Map
Map是一个接口,存储的类型是键值对,提供了key到Value的映射,key和value一一对应,key不能为空。
HashMap
HashMap了解多少?
HashMap底层实现
HashMap 是用【数组 + 链表+ 红黑树】(JDK1.8开始增加了红黑树)进行实现的,当添加一个元素(key-value)时,首先计算元素key的hash值,并根据hash值来确定插入数组的位置(也就是我们常说的桶位),如果发生碰撞(存在其他元素已经被放在数组同一位置),这个时候便使用链表来解决哈希冲突,当链表长度太长的时候,便将链表转为红黑树来提高搜索的效率。
数组的默认容量为16,懒加载机制,new的时候未加载,第一次put的时候才会加载
但是通过反射 获取capacity还是16- 容量是以2的次方扩充的,
一是为了提高性能使用足够大的数组,
二是为了能使用位&运算代替取模预算,因为计算机存储的数据都是二进制的,位运算的速度要比取模%运算快
当以2的次方扩充时,就能保证n永远是2的次幂,此时n-1就能保证后面全为1,此时(n-1)&hash=hash%n,以此来快速决定key- 数组是否需要扩充是通过负载因子判断的,如果当前元素个数为数组容量的0.75时,就会扩充数组,这个0.75就是默认的负载因子,可由构造函数传入。
为什么选择0.75作为负载因子,这是因为在0.75是在时间和空间上的一种折中的选择,如果选择0.5会太浪费空间,而且会频繁扩容,选择0.9或者1的话,又大大增加了查询时间成本,选择0.75的原因还有就是说,8是是链表长度的一个阈值,按照泊松分布来看,当负载因子为0.75时,每个链表超过8的概率是非常非常小的,选择0.75性价比极高 为了解决碰撞,数组中的元素是单向链表类型。当链表长度达一个阈值时(>=8),且总长度大于64,会将链表转换为红黑树提高性能。而当链表长度缩小到另一个阈值(<=6)时,又会将红黑树转换回单向链表提高性能。
如何减少哈希碰撞:HashMap中为了减少哈希碰撞,在原来hash值的基础上,通过高低位异或运算,让高位也参与运算可以减少哈希碰撞,还有就是通过两次位运算扰动,如果没有这两次扰动,仅仅高位发生变化的话,很容易产生哈希碰撞。
HashMap的put方法执行流程/步骤
- 判断数组table是否为null,若为null则执行resize()扩容操作(即进行初始化,没有指定容量就按默认的16开辟数组空间)。
- 根据键key的值进行(n-1)&hash 位运算(位运算代替了取模运算,CPU位运算速度快),得到插入的数组索引i,若table[i] == nulll,则直接新建节点插入,进入步骤6;若table[i]非null,则继续执行下一步。
- 判断table[i]的首个元素key是否和当前key相同(hashCode和equals均相同),若相同则直接覆盖value,进入步骤6,反之继续执行下一步。
- 判断table[i]是否为treeNode,若是红黑树,则直接在树中插入键值对并进入步骤6,反之继续执行下一步。
- 遍历table[i],判断链表长度是否大于8,若>8,则把链表转换为红黑树,在红黑树中执行插入操作;若<8,则进行链表的插入操作;遍历过程中若发现key已存在则会直接覆盖该key的value值。
- 插入成功后,判断实际存在的键值对数量size是否超过了最大容量threshold,若超过则进行扩容。
HashMap的get方法执行流程/步骤
- 根据键key的值进行(n-1)&hash 位运算,得到插入的数组索引i,定位到键所在的数组的下标,并获取对应节点n。
- 判断n是否为null,若n为null,则返回null并结束;反之,继续下一步。
- 判断n的key和要查找的key是否相同(key相同指的是hashCode和equals均相同),若相同则返回n并结束;反之,继续下一步。
- 判断是否有后续节点m,若没有则结束;反之,继续下一步。
- 判断m是否为红黑树,若为红黑树则遍历红黑树,getTreeCode()遍历,遍历过程中如果存在某一个节点的key与要找的key相同,则返回该节点;反之,返回null;若非红黑树则继续下一步。
- 遍历链表,若存在某一个节点的key与要找的key相同,则返回该节点;反之,返回null。
HashMap的扩容机制
扩容是为了防止HashMap中的元素个数超过了阀值,从而影响性能所服务的。而数组是无法自动扩容的,HashMap的扩容是申请一个容量为原数组大小两倍的新数组,然后遍历旧数组,重新计算每个元素的索引位置,并复制到新数组中;又因为HashMap的哈希桶数组大小总是为2的幂次方,所以重新计算后的索引位置要么在原来位置不变,要么就是“原位置+旧数组长度”。其中,threshold和loadFactor两个属性决定着是否扩容。threshold=Length*loadFactor,Length表示table数组的长度(默认值为16),loadFactor为负载因子(默认值为0.75);阀值threshold表示当table数组中存储的元素个数超过该阀值时,即需要扩容。
HashMap的扩容使用新的数组代替旧数组,然后将旧数组中的元素重新计算索引位置并放到新数组中,对旧数组中的元素如何重新映射到新数组中?
