如果说昨天完成了api的编写之后,这个聊天服务器就可以运行起来了,但是仅仅是运行起来也不够,<br />现在还缺少了日志功能,你也不能出了bug就去一行一行的查代码吧,怎么说都得找到一个定位的位置。所以今天来了解日志。<br />我们要输出日志,但是随着并发度的提高,如果说我们将每一条日志都直接的进行io操作的化,那么系统会特别慢,你可以理解吧,因为日志是需要写在磁盘上的,是保存在文件之中,但是现在系统正在进行高度的运行中,根本没有资源来进行io操作,但是日志又不是随时就需要的,所以在这个时候,我们就可以使用消息队列来完成这个事情<br /> 消息队列有两种模型:**队列模型**和**发布/订阅模型**。
队列模型生产者往某个队列里面发送消息,一个队列可以存储多个生产者的消息,一个队列也可以有多个消费者, 但是消费者之间是竞争关系,即每条消息只能被一个消费者消费。发布/订阅模型为了解决一条消息能被多个消费者消费的问题,发布/订阅模型就来了。该模型是将消息发往一个Topic即主题中,所有订阅了这个 Topic 的订阅者都能消费这条消息。其实可以这么理解,发布/订阅模型等于我们都加入了一个群聊中,我发一条消息,加入了这个群聊的人都能收到这条消息。那么队列模型就是一对一聊天,我发给你的消息,只能在你的聊天窗口弹出,是不可能弹出到别人的聊天窗口中的。
消息队列,简称它为MQ(Message Queue),可以简单理解为:将消息放在队列中进行处理,我们把数据放到队列中的称为生产者,吧数据取出队列的称为消费者,这玩意很像操作系统的那个生产者与消费者。现在的问题是,使用消息队列有什么好处呢?
- 解耦
- 异步
- 削峰,限流
解构
先来说明什么是解耦,来结合图片来说明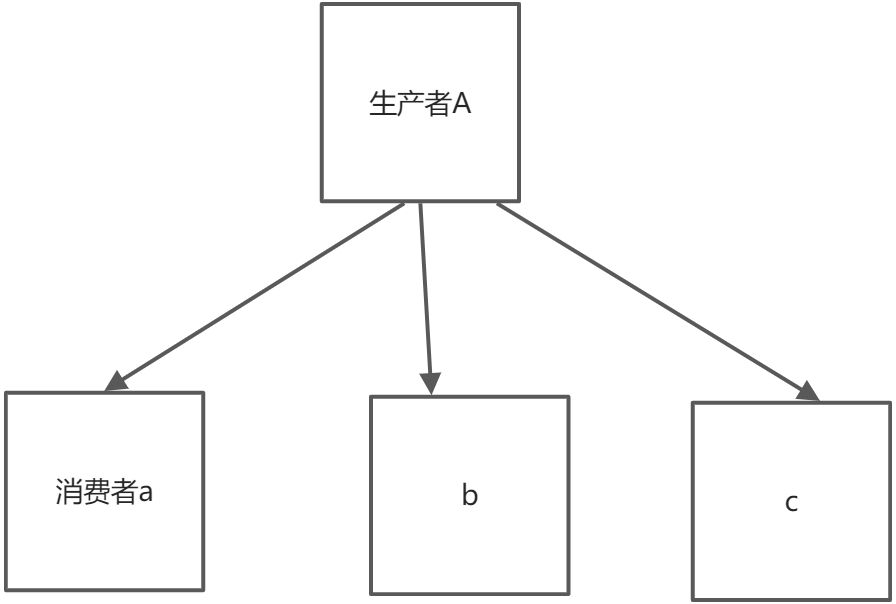
现在有一个生产者A,消费者a,b,c需要使用生产者A所产生的东西来进行他自己的动作,如果说有一天,a不需要A产生的东西了,那你就把他取消掉就可以了,一次还可以,只是注释一下代码就行了,但是次数多了呢?比如b或者c不需要了,或者又增加了一个d来进行消费呢,这样就很麻烦,也可以说A与abc直接耦合度很高,非常的难受
