针对于残差模块的优化,由于很深的 ResNet 通常需要很长时间的训练(也就是训练很慢),作者引入了一种类似于 dropout 的方法,在训练过程中随机丢弃子图层(randomly drop a subset of layers),而在influence 时正常使用完整的 graph。(即在训练的过程中随机丢弃图层的反直觉方法,同时使用完整的网络进行推理。)
resnet 网络是由一个接一个的残差模块(ResBlock)串联起来的,可以视为 ResBlock 的集合。在训练时,对每个 ResBlock 随机 drop(按伯努利分布),drop 就是将上一个 ResBlock 直接输出到下一个 ResBlock,被drop 的 ResBlock 什么都不做也不更新。另外,网络的输入被视为第一层,是不会 drop 的。
与 Dropout 的不同之处在于,该方法 drop 整个 ResBlock,而 Dropout 在训练期间只 drop 一部分 unit。这种方法大大降低了训练时间,甚至在训练完成后删除部分 layer,还能不影响精度。
DropOut
Dropout 现在一般用于全连接层,卷积层一般不使用 Dropout,而是使用BN来防止过拟合,而且卷积核还会有 relu 等非线性函数,降低特征直接的关联性。
典型的神经网络其训练流程是将输入通过网络进行正向传导,然后将 loss 进行反向传播。Dropout 就是针对这一过程之中,随机地删除隐藏层的部分单元,进行上述过程。具体步骤:
- 对一批样本,随机删除网络中的一些隐藏神经元,保持输入输出神经元不变;
- 将输入通过修改后的网络进行前向传播,然后将误差通过修改后的网络进行反向传播;
- 对于另外一批的训练样本,重复上述操作 a,b

DropOut的意义
- 可以理解为模型平均,起到一种 Vote 的作用。对于全连接神经网络而言,我们用相同的数据去训练5个不同的神经网络可能会得到多个不同的结果,我们可以通过一种 vote 机制来决定多票者胜出,因此相对而言提升了网络的精度与鲁棒性。同理,对于单个神经网络而言,如果我们将其进行分批(某些神经元随机失活),虽然不同的网络可能会产生不同程度的过拟合,但是将其公用一个损失函数,相当于对其同时进行了优化,取了平均,因此可以较为有效地防止过拟合的发生。
- 减少神经元之间复杂的共适应性(神经元之间协同性)。隐藏层神经元被随机删除之后,使得全连接网络具有了一定的稀疏化,从而有效地减轻了不同特征的协同效应。也就是说,有些特征可能会依赖于固定关系的隐含节点的共同作用,而通过 Dropout 的话,它强迫一个神经单元,和随机挑选出来的其他神经单元共同工作,达到好的效果。消除减弱了神经元节点间的联合适应性,增强了泛化能力。由于每次用输入网络的样本进行权值更新时,隐含节点都是以一定概率随机出现,因此不能保证每2个隐含节点每次都同时出现,这样权值的更新不再依赖于有固定关系隐含节点的共同作用,阻止了某些特征仅仅在其它特定特征下才有效果的情况。(解耦)
DropPath
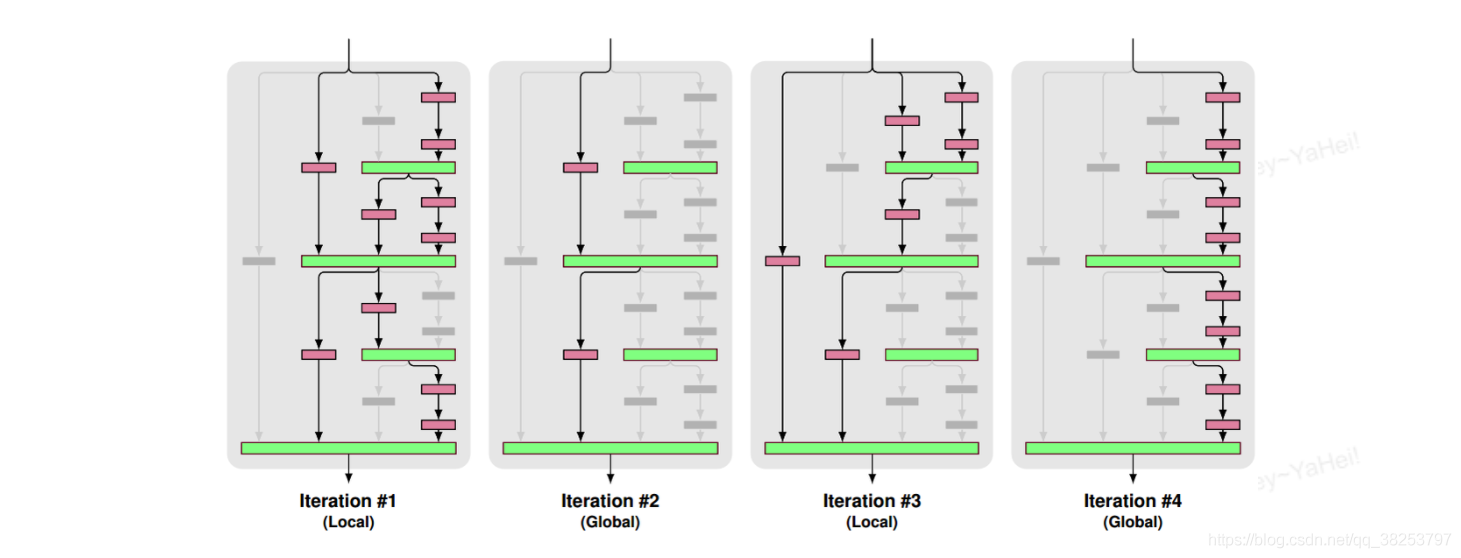
DropPath 是将深度学习模型中的多分支结构随机失活的一种正则化策略。与 FractalNet 一起提出, FractalNet 的 Block 包含很多分支(如下图),DropPath 将 Block 中的多分支结构随机失活。
训练时 DropPath 分为两个阶段交替进行:
- 局部丢弃,以一定的概率随机丢弃 Join 层,但必须保证起码有一条分支是通的。
- 全局丢弃,随机选择一条分支。

若有收获,就点个赞吧
0 人点赞
