71.数组:
相同类型,连续存储空间,数组下标从0开始
优点:数组连续空间,遍历快。数组访问采用数组下标随机访问。
缺点:数组长度固定。
时间复杂度:假如长度为n,访问特定位置O(1),插入删除元素,最坏情况下O(n)。
2.链表:
非连续,若干个节点组成。
优点:链表不用预估程度,使用不连续空间,充分利用内存空间。
缺点:空间占比大,每个节点会包含前后指向,占用空间相对较大。遍历查找指定元素慢。
时间复杂度:插入删除元素O(1),查找元素最坏复杂度O(n)。
2.1常见链表:
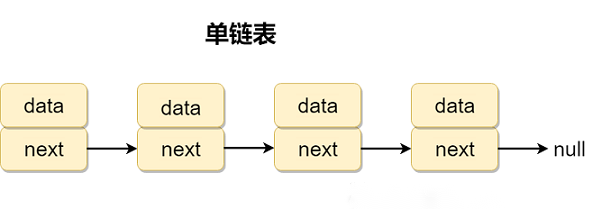
2.2单向链表
2.2.1单向链表只有数据和下一个节点指向,只有一个方向。
private static class Node{int data;Node next;}
2.2.2单向链表的第一个节点为头节点,最后一个节点为尾节点,尾节点最后指向null。
2.3双向链表
2.3.1双向链表多一个前节点指向(prev)。
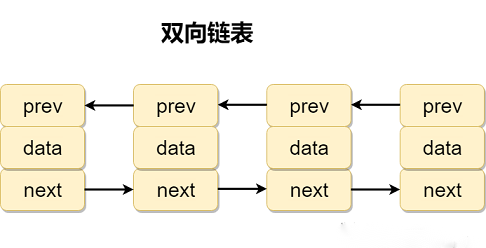
2.3.2双向链表按照指定下标查找。
- 如果指定下标小于size>>1长度一半,则从头部节点开始顺序遍历查找
如果指定下标大于size>>1长度一半,则从尾部节点开始逆序遍历查找
private void linkFirst(E e) {final Node<E> f = first;final Node<E> newNode = new Node<>(null, e, f);first = newNode;if (f == null)last = newNode;elsef.prev = newNode;}
2.3.3双向链表插入元素
添加新节点至表头
private void linkFirst(E e) {final Node<E> f = first; // 获取头节点final Node<E> newNode = new Node<>(null, e, f); // 获取当前节点first = newNode; //新节点指向当前节点if (f == null) //判断新节点是否为空last = newNode; // 为空代表当前只有一个节点,last也只指向新节点elsef.prev = newNode; // 不为空头节点的prev指向新节点}