那增加了消息队列呢,结构就变成了下面这个结构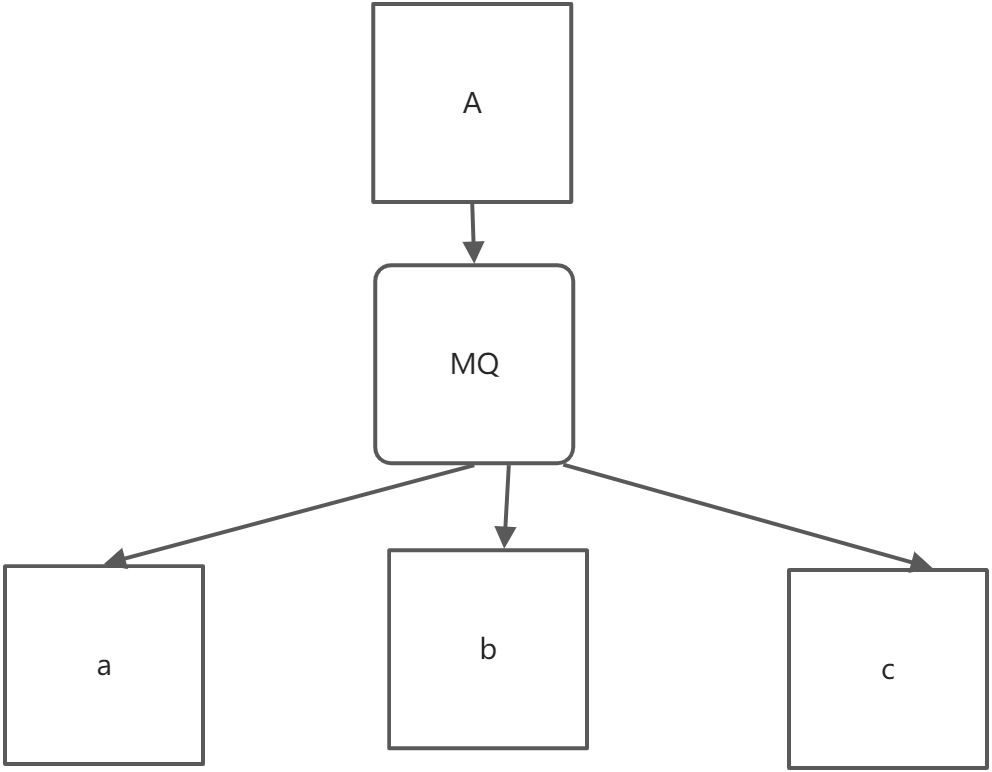
只需要A往消息队列中产生东西,A不关心abc是否需要这个东西,他只管自己生产自己的就行了,这不是A与abc之间的耦合度就降低了么?
异步
再来说什么是异步,通俗的说,就比如一个支付系统,我现在的代码如下
func pay(){id := 下订单 200ms发送短信(id) 300ms发送优惠券(id) 200ms}
在这三个步骤之后,我调用一次这个函数的大约时间是需要200+300+200=700ms,但是我最主要的是下单这个东西,发送短信和发送优惠券可以晚一点点给他发,所以说,为了提高吞吐量和用户体验,其实可以将发送短信和发送优惠券异步的进行,比如这样<br /><br /> 只需要这样的代码逻辑就可以
func A() id{id := 下订单MQ(id)}func b(id){发送短信(id)}func c(id){发送优惠券(id)}
这样我只需要调用一次A()就可以了,而调用一次A的开销远远小于前面的700ms的开销,这样就实现了异步
削峰/限流
这个比较简单,打个比方,如果说我一次只可以处理100个请求,我现在有两台机子,一共可以处理200个请求,但是今天很忙,突然来了300个请求,那电脑可能就会死机了,那现在我就把多的100个请求放在消息队列中,然后慢慢来处理,就相当于是多了一个缓冲区一样
消息队列有这么多好处,难道就没有坏处么?当然有:消息重复消费、消息丢失、消息的顺序消费
先说消息重复消费:还用上面的A-a,b,c做例子,如果说b是要进行增加积分,a是进行扣款,c是进行增加优惠券,那么当A生产后,当abc开始消费的时候,现在消息队列都是有重试机制的,如果b增加积分挂了,没增加上,那么他会让消息队列重新生成,但是a,c也同样监视着消息队列啊,那么重新生成出来的数据就会再一次的被利用,就出现了扣两次款,给两张优惠券的问题,那怎么保证这个问题呢?
