CAP理论
C:Consistency (强一致性)
A:Availability (可用性)
P:Partition tolerance (分区容错性)
CAP理论是指,在分布式存储系统中,最多只能实现CAP的两个特点,分区容错性是必须要实现的,要不然无法进行数据的统一,一般都是选择可用性,牺牲强一致性。
Redis简介
Redis:Remote Dictionary Server(远程字典服务器)
是完全开源免费的,用C语言编写的,遵守BSD协议,是一个高性能的(Key/Value)分布式内存数据 库,基于内存运行,并支持持久化的NoSQL数据库,是当前最热门的NoSQL数据库之一,也被人们称为数据结构服务器。
特点:
- Redis支持数据的持久化,可以将内存中的数据保持在磁盘中,重启的时候会再次进行加载使用
- Redis不仅仅支持简单的key-value类型的数据,还支持list、set、hash、zset等数据结构的存储
Redis支持数据的备份,master-slave模式的数据备份
用途:
redis支持异步将内存的数写到硬盘上,同时不影响继续服务
- 取最新N个数据的操作(例如:可以将最新的10条评论ID放在Redis的List集合里面)
- 高频查找、并发高的数据可以放在Redis中
- 商品秒杀
- 发布、订阅消息系统
- 地图信息分析
- 定时器、计数器
安装:37、Redis精讲.pdf
默认16个数据库,从0开始,默认使用0号库
默认端口:6379常用命令:
select index(数据库号) 切换数据库DBSIZE 查看当前数据库key的数量keys * 查看具体的keyFlushdb 清空当前库Flushall 清空全部库单线程:
Redis在处理客户端的请求时,包括获取 (socket 读)、解析、执行、内容返回 (socket 写) 等都由一个顺序串行的主线程处理,这就是所谓的“单线程”。但如果严格来讲从Redis4.0之后并不是单线程,除了主线程外,它也有后台线程在处理一些较为缓慢的操作,例如清理脏数据、无用连接的释放、大 key 的删除等等
为什么Redis单线程还这么快:
首先最重要的一点就是Redis完全基于内存,纯粹的内存操作非常快速;
Redis对数据操作也简单,数据结构是专门进行设计的;
多线程是CPU空闲,为了提高CPU利用率而采用的办法,CPU不是Redis的瓶颈,Redis的瓶颈在于内存和网络;
使用多路复用I/O,多路I/O复用模型是利用 select、poll、epoll 可以同时监察多个流的 I/O 事件的能力,在空闲的时候,会把当前线程阻塞掉,当有一个或多个流有 I/O 事件时,就从阻塞态中唤醒,于是程序就会轮询一遍所有的流(epoll 是只轮询那些真正发出了事件的流),并且只依次顺序的处理就绪的流,这种做法就避免了大量的无用操作。
Redis采用Reactor的方式来处理文件事件处理器(每一个网络连接其实都对应一个文件描述符)
文件事件处理器使用 I/O 多路复用模块同时监听多个 FD,当 accept、read、write 和 close 文件事件产生时,文件事件处理器就会回调 FD 绑定的事件处理器。
虽然整个文件事件处理器是在单线程上运行的,但是通过 I/O 多路复用模块的引入,实现了同时对多个 FD 读写的监控,提高了网络通信模型的性能,同时也可以保证整个 Redis 服务实现的简单。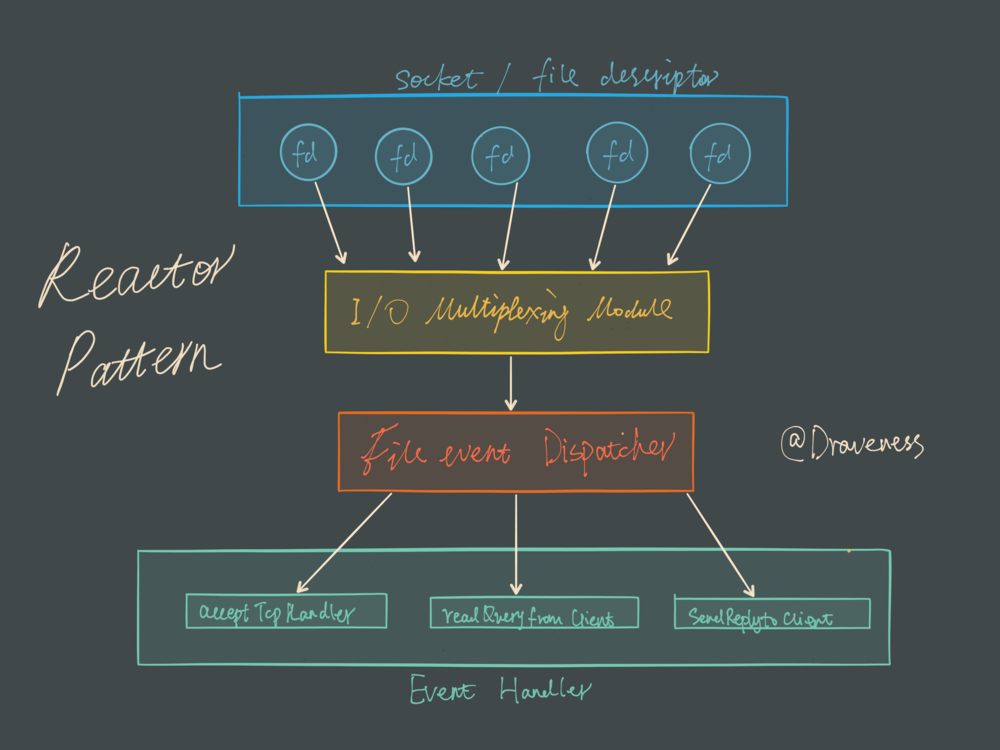
多线程:
Redis 6.0 支持多线程
为什么要开始多线程?
