- 1、面向对象的认知
- 2、面向对象的特征以及理解
- 3、this和super
- 4、抽象类和接口(1.7和1.8)的区别
- 5、各种关键字:static final instanceof
- 6、装箱和拆箱
- 7、排序算法(冒泡、快排)
- ">

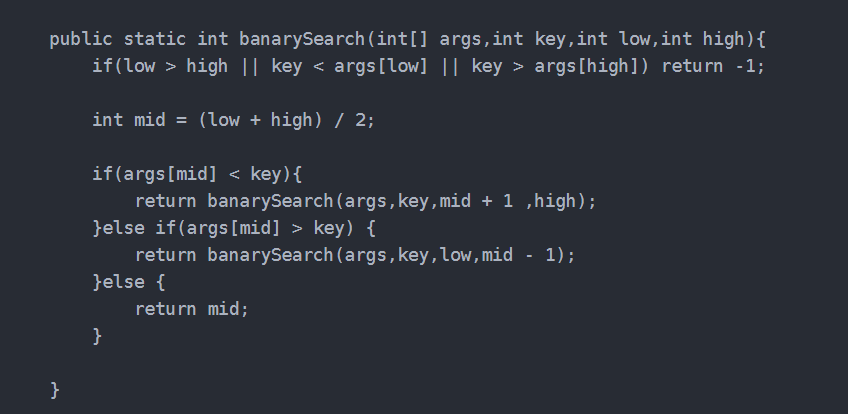
- 8、查找算法(二分)
- ">
- 9、数组元素去重算法
- 10、ArrayList底层,初始容量,扩容
- 11、HashMap底层结构1.7和1.8
- 12、HashMap的头插法和尾插法
- 13、HashMap的put源码过程
- ">
- 14、ConCurrentHashMap底层1.7和1.8 安全(JUC)
- 15、常用的数据结构(数组、栈、队列、红黑二叉树)
- 16、执行顺序
- 17、Lambda表达式
- 18、函数式接口之Stream
- 19、函数式接口之Function
- 20、函数式接口之Predicate
- 21、函数式接口之Consumer
- 22、函数式接口之Supplier
1、面向对象的认知
2、面向对象的特征以及理解
1.封装:
就是类的私有化。将代码及处理数据绑定在一起的一种编程机制,该机制保证程序和数据不受外部干扰。
2.继承:
就是保留父类的属性,开扩新的东西。通过子类可以实现继承,子类继承父类的所有状态和行为,同时添加自身的状态和行为。
3.多态性:
多态性是指允许不同类的对象对同一消息作出响应。即同一消息可以根据发送对象的不同而采用多种不同的行为方式 。重载为编译时多态,重写是运行时多态。
3、this和super
this表示本类对象的引用,super为父类引用。
this:(在程序中易产⽣⼆义性之处,应使⽤this来指明当前对象;如果函数的形参与类中的成员数据同名,这时需⽤this来指明成员变量名)
this是⼀个指向本对象的指针, 然⽽super是⼀个Java关键字
4、抽象类和接口(1.7和1.8)的区别
抽象类可以有默认的方法实现、成员变量、可以有构造器、可以使用public、protected和default修饰,不能够实例化。
- 接口是完全抽象的不存在方法的实现,不能有构造器,默认修饰符为public不能修改。
- 抽象类的子类使用extend继承抽象类,如果子类不是抽象的话必须提供抽象类的所有声明方法的实现,接口使用implements实现接口,必须提供接口中所有方法的实现。
- 在 jdk 7 或更早版本中,接口里面只能有常量变量和抽象方法。这些接口方法必须由选择实现接口的类实现。
- jdk8 的时候接口可以有默认方法和静态方法功能。