所以说得进行幂等,幂等就像在那个get一样,运行多次对服务器没有影响,结果一样。
一般来说,幂等也要分场景去考虑,看是强校验还是弱校验,如果说是关于钱的肯定是强校验,但如果是关于发送个短信无关紧要的就是弱校验了
对于强校验来说,你可以利用数据库中主键唯一来进行检验
对于弱校验, 一些不重要的场景,比如给谁发短信啥的,我就把这个id+场景唯一标识作为Redis的key,放到缓存里面失效时间看你场景,一定时间内的这个消息就去Redis判断
再说消息的顺序消费:如果你生产者的顺序是ABC,那么接受一定是CBA,就像拓扑排序一样,一定要有顺序,如果顺序错了,那么就错了,怎么解决这个问题呢(因为消费者是多个的,并不能保证顺序)
那么我们就消费完成,在发送下一个,那么就可以保证了,用哈希取模让同一个订单到同一个队列中,在让同一个队列保证fifo,不同的中间件有不同的处理方法
那么消息丢失呢,分为三个情况
1.生产者丢了数据,也就是生产者发送到mq的时候丢了,那么就可以用事务机制或者ack来确定,但是事务是同步的,事务提交了会阻塞,ack不是
2.消息队列挂了,那就只能将信息持久化,就是保存到磁盘上,如果挂了就重新读取,但是有很小的概率mq没有持久化就挂了,那只能丢失了
3.消费者挂了,如果数据刚来,消费者挂了,但是mq认为他已经发过了,这个时候来用ack机制了
https://www.jianshu.com/p/4491cba335d1
分布式事务
事务有acid,原子一致隔离持久,事务就是保证这些的
那么怎么保证分布式事务呢,下面有个最简单的,2pc两阶段提交
就是相当于,有一个中间人,有俩数据库,然后中间人分别让俩数据库开始事务,然后在同时结束事务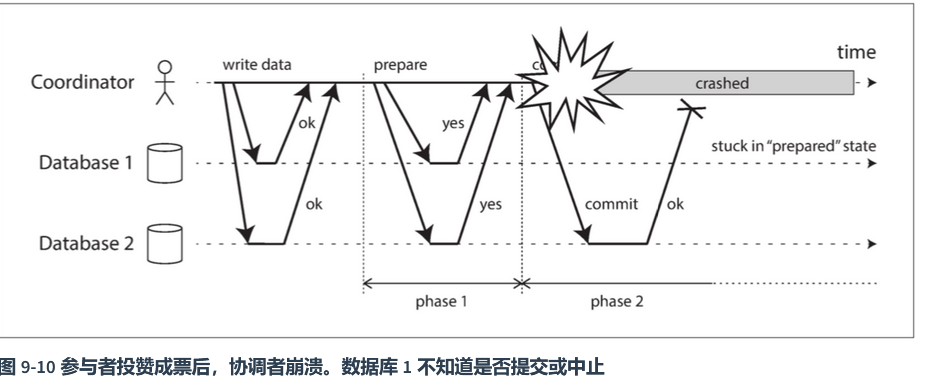
这说完了消息队列,今天的正题还没有进入呢,现在来看看kafka
kafka
如果说要了解kafka,那就得了解他的底层zookeeper,是个树形结构,通过监听来进行同一管理