从Redis自身角度来说,因为读写网络的read/write系统调用占用了Redis执行期间大部分CPU时间,瓶颈主要在于网络的 IO 消耗, 优化主要有两个方向:
• 提高网络 IO 性能,典型的实现比如使用 DPDK 来替代内核网络栈的方式
• 使用多线程充分利用多核,典型的实现比如 Memcached。
协议栈优化的这种方式跟 Redis 关系不大,支持多线程是一种最有效最便捷的操作方式。所以总结起来,redis支持多线程主要就是两个原因:
• 可以充分利用服务器 CPU 资源,目前主线程只能利用一个核
• 多线程任务可以分摊 Redis 同步 IO 读写负荷
基本数据类型
String(字符串类型)
String一个key对应一个value,value最大为512M,另外,String类是二进制安全的,也就是说可以存储图片或者序列化的对象,是Redis最基本的对象。
可以利用INCR命令,方便的统计访问量,比如存放登陆验证码生成的图片。
Hash (类似Java里的Map)
键值对集合,String类型的,就和hashmap差不多,适合于存储对象 比如商品(id,name,数量)
List(列表)
底层是一个String类型的链表,是按插入顺序来排序的,
比如 用户的关注列表,粉丝列表
Set(集合)
是String类型的无序集合(无序指的是不按放进去的顺序排,并不是说完全没顺序),是通过HashTable来实现的,不允许重复。
利用其唯一性求交集,并集,差集:(Set)
ZSet(有序集合)
按照score 进行排序,score允许重复,但value不允许重复,就像java里的Set
应用:排行榜 、取TopN操作
带权重的消息队列
特殊数据类型
GEO地理位置
HyperLogLog 不精确的快速去重技术
比如{1,3,3,4,5,5,6} 基数集{1,3,4,5,6} 不重复元素为5
BitMap
利用二进制存储0和1,比如7天签到 010101 0为未签到 1为签到 节省空间
持久化
RDB
什么是RDB
在指定的时间间隔内或指定的规则内,将内存中的数据集快照以二进制的方式写入到磁盘中,以此来实现持久化,也就是通常说的Snapshot,恢复数据的话是把磁盘里的RDB文件再读到内存里,也就是Redis的进程会基于此运行。
RDB过程
Redis主进程会fork出一个子进程来进行持久化,会先将数据写入到一个临时文件中,等待持久化过程都结束了,再用这个临时文件替换上次持久化好的文件,整个过程中,主进程是不进行任何IO操作的,这样就能保证不影响Redis的性能,如果需要进行大规模数据的恢复,RDB是要比AOF高效的,但是可能最后一次持久化的数据可能会保存不了丢失,所以对数据的完整性要求极高就不要使用RDB,在Redis启动时会自动把RDB文件加载到内存里,保证了Redis数据库的数据,Redis默认配置就是采用RDB来持久化的。
FORK
FORK的意思是分叉,就是复制一个和当前进程一模一样的子进程,新进程的(变量、环境变量、程序计数器等)都和当前进程保持一致,但是是一个全新的进程,并且作为原进程的子进程。
RDB文件
持久化的文件命一般默认为dump.rdb,存放在redis的运行目录下,可以在redis.conf中配置重命名,除此之外还可以自定义RDB的保存规则,在原来的redis.conf中是这样配置的:save 900 1 save 300 10 save 60 10000 ,意思是每 900秒更新一次数据就触发一次rdb操作,除此之外,Redis停止服务的时候也会触发一次持久化,也就是写入新的RDB文件到磁盘,如果是宕机或者突然断电,那么最后一次保存的数据可能就没有写入到磁盘里的RDB恢复文件中。
