python小tips
parse_args()详解:
1-引入模块import argparse
2-建立解析对象parser = argparse.ArgumentParser()
3-增加属性:给xx实例增加一个aa属性 # xx.add_argument(“aa”)parser.add_argument(“echo”)
4-把属性给与args实例: 把parser中设置的所有”add_argument”返回到args子类实例当中, 那么parser中增加的属性内容都会在args实例中,使用即可。args = parser.parse_args()
5-例如打印实例args的echo属性print(args.echo)
6-因为 parse.add_argument() 对于接受的值默认其为str,如果要将之视为int类型,额外加一句 type=int
有了type程序也可以自动过滤掉相关的不符合类型的参数输入。
parser.add_argument("square", help = "To sqaure the number given", type = int)# 4属性给与args实例:add_argument 返回到 args 子类实例args = parser.parse_arg()print(args.square**2)
cv2.copyMakeBorder()
作用:给图片设置边界框(就像一个相框一样的东西),在卷积操作、零填充等也得到了应用,并且可以用于一些数据增广操作
参数:
参数解释:
src : 输入的图片
top, bottom, left, right :相应方向上的边框宽度
borderType:定义要添加边框的类型,它可以是以下的一种:
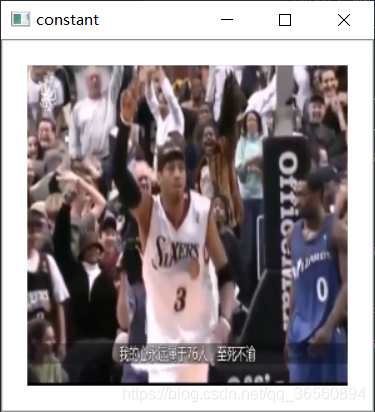
- cv2.BORDER_CONSTANT:添加的边界框像素值为常数(需要额外再给定一个参数)
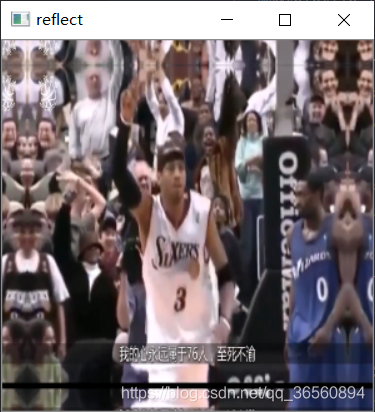
