println(localDate.plusDays(-3));// 2020-07-07System.out.println(localDate.minusDays(3));//2020-07-07//4天后是星期几System.out.println(localDate.plusDays(4).getDayOfWeek()); //TUESDAY//localDate所代表的日期是当月的第几天System.out.println(localDate.getDayOfMonth());//localDate所代表的日期是今年的第多少天System.out.println(localDate.getDayOfYear());//日期格式化System.out.println(localDate.format(DateTimeFormatter.ofPattern("yyyy/MM/dd"))); //2020/07/10//是否闰年System.out.println(localDate.isLeapYear());//当月有多少天System.out.println(localDate.lengthOfMonth());//当年有多少天System.out.println(localDate.lengthOfYear());123456789101112131415161718192021222324252627282930313233343536373839404142434445464748495051
LocalTime
LocalTime是一个不可变的日期时间对象,存储没有日期的时间
LocalTime localTime = LocalTime.now();System.out.println(localTime); //22:42:42.520//时:分System.out.println(LocalTime.of(12,11)); // 12:11//时:分:秒System.out.println(LocalTime.of(12,11,45)); //12:11:45//加2小时System.out.println(localTime.plusHours(2)); //12:11:45...//LocalTime的很多方法和操作跟LocalDate都是一样的,这里不再赘述1234567891011
LocalDateTime
LocalDateTime是一个不可变的日期时间对象,代表日期时间
LocalDateTime localDateTime = LocalDateTime.now();System.out.println(localDateTime); //2020-07-10T22:52:33.898//日期时间格式化System.out.println(localDateTime.format(DateTimeFormatter.ofPattern("yyyy-MM-dd hh:mm:ss")));//10天后是星期几System.out.println(localDateTime.plusDays(10).getDayOfWeek());//17分钟后System.out.println(localDateTime.plusMinutes(17));123456789
LocalDateTime相当于是结合了LocalDate和LocalTime,方法和功能也都是一样的
ZonedDateTime
ZonedDateTime是具有时区的日期时间的不可变表示
ZonedDateTime zonedDateTime = ZonedDateTime.now();System.out.println(zonedDateTime); //2020-07-10T22:57:05.830+08:00[Asia/Shanghai]//转换成LocalDateSystem.out.println(zonedDateTime.toLocalDate()); //2020-07-10//转换成LocalDateTimeSystem.out.println(zonedDateTime.toLocalDateTime());//2020-07-10T22:59:09.501//转换成LocalTimeSystem.out.println(zonedDateTime.toLocalTime());//22:59:09.501//加3天System.out.println(zonedDateTime.plusDays(3));//2020-07-13T23:00:07.716+08:00[Asia/Shanghai]//格式化System.out.println(zonedDateTime.format(DateTimeFormatter.ofPattern("yyyy-MM-dd hh:mm:ss")));//其他方式请参考 locateDate 和 localTime1234567891011121314
Duration
Duration描述的其实是时长,表示一个时间区间
//定义5天Duration duration = Duration.of(5,ChronoUnit.DAYS);System.out.println(duration); //PT120H//3小时System.out.println(Duration.ofHours(3)); //PT3H//输出小时System.out.println(Duration.of(5,ChronoUnit.DAYS).toHours());//加8小时(5天8小时)System.out.println(duration.plusHours(8).toHours()); //128123456789
其他类型
上面已经介绍了常用的日期时间类型的使用,基本上日常的使用通过上面的几个类就够用了,其他类型(Month、DayOfWeek、Year、YearMonth、MonthDay、OffsetTime、OffsetDateTime)的用法都是大同小异,看一下api基本都会了
总结
从上面一些类的用法,可以看出JDK1.8对日期时间类的处理定义了很多类,用来表示不同的日期时间使用场景,基本上我们常用到的场景,都有定义不同的类,通过这些类可以很方便的操作日期和时间。
前人总结/*** Java8日期时间工具类** @author JourWon* @date 2020/12/13*/public class LocalDateUtils {/*** 显示年月日时分秒,例如 2015-08-11 09:51:53.*/public static final String DATETIME_PATTERN = "yyyy-MM-dd HH:mm:ss";/*** 仅显示年月日,例如 2015-08-11.*/public static final String DATE_PATTERN = "yyyy-MM-dd";/*** 仅显示时分秒,例如 09:51:53.*/public static final String TIME_PATTERN = "HH:mm:ss";/*** 显示年月日时分秒(无符号),例如 20150811095153.*/public static final String UNSIGNED_DATETIME_PATTERN = "yyyyMMddHHmmss";/*** 仅显示年月日(无符号),例如 20150811.*/public static final String UNSIGNED_DATE_PATTERN = "yyyyMMdd";/*** 春天;*/public static final Integer SPRING = 1;/*** 夏天;*/public static final Integer SUMMER = 2;/*** 秋天;*/public static final Integer AUTUMN = 3;/*** 冬天;*/public static final Integer WINTER = 4;/*** 星期日;*/public static final String SUNDAY = "星期日";/*** 星期一;*/public static final String MONDAY = "星期一";/*** 星期二;*/public static final String TUESDAY = "星期二";/*** 星期三;*/public static final String WEDNESDAY = "星期三";/*** 星期四;*/public static final String THURSDAY = "星期四";/*** 星期五;*/public static final String FRIDAY = "星期五";/*** 星期六;*/public static final String SATURDAY = "星期六";/*** 年*/private static final String YEAR = "year";/*** 月*/private static final String MONTH = "month";/*** 周*/private static final String WEEK = "week";/*** 日*/private static final String DAY = "day";/*** 时*/private static final String HOUR = "hour";/*** 分*/private static final String MINUTE = "minute";/*** 秒*/private static final String SECOND = "second";/*** 获取当前日期和时间字符串.** @return String 日期时间字符串,例如 2015-08-11 09:51:53*/public static String getLocalDateTimeStr() {return format(LocalDateTime.now(), DATETIME_PATTERN);}/*** 获取当前日期字符串.** @return String 日期字符串,例如2015-08-11*/public static String getLocalDateStr() {return format(LocalDate.now(), DATE_PATTERN);}/*** 获取当前时间字符串.** @return String 时间字符串,例如 09:51:53*/public static String getLocalTimeStr() {return format(LocalTime.now(), TIME_PATTERN);}/*** 获取当前星期字符串.** @return String 当前星期字符串,例如 星期二*/public static String getDayOfWeekStr() {return format(LocalDate.now(), "E");}/*** 获取指定日期是星期几** @param localDate 日期* @return String 星期几*/public static String getDayOfWeekStr(LocalDate localDate) {String[] weekOfDays = {MONDAY, TUESDAY, WEDNESDAY, THURSDAY, FRIDAY, SATURDAY, SUNDAY};int dayOfWeek = localDate.getDayOfWeek().getValue() - 1;return weekOfDays[dayOfWeek];}/*** 获取日期时间字符串** @param temporal 需要转化的日期时间* @param pattern 时间格式* @return String 日期时间字符串,例如 2015-08-11 09:51:53*/public static String format(TemporalAccessor temporal, String pattern) {DateTimeFormatter dateTimeFormatter = DateTimeFormatter.ofPattern(pattern);return dateTimeFormatter.format(temporal);}/*** 日期时间字符串转换为日期时间(java.time.LocalDateTime)** @param localDateTimeStr 日期时间字符串* @param pattern 日期时间格式 例如DATETIME_PATTERN* @return LocalDateTime 日期时间*/public static LocalDateTime parseLocalDateTime(String localDateTimeStr, String pattern) {DateTimeFormatter dateTimeFormatter = DateTimeFormatter.ofPattern(pattern);return LocalDateTime.parse(localDateTimeStr, dateTimeFormatter);}/*** 日期字符串转换为日期(java.time.LocalDate)** @param localDateStr 日期字符串* @param pattern 日期格式 例如DATE_PATTERN* @return LocalDate 日期*/public static LocalDate parseLocalDate(String localDateStr, String pattern) {DateTimeFormatter dateTimeFormatter = DateTimeFormatter.ofPattern(pattern);return LocalDate.parse(localDateStr, dateTimeFormatter);}/*** 获取指定日期时间加上指定数量日期时间单位之后的日期时间.** @param localDateTime 日期时间* @param num 数量* @param chronoUnit 日期时间单位* @return LocalDateTime 新的日期时间*/public static LocalDateTime plus(LocalDateTime localDateTime, int num, ChronoUnit chronoUnit) {return localDateTime.plus(num, chronoUnit);}/*** 获取指定日期时间减去指定数量日期时间单位之后的日期时间.** @param localDateTime 日期时间* @param num 数量* @param chronoUnit 日期时间单位* @return LocalDateTime 新的日期时间*/public static LocalDateTime minus(LocalDateTime localDateTime, int num, ChronoUnit chronoUnit) {return localDateTime.minus(num, chronoUnit);}/*** 根据ChronoUnit计算两个日期时间之间相隔日期时间** @param start 开始日期时间* @param end 结束日期时间* @param chronoUnit 日期时间单位* @return long 相隔日期时间*/public static long getChronoUnitBetween(LocalDateTime start, LocalDateTime end, ChronoUnit chronoUnit) {return Math.abs(start.until(end, chronoUnit));}/*** 根据ChronoUnit计算两个日期之间相隔年数或月数或天数** @param start 开始日期* @param end 结束日期* @param chronoUnit 日期时间单位,(ChronoUnit.YEARS,ChronoUnit.MONTHS,ChronoUnit.WEEKS,ChronoUnit.DAYS)* @return long 相隔年数或月数或天数*/public static long getChronoUnitBetween(LocalDate start, LocalDate end, ChronoUnit chronoUnit) {return Math.abs(start.until(end, chronoUnit));}/*** 获取本年第一天的日期字符串** @return String 格式:yyyy-MM-dd 00:00:00*/public static String getFirstDayOfYearStr() {return getFirstDayOfYearStr(LocalDateTime.now());}/*** 获取本年最后一天的日期字符串** @return String 格式:yyyy-MM-dd 23:59:59*/public static String getLastDayOfYearStr() {return getLastDayOfYearStr(LocalDateTime.now());}/*** 获取指定日期当年第一天的日期字符串** @param localDateTime 指定日期时间* @return String 格式:yyyy-MM-dd 00:00:00*/public static String getFirstDayOfYearStr(LocalDateTime localDateTime) {return getFirstDayOfYearStr(localDateTime, DATETIME_PATTERN);}/*** 获取指定日期当年最后一天的日期字符串** @param localDateTime 指定日期时间* @return String 格式:yyyy-MM-dd 23:59:59*/public static String getLastDayOfYearStr(LocalDateTime localDateTime) {return getLastDayOfYearStr(localDateTime, DATETIME_PATTERN);}/*** 获取指定日期当年第一天的日期字符串,带日期格式化参数** @param localDateTime 指定日期时间* @param pattern 日期时间格式* @return String 格式:yyyy-MM-dd 00:00:00*/public static String getFirstDayOfYearStr(LocalDateTime localDateTime, String pattern) {return format(localDateTime.withDayOfYear(1).withHour(0).withMinute(0).withSecond(0), pattern);}/*** 获取指定日期当年最后一天的日期字符串,带日期格式化参数** @param localDateTime 指定日期时间* @param pattern 日期时间格式* @return String 格式:yyyy-MM-dd 23:59:59*/public static String getLastDayOfYearStr(LocalDateTime localDateTime, String pattern) {return format(localDateTime.with(TemporalAdjusters.lastDayOfYear()).withHour(23).withMinute(59).withSecond(59), pattern);}/*** 获取本月第一天的日期字符串** @return String 格式:yyyy-MM-dd 00:00:00*/public static String getFirstDayOfMonthStr() {return getFirstDayOfMonthStr(LocalDateTime.now());}/*** 获取本月最后一天的日期字符串** @return String 格式:yyyy-MM-dd 23:59:59*/public static String getLastDayOfMonthStr() {return getLastDayOfMonthStr(LocalDateTime.now());}/*** 获取指定日期当月第一天的日期字符串** @param localDateTime 指定日期时间* @return String 格式:yyyy-MM-dd 23:59:59*/public static String getFirstDayOfMonthStr(LocalDateTime localDateTime) {return getFirstDayOfMonthStr(localDateTime, DATETIME_PATTERN);}/*** 获取指定日期当月最后一天的日期字符串** @param localDateTime 指定日期时间* @return String 格式:yyyy-MM-dd 23:59:59*/public static String getLastDayOfMonthStr(LocalDateTime localDateTime) {return getLastDayOfMonthStr(localDateTime, DATETIME_PATTERN);}/*** 获取指定日期当月第一天的日期字符串,带日期格式化参数** @param localDateTime 指定日期时间* @return String 格式:yyyy-MM-dd 00:00:00*/public static String getFirstDayOfMonthStr(LocalDateTime localDateTime, String pattern) {return format(localDateTime.withDayOfMonth(1).withHour(0).withMinute(0).withSecond(0), pattern);}/*** 获取指定日期当月最后一天的日期字符串,带日期格式化参数** @param localDateTime 指定日期时间* @param pattern 日期时间格式* @return String 格式:yyyy-MM-dd 23:59:59*/public static String getLastDayOfMonthStr(LocalDateTime localDateTime, String pattern) {return format(localDateTime.with(TemporalAdjusters.lastDayOfMonth()).withHour(23).withMinute(59).withSecond(59), pattern);}/*** 获取本周第一天的日期字符串** @return String 格式:yyyy-MM-dd 00:00:00*/public static String getFirstDayOfWeekStr() {return getFirstDayOfWeekStr(LocalDateTime.now());}/*** 获取本周最后一天的日期字符串** @return String 格式:yyyy-MM-dd 23:59:59*/public static String getLastDayOfWeekStr() {return getLastDayOfWeekStr(LocalDateTime.now());}/*** 获取指定日期当周第一天的日期字符串,这里第一天为周一** @param localDateTime 指定日期时间* @return String 格式:yyyy-MM-dd 00:00:00*/public static String getFirstDayOfWeekStr(LocalDateTime localDateTime) {return getFirstDayOfWeekStr(localDateTime, DATETIME_PATTERN);}/*** 获取指定日期当周最后一天的日期字符串,这里最后一天为周日** @param localDateTime 指定日期时间* @return String 格式:yyyy-MM-dd 23:59:59*/public static String getLastDayOfWeekStr(LocalDateTime localDateTime) {return getLastDayOfWeekStr(localDateTime, DATETIME_PATTERN);}/*** 获取指定日期当周第一天的日期字符串,这里第一天为周一,带日期格式化参数** @param localDateTime 指定日期时间* @param pattern 日期时间格式* @return String 格式:yyyy-MM-dd 00:00:00*/public static String getFirstDayOfWeekStr(LocalDateTime localDateTime, String pattern) {return format(localDateTime.with(DayOfWeek.MONDAY).withHour(0).withMinute(0).withSecond(0), pattern);}/*** 获取指定日期当周最后一天的日期字符串,这里最后一天为周日,带日期格式化参数** @param localDateTime 指定日期时间* @param pattern 日期时间格式* @return String 格式:yyyy-MM-dd 23:59:59*/public static String getLastDayOfWeekStr(LocalDateTime localDateTime, String pattern) {return format(localDateTime.with(DayOfWeek.SUNDAY).withHour(23).withMinute(59).withSecond(59), pattern);}/*** 获取今天开始时间的日期字符串** @return String 格式:yyyy-MM-dd 00:00:00*/public static String getStartTimeOfDayStr() {return getStartTimeOfDayStr(LocalDateTime.now());}/*** 获取今天结束时间的日期字符串** @return String 格式:yyyy-MM-dd 23:59:59*/public static String getEndTimeOfDayStr() {return getEndTimeOfDayStr(LocalDateTime.now());}/*** 获取指定日期开始时间的日期字符串** @param localDateTime 指定日期时间* @return String 格式:yyyy-MM-dd 00:00:00*/public static String getStartTimeOfDayStr(LocalDateTime localDateTime) {return getStartTimeOfDayStr(localDateTime, DATETIME_PATTERN);}/*** 获取指定日期结束时间的日期字符串** @param localDateTime 指定日期时间* @return String 格式:yyyy-MM-dd 23:59:59*/public static String getEndTimeOfDayStr(LocalDateTime localDateTime) {return getEndTimeOfDayStr(localDateTime, DATETIME_PATTERN);}/*** 获取指定日期开始时间的日期字符串,带日期格式化参数** @param localDateTime 指定日期时间* @param pattern 日期时间格式* @return String 格式:yyyy-MM-dd HH:mm:ss*/public static String getStartTimeOfDayStr(LocalDateTime localDateTime, String pattern) {return format(localDateTime.withHour(0).withMinute(0).withSecond(0), pattern);}/*** 获取指定日期结束时间的日期字符串,带日期格式化参数** @param localDateTime 指定日期时间* @param pattern 日期时间格式* @return String 格式:yyyy-MM-dd 23:59:59*/public static String getEndTimeOfDayStr(LocalDateTime localDateTime, String pattern) {return format(localDateTime.withHour(23).withMinute(59).withSecond(59), pattern);}/*** 切割日期。按照周期切割成小段日期段。例如: <br>** @param startDate 开始日期(yyyy-MM-dd)* @param endDate 结束日期(yyyy-MM-dd)* @param period 周期(天,周,月,年)* @return 切割之后的日期集合* <li>startDate="2019-02-28",endDate="2019-03-05",period="day"</li>* <li>结果为:[2019-02-28, 2019-03-01, 2019-03-02, 2019-03-03, 2019-03-04, 2019-03-05]</li><br>* <li>startDate="2019-02-28",endDate="2019-03-25",period="week"</li>* <li>结果为:[2019-02-28,2019-03-06, 2019-03-07,2019-03-13, 2019-03-14,2019-03-20,* 2019-03-21,2019-03-25]</li><br>* <li>startDate="2019-02-28",endDate="2019-05-25",period="month"</li>* <li>结果为:[2019-02-28,2019-02-28, 2019-03-01,2019-03-31, 2019-04-01,2019-04-30,* 2019-05-01,2019-05-25]</li><br>* <li>startDate="2019-02-28",endDate="2020-05-25",period="year"</li>* <li>结果为:[2019-02-28,2019-12-31, 2020-01-01,2020-05-25]</li><br>*/public static List<String> listDateStrs(String startDate, String endDate, String period) {List<String> result = new ArrayList<>();DateTimeFormatter dateTimeFormatter = DateTimeFormatter.ofPattern(DATE_PATTERN);LocalDate end = LocalDate.parse(endDate, dateTimeFormatter);LocalDate start = LocalDate.parse(startDate, dateTimeFormatter);LocalDate tmp = start;switch (period) {case DAY:while (start.isBefore(end) || start.isEqual(end)) {result.add(start.toString());start = start.plusDays(1);}break;case WEEK:while (tmp.isBefore(end) || tmp.isEqual(end)) {if (tmp.plusDays(6).isAfter(end)) {result.add(tmp.toString() + "," + end);} else {result.add(tmp.toString() + "," + tmp.plusDays(6));}tmp = tmp.plusDays(7);}break;case MONTH:while (tmp.isBefore(end) || tmp.isEqual(end)) {LocalDate lastDayOfMonth = tmp.with(TemporalAdjusters.lastDayOfMonth());if (lastDayOfMonth.isAfter(end)) {result.add(tmp.toString() + "," + end);} else {result.add(tmp.toString() + "," + lastDayOfMonth);}tmp = lastDayOfMonth.plusDays(1);}break;case YEAR:while (tmp.isBefore(end) || tmp.isEqual(end)) {LocalDate lastDayOfYear = tmp.with(TemporalAdjusters.lastDayOfYear());if (lastDayOfYear.isAfter(end)) {result.add(tmp.toString() + "," + end);} else {result.add(tmp.toString() + "," + lastDayOfYear);}tmp = lastDayOfYear.plusDays(1);}break;default:break;}return result;}public static void main(String[] args) {System.out.println(getLocalDateTimeStr());System.out.println(getLocalDateStr());System.out.println(getLocalTimeStr());System.out.println(getDayOfWeekStr());System.out.println(getDayOfWeekStr(LocalDate.now()));System.out.println("========");System.out.println(format(LocalDate.now(), UNSIGNED_DATE_PATTERN));System.out.println("========");System.out.println(parseLocalDateTime("2020-12-13 11:14:12", DATETIME_PATTERN));System.out.println(parseLocalDate("2020-12-13", DATE_PATTERN));System.out.println("========");System.out.println(plus(LocalDateTime.now(), 3, ChronoUnit.HOURS));System.out.println(minus(LocalDateTime.now(), 4, ChronoUnit.DAYS));System.out.println("========");System.out.println(getChronoUnitBetween(LocalDateTime.now(), parseLocalDateTime("2020-12-12 12:03:12", DATETIME_PATTERN), ChronoUnit.MINUTES));System.out.println(getChronoUnitBetween(LocalDate.now(), parseLocalDate("2021-12-12", DATE_PATTERN), ChronoUnit.WEEKS));System.out.println("========");System.out.println(getFirstDayOfYearStr());System.out.println(getFirstDayOfYearStr(parseLocalDateTime("2021-12-12 12:03:12", DATETIME_PATTERN)));System.out.println(getFirstDayOfYearStr(parseLocalDateTime("2021-12-12 12:03:12", DATETIME_PATTERN), UNSIGNED_DATETIME_PATTERN));System.out.println(getLastDayOfYearStr());System.out.println(getLastDayOfYearStr(parseLocalDateTime("2021-12-12 12:03:12", DATETIME_PATTERN)));System.out.println(getLastDayOfYearStr(parseLocalDateTime("2021-12-12 12:03:12", DATETIME_PATTERN), UNSIGNED_DATETIME_PATTERN));System.out.println("========");System.out.println(getFirstDayOfMonthStr());System.out.println(getFirstDayOfMonthStr(parseLocalDateTime("2021-12-12 12:03:12", DATETIME_PATTERN)));System.out.println(getFirstDayOfMonthStr(parseLocalDateTime("2021-12-12 12:03:12", DATETIME_PATTERN), UNSIGNED_DATETIME_PATTERN));System.out.println(getLastDayOfMonthStr());System.out.println(getLastDayOfMonthStr(parseLocalDateTime("2021-12-12 12:03:12", DATETIME_PATTERN)));System.out.println(getLastDayOfMonthStr(parseLocalDateTime("2021-12-12 12:03:12", DATETIME_PATTERN), UNSIGNED_DATETIME_PATTERN));System.out.println("========");System.out.println(getFirstDayOfWeekStr());System.out.println(getFirstDayOfWeekStr(parseLocalDateTime("2021-12-12 12:03:12", DATETIME_PATTERN)));System.out.println(getFirstDayOfWeekStr(parseLocalDateTime("2021-12-12 12:03:12", DATETIME_PATTERN), UNSIGNED_DATETIME_PATTERN));System.out.println(getLastDayOfWeekStr());System.out.println(getLastDayOfWeekStr(parseLocalDateTime("2021-12-12 12:03:12", DATETIME_PATTERN)));System.out.println(getLastDayOfWeekStr(parseLocalDateTime("2021-12-12 12:03:12", DATETIME_PATTERN), UNSIGNED_DATETIME_PATTERN));System.out.println("========");System.out.println(getStartTimeOfDayStr());System.out.println(getStartTimeOfDayStr(parseLocalDateTime("2021-12-12 12:03:12", DATETIME_PATTERN)));System.out.println(getStartTimeOfDayStr(parseLocalDateTime("2021-12-12 12:03:12", DATETIME_PATTERN), UNSIGNED_DATETIME_PATTERN));System.out.println(getEndTimeOfDayStr());System.out.println(getEndTimeOfDayStr(parseLocalDateTime("2021-12-12 12:03:12", DATETIME_PATTERN)));System.out.println(getEndTimeOfDayStr(parseLocalDateTime("2021-12-12 12:03:12", DATETIME_PATTERN), UNSIGNED_DATETIME_PATTERN));System.out.println("========");List<String> dateStrs = listDateStrs("2019-01-30", "2020-12-13", YEAR);for (String dateStr : dateStrs) {System.out.println(dateStr);}System.out.println("========");List<String> dateStrs1 = listDateStrs("2019-01-30", "2020-12-13", MONTH);for (String dateStr : dateStrs1) {System.out.println(dateStr);}System.out.println("========");List<String> dateStrs2 = listDateStrs("2020-12-01", "2020-12-13", DAY);for (String dateStr : dateStrs2) {System.out.println(dateStr);}}}
包装类
- 基本类型对应的引用类型
- 自动装箱/拆箱
- 功能
正则表达式
- public boolean matches (String regex)
- 字符类
- 预定义的字符类
- 量词
- 常见案例
- 手机
- 电话
- 邮箱
- public String replaceAll(String regex,String
newStr) - public String[] split(String regex):public String[] split(String regex)
- 爬取信息
Arrays类
常用方法
public static void main(String[] args) {// 目标:学会使用Arrays类的常用API ,并理解其原理int[] arr = {10, 2, 55, 23, 24, 100};System.out.println(arr);// 1、返回数组内容的 toString(数组)// String rs = Arrays.toString(arr);// System.out.println(rs);System.out.println(Arrays.toString(arr));// 2、排序的API(默认自动对数组元素进行升序排序)Arrays.sort(arr);System.out.println(Arrays.toString(arr));// 3、二分搜索技术(前提数组必须排好序才支持,否则出bug)int index = Arrays.binarySearch(arr, 55);System.out.println(index);// 返回不存在元素的规律: - (应该插入的位置索引 + 1)int index2 = Arrays.binarySearch(arr, 22);System.out.println(index2);// 注意:数组如果么有排好序,可能会找不到存在的元素,从而出现bug!!int[] arr2 = {12, 36, 34, 25 , 13, 24, 234, 100};System.out.println(Arrays.binarySearch(arr2 , 36));}
Comparator比较器
- public static <T> void sort(类型[] a, Comparator<? superT> c)- 自定义排序规则
public static void main(String[] args) {// 目标:自定义数组的排序规则:Comparator比较器对象。// 1、Arrays的sort方法对于有值特性的数组是默认升序排序int[] ages = {34, 12, 42, 23};Arrays.sort(ages);System.out.println(Arrays.toString(ages));// 2、需求:降序排序!(自定义比较器对象,只能支持引用类型的排序!!)Integer[] ages1 = {34, 12, 42, 23};/**参数一:被排序的数组 必须是引用类型的元素参数二:匿名内部类对象,代表了一个比较器对象。*/Arrays.sort(ages1, new Comparator<Integer>() {@Overridepublic int compare(Integer o1, Integer o2) {// 指定比较规则。// if(o1 > o2){// return 1;// }else if(o1 < o2){// return -1;// }// return 0;// return o1 - o2; // 默认升序return o2 - o1; // 降序}});System.out.println(Arrays.toString(ages1));//自定义类排序Student[] students = new Student[3];students[0] = new Student("吴磊",23 , 175.5);students[1] = new Student("谢鑫",18 , 185.5);students[2] = new Student("王亮",20 , 195.5);System.out.println(Arrays.toString(students));// Arrays.sort(students); // 直接运行奔溃Arrays.sort(students, new Comparator<Student>() {@Overridepublic int compare(Student o1, Student o2) {// 自己指定比较规则// return o1.getAge() - o2.getAge(); // 按照年龄升序排序!// return o2.getAge() - o1.getAge(); // 按照年龄降序排序!!// return Double.compare(o1.getHeight(), o2.getHeight()); // 比较浮点型可以这样写 升序return Double.compare(o2.getHeight(), o1.getHeight()); // 比较浮点型可以这样写 降序}});System.out.println(Arrays.toString(students));}
泛型
常用标识T、E、K、V,(定义泛型时使用)
泛型通配符、上下限
泛型,即“参数化类型”。一提到参数,最熟悉的就是定义方法时有形参,然后调用此方法时传递实参。那么参数化类型怎么理解呢?顾名思义,就是将类型由原来的具体的类型参数化,类似于方法中的变量参数,此时类型也定义成参数形式(可以称之为类型形参),然后在使用/调用时传入具体的类型(类型实参)。
泛型的本质是为了参数化类型(在不创建新的类型的情况下,通过泛型指定的不同类型来控制形参具体限制的类型)。也就是说在泛型使用过程中,操作的数据类型被指定为一个参数,这种参数类型可以用在类、接口和方法中,分别被称为泛型类、泛型接口、泛型方法。
一个栗子
一个被举了无数次的例子:
List arrayList = new ArrayList();arrayList.add("aaaa");arrayList.add(100);for(int i = 0; i< arrayList.size();i++){String item = (String)arrayList.get(i);Log.d("泛型测试","item = " + item);}12345678
毫无疑问,程序的运行结果会以崩溃结束:
java.lang.ClassCastException: java.lang.Integer cannot be cast to java.lang.String1
ArrayList可以存放任意类型,例子中添加了一个String类型,添加了一个Integer类型,再使用时都以String的方式使用,因此程序崩溃了。为了解决类似这样的问题(在编译阶段就可以解决),泛型应运而生。
我们将第一行声明初始化list的代码更改一下,编译器会在编译阶段就能够帮我们发现类似这样的问题。
List<String> arrayList = new ArrayList<String>();...//arrayList.add(100); 在编译阶段,编译器就会报错123
特性
泛型只在编译阶段有效。看下面的代码:
List<String> stringArrayList = new ArrayList<String>();List<Integer> integerArrayList = new ArrayList<Integer>();Class classStringArrayList = stringArrayList.getClass();Class classIntegerArrayList = integerArrayList.getClass();if(classStringArrayList.equals(classIntegerArrayList)){Log.d("泛型测试","类型相同");}123456789
输出结果:D/泛型测试: 类型相同。
通过上面的例子可以证明,在编译之后程序会采取去泛型化的措施。也就是说Java中的泛型,只在编译阶段有效。在编译过程中,正确检验泛型结果后,会将泛型的相关信息擦出,并且在对象进入和离开方法的边界处添加类型检查和类型转换的方法。也就是说,泛型信息不会进入到运行时阶段。
对此总结成一句话:泛型类型在逻辑上看以看成是多个不同的类型,实际上都是相同的基本类型。
泛型的使用
泛型有三种使用方式,分别为:泛型类、泛型接口、泛型方法
泛型类
泛型类型用于类的定义中,被称为泛型类。通过泛型可以完成对一组类的操作对外开放相同的接口。最典型的就是各种容器类,如:List、Set、Map。
泛型类的最基本写法(这么看可能会有点晕,会在下面的例子中详解):
class 类名称 <泛型标识:可以随便写任意标识号,标识指定的泛型的类型>{private 泛型标识 /*(成员变量类型)*/ var;.....}}123456
一个最普通的泛型类:
//此处T可以随便写为任意标识,常见的如T、E、K、V等形式的参数常用于表示泛型//在实例化泛型类时,必须指定T的具体类型public class Generic<T>{//key这个成员变量的类型为T,T的类型由外部指定private T key;public Generic(T key) { //泛型构造方法形参key的类型也为T,T的类型由外部指定this.key = key;}public T getKey(){ //泛型方法getKey的返回值类型为T,T的类型由外部指定return key;}}1234567891011121314//泛型的类型参数只能是类类型(包括自定义类),不能是简单类型//传入的实参类型需与泛型的类型参数类型相同,即为Integer.Generic<Integer> genericInteger = new Generic<Integer>(123456);//传入的实参类型需与泛型的类型参数类型相同,即为String.Generic<String> genericString = new Generic<String>("key_vlaue");Log.d("泛型测试","key is " + genericInteger.getKey());Log.d("泛型测试","key is " + genericString.getKey());1234567812-27 09:20:04.432 13063-13063/? D/泛型测试: key is 12345612-27 09:20:04.432 13063-13063/? D/泛型测试: key is key_vlaue12
定义的泛型类,就一定要传入泛型类型实参么?并不是这样,在使用泛型的时候如果传入泛型实参,则会根据传入的泛型实参做相应的限制,此时泛型才会起到本应起到的限制作用。如果不传入泛型类型实参的话,在泛型类中使用泛型的方法或成员变量定义的类型可以为任何的类型。
看一个例子:
Generic generic = new Generic("111111");Generic generic1 = new Generic(4444);Generic generic2 = new Generic(55.55);Generic generic3 = new Generic(false);Log.d("泛型测试","key is " + generic.getKey());Log.d("泛型测试","key is " + generic1.getKey());Log.d("泛型测试","key is " + generic2.getKey());Log.d("泛型测试","key is " + generic3.getKey());123456789D/泛型测试: key is 111111D/泛型测试: key is 4444D/泛型测试: key is 55.55D/泛型测试: key is false1234
注意:
- 泛型的类型参数只能是类类型,不能是简单类型。
- 不能对确切的泛型类型使用instanceof操作。如下面的操作是非法的,编译时会出错。
if(ex_num instanceof Generic<Number>){} 12
泛型接口
泛型接口与泛型类的定义及使用基本相同。泛型接口常被用在各种类的生产器中,可以看一个例子:
//定义一个泛型接口public interface Generator<T> {public T next();}1234
当实现泛型接口的类,未传入泛型实参时:
/*** 未传入泛型实参时,与泛型类的定义相同,在声明类的时候,需将泛型的声明也一起加到类中* 即:class FruitGenerator<T> implements Generator<T>{* 如果不声明泛型,如:class FruitGenerator implements Generator<T>,编译器会报错:"Unknown class"*/class FruitGenerator<T> implements Generator<T>{@Overridepublic T next() {return null;}}1234567891011
当实现泛型接口的类,传入泛型实参时:
/*** 传入泛型实参时:* 定义一个生产器实现这个接口,虽然我们只创建了一个泛型接口Generator<T>* 但是我们可以为T传入无数个实参,形成无数种类型的Generator接口。* 在实现类实现泛型接口时,如已将泛型类型传入实参类型,则所有使用泛型的地方都要替换成传入的实参类型* 即:Generator<T>,public T next();中的的T都要替换成传入的String类型。*/public class FruitGenerator implements Generator<String> {private String[] fruits = new String[]{"Apple", "Banana", "Pear"};@Overridepublic String next() {Random rand = new Random();return fruits[rand.nextInt(3)];}}1234567891011121314151617
泛型通配符
我们知道Ingeter是Number的一个子类,同时在特性章节中我们也验证过Generic<Ingeter>与Generic<Number>实际上是相同的一种基本类型。那么问题来了,在使用Generic<Number>作为形参的方法中,能否使用Generic<Ingeter>的实例传入呢?在逻辑上类似于Generic<Number>和Generic<Ingeter>是否可以看成具有父子关系的泛型类型呢?
为了弄清楚这个问题,我们使用Generic<T>这个泛型类继续看下面的例子:
public void showKeyValue1(Generic<Number> obj){Log.d("泛型测试","key value is " + obj.getKey());}123Generic<Integer> gInteger = new Generic<Integer>(123);Generic<Number> gNumber = new Generic<Number>(456);showKeyValue(gNumber);// showKeyValue这个方法编译器会为我们报错:Generic<java.lang.Integer>// cannot be applied to Generic<java.lang.Number>// showKeyValue(gInteger);12345678
通过提示信息我们可以看到Generic<Integer>不能被看作为`Generic的子类。由此可以看出:同一种泛型可以对应多个版本(因为参数类型是不确定的),不同版本的泛型类实例是不兼容的。
回到上面的例子,如何解决上面的问题?总不能为了定义一个新的方法来处理Generic<Integer>类型的类,这显然与java中的多台理念相违背。因此我们需要一个在逻辑上可以表示同时是Generic<Integer>和Generic<Number>父类的引用类型。由此类型通配符应运而生。
我们可以将上面的方法改一下:
public void showKeyValue1(Generic<?> obj){Log.d("泛型测试","key value is " + obj.getKey());}123
类型通配符一般是使用?代替具体的类型实参,注意了,此处’?’是类型实参,而不是类型形参 。重要说三遍!此处’?’是类型实参,而不是类型形参 ! 此处’?’是类型实参,而不是类型形参 !再直白点的意思就是,此处的?和Number、String、Integer一样都是一种实际的类型,可以把?看成所有类型的父类。是一种真实的类型。
可以解决当具体类型不确定的时候,这个通配符就是 ? ;当操作类型时,不需要使用类型的具体功能时,只使用Object类中的功能。那么可以用 ? 通配符来表未知类型。
泛型方法
在java中,泛型类的定义非常简单,但是泛型方法就比较复杂了。
尤其是我们见到的大多数泛型类中的成员方法也都使用了泛型,有的甚至泛型类中也包含着泛型方法,这样在初学者中非常容易将泛型方法理解错了。
泛型类,是在实例化类的时候指明泛型的具体类型;泛型方法,是在调用方法的时候指明泛型的具体类型 。
/*** 泛型方法的基本介绍* @param tClass 传入的泛型实参* @return T 返回值为T类型* 说明:* 1)public 与 返回值中间<T>非常重要,可以理解为声明此方法为泛型方法。* 2)只有声明了<T>的方法才是泛型方法,泛型类中的使用了泛型的成员方法并不是泛型方法。* 3)<T>表明该方法将使用泛型类型T,此时才可以在方法中使用泛型类型T。* 4)与泛型类的定义一样,此处T可以随便写为任意标识,常见的如T、E、K、V等形式的参数常用于表示泛型。*/public <T> T genericMethod(Class<T> tClass)throws InstantiationException ,IllegalAccessException{T instance = tClass.newInstance();return instance;}123456789101112131415Object obj = genericMethod(Class.forName("com.test.test"));1
泛型方法的基本用法
光看上面的例子有的同学可能依然会非常迷糊,我们再通过一个例子,把我泛型方法再总结一下。
public class GenericTest {//这个类是个泛型类,在上面已经介绍过public class Generic<T>{private T key;public Generic(T key) {this.key = key;}//我想说的其实是这个,虽然在方法中使用了泛型,但是这并不是一个泛型方法。//这只是类中一个普通的成员方法,只不过他的返回值是在声明泛型类已经声明过的泛型。//所以在这个方法中才可以继续使用 T 这个泛型。public T getKey(){return key;}/*** 这个方法显然是有问题的,在编译器会给我们提示这样的错误信息"cannot reslove symbol E"* 因为在类的声明中并未声明泛型E,所以在使用E做形参和返回值类型时,编译器会无法识别。public E setKey(E key){this.key = keu}*/}/*** 这才是一个真正的泛型方法。* 首先在public与返回值之间的<T>必不可少,这表明这是一个泛型方法,并且声明了一个泛型T* 这个T可以出现在这个泛型方法的任意位置.* 泛型的数量也可以为任意多个* 如:public <T,K> K showKeyName(Generic<T> container){* ...* }*/public <T> T showKeyName(Generic<T> container){System.out.println("container key :" + container.getKey());//当然这个例子举的不太合适,只是为了说明泛型方法的特性。T test = container.getKey();return test;}//这也不是一个泛型方法,这就是一个普通的方法,只是使用了Generic<Number>这个泛型类做形参而已。public void showKeyValue1(Generic<Number> obj){Log.d("泛型测试","key value is " + obj.getKey());}//这也不是一个泛型方法,这也是一个普通的方法,只不过使用了泛型通配符?//同时这也印证了泛型通配符章节所描述的,?是一种类型实参,可以看做为Number等所有类的父类public void showKeyValue2(Generic<?> obj){Log.d("泛型测试","key value is " + obj.getKey());}/*** 这个方法是有问题的,编译器会为我们提示错误信息:"UnKnown class 'E' "* 虽然我们声明了<T>,也表明了这是一个可以处理泛型的类型的泛型方法。* 但是只声明了泛型类型T,并未声明泛型类型E,因此编译器并不知道该如何处理E这个类型。public <T> T showKeyName(Generic<E> container){...}*//*** 这个方法也是有问题的,编译器会为我们提示错误信息:"UnKnown class 'T' "* 对于编译器来说T这个类型并未项目中声明过,因此编译也不知道该如何编译这个类。* 所以这也不是一个正确的泛型方法声明。public void showkey(T genericObj){}*/public static void main(String[] args) {}
类中的泛型方法
当然这并不是泛型方法的全部,泛型方法可以出现杂任何地方和任何场景中使用。但是有一种情况是非常特殊的,当泛型方法出现在泛型类中时,我们再通过一个例子看一下
public class GenericFruit {class Fruit{@Overridepublic String toString() {return "fruit";}}class Apple extends Fruit{@Overridepublic String toString() {return "apple";}}class Person{@Overridepublic String toString() {return "Person";}}class GenerateTest<T>{public void show_1(T t){System.out.println(t.toString());}//在泛型类中声明了一个泛型方法,使用泛型E,这种泛型E可以为任意类型。可以类型与T相同,也可以不同。//由于泛型方法在声明的时候会声明泛型<E>,因此即使在泛型类中并未声明泛型,编译器也能够正确识别泛型方法中识别的泛型。public <E> void show_3(E t){System.out.println(t.toString());}//在泛型类中声明了一个泛型方法,使用泛型T,注意这个T是一种全新的类型,可以与泛型类中声明的T不是同一种类型。public <T> void show_2(T t){System.out.println(t.toString());}}public static void main(String[] args) {Apple apple = new Apple();Person person = new Person();GenerateTest<Fruit> generateTest = new GenerateTest<Fruit>();//apple是Fruit的子类,所以这里可以generateTest.show_1(apple);//编译器会报错,因为泛型类型实参指定的是Fruit,而传入的实参类是Person//generateTest.show_1(person);//使用这两个方法都可以成功generateTest.show_2(apple);generateTest.show_2(person);//使用这两个方法也都可以成功generateTest.show_3(apple);generateTest.show_3(person);}}
泛型方法与可变参数
再看一个泛型方法和可变参数的例子:
public <T> void printMsg( T... args){for(T t : args){Log.d("泛型测试","t is " + t);}}12345printMsg("111",222,"aaaa","2323.4",55.55);1
静态方法与泛型
静态方法有一种情况需要注意一下,那就是在类中的静态方法使用泛型:静态方法无法访问类上定义的泛型;如果静态方法操作的引用数据类型不确定的时候,必须要将泛型定义在方法上。
即:如果静态方法要使用泛型的话,必须将静态方法也定义成泛型方法 。
public class StaticGenerator<T> {......../*** 如果在类中定义使用泛型的静态方法,需要添加额外的泛型声明(将这个方法定义成泛型方法)* 即使静态方法要使用泛型类中已经声明过的泛型也不可以。* 如:public static void show(T t){..},此时编译器会提示错误信息:"StaticGenerator cannot be refrenced from static context"*/public static <T> void show(T t){}}
另一文章中的
import java.util.ArrayList;import java.util.Collection;import java.util.HashSet;import java.util.HashMap;import java.util.List;public class StaticMethod {public static void main(String[] args) {System.out.println(test("aaaaa")); //aaaaa 基本用法System.out.println(test1("aa").get(0).equals("aa")); //true 用于内部包装System.out.println(test1(new HashMap()).get(0).put("", "")); //比上一句更能说明用处的例子System.out.println(test2(new HashSet(), Collection.class).size()); //0 用于强制转换类型System.out.println(test3("bbbbb")); //bbbbb 装神弄鬼HashSet ss = test(new HashSet()); //省去了强制转换类型ss.size();test(new HashSet()).size(); //可以看出与句柄无关,是静态方法自动做出的判断//在方法中自动进行强制类型转换,语法很特别。//(这个语句毫无疑问会报错,只是subList这个ArrayList有,而HashSet没有的方法能更明确的展示这个语法)test2(new HashSet(), ArrayList.class).subList(1, 1);}public static<T> T test(T obj){return obj;}public static<T> List<T> test1(T obj){List<T> list = new ArrayList();list.add(obj);return list;}public static<T> T test2(Object str, Class<T> obj){return (T)str;}public static<T> T test2(Object obj){return (T)obj;}public static<T, A, B, C, D> B test3(B obj){return obj;}}
泛型方法总结
泛型方法能使方法独立于类而产生变化,以下是一个基本的指导原则:
无论何时,如果你能做到,你就该尽量使用泛型方法。也就是说,如果使用泛型方法将整个类泛型化,那么就应该使用泛型方法。另外对于一个static的方法,所以如果static方法要使用泛型能力,就必须使其成为泛型方法。
泛型上下边界
在使用泛型的时候,我们还可以为传入的泛型类型实参进行上下边界的限制,如:类型实参只准传入某种类型的父类或某种类型的子类。
- 为泛型添加上边界,即传入的类型实参必须是指定类型的子类型 ? extends Car: ?必须是Car或者其子类 泛型上限
- 为泛型添加下边界,即传入的类型实参必须是指定类型的父类型 ? super Car : ?必须是Car或者其父类 泛型下限
- ?:通配符,泛指所有的类型,是所有类型的父类。
public void showKeyValue1(Generic<? extends Number> obj){Log.d("泛型测试","key value is " + obj.getKey());}123Generic<String> generic1 = new Generic<String>("11111");Generic<Integer> generic2 = new Generic<Integer>(2222);Generic<Float> generic3 = new Generic<Float>(2.4f);Generic<Double> generic4 = new Generic<Double>(2.56);//这一行代码编译器会提示错误,因为String类型并不是Number类型的子类//showKeyValue1(generic1);showKeyValue1(generic2);showKeyValue1(generic3);showKeyValue1(generic4);1234567891011
如果我们把泛型类的定义也改一下:
public class Generic<T extends Number>{private T key;public Generic(T key) {this.key = key;}public T getKey(){return key;}}//这一行代码也会报错,因为String不是Number的子类Generic<String> generic1 = new Generic<String>("11111");
再来一个泛型方法的例子:
//在泛型方法中添加上下边界限制的时候,必须在权限声明与返回值之间的<T>上添加上下边界,即在泛型声明的时候添加//public <T> T showKeyName(Generic<T extends Number> container),编译器会报错:"Unexpected bound"public <T extends Number> T showKeyName(Generic<T> container){System.out.println("container key :" + container.getKey());T test = container.getKey();return test;}
通过上面的两个例子可以看出:泛型的上下边界添加,必须与泛型的声明在一起 。
关于泛型数组
看到了很多文章中都会提起泛型数组,经过查看sun的说明文档,在java中是”不能创建一个确切的泛型类型的数组”的。
也就是说下面的这个例子是不可以的:
List<String>[] ls = new ArrayList<String>[10]; 1
而使用通配符创建泛型数组是可以的,如下面这个例子:
List<?>[] ls = new ArrayList<?>[10]; 1
这样也是可以的:
List<String>[] ls = new ArrayList[10];1
List<String>[] lsa = new List<String>[10]; // Not really allowed.Object o = lsa;Object[] oa = (Object[]) o;List<Integer> li = new ArrayList<Integer>();li.add(new Integer(3));oa[1] = li; // Unsound, but passes run time store checkString s = lsa[1].get(0); // Run-time error: ClassCastException.1234567
这种情况下,由于JVM泛型的擦除机制,在运行时JVM是不知道泛型信息的,所以可以给oa[1]赋上一个ArrayList而不会出现异常,但是在取出数据的时候却要做一次类型转换,所以就会出现ClassCastException,如果可以进行泛型数组的声明,上面说的这种情况在编译期将不会出现任何的警告和错误,只有在运行时才会出错。
而对泛型数组的声明进行限制,对于这样的情况,可以在编译期提示代码有类型安全问题,比没有任何提示要强很多。
下面采用通配符的方式是被允许的:数组的类型不可以是类型变量,除非是采用通配符的方式,因为对于通配符的方式,最后取出数据是要做显式的类型转换的。
List<?>[] lsa = new List<?>[10]; // OK, array of unbounded wildcard type.Object o = lsa;Object[] oa = (Object[]) o;List<Integer> li = new ArrayList<Integer>();li.add(new Integer(3));oa[1] = li; // Correct.Integer i = (Integer) lsa[1].get(0); // OK 1234567
评论