5、各种关键字:static final instanceof
static修饰符用来修饰类方法和类变量,静态变量:声明独立于对象的变量,无论一个类实例多少对象,他的静态变量只有一份拷贝,也被成为类变量,局部变量不能被声明为static变量。静态方法:声明独立于对象的静态方法,不能直接使用类的非静态变量。对于类变量和类方法使用 类名.方法/变量访问。
final用来修饰类、方法、变量。final修饰的类不能被继承、修饰的方法不能被继承类重写、修饰的变量为不可修改。被 final 修饰的实例变量必须显式指定初始值。
instanceof用来在运行时指出对象是否是特定类的一个实例。instanceof通过返回一个布尔值来指出,这个对象是否是这个特定类或者是它的子类的一个实例。6、装箱和拆箱
装箱就是自动将基本数据类型转换为包装器类型(int—>Integer);调用方法:Integer的
valueOf(int) 方法
拆箱就是自动将包装器类型转换为基本数据类型(Integer—>int)。调用方法:Integer的
intValue方法7、排序算法(冒泡、快排)
算法:
快速排序的原理就是分治法;即先比大小,再分区,然后分而治之;public void bubbleSort(int[] arr) {int temp;//定义一个临时变量for(int i=0;i<arr.length-1;i++){//冒泡趟数for(int j=0;j<arr.length-i-1;j++){//如果顺序不对,则交换两个元素if(arr[j+1]<arr[j]){temp = arr[j];arr[j] = arr[j+1];arr[j+1] = temp;}}}}
从数组中取出一个数,作为基准;然后分区,选择出比这个数大的数放到它的右边,比这个数小的数放到他的左边;然后分别对左右分区进行分区,直到每个分区只剩一个数;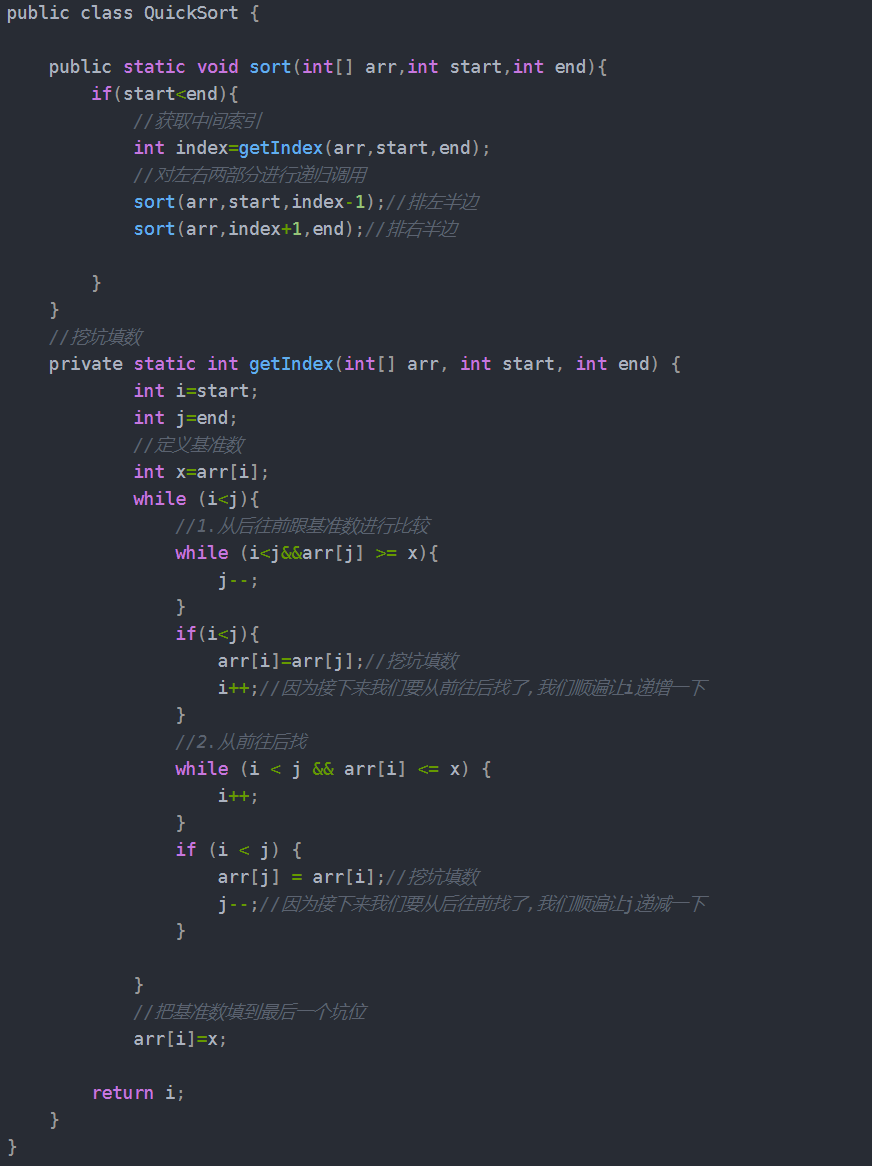
8、查找算法(二分)
9、数组元素去重算法
10、ArrayList底层,初始容量,扩容
初始容量为0(先创建一个长度为0的数组,当添加第一个元素的时候,会通过 grow 方法初始化容量为10),底层是一个object数组。当数组的长度不能容下所添加的内容时候,数组会扩容至原大小的1.5倍。
11、HashMap底层结构1.7和1.8
数组+链表+红黑树,在jdk1.8链表长度大于8使用红黑树,红黑树节点小于6转换为链表。
12、HashMap的头插法和尾插法