- cv2.BORDER_REFLECT:添加的边框像素将是边界元素的镜面反射,类似于gfedcba|abcdefgh|hgfedcba
- cv2.BORDER_REFLECT_101 or cv2.BORDER_DEFAULT:和上面类似,但是有一些细微的不同,类似于gfedcb|abcdefgh|gfedcba
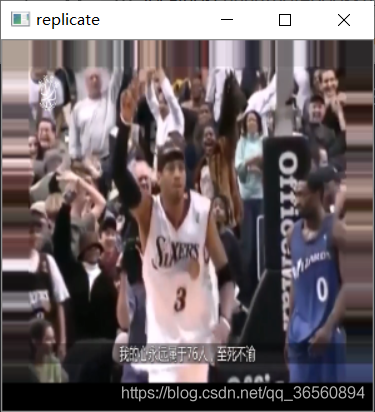
- cv2.BORDER_REPLICATE:使用最边界的像素值代替,类似于aaaaaa|abcdefgh|hhhhhhh
- cv2.BORDER_WRAP:不知道怎么解释,直接看吧,cdefgh|abcdefgh|abcdefg
value:如果borderType为cv2.BORDER_CONSTANT时需要填充的常数值。
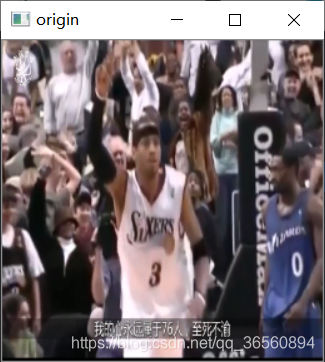
img = cv2.imread('testimg.png')img = cv2.resize(img,(256,256))cv2.imshow('origin',img),cv2.waitKey(0),cv2.destroyAllWindows()replicate = cv2.copyMakeBorder(img,20,20,20,20,cv2.BORDER_REPLICATE)cv2.imshow('replicate',replicate),cv2.waitKey(0),cv2.destroyAllWindows()constant = cv2.copyMakeBorder(img,20,20,20,20,cv2.BORDER_CONSTANT,value=(255,255,255))cv2.imshow('constant',constant),cv2.waitKey(0),cv2.destroyAllWindows()reflect = cv2.copyMakeBorder(img,20,20,20,20,cv2.BORDER_REFLECT)cv2.imshow('reflect',reflect),cv2.waitKey(0),cv2.destroyAllWindows()reflect101 = cv2.copyMakeBorder(img,20,20,20,20,cv2.BORDER_REFLECT_101)cv2.imshow('reflect101',reflect101),cv2.waitKey(0),cv2.destroyAllWindows()wrap = cv2.copyMakeBorder(img,20,20,20,20,cv2.BORDER_WRAP)cv2.imshow('wrap',wrap),cv2.waitKey(0),cv2.destroyAllWindows()

np.random.RandomState()
局部随机种子(在不同机器上运行的结果是一样的),用于生成伪随机数
import numpy as np
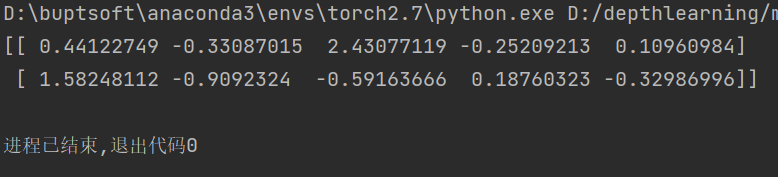
rnd = np.random.RandomState(5)
res = rnd.randn(2, 5) #“2”和“5”代表维数,生成一个2*5的随机矩阵
print(res)
result:
对生成的随机数组进行打乱【通过字符串密码str_key对np.array格式的res进行打乱】np.random.RandomState(str_key).shuffle(res)
copy.copy(list)与copy.deepcopy(list)
copy.copy(list)称作浅复制,在新的数组中对高于一维内的数据进行处理时,会对原数组中的元素也进行改变
copy.deepcopy(list)称作深复制,在新的数组中对高于一维内的数据进行处理时,原数组中的元素不会改变
深复制: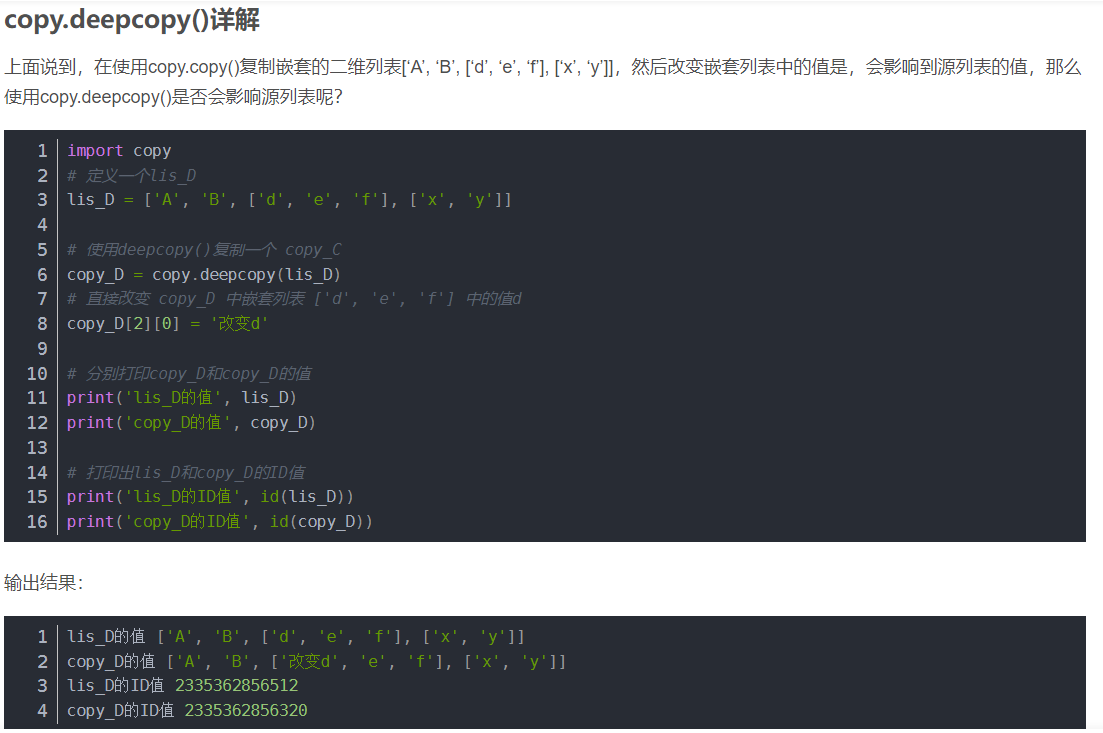
浅复制: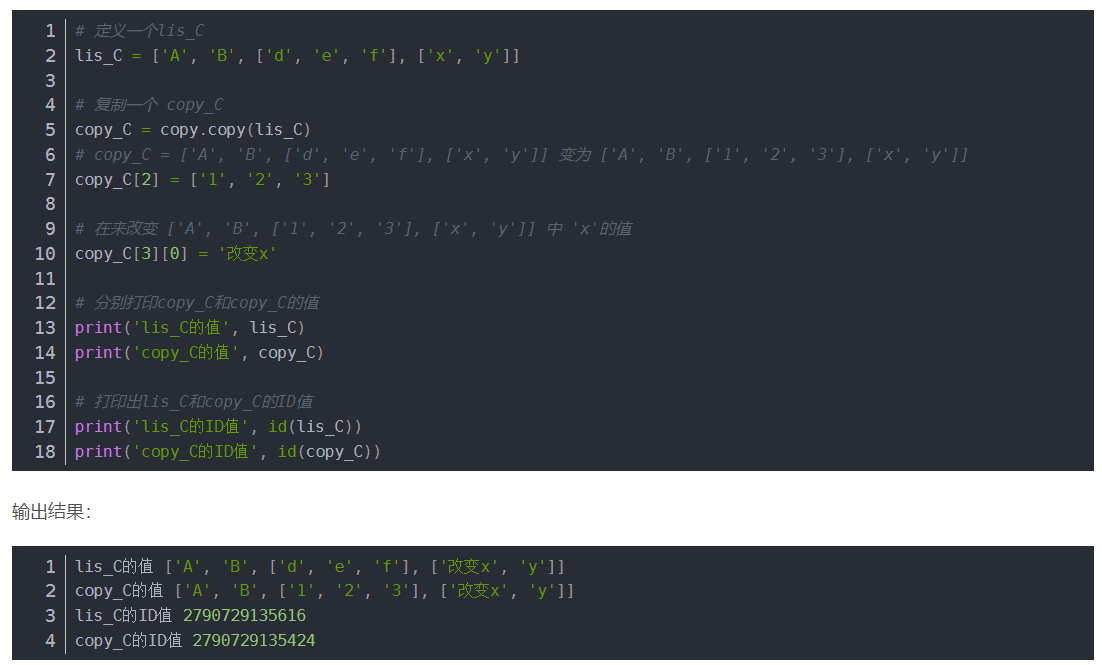