Lambda
Lambda表达式语法
Lambda表达式在Java语言中引入了一个操作符“->”,该操作符被称为Lambda操作符或箭头操作符。它将Lambda分为两个部分:
- 左侧:指定了Lambda表达式需要的所有参数
- 右侧:制定了Lambda体,即Lambda表达式要执行的功能。
像这样:
(parameters) -> expression或(parameters) ->{ statements; }123
以下是lambda表达式的重要特征:
- 可选类型声明:不需要声明参数类型,编译器可以统一识别参数值。
- 可选的参数圆括号:一个参数无需定义圆括号,但无参数或多个参数需要定义圆括号。
- 可选的大括号:如果主体包含了一个语句,就不需要使用大括号。
- 可选的返回关键字:如果主体只有一个表达式返回值则编译器会自动返回值,大括号需要指定明表达式返回了一个数值。
下面对每个语法格式的特征进行举例说明:
(1)语法格式一:无参,无返回值,Lambda体只需一条语句。如下:
@Testpublic void test01(){Runnable runnable=()-> System.out.println("Runnable 运行");runnable.run();//结果:Runnable 运行}12345
(2)语法格式二:Lambda需要一个参数,无返回值。如下:
@Testpublic void test02(){Consumer<String> consumer=(x)-> System.out.println(x);consumer.accept("Hello Consumer");//结果:Hello Consumer}12345
(3)语法格式三:Lambda只需要一个参数时,参数的小括号可以省略,如下:
public void test02(){Consumer<String> consumer=x-> System.out.println(x);consumer.accept("Hello Consumer");//结果:Hello Consumer}1234
(4)语法格式四:Lambda需要两个参数,并且Lambda体中有多条语句。
@Testpublic void test04(){Comparator<Integer> com=(x, y)->{System.out.println("函数式接口");return Integer.compare(x,y);};System.out.println(com.compare(2,4));//结果:-1}12345678
(5)语法格式五:有两个以上参数,有返回值,若Lambda体中只有一条语句,return和大括号都可以省略不写
@Testpublic void test05(){Comparator<Integer> com=(x, y)-> Integer.compare(x,y);System.out.println(com.compare(4,2));//结果:1}12345
(6)Lambda表达式的参数列表的数据类型可以省略不写,因为JVM可以通过上下文推断出数据类型,即“类型推断”
@Testpublic void test06(){Comparator<Integer> com=(Integer x, Integer y)-> Integer.compare(x,y);System.out.println(com.compare(4,2));//结果:1}12345
类型推断:在执行javac编译程序时,JVM根据程序的上下文推断出了参数的类型。Lambda表达式依赖于上下文环境。
语法背诵口诀:左右遇一括号省,左侧推断类型省,能省则省。
函数式接口
什么是函数式接口
==只包含一个抽象方法的接口,就称为函数式接口。==我们可以通过Lambda表达式来创建该接口的实现对象。
我们可以在任意函数式接口上使用@FunctionalInterface注解,这样做可以用于检测它是否是一个函数式接口,同时javadoc也会包含一条声明,说明这个接口是一个函数式接口。
自定义函数式接口
按照函数式接口的定义,自定义一个函数式接口,如下:
@FunctionalInterfacepublic interface MyFuncInterf<T> {public T getValue(String origin);}1234
定义一个方法将函数式接口作为方法参数。
public String toLowerString(MyFuncInterf<String> mf,String origin){return mf.getValue(origin);}123
将Lambda表达式实现的接口作为参数传递。
public void test07(){String value=toLowerString((str)->{return str.toLowerCase();},"ABC");System.out.println(value);//结果ABC}123456
Java内置函数式接口
四大核心函数式接口的介绍,如图所示: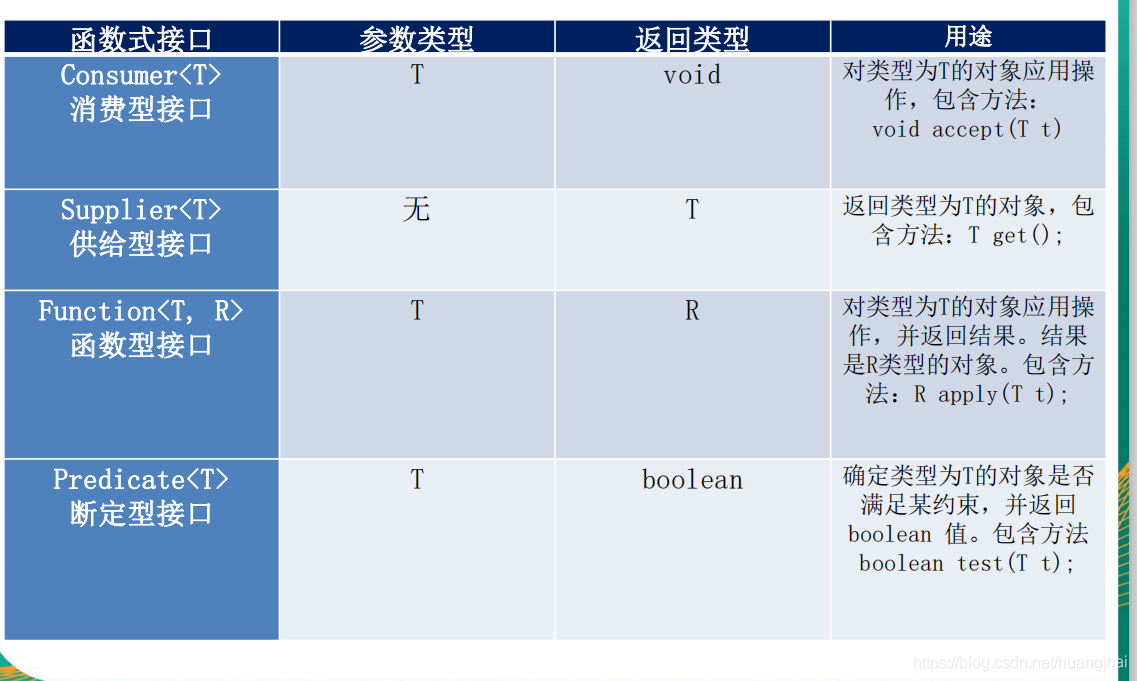
使用示例:
1.Consumer:消费型接口 void accept(T t)
public void makeMoney(Integer money, Consumer<Integer> consumer){consumer.accept(money);}@Testpublic void test01(){makeMoney(100,t-> System.out.println("今天赚了"+t));//结果:今天赚了100}1234567
2.Supplier:供给型接口 T get()
/*** 产生指定的整数集合放到集合中* Iterable接口的forEach方法的定义:方法中使用到了Consumer消费型接口,* default void forEach(Consumer<? super T> action) {* Objects.requireNonNull(action);* for (T t : this) {* action.accept(t);* }* }*/@Testpublic void test02(){List list = addNumInList(10, () -> (int) (Math.random() * 100));list.forEach(t-> System.out.println(t));}public List addNumInList(int size, Supplier<Integer> supplier){List<Integer> list=new ArrayList();for (int i = 0; i < size; i++) {list.add(supplier.get());}return list;}12345678910111213141516171819202122
3.Function
/**** 使用函数式接口处理字符串。*/public String handleStr(String s,Function<String,String> f){return f.apply(s);}@Testpublic void test03(){System.out.println(handleStr("abc",(String s)->s.toUpperCase()));}//结果:ABC123456789101112
4.Predicate:断言型接口 boolean test(T t)
/*** 自定义条件过滤字符串集合*/@Testpublic void test04(){List<String> strings = Arrays.asList("啊啊啊", "2333", "666", "?????????");List<String> stringList = filterStr(strings, (s) -> s.length() > 3);for (String s : stringList) {System.out.println(s);}}public List<String> filterStr(List<String> list, Predicate<String> predicate){ArrayList result = new ArrayList();for (int i = 0; i < list.size(); i++) {if (predicate.test(list.get(i))){result.add(list.get(i));}}return result;}
其他接口的定义,如图所示: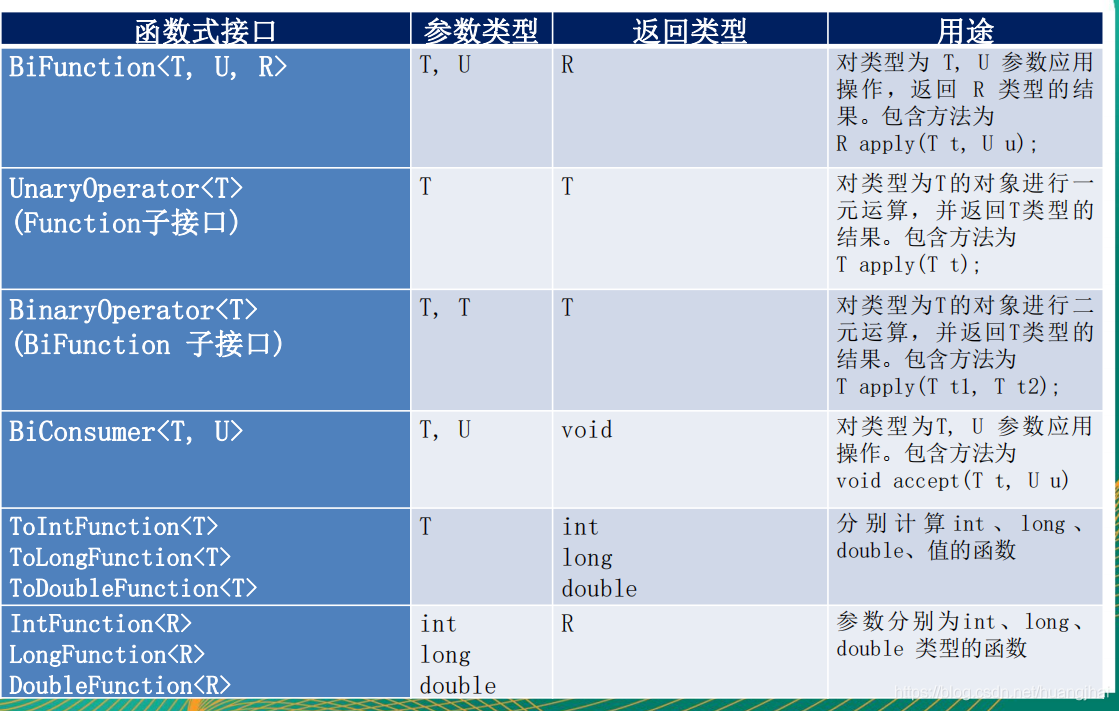
方法引用
当要传递给Lambda体的操作,已经有实现的方法了,就可以使用方法引用!(实现抽象方法的参数列表,必须与方法引用的参数列表一致,方法的返回值也必须一致,即方法的签名一致)。方法引用可以理解为方法引用是Lambda表达式的另外一种表现形式。
方法引用的语法:使用操作符“::”将对象或类和方法名分隔开。
方法引用的使用情况共分为以下三种:
- 对象::实例方法名
- 类::静态方法名
- 类::实例方法名
使用示例:
1.对象::实例方法名
/***PrintStream中的println方法定义* public void println(String x) {* synchronized (this) {* print(x);* newLine();* }* }*///对象::实例方法名@Testpublic void test1(){PrintStream out = System.out;Consumer<String> consumer=out::println;consumer.accept("hello");}12345678910111213141516
- 类::静态方法名
/*** Integer类中的静态方法compare的定义:* public static int compare(int x, int y) {* return (x < y) ? -1 : ((x == y) ? 0 : 1);* }*/@Testpublic void test2(){Comparator<Integer> comparable=(x,y)->Integer.compare(x,y);//使用方法引用实现相同效果Comparator<Integer> integerComparable=Integer::compare;System.out.println(integerComparable.compare(4,2));//结果:1System.out.println(comparable.compare(4,2));//结果:1}1234567891011121314
3.类::实例方法名
@Testpublic void test3(){BiPredicate<String,String> bp=(x,y)->x.equals(y);//使用方法引用实现相同效果BiPredicate<String,String> bp2=String::equals;System.out.println(bp.test("1","2"));//结果:falseSystem.out.println(bp.test("1","2"));//结果:false}12345678
构造器引用
格式:类名::new
与函数式接口相结合,自动与函数式接口中方法兼容,可以把构造器引用赋值给定义的方法。需要注意构造器参数列表要与接口中抽象方法的参数列表一致。使用示例:
创建一个实体类Employee:
public class Employee {private Integer id;private String name;private Integer age;@Overridepublic String toString() {return "Employee{" +"id=" + id +", name='" + name + '\'' +", age=" + age +'}';}public Employee(){}public Employee(Integer id) {this.id = id;}public Employee(Integer id, Integer age) {this.id = id;this.age = age;}public Employee(int id, String name, int age) {this.id = id;this.name = name;this.age = age;}}
使用构造器引用与函数式接口相结合
@Testpublic void test01(){//引用无参构造器Supplier<Employee> supplier=Employee::new;System.out.println(supplier.get());//引用有参构造器Function<Integer,Employee> function=Employee::new;System.out.println(function.apply(21));BiFunction<Integer,Integer,Employee> biFunction=Employee::new;System.out.println(biFunction.apply(8,24));}输出结果:Employee{id=null, name='null', age=null}Employee{id=21, name='null', age=null}Employee{id=8, name='null', age=24}
数组引用
数组引用的格式:type[]:new
使用示例:
@Testpublic void test02(){Function<Integer,String[]> function=String[]::new;String[] apply = function.apply(10);System.out.println(apply.length);//结果:10}123456
Lambda表达式的作用域
Lambda表达式可以看作是匿名内部类实例化的对象,Lambda表达式对变量的访问限制和匿名内部类一样,因此Lambda表达式可以访问局部变量、局部引用,静态变量,实例变量。
访问局部变量
在Lambda表达式中规定只能引用标记了final的外层局部变量。我们不能在lambda 内部修改定义在域外的局部变量,否则会编译错误。
public class TestFinalVariable {interface VarTestInterface{Integer change(String str);}public static void main(String[] args) {//局部变量不使用final修饰Integer tempInt = 1;VarTestInterface var = (str -> Integer.valueOf(str+tempInt));//再次修改,不符合隐式final定义tempInt =2;Integer str =var.change("111") ;System.out.println(str);}}12345678910111213141516
上面代码会出现编译错误,出现如下提示:
特殊情况下,局部变量也可以不用声明为 final,但是必须不可被后面的代码修改(即隐性的具有 final 的语义)
例如上面的代码确保Lambda表达式后局部变量后面不做修改,就可以成功啦!
public class TestFinalVariable {interface VarTestInterface{Integer change(String str);}public static void main(String[] args) {//局部变量不使用final修饰Integer tempInt = 1;VarTestInterface var = (str -> Integer.valueOf(str+tempInt));Integer str =var.change("111") ;System.out.println(str);}}1234567891011121314
访问局部引用,静态变量,实例变量
Lambda表达式不限制访问局部引用变量,静态变量,实例变量。代码测试都可正常执行,代码:
public class LambdaScopeTest {/*** 静态变量*/private static String staticVar;/*** 实例变量*/private static String instanceVar;@FunctionalInterfaceinterface VarChangeInterface{Integer change(String str);}/*** 测试引用变量*/private void testReferenceVar(){ArrayList<String> list = new ArrayList<>();list.add("111");//访问外部引用局部引用变量VarChangeInterface varChangeInterface = ((str) -> Integer.valueOf(list.get(0)));//修改局部引用变量list.set(0,"222");Integer str =varChangeInterface.change("");System.out.println(str);}/*** 测试静态变量*/void testStaticVar(){staticVar="222";VarChangeInterface varChangeInterface = (str -> Integer.valueOf(str+staticVar));staticVar="333";Integer str =varChangeInterface.change("111") ;System.out.println(str);}/*** 测试实例变量*/void testInstanceVar(){instanceVar="222";VarChangeInterface varChangeInterface = (str -> Integer.valueOf(str+instanceVar));instanceVar="333";Integer str =varChangeInterface.change("111") ;System.out.println(str);}public static void main(String[] args) {new LambdaScopeTest().testReferenceVar();new LambdaScopeTest().testStaticVar();new LambdaScopeTest().testInstanceVar();}}123456789101112131415161718192021222324252627282930313233343536373839404142434445464748495051525354555657585960616263
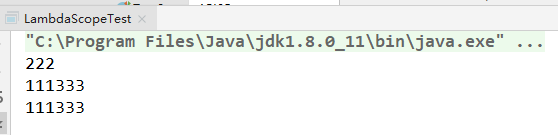
Lambda表达式里不允许声明一个与局部变量同名的参数或者局部变量。
//编程报错Integer tempInt = 1;VarTestInterface varTest01 = (tempInt -> Integer.valueOf(tempInt));VarTestInterface varTest02 = (str -> {Integer tempInt = 1;Integer.valueOf(str);});1234567
Lambda表达式访问局部变量作限制的原因
Lambda表达式不能访问非final修饰的局部变量的原因是,局部变量是保存在栈帧中的。而在Java的线程模型中,栈帧中的局部变量是线程私有的,如果允许Lambda表达式访问到栈帧中的变量地址(可改变的局部变量),则会可能导致线程私有的数据被并发访问,造成线程不安全问题。
基于上述,对于引用类型的局部变量,因为Java是值传递,又因为引用类型的指向内容是保存在堆中,是线程共享的,因此Lambda表达式中可以修改引用类型的局部变量的内容,而不能修改该变量的引用。
对于基本数据类型的变量,在 Lambda表达式中只是获取到该变量的副本,且局部变量是线程私有的,因此无法知道其他线程对该变量的修改,如果该变量不做final修饰,会造成数据不同步的问题。
但是实例变量,静态变量不作限制,因为实例变量,静态变量是保存在堆中(Java8之后),而堆是线程共享的。在Lambda表达式内部是可以知道实例变量,静态变量的变化。
Lambda表达式的优缺点
- 优点:
- 使代码更简洁,紧凑
- 可以使用并行流来并行处理,充分利用多核CPU的优势
有利于JIT编译器对代码进行优化
- 缺点:
- 非并行计算情况下,其计算速度没有比传统的 for 循环快
- 不容易调试
- 若其他程序员没有学过 Lambda 表达式,代码不容易看懂
集合
Iterator接口
Iterator接口,用于遍历集合元素的接口。
在Iterator接口中定义了三个方法:
| 修饰与类型 | 方法与描述 |
|---|---|
boolean |
hasNext()如果仍有元素可以迭代,则返回true。 |
E |
next()返回迭代的下一个元素。 |
void |
remove()从迭代器指向的 collection 中移除迭代器返回的最后一个元素(可选操作)。 |
每一个集合都有自己的数据结构(就是容器中存储数据的方式),都有特定的取出自己内部元素的方式。为了便于操作所有的容器,取出元素。将容器内部的取出方式按照一个统一的规则向外提供,这个规则就是Iterator接口,使得对容器的遍历操作与其具体的底层实现相隔离,达到解耦的效果。
也就说,只要通过该接口就可以取出Collection集合中的元素,至于每一个具体的容器依据自己的数据结构,如何实现的具体取出细节,这个不用关心,这样就降低了取出元素和具体集合的耦合性。
使用迭代器遍历集合元素
public static void main(String[] args) {List<String> list1 = new ArrayList<>();list1.add("abc0");list1.add("abc1");list1.add("abc2");// while循环方式遍历Iterator it1 = list1.iterator();while (it1.hasNext()) {System.out.println(it1.next());}// for循环方式遍历for (Iterator it2 = list1.iterator(); it2.hasNext(); ) {System.out.println(it2.next());}}
使用Iterator迭代器进行删除集合元素,则不会出现并发修改异常。
因为:在执行remove操作时,同样先执行checkForComodification(),然后会执行ArrayList的remove()方法,该方法会将modCount值加1,这里我们将expectedModCount=modCount,使之保持统一。
ListIterator接口
ListIterator是一个功能更加强大的迭代器, 它继承于Iterator接口,只能用于各种List类型的访问。可以通过调用listIterator()方法产生一个指向List开始处的ListIterator, 还可以调用listIterator(n)方法创建一个一开始就指向列表索引为n的元素处的ListIterator。
特点
允许我们向前、向后两个方向遍历 List;
在遍历时修改 List 的元素;
遍历时获取迭代器当前游标所在位置。
常用API
Collection接口
所有集合类都位于java.util包下。Java的集合类主要由两个接口派生而出:Collection和Map,Collection和Map是Java集合框架的根接口,这两个接口又包含了一些子接口或实现类。
- Collection一次存一个元素,是单列集合;
- Map一次存一对元素,是双列集合。Map存储的一对元素:键–值,键(key)与值(value)间有对应(映射)关系。
继承关系图
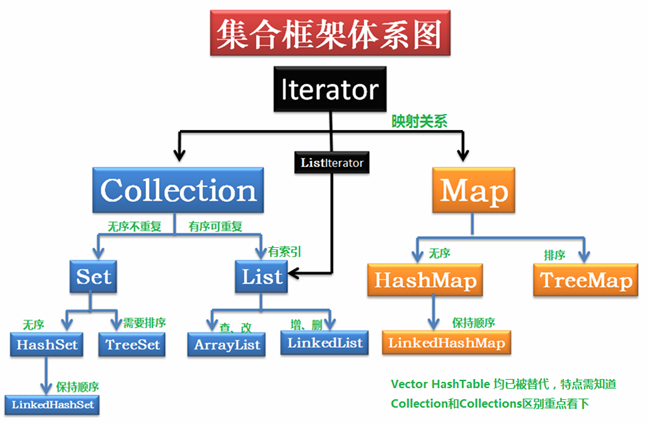
Collection集合主要有List和Set两大接口
- List:有序(元素存入集合的顺序和取出的顺序一致),元素都有索引。元素可以重复。
- Set:无序(存入和取出顺序有可能不一致),不可以存储重复元素。必须保证元素唯一性。
List集合
List是元素有序并且可以重复的集合。
List的主要实现:ArrayList, LinkedList, Vector。
List常用方法
ArrayList、LinkedList、Vector 的区别