添加新节点至表尾
void linkLast(E e) {final Node<E> l = last;final Node<E> newNode = new Node<>(l, e, null);last = newNode;if (l == null)first = newNode;elsel.next = newNode;}
添加新节点至表中
void linkBefore(E e,int index) {Node<E> succ = node(index);final Node<E> pred = succ.prev;final Node<E> newNode = new Node<>(pred, e, succ);succ.prev = newNode;if (pred == null)first = newNode;elsepred.next = newNode;}
删除头节点
private void removeFirst() {final Node<E> f = first;final Node<E> next = f.next;f.item = null;f.next = null; // help GCfirst = next;if (next == null)last = null;elsenext.prev = null;}
删除尾节点
private void removeLast() {final Node<E> l = last; // 获取当前的尾节点lastfinal Node<E> prev = l.prev; // 获取当前的尾节点的prev节点l.item = null; // 把尾节点的数据设置为nulll.prev = null; // help GClast = prev; //尾节点给尾节点的prev节点if (prev == null) // 判断prev是否为空,是否为一个first = null; // 是,把头结点设置为空elseprev.next = null; // 否则前节点的下一个节点设置为null}
3. 链表 vs 数组
|
| 查找 | 修改 | 插入 | 删除 | | —- | —- | —- | —- | —- | | 数组 | O(1) | O(1) | O(n) | O(n) | | 链表 | O(n) | O(1) | O(1) | O(1) |数组擅长通过下标快速定位元素,而且物理空间连续,遍历速度快,适合读多写少的应用场景;
- 链表擅长插入和删除元素,适合读少写多的应用场景;
数组的长度固定,如果声明的数组过小,需要另外申请更大的内存空间+拷贝原数组进行扩容。而链表支持动态扩容。
3.栈
只允许在有序的线性数据集合的一端(称为栈顶 top)进行加入数据(push)和移除数据(pop)先进后出
假设堆栈中有n个元素,常见操作时间复杂度:
- 访问指定位置的元素,时间复杂度为O(n)
-
3.1栈的应用场景
a.浏览器的前进与后退(只需要两个栈就行进行,看的页面进站stack1,回退的时候出战到另外一个栈stack2)
b.反转字符串(每个字符先全部入栈,然后全部出栈)public static void main(String[] args) {String str = "shi jie zhen mei hao";Stack<Character> stack = new Stack<>();char[] chars = str.toCharArray();for (char c : chars) {stack.push(c);}StringBuilder result = new StringBuilder();for (int i = 0, len = stack.size(); i < len; i++) {result.append(stack.pop());}System.out.println(result.toString());}
4.队列
先进先出,线性结构,分队头队尾。
常见操作的时间复杂度:
- 假设队列中有n个元素。
- 访问指定元素的时间复杂度是O(n):最坏情况下,遍历整个队列
- 插入删除元素的时间复杂度是O(1):只需要操作队头或队尾元素
顺序队列会出现”假溢出”的问题,在进行不停的进栈出战,明明还存在空间却无法加入,甚至出现越界的情况。
循环队列:用数组实现的 队列可以采用循环队列的方式来维持队列容量的恒定。
4.1循环队列代码实现:
((队尾下标+1)%数组长度 = 队头下标判满,满的情况下最大容量为数组长度小一)
