1. 集合基础
集合、数组都是对多个数据进行存储操作的结构,简称 Java 容器。但是数组存储有很多弊端:
- 一旦初始化以后,长度就不可修改。
- 数组中提供的方法非常有限,对于添加、删除、插入数据等操作,非常不便,同时效率不高。
- 获取数组中实际元素的个数的需求,数组没有现成的属性或方法可用。
- 数组存储数据的特点:序、可重复。对于无序、不可重复的需求,不能满足。
因此,才引用了 集合 这一概念,集合存在的意义,就是解决数组所有的弊端。
一方面面向对象语言对事物的体现都是以对象的形式,即万物皆类,为了方便对多个对象的操作,就要对对象进行存储(存储对象)。另一方面,使用 Array 存储对象方面具有一些弊端,而Java集合就像一种容器,可以有效解决这些弊端,来 动态地 把多个对象的引用放入容器中。
Java集合类可以用于存储数量不等的多个对象,还可以用于保存具有映射关系的关联数组
2. 集合框架概述
Java 集合可分为 Collection 和 Map 两种体系:
- Collection 接口:单列数据,定义了存取一组对象的方法的集合
- List 接口:元素有序、可重复的集合 ==> “动态数组”
- 实现类:ArrayList、LinkedList、Vector
- Set 接口:元素无需、不可重复的集合 ==> 也即数学中的“集合”
- 实现类:HashSet、LinkedHashSet、TreeSet
- List 接口:元素有序、可重复的集合 ==> “动态数组”
- Map 接口:双列数据,保存具有映射关系“key - value”键值对的集合。 ==> y=f(x)
- 实现类:HashMap、LinkedHashMap、TreeMap、Hashtable、Properties
3. Collection 接口
先声明一个 Collention 实现类的对象:
public class CollectionTest {
public static void main(String[] args) {
Collection coll = new ArrayList();
}
}
3.1 add
可以通过 add 方法向 coll 里添加任意类的对象
public class CollectionTest {
public static void main(String[] args) {
Collection coll = new ArrayList();
// add(Object e)
coll.add("AA");
coll.add(123) ; // 自动装箱,Integer
coll.add(new Object()) ;
}
}
3.2 size
3.3 addAll
通过 addAll 将一个集合的所有元素都加入到另一个集合中
public class CollectionTest {
public static void main(String[] args) {
Collection coll = new ArrayList();
coll.add("AA");
coll.add(123) ;
coll.add(new Object()) ;
Collection coll2 = new ArrayList();
coll2.addAll(coll);
System.out.println(coll2.size());
}
}

3.4 isEmpty
isEmpty用来判断集合是否为空,注意,此空指的是元素个数为0,而不是 null。即,当 size 返回0时,isEmpty 将返回 true。
public class CollectionTest {
public static void main(String[] args) {
Collection coll = new ArrayList();
coll.add("AA");
coll.add(123) ;
coll.add(new Object()) ;
System.out.println(coll.isEmpty());
}
}

3.5 clear
clear 能够将集合的元素全部清空,注意,清空不是赋null,它只是把元素全给丢了而已,和null是有差别的。看下一段代码:
public class CollectionTest {
public static void main(String[] args) {
Collection coll = new ArrayList();
coll.add("AA");
coll.add(123) ;
coll.add(new Object()) ;
coll.clear();
System.out.println(coll.isEmpty());
System.out.println(coll);
}
}
第一个sout输出 true,第二个sout输出 [],说明只是将集合元素清空了,并不是赋值 null。<br />
3.6 contains
contains(Object obj) 用来判断一个集合是否包含对象obj,注意是对象而不是类!这个是否包含的判断规则与 equals 是一样的,即引用型比较(除了String和包装类)。来看下面代码:
public class CollectionTest {
public static void main(String[] args) {
Collection coll = new ArrayList();
coll.add("AA");
coll.add(123) ;
coll.add(new Person("ZhangSan",20)) ;
Person p1 = new Person("Lisi",20);
coll.add(p1);
System.out.println(coll.contains(new Person("ZhangSan",20)));
System.out.println(coll.contains(p1));
System.out.println(coll.contains("AA"));
System.out.println(coll.contains(new String("AA")));
System.out.println(coll.contains(123)); // 自动装箱
System.out.println(coll.contains(new Double(12.3)));
}
}
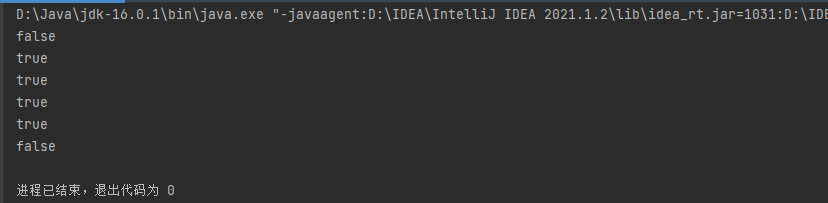
首先看第一个 contains,因为每一个 new Person(“ZhangSan”,20) 虽然内容一致,但是在堆空间中都是一片独立的对象(引用型比较),所以 coll 中并部包含,返回 false ;反观第二个,直接看是否包含 p1,显然是包含的,返回 true ; 第三个和第四个,由于 String 型重写了 equals 方法,比较的实际为内容(值比较),因此都包含在coll中,都返回 true ;第五个,自动装箱的缘故,123被转化为 new Integer(123),cotain 返回 true ;第六个,显然不包含 Double,返回 false。
现在,我们重写 Person 类中的 equals 方法,然后再来进行第一条 cotains 判断:
@Override
public boolean equals(Object o) {
if (this == o) return true;
if (o == null || getClass() != o.getClass()) return false;
Person person = (Person) o;
return age == person.age && Objects.equals(name, person.name);
}
@Override
public int hashCode() {
return Objects.hash(name, age);
}
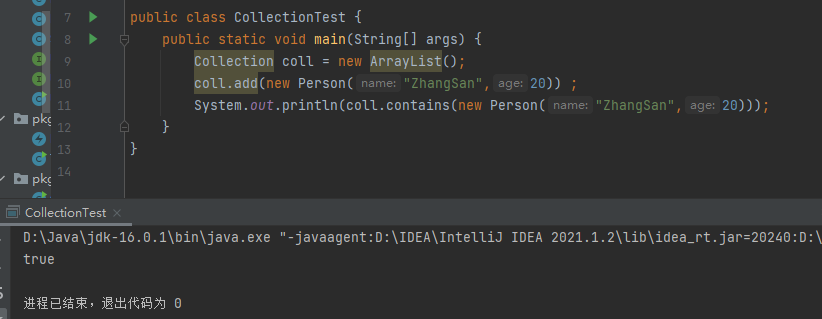
可以看到返回 true,说明 cotains 的判断规则是 obj 对象所在类的 equals 方法。并且一般而言,向Collection 接口的实现类的对象中添加元素时,要求 obj 对象所在类要重写 equals 方法。
3.7 remove
通过 remove(Object obj) 来删除集合中的 obj 对象,如果删除成功则返回 true,删除失败(集合中不存在该对象)则返回 false。其判断标注也是 obj 中的 equals 方法:
public class CollectionTest {
public static void main(String[] args) {
Collection coll = new ArrayList();
coll.add(new Person("ZhangSan",20)) ;
System.out.println(coll.size());
System.out.println(coll.remove(new Person("ZhangSan",20)));
System.out.println(coll.size());
}
}

3.8 removeAll
removeAll(Collection coll2) 将从 coll 中移除 coll2 中的所有元素(与coll的交集),移除成功返回 true,移除失败返回 false,比较规则也是 equals。
public class CollectionTest {
public static void main(String[] args) {
Collection coll = new ArrayList();
coll.add(new Person("ZhangSan",20)) ;
coll.add(123) ;
Collection coll2 = new ArrayList();
coll2.add(new Person("ZhangSan",20)) ;
coll2.add("abc") ;
System.out.println(coll.size());
System.out.println(coll.removeAll(coll2));