利用 ZooKeeper 可以非常方便构建一系列分布式应用中都会涉及到的核心功能。数据发布/订阅负载均衡命名服务分布式协调/通知集群管理Master 选举分布式锁分布式队列
在kafka中,一个消息队列被称为一个topic,类似于数据库的一个表,给每一个队列取名字,那么生产者消费者就知道去哪里去生成去出数据了,然后为了提高一个topic的吞吐量,在一个topic内部也分为很多部分,称为partition,所以说,实质上是在partition中取数据放入数据的。
一个kafka服务器叫broker,kafka集群就是好多broker
你放入数据的其实是放入到了partition中,实际上partition会分布在不同的broker中,所以说kafka是天然分布式的,现在就会出现分布式的问题了,
如果说网络抖动等原因,你生产者放入topic中的数据挂了,这个时候kafka就说,那咱就来一个备份吧,所以说在不同的broker中,对于partition都有一个备份,这个备份就是备份,他不能用作消息的读写,如果说某一个broker挂了,里面的其他broker会进行选举成为新的主分区,画图举例子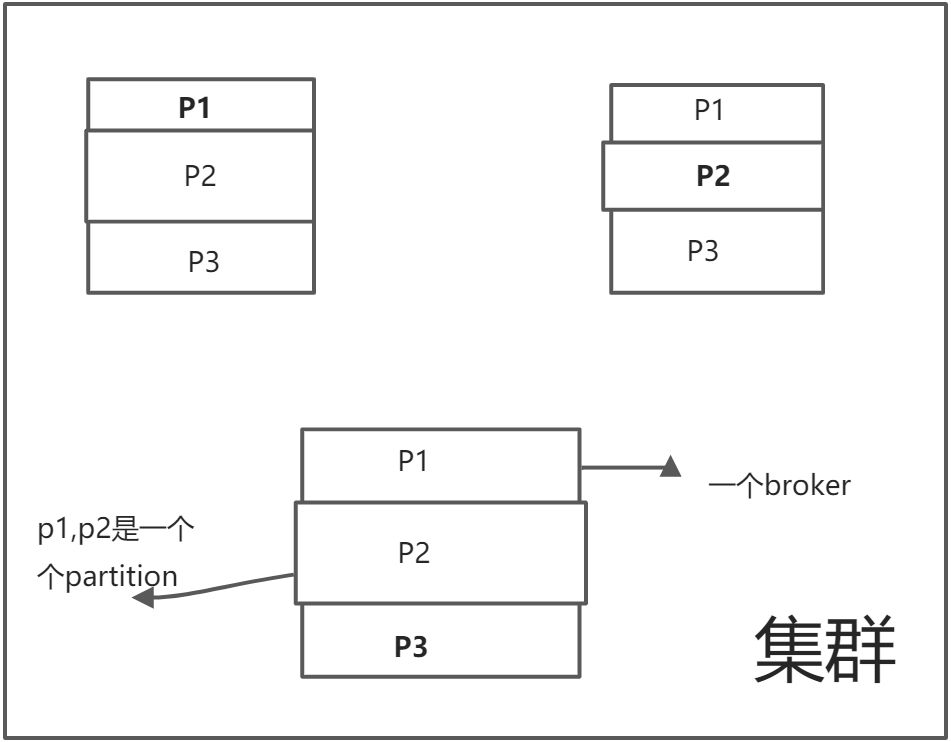
加粗的是主分区,剩下的就是备份分区,这样就可理解了吧
但是你若要读取备份的化,那就得涉及到持久化的问题了,kafka将数据写在磁盘上
1.数据持久化:发现线性的访问磁盘(即:按顺序的访问磁盘),很多时候比随机的内存访问快得多,而且有利于持久化;传统的使用内存做为磁盘的缓存Kafka直接将数据写入到日志文件中,以追加的形式写入2.日志数据持久化特性:写操作:通过将数据追加到文件中实现读操作:读的时候从文件中读就好了3.优势:读操作不会阻塞写操作和其他操作(因为读和写都是追加的形式,都是顺序的,不会乱,所以不会发生阻塞),数据大小不对性能产生影响;没有容量限制(相对于内存来说)的硬盘空间建立消息系统;线性访问磁盘,速度快,可以保存任意一段时间!