手动触发:
save:只管保存,其他请求不管,全部阻塞
bgsave:后台异步进行快照操作,同时还可以处理客户端请求
恢复:
只要放到redis安装的目录下,redis启动的时候就会自动恢复,dir配置文件里可以看,也可以通过命令**config get dir** 来拿到目录。
优缺点:
优点:
适合大量数据的恢复
恢复速度稍微快一点,也简单方便
缺点:
数据的完整性不高,有数据丢失的风险
FORK的时候,内存中的数据相当于被克隆了一份,需要考虑内存空间
AOF
什么是AOF
和RDB不同,AOF是以日志的形式记录下来执行过的每个操作(除了读操作),只许追加不可改写,Redis启动的时候会读取这个日志来构建数据,以此来实现数据的恢复,其实就是把之前执行过的命令执行了一遍,怎样数据就和原来是一样的。
配置
appendonly no # 是否以append only模式作为持久化方式,默认使用的是rdb方式持久化,这种方式在许多应用中已经足够用了appendfilename "appendonly.aof" # appendfilename AOF 文件名称appendfsync everysec # appendfsync aof持久化策略的配置# no表示不执行fsync,由操作系统保证数据同步到磁盘,速度最快。# always表示每次写入都执行fsync,以保证数据同步到磁盘。# everysec表示每秒执行一次fsync,可能会导致丢失这1s数据。No-appendfsync-on-rewrite #重写时是否可以运用Appendfsync,用默认no即可,保证数据安全性Auto-aof-rewrite-min-size # 设置重写的基准值Auto-aof-rewrite-percentage #设置重写的基准值
AOF过程
AOF通过redis.conf的配置开启,即 appendonly yes ,然后根据配置的不同情况,
具体情况有:
always 每次写入都执行 fsync 同步数据到磁盘 这种数据完整性是最高的
everysec 每秒执行一次 fsync 可能会丢失1s数据
no 不执行fsync 由系统保证数据同步到磁盘 速度最快 数据完整性较差
来执行同步,AOF只允许追加,文件会越来越大,一般在大于64M的时候,会采用重写机制,Redis就会将启动AOF文件的内容压缩,只保留可以恢复数据的最小指令集。
优缺点:
优点:
缺点:
Reids事务
Redis事务的本质是一组命令的集合,事务支持一次执行多个命令,一个事务中所有命令都会被序列化,在事务执行过程中,严格按照顺序执行这一系列命令,其他客户端提交的命令不会插入到这一系列命令中。
总的来说:redis的事务就是一次性按顺序执行给定的命令集合,不会插入其他的命令。
正常执行: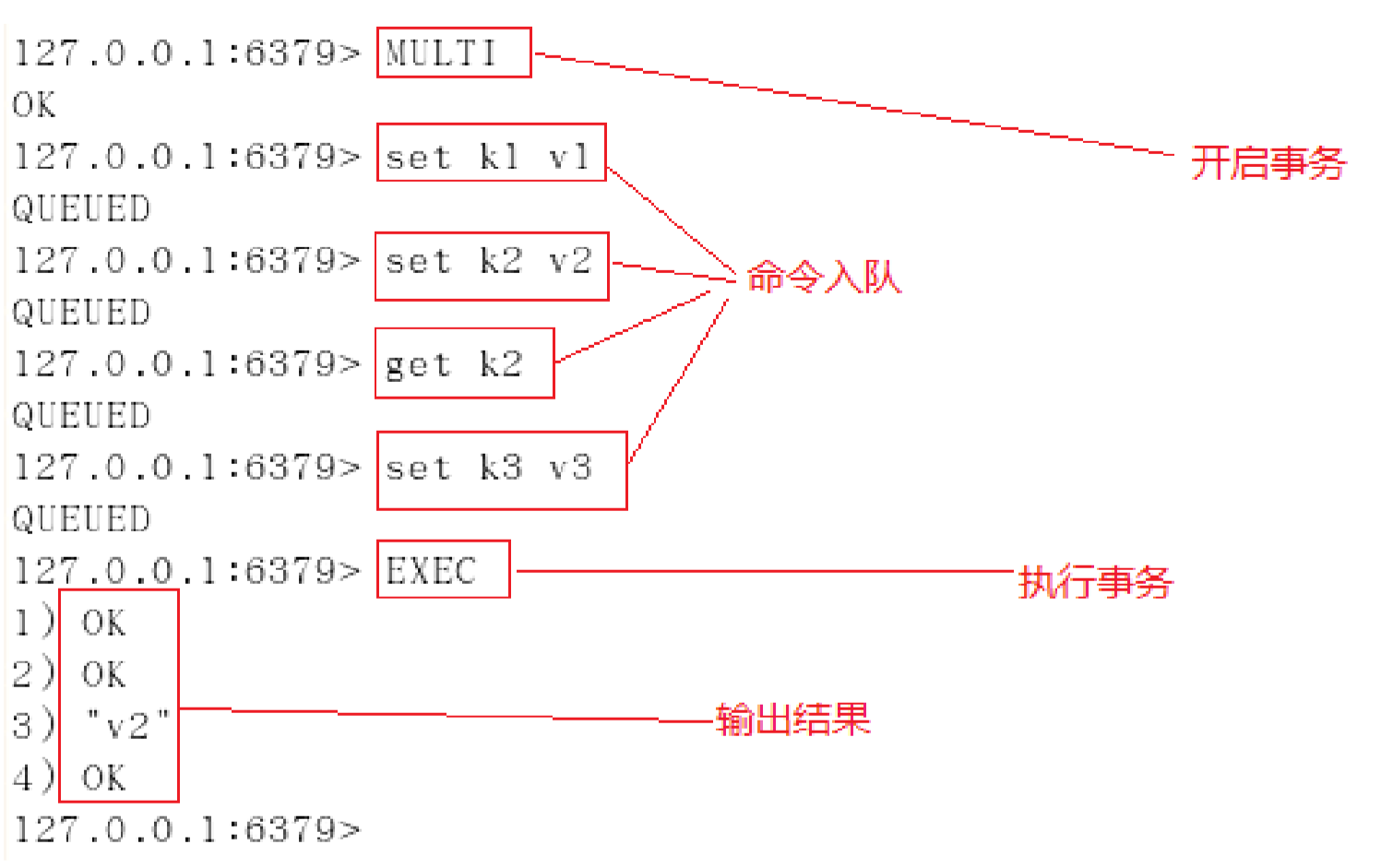
命令性错误

如果有命令性错误,事务里的所有命令都不会执行。
语法性错误

主从复制 读写分离
主从复制,也就是将一台Redis服务器的数据,复制到其他的Redis服务器,前者称为主节点(master),后者称为从节点(leader),数据的复制是单向的,也就是只能从主节点到从节点,Master主要负责写操作,Slave负责读操作,一个主节点可以有多个从节点,一个从节点只能有一个主节点。
作用:
- 数据冗余,主从复制实现了数据的热备份,是持久化之外的一种数据冗余方式