System.out.println(coll.size());
}
}

4. Iterator 迭代器接口
集合元素的遍历操作,就会使用迭代器接口 Iterator 接口。迭代器将提供一种方法,该方法能访问一个容器对象中各个元素,而又不需暴露该对象的内部细节。迭代器模式,就是为容器而生的。
- Collection 接口继承了 java.lang.Iterable 接口,该接口有一个 iterator() 方法,那么所有实现了 Collection 接口的集合类都有一个 iterator() 方法,用以返回一个 Iterator 实现类的对象。
- Iterator 仅用于遍历集合,Iterator 本身并不提供承装对象的能力。如果需要创建 Iterator 对象,则必须有一个被迭代的集合对象
- 集合对象每次调用 iterator() 方法都得到一个全新的迭代器对象,默认游标都在集合的第一个元素之前。
看个使用列子
package pkg12;
import java.util.*;
public class CollectionTest {
public static void main(String[] args) {
Collection coll = new ArrayList();
coll.add(123) ;
coll.add("abc") ;
coll.add(new Person("ZhangSan",20)) ;
coll.add(new Person("LiSi",18)) ;
Iterator iterator = coll.iterator() ; // 生成迭代器
System.out.println(iterator.next());
System.out.println(iterator.next());
System.out.println(iterator.next());
System.out.println(iterator.next());
}
}
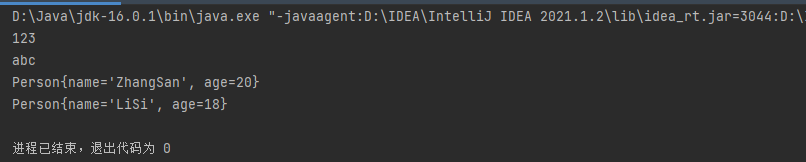
如果迭代器迭代的次数大于集合中的元素个数,就会报异常: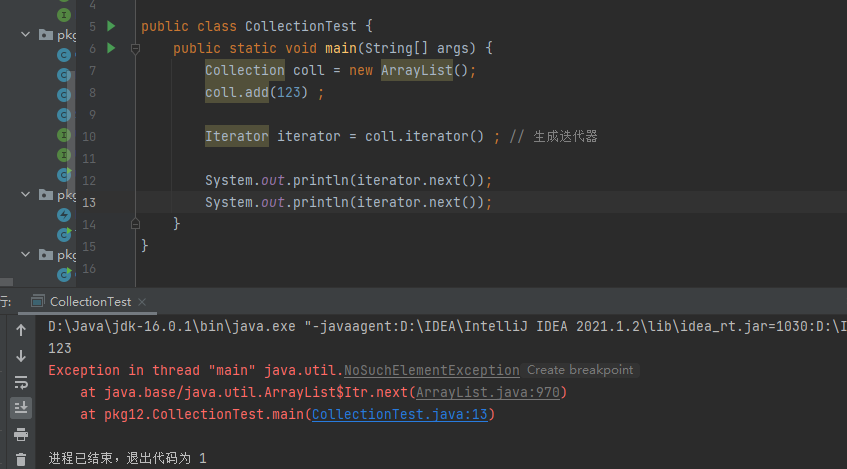
当然,像上面那样一直 sout 看上去会很傻,因此迭代器可以配合 for循环 和 size 方法进行。
public class CollectionTest {
public static void main(String[] args) {
Collection coll = new ArrayList();
coll.add(123) ;
coll.add("abc") ;
coll.add(new Person("ZhangSan",20)) ;
coll.add(new Person("LiSi",18)) ;
Iterator iterator = coll.iterator() ; // 生成迭代器
for (int i = 0;i < coll.size(); i++){
System.out.println(iterator.next());
}
}
}
然而开发中也不会那样写,而是调用了迭代器中的 hasNext() 方法。该方法将判断迭代器后面还有没有元素,如果有则返回 true,反之返回 false,其与 while 循环相配合即可实现集合的遍历:
Iterator iterator = coll.iterator() ; // 生成迭代器
while (iterator.hasNext()){
System.out.println(iterator.next());
}
另外,迭代器可以直接影响集合中的元素,它可以通过 iterator.remove() 方法来删除集合中的元素,注意,不是删除迭代器中元素,而是直接删除了集合中的元素!
public class CollectionTest {
public static void main(String[] args) {
Collection coll = new ArrayList();
coll.add(123) ;
coll.add("abc") ;
coll.add(new Person("ZhangSan",20)) ;
coll.add(new Person("LiSi",18)) ;
System.out.println(coll.size());
Iterator iterator = coll.iterator() ; // 生成迭代器
while (iterator.hasNext()){
if (iterator.next().equals("abc"))
iterator.remove(); // 删除当前元素
}
System.out.println(coll.size());
}
}

5. foreach
JDK5.0 新增了foreach循环,用于更方便的遍历 集合 和 数组。格式如下
// 遍历集合
for(Object obj : 集合对象){
// ...
}
// 遍历数组
for(元素类型 obj : 数组){
// ...
