- 索引分析
- 索引失效(应该避免)
- 1), 全值匹配我最爱
- 2),最佳左前缀法则
- 3),不在索引where列上做任何操作(计算,函数,(自动or手动)类型转换),会导致索引失效转向全表扫描
- 4),存储引擎不能使用索引中范围条件右边的列(这里说的是建索引的地方)
- 5),尽量使用覆盖索引(只访问索引的查询(索引列和查询列一致)),减少select *
- 6),mysql在使用 不等于(!= 或者 <>) 的时候无法使用索引回导致全表扫描
- 7),is null 走索引,is not null 也无法使用索引
- 8), like 以通配符开头 (‘%abc’) mysql索引会失效会变为全表扫描
- 9),字符串不加单引号索引会失效
- 10),少用 or 用它来连接时索引失效
- 单表-一般性建议
- ">
- 单表-口诀
- 关联查询-建议
- 面试题讲解
- 索引优化口诀
- 一般性建议
索引分析
单表优化
- 创表语句 ```sql create table article( id int not null auto_increment primary key, author_id int, category_id int, views int , comments int , title varchar(300), content text );
—单表语句 explain select id from article where category_id=1 and comments >1 order by views desc limit 1 ;
- 第一次优化:创建了ccv的复合索引,但comments > 1是范围查询,导致索引失效,依然会出现using filesort排序的情况- 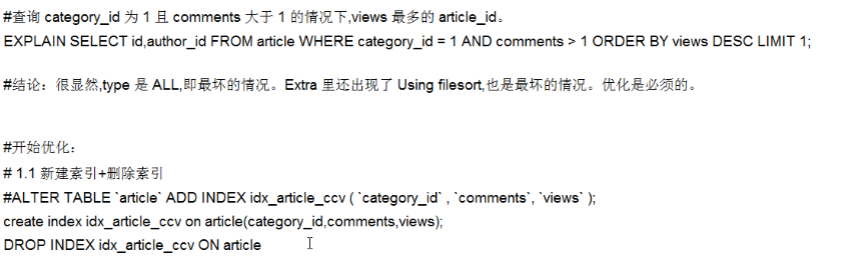- - 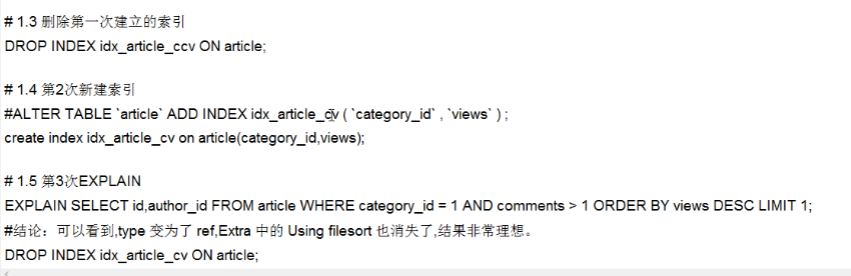<a name="prItJ"></a>## 两表建表语句```sqlcreate table class(id int not null primary key auto_increment,card int);create table book(bookid int not null auto_increment primary key,card int);insert into class values (null,10),(null,7),(null,3),(null,13),(null,17),(null,4),(null,9),(null,13),(null,19),(null,16),(null,20),(null,13),(null,3),(null,15),(null,5),(null,20),(null,6),(null,9),(null,6),(null,4);insert into book values(null,2),(null,18),(null,3),(null,2),(null,20),(null,15),(null,11),(null,13),(null,8),(null,4),(null,13),(null,14),(null,10),(null,7),(null,3),(null,16),(null,10),(null,3),(null,5),(null,14);


结论:两表做关联查询,当使用left join时,将关联字段的索引建立在右表,原因是:left join条件用于确定如何从右表搜索行,左边一定都有; right join也是同理(right join(右连接)把索引建立在 right 前面那个表);
三表
建表SQL
create table phone(pid int not null primary key auto_increment,card int);insert into phone values (null,16),(null,17),(null,14),(null,17),(null,16),(null,20),(null,11),(null,15),(null,3),(null,7),(null,5),(null,5),(null,7),(null,3),(null,11),(null,4),(null,9),(null,12),(null,13),(null,8);--三表连接explain select * from classleft join book on class.card = book.cardleft join phone on book.card=phone.card;


