
Cpu高速缓存
cpu 高速缓存是由 若干个缓存行 组成的,缓存行是cpu 高速缓存的最小存储单位 也是cpu和内存交互的最小单元在x86架构中每个缓存行大小为64位 即8字节 cpu每次从内存中加载8字节的数据作为一个缓存行保存到高速缓存中
空间局部性原理
如果一个存储器的位置被引用 那么将来它附近的位置也会被引用 这种缓存行读取的方式能够减少与内存交互的次数 提高 cpu的利用率 从而节省cpu读取数据的时间
寄存器

伪共享

当Cpu从内存加载数据到缓存行时会把临近的64位数据一起保存到缓存行中基于空间局部性原理 CPU在读取第二个数据时发现该数据已经存在于缓存行中则不会再去内存寻址 而是直接读取
两个线程 一个读取long[1] 另一个读取long[4] 由于缓存行机制使得两个cpu的高速缓存会共享同一个缓存行 为了保证缓存一致性 cpu会不断使缓存行失效 并重新加载进高速缓存 竞争激烈的情况下就伪共享了
对其填充解决伪共享问题
@Contended配置jvm 参数 -XX:-RestrictContended
Cpu缓存一致性问题
CPUA修改缓存x=20的值改为40 同步到本地缓存行 但是没同步到 内存中 所以CPUB读到的还是X=20是之前的值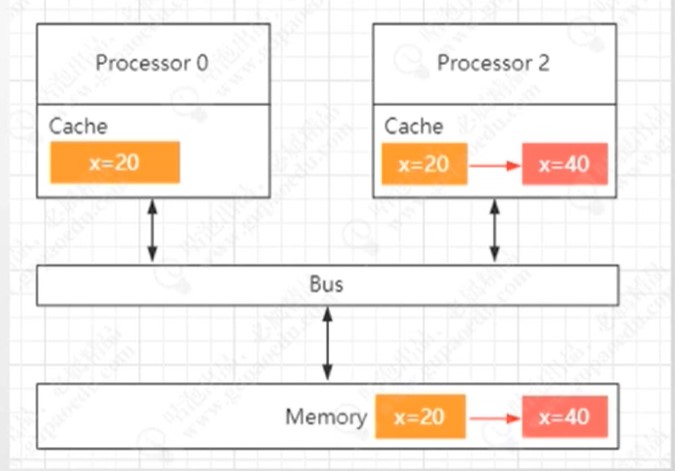
总线锁 和缓存锁

总线
cpu与内存 输出/输入设备传递信息的公共通道 当cpu访问内存进行数据交互时 必须经过总线来传输
总线锁
在总线上声明了一个lock#信号 这个信号可以确保共享内存只有当前cpu可以访问
缓存锁
如果当前cpu访问的数据已经被缓存到其他cpu高速缓存中 那么 cpu不会在总线上生命Lock#信号 而是采用缓存一致性协议来保证多个cpu的缓存一致性
缓存一致性协议
M(Modify)
表示共享数据只缓存在当前CPU缓存中 并且是被修改状态 缓存的数据和主内存的数据一致
E(Exclusive)
表示缓存的独占状态 数据只缓存在当前CPU缓存中 并且没有被修改
S(Shared)
表示数据可能被多个CPU缓存 并且各个缓存中的数据和主内存数据一致
I(Invalid)表示缓存已经失效