public class CircularQueueDemo {// 基于数组实现private int[] array;// 队头private int front;// 队尾private int rear;public CircularQueueDemo(int capacity) {this.array = new int[capacity];}/*** 入队** @param element 入队的元素*/public void enQueue(int element) throws Exception {if ((rear + 1) % array.length == front) {throw new Exception(" 队列已满!");}array[rear] = element;rear = (rear + 1) % array.length;}/*** 出队**/public int deQueue() throws Exception {if (rear == front) {throw new Exception(" 队列已空!");}int deQueueElement = array[front];front = (front + 1) % array.length;return deQueueElement;}@Overridepublic String toString() {StringBuilder sb = new StringBuilder();for (int i = front; i != rear; i = (i + 1) % array.length) {sb.append(array[i] + "\t");}return sb.toString();}/*** 输出队列*/public static void main(String[] args) throws Exception {CircularQueueDemo myQueue = new CircularQueueDemo(6);myQueue.enQueue(3);myQueue.enQueue(5);myQueue.enQueue(6);myQueue.enQueue(8);myQueue.enQueue(1);myQueue.deQueue();myQueue.deQueue();myQueue.deQueue();myQueue.enQueue(2);myQueue.enQueue(4);myQueue.enQueue(9);// myQueue.enQueue(9);System.out.println(myQueue);}}