当HashMap要在链表里插入新的Entry时,在Java 8之前是将Entry插入到链表头部,在Java 8开始是插入链表尾部(Java 8用Node对象替代了Entry对象)。<br />Java 7插入链表头部,是考虑到新插入的数据,更可能作为热点数据被使用,放在头部可以减少查找时间。<br />Java 8改为插入链表尾部,原因就是防止环化。<br /> 因为resize的赋值方式,也就是使用了单链表的头插入方式,同一位置上新元素总会被放在链表的头部位置,在旧数组中同一条Entry链上的元素,通过重新计算索引位置后,有可能被放到了新数组的不同位置上。
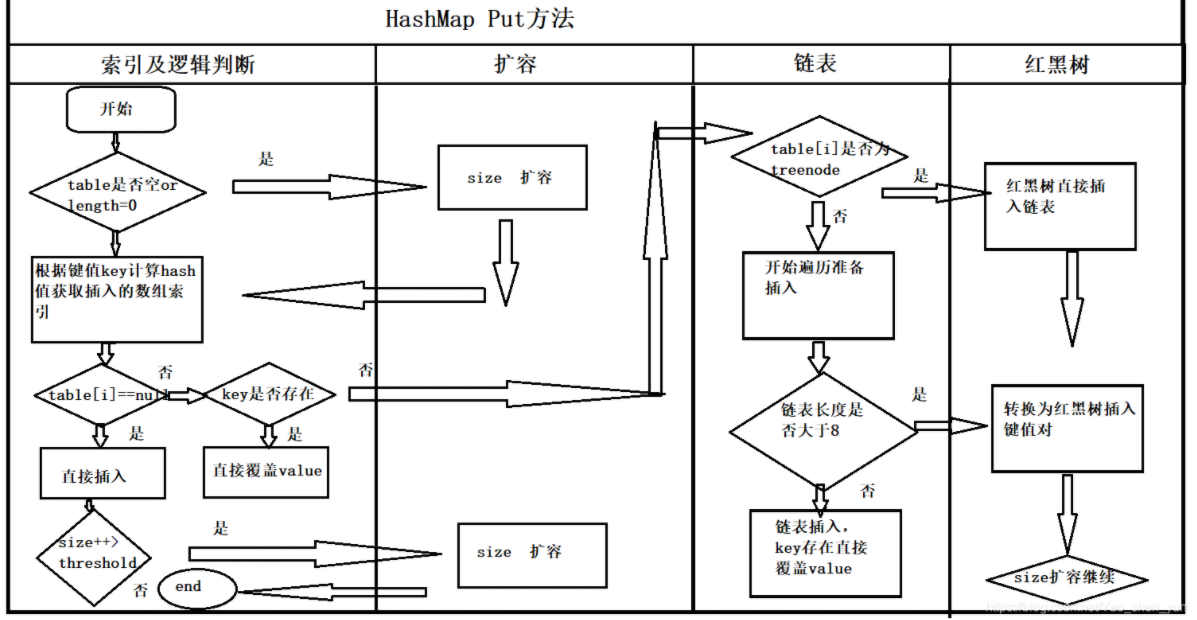
13、HashMap的put源码过程
put:(key-value)方法是HashMap中最重要的方法,使用HashMap最主要使用的就是put,get两个方法。
判断键值对数组table[i]是否为空或者为null,否则执行resize()进行扩容;
根据键值key计算hash值得到插入的数组索引 i ,如果table[i] == null ,直接新建节点添加即可,转入6,如果table[i] 不为空,则转向3;
判断table[i] 的首个元素是否和key一样,如果相同(hashCode和equals)直接覆盖value,否则转向4;
判断table[i] 是否为treeNode,即table[i]是否为红黑树,如果是红黑树,则直接插入键值对,否则转向5;
遍历table[i] ,判断链表长度是否大于8,大于8的话把链表转换成红黑树,进行插入操作,否则进行链表插入操作;便利时遇到相同key直接覆盖value;
插入成功后,判断实际存在的键值对数量size是否超过了threshold,如果超过,则扩容;
get方法取值过程:
int hash = key.hashCode();
int index = hash%Entry[].length;
指定key通过hash函数得到key的hash值;
调用内部方法getNode(),得到桶号(一般为hash值对桶数求摸);
比较桶的内部元素是否和key相等,如不相等,则没有找到,相等,则取出相等记录的value;
如果得到key所在桶的头结点恰好是红黑树节点,就调用红黑树节点的getTreeNode()方法,否则就遍历链表节点。getTreeNode()方法通过调用树形节点的find()方法进行查找。由于之前添加时已经保证这个树是有序的,因此查找时基本就是折半查找,效率高;
如果对比节点的哈希值和要查找的哈希值相等,就会判断key是否相等,相等就直接返回;不相等就从子树中递归查找;
14、ConCurrentHashMap底层1.7和1.8 安全(JUC)
15、常用的数据结构(数组、栈、队列、红黑二叉树)
16、执行顺序
父类静态代码块、静态变量 ps:按声明顺序执行
