一、Sequential的使用

Tips:实际Flatten和Fully connented ,Fully connented 和output层之间是全连接层
导包
import torchfrom torch import nnfrom torch.nn import Conv2d, MaxPool2d,Flatten, Linearfrom tensorboardX import SummaryWriter
定义网络 ```python class Classify(nn.Module): def init(self):
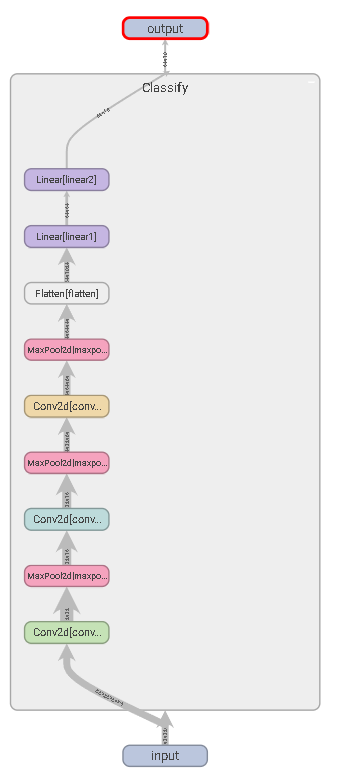
super().__init__()"""# 使用普通方式self.conv1 = Conv2d(3, 32, 5, padding=2, stride=1)self.maxpool1 = MaxPool2d(2)self.conv2 = Conv2d(32,32,5, padding=2, stride=1)self.maxpool2 = MaxPool2d(2)self.conv3 = Conv2d(32, 64, 5, padding=2 ,stride=1)self.maxpool3 = MaxPool2d(2)self.flatten = Flatten()self.linear1 = Linear(1024,64)self.linear2 = Linear(64,10)"""self.model1 = nn.Sequential(Conv2d(3, 32, 5, padding=2, stride=1),MaxPool2d(2),Conv2d(32,32,5, padding=2, stride=1),MaxPool2d(2),Conv2d(32, 64, 5, padding=2 ,stride=1),MaxPool2d(2),Flatten(),Linear(1024,64),Linear(64,10))
def forward(self,x):"""x = self.conv1(x)x = self.maxpool1(x)x = self.conv2(x)x = self.maxpool2(x)x = self.conv3(x)x = self.maxpool3(x)x = self.flatten(x)x = self.flatten(x)x = self.linear1(x)x = self.linear2(x)"""x = self.model1(x)return x
3. 运行```pythonwriter = SummaryWriter("logs")model = Classify()input = torch.ones((64,3,32,32))output = model(x)writer.add_graph(model, input)writer.close()
二、优化器和损失函数
# 定义数据集和数据加载器dataset = torchvision.datasets.CIFAR10("./dataset", train = False, transform = torchvision.transforms.ToTensor(), download = False)dataloader = DataLoader(dataset,batch_size = 32)
# 构造模型model = Classify()#----------------------------------## 构造优化器(随机梯度下降)# model.parameters() 为网络的参数# lr为学习率#----------------------------------#optim = torch.optim.SGD(model.parameters(), lr=0.01)# 计算交叉熵损失loss = nn.CrossEntropyLoss()writer = SummaryWriter("logs")# 20个epochfor epoch in range(20):# runing_loss为本次epoch中所有损失的和runing_loss = 0.0for idx,data in enumerate(dataloader):imgs ,targets = dataoutputs = model(imgs)# 计算本次batch的损失result_loss = loss(outputs, targets)# 求和runing_loss = runing_loss + result_loss#-------------------## zero_grad():清空所管理参数的梯度。# 由于 PyTorch 的特性是张量的梯度不自动清零,因此每次反向传播之后都需要清空梯度# optim为定义的随机梯度下降优化器#-------------------#optim.zero_grad()# 反向传播(为batch,不是epoch)result_loss.backward()# 执行一步梯度更新optim.step()print(runing_loss)writer.close()

若有收获,就点个赞吧
0 人点赞
