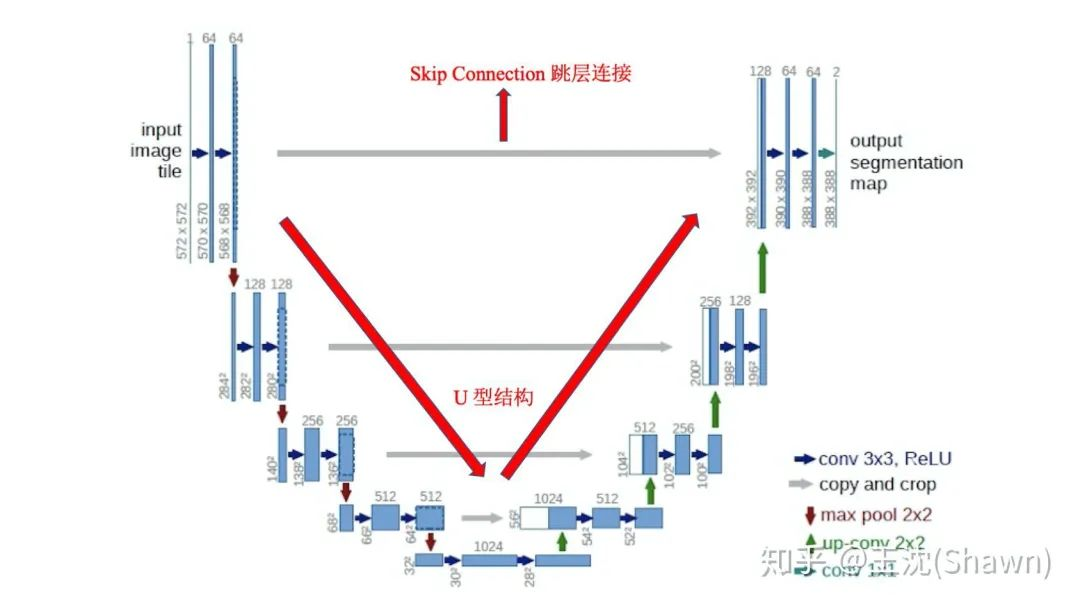
<br />UNet的encoder下采样4次,一共下采样16倍,对称地,其decoder也相应上采样4次,将encoder得到的高级语义特征图恢复到原图片的分辨率。<br />相比于FCN和Deeplab等,UNet共进行了4次上采样,并在同一个stage使用了skip connection,而不是直接在高级语义特征上进行监督和loss反传,这样就保证了最后恢复出来的特征图融合了更多的low-level的feature,也使得不同scale的feature得到了的融合,从而可以进行多尺度预测和DeepSupervision。4次上采样也使得分割图恢复边缘等信息更加精细。
对于医学影像
- 相比于FCN和Deeplab等,UNet共进行了4次上采样,并在同一个stage使用了skip connection,而不是直接在高级语义特征上进行监督和loss反传,这样就保证了最后恢复出来的特征图融合了更多的low-level的feature,也使得不同scale的feature得到了的融合,从而可以进行多尺度预测和DeepSupervision。4次上采样也使得分割图恢复边缘等信息更加精细。
- 数据量少。医学影像的数据获取相对难一些,很多比赛只提供不到100例数据。所以我们设计的模型不宜多大,参数过多,很容易导致过拟合。原始UNet的参数量在28M左右(上采样带转置卷积的UNet参数量在31M左右),而如果把channel数成倍缩小,模型可以更小。缩小两倍后,UNet参数量在7.75M。缩小四倍,可以把模型参数量缩小至2M以内,非常轻量。个人尝试过使用Deeplab v3+和DRN等自然图像语义分割的SOTA网络在自己的项目上,发现效果和UNet差不多,但是参数量会大很多。
多模态。相比自然影像,医疗影像比较有趣和不同的一点是,医疗影像是具有多种模态的。以ISLES脑梗竞赛为例,其官方提供了CBF,MTT,CBV,TMAX,CTP等多种模态的数据。
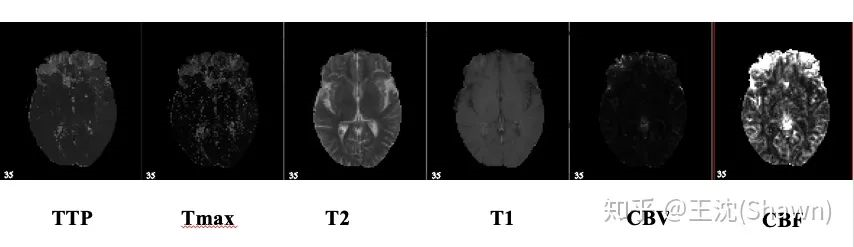可解释性重要。由于医疗影像最终是辅助医生的临床诊断,所以网络告诉医生一个3D的CT有没有病是远远不够的,医生还要进一步的想知道,病灶在哪一层,在哪一层的哪个位置,分割出来了吗,能求体积嘛?同时对于网络给出的分类和分割等结果,医生还想知道为什么,所以一些神经网络可解释性的trick就有用处了,比较常用的就是画activation map。看网络的哪些区域被激活了

若有收获,就点个赞吧
0 人点赞