基于多核CPU的python文件运行
问题说明:通常现有的计算机都包含多个 CPU 内核,然而,现实中运行程序时,通常仅用到单核 CPU,导致 CPU资源无法充分利用。因此,我们可以通过多核 CPU 并行计算来加快程序的运行。
由于python解释器中一种互斥锁的设计,执行CPU密集型任务时,对于同一进程中的线程,并不能实现多核CPU一起操作不同的线程,所以需要将一个进程转换为多个进程,提高CPU的利用率
方法1:如果程序是关于numpy的相关线性代数运算,可以参考该方法,可以在不修改源代码的基础上实现多核CPU的并行计算
方法2:如果是重复性高的数据预处理工作,则可以对原程序进行修改,在同一个服务器上使用不同的CPU进行运算,可以实现”物理“上的多核CPU并行,如下图同时运行不同的.py文件处理不同的dataset的方法: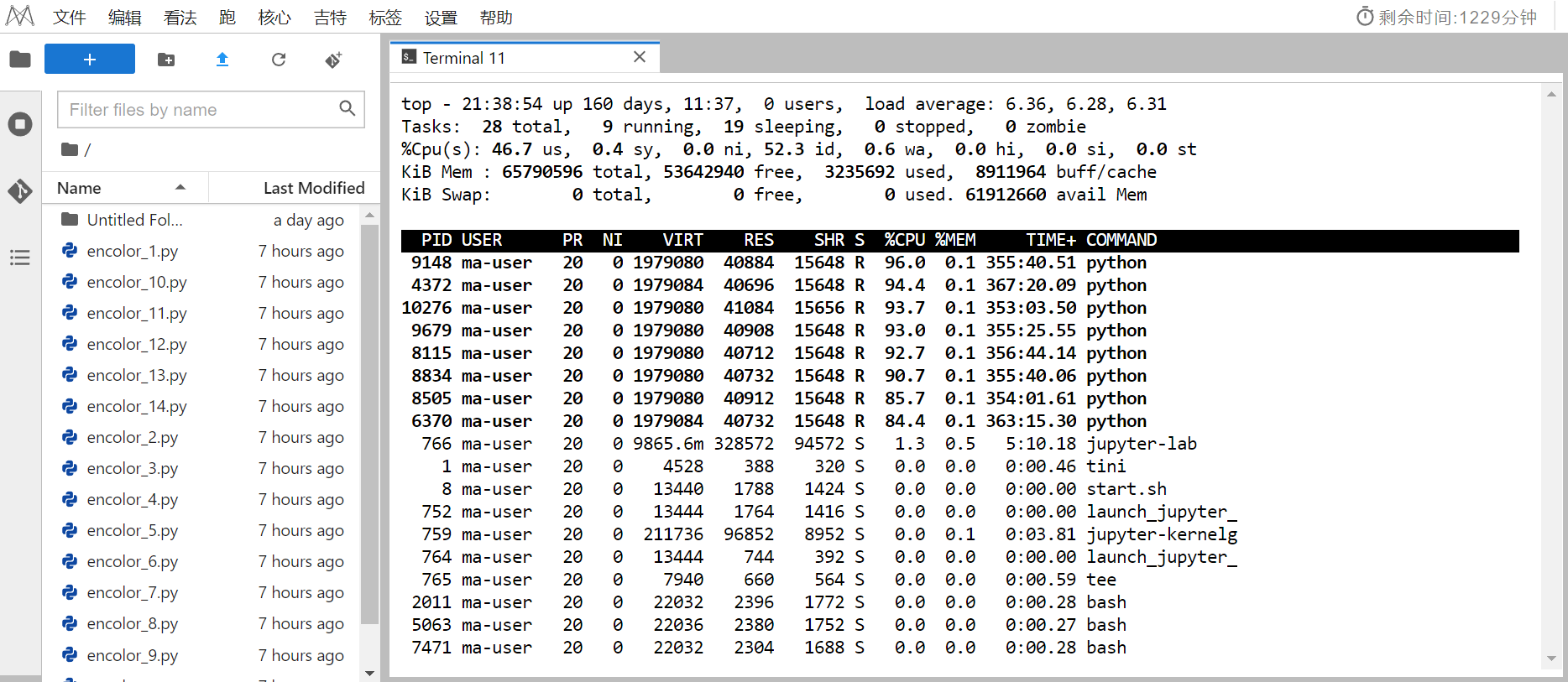
方法3:参考链接(还未实践)
在华为云modelarts中使用notebook创建环境(tips)
- 在配置时需要设置镜像,【镜像的服务器类型可以选择CPU或者GPU,单核or多核】
- 需要注意notebook创建时候的地区选择,部分地区可能没有GPU服务器,如下图所示,为北京一区的服务器情况,并没有GPU服务器配置:
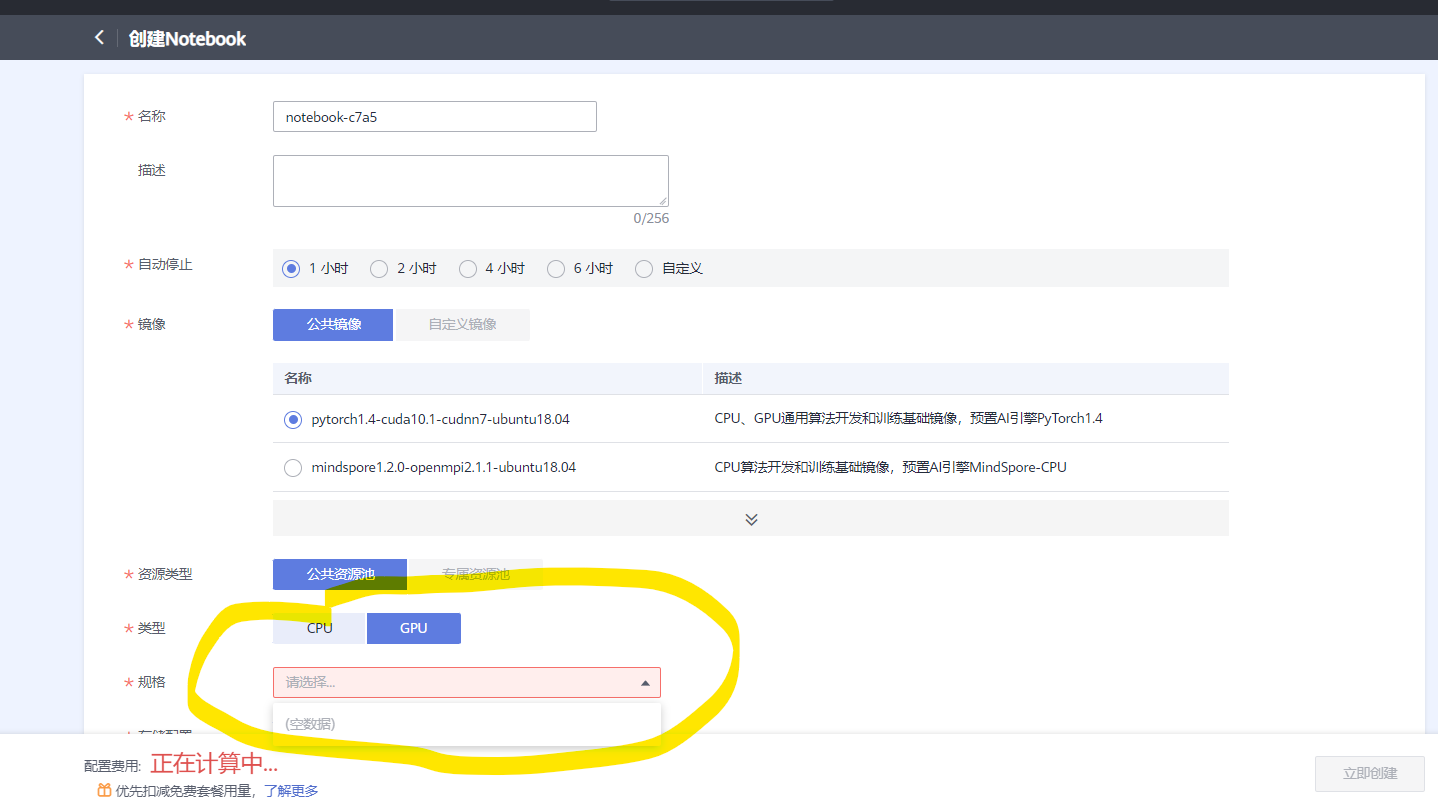
- notebook中可以通过github链接、本地文件上传(文件夹只支持压缩文件的格式)、远端URL文件、OBS文件(通过OBS地址)导入文件
- notebook中可以调用终端(terminal),完成环境的配置,通过pip等命令
- notebook中也可以创建.ypinb文件,完成对整个工程的操作,其优点是可以分块对工程进行相关包的导入、相关文件的运行
- 在.ypinb文件的运行过程中要注意文件目录的正确使用,使用
**print(os.getcwd())**语句可以查看当前文件的工作目录,如下:
- 在.ypinb文件的运行过程中要注意文件目录的正确使用,使用