总结:
- ArrayList 和 Vector 基于数组实现,对于随机访问get和set,ArrayList优于LinkedList,因为LinkedList要移动指针。
- LinkedList 不会出现扩容的问题,所以比较适合随机位置增、删。但是其基于链表实现,所以在定位时需要线性扫描,效率比较低。
- 当操作是在一列数据的后面添加数据而不是在前面或中间,并且需要随机地访问其中的元素时,使用ArrayList会提供比较好的性能;
- 当你的操作是在一列数据的前面或中间添加或删除数据,并且按照顺序访问其中的元素时,就应该使用LinkedList了。
遍历时操作元素*
遍历集合时,同时操作集合中的元素(增删等)
/*** Description: for循环遍历* 输出结果:* [a, b, c, d, e]* 由结果可知,第二个元素b并未删除,原因是当第一个元素b被删除后,它后面所有的元素都向前移动了一个单位,循环时导致第二个元素b漏掉了*/public static void remove(List<String> list) {for (int i = 0; i < list.size(); i++) {String s = list.get(i);if (s.equals("b")) {list.remove(s);}}}/*** Description: foreach循环遍历** 会报错:java.util.ConcurrentModificationException。这是因为在这里,foreach循环遍历容器本质上是使用迭代器进行遍历的,会对修改次数modCount进行检查,不允许集合进行更改操作*/public static void remove2(List<String> list) {for (String s : list) {if (s.equals("b")) {list.remove(s);}System.out.println(s);}}/*** Description: 使用迭代器遍历*/public static void remove3(List<String> list) {Iterator<String> it = list.iterator();while (it.hasNext()) {String s = it.next();if (s.equals("b")) {it.remove();}}}
使用迭代器遍历删除时,能够避免方法二中出现的问题。这是因为:在ArrayList中,modCount是指集合的修改次数,当进行add或者delete时,modCount会+1;expectedModCount是指集合的迭代器的版本号,初始值是modCount,但是当集合进行add或者delete操作时,modCount会+1,而expectedModCount不会改变,所以方法二中会抛出异常。但是it.remove操作时,会同步expectedModCount的值,把modCount的值赋予expectedModCount。所以不会抛出异常。
测试方法
public static void main(String[] args) {List<String> arrayList = new ArrayList<String>();arrayList.add("a");arrayList.add("b");arrayList.add("b");arrayList.add("c");arrayList.add("d");arrayList.add("e");// remove(arrayList);// remove2(arrayList);remove3(arrayList);System.out.println(arrayList);}
总结:如果想正确的循环遍历删除(增加)元素,需要使用方法三,也就是迭代器遍历删除(增加)的方法。
Set集合
Set集合元素无序(存入和取出的顺序不一定一致),并且没有重复对象。
Set的主要实现类:HashSet, TreeSet。
Set常用方法
HashSet、TreeSet、LinkedHashSet的区别

HashSet检查重复
当你把对象加入HashSet时,HashSet会先计算对象的hashcode值来判断对象加入的位置,同时也会与其他加入的对象的hashcode值作比较,如果没有相符的hashcode,HashSet会假设对象没有重复出现。但是如果发现有相同hashcode值的对象,这时会调用equals()方法来检查hashcode相等的对象是否真的相同。如果两者相同,HashSet就不会让加入操作成功。
hashCode()与equals()的相关规定:
- 如果两个对象相等,则hashcode一定也是相同的
- 两个对象相等,equals方法返回true
- 两个对象有相同的hashcode值,它们也不一定是相等的
- 综上,equals方法被覆盖过,则hashCode方法也必须被覆盖
hashCode()的默认行为是对堆上的对象产生独特值。如果没有重写hashCode(),则该class的两个对象无论如何都不会相等(即使这两个对象指向相同的数据)。
总结:
HashSet是一个通用功能的Set,而LinkedHashSet 提供元素插入顺序保证,TreeSet是一个SortedSet实现,由Comparator 或者 Comparable指定的元素顺序存储元素。
Map接口
Map 是一种把键对象和值对象映射的集合,它的每一个元素都包含一对键对象和值对象。 Map没有继承于Collection接口,从Map集合中检索元素时,只要给出键对象,就会返回对应的值对象。
Map 的常用实现类:HashMap、TreeMap、HashTable、LinkedHashMap、ConcurrentHashMap
继承关系图
HashMap、HashTable、TreeMap的区别
- TreeMap:基于红黑树实现。
- HashMap:基于哈希表实现。
- HashTable:和 HashMap 类似,但它是线程安全的,这意味着同一时刻多个线程可以同时写入 HashTable 并且不会导致数据不一致。它是遗留类,不应该去使用它。现在可以使用 ConcurrentHashMap 来支持线程安全,并且 ConcurrentHashMap 的效率会更高,因为 ConcurrentHashMap 引入了分段锁。
- LinkedHashMap:使用双向链表来维护元素的顺序,顺序为插入顺序或者最近最少使用(LRU)顺序。

HashMap底层
JDK1.7和JDK1.8

集合工具类Collections
Collections:集合工具类,方便对集合的操作。这个类不需要创建对象,内部提供的都是静态方法。
静态方法:
Collections.sort(list);//list集合进行元素的自然顺序排序。Collections.sort(list,new ComparatorByLen());//按指定的比较器方法排序。class ComparatorByLen implements Comparator<String>{public int compare(String s1,String s2){int temp = s1.length()-s2.length();return temp==0?s1.compareTo(s2):temp;}}Collections.max(list);//返回list中字典顺序最大的元素。int index = Collections.binarySearch(list,"zz");//二分查找,返回角标。Collections.reverseOrder();//逆向反转排序。Collections.shuffle(list);//随机对list中的元素进行位置的置换。//将非同步集合转成同步集合的方法:Collections中的 XXX synchronizedXXX(XXX);//原理:定义一个类,将集合所有的方法加同一把锁后返回。List synchronizedList(list);Map synchronizedMap(map);
Collection 和 Collections的区别
Collections是个java.util下的类,是针对集合类的一个工具类,提供一系列静态方法,实现对集合的查找、排序、替换、线程安全化(将非同步的集合转换成同步的)等操作。Collection是个java.util下的接口,它是各种集合结构的父接口,继承于它的接口主要有Set和List,提供了关于集合的一些操作,如插入、删除、判断一个元素是否其成员、遍历等。
Arrays<=> 集合
用于操作数组对象的工具类,里面都是静态方法。
数组 -> 集合:asList方法,将数组转换成list集合。
String[] arr ={"abc","kk","qq"};List<String> list =Arrays.asList(arr);//将arr数组转成list集合。
将数组转换成集合,有什么好处呢?用aslist方法,将数组变成集合;
可以通过list集合中的方法来操作数组中的元素:isEmpty()、contains、indexOf、set;注意(局限性):数组是固定长度,不可以使用集合对象增加或者删除等,会改变数组长度的功能方法。比如add、remove、clear。(会报不支持操作异常UnsupportedOperationException);如果数组中存储的引用数据类型,直接作为集合的元素可以直接用集合方法操作。如果数组中存储的是基本数据类型,asList会将数组实体作为集合元素存在。
集合 -> 数组:用的是Collection接口中的toArray()方法;
如果给toArray传递的指定类型的数据长度小于了集合的size,那么toArray方法,会自定再创建一个该类型的数据,长度为集合的size。如果传递的指定的类型的数组的长度大于了集合的size,那么toArray方法,就不会创建新数组,直接使用该数组即可,并将集合中的元素存储到数组中,其他为存储元素的位置默认值null。所以,在传递指定类型数组时,最好的方式就是指定的长度和size相等的数组。
将集合变成数组后有什么好处?限定了对集合中的元素进行增删操作,只要获取这些元素即可。
用基本数据类型的数组转换ArrayList,ArrayList的size有问题
public static void main(String[] args) {int[] arr1 = { 1, 2, 3, 4, 5 };List<int[]> intList = Arrays.asList(arr1);// intList size: 1System.out.println(String.format("intList size: %s", intList.size()));Integer[] arr2 = { 1, 2, 3, 4, 5 };List<Integer> integerList = Arrays.asList(arr2);// integerList size: 5System.out.println(String.format("integerList size:%s", integerList.size()));}
asList方法接受的参数是一个泛型的变长参数,我们知道基本数据类型是无法泛型化的,也就是说基本类型是无法作为asList方法的参数的, 要想作为泛型参数就必须使用其所对应的包装类型。但是这个这个实例中为什么没有出错呢?因为该实例是将int 类型的数组当做其参数,而在Java中数组是一个对象,它是可以泛型化的。所以该例子是不会产生错误的。既然例子是将整个int 类型的数组当做泛型参数,那么经过asList转换就只有一个int 的列表了.
结论:
在使用asList()时尽量不要将基本数据类型数组转List.
asList转换得到的ArrayList不是java.util.ArrayList
public static void main(String[] args) {String[] arr = {"abc", "kk", "qq"};List<String> list = Arrays.asList(arr);// 添加一个元素,抛出异常UnsupportedOperationExceptionlist.add("bb");}原因:
此处ArrayList是Arrays的内部类,并没有add方法,add方法是父类AbstractList的,但是没有具体实现,
而是直接抛出UnsupportedOperationException异常.