当挂了的时候,我们就需要另一个消费者来进行读取,但是那个消费者怎么知道要读到哪里呢?这里就有了offset的概念了,offset就是消费进度,而且为了避免消息只读了一次就没了的问题,kafka是把消息持久化储存的,每次读取只需要用offset来读哪一个东西就好了,实现了一个消息可以被消费多次。
kafka为什么快?
首先第一点,他是顺序读写的,直接写到磁盘上,怎么说呢,影响磁盘读写速度主要是这几个:寻道时间,转圈圈的时间,写数据的时间,一般说寻道时间是最长的,但是如果是顺序读写呢?他就会省略不少了。
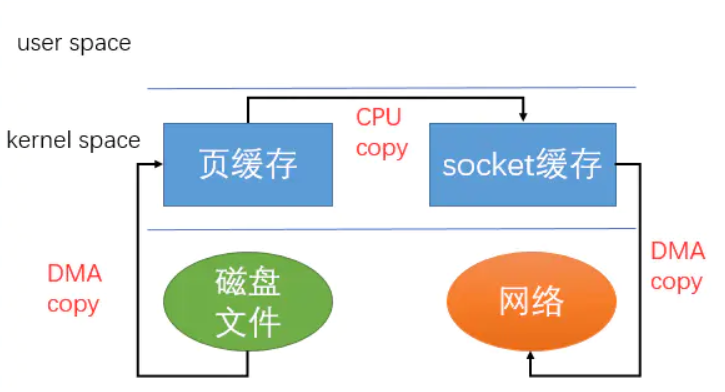
第二点就是零拷贝了,你从broker发送到customer的时候,你是不是先要读磁盘,然后在发送呢,一般流程是这样的: 用户态从磁盘内读取到缓冲区,然后再从缓冲区拷贝到socket的中,然后调用内核态的socket发送,然后在copy到网卡里,这样就有了一次拷贝,一共四次拷贝。kafka从这里优化:直接调用内核态的sendfile,就不用拷贝了。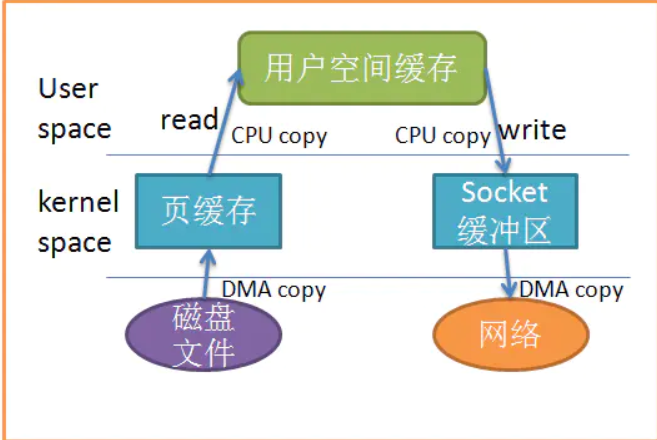
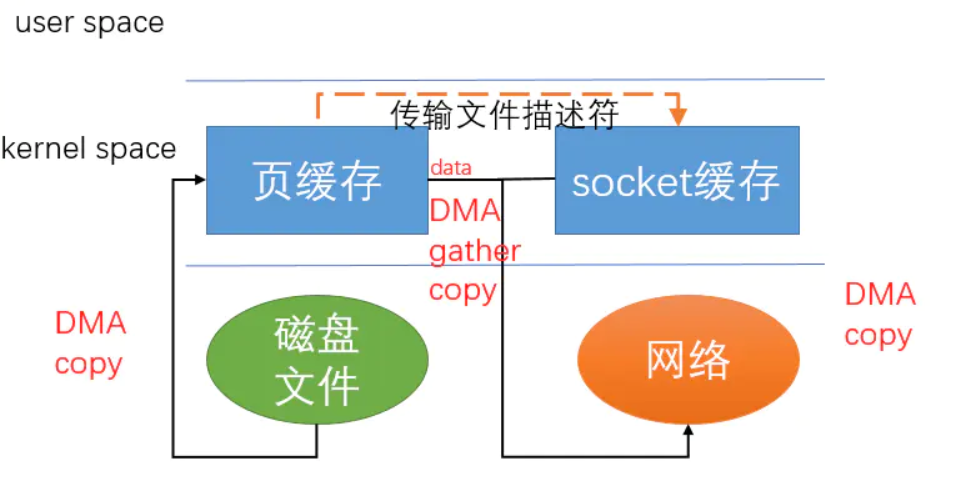
还要对于网络方面的问题,网络io也是一个瓶颈,这个问题嘛,其中一个解决是发送消息集合,降低了开销,还要消息压缩
https://mp.weixin.qq.com/s/sFUvgaQUXSA8b4hshhbwOQ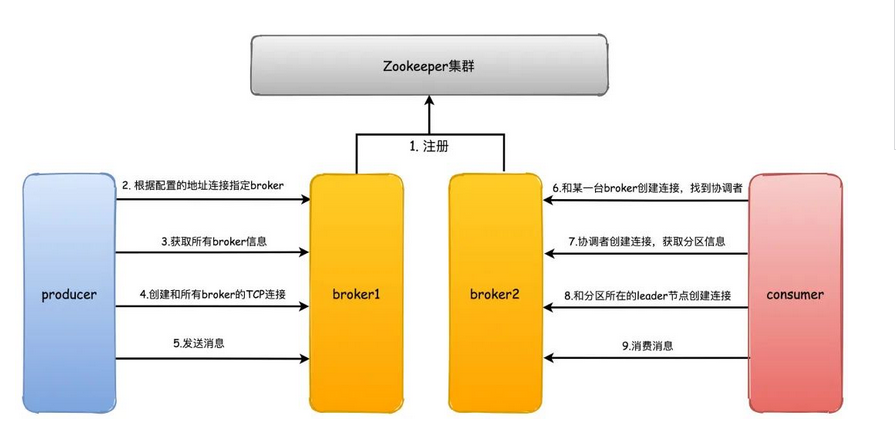
接下来利用kafka来实现日志功能
golang使用sarama包来实现kafka
先来一个小demo为了以后使用
目录结构----sarama_test-----main.go||---go.mod|---vendor||---kafka------customer.go|||--producer.go
//main.gopackage mainimport "gotest/kafka"func main(){bytes := []byte("aloha!this is test message for kafka")kafka.Send(bytes)kafka.Receive()kafka.Close()}
//go.modmodule gotestgo 1.17require github.com/Shopify/sarama v1.32.0require (github.com/davecgh/go-spew v1.1.1 // indirectgithub.com/eapache/go-resiliency v1.2.0 // indirectgithub.com/eapache/go-xerial-snappy v0.0.0-20180814174437-776d5712da21 // indirectgithub.com/eapache/queue v1.1.0 // indirectgithub.com/golang/snappy v0.0.4 // indirectgithub.com/hashicorp/go-uuid v1.0.2 // indirectgithub.com/jcmturner/aescts/v2 v2.0.0 // indirectgithub.com/jcmturner/dnsutils/v2 v2.0.0 // indirectgithub.com/jcmturner/gofork v1.0.0 // indirectgithub.com/jcmturner/gokrb5/v8 v8.4.2 // indirectgithub.com/jcmturner/rpc/v2 v2.0.3 // indirectgithub.com/klauspost/compress v1.14.4 // indirectgithub.com/pierrec/lz4 v2.6.1+incompatible // indirectgithub.com/rcrowley/go-metrics v0.0.0-20201227073835-cf1acfcdf475 // indirectgolang.org/x/crypto v0.0.0-20220214200702-86341886e292 // indirectgolang.org/x/net v0.0.0-20220127200216-cd36cc0744dd // indirect)