- HashMap的哈希算法数组扩容
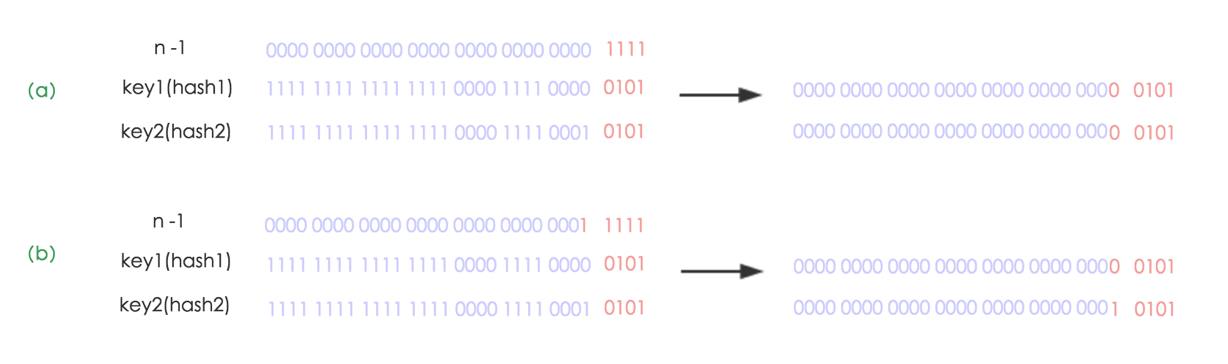
(a)为扩容前,key1和key2两个key确定索引的位置;(b)为扩容后,key1和key2两个key确定索引的位置;hash1和hash2分别是key1与key2对应的哈希“与高位运算”结果。
(a)中数组的高位bit为“1111”,120 + 121 + 122 + 123 = 15,而 n-1 =15,所以扩容前table的长度n为16;
(b)中n扩大为原来的两倍,其数组大小的高位bit为“1 1111”,120 + 121 + 122 + 123 + 1*24 = 15+16=31,而 n-1=31,所以扩容后table的长度n为32;
(a)中的n为16,(b)中扩大两倍n为32,相当于(n-1)这部分的高位多了一个1,然后和原hash码作与操作,最后元素在新数组中映射的位置要么不变,要么向后移动16个位置。 - HashMap中数组扩容两倍后位置的变化
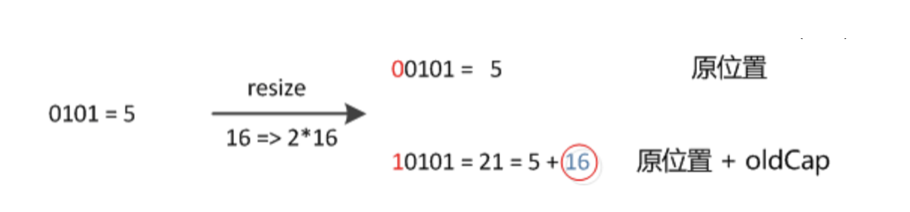
因此,在扩充HashMap,复制数组元素及确定索引位置时不需要重新计算hash值,只需要判断原来的hash值新增的那个bit是1,还是0;若为0,则索引未改变;若为1,则索引变为“原索引+oldCap” - HashMap中数组16扩容至32
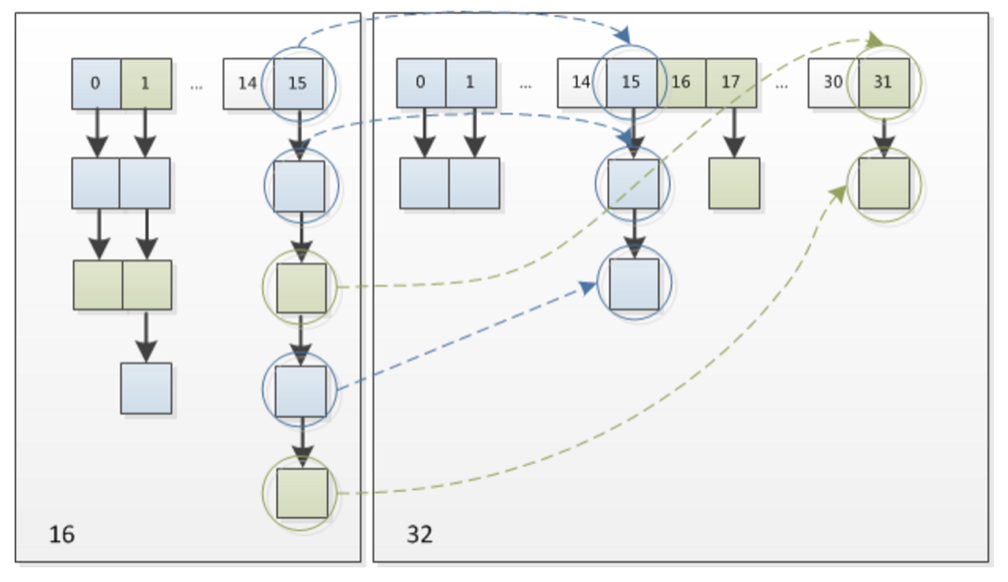
JDK1.7中扩容时,旧链表迁移到新链表的时候,若出现在新链表的数组索引位置相同情况,则链表元素会倒置,但从上图中看出JKD1.8的扩容并不会颠倒相同索引的链表元素。
- HashMap的哈希算法数组扩容
- **扩容机制设计的优点
**
- 省去了重新计算hash值的时间(由于位运算直接对内存数据进行操作,不需要转成十进制,因此处理速度非常快),只需判断新增的一位是0或1;
- 由于新增的1位可以认为是随机的0或1,因此扩容过程中会均匀的把之前有冲突的节点分散到新的位置(bucket槽),并且位置的先后顺序不会颠倒;
线程安全
- HashMap是非线程安全的;
- Hashtable是线程安全的,方法被synchronized修饰;
