一,SE基础
1,多肽
父类引用指向子类对象,或者父类接口指向其实现类!
编译时看=左边的类型,检查是否有此类型,如果有则编译通过,运行时看右边,找到对应的对象地址,执行其方法或属性,实现多肽,既有2种状态。这也就是我们的向上转型(对于基本数据类型而言是自动转型)
当我们要用到子类中特有的方法,其父类没有时,此时在多态里是不允许的,所以此时应该进行对应的向下转型 (对于基本数据类型而言是强制转型)
Animal a=new Cat();Cat c=(Cat) a;
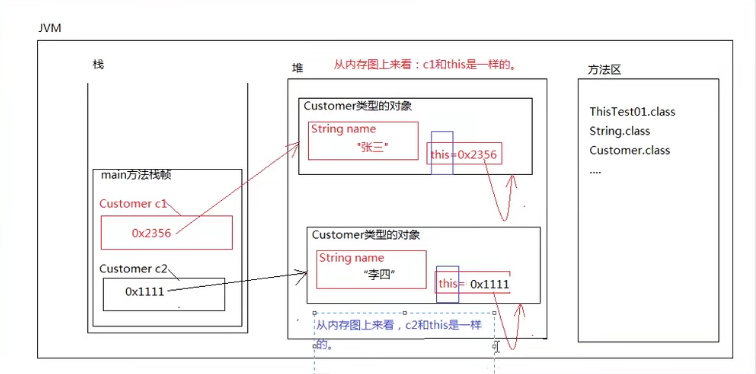
2,this关键字
- this首先是我们java中的一个关键字,它是一个引用,在堆内存中保存内存地址指向自身
- this可以出现在实例方法中,也可以出现在构造方法中
- 它出现在实例方法中代表的是此时调用这个方法的对象
- this不能出现在静态方法中,因为静态方法是类所有的,调用时没有引用对象,此时使用this会报错
- this大部分情况下时可以省略的,但在区分区部变量和实例变量时不可以省略
3,static关键字
static是静态的意思,它修饰变量的变量为静态变量,它修饰的方法为静态方法。
成员变量分为:实例变量和静态变量。
首先实例变量必须要new 对象,通过引用.变量名的方式访问。
静态变量在类加载时初始化,不需要new对象,静态变量的空间即可被开辟出来,而且静态变量存储的位置是在方法区中。
什么时候用静态变量呢?
如果这个类型的所有对象的某个属性值都是一样的,不建议定义为实例变量,这样会浪费内存空间。此时建议定义为类级别级,既定义为静态变量,在方法区中只保留一份,节省内存开销。
—>一个对象一份,实例变量
—>所有对象一份,静态变量
其内存结构图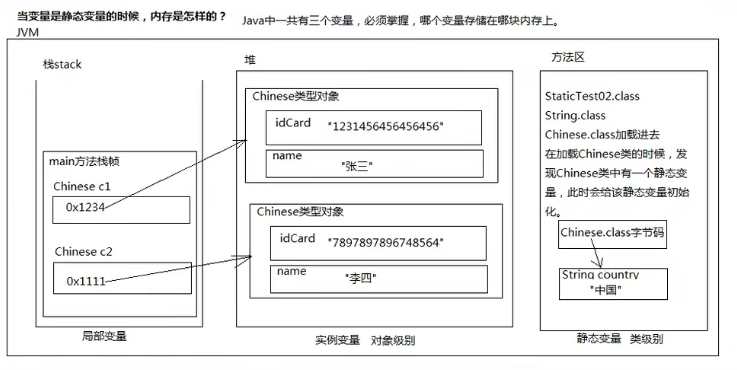
4,引用传递和值传递的区别
在Java中参数的传递主要有两种:值传递和参数传递;
4.1 值传递
实参传递给形参的是值 形参和实参在内存上是两个独立的变量 对形参做任何修改不会影响实参
package arrayDemo;public class Demo1 {public static void main(String[] args) {int b =20;change(b);// 实参 实际上的参数System.out.println(b);}public static void change(int a){//形参 形式上的参数a=100;}}输出结果为 20
形参只是实参创建的一个副本,副本改变了,原本当然不可能跟着改变;
4.2引用传递
实参传递给形参的是参数对于 堆内存上的引用地址 实参和 形参在内存上指向 了同一块区域 对形参的修改会影响实参
package arrayDemo;public class Demo1 {public static void main(String[] args) {int [] a={1,2,3};System.out.println(a[0]);change(a);System.out.println(a[0]);}public static void change(int[] a ){a[0]=100;}}输出结果为:1 100
由于引用传递,传递的是地址,方法改变的都是同一个地址中的值,
原来a[0]指向0x13地址,值是1,
后来在a[0] 指向的也是0x13地址,将值变成了100
所以,再查询a[0]的值的时候,值自然变成了100
5,final关键字
final表示最终的,最后的。
- final修饰的类无法被继承
- final修饰的方法无法被覆盖,不能重写
- final修饰的变量一旦赋值,不能再次赋值,此时就是一个常量
- final修饰的引用,表示该引用只能指向一个对象,无法再指向其他对象,并且该对象在方法执行过程中不会被垃圾回收器回收,直到方法结束,才会释放空间
final修饰的实例变量,如果赋值时不给初始值,系统此时也不会赋给它默认值,需要我们手动赋值
6,抽象类
什么是抽象类?