4.2常见应用场景
a.阻塞队列(当队列满的时候,禁止入队操作;当队列空的时候禁止出队操作)
b.线程池中的请求/任务队列(分为有界无界队列;无界队列长度没有限制,只有资源耗尽才结束。有界队列,队列满时直接进行拒绝策略)例如:FixedThreadPool 使用无界队列 LinkedBlockingQueue
c.播放器播放列表
5.树
5.1树(tree)
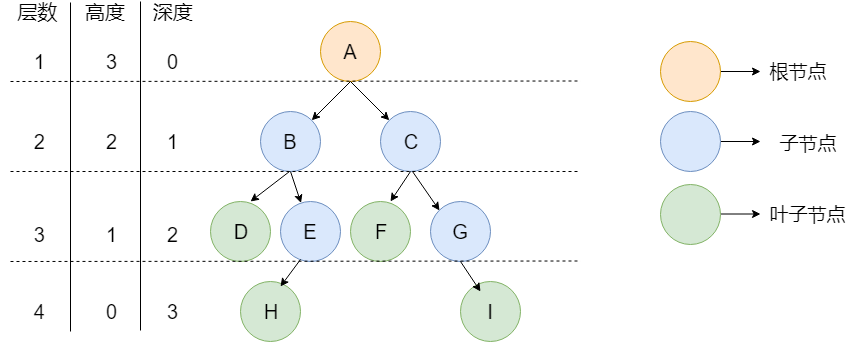
n(n≥0)个节点的有限集。当n=0时,称为空树。
- 节点高度 :该节点到叶子节点的最长路径所包含的边数
- 树的高度 :根节点的高度,也被称为树的深度
- 节点深度 :根节点到该节点的路径所包含的边数
- 节点层数 :节点的深度+1
5.2二叉树:
- 二叉树(Binary tree)是一种特殊的树
- 每个节点最多只有两个子节点,左孩子,右孩子
满二叉树:所有非叶子节点都存在左右子节点
平衡二叉树:除过最后一层节点为满二叉树
完全二叉树:
- 可以是一棵空树
- 如果不是空树,它的左右两个子树的高度差的绝对值不超过 1,并且左右两个子树都是一棵平衡二叉树。
二叉树存储:
1.链式存储:包含左节点指针和右节点指针,不需要连续空间。
2.顺序存储:用数组进行存储,存储每个节点的数据。
二叉树遍历:
1.前序遍历:根左右
2.中序遍历:左根右
3.后续遍历:左右根
6.二叉排序树&AVL
6.1 二叉排序树
特点:二叉排序树左孩子小于等于根节点,右孩子大于等于跟节点。
时间复杂度分析:二叉排序树的插入和查找、删除操作的最坏时间复杂度为O(h) ,其中 h 是二叉排序树的高度。最极端的情况下,我们可能必须从根结点访问到最深的叶子结点,斜树的高度可能变成 n,插入和删除操作的时间复杂度将可能变为O(n) 。
6.1 查询
二分查找是在一个有序数组上进行的,就像前面我们通过对二叉排序树进行中序遍历得到的结果一样,初始时,我们将整个有序数组当做二分查找的搜索空间,然后计算搜索空间的中间元素,并与查找元素进行比较;然后将整个搜索空间缩减一半;重复上面的步骤,直到找到待查找元素或者返回查找失败的信息。