排序接口
Comparable 简介
Comparable 是排序接口。
若一个类实现了Comparable接口,就意味着“该类支持排序”。此外,“实现Comparable接口的类的对象”可以用作“有序映射(如TreeMap)”中的键或“有序集合(TreeSet)”中的元素,而不需要指定比较器。
接口中通过x.compareTo(y)来比较x和y的大小。若返回负数,意味着x比y小;返回零,意味着x等于y;返回正数,意味着x大于y。
Comparator 简介
Comparator 是比较器接口。我们若需要控制某个类的次序,而该类本身不支持排序(即没有实现Comparable接口);那么,我们可以建立一个“该类的比较器”来进行排序。这个“比较器”只需要实现Comparator接口即可。也就是说,我们可以通过“实现Comparator类来新建一个比较器”,然后通过该比较器对类进行排序。
int compare(T o1, T o2)和上面的x.compareTo(y)类似,定义排序规则后返回正数,零和负数分别代表大于,等于和小于。
两者的联系
Comparable相当于“内部比较器”,而Comparator相当于“外部比较器”。
代码实现
package com.github.compare;import java.util.ArrayList;import java.util.Collections;import java.util.Comparator;import java.util.List;/*** @ _ooOoo_* o8888888o* 88" . "88* (| -_- |)* O\ = /O* ____/`---'\____* .' \\| |// `.* / \\||| : |||// \* / _||||| -:- |||||- \* | | \\\ - /// | |* | \_| ''\---/'' | |* \ .-\__ `-` ___/-. /* ___`. .' /--.--\ `. . __* ."" '< `.___\_<|>_/___.' >'"".* | | : `- \`.;`\ _ /`;.`/ - ` : | |* \ \ `-. \_ __\ /__ _/ .-` / /* ======`-.____`-.___\_____/___.-`____.-'======* `=---='* ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^* 佛祖保佑 永无BUG*@DESCRIPTION Comparable是排序接口;若一个类实现了Comparable接口,就意味着“该类支持排序”。* Comparable相当于“内部比较器”*@AUTHOR SongHongWei*@TIME 2018/12/14-16:11*@PACKAGE_NAME com.github.compare**/public class ComparableAndCompartor{public static void main(String[] args){List<House> houses = new ArrayList();House h1 = new House(95.0, 12000);House h2 = new House(110.0, 12160);House h3 = new House(80.0, 16300);House h4 = new House(150.3, 10690);houses.add(h1);houses.add(h2);houses.add(h3);houses.add(h4);comparable(houses);comparator(houses);}/***@DESCRIPTION House类实现类Comparable接口, 并重写了compareTo方法, 所以执行Collections.sort方法时会去调用我们重写的compareTo方法*@AUTHOR SongHongWei*@TIME 2018/12/14-16:46*@CLASS_NAME ComparableAndCompartor**/private static void comparable(List houses){System.out.printf("未排序前的顺序,%s\n", houses);Collections.sort(houses);System.out.printf("按面积大小排序后的顺序,%s\n", houses);}private static void comparator(List houses){System.out.printf("未排序前的顺序,%s\n", houses);Collections.sort(houses, new ComparatorDetail());System.out.printf("按单价大小排序后的顺序,%s\n", houses);}/***@DESCRIPTION 实现Compatator接口, 并重写compare方法, 根据单价倒序排序*@AUTHOR SongHongWei*@TIME 2018/12/14-16:49*@CLASS_NAME ComparableAndCompartor**/static class ComparatorDetail implements Comparator<House>{@Overridepublic int compare(House o1, House o2){if (o1.price < o2.price)return 1;else if (o1.price > o2.price)return -1;return 0;}}}12345678910111213141516171819202122232425262728293031323334353637383940414243444546474849505152535455565758596061626364656667686970717273747576777879808182838485868788899091929394package com.github.compare;/*** @ _ooOoo_* o8888888o* 88" . "88* (| -_- |)* O\ = /O* ____/`---'\____* .' \\| |// `.* / \\||| : |||// \* / _||||| -:- |||||- \* | | \\\ - /// | |* | \_| ''\---/'' | |* \ .-\__ `-` ___/-. /* ___`. .' /--.--\ `. . __* ."" '< `.___\_<|>_/___.' >'"".* | | : `- \`.;`\ _ /`;.`/ - ` : | |* \ \ `-. \_ __\ /__ _/ .-` / /* ======`-.____`-.___\_____/___.-`____.-'======* `=---='* ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^* 佛祖保佑 永无BUG*@DESCRIPTION 一个房子对象, 有面积和单价两个属性*@AUTHOR SongHongWei*@TIME 2018/12/14-16:14*@PACKAGE_NAME com.github.compare**/public class House implements Comparable<House>{/*房子的面积*/protected double proportion;/*房子每平米的售价*/protected double price;public House(double proportion, double price){this.proportion = proportion;this.price = price;}/***@DESCRIPTION 重写compareTo方法, 利用房子的面积来进行大小比较*@AUTHOR SongHongWei*@TIME 2018/12/14-16:18*@CLASS_NAME House**/@Overridepublic int compareTo(House o){/*当前对象的面积大,返回正数*/if (this.proportion > o.proportion)return 1;/*当前面积小,返回负数*/else if (this.proportion < o.proportion)return -1;/*相等返回0*/return 0;}@Overridepublic String toString(){return "面积为" + proportion + "\t价格为" + price;}}1234567891011121314151617181920212223242526272829303132333435363738394041424344454647484950515253545556575859606162636465666768
附注
Collection与Collections的区别
Collection是集合类的上级接口,继承与他有关的接口主要有List和Set
Collections是针对集合类的一个帮助类,他提供一系列静态方法实现对各种集合的搜索、排序、线程安全等操作
public static void main(String args[]) {//注意List是实现Collection接口的List list = new ArrayList();double array[] = { 112, 111, 23, 456, 231 };for (int i = 0; i < array.length; i++) {list.add(new Double(array[i]));}Collections.sort(list); //把list按从小到大排序for (int i = 0; i < array.length; i++) {System.out.println(list.get(i));}// 结果:23.0 111.0 112.0 231.0 456.0}
Collections如何调用重写的compareTo方法的
集合框架中,Collections工具类支持两种排序方法:
Collections.sort(List<T> list);Collections.sort(List<T> list, Comparator<? super T> c)12
如果待排序的列表中是数字或者字符,可以直接使用Collections.sort(list);当需要排序的集合或数组不是单纯的数字型时,需要自己定义排序规则,实现一个Comparator比较器。
Collections调用Collections.sort(list)方法,方法传递一个List集合,这里要求,List泛型里面装的元素必须实现Compareable接口此外,列表中的所有元素都必须是可相互比较的(也就是说,对于列表中的任何 e1 和 e2 元素,e1.compareTo(e2) 不得抛出 ClassCastException)。Java源码里是这样写的All elements in the list must implement the {@link Comparable}interface.Furthermore, all elements in the list must be <i>mutually comparable</i> (that is, {@code e1.compareTo(e2)} must not throw a {@code ClassCastException} for any elements
Collections.sort源码
public static <T extends Comparable<? super T>> void sort(List<T> list) {Object[] a = list.toArray();Arrays.sort(a);ListIterator<T> i = list.listIterator();for (int j=0; j<a.length; j++) {i.next();i.set((T)a[j]);}}123456789
由源码可以看出来,sort内部调用了Arrays.sort的方法,继续向下看
Arrays.sort源码
public static void sort(Object[] a) {if (LegacyMergeSort.userRequested)legacyMergeSort(a);elseComparableTimSort.sort(a);}123456
源码里首先判断是否采用传统的排序方法,LegacyMergeSort.userRequested属性默认为false,也就是说默认选中 ComparableTimSort.sort(a)方法(传统归并排序在1.5及之前是默认排序方法,1.5之后默认执行ComparableTimSort.sort()方法。除非程序中强制要求使用传统归并排序,语句如下:System.setProperty("java.util.Arrays.useLegacyMergeSort", "true"))
继续看 ComparableTimSort.sort(a)源码
ComparableTimSort.sort(a)源码
static void sort(Object[] a) {sort(a, 0, a.length);}static void sort(Object[] a, int lo, int hi) {rangeCheck(a.length, lo, hi);int nRemaining = hi - lo;if (nRemaining < 2)return; // Arrays of size 0 and 1 are always sorted// If array is small, do a "mini-TimSort" with no mergesif (nRemaining < MIN_MERGE) {int initRunLen = countRunAndMakeAscending(a, lo, hi);binarySort(a, lo, hi, lo + initRunLen);return;}/*** March over the array once, left to right, finding natural runs,* extending short natural runs to minRun elements, and merging runs* to maintain stack invariant.*/ComparableTimSort ts = new ComparableTimSort(a);int minRun = minRunLength(nRemaining);do {// Identify next runint runLen = countRunAndMakeAscending(a, lo, hi);// If run is short, extend to min(minRun, nRemaining)if (runLen < minRun) {int force = nRemaining <= minRun ? nRemaining : minRun;binarySort(a, lo, lo + force, lo + runLen);runLen = force;}// Push run onto pending-run stack, and maybe mergets.pushRun(lo, runLen);ts.mergeCollapse();// Advance to find next runlo += runLen;nRemaining -= runLen;} while (nRemaining != 0);// Merge all remaining runs to complete sortassert lo == hi;ts.mergeForceCollapse();assert ts.stackSize == 1;}12345678910111213141516171819202122232425262728293031323334353637383940414243444546474849
nRemaining表示没有排序的对象个数,方法执行前,如果这个数小于2,就不需要排序了。
如果2<= nRemaining <=32,即MIN_MERGE的初始值,表示需要排序的数组是小数组,可以使用mini-TimSort方法进行排序,否则需要使用归并排序。
mini-TimSort排序方法:先找出数组中从下标为0开始的第一个升序序列,或者找出降序序列后转换为升序重新放入数组,将这段升序数组作为初始数组,将之后的每一个元素通过二分法排序插入到初始数组中。注意,这里就调用到了我们重写的compareTo()方法了。
private static int countRunAndMakeAscending(Object[] a, int lo, int hi) {assert lo < hi;int runHi = lo + 1;if (runHi == hi)return 1;// Find end of run, and reverse range if descendingif (((Comparable) a[runHi++]).compareTo(a[lo]) < 0) { // Descendingwhile (runHi < hi && ((Comparable) a[runHi]).compareTo(a[runHi - 1]) < 0)runHi++;reverseRange(a, lo, runHi);} else { // Ascendingwhile (runHi < hi && ((Comparable) a[runHi]).compareTo(a[runHi - 1]) >= 0)runHi++;}return runHi - lo;}
Stream
不可变集合
- static List of(E…elements) 创建一个具有指定元素的List集合对象
- static Set of(E…elements) 创建一个具有指定元素的Set集合对象
- static
Map of(E…elements) 创建一个具有指定元素的Map集合对象
Stream
Stream是Java8中处理集合的关键抽象概念,Stream API提供了一种高效且易于使用的处理数据的方式。你可以使用它对集合数据进行指定操作,如可以执行非常复杂的查找、过滤和映射数据等操作。
注意:
- Stream自己不会存储元素
- Stream不会改变源对象,Stream操作会返回一个新的Stream
- Stream操作是延迟执行的,这意味着等到获取结果时,Stream才会执行
Stream操作的三个步骤:
- Stream创建,由一个数据源,如集合、数组来获取一个Stream
- 中间操作。一个中间操作链,对数据源的数据进行处理
- 终止操作。执行中间操作链并产生结果。
Stream的操作步骤示例图:
Stream的创建
1.使用集合来创建Stream
Java8中的Collection接口被扩展,提供了两个获取Stream的方法:
//返回一个顺序流default Stream<R> stream()//返回一个并行流default Stream<E> parallelStream()1234
2.使用数组创建Stream
Java8中的Arrays的静态方法stream()可以获取流
static <T> Stream<T> stream(T[] array)static IntStream<T> stream(int[] array)static LongStream<T> stream(long[] array)static DoubleStream<T> stream(double[] array)1234
3.由值创建Stream
使用Stream的静态方法of来创建一个流,该方法可以接收任意数量的参数。
static<T> Stream<T> of(T... values)1
4.由函数创建Stream
可以使用Stream的静态方法iterate()和generate()创建无限流
public static<T> Stream<T> iterate(final T seed, final UnaryOperator<T> f)public static<T> Stream<T> generate(Supplier<T> s)12
Stream创建代码示例:
@Testpublic void test01(){//1.通过Collection系列集合提供的stream()或parallelStream()获取ArrayList<String> list = new ArrayList<>();Stream<String> stream1 = list.stream();//2.通过Arrays中的静态方法stream()获取String[] strings=new String[10];Stream<String> stream2 = Arrays.stream(strings);//3.通过Stream类中的静态方法of()获取Stream<String> stream3 = Stream.of(strings);//4.创建无限流//4.1迭代Stream<Integer> stream4 = Stream.iterate(0, x-> x + 2);//4.2生成Stream<Double> stream5 = Stream.generate(() -> Math.random());}12345678910111213141516
Stream的中间操作
多个中间操作可以连接起来形成一个流水线,除非流水线上触发终止操作,否则中间操作不会执行任何处理,而是在种植操作时一次性全部处理,称为“惰性求值”。
1.筛选与切片
筛选与切片的相关方法介绍: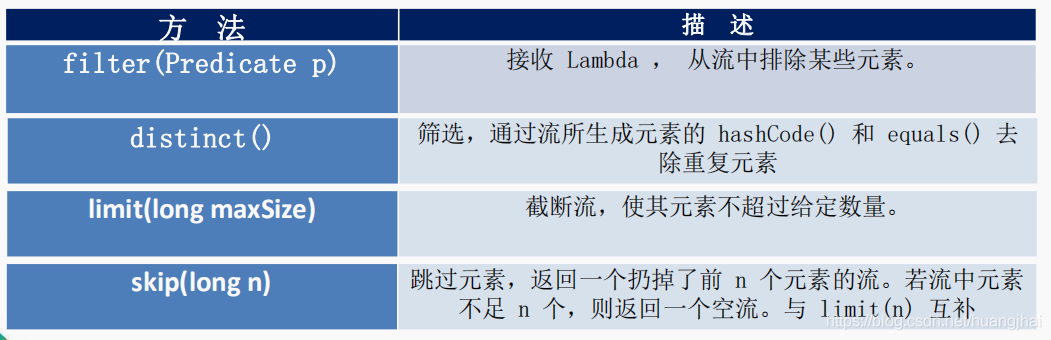
使用示例
创建一个Employee类用于后续使用:
public class Employee {private Integer id;private String name;private Integer age;private State state;public Employee(Integer id, String name, Integer age, State state) {this.id = id;this.name = name;this.age = age;this.state = state;}@Overridepublic Employee(){}public Employee(Integer id) {this.id = id;}public Employee(Integer id, Integer age) {this.id = id;this.age = age;}public Employee(int id, String name, int age) {this.id = id;this.name = name;this.age = age;}@Overridepublic boolean equals(Object o) {if (this == o) return true;if (o == null || getClass() != o.getClass()) return false;Employee employee = (Employee) o;return Objects.equals(id, employee.id) &&Objects.equals(name, employee.name) &&Objects.equals(age, employee.age) &&state == employee.state;}@Overridepublic int hashCode() {return Objects.hash(id, name, age, state);}//省略getter、setter、toString方法}
State枚举类的定义
public enum State {BUSY,FREE,VACATION}
filter方法——接收Lambda,从流中排除某些元素
public class TestStreamAPI02 {List<Employee> employees=Arrays.asList(new Employee(1,"张三",60),new Employee(2,"李四",50),new Employee(3,"王五",45),new Employee(26,"赵六",45),new Employee(26,"赵六",45),new Employee(26,"赵六",45));//filter——接收Lambda,从流中排除某些元素@Testpublic void test01(){//中间操作:不会执行任何操作Stream<Employee> stream = employees.stream().filter((employee -> {System.out.println("执行过滤操作");return employee.getAge() > 45;}));//终止操作:一次性执行全部内容,即“惰性求值”stream.forEach(System.out::println);}}
控制台输出结果:
limit——截断流,使其元素不超过给定数量
@Testpublic void test02(){employees.stream().filter(e->e.getAge()>18).limit(3).forEach(System.out::println);}1234567
控制台输出结果:
skip–跳过元素,返回一个扔掉了前n个元素的流,若流中的元素不足n个,则返回空流。与limit互补。
@Testpublic void test03(){employees.stream().skip(2).forEach(System.out::println);}
控制台输出结果:
distinct–筛选,去取流中的hashcode()和equals相同的元素
@Testpublic void test04(){employees.stream().distinct().forEach(System.out::println);}
Employee类中重写了hashcode()和equals()方法根据id, name, age, state属性进行比较计算对象是否相等,以此控制台输出结果: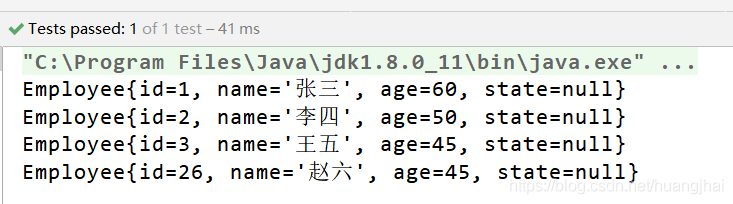
2.映射
映射相关方法如下: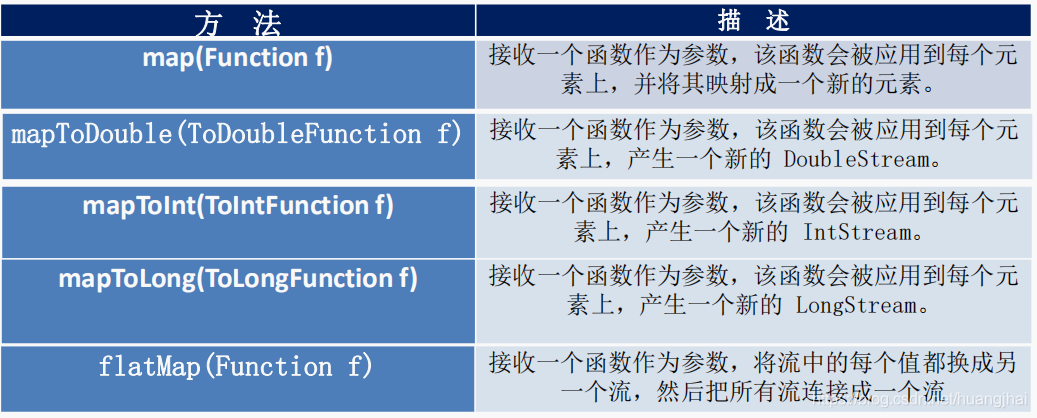
使用示例
map方法——接收Lambda,将元素转化成其他形式或提取信息。接收一个函数作为参数, 该函数会被应用到每个元素上,并将其映射成一个新的元素。
public class TestStreamAPI03 {List<Employee> employees=Arrays.asList(new Employee(1,"张三",60),new Employee(2,"李四",50),new Employee(3,"王五",45),new Employee(26,"赵六",45),new Employee(26,"赵六",45),new Employee(26,"赵六",45));@Testpublic void test01(){List<String> list = Arrays.asList("a", "bb", "ccc", "dddd");//将list中元素转化成其他形式list.stream().map(s->s.toUpperCase()).forEach(System.out::print);//原集合不受到影响list.forEach(System.out::print);//提取list中元素的信息employees.stream().map(employee -> employee.getName()).forEach(System.out::print);}}
控制台输出结果:
flatMap方法–接收一个函数作为参数,将流中的每个值都换成另一个流,然后把所有流连接成一个流
public class TestStreamAPI03 {List<Employee> employees=Arrays.asList(new Employee(1,"张三",60),new Employee(2,"李四",50),new Employee(3,"王五",45),new Employee(26,"赵六",45),new Employee(26,"赵六",45),new Employee(26,"赵六",45));//提取字符串中的每个字符到list中,并放入stream流public static Stream<Character> filterCharacter(String str){ArrayList<Character> list = new ArrayList<>();for (Character ch:str.toCharArray()) {list.add(ch);}return list.stream();}//测试flatMap@Testpublic void test02(){List<String> list = Arrays.asList("a", "bb", "ccc", "dddd");Stream<Stream<Character>> streams = list.stream().map(TestStreamAPI03::filterCharacter);//得到的流的形式类似{{a},{b,b},{c,c,c},{d,d,d,d}}//不使用flatMap函数System.out.println("不使用flatMap函数");streams.forEach(stream->stream.forEach(System.out::print));//使用flatMap函数System.out.println("\n使用flatMap函数");Stream<Character> streams2 = list.stream().flatMap(TestStreamAPI03::filterCharacter);//得到流的形式类似{a,b,b,c,c,c,d,d,d,d}streams2.forEach(System.out::print);}}
控制台输出结果:
3.排序
排序的相关方法:
使用示例:
sorted()–产生一个新流,自然排序(Comparable)
public class TestStreamAPI04 {List<Employee> employees=Arrays.asList(new Employee(1,"张三",60),new Employee(2,"李四",50),new Employee(3,"王五",45),new Employee(23,"赵六",45),new Employee(21,"田七",45),new Employee(24,"天启",45));@Testpublic void test01(){List<String> list = Arrays.asList("ddd", "ccc", "bbb", "aaa");//默认使用泛型的实现Comparable接口中的compareTo方法进行比较list.stream().sorted().forEach(System.out::println);}}
sorted(Comparator com)–产生一个新流,定制排序(Comparator)
@Testpublic void test02(){employees.stream().sorted((e1,e2)->{if (e1.getAge().equals(e2.getAge())){return e1.getId().compareTo(e2.getId());}else{return e1.getAge().compareTo(e2.getAge());}}).forEach(System.out::println);}
Stream的终止操作
终端操作会从stream的流水线生成结果,其结果可以不是流的值,可以是List,Integer,甚至是Void。
1.查找与匹配
查找与匹配的相关方法: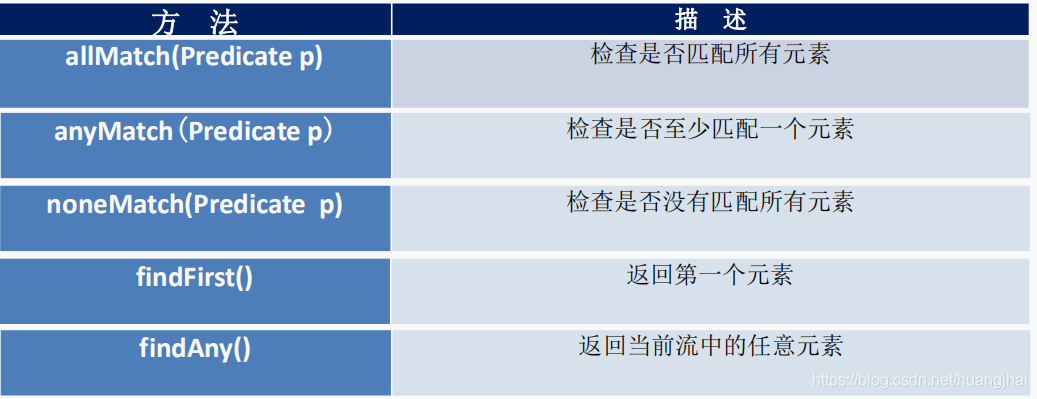
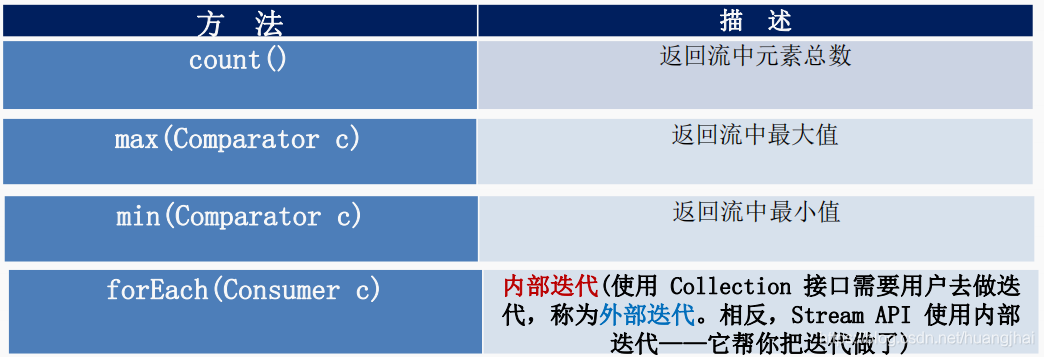
测试 allMatch,anyMatch,noneMatch方法的使用
public class TestStreamAPI05 {List<Employee> employees=Arrays.asList(new Employee(1,"张三",60),new Employee(2,"李四",50, State.BUSY),new Employee(3,"王五",45,State.BUSY),new Employee(23,"赵六",45,State.FREE),new Employee(21,"田七",40,State.VACATION),new Employee(24,"天启",35,State.FREE));//测试allMatch,anyMatch,noneMatch@Testpublic void test01(){boolean allMatch = employees.stream().allMatch(e -> e.getAge() >= 45);System.out.println(allMatch);boolean anyMatch = employees.stream().anyMatch((e -> e.getAge() > 65));System.out.println(anyMatch);boolean noneMatch = employees.stream().noneMatch((e -> e.getAge() > 65));System.out.println(noneMatch);}}
控制台输出结果:
测试findFirst,findAny方法的使用
//测试findFirst,findAny@Testpublic void test02(){Optional<Employee> first = employees.stream().sorted((e1, e2) -> e1.getAge().compareTo(e2.getAge())).findFirst();System.out.println(first.get());Optional<Employee> any = employees.stream().filter(e -> e.getState()==State.FREE).findAny();System.out.println(any.get());}12345678910
控制台输出结果:
测试count,max,min方法的使用
//测试count,max,min@Testpublic void test03(){//测试countlong count = employees.stream().count();System.out.println(count);//测试maxOptional<Employee> max = employees.stream().max((e1, e2) -> e1.getAge().compareTo(e2.getAge()));System.out.println(max.get());//测试minOptional<Employee> min = employees.stream().min((e1, e2) -> e1.getAge().compareTo(e2.getAge()));System.out.println(min.get());}12345678910111213
控制台输出的结果: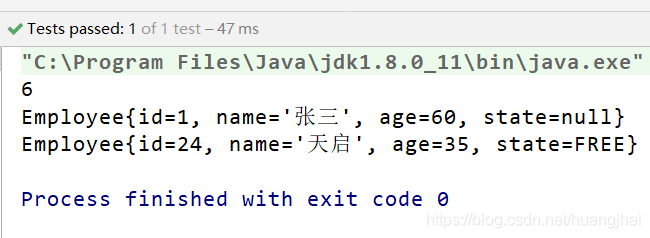
2.规约
规约相关方法:
测试reduce(T identity,BinaryOperator)和reduce(BinaryOperator),其中identity为原始的结合值。
public class TestStreamAPI06 {List<Employee> employees=Arrays.asList(new Employee(1,"张三",60),new Employee(2,"李四",50, State.BUSY),new Employee(3,"王五",45,State.BUSY),new Employee(23,"赵六",45,State.FREE),new Employee(21,"田七",40,State.VACATION),new Employee(24,"天启",35,State.FREE));@Testpublic void test01(){//计算整数数组累加List<Integer> integers = Arrays.asList(1, 2, 3, 4, 5, 6, 7, 8, 9, 10);Integer result = integers.stream().reduce(5, (x, y) -> x + y);System.out.println(result);//计算平均年龄Optional<Integer> ageTotal = employees.stream().map(Employee::getAge).reduce(Integer::sum);long empNum=employees.stream().count();System.out.println(ageTotal.get()/empNum);}}12345678910111213141516171819
控制台输出结果: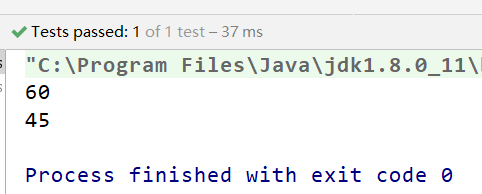
3.收集
收集的方法定义
Collector接口中的方法的实现决定了如何对流执行收集操作(如收集到List、Set、Map)。Collectors实用类提供了很多静态方法,可以方便地创建常用的收集器实例,具体方法与实例如下图: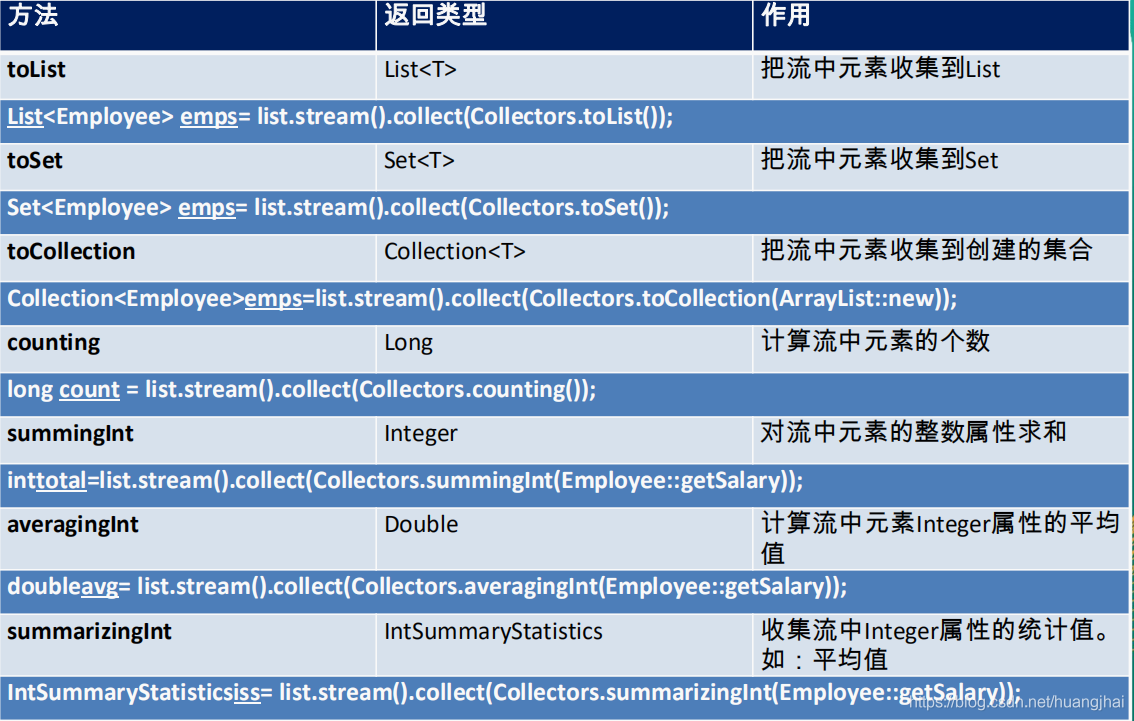