}
改遍历方式方便之处在于,我们调用时根本不需要迭代器。
import java.util.*;
public class CollectionTest {
public static void main(String[] args) {
Collection coll = new ArrayList();
coll.add(123) ;
coll.add("abc") ;
coll.add(new Person("ZhangSan",20)) ;
coll.add(new Person("LiSi",18)) ;
for (Object obj : coll){
System.out.println(obj);
}
}
}
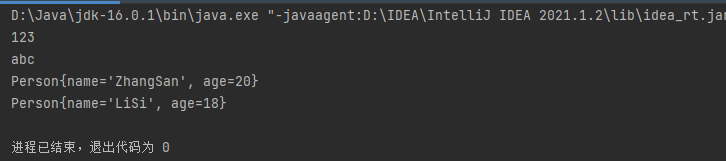
虽然,调用 foreach 循环时没有用到迭代器,但是改循环的内部是用来迭代器的,也就是说,foreach本质上还是借用了迭代器,只不过内部帮忙实现了而已。
6. List 接口
List集合类中 元素有序、可重复,集合中的每个元素都有其对应的顺序索引。List容器中的元素都对应一个整数型的序号记载其在容器中的位置,可以根据序号存取容器中的元素。
List 接口的实现类常用有:ArrayList、LinkedList 和 Vector。 ArrayList 是List的最主要实现类,其余两个用的不多,Vector更不用说,JDK1.0的东西,现在基本不用了。可以用数据结构的思想来理解 ArrayList 和 LinkedList的区别:
- ArrayList :底层使用 Object[] elementData 存储,如其名一样,内存中是一段无限但连续的数组。
LinkedList:底层使用双向链表,对于频繁的插入、删除操作,使用此类效率比 ArrayList 高。
6.1 ArrayList 实现类
ArrayList 的使用和前文 Collection 中的方法几乎是一致的。
public class CollectionTest { public static void main(String[] args) { ArrayList list = new ArrayList(); list.add(123) ; list.add(123) ; // List 是可重复元素的 list.add("abc") ; list.add(new Person("ZhangSan",20)) ; list.add(new Person("LiSi",18)) ; for (Object obj : list){ System.out.println(obj); } } }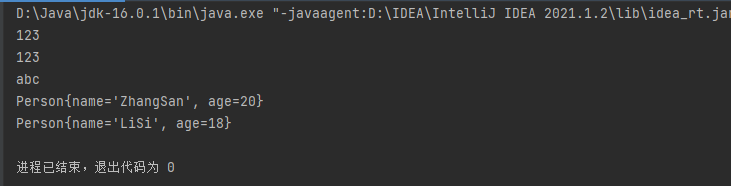
Collection接口中的所有方法 ArrayList 都能用,同时 ArryList 还有自己独有的方法,比如 双参数的 add 和 addAll(重载)
其中 add(int index,Object element) 将在集合的 index 位前插入一个元素(从0开始)public class CollectionTest { public static void main(String[] args) { ArrayList list = new ArrayList(); list.add(123) ; list.add("abc") ; list.add(new Person("ZhangSan",20)) ; for (Object obj : list){ System.out.println(obj); } System.out.println("***************"); list.add(0,new Person("NewOne",12)); for (Object obj : list){ System.out.println(obj); } } }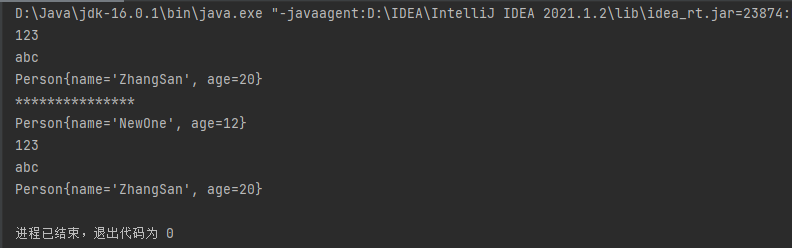
addAll 用来在 index 位前插入一个 Collection(或子接口)的实现类的对象。public class CollectionTest { public static void main(String[] args) { ArrayList list = new ArrayList(); ArrayList list1 = new ArrayList(); // 也可也写为 Collection list1 = new ArrayList(); list1.add("list1"); list.add(123) ; list.add("abc") ; list.add(new Person("ZhangSan",20)) ; for (Object obj : list){ System.out.println(obj); } System.out.println("\n***************\n"); list.addAll(0,list1) ; for (Object obj : list){ System.out.println(obj); } } }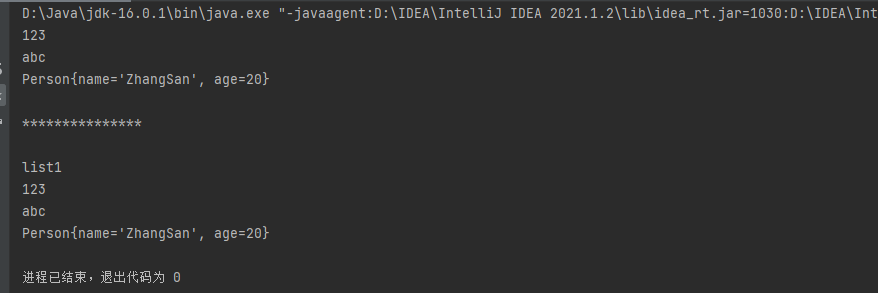
