1、文件分发脚本
修改每个虚拟机的hostname:
vi /etc/hostname
修改hosts文件:
vi /etc/hosts
注意IP和对应的hostname
192.168.119.128 centos7-1
192.168.119.129 centos7-2
192.168.119.130 centos7-3
1.1 scp
发送文件到其他虚拟机:
scp -r hadoop/ root@centos7-2:/opt/module/
从其他虚拟机拉去文件:
scp -r root@centos7-1:/opt/module/hadoop ./
1.2 rsync

1.3 文件同步脚本
cd /usr/local/bin
vi xsync
#!/bin/bash#1. 判断参数个数if [ $# -lt 1 ]thenecho Not Enough Arguement!exit;fi#2. 遍历集群所有机器for host in centos7-1 centos7-2 centos7-3doecho ==================== $host ====================#3. 遍历所有目录,挨个发送for file in $@do#4. 判断文件是否存在if [ -e $file ]then#5. 获取父目录pdir=$(cd -P $(dirname $file); pwd)#6. 获取当前文件的名称fname=$(basename $file)ssh $host mkdir -p $pdirrsync -av $pdir/$fname $host:$pdirelseecho $file does not exists!fidonedone
1.4 ssh登录免密码
生成私钥和公钥,注意切换成非root用户
ssh-keygen -t rsa
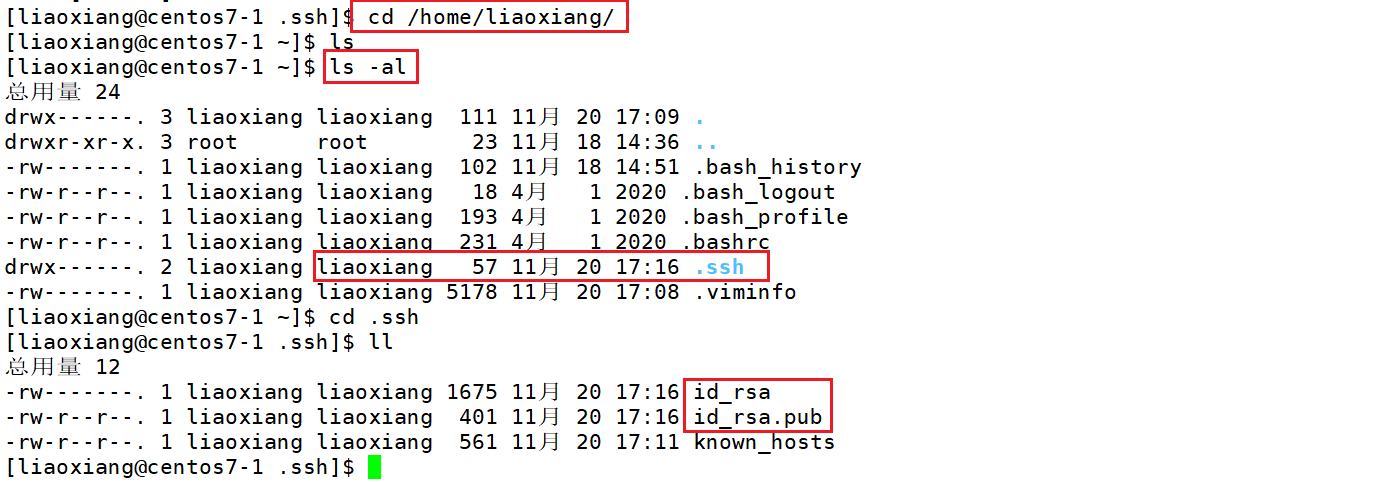
ssh-copy-id centos7-2
输入密码之后,再使用ssh连接centos7-2就不用输入密码了
完成上述配置之后,使用xsync分发脚本就不用再输入密码,上述步骤需要在每个虚拟机上都执行一次,方便互相之间分发文件。
2、集群搭建
2.1 相关配置
下载、解压hadoop到/opt/module目录下
102 103 104 对应7-1 7-2 7-3
修改/opt/module/hadoop/etc/hadoop目录下的配置文件:
core-site.xml
<configuration><!-- nameNode的地址 --><property><name>fs.defaultFS</name><value>hdfs://centos7-1:8020</value></property><!-- 指定hadoop数据的存储目录 --><property><name>hadoop.tmp.dir</name><value>/opt/module/hadoop/data</value></property><!-- 配置HDFS网页登陆使用的静态用户 --><property><name>hadoop.http.staticuser.user</name><value>root</value></property></configuration>
hdfs-site.xml
<configuration><!-- nnweb端访问地址 --><property><name>dfs.namenode.http-address</name><value>centos7-1:9870</value></property><!-- 2nnweb端访问地址 --><property><name>dfs.namenode.secondary.http-address</name><value>centos7-3:9868</value></property></configuration>
yarn-site.xml
<configuration><!-- shuffle --><property><name>yarn.nodemanager.aux-services</name><value>mapreduce_shuffle</value></property><!-- 指定resourceManager的地址 --><property><name>yarn.resourcemanager.hostname</name><value>centos7-2</value></property><!-- 环境变量的继承 --><property><name>yarn.nodemanager.env-whitelist</name><value>JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_MAPRED_HOME</value></property></configuration>
mapred-site.xml
<configuration><!-- 指定 MapReduce 程序运行在 Yarn 上 --><property><name>mapreduce.framework.name</name><value>yarn</value></property></configuration>
配置java环境:
vim hadoop-env.sh
添加:
export JAVA_HOME=jdk路径
修改works:
vim works
centos7-1
centos7-2
centos7-3
修改slaves(3.0以上版本是works)
配置完成之后,使用xsync将hadoop目录分发到其他机器上
2.2 集群启动
在7-1上格式化:
hdfs namenode -format
在7-1的hadoop目录启动hdfs
启动:sbin/start-dfs.sh
停止:sbin/stop-dfs.sh