子类静态代码块、静态变量 ps:按声明顺序执行
父类局部代码块、成员变量 ps:按声明顺序执行
父类构造函数
子类局部代码块、成员变量 ps:按声明顺序执行
子类构造函数
17、Lambda表达式
Lambda Expression可以定义为允许⽤户将⽅法作为参数传递的匿名函数。这有助于删除⼤ 量的样板代
码。Lambda函数没有访问修饰符(私有,公共或受保护),没有返回类型声明和 没有名称。
Lambda表达式允许⽤户将“函数”传递给代码。所以,与以前需要⼀整套的接⼝/抽象类想 必,我们可以
更容易地编写代码。例如,假设我们的代码具有⼀些复杂的循环/条件逻辑或⼯作 流程。使⽤lambda表
达式,在那些有难度的地⽅,可以得到很好的解决。
18、函数式接口之Stream
中间操作:
- filter:过滤元素
- map:映射,将元素转换成其他形式或提取信息
- flatMap:扁平化流映射
- limit:截断流,使其元素不超过给定数量
- skip:跳过指定数量的元素
- sorted:排序
- distinct:去重
终端操作:
- anyMatch:检查流中是否有一个元素能匹配给定的谓词
- allMatch:检查谓词是否匹配所有元素
- noneMatch:检查是否没有任何元素与给定的谓词匹配
- findAny:返回当前流中的任意元素(用于并行的场景)
- findFirst:查找第一个元素
- collect:把流转换成其他形式,如集合 List、Map、Integer
- forEach:消费流中的每个元素并对其应用 Lambda,返回 void
- reduce:归约,如:求和、最大值、最小值
- count:返回流中元素的个数
19、函数式接口之Function
java.util.function.Function20、函数式接口之Predicate
java.util.function.Predicate接口定义了一个名叫 test 的抽象方法,它接受泛型 T 对象,并返回一个 boolean。在需要表示一个涉及类型 T 的布尔表达式时,可以使用这个接口,通常称为断言性接口。 21、函数式接口之Consumer
java.util.function.Consumer接口定义了一个名叫 accept 的抽象方法,它接受泛型T,没有返回值(void)。如果需要访问类型 T 的对象,并对其执行某些操作,可以使用这个接口,通常称为消费性接口。 22、函数式接口之Supplier
java.util.function.Supplier接口定义了一个 get 的抽象方法,它没有参数,返回一个泛型 T 的对象,这类似于一个工厂方法,通常称为功能性接口。

若有收获,就点个赞吧
0 人点赞