使用的是, synchronized多线程下会进入阻塞或者轮询状态,比如进行一个put会把整个map对象锁住
- 是否允许NULL值
- HashMap允许有一个key是NULL,允许值为NULL;
- Hashtable无论是key还是value都不允许为NULL;
- 继承的父类
- HashMap和Hashtable都实现了Map接口;
- HashMap继承的父类是AbstractMap;
- Hashtable继承的父类是Dictionary;
- contains()方法
- HashMap没有contains()方法,但有containsValue和containsKey方法;
- Hashtable保留了contains方法,也有containsValue和containsKey方法;contains方法与containsValue方法效果一样(containsValue方法里调用contains方法)。
- 计算hash值的方式不同
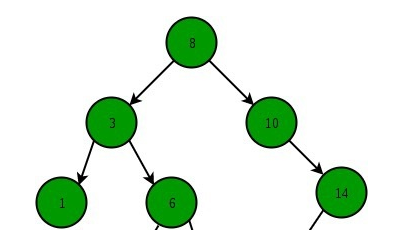
- 二叉树
- 某节点的左子树节点值仅包含小于该节点值
- 某节点的右子树节点值仅包含大于该节点值
左右子树每个也必须是二叉查找树
图示
红黑树
每个节点都有红色或黑色
树的根始终是黑色的
没有两个相邻的红色节点(红色节点不能有红色父节点或红色子节点,并没有说不能出现连续的黑色节点)
从节点(包括根)到其任何后代NULL节点(叶子结点下方挂的两个空节点,并且认为他们是黑色的)的每条路径都具有相同数量的黑色节点。
ConcurrentHashMap
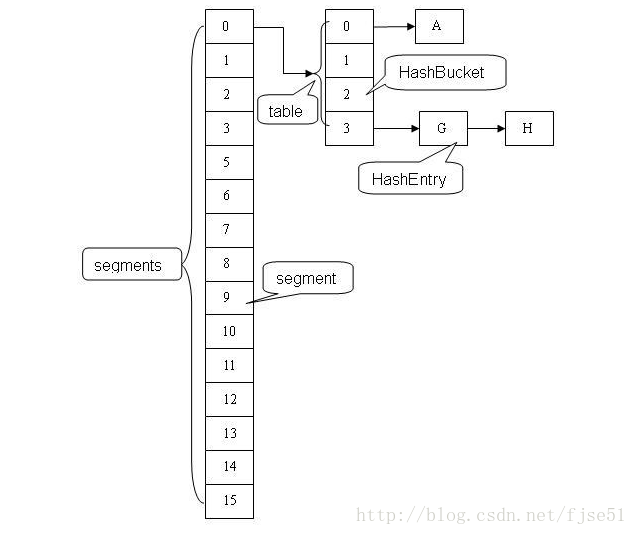
因为hashMap线程不安全,hashTable线程安全但效率又很低,所以诞生了ConcurrentHashMap,适用于多线程和并发环境下
- 多线程
- 1.7
- 采用分段锁,底层是由Segments数组和HashEntry数组组成,Segment继承了RetrenLock充当锁的角色,每个Segment按并发度来操作对应数量的HashEntry,HashEntry是存放k-v键值对的,当要对对应得 HashEntry数组的数据进行修改时,必须首先获得它对应的 Segment 锁