6.2 插入
对于任意一个待插入的元素 x 都是插入在二叉排序树的叶子结点,问题的关键就是确定插入的位置,原理当然和上面的查找操作一样,从根结点开始进行判断,直到到达叶子结点,则将待插入的元素作为一个叶子结点插入即可。
6.3 删除
一、被删除的结点D是叶子结点:直接从二叉排序树当中移除即可,也不会影响树的结构
二、被删除的结点D仅有一个孩子:如果只有左孩子,没有右孩子,那么只需要把要删除结点的左孩子链接到要删除结点的父亲节点,然后删除D结点就好了;如果只有右孩子,没有左孩子,那么只要将要删除结点D的右孩子重接到要删除结点D的父亲结点。
三、被删除结点的左右孩子都存在
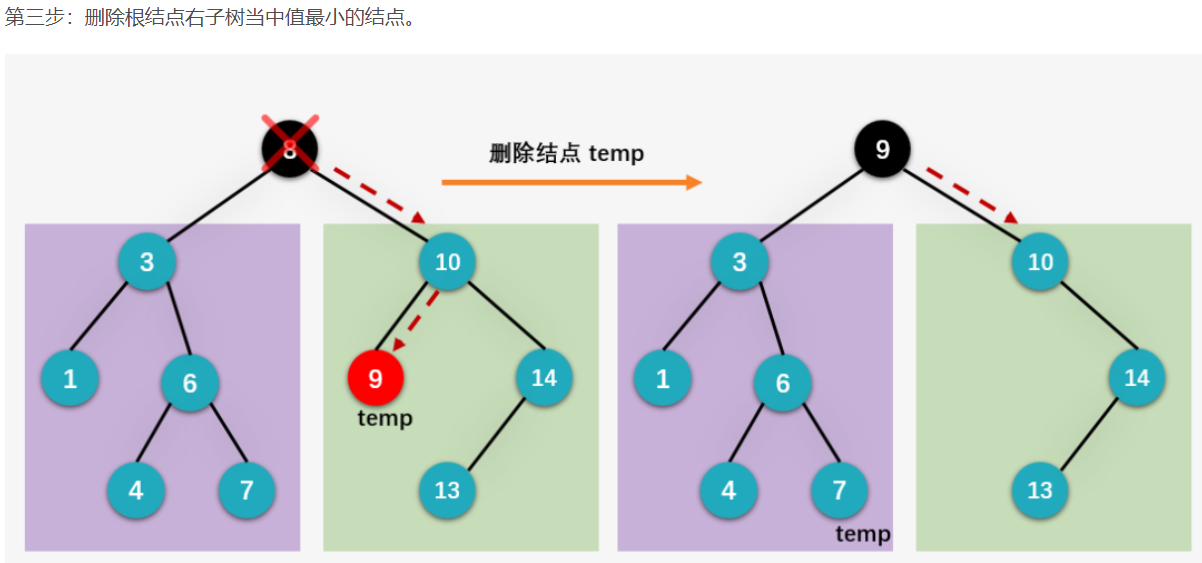
我们下面就来看删除左右孩子都存在的结点是如何实现的,依旧以删除根结点 8 为例。首先我们一起看用根结点的左子树当中值最大的结点 7 来替换根结点的情况。
第一步:获得待删除结点 8 的左子树当中值最大的结点 7 ,并保存在临时指针变量 temp 当中(这一步可以通过从删除结点的左孩子 3 开始,一个劲地访问右子结点,直到叶子结点为止获得):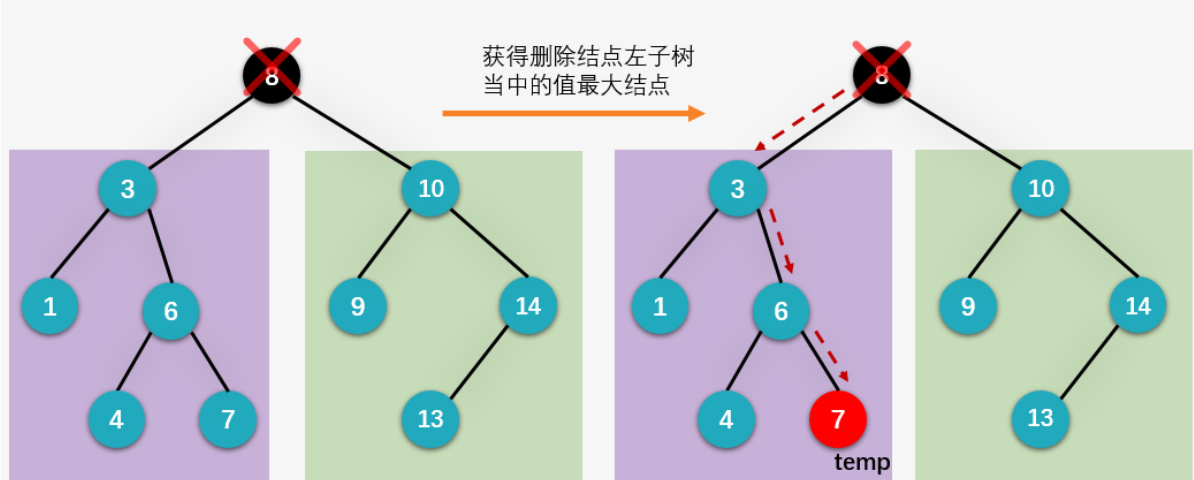
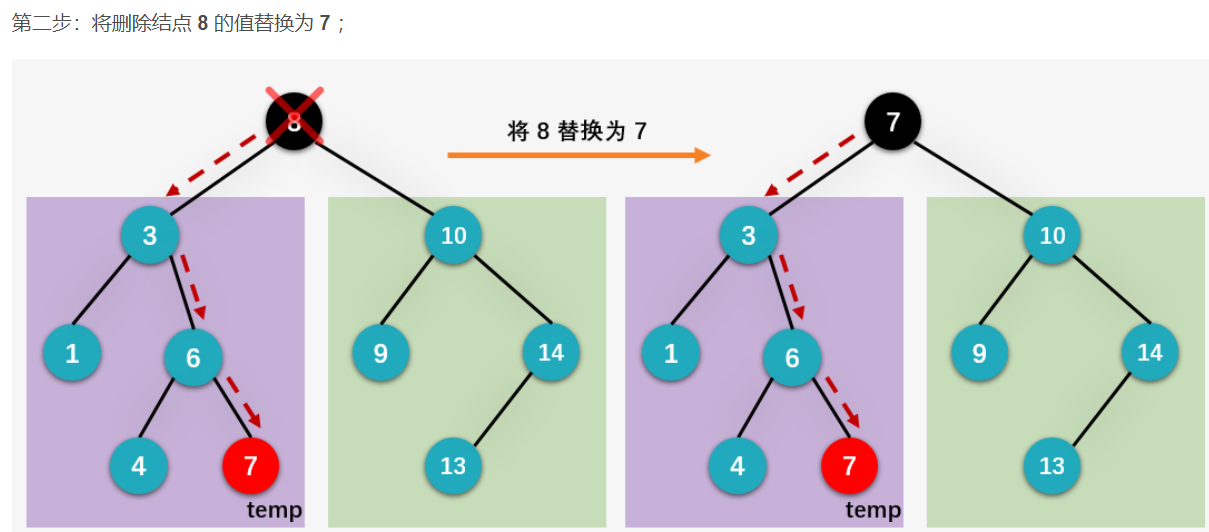
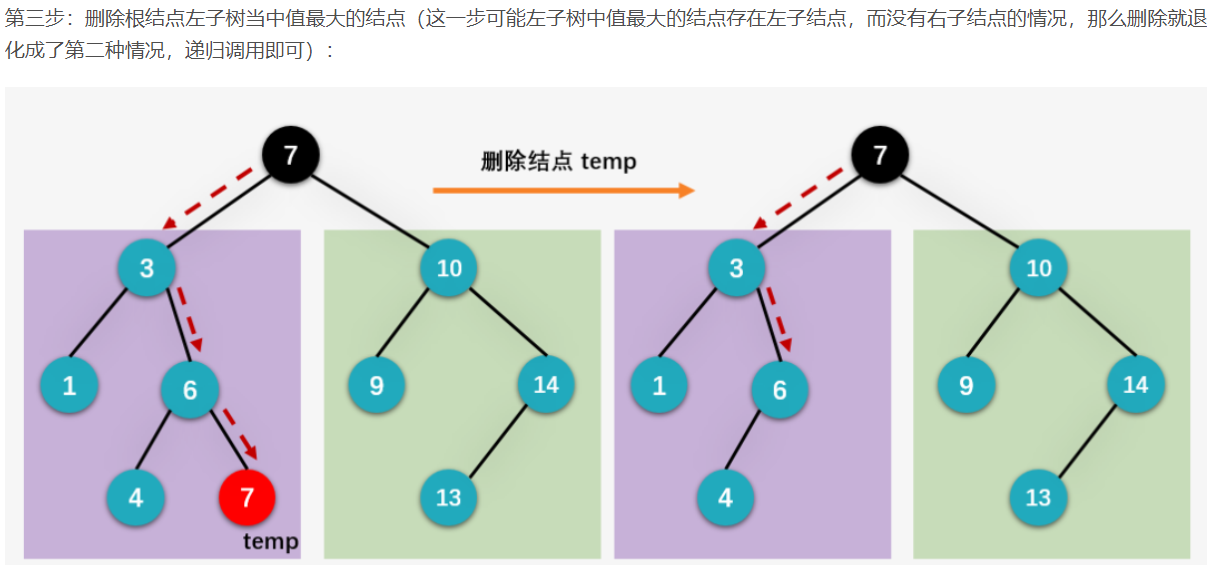
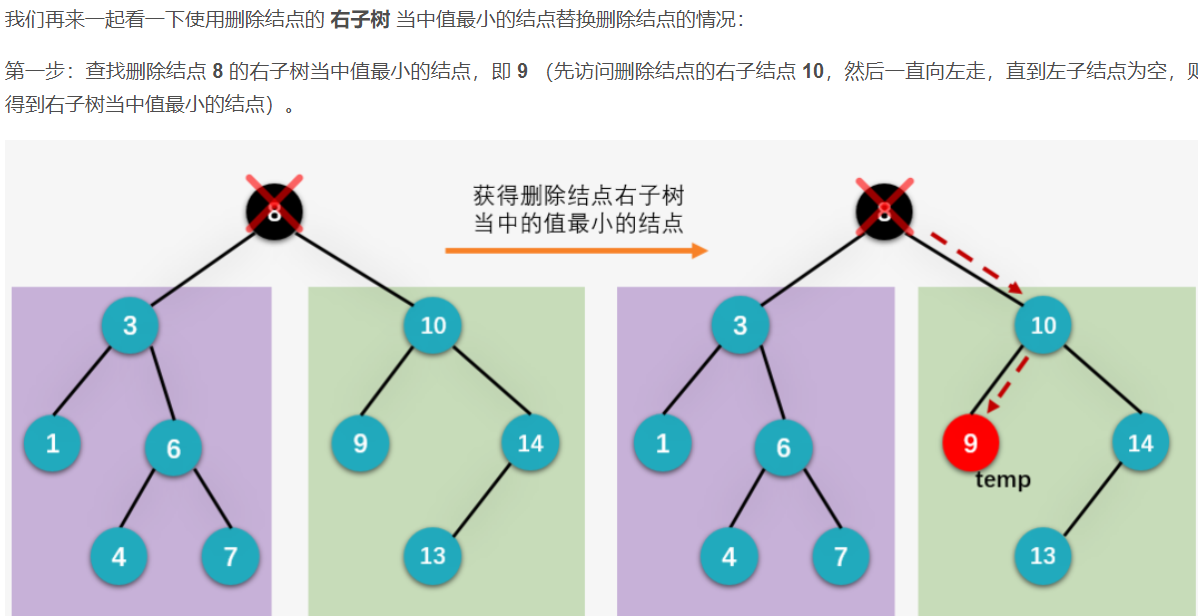
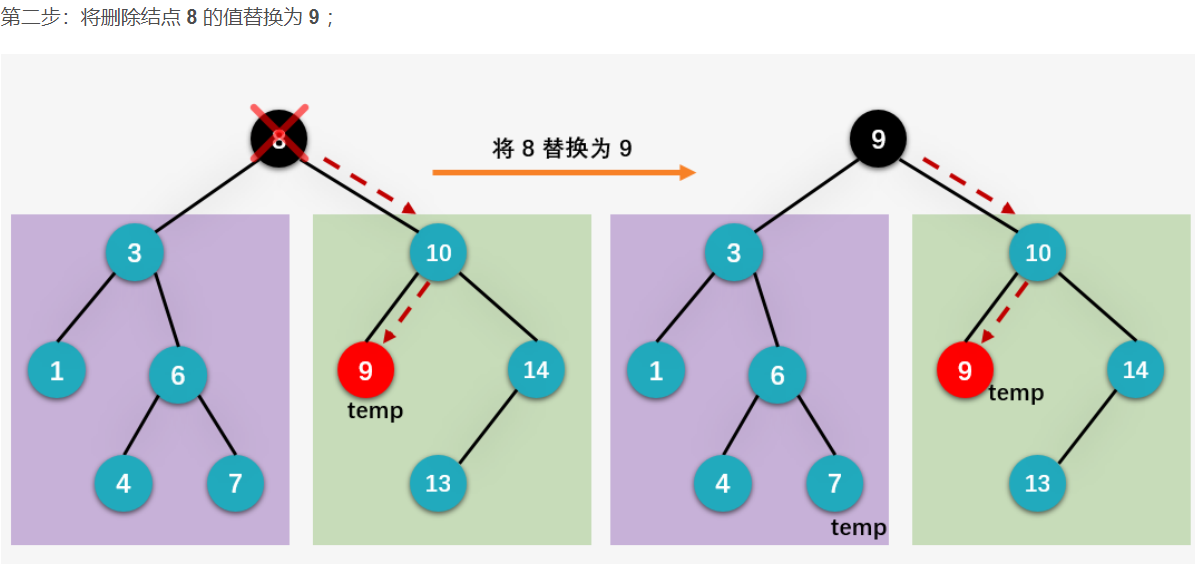
6.2 平衡二叉树
平衡二叉树:保证了树的平衡,左右两个子树的高度差绝对值不超过1,并且左右两个子树都是平衡二叉树。
时间复杂度:
6.2.1 添加节点
添加节点可能造成二叉树失去平衡,所以在每次插入过程后要进行平衡的维护操作(旋转)
旋转的目的就是为了降低树的高度,哪边的树高,那边的数就向上旋转。
插入节点的四种情况:
向左子树(L)的左孩子(L)中插入新节点后导致不平衡,这种情况下需要右旋操作。
右旋: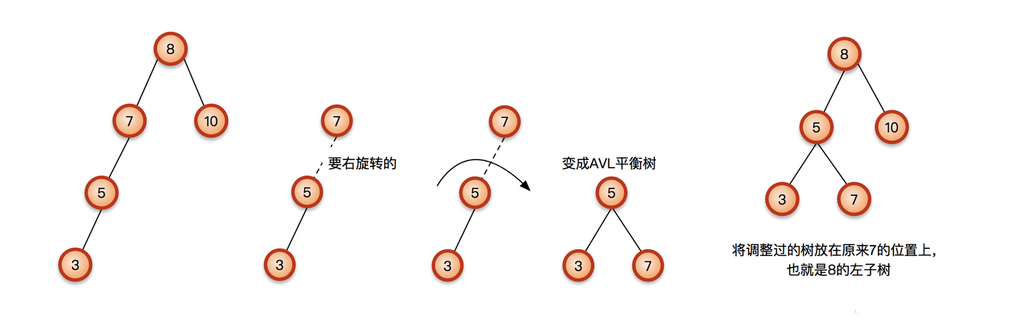
