Paxos协议(希腊城邦算法)
一致性算法的最终目的是让各个节点的数据内容达成一致,那么什么情况下可以认为各节点已经成功达成一致了呢?Paxos中的判定方法是如果存在大部分节点共同接收了该更新内容,可以认为本次更新已经达成一致。
Paxos将节点进程分成“发起者””接收者””学习者”三类,论文称每个发起者发起的新的更新为”提议”,每个提议包含一个数字n和提议内容,算法的实现状态见图1。首先考虑一种特殊情况,如果在最开始的阶段,所有接收者没有收到任何”提议”,这时发起者发出的提议它们是会直接接受的。然而每次更新过程中,可能存在多个发起者发送提议,那么初始阶段可能各个接收者接受不同的提议,进而无法达成一致。这就要求一个接收者能够接受不止一个”提议”。这么一来就可能存在多个”提议”被”选择”(被大部分接收者接受)。既然会出现多个”提议”同时被选择的情况,最终如何达成一致呢?把条件设严格一点,如果后面被”选择”的”提议”内容都和第一个一致,那么无论有多少”提议”,最终不就相当于只有一个被选择了嘛!问题又来了,如何使得后面被选择的”提议”内容都和第一个一致呢?很简单,再把条件设严格一些,如果已经有”提议1”被选择,那么后续发起者发送的新”提议”的内容必须与”提议1”一致。
因为作者在描述Paxos时,列举了希腊城邦选举的例子,所以该算法又被称为希腊城邦算法。我们这里便列举希腊城邦选举的例子,帮助我们理解Paxos算法。城中的一些位高权重的人们(“发起者”)会提出新的”法案”,这些法案需要立法委员(“接收者”)达成一致即多数同意才能通过。于是权贵们会预先给立法委员一些金钱,让他们通过自己的法案,这对应的就是”预请求”,如果立法委员已经收到过更高贿赂的”预请求”,他们会拒绝,否则会同意。权贵们贿赂成功后,会告诉立法委员新的法案,在收到新法案之前,如果立法委员没有收到更高的贿赂,他们会选择接受这个法案,否则会拒绝。很关键的一点是,不要忘了我们是一致性协议,不是真正的立法,因此很关键的一点是如果立法委员在接收到更高的贿赂时已经接受了某个法案,那他会告诉贿赂的权贵这个法案的内容,权贵会将自己发起的法案改成该法案的内容,这样才能够迅速达成一致性。
Paxos是非常经典的一致性协议,但是因为过于理论化,难以直接工程化,因此工业界出现了诸多基于Paxos思想出发的变种。虽然这些变种最终很多都和原始的Paxos有比较大的差距,甚至完全演变成了新的协议,但是作为奠基者的Paxos在分布式一致性协议中依然持有不可撼动的地位。
**
Raft协议
Raft协议是斯坦福的Diego Ongaro、John Ousterhout两人于2013年提出,作者表示流行的Paxos算法难以理解,且其过于理论化致使直接应用于工程实现时出现很多困难,因此作者希望提出一个能被大众比较容易地理解接受,且易于工程实现的协议。Raft由此应运而生。
Raft的算法逻辑主要可以分成两个部分,一个是选举部分,另一个是log传输部分。和Paxos部分不同的是,这里的log是连续并且按序传输的。Raft中定义了一个叫term概念,一个term实际上相当于一个时间片,如下图所示,这个时间片被分成两个部分,第一部分是选举部分,第二部分是传输部分。由此Raft的逻辑也可以分成选举和传输前后两个方面进行讲解。
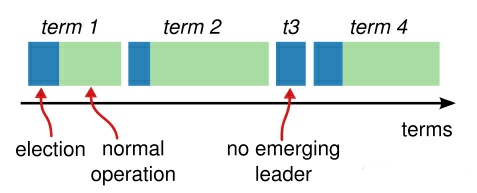