这里要提一个方法:Arrays.asList(1,2,3) ; 它将返回一个元素为1,2,3的 List 的实现类对象,其源码为: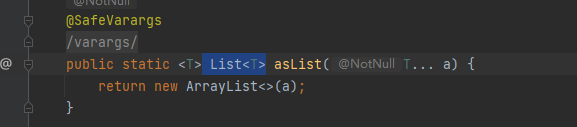
用它来测试 addAll:public class CollectionTest { public static void main(String[] args) { ArrayList list = new ArrayList(); List list2 = Arrays.asList(1,2,3) ; list.add(123) ; list.add("abc") ; list.add(new Person("ZhangSan",20)) ; for (Object obj : list){ System.out.println(obj); } System.out.println("\n***************\n"); list.addAll(0,list2) ; for (Object obj : list){ System.out.println(obj); } } }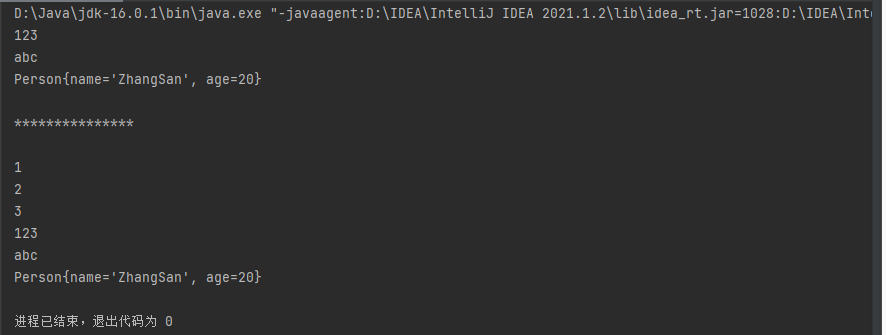
ArrayList 还可以通过 indexOf 方法来返回 obj 在集合中首次出现的位置。如果不存在,则返回 -1 。public class CollectionTest { public static void main(String[] args) { ArrayList list = new ArrayList(); list.add(123) ; list.add("abc") ; list.add(new Person("ZhangSan",20)) ; System.out.println(list.indexOf(new Person("ZhangSan",20))); System.out.println(list.indexOf(321)); } }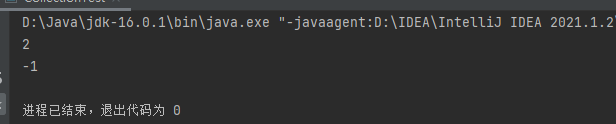
与其对应的,还有个 lastIndexOf 方法,返回 obj 在集合中最后一次出现的位置,用法同 indexOf。
ArrayList 还重载了 remove 方法,使其能够删除对应 index 处的元素,然后后面元素向前移动一位,并且返回删除的元素。重载的 remove 方法源码为:E remove(int index);还有一个常用的方法:set(int index, E element)
public E set(int index, E element) { Objects.checkIndex(index, size); E oldValue = elementData(index); elementData[index] = element; return oldValue; }
【总结常用方法】
- 增:两个 add,两个 addAll
- 删:两个 remove
- 改: set(int index, Object obj)
- 查: get(int index)
- 长度: size()
- 遍历:
7. Set 接口
Set 集合类中 元素无序、不可重复。就是数学上的“集合”,有三个实现类
- HashSet:是 Set 接口的主要实现类,线程不安全,可以存储 null 值
- LinkedHashSet:是 HashSet 的子类,在 HashSet 的基础上添加了前后指针;
- TreeSet:二叉树结构的,可以按照添加对象的指定属性进行排序。
【无序性】:
以 HashSet 为例。无序性不等于随机性。HashSet 的底层仍然是数组,但存储的数据在底层数组中并非按照数组索引的顺序添加的,而是根据数据的 hash值 决定的。所谓无序,不是指输出顺序的无序,而是指存放位置的无序。
public class CollectionTest {
public static void main(String[] args) {
Set set = new HashSet();
set.add(123) ;
set.add("abc") ;
set.add(new Person("ZhangSan",20)) ;
for (Object obj : set){
System.out.println(obj);
}
}
}
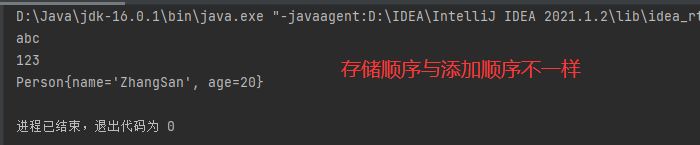
【不可重复性】
是否重复的比较标准是 equals,但不仅仅是 equals,还涉及到了 hashCode。
public class CollectionTest {
public static void main(String[] args) {
Set set = new HashSet();