- 结构是数组加链表
- put操作基本思路跟HashMap基本上是一样的,只是在开始跟结束进行了加锁的操作tryLock and unlock,然后JDK7中都是先扩容再添加数据的,并且获得不到锁也会进行自旋的tryLock或者lock阻塞排队进行等待(同时获得锁前提前new出新数据)。
- 1.8
- 舍弃了Segment,直接采用
**transient volatile HashEntry<K,V> table**保存数据,采用table数组元素作为锁,从而实现了对每一行数据进行加锁,进一步减少并发冲突的概率。 - 将原先table数组+单向链表的数据结构,变更为table数组+单向链表+红黑树的结构
- 舍弃了Segment,直接采用
- 基于并发的等级来划分整个Map来达到线程安全,只会锁操作的那一段数据,而不是像HashTable和collection.synchronizedMap修饰的HashMap直接锁整个map对象
- 利用Node +CAS+synchronized来保证并发安全,划分并发等级
- 1.7
- put方法
- 根据 key 计算出 hashcode 。
- 判断是否需要进行初始化。
- f 即为当前 key 定位出的 Node,如果为空表示当前位置可以写入数据,利用 CAS 尝试写入,失败则自旋保证成功。
- 如果当前位置的 hashcode == MOVED == -1,则需要进行扩容。
- 如果都不满足,则利用 synchronized 锁写入数据。
- 如果数量大于 TREEIFY_THRESHOLD 则要转换为红黑树。
-
LinkedHashMap
继承HashMap 实现Map类,
底层数据结构:
数组+双向链表,就是在hashmap的基础上维护了一个双向链表,将所有节点串起来,Map因为通过key然后hashcode计算的原因,所以位置都是乱的,put进去的顺序和拿出来的是不一样的,LinkedHashMap通过双项链表弥补了这个缺陷,是有序的。-
TreeMap
底层数据结构:红黑树
- 能够将保存的记录根据键排序
- 如果是自己写的类的话,需要实现
Comparable,重写CompareTo方法,要不然无法排序如果放置50个元素 是怎么一个过程?