类和类之间具有共同特征,将这些共同特征提取出来,形成的就是抽象类。
抽象类的特点:
- 抽象类无法实例化,必须用来被子类所继承
- 抽象类虽然无法实例化,但是也有构造方法,构造方法是提供给子类用的
- 抽象类里面可以没有抽象方法,但是如果一个类里面有抽象方法,这个类就必须是抽象类
一个非抽象类继承抽象类时,必须重写这个抽象类里面的所有抽象方法进行覆盖
7,接口
接口是一种引用数据类型
- 接口时完全抽象的
- 接口中只有常量+抽象方法
- 接口中抽象方法的public abstract是可以省略的
- 接口中常量的public static final可以省略
接口和抽象类的区别:
- 抽象类只能继承一次,但是可以实现多个接口
- 接口和抽象类必须实现其中所有的方法,抽象类中如果有未实现的抽象方法,那么子类也需要定义为抽象类。抽象类中可以有非抽象的方法
- 接口中的变量必须用 public static final 修饰,并且需要给出初始值。所以实现类不能重新定义,也不能改变其值。
- 接口中的方法默认是 public abstract,也只能是这个类型。不能是 static,接口中的方法也不允许子类覆写,抽
- 象类中允许有static 的方法
8,集合
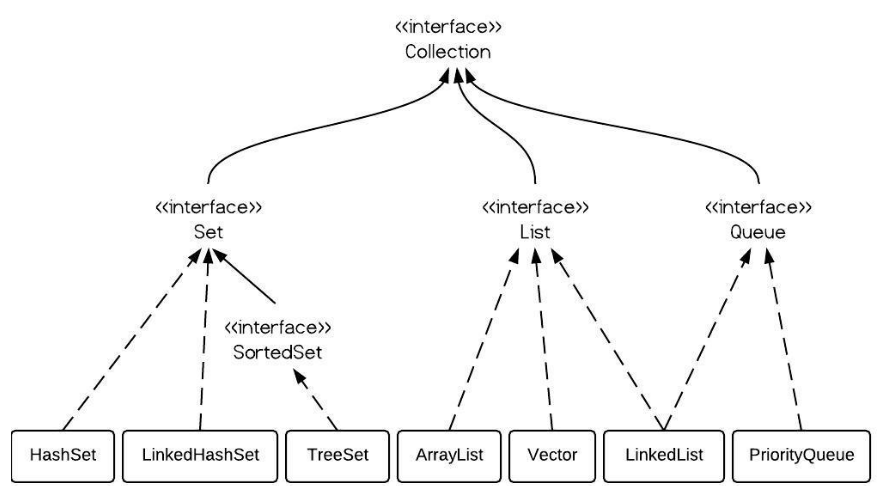
- List , Set, Map都是接口,前两个继承至Collection接口,Map为独立接口
- Set下有HashSet,LinkedHashSet,TreeSet
- List下有ArrayList,Vector,LinkedList
- Map下有Hashtable,LinkedHashMap,HashMap,TreeMap
- Collection接口下还有个Queue接口,有PriorityQueue类
注意:
Queue接口与List、Set同一级别,都是继承了Collection接口。
看图你会发现,LinkedList既可以实现Queue接口,也可以实现List接口.只不过呢, LinkedList实现了Queue接口。Queue接口窄化了对LinkedList的方法的访问权限(即在方法中的参数类型如果是Queue时,就完全只能访问Queue接口所定义的方法 了,而不能直接访问 LinkedList的非Queue的方法),以使得只有恰当的方法才可以使用。
SortedSet是个接口,它里面的(只有TreeSet这一个实现可用)中的元素一定是有序的。
总结:
Connection接口:
— List 有序,可重复
ArrayList
优点: 底层数据结构是数组,查询快,增删慢。
缺点: 线程不安全,效率高
Vector
优点: 底层数据结构是数组,查询快,增删慢。
缺点: 线程安全,效率低
LinkedList
优点: 底层数据结构是链表,查询慢,增删快。
缺点: 线程不安全,效率高
二:Set 无序,唯一
HashSet
底层数据结构是哈希表。(无序,唯一)
如何来保证元素唯一性?