报错找不到文件main_0bit.py,可以通过print(os.getcwd())进行排错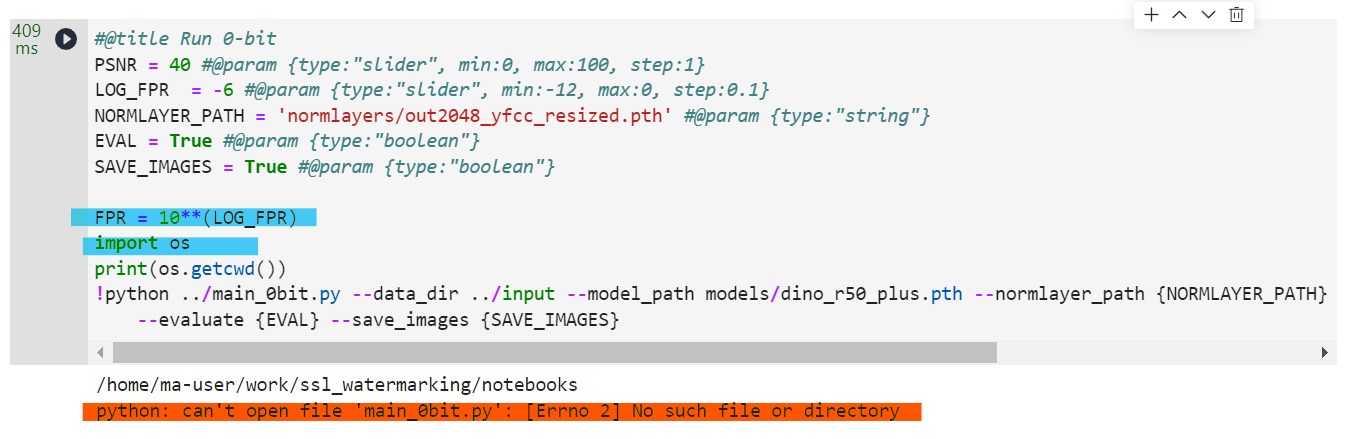
- notebook中的工程也可以引用到本地,但是在创建的时候需要选中支持远程ssh开发

- notebook中支持【增添数据存储】,可以将OBS中的并行文件系统数据挂载在服务器的本地,但是服务器本地路径只能选择 “data/子目录名称”
- 在关闭notebook之前可以通过保存镜像,实现对工程环境的保存
通过切片访问字符串中部分字符
示例:[start:stop:step]
start :需要获取的字符串的开始位置,默认为 0 。(通常可以不写)
stop :需要获取的字符串的结束位置 的后一个位置。
step :步长,默认为 1 、当 start 大于 stop 时,step 为负数。
# 使用[start:stop:step]切片操作获取字符串
strs = "ABCDEFG"
print(strs[:4])
# ABCD
print(strs[:4:2])
# AC
print(strs[2:6])
# CDEF
print(strs[2:6:2])
# CE
python中的文件移动与创建
其中介绍了一种可以常用的程序进度表示方法:
:::info
for idx, path_img in enumerate(imgs): #enumerate(imgs)会获取imgs列表中的元素序号及元素
print(“{}/{}”.format(idx + 1, len(imgs)))
:::
def my_mkdir(my_dir):
if not os.path.isdir(my_dir):
os.makedirs(my_dir)
def move_img(imgs, roor_dir, setname): #其中,imgs是待移动的图像的路径,具体到了每一张图像
data_dir = os.path.join(root_dir, setname)