嗯,hashmap的扩容的话,放置50个对象的话 如果利用的是hashmap的无参构造进行创建的hashmap的话,因为hashmap是懒加载,所以我new的时候并没有产生实际的容量,当我们第一次put的时候,才会调用resize();
但是如果我们去验证的话,没put就通过反射拿到capacity的时候,会发现他还是16,看源码的话,会发现在table长度为0的时候 capacity会返回默认的16;
这个时候的容量就是16,我们继续put,如果说通过key得到的hashcode 经过高低位异或运算 还是发生了冲突,这个时候就检查得到的桶位是不是已经生成了链表,如果生产了链表就往后续插入,这里不需要考虑红黑树的问题,
因为当size小于64的时候 是不会出现红黑树的 如果我们放置的已经到了12 这个12是通过默认加载因子和当前的容量 相乘得到的 即0,75*16 那么放置完成后会自动检查是否需要扩容 显然需要扩容 hashmap扩容的过程是创建一个原数组两倍大的数组
然后将旧数组移过去,位置要不然是原位置要不然就是加上原数组的长度 这里为什么选0.75 做加载因子太小了占空间 太大了性能不好 我觉得是基于性能和空间的一个最佳考虑,还有当链表转化为红黑树的界限为8的时候,
通过计算概率的话 0.75是性价比极高的一个选择,产生红黑树的概率极小,这个时候我们的16已经变成了32 ,继续放置,那么32也不够用,到达24的时候会扩容为64,继续放置当到达48的时候,会扩容为128,直到放置第50个元素就结束了
如果我们在一开始就设置了容量为1的话,那么在放置第一个的之前容量会是1 然后限制是0.75 所以会扩容 放完后时候会容量会是2,放第二个的时候限制是1.5,所以会扩容为4,为什么都会扩容为2的次幂,是因为想要用位运算代替取模运算,来提高性能,当为2的次幂的时候
恰好与取模相同 所以当为3的时候 限制是3 大于3就会扩容 所以4的时候 也会扩容为8 以此类推 最后扩容到50
扩容牵扯到整个数组的数据迁移 所以是很废时间的一个操作 如果我们能确切的知道放置的个数是50的话,new的时候就直接算到是128了,尽量不要让去自动扩容,特别是这种我们已经确定容量的场合,建议初始化的时候就设置好容量。Map的遍历
Map.entrySet
for(Map.Entry<String, String> entry : map.entrySet()){String mapKey = entry.getKey();String mapValue = entry.getValue();System.out.println(mapKey+":"+mapValue);}
Map.keySet & Map.ValueSet
for (String key:a.keySet()) {System.out.println(a1);}for (String value:a.values()) {System.out.println(a2);}
Itertor
Iterator<Map.Entry<String,String>> entryIteratorA=a.entrySet().iterator();while (entryIteratorA.hasNext()){System.out.println(entryIteratorA.next());}