如果一个缓存行处于M状态 则必须监听所有试图获取该缓存行对应的主内存地址的操作 如果监听这类操作的发生 则必须在该操作 之前把缓存行中的数据写回主内存
如果缓存行处于S状态 那么则必须要监听使该缓存行状态设置为Invalid 或者对缓存行执行Exclusive操作的请求 如果存在则必须要把当前缓存行状态设置为Invalid
如果一个缓存行状态为E状态 那么它必须要监听其他试图读取该缓存行对应的主内地址的操作一旦有这种操作该缓存行需要设置成Shared
监听过程由嗅探协议完成
读取数据过程
1.Cpu0发出一条从内存中读取X变量的指令 主内存通过总线返回数据后缓存到CPU0的高速缓存中 将状态设置成E
2.如果此时CPU1发出对变量X的读取指令 那么当CPU0检测到缓存地址冲突就会针对该消息作出响应,将缓存在cpu0的x的值通过ReadResponse消息返回给CPU1 此时X分别存在CPU0和CPU1的高速缓存中所有X的状态为S
3.然后CPU0把X变量的值修改成x=30 把自己的缓存行状态设置成E 接着把修改后的数据写入内存中 此时X的缓存行是共享状态 同时需要发送一个Invalidate消息给其他缓存 Cpu1收到消息后把高速缓存的x置为Invalid状态
指令重排序
编译器或CPU为了优化程序的执行性能而对指令进行重新排序的一种手段
指令重排序的阶段
1.编译器重排序
在编译过程中编译器根据上下文分析对指令进行重排序 目的是减少CPU和内存的交互 重排序之后尽可能保证CPU从寄存器或缓存行中读取数据
2.处理器重排序
1.并行指令集重排序
2.内存系统重排序
引入Store Buffer缓冲区延时写入产生的指令顺序执行不一致的问题
as-if-serial语义
所有的程序指令都可以因为优化而被重排序 但是必须是在单线程环境下
单线程环境下 运行结果和重排序之后的结果一致
Store Buffer
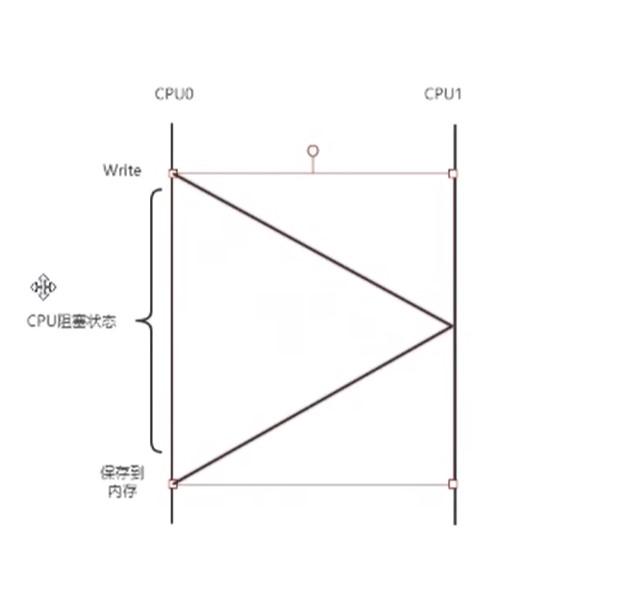
防止缓存一致性导致的不必要的CPU阻塞所以每个缓存行之间增加一个Store Buffer
Cpu0引入Store Buffer的设计后 CPU0会先发送一个Invalidate消息给其他包含该缓存行的CPU1 并把当前修改的数据写入StoreBuffers中 然后继续执行后续的指令 等收到CPU1的Ack消息后 Cpu0再把Store Buffer挪到缓存行