set.add(123) ;
set.add("abc") ;
set.add(new Person("ZhangSan",20)) ; // Person已重写equals和hashCode
set.add(new Person("ZhangSan",20)) ;
set.add(new Person("ZhangSan",20)) ;
for (Object obj : set){
System.out.println(obj);
}
}
}

7.1 HashSet
至于 HashSet 为什么需要用到 hashCode 方法,这就涉及到 Set 集合底层的存储逻辑了。当 Set 想要存储一个对象时,它会先算出该对象的 hash 值,用的就是 hashCode 方法,这个 hash 值是不存在碰撞的,也即一个对象唯一对应一个 hash,反之亦然。那么底层就将对象的 hash 作为该对象的唯一标识。
然后,再根据对象的 hash 值来决定该对象存放在哪里,这就涉及到数据结构的算法。Set 底层的排列算法是很复杂的,只需要直到,它通过对象的 hash 值来唯一标识对象,再通过 hash 来算出它的位置。也正因如此,Set 才会表现出无序性。所谓无序,是指存放位置的无序!
那么到底怎么来比较两个对象是否相同呢?Set 认为两对象相同的话要满足两个条件:hash值相同、equals满足。因此,两个对象首先要满足hash相同,然后才有比较 equals 的意义。这也正是为什么,在我们重写 equals 的同时基本都要顺手重写了 hashCode 方法
如果二者任意一个没有被重写,Set 就会认为该类的众多对象都是 不同的,因此都会存放进去。比如这里,我们只重写了 equals 方法,而没有重写 hashCode 方法,就导致了 Set 的不可重复性无法体现: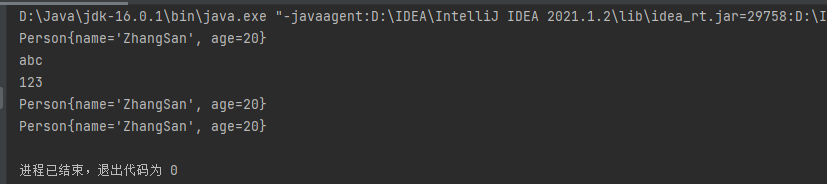
7.2 LinkedHashSet
LinkedHashSet 是 HashSet 的子类,本质上就是把 HashSet 的各元素之间加了前后指针。LinkedHashSet 仍然具有无序性,但是它的输出是有序的。
public class CollectionTest {
public static void main(String[] args) {
Set set = new LinkedHashSet();
set.add(123) ;
set.add(456) ;
set.add(789) ;
set.add(new Person("ZhangSan",20)) ;
for (Object obj : set){
System.out.println(obj);
}
}
}
至于为什么输出有序,也很好理解,是因为它将内存中无序的元素用前后指针连起来了,输出时按添加顺序输出罢了。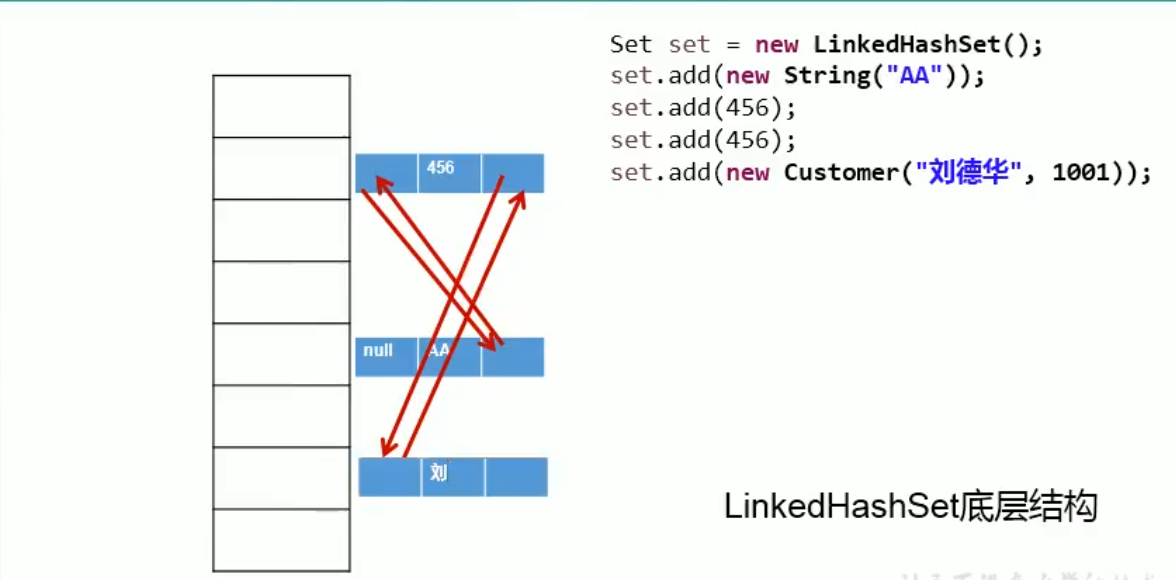
因此,对于频繁的遍历操作,LinkedHashSet 效率是远高于 HashSet 的,一般还是很常用的。
7.3 TreeSet
TreeSet 是按照述二叉树的结构存储的,可以按照添加对象的指定属性对集合进行排序,说白了,它就是用来排序的。因为它要按照“指定属性”来排序,所以要求每个对象的类型是一样的,否则会报错。
7.3.1 自然排序
对于 Integer 型,TreeSet 会按照从小到大来排序:
public class CollectionTest {
public static void main(String[] args) {
Set set = new TreeSet();
set.add(789) ;
set.add(456) ;
set.add(123) ;
for (Object obj : set){
System.out.println(obj);
}
}
}

对于 String 型,会按照字典序升序排列。
对于自定义类,TreeSet 的排序规则和之前 Arrays.sort 完全一致,通过两个接口:Comparable 和 Comparator,前者称为 自然排序,后者称为 定制排序
对于自然排序,只需要让对象的类实现 Comparable 接口即可:
public class Person implements Comparable{
@Override
public int compareTo(Object o) {
// ...
return ...;
}
}
比如按照商品的价格对商品进行排序
public class Good implements Comparable {
@Override
public int compareTo(Object o) {
Good o1 = (Good) o;
return this.price - o1.price;
}
private int price ;
private String name ;
// 重写 toString 方法
...
}
7.3.2 定制排序
