网络结构
这幅图分为上下两个部分的网络,论文中提到这两部分网络是分别对应两个 GPU,只有到了特定的网络层后才需要两块 GPU 进行交互
网络总共的层数为 8 层,5 层卷积,3 层全连接层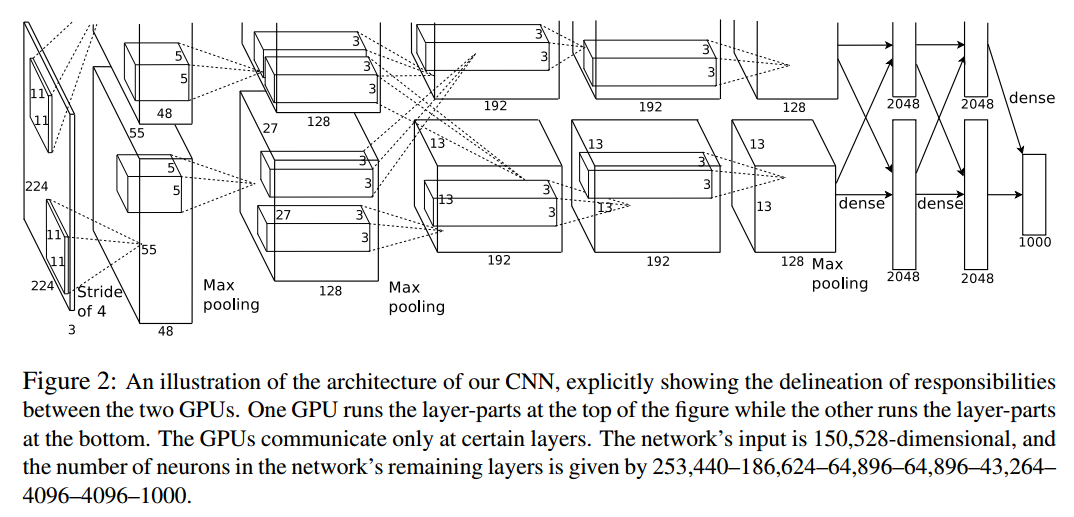
第一层:卷积层 1,输入为 224 × 224 × 3 的图像,卷积核的数量为 96,论文中两片 GPU 分别计算 48 个核; 卷积核的大小为 11 × 11 × 3; stride = 4, stride 表示的是步长,pad = 0, 表示不扩充边缘;
卷积后的图形大小是怎样的呢?
wide = (224 + 2 padding - kernel_size) / stride + 1 = 54
height = (224 + 2 padding - kernel_size) / stride + 1 = 54
dimention = 96
然后进行 (Local Response Normalized), 后面跟着池化 pool_size = (3, 3), stride = 2, pad = 0 最终获得第一层卷积的 feature map
第二层:卷积层 2, 输入为上一层卷积的 feature map, 卷积的个数为 256 个,论文中的两个 GPU 分别有 128 个卷积核。卷积核的大小为:5 × 5 × 48; pad = 2, stride = 1; 然后做 LRN, 最后 max_pooling, pool_size = (3, 3), stride = 2;
第三层:卷积 3, 输入为第二层的输出,卷积核个数为 384, kernel_size =(3 × 3 × 256),padding = 1, 第三层没有做 LRN 和 Pool
第四层:卷积 4, 输入为第三层的输出,卷积核个数为 384, kernel_size = (3 × 3 3), padding = 1, 和第三层一样,没有 LRN 和 Pool
第五层:卷积 5, 输入为第四层的输出,卷积核个数为 256, kernel_size = (3 × 3 3), padding = 1。然后直接进行 max_pooling, pool_size = (3, 3), stride = 2;
第 6,7,8 层是全连接层,每一层的神经元的个数为 4096,最终输出 softmax 为 1000,因为上面介绍过,ImageNet 这个比赛的分类个数为 1000。全连接层中使用了 RELU 和 Dropout。
ReLU Nonlinearity(Rectified Linear Unit)
标准的L-P神经元的输出一般使用tanh 或 sigmoid作为激活函数, 
但是这些饱和的非线性函数在计算梯度的时候都要比非饱和的线性函数f(x) = max(0, x)慢很多,在这里称为 Rectified Linear Units(ReLUs)。在深度学习中使用ReLUs要比等价的tanh快很多。
上图是使用ReLUs和tanh作为激活函数的典型四层网络的在数据集CIFAR-10s实验中,error rate收敛到0.25时的收敛曲线,可以很明显的看到收敛速度的差距。虚线为tanh,实线是ReLUs。
Local Response Normalization(局部响应归一化)
在神经网络中,我们用激活函数将神经元的输出做一个非线性映射,但是tanh和sigmoid这些传统的激活函数的值域都是有范围的,但是ReLU激活函数得到的值域没有一个区间(non-saturating neurons非饱和神经元),所以要对ReLU得到的结果进行归一化。也就是Local Response Normalization。局部响应归一化的方法如下面的公式:
 代表的是ReLU在第i个kernel的(x, y)位置的输出,n表示的是
代表的是ReLU在第i个kernel的(x, y)位置的输出,n表示的是 的邻居个数,N表示该kernel的总数量。
的邻居个数,N表示该kernel的总数量。 表示的是LRN的结果。ReLU输出的结果和它周围一定范围的邻居做一个局部的归一化
表示的是LRN的结果。ReLU输出的结果和它周围一定范围的邻居做一个局部的归一化
每一个矩形表示的一个卷积核生成的feature map。所有的pixel已经经过了ReLU激活函数,现在我们都要对具体的pixel进行局部的归一化。
假设绿色箭头指向的是第i个个kernel对应的map,其余的四个蓝色箭头是它周围的邻居kernel层对应的map,假设矩形中间的绿色的pixel的位置为(x, y),那么我需要提取出来进行局部归一化的数据就是周围邻居kernel对应的map的(x, y)位置的pixel的值。也就是上面式子中的
然后把这些邻居pixel的值平方再加和。乘以一个系数α 再加上一个常数k,然后β 次幂,就是分母,分子就是第i个kernel对应的map的(x, y)位置的pixel值。
Overlapping Pooling(覆盖的池化操作)
一般的池化层因为没有重叠,所以pool_size 和 stride一般是相等的
如果 stride < pool_size, 那么就会产生覆盖的池化操作,这种有点类似于convolutional化的操作,这样可以得到更准确的结果
Reducing Overfitting
Data Augmentation
数据扩充是防止过拟合的最简单的方法,只需要对原始的数据进行合适的变换,就会得到更多有差异的数据集,防止过拟合。
1.image translations and horizontal reflections
Extracting random 224 × 224 patches (and their horizontal reflections) from the
256×256 images and training our network on these extracted patches
2.altering the intensities of the RGB channels in training images
Perform PCA on the set of RGB pixel values, we add multiples of the found principal components, with magnitudes proportional to the corresponding eigenvalues times a random variable drawn from a Gaussian with mean zero and standard deviation 0.1
对RGB像素集进行主成分分析, 对得到的主成分乘以一个倍数(大小与相应的特征值成正比),再乘以一个随机变量(从方差为0,均值为1的Gaussian函数中提取)
Dropout
consists of setting to zero the output of each hidden neuron with probability 0.5
在全连接层中去掉了一些神经节点,达到防止过拟合的目的,
论文在第六层和第七层We use dropout in the first two fully-connected layers设置了Dropout
Details of learning
We trained our models using stochastic gradient descent with a batch size of 128 examples, momentum of 0.9, and weight decay of 0.0005.

若有收获,就点个赞吧
0 人点赞