测试将流转换为其他形式,收集到新的集合上,包括Collectors.toList()、Collectors.toSet()、Collectors.toCollection(集合对象)
List<Employee> employees=Arrays.asList(new Employee(1,"张三",60,State.VACATION),new Employee(2,"李四",50, State.BUSY),new Employee(3,"王五",45,State.BUSY),new Employee(23,"赵六",45,State.FREE),new Employee(23,"赵六",45,State.FREE),new Employee(21,"田七",40,State.VACATION),new Employee(24,"天启",35,State.FREE));@Testpublic void test01(){List<String> list = employees.stream().map(Employee::getName).collect(Collectors.toList());list.forEach(System.out::println);System.out.println("-----------------");Set<String> set = employees.stream().map(Employee::getName).collect(Collectors.toSet());set.forEach(System.out::println);System.out.println("-----------------");HashSet<String> hashSet = employees.stream().map(Employee::getName).collect(Collectors.toCollection(HashSet::new));hashSet.forEach(System.out::println);}}12345678910111213141516171819
数组统计相关方法,包括counting、averagingDouble、summingInt等方法。
@Testpublic void test02(){//总数Long sum= employees.stream().collect(Collectors.counting());System.out.println(sum);//平均值Double averageAge = employees.stream().collect(Collectors.averagingDouble(Employee::getAge));System.out.println(averageAge);//某属性的综合Integer ageSum = employees.stream().collect(Collectors.summingInt(Employee::getAge));System.out.println(ageSum);//最大值Optional<Employee> maxAgeEmployee = employees.stream().collect(Collectors.maxBy((e1, e2) -> e1.getAge().compareTo(e2.getAge())));System.out.println(maxAgeEmployee.get());//最小值Optional<Employee> minAgeEmployee = employees.stream().collect(Collectors.minBy((e1, e2) -> e1.getAge().compareTo(e2.getAge())));System.out.println(minAgeEmployee.get());//所有数据IntSummaryStatistics totalData = employees.stream().collect(Collectors.summarizingInt(Employee::getAge));System.out.println(totalData);}123456789101112131415161718192021
控制台输出结果: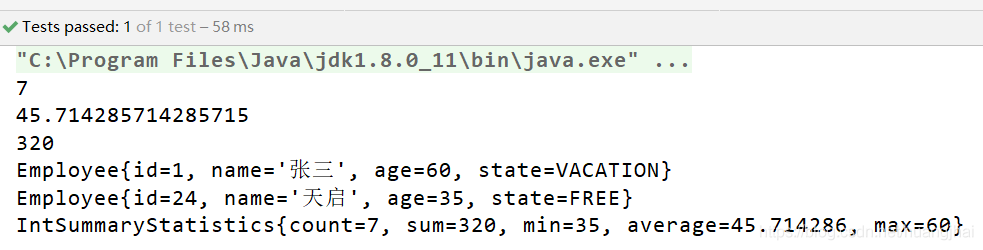
测试分组groupingBy方法
@Testpublic void test03(){Map<State, List<Employee>> stateListMap = employees.stream().collect(Collectors.groupingBy(Employee::getState));System.out.println(stateListMap);}12345
程序输出结果:
{FREE=[Employee{id=23, name='赵六', age=45, state=FREE}, Employee{id=23, name='赵六', age=45, state=FREE}, Employee{id=24, name='天启', age=35, state=FREE}], VACATION=[Employee{id=1, name='张三', age=60, state=VACATION}, Employee{id=21, name='田七', age=40, state=VACATION}], BUSY=[Employee{id=2, name='李四', age=50, state=BUSY}, Employee{id=3, name='王五', age=45, state=BUSY}]}1
测试多级分组:
@Testpublic void test04(){Map<State, Map<String, List<Employee>>> collect = employees.stream().collect(Collectors.groupingBy(Employee::getState, Collectors.groupingBy((e) -> {if (((Employee) e).getAge() <= 30) {return "青年";} else if (((Employee) e).getAge() <= 50) {return "中年";} else {return "老年";}})));System.out.println(collect);}1234567891011121314
控制台输出结果:
{VACATION={老年=[Employee{id=1, name='张三', age=60, state=VACATION}], 中年=[Employee{id=21, name='田七', age=40, state=VACATION}]}, FREE={中年=[Employee{id=23, name='赵六', age=45, state=FREE}, Employee{id=23, name='赵六', age=45, state=FREE}, Employee{id=24, name='天启', age=35, state=FREE}]}, BUSY={中年=[Employee{id=2, name='李四', age=50, state=BUSY}, Employee{id=3, name='王五', age=45, state=BUSY}]}}1
测试分区方法partitioningBy,接收Predicate,满足属于true,不满足就属于false。
//分区@Testpublic void test08(){Map<Boolean, List<Employee>> collect = employees.stream().collect(Collectors.partitioningBy(employee -> employee.getAge() > 40));System.out.println(collect);}1234567
程序输出结果:
{false=[Employee{id=21, name='田七', age=40, state=VACATION}, Employee{id=24, name='天启', age=35, state=FREE}], true=[Employee{id=1, name='张三', age=60, state=VACATION}, Employee{id=2, name='李四', age=50, state=BUSY}, Employee{id=3, name='王五', age=45, state=BUSY}, Employee{id=23, name='赵六', age=45, state=FREE}, Employee{id=23, name='赵六', age=45, state=FREE}]}1
笔记总结自:https://www.bilibili.com/video/BV14W411u7Ly?from=search&seid=6050719224094931659
异常
- 体系
- 编译时异常
- 常见场景
- 运行时异常
- 常见场景
- 默认处理流程
- 自定义异常
日志框架
- 体系结构
- Logback
- Logbac-core
- Logback-classic
- Logbac-access
- logback.xml配置
File、递归
FIle类
file类常用API
- 判断文件类型、获取文件信息
- 创建文件、删除文件功能
- 遍历文件夹
方法递归
- ……
- 文件搜索案例
IO流
字符集
- 常见字符集
- 编码解码
字节流
- 字节输入流InputStream
- FIleInputStream
- 字节输出流OutStream
- FileOutputStream
- 资源释放
- trycatch-finally
- trycatch-resource
字符流
- 字符输入流Reader
- FileReader
- 一次读取一个字符
- 一次读取一个字符数组
- FileReader
- 字符输出流Writer
- FileWriter
缓冲流
- 字节缓冲输入流BufferedInputStream
- BufferedOutputStream
- BufferedReader
- BufferedWriter
转换流
- 字符输入转换流InputStreamReader
- OutputStreamReader
序列化
- 对象序列化
- ObjectOutputStream
- 对象反序列化
- ObjectInputStream
打印流
- PrintStream
- PrintWriter
- 输出语句重定向
properties
l Properties代表的是一个属性文件,可以把自己对象中的键值对信息存入到一个属性文件中去。
属性文件:后缀是.properties结尾的文件,里面的内容都是 key=value,后续做系统配置信息的。
commons-io框架
- String readFileToString(File file, String encoding) 读取文件中的数据, 返回字符串
- void copyFile(File srcFile, File destFile) 复制文件。
- void copyDirectoryToDirectory(File srcDir, File destDir) 复制文件夹。
多线程
网络编程
单元测试
反射
注解
代理
反射
反射不会用于常规开发,但关键时刻,还是有用的,技多不压身
一、Java 反射机制
参考了许多博文,总结了以下个人观点,若有不妥还望指正:
Java 反射机制在程序运行时,对于任意一个类,都能够知道这个类的所有属性和方法;对于任意一个对象,都能够调用它的任意一个方法和属性。这种 动态的获取信息 以及 动态调用对象的方法 的功能称为 java 的反射机制。
反射机制很重要的一点就是“运行时”,其使得我们可以在程序运行时加载、探索以及使用编译期间完全未知的
.class文件。换句话说,Java 程序可以加载一个运行时才得知名称的.class文件,然后获悉其完整构造,并生成其对象实体、或对其 fields(变量)设值、或调用其 methods(方法)。
不知道上面的理论你能否明白,反正刚接触反射时我一脸懵比,后来写了几个例子之后:哦~~原来是这个意思!
若暂时不明白理论没关系,先往下看例子,之后再回来看相信你就能明白了。
二、使用反射获取类的信息
为使得测试结果更加明显,我首先定义了一个 FatherClass 类(默认继承自 Object 类),然后定义一个继承自 FatherClass 类的 SonClass 类,如下所示。可以看到测试类中变量以及方法的访问权限不是很规范,是为了更明显得查看测试结果而故意设置的,实际项目中不提倡这么写。
FatherClass.java
public class FatherClass {public String mFatherName;public int mFatherAge;public void printFatherMsg(){}}
SonClass.java
public class SonClass extends FatherClass{private String mSonName;protected int mSonAge;public String mSonBirthday;public void printSonMsg(){System.out.println("Son Msg - name : "+ mSonName + "; age : " + mSonAge);}private void setSonName(String name){mSonName = name;}private void setSonAge(int age){mSonAge = age;}private int getSonAge(){return mSonAge;}private String getSonName(){return mSonName;}}
1. 获取类的所有变量信息
/*** 通过反射获取类的所有变量*/private static void printFields(){//1.获取并输出类的名称Class mClass = SonClass.class;System.out.println("类的名称:" + mClass.getName());//2.1 获取所有 public 访问权限的变量// 包括本类声明的和从父类继承的Field[] fields = mClass.getFields();//2.2 获取所有本类声明的变量(不问访问权限)//Field[] fields = mClass.getDeclaredFields();//3. 遍历变量并输出变量信息for (Field field :fields) {//获取访问权限并输出int modifiers = field.getModifiers();System.out.print(Modifier.toString(modifiers) + " ");//输出变量的类型及变量名System.out.println(field.getType().getName()+ " " + field.getName());}}
以上代码注释很详细,就不再解释了。需要注意的是注释中 2.1 的 getFields() 与 2.2的 getDeclaredFields() 之间的区别,下面分别看一下两种情况下的输出。看之前强调一下: SonClass extends FatherClass extends Object :
- 调用
getFields()方法,输出SonClass类以及其所继承的父类( 包括FatherClass和Object) 的public方法。注:Object类中没有成员变量,所以没有输出。类的名称:obj.SonClasspublic java.lang.String mSonBirthdaypublic java.lang.String mFatherNamepublic int mFatherAge
- 调用
getDeclaredFields(), 输出SonClass类的所有成员变量,不问访问权限。类的名称:obj.SonClassprivate java.lang.String mSonNameprotected int mSonAgepublic java.lang.String mSonBirthday
2. 获取类的所有方法信息
/*** 通过反射获取类的所有方法*/private static void printMethods(){//1.获取并输出类的名称Class mClass = SonClass.class;System.out.println("类的名称:" + mClass.getName());//2.1 获取所有 public 访问权限的方法//包括自己声明和从父类继承的Method[] mMethods = mClass.getMethods();//2.2 获取所有本类的的方法(不问访问权限)//Method[] mMethods = mClass.getDeclaredMethods();//3.遍历所有方法for (Method method :mMethods) {//获取并输出方法的访问权限(Modifiers:修饰符)int modifiers = method.getModifiers();System.out.print(Modifier.toString(modifiers) + " ");//获取并输出方法的返回值类型Class returnType = method.getReturnType();System.out.print(returnType.getName() + " "+ method.getName() + "( ");//获取并输出方法的所有参数Parameter[] parameters = method.getParameters();for (Parameter parameter:parameters) {System.out.print(parameter.getType().getName()+ " " + parameter.getName() + ",");}//获取并输出方法抛出的异常Class[] exceptionTypes = method.getExceptionTypes();if (exceptionTypes.length == 0){System.out.println(" )");}else {for (Class c : exceptionTypes) {System.out.println(" ) throws "+ c.getName());}}}}
同获取变量信息一样,需要注意注释中 2.1 与 2.2 的区别,下面看一下打印输出:
- 调用
getMethods()方法 获取SonClass类所有public访问权限的方法,包括从父类继承的。打印信息中,printSonMsg()方法来自SonClass类,printFatherMsg()来自FatherClass类,其余方法来自 Object 类。类的名称:obj.SonClasspublic void printSonMsg( )public void printFatherMsg( )public final void wait( ) throws java.lang.InterruptedExceptionpublic final void wait( long arg0,int arg1, ) throws java.lang.InterruptedExceptionpublic final native void wait( long arg0, ) throws java.lang.InterruptedExceptionpublic boolean equals( java.lang.Object arg0, )public java.lang.String toString( )public native int hashCode( )public final native java.lang.Class getClass( )public final native void notify( )public final native void notifyAll( )
- 调用
getDeclaredMethods()方法
打印信息中,输出的都是SonClass类的方法,不问访问权限。类的名称:obj.SonClassprivate int getSonAge( )private void setSonAge( int arg0, )public void printSonMsg( )private void setSonName( java.lang.String arg0, )private java.lang.String getSonName( )
三、访问或操作类的私有变量和方法
在上面,我们成功获取了类的变量和方法信息,验证了在运行时 动态的获取信息 的观点。那么,仅仅是获取信息吗?我们接着往后看。
都知道,对象是无法访问或操作类的私有变量和方法的,但是,通过反射,我们就可以做到。没错,反射可以做到!下面,让我们一起探讨如何利用反射访问 类对象的私有方法 以及修改 私有变量或常量。
老规矩,先上测试类。
注:
- 请注意看测试类中变量和方法的修饰符(访问权限);
- 测试类仅供测试,不提倡实际开发时这么写 : )
TestClass.java
public class TestClass {private String MSG = "Original";private void privateMethod(String head , int tail){System.out.print(head + tail);}public String getMsg(){return MSG;}}
3.1 访问私有方法
以访问 TestClass 类中的私有方法 privateMethod(...) 为例,方法加参数是为了考虑最全的情况,很贴心有木有?先贴代码,看注释,最后我会重点解释部分代码。
/*** 访问对象的私有方法* 为简洁代码,在方法上抛出总的异常,实际开发别这样*/private static void getPrivateMethod() throws Exception{//1. 获取 Class 类实例TestClass testClass = new TestClass();Class mClass = testClass.getClass();//2. 获取私有方法//第一个参数为要获取的私有方法的名称//第二个为要获取方法的参数的类型,参数为 Class...,没有参数就是null//方法参数也可这么写 :new Class[]{String.class , int.class}Method privateMethod =mClass.getDeclaredMethod("privateMethod", String.class, int.class);//3. 开始操作方法if (privateMethod != null) {//获取私有方法的访问权//只是获取访问权,并不是修改实际权限privateMethod.setAccessible(true);//使用 invoke 反射调用私有方法//privateMethod 是获取到的私有方法//testClass 要操作的对象//后面两个参数传实参privateMethod.invoke(testClass, "Java Reflect ", 666);}}
需要注意的是,第3步中的 setAccessible(true) 方法,是获取私有方法的访问权限,如果不加会报异常 IllegalAccessException,因为当前方法访问权限是“private”的,如下:
java.lang.IllegalAccessException: Class MainClass can not access a member of class obj.TestClass with modifiers "private"
正常运行后,打印如下,调用私有方法成功:
Java Reflect 666
3.2 修改私有变量
以修改 TestClass 类中的私有变量 MSG 为例,其初始值为 “Original” ,我们要修改为 “Modified”。老规矩,先上代码看注释。
/*** 修改对象私有变量的值* 为简洁代码,在方法上抛出总的异常*/private static void modifyPrivateFiled() throws Exception {//1. 获取 Class 类实例TestClass testClass = new TestClass();Class mClass = testClass.getClass();//2. 获取私有变量Field privateField = mClass.getDeclaredField("MSG");//3. 操作私有变量if (privateField != null) {//获取私有变量的访问权privateField.setAccessible(true);//修改私有变量,并输出以测试System.out.println("Before Modify:MSG = " + testClass.getMsg());//调用 set(object , value) 修改变量的值//privateField 是获取到的私有变量//testClass 要操作的对象//"Modified" 为要修改成的值privateField.set(testClass, "Modified");System.out.println("After Modify:MSG = " + testClass.getMsg());}}
此处代码和访问私有方法的逻辑差不多,就不再赘述,从输出信息看出 修改私有变量 成功:
Before Modify:MSG = OriginalAfter Modify:MSG = Modified
3.3 修改私有常量
在 3.2 中,我们介绍了如何修改私有 变量,现在来说说如何修改私有 常量,
01. 真的能修改吗?
常量是指使用 final 修饰符修饰的成员属性,与变量的区别就在于有无 final 关键字修饰。在说之前,先补充一个知识点。
Java 虚拟机(JVM)在编译 .java 文件得到 .class 文件时,会优化我们的代码以提升效率。其中一个优化就是:JVM 在编译阶段会把引用常量的代码替换成具体的常量值,如下所示(部分代码)。
编译前的 .java 文件:
//注意是 String 类型的值private final String FINAL_VALUE = "hello";if(FINAL_VALUE.equals("world")){//do something}
编译后得到的 .class 文件(当然,编译后是没有注释的):
private final String FINAL_VALUE = "hello";//替换为"hello"if("hello".equals("world")){//do something}
但是,并不是所有常量都会优化。经测试对于 int 、long 、boolean 以及 String 这些基本类型 JVM 会优化,而对于 Integer 、Long 、Boolean 这种包装类型,或者其他诸如 Date 、Object 类型则不会被优化。
总结来说:对于基本类型的静态常量,JVM 在编译阶段会把引用此常量的代码替换成具体的常量值。
这么说来,在实际开发中,如果我们想修改某个类的常量值,恰好那个常量是基本类型的,岂不是无能为力了?反正我个人认为除非修改源码,否则真没办法!
这里所谓的无能为力是指:我们在程序运行时刻依然可以使用反射修改常量的值(后面会代码验证),但是 JVM 在编译阶段得到的 .class 文件已经将常量优化为具体的值,在运行阶段就直接使用具体的值了,所以即使修改了常量的值也已经毫无意义了。
下面我们验证这一点,在测试类 TestClass 类中添加如下代码:
//String 会被 JVM 优化private final String FINAL_VALUE = "FINAL";public String getFinalValue(){//剧透,会被优化为: return "FINAL" ,拭目以待吧return FINAL_VALUE;}
接下来,是修改常量的值,先上代码,请仔细看注释:
/*** 修改对象私有常量的值* 为简洁代码,在方法上抛出总的异常,实际开发别这样*/private static void modifyFinalFiled() throws Exception {//1. 获取 Class 类实例TestClass testClass = new TestClass();Class mClass = testClass.getClass();//2. 获取私有常量Field finalField = mClass.getDeclaredField("FINAL_VALUE");//3. 修改常量的值if (finalField != null) {//获取私有常量的访问权finalField.setAccessible(true);//调用 finalField 的 getter 方法//输出 FINAL_VALUE 修改前的值System.out.println("Before Modify:FINAL_VALUE = "+ finalField.get(testClass));//修改私有常量finalField.set(testClass, "Modified");//调用 finalField 的 getter 方法//输出 FINAL_VALUE 修改后的值System.out.println("After Modify:FINAL_VALUE = "+ finalField.get(testClass));//使用对象调用类的 getter 方法//获取值并输出System.out.println("Actually :FINAL_VALUE = "+ testClass.getFinalValue());}}
上面的代码不解释了,注释巨详细有木有!特别注意一下第3步的注释,然后来看看输出,已经迫不及待了,擦亮双眼:
Before Modify:FINAL_VALUE = FINALAfter Modify:FINAL_VALUE = ModifiedActually :FINAL_VALUE = FINAL
结果出来了:
第一句打印修改前 FINAL_VALUE 的值,没有异议;
第二句打印修改后常量的值,说明FINAL_VALUE确实通过反射修改了;
第三句打印通过 getFinalValue() 方法获取的 FINAL_VALUE 的值,但还是初始值,导致修改无效!
这结果你觉得可信吗?什么,你还不信?问我怎么知道 JVM 编译后会优化代码?那要不这样吧,一起来看看 TestClass.java 文件编译后得到的 TestClass.class 文件。为避免说代码是我自己手写的,我决定不粘贴代码,直接截图:
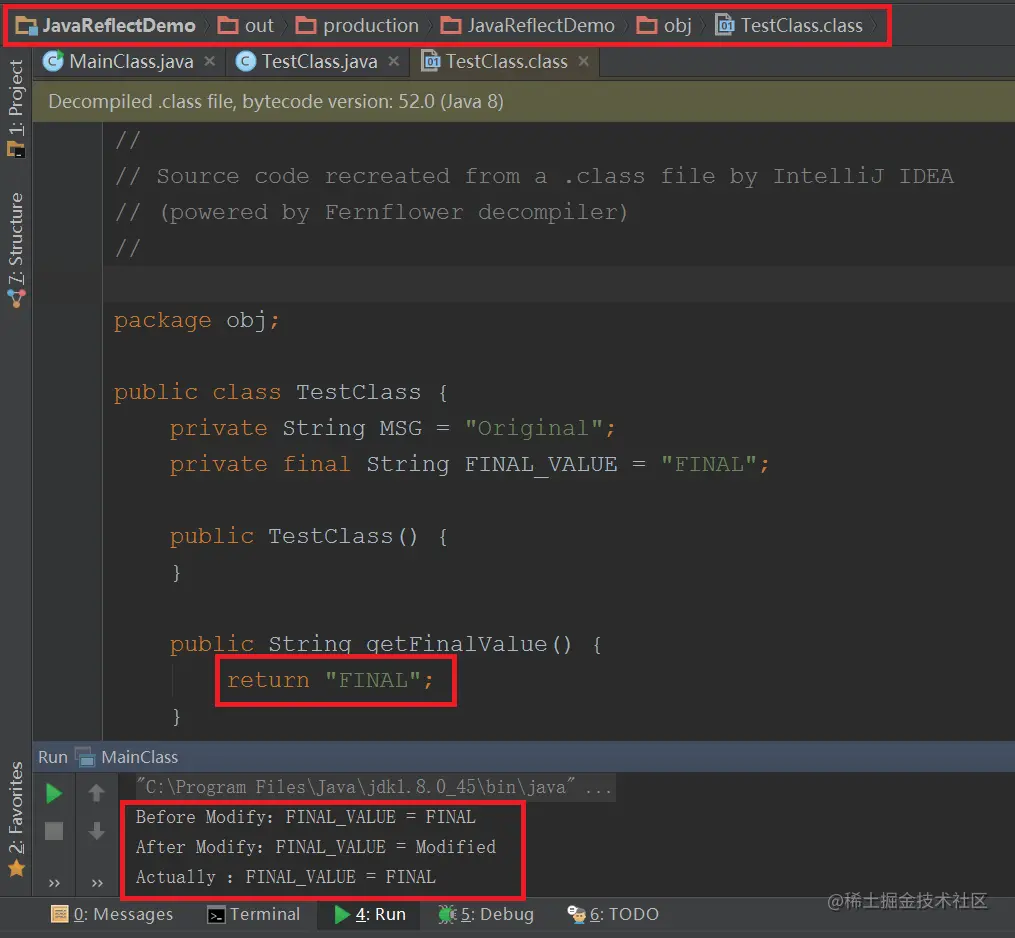
看到了吧,有图有真相,getFinalValue() 方法直接 return "FINAL"!同时也说明了,程序运行时是根据编译后的 .class 来执行的。
顺便提一下,如果你有时间,可以换几个数据类型试试,正如上面说的,有些数据类型是不会优化的。你可以修改数据类型后,根据我的思路试试,看输出觉得不靠谱就直接看 .classs 文件,一眼就能看出来哪些数据类型优化了 ,哪些没有优化。下面说下一个知识点。
02. 想办法也要修改!
不能修改,这你能忍?别着急,不知你发现没,刚才的常量都是在声明时就直接赋值了。你可能会疑惑,常量不都是在声明时赋值吗?不赋值不报错?当然不是啦。
方法一
事实上,Java 允许我们声明常量时不赋值,但必须在构造函数中赋值。你可能会问我为什么要说这个,这就解释:
我们修改一下 TestClass 类,在声明常量时不赋值,然后添加构造函数并为其赋值,大概看一下修改后的代码(部分代码 ):
public class TestClass {//......private final String FINAL_VALUE;//构造函数内为常量赋值public TestClass(){this.FINAL_VALUE = "FINAL";}//......}
现在,我们再调用上面贴出的修改常量的方法,发现输出是这样的:
Before Modify:FINAL_VALUE = FINALAfter Modify:FINAL_VALUE = ModifiedActually :FINAL_VALUE = Modified
纳尼,最后一句输出修改后的值了?对,修改成功了!想知道为啥,还得看编译后的 TestClass.class 文件的贴图,图中有标注。
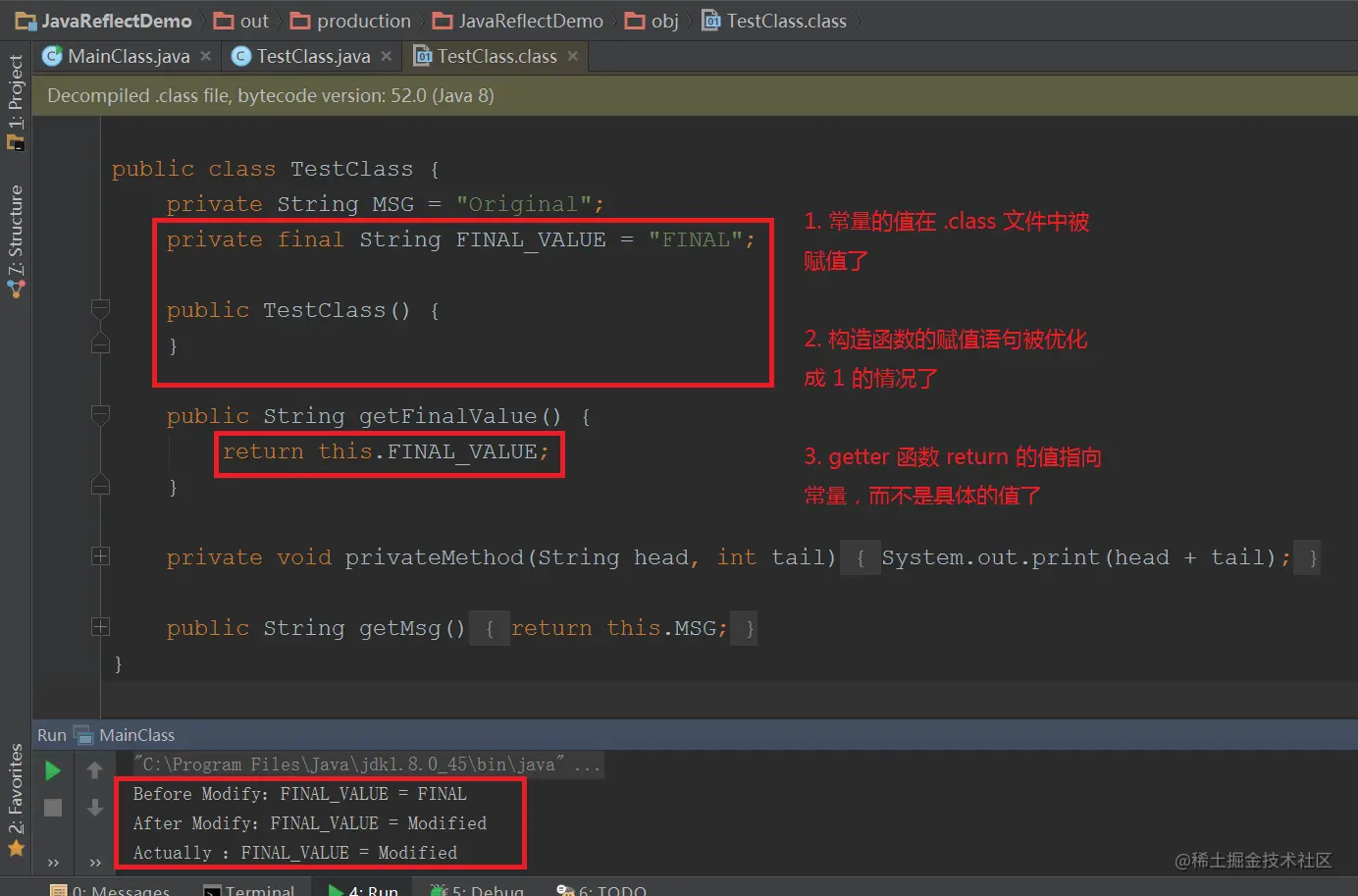
解释一下:我们将赋值放在构造函数中,构造函数是我们运行时 new 对象才会调用的,所以就不会像之前直接为常量赋值那样,在编译阶段将 getFinalValue() 方法优化为返回常量值,而是指向 FINAL_VALUE ,这样我们在运行阶段通过反射修改敞亮的值就有意义啦。但是,看得出来,程序还是有优化的,将构造函数中的赋值语句优化了。再想想那句 程序运行时是根据编译后的 .class 来执行的 ,相信你一定明白为什么这么输出了!
方法二
请你务必将上面捋清楚了再往下看。接下来再说一种改法,不使用构造函数,也可以成功修改常量的值,但原理上都一样。去掉构造函数,将声明常量的语句改为使用三目表达式赋值:
private final String FINAL_VALUE= null == null ? "FINAL" : null;
其实,上述代码等价于直接为 FINAL_VALUE 赋值 “FINAL”,但是他就是可以!至于为什么,你这么想:null == null ? "FINAL" : null 是在运行时刻计算的,在编译时刻不会计算,也就不会被优化,所以你懂得。
总结来说,不管使用构造函数还是三目表达式,根本上都是避免在编译时刻被优化,这样我们通过反射修改常量之后才有意义!好了,这一小部分到此结束!
最后的强调:
必须提醒你的是,无论直接为常量赋值 、 通过构造函数为常量赋值 还是 使用三目运算符,实际上我们都能通过反射成功修改常量的值。而我在上面说的修改”成功”与否是指:我们在程序运行阶段通过反射肯定能修改常量值,但是实际执行优化后的 .class 文件时,修改的后值真的起到作用了吗?换句话说,就是编译时是否将常量替换为具体的值了?如果替换了,再怎么修改常量的值都不会影响最终的结果了,不是吗?。
其实,你可以直接这么想:反射肯定能修改常量的值,但修改后的值是否有意义?
03. 到底能不能改?
到底能不能改?也就是说反射修改后到底有没有意义?
如果你上面看明白了,答案就简单了。俗话说“一千句话不如一张图”,下面允许我用不太规范的流程图直接表达答案哈。
注:图中”没法修改”可以理解为”能修改值但没有意义”;”可以修改”是指”能修改值且有意义”。
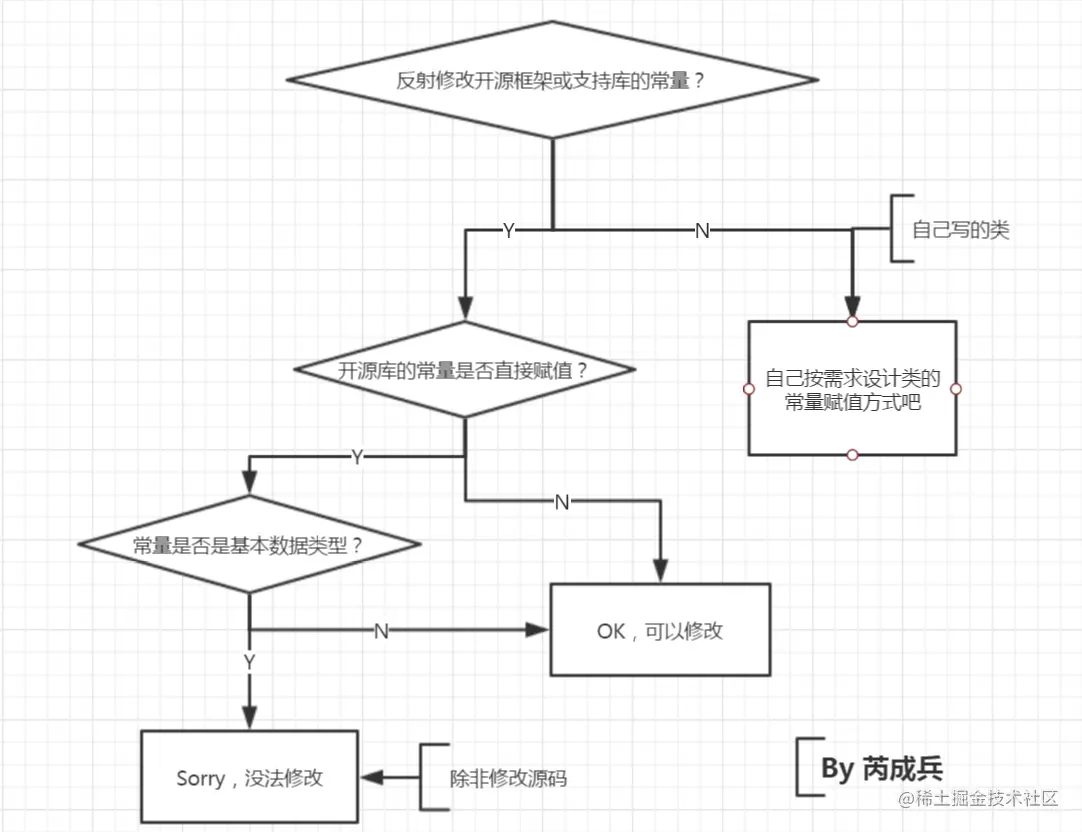
注解
基础
Java注解定义
Java注解又称Java标注,是在 JDK5 时引入的新特性,注解(也被称为元数据)。
Java注解它提供了一种安全的类似注释的机制,用来将任何的信息或元数据(metadata)与程序元素(类、方法、成员变量等)进行关联。
Java注解是附加在代码中的一些元信息,用于一些工具在编译、运行时进行解析和使用,起到说明、配置的功能。
Java注解应用
1.生成文档这是最常见的,也是java 最早提供的注解;
2.在编译时进行格式检查,如@Override放在方法前,如果你这个方法并不是覆盖了超类方法,则编译时就能检查出;
3.跟踪代码依赖性,实现替代配置文件功能,比较常见的是spring 2.5 开始的基于注解配置,作用就是减少配置;
4.在反射的 Class, Method, Field 等函数中,有许多于 Annotation 相关的接口,可以在反射中解析并使用 Annotation。
Java注解分类
1、Java自带的标准注解
包括@Override、@Deprecated、@SuppressWarnings等,使用这些注解后编译器就会进行检查。
2、元注解
元注解是用于定义注解的注解,包括@Retention、@Target、@Inherited、@Documented、@Repeatable 等。
元注解也是Java自带的标准注解,只不过用于修饰注解,比较特殊。
3、自定义注解
用户可以根据自己的需求定义注解。
Java标准注解
JDK 中内置了以下注解:
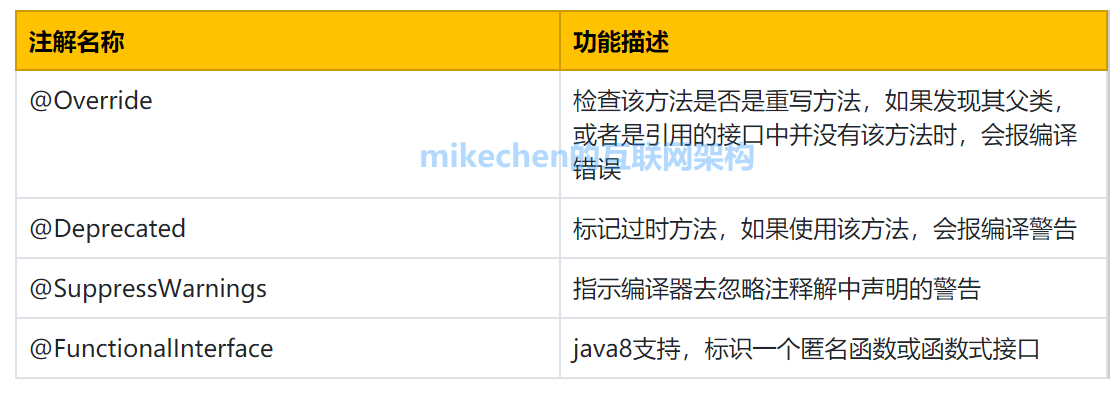
1.@Override
如果试图使用 @Override 标记一个实际上并没有覆写父类的方法时,java 编译器会告警。
class Parent {public void test() {}}class Child extends Parent {/*** 放开下面的注释,编译时会告警*//*@Overridepublic void test() {}*/}
2.Deprecated
@Deprecated 用于标明被修饰的类或类成员、类方法已经废弃、过时,不建议使用。@Deprecatedclass TestClass {// do something}
3.@SuppressWarnings
@SuppressWarnings 用于关闭对类、方法、成员编译时产生的特定警告。
1)抑制单类型的警告
@SuppressWarnings("unchecked")public void addItems(String item){@SuppressWarnings("rawtypes")List items = new ArrayList();items.add(item);}
2)抑制多类型的警告
@SuppressWarnings(value={"unchecked", "rawtypes"})public void addItems(String item){List items = new ArrayList();items.add(item);}
3)抑制所有类型的警告
@SuppressWarnings("all")public void addItems(String item){List items = new ArrayList();items.add(item);}
@SuppressWarnings 注解的常见参数值的简单说明:

4.@FunctionalInterface
@FunctionalInterface 用于指示被修饰的接口是函数式接口,在 JDK8 引入。
@FunctionalInterfacepublic interface UserService {void getUser(Long userId);// 默认方法,可以用多个默认方法public default void setUser() {}// 静态方法public static void saveUser() {}// 覆盖Object中的equals方法public boolean equals(Object obj);}
函数式接口(Functional Interface)就是一个有且仅有一个抽象方法,但是可以有多个非抽象方法的接口。
Java元注解
元注解是java API提供的,是用于修饰注解的注解,通常用在注解的定义上:

1.@Retention
@ Retention用来定义该注解在哪一个级别可用,在源代码中(SOURCE)、类文件中(CLASS)或者运行时(RUNTIME)。
@Retention 源码:
@Documented@Retention(RetentionPolicy.RUNTIME)@Target(ElementType.ANNOTATION_TYPE)public @interface Retention {RetentionPolicy value();}public enum RetentionPolicy {//此注解类型的信息只会记录在源文件中,编译时将被编译器丢弃,也就是说//不会保存在编译好的类信息中SOURCE,//编译器将注解记录在类文件中,但不会加载到JVM中。如果一个注解声明没指定范围,则系统//默认值就是ClassCLASS,//注解信息会保留在源文件、类文件中,在执行的时也加载到Java的JVM中,因此可以反射性的读取。RUNTIME}
RetentionPolicy 是一个枚举类型,它定义了被 @Retention 修饰的注解所支持的保留级别:

@Target(ElementType.METHOD)@Retention(RetentionPolicy.SOURCE) //注解信息只能在源文件中出现public @interface Override {}@Documented@Retention(RetentionPolicy.RUNTIME) //注解信息在执行时出现@Target(value={CONSTRUCTOR, FIELD, LOCAL_VARIABLE, METHOD, PACKAGE, PARAMETER, TYPE})public @interface Deprecated {}@Target({TYPE, FIELD, METHOD, PARAMETER, CONSTRUCTOR, LOCAL_VARIABLE})@Retention(RetentionPolicy.SOURCE) //注解信息在源文件中出现public @interface SuppressWarnings {String[] value();}
2.@Documented
@Documented:生成文档信息的时候保留注解,对类作辅助说明
@Documented 示例
@Target(ElementType.FIELD)@Retention(RetentionPolicy.RUNTIME)@Documentedpublic @interface Column {public String name() default "fieldName";public String setFuncName() default "setField";public String getFuncName() default "getField";public boolean defaultDBValue() default false;}
3.@Target
@Target:用于描述注解的使用范围(即:被描述的注解可以用在什么地方)
@Target源码:
@Documented@Retention(RetentionPolicy.RUNTIME)@Target(ElementType.ANNOTATION_TYPE)public @interface Target {ElementType[] value();}
ElementType 是一个枚举类型,它定义了被 @Target 修饰的注解可以应用的范围:
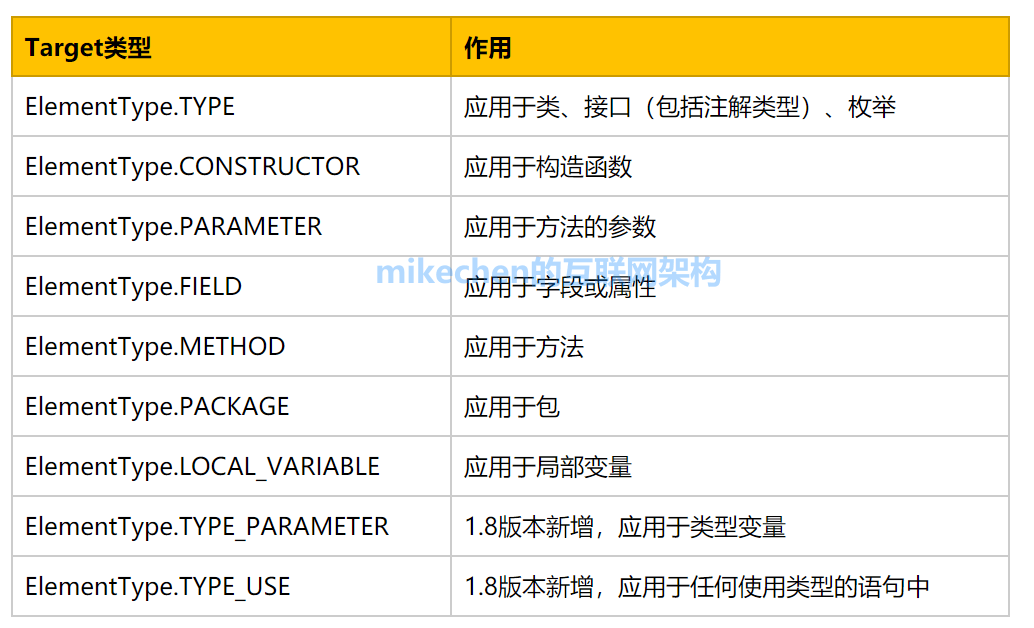
@Inherited:说明子类可以继承父类中的该注解
表示自动继承注解类型。 如果注解类型声明中存在 @Inherited 元注解,则注解所修饰类的所有子类都将会继承此注解。
@Inheritedpublic @interface Greeting {public enum FontColor{ BULE,RED,GREEN};String name();FontColor fontColor() default FontColor.GREEN;}
5.@Repeatable
@Repeatable 表示注解可以重复使用。
当我们需要重复使用某个注解时,希望利用相同的注解来表现所有的形式时,我们可以借助@Repeatable注解。
以 Spring @Scheduled 为例:
@Target({ElementType.METHOD, ElementType.ANNOTATION_TYPE})@Retention(RetentionPolicy.RUNTIME)@Documentedpublic @interface Schedules {Scheduled[] value();}@Target({ElementType.METHOD, ElementType.ANNOTATION_TYPE})@Retention(RetentionPolicy.RUNTIME)@Documented@Repeatable(Schedules.class)public @interface Scheduled {// ...}

Java注解开发**
一. 什么是注解
Annotation(注解)就是Java提供了一种为程序元素关联任何信息或任何元数据(metadata)的途径和方法。Annotion(注解)是一个接口,程序可以通过反射来获取指定程序元素的Annotion对象,然后通过Annotion对象来获取注解里面的元数据。
- 注解出现的位置
Annotation(注解)是JDK5.0及以后版本引入的。它可以用于创建文档,跟踪代码中的依赖性,甚至执行基本编译时检查。从某些方面看,annotation就像修饰符一样被使用,并应用于包、类型、构造方法、方法、成员变量、参数、本地变量的声明中。这些信息被存储在Annotation的“name=value”结构对中。 - 注解的成员提供了程序元素的关联信息(成员称为参数或注解属性)
Annotation的成员在Annotation类型中以无参数的方法的形式被声明。其方法名和返回值定义了该成员的名字和类型。在此有一个特定的默认 语法:允许声明任何Annotation成员的默认值。一个Annotation可以将name=value对作为没有定义默认值的Annotation 成员的值,当然也可以使用name=value对来覆盖其它成员默认值。这一点有些近似类的继承特性,父类的构造函数可以作为子类的默认构造函数,但是也 可以被子类覆盖。 - 注解不会影响程序代码的执行
Annotation能被用来为某个程序元素(类、方法、成员变量等)关联任何的信息。需要注意的是,这里存在着一个基本的规则:Annotation不能影响程序代码的执行,无论增加、删除 Annotation,代码都始终如一的执行。另外,尽管一些annotation通过java的反射api方法在运行时被访问,而java语言解释器在工作时忽略了这些annotation。正是由于java虚拟机忽略了Annotation,导致了annotation类型在代码中是“不起作用”的; 只有通过某种配套的工具才会对annotation类型中的信息进行访问和处理
5、注解的作用是什么
注解(Annotation) 为我们在代码中添加信息提供了一种形式化的方法,是我们可以在稍后 某个时刻方便地使用这些数据(通过 解析注解 来使用这些数据),常见的作用有以下几种:
(1).生成文档。这是最常见的,也是java 最早提供的注解。常用的有@see @param @return 等;
(2).在编译时进行格式检查。如@Override放在方法前,如果你这个方法并不是覆盖了超类方法,则编译时就能检查出;
(3).跟踪代码依赖性,实现替代配置文件功能。比较常见的是spring 2.5 开始的基于注解配置。作用就是减少配置。现在的框架基本都使用了这种配置来减少配置文件的数量;
二.JDK自带的注解
- @Override 表示当前方法覆盖了父类的方法
此注释只适用于修辞方法,表示一个方法声明打算重写超类中的另一个方法声明。如果方法利用此注释类型进行注解但没有重写超类方法,则编译器
会生成一条错误消息
- @Deprecated 表示方法已经过时,方法上有横线,使用时会有警告。
此注释可用于修辞方法、属性、类,表示不鼓励程序员使用这样的元素,通常是因为它很危险或存在更好的选择。在使用不被赞成的程序元素或在不被赞成的代码中执行重写时,编译器会发出警告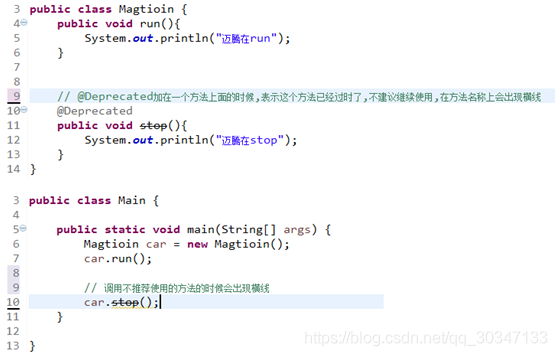
- @SuppressWarings 表示关闭一些警告信息(通知java编译器忽略特定的编译警告)
用来抑制编译时的警告信息。与前两个注释有所不同,你需要添加一个参数才能正确使用,这些参数值都是已经定义好了的,我们选择性的使用就好了,
参数如下: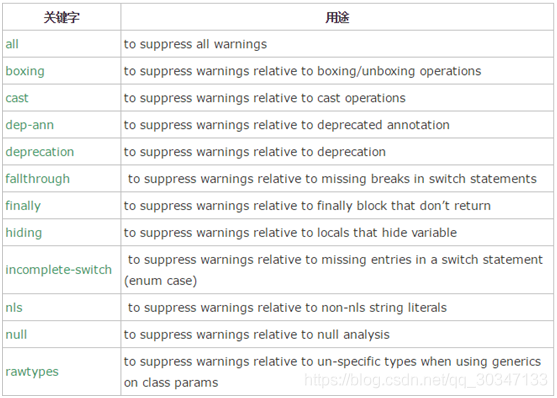

实例代码:
我们在方法上面加上 @SuppressWarnings(“rawtypes”) .这是泛型的警告就会消失.但是还有一个变量未使用的警告
我们可以添加多种类型,多种类型用{}扩起来

另外,由于@SuppressWarnings注释只有一个参数,并且参数名为value,所以我们可以将上面一句注释简写为
@SuppressWarnings(“unchecked”);
同时参数value可以取多个值如:
@SuppressWarnings(value={“unchecked”, “deprecation”})
或@SuppressWarnings({“unchecked”, “deprecation”})。
三.开发自定义注解
- 自定义注解的语法规则
(1).使用@interface关键字定义注解,注意关键字的位置
使用@interface自定义注解时,自动继承了java.lang.annotation.Annotation接口,由编译程序自动完成其他细节。在定义注解时,不能继承其他的注解或接口。
(2).成员以无参数无异常的方式声明,注意区别一般类成员变量的声明
其中的每一个方法实际上是声明了一个配置参数。方法的名称就是参数的名称
(3).可以使用default为成员指定一个默认值,如上所示
(4).成员类型是受限的,合法的类型包括原始类型以及String、Class、Annotation、Enumeration (JAVA的基本数据类型有8种:
byte(字节)、short(短整型)、int(整数型)、long(长整型)、float(单精度浮点数类型)、double(双精度浮点数类型)、char(字符类型)、boolean(布尔类型)
(5).注解类可以没有成员,没有成员的注解称为标识注解,例如JDK注解中的@Override、@Deprecation
(6).如果注解只有一个成员,并且把成员取名为value(),则在使用时可以忽略成员名和赋值号“=” ,例如JDK注解的@SuppviseWarnings ;如果成员名 不为value,则使用时需指明成员名和赋值号”=”,


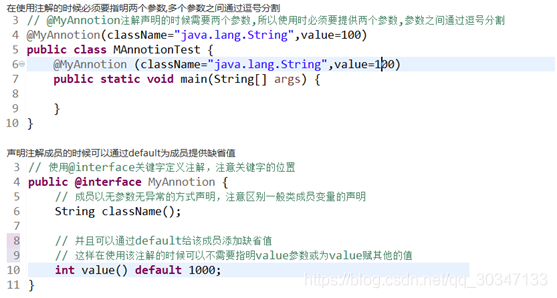
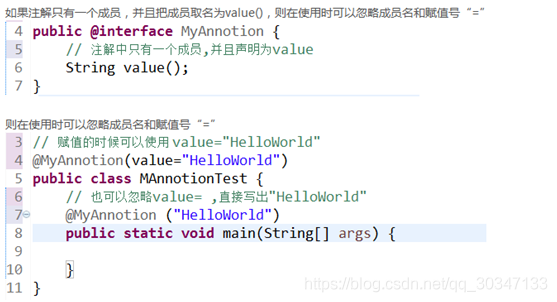
- 元注解:
何为元注解?就是注解的注解,就是给你自己定义的注解添加注解,你自己定义了一个注解,但你想要你的注解有什么样的功能,此时就需要用元注解对你的注解进行说明了。Java5.0定义了4个标准的meta-annotation类型,它们被用来提供对其它 annotation类型作说明。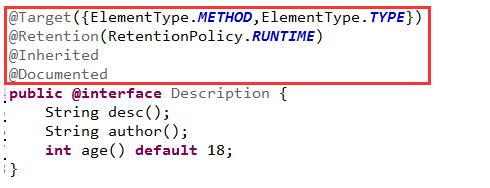
2.1、@Target
@Target说明了Annotation所修饰的对象范围:即注解的作用域,用于说明注解的使用范围(即注解可以用在什么地方,比如类的注解,方法注解,成员变量注解等等)
注意:如果Target元注解没有出现,那么定义的注解可以应用于程序的任何元素。
取值是在java.lang.annotation.ElementType这个枚举中规定的:
1.CONSTRUCTOR:用于描述构造器
2.FIELD:用于描述域
3.LOCAL_VARIABLE:用于描述局部变量
4.METHOD:用于描述方法
5.PACKAGE:用于描述包
6.PARAMETER:用于描述参数
7.TYPE:用于描述类、接口(包括注解类型) 或enum声明
实例代码
2.2 @Retention
@Retention定义了该Annotation被保留的时间长短:
(1)某些Annotation仅出现在源代码中,而被编译器丢弃;
(2)而另一些却被编译在class文件中;编译在class文件中的Annotation可能会被虚拟机忽略,
(3)而另一些在class被装载时将被读取(请注意并不影响class的执行,因为Annotation与class在使用上是被分离的)。
使用这个meta-Annotation可以对 Annotation的“生命周期”限制。
@Retention的取值是在RetentionPoicy这个枚举中规定的
1.SOURCE:在源文件中有效(即源文件保留)
2.CLASS:在class文件中有效(即class保留)
3.RUNTIME:在运行时有效(即运行时保留)
实例代码如下:

注意:注解的的RetentionPolicy的属性值是RUTIME,这样注解处理器可以通过反射,获取到该注解的属性值,从而去做一些运行时的逻辑处理
2.3、@Documented
@Documented用于描述其它类型的annotation应该被作为被标注的程序成员的公共API,因此可以被例如javadoc此类的工具文档化。Documented是一个标记注解,没有成员。
2.4、@Inherited
@Inherited 元注解是一个标记注解,@Inherited阐述了某个被标注的类型是被继承的。如果一个使用了@Inherited修饰的annotation类型被用于一个class,则这个annotation将被用于该class的子类。
注意:@Inherited annotation类型是被标注过的class的子类所继承。类并不从它所实现的接口继承annotation,方法并不从它所重载的方法继承annotation。
当@Inherited annotation类型标注的annotation的Retention是RetentionPolicy.RUNTIME,则反射API增强了这种继 承性。如果我们使用java.lang.reflect去查询一个@Inherited annotation类型的annotation时,反射代码检查将展开工作:检查class和其父类,直到发现指定的annotation类型被发现, 或者到达类继承结构的顶层。
(1) 定义注解1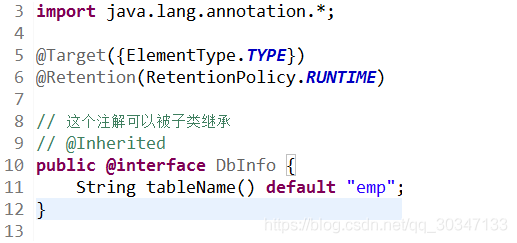
(2) 定义注解2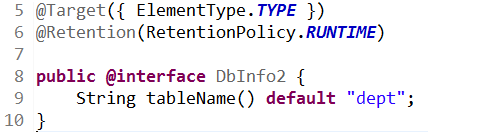
(3) 定义一个基类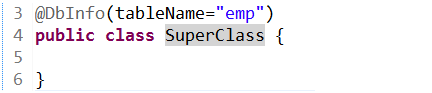
(4) 定义一个子类
(5) 通过反射获取子类中使用的所有的注解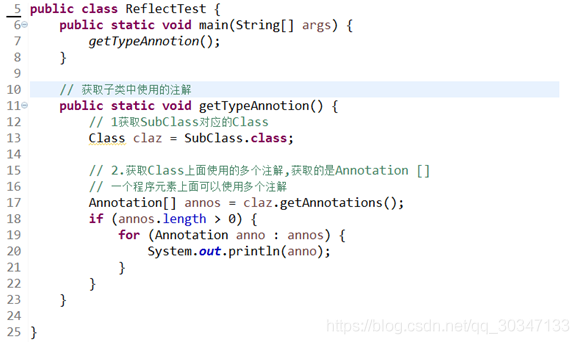
四.注解开发实例:通过注解创建数据库表
- 创建Column注解,表示数据库中的字段信息
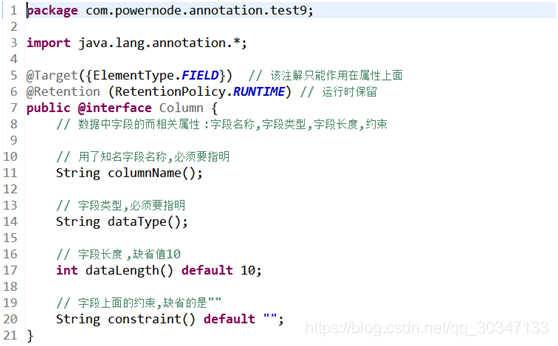
- 创建Table注解,表示数据库中的表

- 创建JavaBen类,使用定义的注解
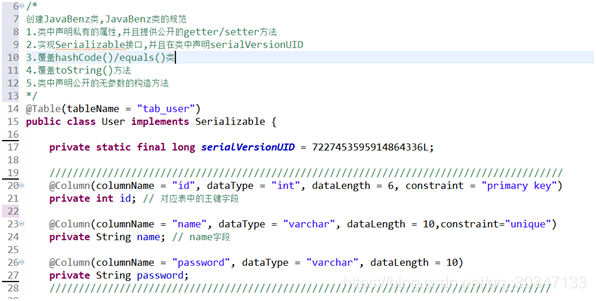
- 创建Main方法,读取JavaBen类中的注解信息,根据注解信息自动生成DDL语句