Join优化总结 1),尽可能减少Join语句中的NestedLoop的循环总次数,永远用小结果集驱动大的结果集(小表驱动大表) 2),优先优化 NestedLoop的内层循环 3),保证Join语句中被驱动表上Join条件字段已经被索引 4),当无法保证驱动表的Join条件字段被索引且内存资源充足的前提下,不要太吝啬JoinBuffer的设置
索引失效(应该避免)
建表sql
-- 建立员工表create table staffs(`id` int not null primary key auto_increment,`name` varchar(30),age int,pos varchar(20),add_time TIMESTAMP);insert into staffs values (null,'zs',23,'manager',now()),(null,'july',11,'dev',now()),(null,'tomc',33,'dev',now());-- 建立覆合索引alter table staffs add index idx_staffs_nameAagePos(name,age,pos);

explain select * from staffs where name ='july';
结论: 从上述图片可以看出 type 类型是 ref 用到了覆合索引 ref是一个常量 const
- 只查覆合索引前俩个

explain select * from staffs where name ='july' and age = 25;
结论: key_len的精度越小越好,你要想查询的精度提高,付出的代价肯定要大,在上面可以看出ref 里面有俩个const
- 全值匹配

explain select * from staffs where name ='july' and age = 25 and pos ='dev';
索引如何不会生效呢?(没有了火车头 ,索引就会失效)
- 创建的索引是 nameAgePos 这时我们只查Age 和 pos

explain select * from staffs where age = 25 and pos ='dev';
type 是all 变为了全表扫描 key 没有用到覆合索引 ref 从const 常量变为了 null
- 创建的索引是 nameAgePos 这时我们只查 pos

explain select * from staffs where pos ='dev';
结论: 只查pos字段 覆合索引失效 type类型是all进行了全表扫描 ref 也是null key 也没有用到覆合索引
口诀1 : 带头大哥不能死(我们建立的索引 nameAgePos 这里的带头大哥就是 name 相当于火车头,它不能丢)
我们创建的索引 nameAgePos 这时我们只查 name与Pos
explain select * from staffs where name ='july' and pos ='dev';
结论: 用到了覆合索引,从key可以看出,但是只是部分用到了索引 从ref 只有一个const可以看出 违背了最左前缀法则的第二个口诀 中间兄弟不能丢
2),最佳左前缀法则
如果索引多列,要遵循最左前缀法则,指的是查询从索引的最左侧前列开始并且 不跳过索引中间列
3),不在索引where列上做任何操作(计算,函数,(自动or手动)类型转换),会导致索引失效转向全表扫描
过程和结果同样重要
问题查询name为 july的用户信息
方式1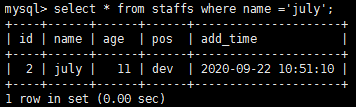
select * from staffs where name ='july';
方式2
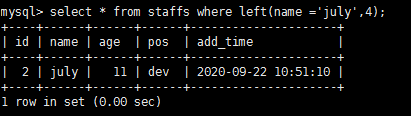
select * from staffs where left(name ='july',4);-- 使用函数进行查询
4),存储引擎不能使用索引中范围条件右边的列(这里说的是建索引的地方)
全值匹配



explain select * from staffs where name ='july' and age = 25 and pos ='dev';
- 范围之后全失效

explain select * from staffs where name ='july' and age > 25 and pos ='dev';
注意: name 用于检索 而 age 用于排序 范围之后全失效
5),尽量使用覆盖索引(只访问索引的查询(索引列和查询列一致)),减少select *
使用 * 
explain select * from staffs where name ='july' and age= 25 and pos ='dev';
不使用 *(返回索引字段)
explain select name,age,pos from staffs where name ='july' and age= 25 and pos ='dev';
明显 不使用 比使用 的效率要高,因为 同样是 ref 但是 不使用* Extra 出现了 Using Index
不使用* 且查询包含 < 或者> 
explain select name,age,pos from staffs where name ='july' and age > 25 and pos ='dev';
对比发现: 判断条件一样的sql语句,一个用select ,一个用 查询字段,明显可以看出 ,使用查询字段的sql语句效率比它高 select 字段 vs select ref > range key_len < key_len Extra 效率高于 Extra
6),mysql在使用 不等于(!= 或者 <>) 的时候无法使用索引回导致全表扫描
- 等于 =

explain select * from staffs where name = 'july';
- 不等于 !=

explain select * from staffs where name != 'july';
- 不等于 <>

explain select * from staffs where name <> 'july';
7),is null 走索引,is not null 也无法使用索引
- is null