1.依赖两个方法:hashCode()和equals()
LinkedHashSet
底层数据结构是链表和哈希表。(FIFO插入有序,唯一)
1.由链表保证元素有序
2.由哈希表保证元素唯一
TreeSet
底层数据结构是红黑树。(唯一,有序)
1. 如何保证元素排序的呢?
自然排序
比较器排序
2.如何保证元素唯一性的呢?
根据比较的返回值是否是0来决定
针对Collection集合我们到底使用谁呢?(掌握)
唯一吗?
是:Set
排序吗?
是:TreeSet或LinkedHashSet
否:HashSet
如果你知道是Set,但是不知道是哪个Set,就用HashSet。
否:List
要安全吗?
是:Vector
否:ArrayList或者LinkedList
查询多:ArrayList
增删多:LinkedList
如果你知道是List,但是不知道是哪个List,就用ArrayList。
如果你知道是Collection集合,但是不知道使用谁,就用ArrayList。
如果你知道用集合,就用ArrayList。
三:Map接口:
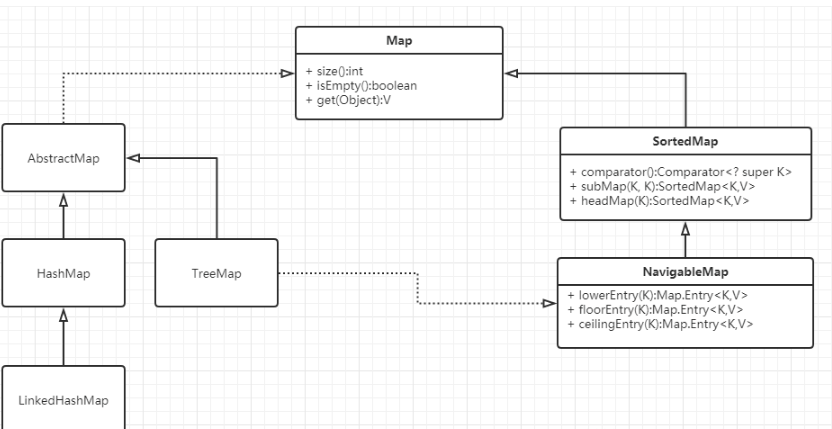
Map接口有三个比较重要的实现类,分别是HashMap、TreeMap和HashTable。
TreeMap是有序的,HashMap和HashTable是无序的。
Hashtable的方法是同步的,HashMap的方法不是同步的。这是两者最主要的区别。
这就意味着:
Hashtable是线程安全的,HashMap不是线程安全的。
HashMap效率较高,Hashtable效率较低。
如果对同步性或与遗留代码的兼容性没有任何要求,建议使用HashMap。 查看Hashtable的源代码就可以发现,除构造函数外,Hashtable的所有 public 方法声明中都有 synchronized关键字,而HashMap的源码中则没有。
Hashtable不允许null值,HashMap允许null值(key和value都允许)
父类不同:Hashtable的父类是Dictionary,HashMap的父类是AbstractMap
9,线程
进程:
进程一个正在运行的程序的实例,是一个程序在其自身地址空间中的一次执行活动。
进程需要独立占有地址空间 导致资源消耗过多 重量型,是申请资源、调度和独立运行的单位,它使用系统中的运行资源。进程是程序的一次执行过程,是一个动态概念,是程序在执行过程中分配和管理资源的基本单位,每一个进程都有一个自己的地址空间,
线程:
线程是进程中一个单一的连续控制流程。一个进程可以拥有多个线程。线程又称轻量级进程,和进程一样拥有独立的执行控制,由操作系统负责调度,区别在于线程没有独立的存储空间,而和所属进程中的其他线程共享一个存储空间。
线程的生命周期:
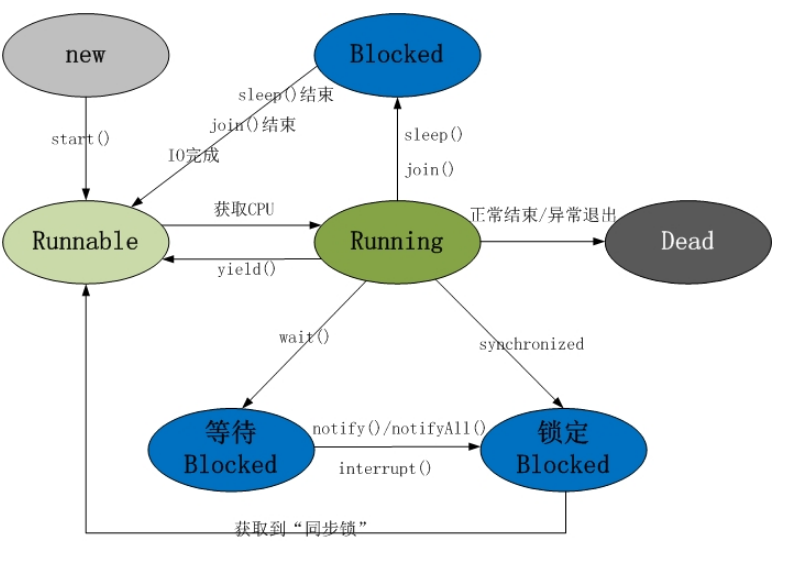
Java线程具有五中基本状态
新建状态(New):当线程对象对创建后,即进入了新建状态,如:Thread t = new MyThread();
就绪状态(Runnable):当调用线程对象的start()方法(t.start();),线程即进入就绪状态。处于就绪状态的线程,只是说明此线程已经做好了准备,随时等待CPU调度执行,并不是说执行了t.start()此线程立即就会执行;
运行状态(Running):当CPU开始调度处于就绪状态的线程时,此时线程才得以真正执行,即进入到运行状态。注:就 绪状态是进入到运行状态的唯一入口,也就是说,线程要想进入运行状态执行,首先必须处于就绪状态中;
阻塞状态(Blocked):处于运行状态中的线程由于某种原因,暂时放弃对CPU的使用权,停止执行,此时进入阻塞状态,直到其进入到就绪状态,才 有机会再次被CPU调用以进入到运行状态。根据阻塞产生的原因不同,阻塞状态又可以分为三种:
1.等待阻塞:运行状态中的线程执行wait()方法,使本线程进入到等待阻塞状态;
2.同步阻塞 — 线程在获取synchronized同步锁失败(因为锁被其它线程所占用),它会进入同步阻塞状态;