- 故障恢复,当主节点出现问题时,可以由从节点提供服务,实现快速的故障恢复
- 负载均衡,主从复制的基础上,实现了读写分离,分担了服务器的负载,正常情况下肯定是写少读多的场景,这种场景下读写分离是非常有利于分摊服务器的压力的,提高Redis服务器的并发量。
- 高可用的基石(是哨兵和集群实施的基础)

配置
至少需要三台Redis服务器,第一种方式是在从机配置文件里就写好主机的地址,直接按配置文件启动redis-server /etc/redis.conf就可以实现主从复制。
另外一种就是在从机上 slaveof 主机ip+主机端口 也可以实现。redis-cli -p 6379auth 123123
可以在redis里面通过info replication来查看当前主从关系
需要注意的是,如果主机有密码,从机需要将密码写在配置文件里。
复制原理
Slave 启动成功连接到 master 后会发送一个sync命令
Master 接到命令,启动后台的存盘进程,同时收集所有接收到的用于修改数据集命令,在后台进程执行
完毕之后,master将传送整个数据文件到slave,并完成一次完全同步。
全量复制:而slave服务在接收到数据库文件数据后,将其存盘并加载到内存中。
增量复制:Master 继续将新的所有收集到的修改命令依次传给slave,完成同步
但是只要是重新连接master,一次完全同步(全量复制)将被自动执行
哨兵模式
如果没有哨兵模式的情况下,当我们的主Redis服务器挂掉后,我们需要在从机的服务器中,手动的通过slave no one 来将自己改为主机。这样做麻烦又费时,所以诞生了哨兵模式。
哨兵是一个独立的进程,独立运行,他的基本原理就是:给redis服务器发送命令,看redis服务器回不回,如果回了就证明redis服务器好着呢,没回到一定条件就认为这个服务器挂掉了。
如上是一个哨兵监控多个redis服务器
哨兵作用:
- 通过发送命令,让redis服务器返回其运行状态,包括主服务器和从服务器
- 当哨兵检测到master宕机,会自动将slave切换到master,然后通过发布订阅模式通知其他的从服务器,修改配置文件,让他们切换主机

单个哨兵可能会出现问题,一般使用多个哨兵进行监控,比如上面的3个哨兵检测3台服务器,当哨兵1发现master宕机后,并不会直接通知slave1和slave2切换主机,而是会等待其他的两台哨兵也检测到master宕机后,然后进行投票,投票通过后由一个哨兵发起,进行【故障转移】操作,切换成功后,就会通过发布订阅模式,让各个哨兵把自己监控的从服务器实现切换主机。
配置测试
- 调整结构,6379带着80、81
- 自定义的 /myredis 目录下新建 sentinel.conf 文件,名字千万不要错
- 配置哨兵,填写内容
sentinel monitor 被监控主机名字 127.0.0.1 6379 1,上面最后一个数字1,表示主机挂掉后slave投票看让谁接替成为主机,得票数多少后成为主机 - 启动哨兵
Redis-sentinel /myredis/sentinel.conf上述目录依照各自的实际情况配置,可能目录不同 - 正常主从演示
- 原有的Master 挂了
- 投票新选
- 重新主从继续开工,info replication 查查看
- 问题:如果之前的master 重启回来,会不会双master 冲突?
-
优缺点:
优点:
- 哨兵模式具有主从模式的所有优点
- 在主从模式上进一步实现了故障自动转移,可用性更好
- 系统更健壮,可用性更高
缺点:
- redis较难支持在线扩容
- 配置也比较繁琐
配置
# Example sentinel.conf# 哨兵sentinel实例运行的端口 默认26379port 26379# 哨兵sentinel的工作目录dir /tmp# 哨兵sentinel监控的redis主节点的 ip port# master-name 可以自己命名的主节点名字 只能由字母A-z、数字0-9 、这三个字符".-_"组成。# quorum 配置多少个sentinel哨兵统一认为master主节点失联 那么这时客观上认为主节点失联了# sentinel monitor <master-name> <ip> <redis-port> <quorum>sentinel monitor mymaster 127.0.0.1 6379 2# 当在Redis实例中开启了requirepass foobared 授权密码 这样所有连接Redis实例的客户端都要提供密码# 设置哨兵sentinel 连接主从的密码 注意必须为主从设置一样的验证密码# sentinel auth-pass <master-name> <password>sentinel auth-pass mymaster MySUPER--secret-0123passw0rd# 指定多少毫秒之后 主节点没有应答哨兵sentinel 此时 哨兵主观上认为主节点下线 默认30秒# sentinel down-after-milliseconds <master-name> <milliseconds>sentinel down-after-milliseconds mymaster 30000# 这个配置项指定了在发生failover主备切换时最多可以有多少个slave同时对新的master进行 同步,这个数字越小,完成failover所需的时间就越长,但是如果这个数字越大,就意味着越 多的slave因为replication而不可用。可以通过将这个值设为 1 来保证每次只有一个slave 处于不能处理命令请求的状态。# sentinel parallel-syncs <master-name> <numslaves>sentinel parallel-syncs mymaster 1# 故障转移的超时时间 failover-timeout 可以用在以下这些方面:#1. 同一个sentinel对同一个master两次failover之间的间隔时间。#2. 当一个slave从一个错误的master那里同步数据开始计算时间。直到slave被纠正为向正确的master那里同步数据时。#3.当想要取消一个正在进行的failover所需要的时间。#4.当进行failover时,配置所有slaves指向新的master所需的最大时间。不过,即使过了这个超时,slaves依然会被正确配置为指向master,但是就不按parallel-syncs所配置的规则来了# 默认三分钟# sentinel failover-timeout <master-name> <milliseconds>sentinel failover-timeout mymaster 180000# SCRIPTS EXECUTION#配置当某一事件发生时所需要执行的脚本,可以通过脚本来通知管理员,例如当系统运行不正常时发邮件通知相关人员。#对于脚本的运行结果有以下规则:#若脚本执行后返回1,那么该脚本稍后将会被再次执行,重复次数目前默认为10#若脚本执行后返回2,或者比2更高的一个返回值,脚本将不会重复执行。