所谓定制排序,就是在 new TreeSet 时定义 Comparator 的实现类的匿名对象,直接定义排序规则。
8. Map 接口
Map 是 Collection 的子接口,用来存储双列数据,也就是键值对,有五个实现类:HashMap、LinkedHashMap、TreeMap、Hashtable、Properties。
- HashMap:Map的主要实现类,一般Map都用这个,效率高
- LinkedHashMap:HashMap 的子类,在 HashMap 底层的基础上添加了一对指针,使其可以按照添加顺序实现遍历。
- TreeMap:存储有序键值对,可以按照添加的key-value进行排序,标准是key。
- Hashtable:古老的实现类,都不用了
- Properties:太老了,不用了
【Map中 key-value 的特定】
- Key 是无序的、不可重复的,使用Set存储所有的key
- 因此 key 所在的类是要重写 equals 和 hashCode 的
- Value 是无序的、可重复的,使用Collection存储所有的value
8.1 HashMap
创建 HashMap 集合:public class MapTest { public static void main(String[] args) { Map map = new HashMap(); } }
- 增
向 HashMap 里添加元素用的不是 add,而是 put,其入参格式为 左key右value。
public class MapTest {
public static void main(String[] args) {
Map map = new HashMap();
map.put("abc",new Person("ZhangSan",12)) ;
map.put(123,new Person("ZhangSan",12)) ;
System.out.println(map);
}
}

- 删
使用 remove(key) 方法移除指定的 key-value,返回被移除的value。如果没有的话,返回null。
public class MapTest { public static void main(String[] args) { Map map = new HashMap(); map.put("abc",new Person("ZhangSan",12)) ; map.put(123,new Person("ZhangSan",12)) ; System.out.println(map.remove(123)); System.out.println(map); } }
使用 clear 清空 map,同样,清空是指清空数据,而不是赋值 null。
public class MapTest { public static void main(String[] args) { Map map = new HashMap(); map.put("abc",new Person("ZhangSan",12)) ; map.put(123,new Person("ZhangSan",12)) ; map.clear(); System.out.println(map); } }
- 改
改操作也是用 put 方法,和增一模一样,只是会将对应 key 下的 value 换成新的(因为 key 不可重复)
public class MapTest {
public static void main(String[] args) {
Map map = new HashMap();
map.put("abc",new Person("ZhangSan",12)) ;
map.put("abc",new Person("LiSi",20)) ;
System.out.println(map);
}
}

- 查
使用 get(key) 来获取指定 key 对应的 value,并返回该 value。
public class MapTest {
public static void main(String[] args) {
Map map = new HashMap();
map.put("abc",new Person("ZhangSan",12)) ;
map.put(123,new Person("LiSi",20)) ;
System.out.println(map.get(123));
}
}

- 包含
使用 cotainsKey 来判断 Map 中是否包含指定的 key,如果包含则返回 true,反之返回 false。
public class MapTest { public static void main(String[] args) { Map map = new HashMap(); map.put(123,new Person("LiSi",20)) ; System.out.println(map.containsKey(123)); System.out.println(map.containsKey("123")); } }
