四、索引讲解
1、索引的基本介绍
利用关键字,就是记录的部分数据(某个字段,某些字段,某个字段的一部分),建立与记录位置的对应关系,就是索引。
索引的作用:是用于快速定位实际数据位置的一种机制。
例如:字典的 检索写字楼 导航

2、索引的类型
主键索引,唯一索引,普通索引,全文索引无论任何类型,都是通过建立**_关键字_**与**_位置_**的对应的关系来实现的。以上类型的差异,是对关键字的要求不同。关键字:记录的部分数据(某个字段,某些字段,某个字段的一部分)
普通索引:对关键字没有要求。
唯一索引:要求关键字不能重复,同时增加唯一约束。
主键索引:要求关键字不能重复,也不能为NULL。同时增加主键约束。
全文索引:关键字的来源不是所有字段的数据,而是从字段中提取的特别关键词。
关键词的来源:可以是某个字段,也可以是某些字段(复合索引)。如果一个索引通过在多个字段上提取的关键字,称之为复合索引。
alter table emp add index (field1,field2);
3、索引管理语法
1、创建索引
-- 该语句添加一个主键,这意味着索引值必须是唯一的,且不能为nullalter table 表名 add primary key (column_list);-- 该语句创建索引的值必须是唯一的(除了null外,null可能会出现多次)alter table 表名 add unique [索引名] (column_list);-- 添加普通索引,索引值可出现多次alter table 表名 add index [索引名] (column_list);-- 该语句指定了索引为 fulltext,用于全文索引alter table 表名 add fulltext [索引名] (column_list);
2、删除索引
-- 主键索引的删除,如果没有auto_increment 属性则使用 alter table 表名 drop primary keyalter table 表名 drop primary key;-- 如果在删除主键索引时,该字段中有auto_increment则先去掉该属性再删除。alter table 表名 modify id int unsigned not null comment '主键';-- 删除普通索引,唯一索引,全文索引,复合索引;alter table 表名 drop index 索引的名称;如果没有指定索引名,则可以通过查看索引的方法得到索引名(一般依赖于索引字段的名字)
3、查看索引
show indexes from 表名;show index from 表名\Gshow create table 表名;show keys from 表名;desc 表名;
4、创建索引注意事项
第一:较频繁的作为查询条件字段应该创建索引
select * from emp where empno = 1第二:唯一性太差的字段不适合单独创建索引,即使频繁作为查询条件
select * from emp where sex = '男‘第三:更新非常频繁的字段不适合创建索引
select * from emp where logincount = 1第四:不会出现在WHERE子句中字段不该创建索引
六、索引的数据结构
查看索引的类型
show keys from 表名;

1、myisam的存储引擎的索引结构
索引的节点中存储的是数据的物理地址(磁道和扇区)
在查找数据时,查找到索引后,根据索引节点中记录的物理地址,查找到具体的数据内容。

2、innodb的存储引擎的索引结构
innodb的主键索引文件上 直接存放该行数据,称为聚簇索引,
非主索引指向对主键的引用(非主键索引的节点存储是主键的id)
比如要通过nam创建的索引,查询name=’采臣’的,先根据name建立的索引,找出该条记录的主键id,再根据主键的id通过主键索引找出该条记录。

注意: innodb来说:
1: 主键索引 既存储索引值,又存储行的数据
2: 如果没有主键, 则会Unique key做主键
3: 如果没有unique,则系统生成一个内部的rowid做主键.
4: 像innodb中,主键的索引结构中,既存储了主键值,又存储了行数据,这种结构称为”聚簇索引”
聚簇索引
优势: 根据主键查询条目比较少时,不用回行(数据就在主键节点下)劣势: 如果碰到不规则数据插入时,造成频繁的页分裂(索引的节点移动).
区别:
innodb的主索引文件上 直接存放该行数据,称为聚簇索引,非主索引指向对主键的引用myisam中, 主索引和非主索引,都指向物理行(磁盘位置).
七、索引覆盖
如果查询的列恰好是索引的一部分,那么查询只需要在索引区上进行,不需要到数据区再找数据,这种查询速度非常快,称为“索引覆盖”
索引覆盖就是,我要在书里 查找一个内容,由于目录写的很详细,我在目录中就获取到了,不需要再翻到该页查看。
准备两张表来测试使用;
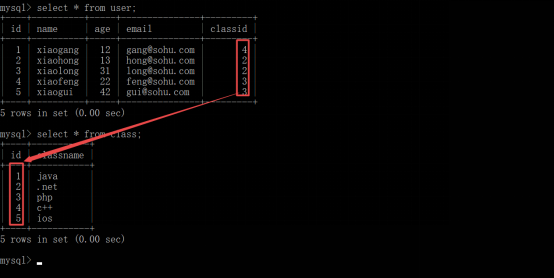
案例1,比如给id建立了主键索引,使用id查询数据。