#如果脚本在执行过程中由于收到系统中断信号被终止了,则同返回值为1时的行为相同。#一个脚本的最大执行时间为60s,如果超过这个时间,脚本将会被一个SIGKILL信号终止,之后重新执行。#通知型脚本:当sentinel有任何警告级别的事件发生时(比如说redis实例的主观失效和客观失效等等),将会去调用这个脚本,这时这个脚本应该通过邮件,SMS等方式去通知系统管理员关于系统不正常运行的信息。调用该脚本时,将传给脚本两个参数,一个是事件的类型,一个是事件的描述。如果sentinel.conf配置文件中配置了这个脚本路径,那么必须保证这个脚本存在于这个路径,并且是可执行的,否则sentinel无法正常启动成功。#通知脚本# sentinel notification-script <master-name> <script-path>sentinel notification-script mymaster /var/redis/notify.sh# 客户端重新配置主节点参数脚本# 当一个master由于failover而发生改变时,这个脚本将会被调用,通知相关的客户端关于master地址已经发生改变的信息。# 以下参数将会在调用脚本时传给脚本:# <master-name> <role> <state> <from-ip> <from-port> <to-ip> <to-port># 目前<state>总是“failover”,# <role>是“leader”或者“observer”中的一个。# 参数 from-ip, from-port, to-ip, to-port是用来和旧的master和新的master(即旧的slave)通信的# 这个脚本应该是通用的,能被多次调用,不是针对性的。# sentinel client-reconfig-script <master-name> <script-path>sentinel client-reconfig-script mymaster /var/redis/reconfig.sh
缓存穿透雪崩击穿
缓存穿透(缓存和数据库都没有)
缓存穿透是指,客户端发过来的请求查询一个数据,发现Redis中没有数据,去数据库MySQL中查找,造成MySQL压力过大,响应慢,这个时候就相当于出现了缓存穿透。
解决方案:
对于一些恶意查询请求,接口层添加相应的过滤(布隆过滤器)
缓存空对象,当MySQL也没查到时,将返回的空对象也缓存到redis中,设置一个30s的过期时间(不要太长,但是可以极大降级性能影响),这样的话能起到保护MySQL的作用缓存击穿(缓存突然没有数据库还有单个)
缓存击穿是指,一个key非常热点,不停的扛着高并发,高并发持续集中对着一个点进行访问,如果这个key设置了过期时间,那么一瞬间会涌向MySQL,会导致数据库瞬间压力过大。
解决方案:
设置热点key永不过期
使用分布式锁,保证每个key同时只有一个线程去查询后端服务,压力转移给分布式锁缓存雪崩(缓存没有数据库还有批量)
缓存雪崩是指,在某一个时间段,缓存集中过期失效,致命的是缓存服务器的某个节点宕机或者断网形成的缓存雪崩(比如只有一台redis),可能会瞬间把数据库服务器击垮。
比如,秒杀抢购的时候,一批商品放进了缓存,刚好0点过期了,就会导致大批量进入数据库查询,数据库的访问暴增,造成数据库也挂掉。
解决方案:
集群布置,主从复制,多台Redis一起工作
限流降级,加锁,排队查询数据库
数据预热:热点key提前放进数据库,过期时间设置成不同的,均匀过期,不能说同时过期。面试题:
redis为什么这么快?