3.其他阻塞 — 通过调用线程的sleep()或join()或发出了I/O请求时,线程会进入到阻塞状态。当sleep()状态超时、join()等待线程终止或者超时、或者I/O处理完毕时,线程重新转入就绪状态。
死亡状态(Dead):线程执行完了或者因异常退出了run()方法,该线程结束生命周期。
创建线程的方式:
1,实现Runnable接口:
通过实现Runnable接口,重写run()方法。然后借助Thread的start()方法开启线程,调用run()方法是不会开启新线程的,只是一次方法调用而已。
public class CreateThreads implements Runnable{@Overridepublic void run() {System.out.println("通过实现Runnable接口开启线程~");}public static void main(String[] args) {CreateThreads createThreads = new CreateThreads();Thread thread = new Thread(createThreads);thread.start();}
2,继承Thread类,重写run()方法。
public class CreateThreads extends Thread{@Overridepublic void run() {System.out.println("通过继承Thread开启线程~");}public static void main(String[] args) {CreateThreads createThreads = new CreateThreads();Thread thread = new Thread(createThreads);thread.start();}
再加上java中多实现,单继承的特点,在选用上述两种方式创建线程时,应该首先考虑第一种(通过实现Runnable接口的方式)。
3,实现callable接口,重写call方法
因为前2种方法都没有返回值,所以就有了callable接口,它是有返回值的。
我们可以这样获取其返回值:
1,生成一个线程池: ExecutorService executorService = Executors.newFixedThreadPool(2);
2,用其submit方法获得 Future对象 Future
3使用Future的get()方法等待子线程计算完成返回的结果 int result = result1.get() + result2.get();
import java.util.concurrent.*;/*** @author wolf* @create 2019-04-25 14:53* 计算1+...+100的结果,开启三个线程,主线程获取两个子线程计算的结果,一个子线程计算1+...+50,一个子线程计算51+...+100。*/public class CreateThreads implements Callable {public static void main(String[] args) throws ExecutionException, InterruptedException {//生成具有两个线程的线程池ExecutorService executorService = Executors.newFixedThreadPool(2);//调用executorService.submit()方法获取FutureFuture<Integer> result1 = executorService.submit(new CreateThreads());Future<Integer> result2 = executorService.submit(new SubThread());//使用Future的get()方法等待子线程计算完成返回的结果int result = result1.get() + result2.get();//关闭线程池executorService.shutdown();//打印结果System.out.println(result);}//子线程1,用来计算1+...