在user表里面,给name字段添加索引,查询name,就用到了索引覆盖。

案例2:比如给id和name 建立了复合索引,使用name作为条件查询。
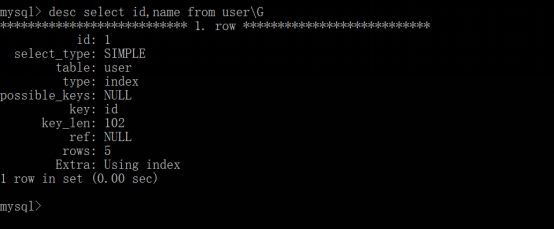
典型情况如下:
学生表:共30个字段。经常查询某几个字段,就把某几个字段单独做成复合索引。
Alter table student add index (name, id, height, gender, class_id);select name, id, height, gender, class_id from student;
负面影响,增加了索引的尺寸。
建立复合索引时,应保证该索引的使用率尽可能高,索引覆盖才有意义。
八、索引的使用原则
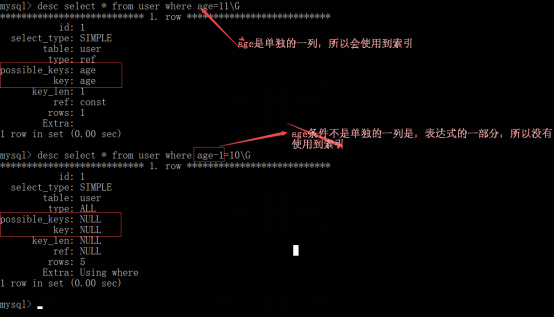
1、列独立
只有参与条件表达式的字段独立在关系运算符的一侧,该字段才可能使用到索引。
“独立的列”是指索引列不能是表达式的一部分,也不能是函数的参数。

2、like查询
在使用like(模糊匹配)的时候,在左边没有通配符的情况下,才可以使用索引。
在mysql里,以%开头的like查询,用不到索引。

注意:如果select的字段正好就是索引,那么会用到索引即索引覆盖

如果该表改为innodb引擎,
alter table user engine innodb;
因为非主键索引中存储的是id,select的字段是id因此用到了索引覆盖。
比如对name建立了索引,如下查询,就用到了索引覆盖。

注意以下查询会用到索引:

3、OR运算都具有索引
如果出现OR(或者)运算,要求所有参与运算的字段都存在索引,才会使用到索引。
如下:name有索引,classid没有索引

如下:id有索引,name有索引

4、复合索引使用
当前查询环境:
最左原则:对于创建的多列(复合)索引,只要查询条件使用了最左边的列,索引一般就会被使用。

注意:在多列索引里面,如果有多个查询条件,要想查询效率比较高,
比如如下建立的索引,index(a,b,c,d) 要保证最左边的列用到索引。则 a = 12 and b = 12 and c = 23
5、mysql智能选择
如果mysql认为,全表扫描不会慢于使用索引,则mysql会选择放弃索引,直接使用全表扫描。
一般当取出的数据量超过表中数据的20%,优化器就不会使用索引,而是全表扫描。

6、优化group by语句

默认情况下, mysql对所有的group by col1,col2进行排序。
-- 根据classid分组,自动根据classid进行 了排序select classid,sum(age) from user group by classid;

这与在查询中指定order by col1,col2类似,如果查询中包括group by, 但用户想要避免排序结果的消耗,则可以使用order by null禁止排序。
-- 如果不想根据classid排序,则可以在后面使用order by nulllselect classid,sum(age) from user group by classid order by null;
通过分析语句发现:


若有收获,就点个赞吧
0 人点赞