- Redis是基于内存的,这一点就比基于硬盘的要快很多。
对于Mysql这些基于磁盘的而言,会受到磁盘IO的限制和影响,内存速度一般肯定比磁盘快很多的,磁盘一般都是永久化存储,除了固态是电压,普通的机械盘其实就是碟片,还是机械式的获取数据,而 - Redis对数据类型的优化,对底层数据结构的优化。
- String :动态字符串
- 长度处理:C语言是遍历到”/0”,然后得到字符串的长度,而Redis中,有一个字段len就存储着字符串的长度,这样对比速度是O(n)到O(1)的提升
- 空间预分配:len长度小于1M,那么将分配同等大小的未使用空间,如果大于1M。那么就分配1M的使用空间。
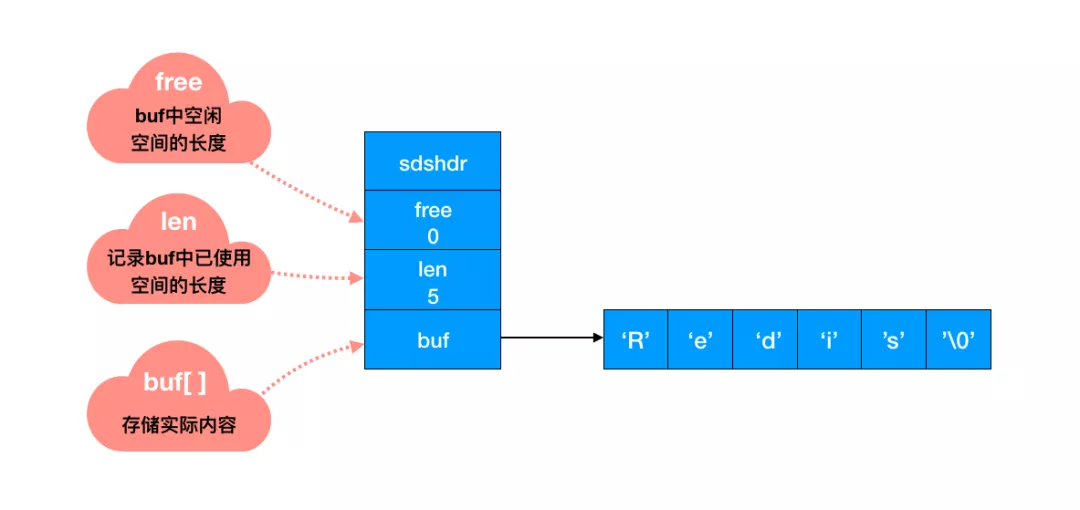
- List 也有一个len来记录链表长度,是一个双向无环链表
- String :动态字符串
https://mp.weixin.qq.com/s/0R0Evh1QX5BPOQt9233vpQ
- Redis合适的线程模型
多路复用IO,对内存而言,一直干活就是最快的,频繁的切换会拖延时间,多次读写都在一个CPU 上,对于内存来说就是最佳方案,Redis 中使用 I/O 多路复用程序同时监听多个套接字,并将这些事件推送到一个队列里,然后命令逐个被执行,最终将结果返回给客户端。Reids项目中的实际应用:
是验证码的存储,项目登陆的验证码是用的base64加密,每一个验证码有一个UUID作为key,验证码的答案作为value存入到Redis中,到时候前端提交过来的答案就对比一下,按条件返回异常或者成功。
还有就是采购还有出库的一些商品记录,一般就是放5条最新的历史记录,这个是放在Set里面,可以去重,然后按时间排序,再就是满5个自动删除一个,就可以了。

若有收获,就点个赞吧
0 人点赞