//kafka/customer.gopackage kafkaimport ("fmt""github.com/Shopify/sarama")var consumer sarama.Consumerfunc init(){config := sarama.NewConfig()client, _ := sarama.NewClient([]string{"127.0.0.1:9092"}, config)consumer, _ = sarama.NewConsumerFromClient(client)}func Receive(){partitionConsumer, _ := consumer.ConsumePartition("default_message", 0, sarama.OffsetNewest)defer partitionConsumer.Close()for {msg := <-partitionConsumer.Messages()fmt.Println("customer:",string(msg.Value))}}
//kafka/producer.gopackage kafkaimport("github.com/Shopify/sarama""fmt")var (producer sarama.AsyncProducerbrokers = []string{"127.0.0.1:9092"}topic = "heima")func init(){config := sarama.NewConfig()config.Producer.Compression = sarama.CompressionGZIPclient, _ := sarama.NewClient(brokers, config)fmt.Println("producer init success")producer, _ = sarama.NewAsyncProducerFromClient(client)}func Send(data []byte) {be := sarama.ByteEncoder(data)fmt.Println("producer:",string(data))producer.Input() <- &sarama.ProducerMessage{Topic: "default_message", Key: nil, Value: be}}func Close() {if producer != nil {producer.Close()}}

现在开始在你的服务器上安装kafka
1.首先下载kafka并解压到你的服务器上,记得放开端口
2.由于kafka需要zookeeper进行支持,但是高版本的kafka自带zookeeper,所以就不需要下载zookeeper了
3.kafka需要java环境,jdk需大于1.8,所以你可以选择在官网下载jdk然后自己配置环境或者是直接yum install java ,记得选择合适的版本,然后最重要的是在 /etc/profile中配置你的path,然后 source /etc/profile
4.下载好java环境后,cd进入kafka解压的目录,就可以进行kafka的开启了
5.你是选择后台运行的就不用开启多个shell了,但是下面的命令需要在多个界面中输入
6.先进入到kafka,在有bin config libs 等的这个目录下进行输入,
7.首先启动zookeeper
bin/zookeeper-server-start.sh config/zookeeper.properties
8.在启动kafka
bin/kafka-server-start.sh config/server.properties