Store Buffer 带来的问题
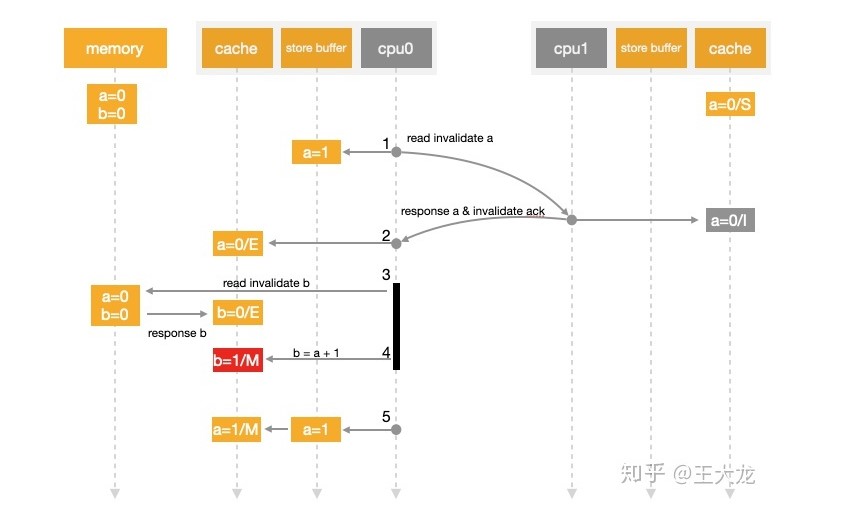
1.假设a 变量的缓存状态是SharedCpu0执行a=1的指令 此时a不存在cpu0的缓存中 但是在其他cpu缓存中他是Shared状态 所以cpu0会发送一个MESI协议消息 read invalidate给CPU1 企图从其他缓存了该变量 cpu中去读取值 并使得其他cpu缓存行失效
2.cpu0把a=1写入cpu0的store buffer中
3.CPU1收到read invalidate消息后 返回 ReadResponse 把 a=0返回 并让cpu1的缓存行失效
4.由于StoreBuffer存在 cpu0在等待cpu1返回之前就继续往下执行b=a+1的指令此时Cache 中还没有加载b 所以b=0
5.cpu0 收到其他cpu返回的结果 更新了缓存行 a=0 接着加载出了a=0
6.接着cpu0把store buffer a=1的数据同步到缓存行中
7.结果判断失败
Store Forwarding
store buffer可能导致破坏程序顺序的问题,硬件工程师在store buffer的基础上,又实现了”store forwarding”技术: cpu可以直接从store buffer中加载数据,即支持将cpu存入store buffer的数据传递(forwarding)给后续的加载操作,而不经由cache。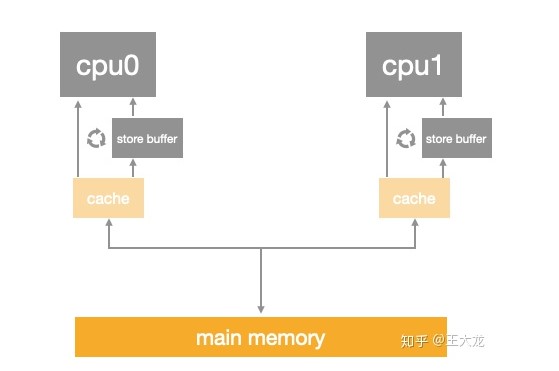
带来的问题
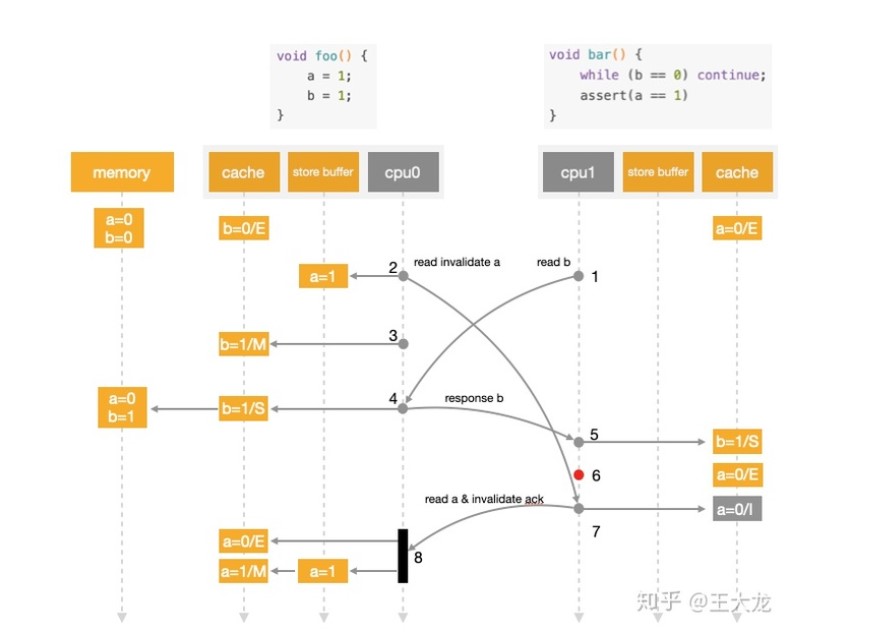
1.CPU0执行a=1的指令 a是独占且a不存在cou0的缓存行中 因此cpu0把a=1写入StoreBuffer中并发送MESI协议消息给 cpu1
2.cpu1执行 b=1的操作 cpu1的缓存行中没有b的缓存 所以cpu1发出一个MESI协议消息 给cpu0
3.cpu0执行 b=1的指令 而B变量 存在于CPU0的缓存行中 也就说缓存行属于M或者E状态 因此直接把b=1写入缓存行