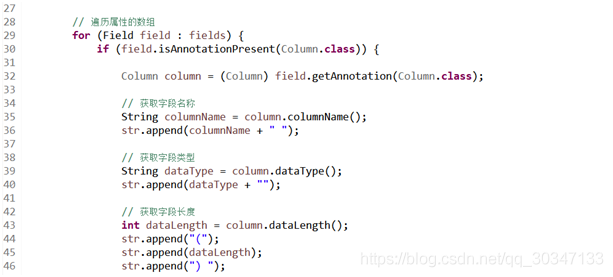
 *
*
1.Java中的注释类型Annotation是一种引用数据类型,也称为注解。*
自定义注释的开发过程。
no.1.声明一个类My Annotation
no.2.把class 关键字改成 @interface,实质上声明了一个接口,这个接口自动的继承了Java.lang.annotation.Annotation接口。
2.常用内置注解: @Override @Deprecated @SuppressWarnings,以及它们各自的作用。*
@Deprecated,表示这个方法过时了,最好别用了 @Override表示方法重写,或者覆盖。@SuppressWarnings让编译器忽略警告信息。 (@suppressWarnings({rawtypes}))@suppressWarnings(value = {rawtypes})//泛型123
3.自定义注解的时候,这几个注解你知道分别是干什么的吗? @Retention @Target @Inherited @Documented*
no1. //@Target元注解是用来限定自定义注解的使用范围的。
@Target说明了Annotation所修饰的对象范围:即注解的作用域,
用于说明注解的使用范围(即注解可以用在什么地方,比如类的注解,方法注解,成员变量注解等等)
注意:如果Target元注解没有出现,那么定义的注解可以应用于程序的任何元素。
@Target取值是在java.lang.annotation.ElementType这个枚举中规定的:
//@Target({ ElementType.TYPE }) // 规定了自定义注解的使用范围是:只能在类型上面使用
@Target({ ElementType.TYPE, ElementType.METHOD }) // 规定了自定义注解的使用范围是:可以在类型上面使用,也可以在方法上面使用
@Retention(RetentionPolicy.RUNTIME) // 注解信息在运行时保留
public @interface MyAnnotation {
int age();
String name();String schoolName() default "动力节点";123
}
no2.@Retention定义了该Annotation被保留的时间长短:
// (1)某些Annotation仅出现在源代码中,而被编译器丢弃;
// (2)而另一些却被编译在class文件中;编译在class文件中的Annotation可能会被虚拟机忽略,运行时被忽略
// (3)而另一些在class被装载时将被读取(请注意并不影响class的执行,因为Annotation与class在使用上是被分离的)。
// 使用这个meta-Annotation可以对 Annotation的“生命周期”限制。
// @Retention的取值是在RetentionPoicy这个枚举中规定的
// 1.SOURCE:在源文件中有效(即源文件保留)
// 2.CLASS:在class文件中有效(即class保留)
// 3.RUNTIME:在运行时有效(即运行时保留,注意:只有注解信息在运行时保留,我们才能在运行时通过反射读取到注解信息)
// 注解的保留范围,只能三选一
no3.@Documented保存文件的
no4.@Inherit父类中使用的注解可以被子类继承.
自定义注解实际上就是一种类型而已,也就是引用类型(Java中除了8种基本类型之外,我们见到的任何类型都是引用类型)
类型的作用:(1)声明变量;(2)声明方法的参数;(3)声明方法的返回类型;(4)强制类型转换
因为我们在注解中声明了属性,所以在使用注解的时候必须要指明 属性值 ,多个属性之间没有顺序,多个属性之间通过逗号分隔
4.能够通过反射机制读取注解吗?*
能
package com.bjpowernode.annotationtest10;import java.lang.reflect.Field;public class ReflectTest {/*** 通过反射操作,获取类中携带的注解信息.根据读取到的信息生成数据库的建表语句** @return*/public static String buildSql() {// 准备数据库的建表语句StringBuilder str = new StringBuilder("CREATE TABLE ");// 获取Emp类对应的Class对象Class claz = Emp.class;// =============================================================// 一.获取Emp类中携带的@Table注解,以此来获取表名信息// (1)获取Emp类中携带的Table注解Table table = (Table) claz.getAnnotation(Table.class);System.out.println(table);// (2)获取Table注解中的的属性信息String tableName = table.tableName();// 获取表名信息System.out.println(tableName);// (3)把表名信息拼接到SQL语句中str.append(tableName + " (");// =============================================================// 二:获取Emp类中携带的Column注解,来获取字段的相关信息// (1)获取类中声明的所有的属性Field[] fields = claz.getDeclaredFields();// (2)遍历保存所有属性的Field的数组,取出每个属性for (Field field : fields) {// (3)判断属性中是否使用了Column注解if (field.isAnnotationPresent(Column.class)) {// (4)获取属性中使用的Column注解Column column = field.getAnnotation(Column.class);// (5)获取注解中携带的字段信息String columnName = column.columnName(); // 获取字段名信息String columnType = column.columnType(); // 获取字段类型信息int columnLength = column.columnLength(); // 获取字段长度信息String columnConstraint = column.columnConstraint(); // 获取字段约束信息// (6)把字段的相关信息拼接到SQL语句中if (columnName.equalsIgnoreCase("hiredate")) {str.append(columnName + " " + columnType + " " + columnConstraint + ",");System.out.println(str);System.out.println();} else {str.append(columnName + " " + columnType + " (" + columnLength + ") " + columnConstraint + ",");System.out.println(str);}}}// 去除SQL中最末尾的逗号,并且关闭SQL语句中的()String sql = str.substring(0, str.length() -1) + ")";//截取字符串语句。return sql;}public static void main(String[] args) {String sql = buildSql();System.out.println(sql);}}
5.java中的Annotation/注释类型,它有什么用?*是为了在其他类中使用这个注释(使用注解来携带信息),这些携带信息可以在其他类的任何位置使用从某些方面来看,annotatiom就像是一个修饰符一样来使用 ,并用于包,类型,方法,构造方法,成员变量,参数,本地变量声明中。必须要和反射一起操作。【通过class 获取类的相关信息,通过class创建对象,通过class调用对象的方法和属性,这种操作称为反射操作。】要想执行反射操作,必须先获取指定类名的class。eg.String.classclass.forname("字符串")String obj="Hello",Class claz = obj.getClass()6. 注解中声明属性的语法比较怪异,即像在Java类中声明属性,又像在Java类中声明方法(实际上:即是声明了属性,又是声明了方法)注解中声明属性的规范: 属性类型 属性名称 ();属性名称的规范:名词或名词性短语,第一个单词首字符小写,其余单词首字符大写在使用注解的时候,通过注解中的属性来携带信息因为我们在注解中声明了属性,所以在使用注解的时候必须要指明属性值,多个属性之间没有顺序,多个属性之间通过逗号分隔
7.可以给注解中的属性提供缺省值// 我们可以在注解中声明属性.(在注解中通过属性来携带信息)public @interface MyAnnotation {// 注解中声明属性的语法比较怪异,即像在Java类中声明属性,又像在Java类中声明方法(实际上:即是声明了属性,又是声明了方法)// 注解中声明属性的规范: 属性类型 属性名称 ();// 属性名称的规范:名词或名词性短语,第一个单词首字符小写,其余单词首字符大写int age();String name();// 可以给注解中的属性提供缺省值String schoolName() default "动力节点";int [] arr() ;8.如果注解中只有一个属性,并且属性名称是value,这样的话我们使用注解的时候,可以指明属性名称,也可以忽略属性名称@MyAnnotation(value = { "Hello", "World" })public class Main {@MyAnnotation({ "Hello", "World" })public static void main(String[] args) {}package com.bjpowernode.annotation8;public @interface MyAnnotation {String[] value();}
9.方法重写要求访问权限不能降低,
priority : private 私有的,访问权限最低
default默认的
protected 受保护的 父子关系中常用
public 访问权限最高。
也不能抛出比父类更多的异常。 exceotion
IO exception
file not found
10.现实中的一个实体对应着一个数据库表;一个数据库表会对应着一个Java类;
实体中的属性成为表中的字段;表中的字段对应着类中的属性
和数据库表对应着的类称为JavaBean类,JavaBean的规范
1.类中的属性私有化,并且提供公开的getter/settter()方法
2.类中覆盖toString()方法 (为了输出对象做好了准备)
3.类中覆盖hashCode()/equals()方法(覆盖hashCode()/equals()的目的是为了把JavaBean类的对象放到HashMap/HashSet中做好准备)
4.类中提供公开的无参数的构造方法
5.该类要实现Serialiazble接口,并且声明serialVersionUID(使用Eclipse工具生成的) 为序列化做好了准备
我们要执行的功能,根据一个写好的JavaBean类,自动的生成数据库的建表语句(DDL)
创建数据库表所需要的信息:
(1)表名信息
(2)字段的信息,包括 字段名称,字段类型,字段长度,字段约束
我们如何来携带上面的建表所需要的信息呢?使用注解!
1.为了在JavaBean类中携带表名信息,我们创建一个@Table的注解,这个注解在类型上面使用,因为一个JavaBean类对应一个表
2.为了在JavaBean类中携带字段信息,我们创建一个@Column的注解,这个注解在类的属性中使用;因为类的属性对应着表中的字段
注解在实际开发中的作用
使用注解在类中携带信息,程序运行的时候通过反射操作获取到注解信息,然后根据获取到的信息生成数据库的建表语句
程序中携带信息的方式
1.通过注解来携带信息,然后通过反射来读取信息
2.通过文件来携带信息,然后通过IO来读取信息
代理
代理是英文 Proxy 翻译过来的。我们在生活中见到过的代理,大概最常见的就是朋友圈中卖面膜的同学了。
她们从厂家拿货,然后在朋友圈中宣传,然后卖给熟人。
按理说,顾客可以直接从厂家购买产品,但是现实生活中,很少有这样的销售模式。一般都是厂家委托给代理商进行销售,顾客跟代理商打交道,而不直接与产品实际生产者进行关联。
所以,代理就有一种中间人的味道。
接下来,我们说说软件中的代理模式。
代理模式
代理模式是面向对象编程中比较常见的设计模式。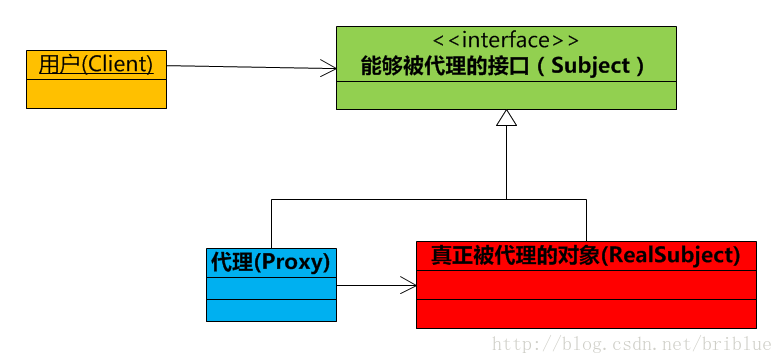
这是常见代理模式常见的 UML 示意图。
需要注意的有下面几点:
\1. 用户只关心接口功能,而不在乎谁提供了功能。上图中接口是 Subject。
\2. 接口真正实现者是上图的 RealSubject,但是它不与用户直接接触,而是通过代理。
\3. 代理就是上图中的 Proxy,由于它实现了 Subject 接口,所以它能够直接与用户接触。
\4. 用户调用 Proxy 的时候,Proxy 内部调用了 RealSubject。所以,Proxy 是中介者,它可以增强 RealSubject 操作。
如果难于理解的话,我用事例说明好了。值得注意的是,代理可以分为静态代理和动态代理两种。先从静态代理讲起。
静态代理
我们平常去电影院看电影的时候,在电影开始的阶段是不是经常会放广告呢?
电影是电影公司委托给影院进行播放的,但是影院可以在播放电影的时候,产生一些自己的经济收益,比如卖爆米花、可乐等,然后在影片开始结束时播放一些广告。
现在用代码来进行模拟。
首先得有一个接口,通用的接口是代理模式实现的基础。这个接口我们命名为 Movie,代表电影播放的能力。
1 package com.frank.test;23 public interface Movie {4 void play();5 }
然后,我们要有一个真正的实现这个 Movie 接口的类,和一个只是实现接口的代理类。
 ;)
;)
package com.frank.test;public class RealMovie implements Movie {@Overridepublic void play() {// TODO Auto-generated method stubSystem.out.println("您正在观看电影 《肖申克的救赎》");}}
 ;)
;)
这个表示真正的影片。它实现了 Movie 接口,play() 方法调用时,影片就开始播放。那么 Proxy 代理呢?
 ;)
;)
1 package com.frank.test;23 public class Cinema implements Movie {45 RealMovie movie;67 public Cinema(RealMovie movie) {8 super();9 this.movie = movie;10 }111213 @Override14 public void play() {1516 guanggao(true);1718 movie.play();1920 guanggao(false);21 }2223 public void guanggao(boolean isStart){24 if ( isStart ) {25 System.out.println("电影马上开始了,爆米花、可乐、口香糖9.8折,快来买啊!");26 } else {27 System.out.println("电影马上结束了,爆米花、可乐、口香糖9.8折,买回家吃吧!");28 }29 }3031 }
 ;)
;)
Cinema 就是 Proxy 代理对象,它有一个 play() 方法。不过调用 play() 方法时,它进行了一些相关利益的处理,那就是广告。现在,我们编写测试代码。
 ;)
;)
package com.frank.test;
public class ProxyTest {
public static void main(String[] args) {
RealMovie realmovie = new RealMovie();
Movie movie = new Cinema(realmovie);
movie.play();
}
}
 ;)
;)
然后观察结果:
电影马上开始了,爆米花、可乐、口香糖9.8折,快来买啊!
您正在观看电影 《肖申克的救赎》
电影马上结束了,爆米花、可乐、口香糖9.8折,买回家吃吧!
现在可以看到,代理模式可以在不修改被代理对象的基础上,通过扩展代理类,进行一些功能的附加与增强。值得注意的是,代理类和被代理类应该共同实现一个接口,或者是共同继承某个类。
上面介绍的是静态代理的内容,为什么叫做静态呢?因为它的类型是事先预定好的,比如上面代码中的 Cinema 这个类。下面要介绍的内容就是动态代理。
动态代理
既然是代理,那么它与静态代理的功能与目的是没有区别的,唯一有区别的就是动态与静态的差别。
那么在动态代理的中这个动态体现在什么地方?
上一节代码中 Cinema 类是代理,我们需要手动编写代码让 Cinema 实现 Movie 接口,而在动态代理中,我们可以让程序在运行的时候自动在内存中创建一个实现 Movie 接口的代理,而不需要去定义 Cinema 这个类。这就是它被称为动态的原因。
也许概念比较抽象。现在实例说明一下情况。
假设有一个大商场,商场有很多的柜台,有一个柜台卖茅台酒。我们进行代码的模拟。
 ;)
;)
package com.frank.test;
public interface SellWine {
void mainJiu();
}
 ;)
;)
SellWine 是一个接口,你可以理解它为卖酒的许可证。
 ;)
;)
package com.frank.test;
public class MaotaiJiu implements SellWine {
@Override
public void mainJiu() {
// TODO Auto-generated method stub
System.out.println("我卖得是茅台酒。");
}
}
 ;)
;)
然后创建一个类 MaotaiJiu,对的,就是茅台酒的意思。
我们还需要一个柜台来卖酒:
 ;)
;)
package com.frank.test;
import java.lang.reflect.InvocationHandler;
import java.lang.reflect.Method;
public class GuitaiA implements InvocationHandler {
private Object pingpai;
public GuitaiA(Object pingpai) {
this.pingpai = pingpai;
}
@Override
public Object invoke(Object proxy, Method method, Object[] args)
throws Throwable {
// TODO Auto-generated method stub
System.out.println("销售开始 柜台是: "+this.getClass().getSimpleName());
method.invoke(pingpai, args);
System.out.println("销售结束");
return null;
}
}
 ;)
;)
GuitaiA 实现了 InvocationHandler 这个类,这个类是什么意思呢?大家不要慌张,待会我会解释。
然后,我们就可以卖酒了。
 ;)
;)
package com.frank.test;
import java.lang.reflect.InvocationHandler;
import java.lang.reflect.Proxy;
public class Test {
public static void main(String[] args) {
// TODO Auto-generated method stub
MaotaiJiu maotaijiu = new MaotaiJiu();
InvocationHandler jingxiao1 = new GuitaiA(maotaijiu);
SellWine dynamicProxy = (SellWine) Proxy.newProxyInstance(MaotaiJiu.class.getClassLoader(),
MaotaiJiu.class.getInterfaces(), jingxiao1);
dynamicProxy.mainJiu();
}
}
 ;)
;)
这里,我们又接触到了一个新的概念,没有关系,先别管,先看结果。
销售开始 柜台是: GuitaiA
我卖得是茅台酒。
销售结束
看到没有,我并没有像静态代理那样为 SellWine 接口实现一个代理类,但最终它仍然实现了相同的功能,这其中的差别,就是之前讨论的动态代理所谓“动态”的原因。
动态代理语法
放轻松,下面我们开始讲解语法,语法非常简单。
动态代码涉及了一个非常重要的类 Proxy。正是通过 Proxy 的静态方法 newProxyInstance 才会动态创建代理。
Proxy
public static Object newProxyInstance(ClassLoader loader,
Class<?>[] interfaces,
InvocationHandler h)
下面讲解它的 3 个参数意义。
- loader 自然是类加载器
- interfaces 代码要用来代理的接口
- h 一个 InvocationHandler 对象
初学者应该对于 InvocationHandler 很陌生,我马上就讲到这一块。
InvocationHandler
InvocationHandler 是一个接口,官方文档解释说,每个代理的实例都有一个与之关联的 InvocationHandler 实现类,如果代理的方法被调用,那么代理便会通知和转发给内部的 InvocationHandler 实现类,由它决定处理。
public interface InvocationHandler {
public Object invoke(Object proxy, Method method, Object[] args)
throws Throwable;
}
InvocationHandler 内部只是一个 invoke() 方法,正是这个方法决定了怎么样处理代理传递过来的方法调用。
- proxy 代理对象
- method 代理对象调用的方法
- args 调用的方法中的参数
因为,Proxy 动态产生的代理会调用 InvocationHandler 实现类,所以 InvocationHandler 是实际执行者。
 ;)
;)
public class GuitaiA implements InvocationHandler {
private Object pingpai;
public GuitaiA(Object pingpai) {
this.pingpai = pingpai;
}
@Override
public Object invoke(Object proxy, Method method, Object[] args)
throws Throwable {
// TODO Auto-generated method stub
System.out.println("销售开始 柜台是: "+this.getClass().getSimpleName());
method.invoke(pingpai, args);
System.out.println("销售结束");
return null;
}
}
 ;)
;)
GuitaiA 就是实际上卖酒的地方。
现在,我们加大难度,我们不仅要卖茅台酒,还想卖五粮液。
 ;)
;)
package com.frank.test;
public class Wuliangye implements SellWine {
@Override
public void mainJiu() {
// TODO Auto-generated method stub
System.out.println("我卖得是五粮液。");
}
}
 ;)
;)
Wuliangye 这个类也实现了 SellWine 这个接口,说明它也拥有卖酒的许可证,同样把它放到 GuitaiA 上售卖。
 ;)
;)
public class Test {
public static void main(String[] args) {
// TODO Auto-generated method stub
MaotaiJiu maotaijiu = new MaotaiJiu();
Wuliangye wu = new Wuliangye();
InvocationHandler jingxiao1 = new GuitaiA(maotaijiu);
InvocationHandler jingxiao2 = new GuitaiA(wu);
SellWine dynamicProxy = (SellWine) Proxy.newProxyInstance(MaotaiJiu.class.getClassLoader(),
MaotaiJiu.class.getInterfaces(), jingxiao1);
SellWine dynamicProxy1 = (SellWine) Proxy.newProxyInstance(MaotaiJiu.class.getClassLoader(),
MaotaiJiu.class.getInterfaces(), jingxiao2);
dynamicProxy.mainJiu();
dynamicProxy1.mainJiu();
}
}
 ;)
;)
我们来看结果:
销售开始 柜台是: GuitaiA
我卖得是茅台酒。
销售结束
销售开始 柜台是: GuitaiA
我卖得是五粮液。
销售结束
有人会问,dynamicProxy 和 dynamicProxy1 什么区别没有?他们都是动态产生的代理,都是售货员,都拥有卖酒的技术证书。
我现在扩大商场的经营,除了卖酒之外,还要卖烟。
首先,同样要创建一个接口,作为卖烟的许可证。
package com.frank.test;
public interface SellCigarette {
void sell();
}
然后,卖什么烟呢?我是湖南人,那就芙蓉王好了。
 ;)
;)
public class Furongwang implements SellCigarette {
@Override
public void sell() {
// TODO Auto-generated method stub
System.out.println("售卖的是正宗的芙蓉王,可以扫描条形码查证。");
}
}
 ;)
;)
然后再次测试验证:
 ;)
;)
package com.frank.test;
import java.lang.reflect.InvocationHandler;
import java.lang.reflect.Proxy;
public class Test {
public static void main(String[] args) {
// TODO Auto-generated method stub
MaotaiJiu maotaijiu = new MaotaiJiu();
Wuliangye wu = new Wuliangye();
Furongwang fu = new Furongwang();
InvocationHandler jingxiao1 = new GuitaiA(maotaijiu);
InvocationHandler jingxiao2 = new GuitaiA(wu);
InvocationHandler jingxiao3 = new GuitaiA(fu);
SellWine dynamicProxy = (SellWine) Proxy.newProxyInstance(MaotaiJiu.class.getClassLoader(),
MaotaiJiu.class.getInterfaces(), jingxiao1);
SellWine dynamicProxy1 = (SellWine) Proxy.newProxyInstance(MaotaiJiu.class.getClassLoader(),
MaotaiJiu.class.getInterfaces(), jingxiao2);
dynamicProxy.mainJiu();
dynamicProxy1.mainJiu();
SellCigarette dynamicProxy3 = (SellCigarette) Proxy.newProxyInstance(Furongwang.class.getClassLoader(),
Furongwang.class.getInterfaces(), jingxiao3);
dynamicProxy3.sell();
}
}
 ;)
;)
然后,查看结果:
 ;)
;)
销售开始 柜台是: GuitaiA
我卖得是茅台酒。
销售结束
销售开始 柜台是: GuitaiA
我卖得是五粮液。
销售结束
销售开始 柜台是: GuitaiA
售卖的是正宗的芙蓉王,可以扫描条形码查证。
销售结束
 ;)
;)
结果符合预期。大家仔细观察一下代码,同样是通过 Proxy.newProxyInstance() 方法,却产生了 SellWine 和 SellCigarette 两种接口的实现类代理,这就是动态代理的魔力。
动态代理的秘密
一定有同学对于为什么 Proxy 能够动态产生不同接口类型的代理感兴趣,我的猜测是肯定通过传入进去的接口然后通过反射动态生成了一个接口实例。
比如 SellWine 是一个接口,那么 Proxy.newProxyInstance() 内部肯定会有
new SellWine();
这样相同作用的代码,不过它是通过反射机制创建的。那么事实是不是这样子呢?直接查看它们的源码好了。需要说明的是,我当前查看的源码是 1.8 版本。
 ;)
;)
public static Object newProxyInstance(ClassLoader loader,
Class<?>[] interfaces,
InvocationHandler h)
throws IllegalArgumentException
{
Objects.requireNonNull(h);
final Class<?>[] intfs = interfaces.clone();
/*
* Look up or generate the designated proxy class.
*/
Class<?> cl = getProxyClass0(loader, intfs);
/*
* Invoke its constructor with the designated invocation handler.
*/
try {
final Constructor<?> cons = cl.getConstructor(constructorParams);
final InvocationHandler ih = h;
if (!Modifier.isPublic(cl.getModifiers())) {
AccessController.doPrivileged(new PrivilegedAction<Void>() {
public Void run() {
cons.setAccessible(true);
return null;
}
});
}
return cons.newInstance(new Object[]{h});
} catch (IllegalAccessException|InstantiationException e) {
throw new InternalError(e.toString(), e);
} catch (InvocationTargetException e) {
Throwable t = e.getCause();
if (t instanceof RuntimeException) {
throw (RuntimeException) t;
} else {
throw new InternalError(t.toString(), t);
}
} catch (NoSuchMethodException e) {
throw new InternalError(e.toString(), e);
}
}
 ;)
;)
newProxyInstance 的确创建了一个实例,它是通过 cl 这个 Class 文件的构造方法反射生成。cl 由 getProxyClass0() 方法获取。
 ;)
;)
private static Class<?> getProxyClass0(ClassLoader loader,
Class<?>... interfaces) {
if (interfaces.length > 65535) {
throw new IllegalArgumentException("interface limit exceeded");
}
// If the proxy class defined by the given loader implementing
// the given interfaces exists, this will simply return the cached copy;
// otherwise, it will create the proxy class via the ProxyClassFactory
return proxyClassCache.get(loader, interfaces);
}
 ;)
;)
直接通过缓存获取,如果获取不到,注释说会通过 ProxyClassFactory 生成。
 ;)
;)
/**
* A factory function that generates, defines and returns the proxy class given
* the ClassLoader and array of interfaces.
*/
private static final class ProxyClassFactory
implements BiFunction<ClassLoader, Class<?>[], Class<?>>
{
// Proxy class 的前缀是 “$Proxy”,
private static final String proxyClassNamePrefix = "$Proxy";
// next number to use for generation of unique proxy class names
private static final AtomicLong nextUniqueNumber = new AtomicLong();
@Override
public Class<?> apply(ClassLoader loader, Class<?>[] interfaces) {
Map<Class<?>, Boolean> interfaceSet = new IdentityHashMap<>(interfaces.length);
for (Class<?> intf : interfaces) {
/*
* Verify that the class loader resolves the name of this
* interface to the same Class object.
*/
Class<?> interfaceClass = null;
try {
interfaceClass = Class.forName(intf.getName(), false, loader);
} catch (ClassNotFoundException e) {
}
if (interfaceClass != intf) {
throw new IllegalArgumentException(
intf + " is not visible from class loader");
}
/*
* Verify that the Class object actually represents an
* interface.
*/
if (!interfaceClass.isInterface()) {
throw new IllegalArgumentException(
interfaceClass.getName() + " is not an interface");
}
/*
* Verify that this interface is not a duplicate.
*/
if (interfaceSet.put(interfaceClass, Boolean.TRUE) != null) {
throw new IllegalArgumentException(
"repeated interface: " + interfaceClass.getName());
}
}
String proxyPkg = null; // package to define proxy class in
int accessFlags = Modifier.PUBLIC | Modifier.FINAL;
/*
* Record the package of a non-public proxy interface so that the
* proxy class will be defined in the same package. Verify that
* all non-public proxy interfaces are in the same package.
*/
for (Class<?> intf : interfaces) {
int flags = intf.getModifiers();
if (!Modifier.isPublic(flags)) {
accessFlags = Modifier.FINAL;
String name = intf.getName();
int n = name.lastIndexOf('.');
String pkg = ((n == -1) ? "" : name.substring(0, n + 1));
if (proxyPkg == null) {
proxyPkg = pkg;
} else if (!pkg.equals(proxyPkg)) {
throw new IllegalArgumentException(
"non-public interfaces from different packages");
}
}
}
if (proxyPkg == null) {
// if no non-public proxy interfaces, use com.sun.proxy package
proxyPkg = ReflectUtil.PROXY_PACKAGE + ".";
}
/*
* Choose a name for the proxy class to generate.
*/
long num = nextUniqueNumber.getAndIncrement();
String proxyName = proxyPkg + proxyClassNamePrefix + num;
/*
* Generate the specified proxy class.
*/
byte[] proxyClassFile = ProxyGenerator.generateProxyClass(
proxyName, interfaces, accessFlags);
try {
return defineClass0(loader, proxyName,
proxyClassFile, 0, proxyClassFile.length);
} catch (ClassFormatError e) {
/*
* A ClassFormatError here means that (barring bugs in the
* proxy class generation code) there was some other
* invalid aspect of the arguments supplied to the proxy
* class creation (such as virtual machine limitations
* exceeded).
*/
throw new IllegalArgumentException(e.toString());
}
}
}
 ;)
;)
这个类的注释说,通过指定的 ClassLoader 和 接口数组 用工厂方法生成 proxy class。 然后这个 proxy class 的名字是:
// Proxy class 的前缀是 “$Proxy”,
private static final String proxyClassNamePrefix = "$Proxy";
long num = nextUniqueNumber.getAndIncrement();
String proxyName = proxyPkg + proxyClassNamePrefix + num;
所以,动态生成的代理类名称是包名+$Proxy+id序号。
生成的过程,核心代码如下:
byte[] proxyClassFile = ProxyGenerator.generateProxyClass(
proxyName, interfaces, accessFlags);
return defineClass0(loader, proxyName,
proxyClassFile, 0, proxyClassFile.length);
这两个方法,我没有继续追踪下去,defineClass0() 甚至是一个 native 方法。我们只要知道,动态创建代理这回事就好了。
现在我们还需要做一些验证,我要检测一下动态生成的代理类的名字是不是包名+$Proxy+id序号。
 ;)
;)
public class Test {
public static void main(String[] args) {
// TODO Auto-generated method stub
MaotaiJiu maotaijiu = new MaotaiJiu();
Wuliangye wu = new Wuliangye();
Furongwang fu = new Furongwang();
InvocationHandler jingxiao1 = new GuitaiA(maotaijiu);
InvocationHandler jingxiao2 = new GuitaiA(wu);
InvocationHandler jingxiao3 = new GuitaiA(fu);
SellWine dynamicProxy = (SellWine) Proxy.newProxyInstance(MaotaiJiu.class.getClassLoader(),
MaotaiJiu.class.getInterfaces(), jingxiao1);
SellWine dynamicProxy1 = (SellWine) Proxy.newProxyInstance(MaotaiJiu.class.getClassLoader(),
MaotaiJiu.class.getInterfaces(), jingxiao2);
dynamicProxy.mainJiu();
dynamicProxy1.mainJiu();
SellCigarette dynamicProxy3 = (SellCigarette) Proxy.newProxyInstance(Furongwang.class.getClassLoader(),
Furongwang.class.getInterfaces(), jingxiao3);
dynamicProxy3.sell();
System.out.println("dynamicProxy class name:"+dynamicProxy.getClass().getName());
System.out.println("dynamicProxy1 class name:"+dynamicProxy1.getClass().getName());
System.out.println("dynamicProxy3 class name:"+dynamicProxy3.getClass().getName());
}
}
 ;)
;)
结果如下:
 ;)
;)
销售开始 柜台是: GuitaiA
我卖得是茅台酒。
销售结束
销售开始 柜台是: GuitaiA
我卖得是五粮液。
销售结束
销售开始 柜台是: GuitaiA
售卖的是正宗的芙蓉王,可以扫描条形码查证。
销售结束
dynamicProxy class name:com.sun.proxy.$Proxy0
dynamicProxy1 class name:com.sun.proxy.$Proxy0
dynamicProxy3 class name:com.sun.proxy.$Proxy1
 ;)
;)
SellWine 接口的代理类名是:com.sun.proxy.$Proxy0
SellCigarette 接口的代理类名是:com.sun.proxy.$Proxy1
这说明动态生成的 proxy class 与 Proxy 这个类同一个包。
下面用一张图让大家记住动态代理涉及到的角色。
红框中 $Proxy0 就是通过 Proxy 动态生成的。$Proxy0 实现了要代理的接口。$Proxy0 通过调用 InvocationHandler 来执行任务。
代理的作用
可能有同学会问,已经学习了代理的知识,但是,它们有什么用呢?
主要作用,还是在不修改被代理对象的源码上,进行功能的增强。
这在 AOP 面向切面编程领域经常见。
在软件业,AOP为Aspect Oriented Programming的缩写,意为:面向切面编程,通过预编译方式和运行期动态代理实现程序功能的统一维护的一种技术。AOP是OOP的延续,是软件开发中的一个热点,也是Spring框架中的一个重要内容,是函数式编程的一种衍生范型。利用AOP可以对业务逻辑的各个部分进行隔离,从而使得业务逻辑各部分之间的耦合度降低,提高程序的可重用性,同时提高了开发的效率。
主要功能
日志记录,性能统计,安全控制,事务处理,异常处理等等。
上面的引用是百度百科对于 AOP 的解释,至于,如何通过代理来进行日志记录功能、性能统计等等,这个大家可以参考 AOP 的相关源码,然后仔细琢磨。
同注解一样,很多同学可能会有疑惑,我什么时候用代理呢?
这取决于你自己想干什么。你已经学会了语法了,其他的看业务需求。对于实现日志记录功能的框架来说,正合适。
至此,静态代理和动态代理者讲完了。
总结
- 代理分为静态代理和动态代理两种。
- 静态代理,代理类需要自己编写代码写成。
- 动态代理,代理类通过 Proxy.newInstance() 方法生成。
- 不管是静态代理还是动态代理,代理与被代理者都要实现两样接口,它们的实质是面向接口编程。
- 静态代理和动态代理的区别是在于要不要开发者自己定义 Proxy 类。
- 动态代理通过 Proxy 动态生成 proxy class,但是它也指定了一个 InvocationHandler 的实现类。
- 代理模式本质上的目的是为了增强现有代码的功能。
XML
设计模式
- Java 基础语法
- 数据类型
- 流程控制
- 数组
- 面向对象
- 方法
- 重载
- 封装
- 继承
- 多态
- 抽象类
- 接口
- 枚举
- 常用类
- String
- 日期时间
- 集合类
- 泛型
- 注解
- 异常处理
- 多线程
- IO 流
- 反射
Java 8
- Stream API
- Lambda 表达式
- 新日期时间 API
- 接口默认方法

若有收获,就点个赞吧
0 人点赞