my_mkdir(data_dir) #如果没有新的要存入图像的文件夹,就新建一个文件夹
for idx, path_img in enumerate(imgs):
print("{}/{}".format(idx + 1, len(imgs))) #可以在很多地方复用的进度表示写法
shutil.copy(path_img, data_dir) #shutil.copy()函数实现path_img存入data_dir
print("{} datasets,copy {} images to {}".format(setname, len(imgs), data_dir))
python中遍历文件夹下的所有文件
files = os.listdir(single_face_path) #files是列表类型,里面存储文件夹下的所有文件(夹)名称
关于图像的读取问题
图像被读取之后,一般都要基于numpy库中的np.array数据类型进行处理;
现在的图像读取可以通过以下几种常见法进行,
- 通过cv2库实现
【cv2读取文件的默认方式是BGR通道】
import cv2
img_bgr = cv2.imread("screen.png")
img_rgb=cv2.cvtColor(img_bgr, cv2.COLOR_BGR2RGB)
wide = img_rgb.shape[0]
height = img_rgb.shape[1]
type=img_rgb.shape[2] #返回图像的通道数,如果是4,则说明是RGBA的形式,有透明度属性
cv2.imshow("a name",img_rgb)
cv2.imwrite("图片路径", img_rgb )
- 通过PIL库实现【推荐,因为其中不涉及图像通道的转换,不会出现玄学问题,已实证】
from PIL import Image
img = Image.open(temp_path)
img_arr = np.asarray(img)