首先我们介绍选举部分的算法逻辑。在Raft中可以存在多个server,其中每一个server都有机会成为leader,但是真实有效的leader只有一个。于是这个leader的产生需要所有的server去进行竞争。在每个term开始的阶段,众多server需要进行竞选,选出一个有效的leader。每个server被设置了一个300-400ms之间随机的timeout,在如果在timeout内没有收到某一个leader发来的心跳信息,那么这个server就会发起竞选,将自己的term值加一,成为candidate,并寻求其他server的投票。当且仅当某一个candidate收到超过一半的server的票数时,它就成功当选了leader,并开始向每个server发送心跳信息。仅仅这么做其实是存在问题的,如果有多个candidate同时参与竞选,很可能出现选票分散的情况,最终无法选出有效的leader。因而除此之外,Raft还要求如果candidate收到term比自己大的投票请求时将自己的状态修改成follower,这么一来就成了谁的term增加得快的问题,因为timeout是随机的,总会出现更快的server,因此算法最终是收敛的。选举过程的状态图可见下图.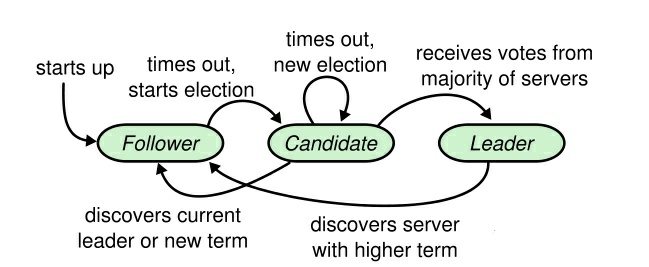
那么当选举成功后,整个集群进入log传输的状态。client会给leader发送需要传输的log,leader收到后在log上附加log的位置索引值和当前term值。这么一来每个log的索引与term值都是独一无二的。leader中会记录所有待传输给server的log索引值,针对于某个server,如果leader现存的索引数目大于待传输值,leader就会向该server传输新的logs。server收到logs后验证第一个log的term是否与自己同索引log的term一致,如果不一致告知leader匹配失败,leader会将传输的索引值减一,再重新传送。如果server验证后发现一致,则删除冲突索引后的所有log,并将新收到的log续借在该索引后面。
Paxos和Raft的对比
Paxos算法和Raft算法有显而易见的相同点和不同点。二者的共同点在于,它们本质上都是单主的一致性算法,且都以不存在拜占庭将军问题作为前提条件。二者的不同点在于,Paxos算法相对于Raft,更加理论化,原理上理解比较抽象,仅仅提供了一套理论原型,这导致很多人在工业上实现Paxos时,不得已需要做很多针对性的优化和改进,但是改进完却发现算法整体和Paxos相去甚远,无法从原理上保证新算法的正确性,这一点是Paxos难以工程化的一个很大原因。相比之下Raft描述清晰,作者将算法原型的实现步骤完整地列在论文里,极大地方便了业界的工程师实现该算法,因而能够受到更广泛的应用。同时Paxos日志的传输过程中允许有空洞,而Raft传输的日志却一定是需要有连续性的,这个区别致使它们确认日志传输的过程产生差异。
但其实从根本上来看,Raft的核心思想和Paxos是非常一致的,甚至可以说,Raft是基于Paxos的一种具体化实现和改进,它让一致性算法更容易为人所接受,更容易得到实现。由此亦可见,Paxos在一致性算法中的奠基地位是不可撼动的。
这些算法往往具有很多看似不起眼的细节,然而真正遇到问题时,忽略算法中的任何一个细节都会导致问题无法正确解决。这是因为一致性算法大多每一步都经过严格的推导与证明,整体是一个相当严谨的结构。这一点在阅读Paxos论文时就可见一斑。往往看似简单的方法背后蕴含大量的工作量,其中每一个细节,每一个步骤都需经过仔细考量方能确定,忽略其中任何一个细节都可能导致系统最终崩溃。这样做出的算法才是稳定、高效、实用的。我想,不仅是这一个个精妙的算法需要我们学习,系统研究者们严谨细致的”匠心”更加值得我们去继承。

若有收获,就点个赞吧
0 人点赞