注意对应关系:
浏览器访问:http://192.168.146.128:9870
在这里可以查看文件:
在7-2上启动yarn
启动:sbin/start-yarn.sh
停止:sbin/stop-yarn.sh

浏览器访问:http://192.168.146.129:8088
配置历史服务器
修改centos7-1的mapred-site.xml ,并分发到其他机器
<!-- 历史服务器端地址 --><property><name>mapreduce.jobhistory.address</name><value>hadoop102:10020</value></property><!-- 历史服务器 web 端地址 --><property><name>mapreduce.jobhistory.webapp.address</name><value>centos7-1:19888</value></property>
启动历史服务器:
mapred —daemon start historyserver
停止历史服务器:
mapred —daemon stop historyserver
浏览器访问:http://192.168.146.128:19888/jobhistory
配置日志的聚集
应用运行完成以后,将程序运行日志信息上传到 HDFS 系统上,开启日志聚集功能, 需要重新启动NodeManager 、 ResourceManager 和HistoryServer。
配置 yarn-site.xml
<!-- 开启日志聚集功能 --><property><name>yarn.log-aggregation-enable</name><value>true</value></property><!-- 设置日志聚集服务器地址 --><property><name>yarn.log.server.url</name><value>http://centos7-1:19888/jobhistory/logs</value></property><!-- 设置日志保留时间为 7 天 --><property><name>yarn.log-aggregation.retain-seconds</name><value>604800</value></property>
分别启动/停止 HDFS 组件:
hdfs —daemon start/stop namenode/datanode/secondarynamenode
启动/停止 YARN:
yarn —daemon start/stop resourcemanager/nodemanager
在/usr/local/bin下创建集群启动脚本:myhadoops
vim myhadoops
#!/bin/bashif [ $# -lt 1 ]thenecho "No Args Input..."exit ;ficase $1 in"start")echo " =================== 启动 hadoop 集群 ==================="echo " --------------- 启动 hdfs ---------------"ssh centos7-1 "/opt/module/hadoop/sbin/start-dfs.sh"echo " --------------- 启动 yarn ---------------"ssh centos7-2 "/opt/module/hadoop/sbin/start-yarn.sh"echo " --------------- 启动 historyserver ---------------"ssh centos7-1 "/opt/module/hadoop/bin/mapred --daemon start historyserver";;"stop")echo " =================== 关闭 hadoop 集群 ==================="echo " --------------- 关闭 historyserver ---------------"ssh centos7-1 "/opt/module/hadoop/bin/mapred --daemon stop historyserver"echo " --------------- 关闭 yarn ---------------"ssh centos7-2 "/opt/module/hadoop/sbin/stop-yarn.sh"echo " --------------- 关闭 hdfs ---------------"ssh centos7-1 "/opt/module/hadoop/sbin/stop-dfs.sh";;*)echo "Input Args Error...";;esac
chmod 777 myhadoops
编写查看java进程脚本:
#!/bin/bashfor host in centos7-1 centos7-2 centos7-3doecho =============== $host ===============ssh $host /usr/local/java/jdk1.8.0_212/bin/jpsdone

若有收获,就点个赞吧
0 人点赞