im = Image.fromarray(screen)
im.save("watermark" + watermark_ori + check_str_binary+"_black.png")
对图像的像素点遍历方法
- 通过图像的高度和宽度进行双层循环遍历
在每处使用img_arr[x, y].all()==np.array[(255, 255, 255)].all()判断像素点的颜色值属性
for y in range(height):
for x in range(wide):
if img[y, x].all() == np.array([0, 0, 0]).all():
img[y, x] = (255, 255, 255)
- 通过对图像对应的array数据类型中的元素进行遍历,单个比较每个通道的RGB值【推荐,已实证】
for i in img_arr: for j in i: if (j[0] == 255 and j[1] == 255 and j[2] == 255): # 满足条件进行像素值更换 j[0] = 0 j[1] = 255 j[2] = 25
spade中的图像处理流程
数据集构成
CelebA-HQ-img
CelebAMask-HQ-mask-anno
一共分成了15组,每一组中有2000张人脸图片对应的分割图像集
每个人脸的分割图像集由10-15个单个元素图像组成,每个图象都是二值图,有效元素部分是白色,其余部分是黑色
1、遍历每张图片元素图像,对有效元素部分进行染色
2、将每个人的10-15个元素图片叠加在一起,就可以构成一张人脸图片
主要函数
image_processing
image_processing(self, filename, segmap):
x = tf.read_file(filename)
segmap_x = tf.read_file(segmap)
......
return img, segmap_img, segmap_onehot

若有收获,就点个赞吧
0 人点赞