4.此时cpu0收到 cpu1发来的消息 将缓存行中的B=1返回给cpu1 并修改缓存状态为 S
5.CPU1 修改缓存行 b=1并将状态设置为S
6.获取b=1后 cpu1继续执行assert(a=1)的指令 此时cpu1的缓存行中 a=0
7.cpu1收到cpu0的消息把包含a=0的缓存行 返回给cpu0 并设置成I(失效)但此时这个过程比前面的异步步骤执行晚已经导致了问题
8.CPU0收到包含a的缓存行后 把 stre buffer中a=1同步到缓存行
问题原因
cpu之间不知道a和b的数据依赖 通信之间有延迟
Invalidate Queues(用于让缓存行失效的消息)
store Buffers本身存储容量是有限的 如果被填满就必须要等到 cpu返回 ack消息后storebuffes才会对对应的指令进行清理 而这个过程必须要等待
流程
当cpu 收到 Invalidate 消息时 把让缓存行失效的消息放入Invalidate Queues 然后同步返回ack 消息
导致的问题
cpu内存系统的write操作的重排序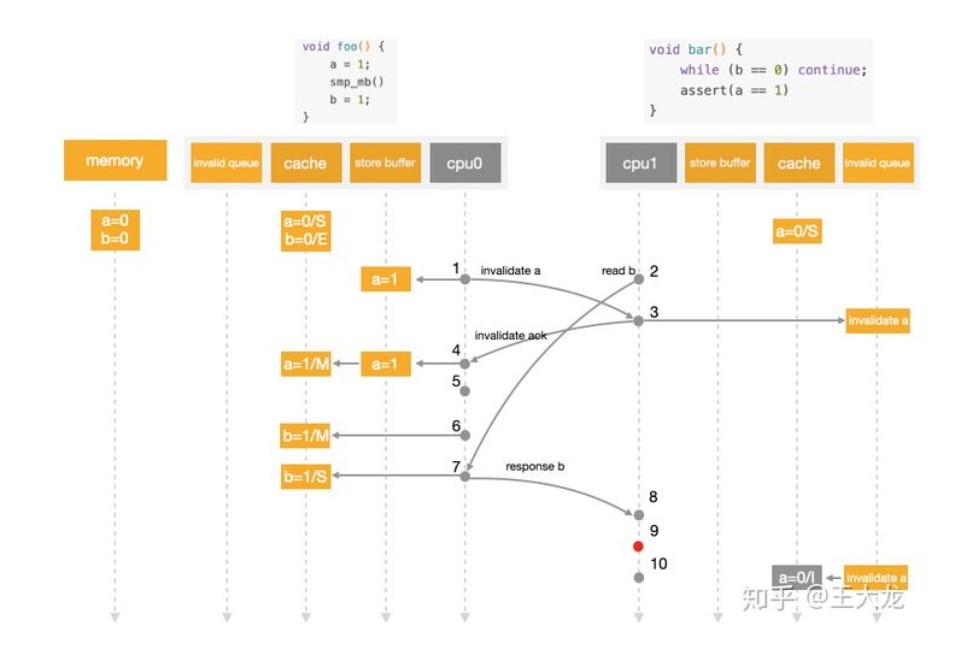
- cpu0执行a=1,由于其有包含a的cache line,将a写入store buffer,并发出Invalidate a消息。
- cpu1执行while(b == 0),它没有b的cache,发出Read b消息。
- cpu1收到cpu0的Invalidate a消息,将其放入Invalidate Queue,返回Invalidate ACK。
- cpu0收到Invalidate ACK,将store buffer中的a=1刷新到cache line,标记为Modified。
- cpu0看到smp_wmb()内存屏障,但是由于其store buffer为空,因此它可以直接跳过该语句。
- cpu0执行b=1,由于其cache独占b,因此直接执行写入,cache line标记为Modified。
- cpu0收到cpu1发的Read b消息,将包含b的cache line写回内存并返回该cache line,本地的cache line标记为Shared。