9.创建一个topic<br />这里kafka版本为2.13,所以用这个命令
bin/kafka-topics.sh --bootstrap-server localhost:9092 --create --topic test --partitions 2 --replication-factor 1
这里创建了一个叫做test的topic,然后具有两个partition,没有备份,具体可以搜索后面参数来看<br />10.然后运行demo的golang代码,就可以看到上面的信息了,但是得改一下demo中topic的名字<br />这里还有一个问题,由于我的服务器是单核的,所以需要在kafka配置启动jvm的时候要进行添加参数
//kafka_server_start.shif [ "x$KAFKA_LOG4J_OPTS" = "x" ]; thenexport KAFKA_LOG4J_OPTS="-Dlog4j.configuration=file:$base_dir/../config/log4j.properties"fiif [ "x$KAFKA_HEAP_OPTS" = "x" ]; thenexport KAFKA_HEAP_OPTS="-Xmx256m -Xms120m -XX:ParallelGCThreads=1"//这里添加-XX:ParallelGCThreads=1fi
然后接下来就是在代码中进行写kafka传输日志的部分了<br />在internal新建包kafka 模仿上面的创建customer.go 和 producer.go<br />利用viper来读取端口与网站<br />修改后的代码如下
//producer.gopackage kafkaimport("github.com/Shopify/sarama""fmt""gochat/config")var (c = config.GetConfig().MsgChannelTypeproducer sarama.AsyncProducerbrokers = []string{c.KafkaHosts}topic = c.KafkaTopic)func init(){logType := c.ChannelTypeif "kafka" == logType{config := sarama.NewConfig()config.Producer.Compression = sarama.CompressionGZIPclient, _ := sarama.NewClient(brokers, config)fmt.Println("producer init success")producer, _ = sarama.NewAsyncProducerFromClient(client)}}func Send(data []byte) {be := sarama.ByteEncoder(data)fmt.Println("producer:",string(data))producer.Input() <- &sarama.ProducerMessage{Topic: "default_message", Key: nil, Value: be}}
在本项目中,并不需要customer的代码,因为消费者会在另一个机子上,所以我们使用zap库来生成日志,并利用生产者发送到kafka中,
// pkg/global/log/log.gopackage logimport (// "github.com/gookit/color""go.uber.org/zap""go.uber.org/zap/zapcore""gochat/internal/kafka""net/url")type Color struct {}func (c Color) Sync() error {// 因为只是控制台打印, 涉及不到缓存同步问题, 所以简单return就可以return nil}func (c Color) Close() error {// 因为只是控制台打印, 也涉及不到关闭对象的问题, return就好return