map.get()
for (String keya:a.keySet()) {String valueA=a.get(keya);System.out.println(keya+"--"+valueA);}
Map的排序
Map如果需要根据key来排序,那直接用TreeMap就可以,自动排序的,如果需要对values进行排序的话,就需要借用list,然后通过Collection的sort方法,借助比较器comparator。List
List是继承于Collection的一个接口,是有序的,这个有序指的是放进去的顺序,每一个元素都有一个从0开始的索引,且可以为null
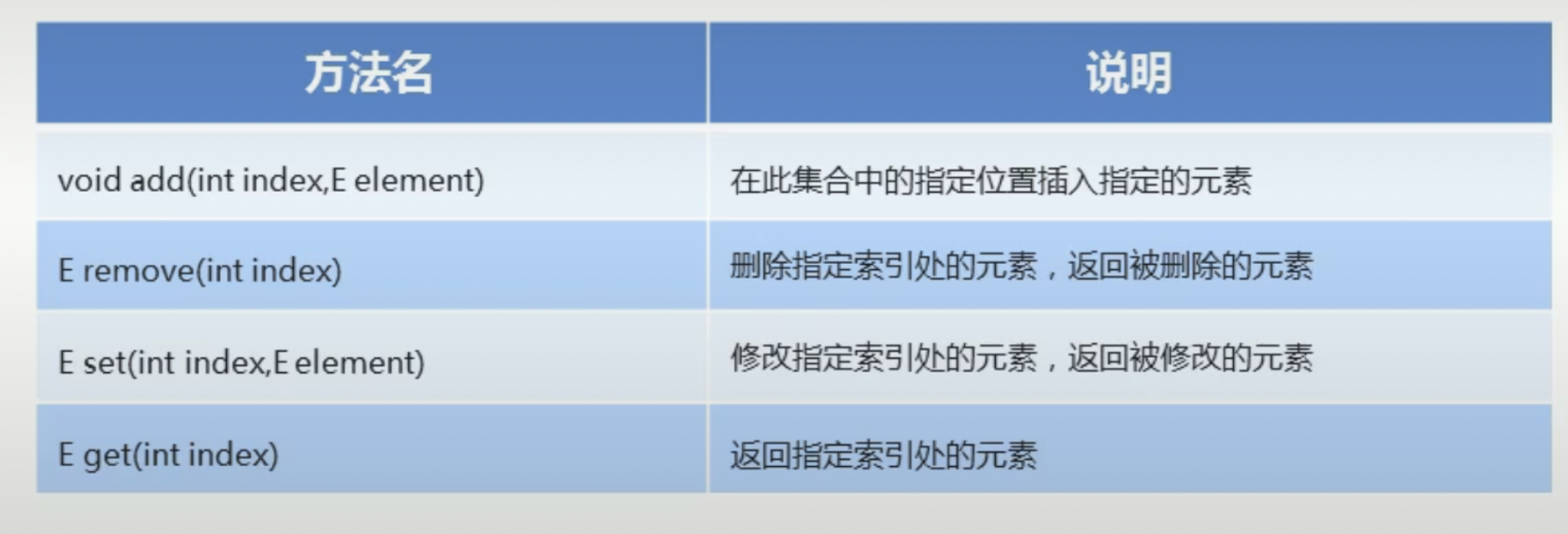
- 特有方法
LinkedList
底层结构是双向链表
LinkedList是实现List接口的, 底层采用 双向链表
还实现了Deque接口,双向队列 ,栈和List集合使用
特点:随机访问效率低,增删修改指定对象容易,其他元素不受影响
场景:适合频繁增删的地方,不适合经常随机访问
先进先出,
LinkedList的随机访问集合元素时性能较差,因为需要在双向列表中找到要index的位置,再返回
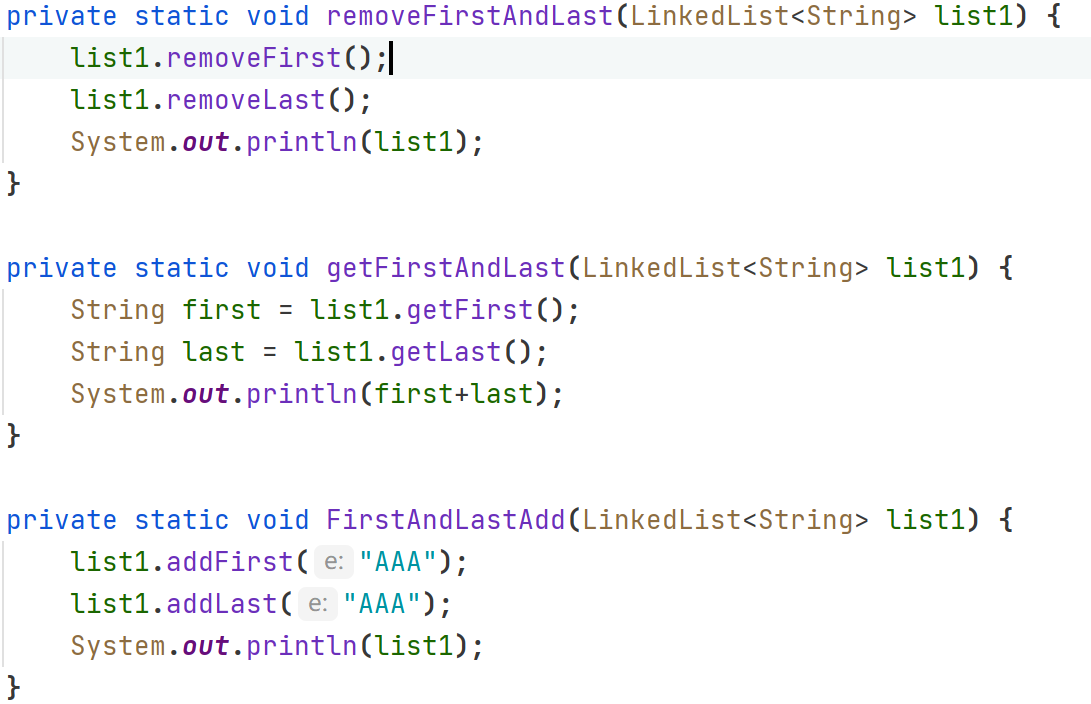
特有方法
ArrayList

和Vector比较,一般是单线程下使用,日常使用比较多,与数组相比可以进行自动扩容,数组的容量是固定的**ArrayList是实现List接口的,底层采用 数组实现。
**
ArrayList 实现了Cloneable接口,即覆盖了函数clone(),能被克隆。
ArrayList 实现java.io.Serializable接口,这意味着ArrayList支持序列化,能通过序列化去传输。
Array是基于索引(index)的数据结构,查找快,不适合大量增删的场景,因为要前移后移。
现在计算机cpu支持块操作,增删也不会慢于linkedList了Arraylist的初始size其实是0,存储的数组在底层的名字为elementData

添加元素默认生成长度为10的,如果size等于了底层elementdata数组的长度,就会调用grow方法扩容,每次扩大后为旧容量的1.5倍。- **get /set
Vector向量
和ArrayList是兄弟,多线程下保证线程安全,已经很少使用
ArrayList是实现List接口的,底层采用数组实现。
ArrayList 实现java.io.Serializable接口,这意味着ArrayList支持序列化,能通过序列化去传输。
ArrayList 实现了Cloneable接口,即覆盖了函数clone(),能被克隆。
为什么不再使用vector
因为vector是线程安全的,所以效率低,这容易理解,类似StringBuffer,同时只能在尾部进行插入和删除操作,更加造成效率低;
- Vector空间满了之后,扩容是一倍,而ArrayList仅仅是一半;
- Vector分配内存的时候需要连续的存储空间,如果数据太多,容易分配内存失败;
**每个操作方法都加的有synchronized关键字
-