explain select * from staffs where name is null;
- is not null

explain select * from staffs where name is not null;
8), like 以通配符开头 (‘%abc’) mysql索引会失效会变为全表扫描
- like查询%号写右边
- 方式1

explain select * from staffs where name like '%july%';
- 方式2

explain select * from staffs where name like '%july';
- 方式3

explain select * from staffs where name like 'july%';
- 问题?(解决like %xx% 时索引不被引用的方法?)
- 使用覆盖索引(你建的索引和你查的字段个数顺序上最好完全一致)
- 覆合索引 nameAgePos
- 生效
- 查询语句1
- 覆合索引 nameAgePos
- 使用覆盖索引(你建的索引和你查的字段个数顺序上最好完全一致)

explain select id,name,age,pos from staffs where name like '%july%';
- 查询语句2

explain select id,name from staffs where name like '%july%';
- 查询语句3

explain select id,name,age from staffs where name like '%july%';
- 查询语句4

explain select id from staffs where name like '%july%';
- 失效- 语句1查询 索引之外字段

explain select name,age,pos,add_time from staffs where name like '%july%';
- 语句2 select*查询全部字段

explain select * from staffs where name like '%july%';
9),字符串不加单引号索引会失效
- 语句1(加单引号)

explain select * from staffs where name ='2000';
- 语句2(不加单引号)

explain select * from staffs where name =2000;
10),少用 or 用它来连接时索引失效
- 使用or 关键字索引失效

explain select * from staffs where name ='2000' or name='july';
单表-一般性建议
- 对于单键索引,尽量选择针对当前query 过滤性更好的索引
- 在选择组合索引的时候,当前Query中过滤性最好的字段顺序中,位置越靠前越好
- 在选择组合索引的时候,尽量选择可以能够包括当前query中 where 子句中更多字段的索引
- 在选择组合索引的时候,如果某个字段可能出现范围查询时,尽量把这个字段放在索引次序列的最后
-
单表-口诀
1.头部打个不能丢,中间兄弟不能断
2.永远要符合最佳最左侧前缀法则
3.索引列上无计算
4.like %加右边
5.范围之后全失效
6.字符串里有引号关联查询-建议
保证被驱动表的join字段已经被索引
- left join 时,选择小表作为驱动表,大表作为被驱动表
- inner join时,mysql会自己帮你把小结果集选为驱动表
- 子查询尽量不要放在被驱动表,有可能使用不到索引
-
子查询优化
尽量不要使用 not in 或者 not exists 用left join 表名 on xxx is null 来代替它
面试题讲解
建表语句
create table test03( id int not null primary key auto_increment,c1 char(10),c2 char(10),c3 char(10),c4 char(10),c5 char(10) );insert into test03 values (null,'a1','a2','a3','a4','a5'), (null,'b1','b2','b3','b4','b5'), (null,'c1','c2','c3','c4','c5'), (null,'d1','d2','d3','d4','d5'), (null,'e1','e2','e3','e4','a5');select * from test03;-- 建立覆合索引 alter table test03 add index idx_test03_c1234(c1,c2,c3,c4);
案例
(创建的覆合索引 idx_test03_c1234 根据以下sql分析下索引的使用情况)
热身(都按照索引顺序来进行查询)
全值匹配我最爱
explain select * from test03 where c1='a1' and c2='a2' and c3 ='a3' and c4='a4';
前俩个索引
explain select * from test03 where c1='a1' and c2='a2';
只查最左侧索引
explain select * from test03 where c1='a1';
查左侧的三个索引
explain select * from test03 where c1='a1' and c2='a2' and c3 ='a3';
索引顺序和where查询的顺序不同(不包含< 或者 >)
explain select * from test03 where c1='a1' and c2='a2' and c4='a4' and c3='a3';

explain select * from test03 where c4='a4' and c3='a3' and c2='a2' and c1='a1';

总结: mysql 底层会对sql语句进行一次优化,在 optimiter 中,建议where 后面的判断根据索引来写,因为这样会减少一次mysql底层的优化
索引顺序和where查询的顺序不同(包含< 或者 >)
explain select * from test03 where c1='a1' and c2='a2' and c3 >'a3' and c4='a4';

用到了三个索引字段,因为范围之后全部失效c4没有用到索引
explain select * from test03 where c1='a1' and c2='a2' and c4 >'a4' and c3='c3';