+50@Overridepublic Object call() throws Exception {int count = 0;for (int i = 1; i <= 50; i++)count = count + i;return count;}}class SubThread implements Callable {//子线程2,用来计算51+...+100@Overridepublic Object call() throws Exception {int count = 0;for (int i = 51; i <= 100; i++)count = count + i;return count;}
Runnable和Callable的区别
(1) Callable规定(重写)的方法是call(),Runnable规定(重写)的方法是run()。(2) Callable的任务执行后可返回值,而Runnable的任务是不能返回值的。(3) call方法可以抛出异常,run方法不可以。(4) 运行Callable任务可以拿到一个Future对象,表示异步计算的结果。它提供了检查计算是否完成的方法,以等待计算的
线程池:
Java通过Executors提供四种线程池,分别为:
1,newCachedThreadPool创建一个可缓存线程池,如果线程池长度超过处理需要,可灵活回收空闲2线程,若无可回收,则新建线程。
2,newFixedThreadPool 创建一个定长线程池,可控制线程最大并发数,超出的线程会在队列中等待。
3,newScheduledThreadPool 创建一个定长线程池,支持定时及周期性任务执行。
4,newSingleThreadExecutor 创建一个单线程化的线程池,它只会用唯一的工作线程来执行任务,保证所有任务按照指定顺序(FIFO, LIFO, 优先级)执行。
其核心参数:
1 ,corepoolsize:核心线程数
创建线程池后,线程池中线程数为0,有任务来时才创建线程去执行任务。当线程池中线程数目=corepoolsize,到达的任务会放 到缓存队列里面。
2 ,maxmumpoolsize:最大线程数线程池能容纳的最大线程数。
3, keepalivetime 最大空闲时间:空闲的线程保留时间,超过这个时间普通线程就会被销毁,保留corepoolsize个线程。
4 ,TimeUnit:空闲线程保留单位,可以是秒,毫秒,分钟,天,月,年
5 ,BlokingQueue 阻塞队列:存储等待执行的任务。主要有ArrayBlokingQueue,LinkedBlokingQueue,SynchronousQueue
6, ThreadFactor 线程工厂:用来创建线程。
7 ,RejectedExecutionHandler:队列已满,超过最大线程数处理策略。
主要有四种策略:
ThreadPoolExecutor.AbortPolicy:丢弃任务并抛出RejectedExecutionException
ThreadPoolExecutor.DiscardPolicy:丢弃任务但不抛出异常。
ThreadPoolExecutor.DiscardOldestPolicy:丢弃最前面的任务,然后重新尝试执行任务。
ThreadPoolExecutor.CallerRunsPolicy:调用线程处理该任务。
关键字:
让步(yield)
yield方法只是临时放弃当前线程的执行,并不代表该线程就不执行了,此时线程将转为可运行状态,在CPU可用的情况下,线程调度器会根据调度算法选择下一个可运行的程序来运行。
休眠(sleep)
让线程休眠,放弃执行,加入到等待队列。等休眠时间到了,再执行。以毫秒为单位。暂时放弃执行
导致当前执行的线程在指定的毫秒数内出现睡眠(暂时停止执行)
优先级 (setPriority)
hread类中的setPriority方法用于设置一个线程的优先级。方法接收一个int类型的整数。
加入线程(join)

若有收获,就点个赞吧
0 人点赞