Stack
Vector的子类,不常用,常用的被LinkedList取代
添加

studentlist.add(0,”小张”)
0为索引位置,小张为替换后的字符串内容System.out.println(ArrayList)
删除
实质是在比较.equals() —— ==判断字符串删除

-
集合的遍历
for
普通for循环可以遍历 也可以删除 但是有一个问题就是删除时 如果有重复的只会删一个然后就退出foreach
可以遍历 但不能删除 添加 会报错 因为没有进行modcount同步迭代器
迭代器的效率低,有锁,多线程时可以保证安全,删除添加也正常 迭代器 集合的遍历
在迭代中,foreach中就是采用的迭代器的删除,list的删除元素,添加元素可能会ConcurrentModificationException报错
解决办法:使用Iterator的remove方法,其修改了modCount之后,又同步了Iterator
遍历

删除

listIterator比itertor安全性更高(添加时同步modcount)


Set
Set和List一样都是继承于Collection接口,相比较 list,set 是一个不允许有重复元素的集合,同理set 也有自己的实现类,主 要有两个实现类HashSet 和TreeSet,他们两个实际上都是借助HashMap和TreeMap进行实现的,Set集合就像一个箱子,可以把数据扔进去,但是是无序的(这个无序指的是添加进去和遍历拿出来的不是一个顺序,并不是真正的每次都乱的,实际上是根据算法算出位置放的,比如HashSet就是根据HashCode计算然后得到位置,所以其实Set的位置也是固定的)
特点
- 不能保证元素的顺序,元素是无序的
- HashSet是不同步的,需要外部保持线程之间的同步问题,Collections.synchronizedSet(new XXSet());
- 集合元素值允许为null
HashSet
HashSet底层就是采用HashMap实现的,相当于HashMap的键,然后值都是一样的。TreeSet
TreeSet是有序的Set集合,因此支持add、remove、get等方法,底层是TreeMap.
可以为空
自定义对象如果作为数据,需要实现Comparable接口,重写ComparaTo方法。LinkedHashSet
LinkedHashSet继承自HashSet,源码更少、更简单,唯一的区别是LinkedHashSet内部使用的是LinkHashMap。这样做的意义或者好处就是LinkedHashSet中的元素顺序是可以保证的,也就是说遍历序和插入序是一致的。
Set的遍历
迭代器
Iterator a=set.iterator();while (a.hasNext()){System.out.println(a.next());}
foreach
Set<String> set=new HashSet<>();set.add("1sadas");set.add("2sadas");set.add("3sadasd");for (String a:set) {System.out.println(a);}

若有收获,就点个赞吧
0 人点赞