-- 它会把sql 语句优化成如下explain select * from test03 where c1='a1' and c2='a2' and c3='a3' and c4 >'a4';
使用到了四个索引字段 从ref是124 可以看出,也使用到了索引
索引中使用 order by(出现 Using filesort 就是没有用到索引)
顺序错,必排序
explain select * from test03 where c1='a1' and c5='a5' order by c3,c2;

出现 filesort
explain select * from test03 where c1='a1' and c2='a2' and c5='a5' order by c3,c2;

explain select * from test03 where c1='a1' and c2='a2' and c5='a5' order by c2,c3;

explain select * from test03 where c1='a1' and c2='a2' order by c2,c3 and c5='a5';
用c1,和c2 俩个字段的索引,但是c2和c3用于排序 无filesort 本例是有常量 c2=’a2’ 索引 order by c3,’a2’(c2)
explain select * from test03 where c1='a1' and c2='a2' order by c2,c3;

explain select * from test03 where c1='a1' and c5='a5' order by c3,c2;

有filesort,我们建的索引是 1234 它没有按照索引顺序来,3 和 2 颠倒了
explain select * from test03 where c1='a1' and c5='a5' order by c2,c3;

只用到了一个索引 c1 但是c2和c3用于排序,无filesort
explain select * from test03 where c1='a1' and c2='a2' order by c4;

Using filesort
explain select * from test03 where c1='a1' and c2='a2'order by c3;

explain select * from test03 where c1='a1' and c2='a2'and c4='a4' order by c3;

-- 优化成explain select * from test03 where c1='a1' and c2='a2' order by c3 and c4='a4';
ref 级别,用到了俩个索引c1 与c2 索引,索引的俩大功能查找和排序,c3用于排序
无过滤条件,不使用索引
explain select SQL_NO_CACHE * from emp order by age,deptId;

--创建索引create index idx_emp_ageDeptid on emp(age,deptId);再次执行explain 语句

我们需要添加过滤条件,如果实在没有过滤条件就是 limit 10
方向相反,必排序(Using filesort)
--创建覆合索引create index idx_emp_ageDeptidName on emp(age,deptId,name);explain select SQL_NO_CACHE * from emp where age=1 order by deptId desc,name desc;

explain select SQL_NO_CACHE * from emp where age=1 order by deptId asc,name desc;

排序分组优化
索引的选择
例子,查询年龄为30岁的,且员工编号小于101000的用户,按用户名称排序 select SQL_NO_CACHE* from emp where age =30 and empno <101000 order by name;
建立索引create index idx_emp_ageEmpno on emp(age,empno);explain 执行sql语句( type 类型为 range rows 为 4000多行 会出现手动排序的Using filesort)

create index idx_emp_ageName on emp(age,name);explain 执行sql语句 (type 类型为 ref rows 物理扫描行数为 5w行)

总结: 如果上面俩个索引(idx_emp_ageEmpno 和 idx_emp_ageName ) 这时mysql 会选择 idx_emp_ageEmpno ,因为mysql 会自动给我们选择 效率最高的索引
这时mysql 会选择 idx_emp_ageEmpno ,因为mysql 会自动给我们选择 效率最高的索引
如果不在索引列上,filesort有俩种算法 mysql就要启动双路排序和单路排序
索引中使用 group by
explain select * from test03 where c1='a1' and c4 ='a4' group by c2,c3;

无filesort
explain select * from test03 where c1='a1' and c4 ='a4' group by c3,c2;

有filesort 并且还有 temporary
总结: group by 表面交分组,分组之前必排序,group by 和 order by其排序法则和优化原则大都是一致的,只是group by 有having 这个筛选
like 模糊查询
explain select * from test03 where c1='a1' and c2 like 'a2%'and c3='a3';

用到了3索引,
explain select * from test03 where c1='a1' and c2 like '%a2'and c3='a3';

用到了1个索引 c1
explain select * from test03 where c1='a1' and c2 like '%a2%'and c3='a3';

只用到了 c1这个索引
explain select * from test03 where c1='a1' and c2 like 'a%a2%'and c3='a3';

用到了 3个索引
定值(const常量)、范围还是排序,一般order by是给个范围
group by 基本上都需要进行排序,如果有错乱的产生,会有临时表产生
索引优化口诀

若有收获,就点个赞吧
0 人点赞