向右子树(R)的右孩子(R)中插入新节点后导致不平衡,这种情况下需要左旋操作。
左旋: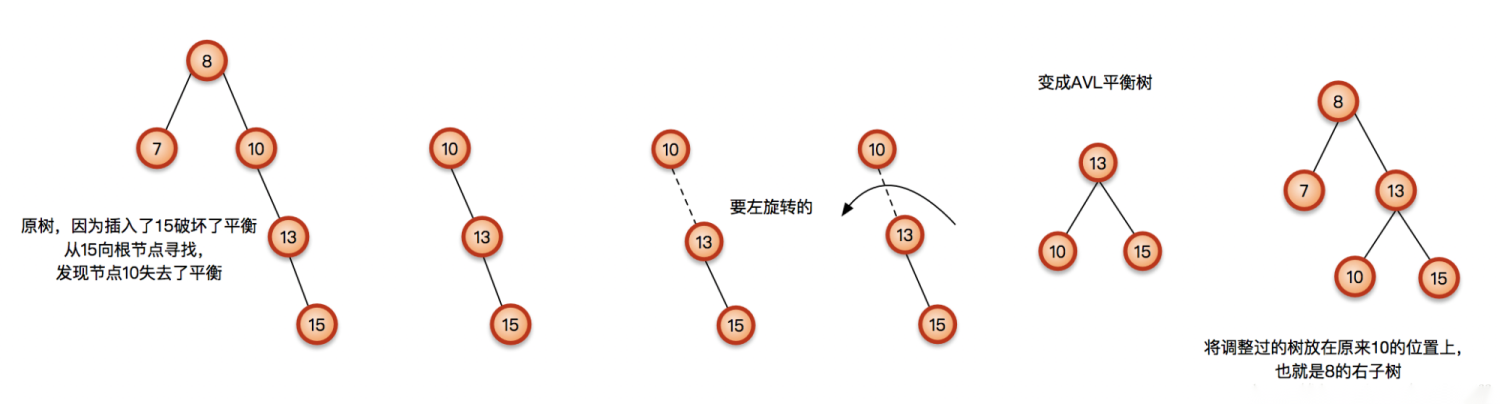
向左子树(L)的右孩子(R)中插入新节点后导致不平衡,这种情况下需要LR旋转操作。
先左旋再右旋: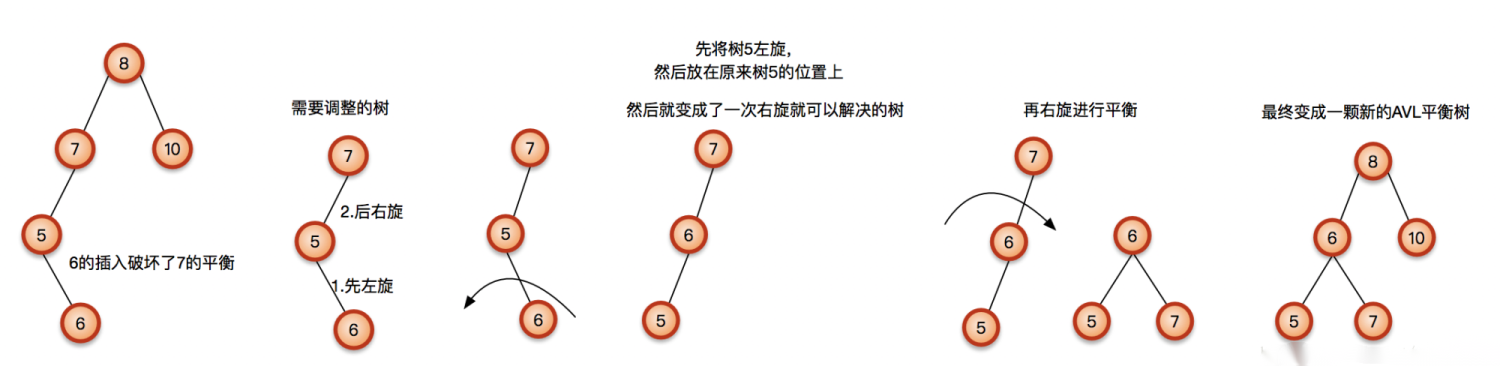
向右子树(R)的左孩子(L)中插入新节点后导致不平衡,这种情况下需要RL旋转操作。
先右旋再左旋: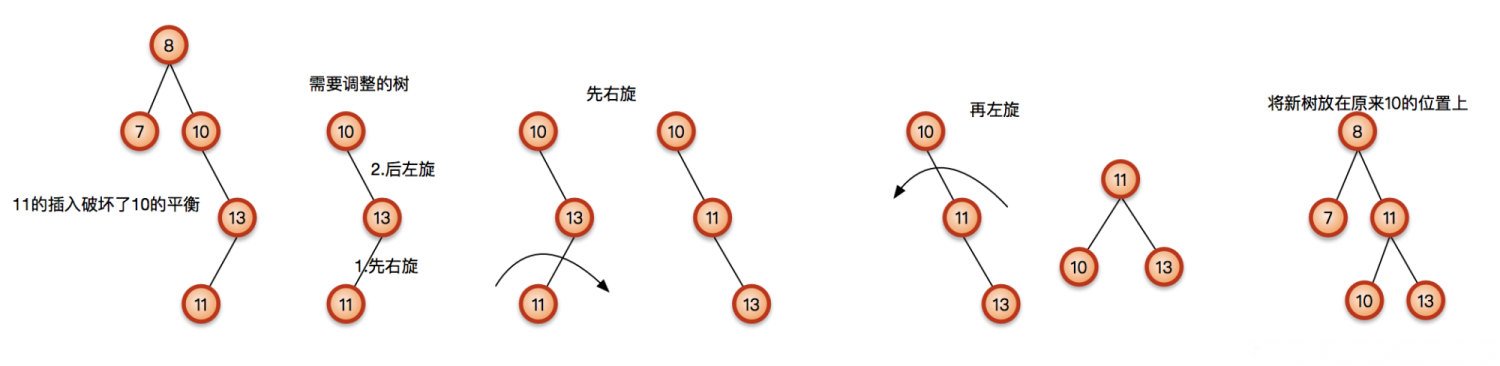
6.2.2 删除节点
7.B树和B+树
7.1 B树:(多路平衡查找树)
优点:每次比较操作都会去掉当前数据量一半的数据,因此查找的时间复杂度为O(log2n)。
缺点:每个节点只能存放一个数据,会导致树的高度很高。
B树的定义与性质:
在B树中,分为两种节点:
- 内部节点(internal node):存储了数据以及指向其子节点的指针。
- 叶子节点(leaf node):与内部节点不同的是,叶子节点只存储数据,并没有子节点。
为了维持B树的平衡性,需要满足以下的属性:
- 在每个节点上的键值,以递增顺序排列;
- 一个键值的左边子树,其键值大于该键值左边子树的所有键值;
- 一个键值的右边子树,其键值小于或等于该键值右边子树的所有键值;
- 在内部节点中,指向子节点的指针数量总是存储数据节点的数量+1;
- 所有叶子节点的高度一致;
- 无论是内部节点还是叶子节点,其存储的键值数量在[t-1,2t-1]之间,如果数量不满足此条件,需要做重平衡操作。如果少于t-1,需要借用或合并数据;反之,如果数据量大于2t-1,则需要分裂成两个节点;(t指的是度数)
插入数据:
插入数据时,找到做适合的节点,如果该节点的数据量已满,进行分裂操作,然后插入数据。否则插入数据就行。
删除数据:
1.数据在叶子节点,直接删除。
2.数据存在于内部节点,这种情况下,如果该内部节点的数据数量不大于t,则需要做重新平衡操作,这里区分成两种情况:
- 如果左右子树节点中有一个数据量至少有t,则可以从相邻子树中借用数据。
例如:
从[3,7,13]的节点删除13:满足借用条件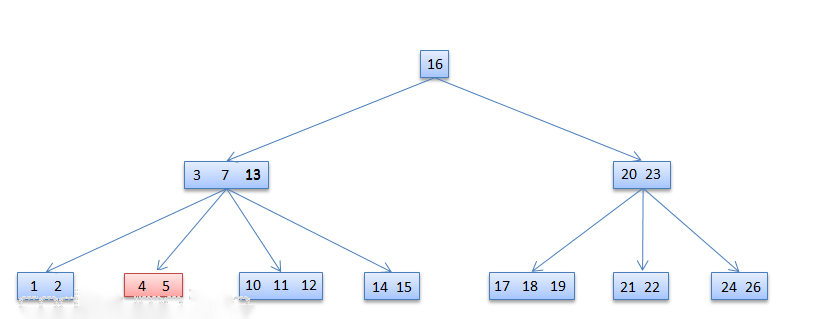
删除后如下图所示: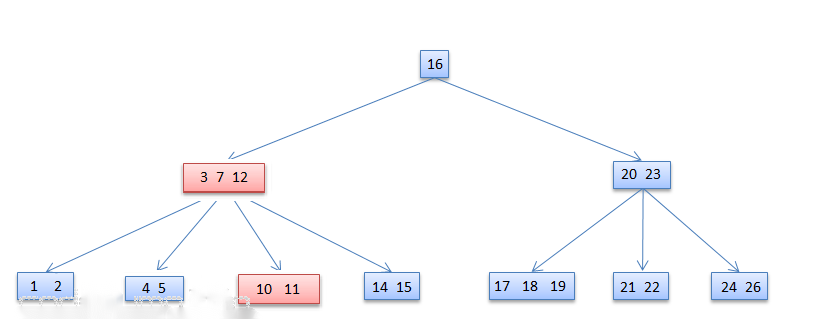