nil}func (c Color) Write(p []byte) (n int, err error) {// 使用带颜色的控制台输出日志信息kafka.SendLog(string(p))// 返回写入日志的长度,以及错误return len(p), nil}func colorSink(url *url.URL) (sink zap.Sink, err error) {// 工厂函数中, 定义了必须接收一个*url.URL参数// 但是我们的需求比较简单, 暂时用不到, 所以可以直接忽略这个参数的使用// 实例化一个Color对象, 该对象实现了Sink接口c := Color{}return c, nil}var Logger *zap.Loggervar Any =zap.Anyvar String = zap.Stringvar Int = zap.Intvar Float32 = zap.Float32func init(){// 将colorSink工厂函数注册到zap中, 自定义协议名为 Colorif err := zap.RegisterSink("Color", colorSink); err != nil {return}logLevel := zap.NewAtomicLevelAt(zapcore.DebugLevel)var zc = zap.Config{Level: logLevel,Development: false,DisableCaller: false,DisableStacktrace: false,Sampling: nil,Encoding: "json",EncoderConfig: zapcore.EncoderConfig{MessageKey: "message",LevelKey: "level",TimeKey: "time",NameKey: "name",CallerKey: "caller",StacktraceKey: "stacktrace",LineEnding: zapcore.DefaultLineEnding,EncodeLevel: zapcore.LowercaseLevelEncoder,EncodeTime: zapcore.ISO8601TimeEncoder,EncodeDuration: zapcore.StringDurationEncoder,EncodeCaller: zapcore.ShortCallerEncoder,EncodeName: zapcore.FullNameEncoder,},// 日志标准输出的定义中, 除了标准的控制台输出, 还增加了一个我们自定义的Color协议输出// 这里需要注意的是, 我们的自定义协议中, 固定是接收了一个 *url.URL, 虽然我们没有用到// 但是在日志实际配置使用时, 我们仍需要显示传递该参数. 按照http协议的风格, 我们可以// 将其定义为 "Color://127.0.0.1", 当然 "Color:127.0.0.1" 和 "Color:"// 这种形式也是可以的. 但是 "Color" 这种是错误的配置形式OutputPaths: []string{"Color://127.0.0.1"},ErrorOutputPaths: []string{"stderr"},InitialFields: map[string]interface{}{"app": "apdex"},}Logger, _= zc.Build()defer Logger.Sync()}
这个就利用我们自己写的kafka.sendlog发送到kafka中,利用zap库可以更好的完成日志的写,然后在 消费者中,利用logstash来完成消费者代码,在go中,有一个叫做go-stash的替代,可以节省三分之二的资源[https://gitee.com/kevwan/go-stash](https://gitee.com/kevwan/go-stash),有时间在研究吧,你现在就随便用个write就可以了

若有收获,就点个赞吧
0 人点赞