使用 cotainsValue 来判断 Map 中是否包含指定的 value,如果包含则返回 true,反之返回 false。
public class MapTest { public static void main(String[] args) { Map map = new HashMap(); map.put(123,new Person("LiSi",20)) ; System.out.println(map.containsValue(123)); System.out.println(map.containsValue(new Person("LiSi",20))); } }
使用 size 获取当前 Map 中 key-value 对的个数,返回 int
public class MapTest { public static void main(String[] args) { Map map = new HashMap(); map.put(123,new Person("LiSi",20)) ; map.put("123",new Person("LiSi",20)) ; map.put("abc",new Person("LiSi",20)) ; System.out.println(map.size()); } }
- 遍历
注意,Collection 有迭代器,但是 Map 是没有迭代器的。
使用 keySet 方法遍历所有的 key,返回一个 Set,然后对返回的 Set 进行遍历就行,用迭代器和foreach都行
public class MapTest { public static void main(String[] args) { Map map = new HashMap(); map.put(123,new Person("LiSi",20)) ; map.put("123",new Person("LiSi",20)) ; map.put("abc",new Person("LiSi",20)) ; Set set = map.keySet(); Iterator it = set.iterator(); while (it.hasNext()){ System.out.println(it.next()); } } }
使用 values 方法遍历所有的 value,返回一个 Collection,然后对返回的 Collection 进行遍历就行,用迭代器和foreach都行
public class MapTest { public static void main(String[] args) { Map map = new HashMap(); map.put(123,new Person("ZhangSan",20)) ; map.put("123",new Person("LiSi",20)) ; map.put("abc",new Person("WangWu",20)) ; Set set = map.keySet(); Collection coll = map.values(); for (Object obj : coll){ System.out.println(obj); } } }8.2 LinkedHashMap
LinkedHashMap 只是底层中在 HashMap 的基础上增加了双向指针,常用方法几乎和 HashMap 一样的,都是用 Map 接口中的方法。而且除了特殊情况,一般用 HashMap 就够了,就不写了。
8.3 TreeMap
TreeMap 是按照 key 排序的,所以在向 TreeMap 中添加元素时,必须要求所有 key 的类型一样!它的排序比较标准和 TreeSet 是一样的,要么用 Comparable,要么用 Comparator。前者为自然排序,后者为定制排序,一般都用后者:
public class MapTest { public static void main(String[] args) { Map map = new TreeMap(new Comparator() { @Override public int compare(Object o1, Object o2) { Key key1 = (Key) o1; Key key2 = (Key) o2; return key1.getNum() - key2.getNum(); } }); map.put(new Key(789),new Person("ZhangSan",20)) ; map.put(new Key(456),new Person("LiSi",20)) ; map.put(new Key(123),new Person("WangWu",20)) ; Set set = map.keySet(); for (Object obj : set){ System.out.println(obj+"==>"+map.get(obj)); } } }


若有收获,就点个赞吧
0 人点赞