- 如果左右两边相邻的子树节点数据也都不够,则进行合并操作。
在从节点[3,7,12]中删除键值7,此时该节点的左右两边的子树[4,5]和[10,11]都不满足借用条件: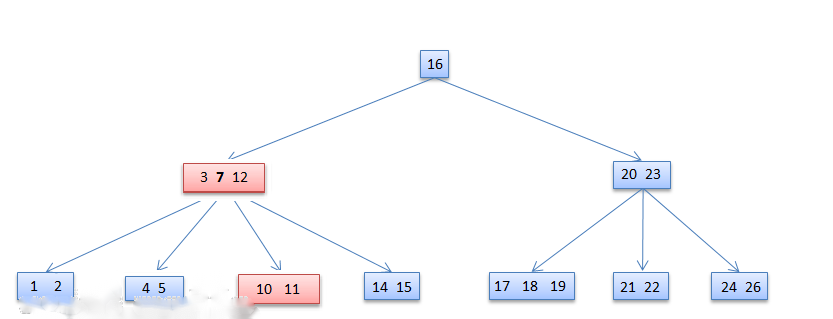
删除后如下图所示: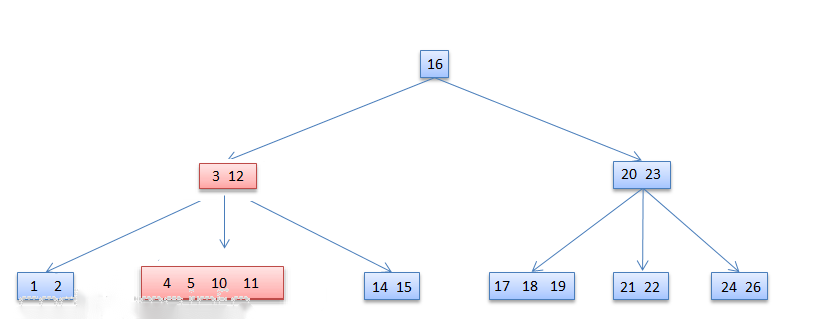
7.2 B+树
B+树是B树的一个升级版,相对于B树来说B+树更充分的利用了节点的空间,让查询速度更加稳定
基本定义
- B+树中,内部节点上仅存放数据的索引,数据只存储在叶子节点上。
- B+树中,在内部节点中的键值,被称为“索引”,由于是数据索引,因此可能出现同一个键值,既出现在内部节点,也出现在叶子节点中的情况。
- 内部节点的“索引”,应该满足以下条件:
- 大于左边子树的最大键值;
- 小于等于右边子树的最小键值;
- 内部节点的“索引”,应该满足以下条件:
- B+树中,为了方便范围查询,叶子节点之间还用指针串联起来。
B+树的特征
- 每个元素不保存数据,只用来索引,所有数据都保存在叶子节点;
- 所有的叶子结点中包含了全部元素的信息,及指向含这些元素记录的指针,且叶子结点本身依关键字的大小自小而大顺序链接;
所有的中间节点元素都同时存在于子节点,在子节点元素中是最大(或最小)元素;
B+树的优势
单一节点存储更多的元素,使得查询的IO次数更少;
- 所有查询都要查找到叶子节点,查询性能稳定;
- 所有叶子节点形成有序链表,便于范围查询。
数据库索引
数据库索引采用了这样的结构,B+树对比B树有以下优点:
● 索引节点上由于只有索引而没有数据,所以索引节点上能存储比B树更多的索引,这样树的高度就会更矮。
● 数据库索引的内容,这种面向磁盘的数据结构,树的高度越矮,磁盘寻道的次数就会越少。
● 因为数据都集中在叶子节点了,而所有叶子节点的高度相同,那么可以在叶子节点中增加前后指针,指向同一个父节点的相邻兄弟节点,给范围查询提供遍历。
例如这样的SQL语句:select * from tbl where t > 10,如果使用B+树存储数据的话,可以首先定位到数据为10的节点,再沿着它的next指针一路找到所有在该叶子节点右边的叶子节点数据返回。

若有收获,就点个赞吧
0 人点赞