- cpu1收到包含b(当前值1)的cache line,结束while循环。
- cpu1执行assert(a == 1),由于其本地有包含a旧值的cache line,读到a初始值0,断言失败。
- cpu1这时才处理Invalid Queue中的消息,将包含a旧值的cache line置为Invalid
CPU优化
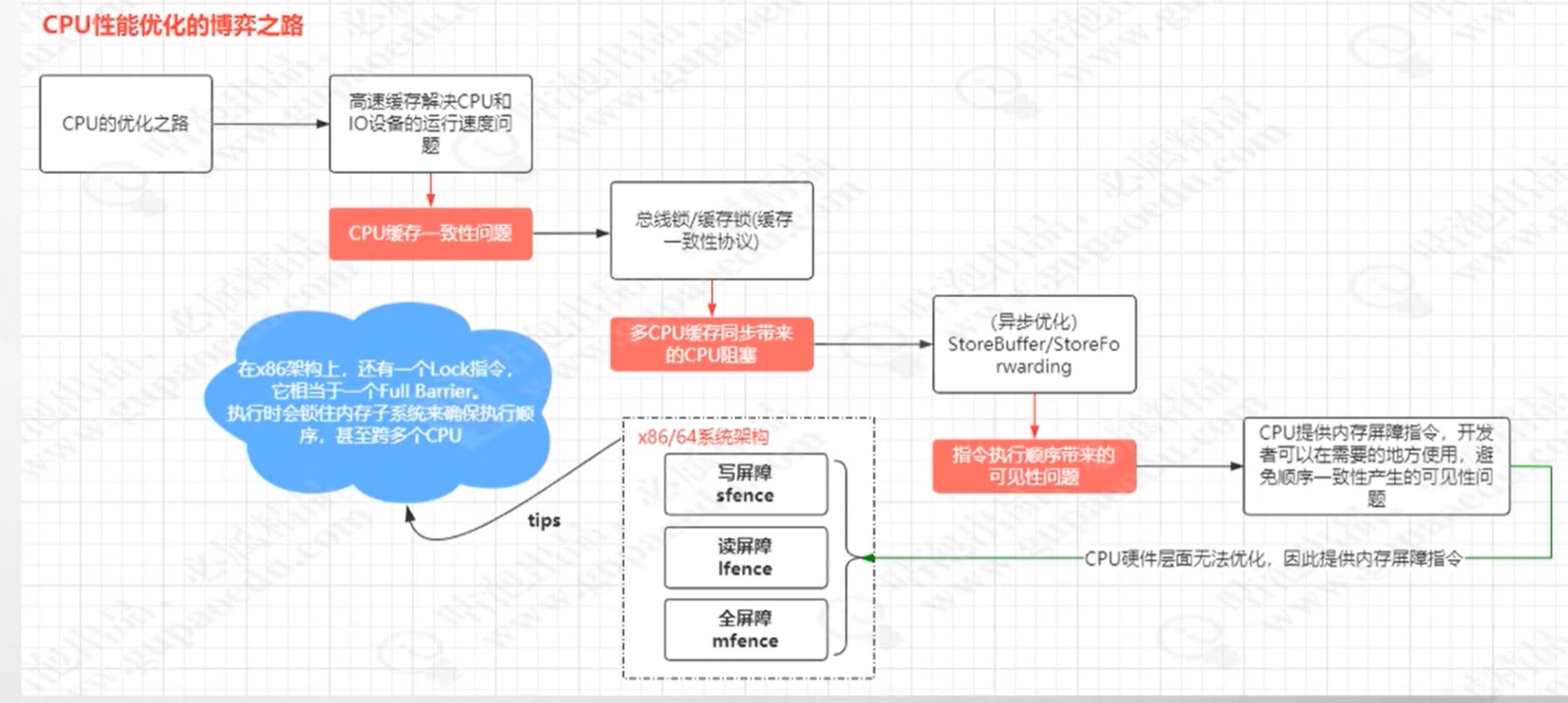
内存屏障(解决指令重排序)
1.读屏障(ifence)
将Invalidate Queues中的指令立即处理 并且强制读取cpu的缓存行 执行 ifence指令之后的读操作不会被重排序到ifence指令之前这意味着其他cpu 暴露出来的缓存行对当前cpu可见
2.写屏障(sfence)
会把 store Buffers中修改刷新到本地缓存中 使得其他cpu可以看到这些修改 而且在执行sfence指令之后的写操作不会重排序到 sfence指令之前 这意味着sfence指令之前的写操作全局可见
3.读写屏障(mfence)
保证了 mfence指令执行前后的读写操作的顺序 同时要求执行 mfence指令之后的写操作全局可见 之前的写操作全局可见
Java Memory Mode(JMM)
Happens-Before模型
as-if-serial
一个线程中 存在两个操作 x和y 并且x源代码现在y之前
传递性规则
A Happens-Before B
B Happens-Before C
A Happens-Before C
volatile规则
通过内存屏障来保证 volatile变量修饰的写操作一定 Happens-Before读操作
监视器锁规则
一个线程释放锁必须 Happens-Before 后续线程的加锁操作
start 规则
一个线程调用start方法之前的所有操作 Happens-Before 线程B的任意操作
join 规则
main线程执行了一个线程A的join方法并成功返回 那么线程A中的任意操作 Happens-Before 于main线程线程join方法返回之后的操作

若有收获,就点个赞吧
0 人点赞
