栈
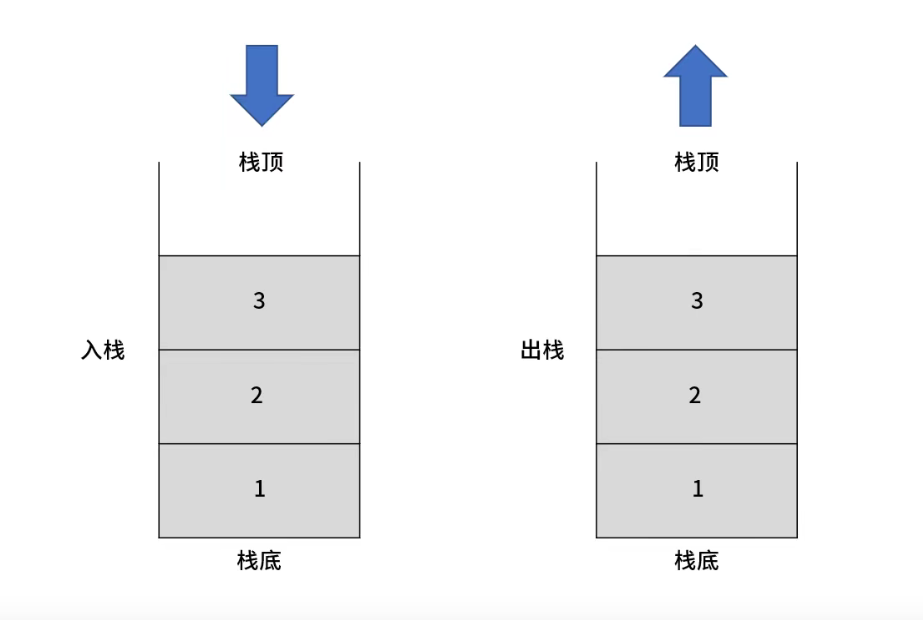
内存中的堆栈和数据结构中的堆栈不是一个概念,内存中的堆栈是真实存在的物理区,数据结构中的堆栈是抽象数据存储结构。栈:是一种受限制的线性表。它遵循后进先出(LIFO)规则。受限制最直白的理解就是:新增数据、删除数据、查找等操作时,不能随心所欲其限制是仅允许在表的一端进行插入和删除运算,这一端被称为栈顶,相对的,把另一端称为栈底。向一个栈插入新元素又称作进栈、入栈或压栈,他是把新元素放到栈顶元素的上面,使之成为新的栈顶元素从一个栈删除元素又称作出栈或退栈,他是把栈顶元素删除掉,使其相邻的元素成为新的栈顶元素。最开始的时候,栈是不含有任何数据的,叫做空栈push()pop()JS的调用栈执行上下文:执行上下文就是当前JS代码被解析和执行所在环境的抽象的概念Js中的任何代码都是在执行上下文中运行的。(执行环境)人的执行环境:空气、水JS的执行环境:JS代码运行起来,执行上下文JS的执行上下文分三种:全局执行上下文:默认的,他是最基础的执行上下文1、创建全局对象2、将this指向这个全局对像函数执行上下文:每次调用函数的时候,会为这个函数创建一个新的执行上下文Eval函数执行上下文:能够将符合JS标准的字符串当初语句执行
执行栈、调用栈后进先出,用于存储在代码执行期间创建的所有的执行上下文。1、JS引擎创建一个新的全局执行上下文并且将这个执行上下文推入到当前的执行栈中。执行栈用于:存储在代码执行期间创建的所有的执行上下文。每当发生函数调用的时候,JS引擎都会为该函数创建一个新的执行上下文并且push到当前执行栈的栈顶。当调用one函数的时候,js引擎为这个函数创建一个新的执行上下文并将其推到当前执行栈的栈顶。当调用two函数的时候,js引擎为这个函数创建一个新的执行上下文并将其推到当前执行栈的栈顶。当two函数调用完毕以后,他的执行上下文从当前执行栈中出栈,并把控制权交给下一个执行上下文。递归的原理函数的调用的本质:“压栈与出栈操作”。函数在调用栈里边有一个特例叫递归递归:自己调用自己递归调用,递归栈。LIFO先进栈,到条件后再出栈,如果不出栈,会导致栈溢出的问题。调用帧:函数调用会在内存里面形成一个调用记录,这个调用记录就是调用帧,作用是保存调用位置和内部变量的信息。尾调用:一个函数的最后一步是调用另外一个函数。尾递归:尾调用自身,尾递归。递归非常耗费内存的,因为它需要同时保存很多个调用帧,尾递归:它只存在一个调用帧,所以它是不会发生栈溢出错误的。
斐波那契数列(黄金分割数列)
斐波那契数列:从第3项开始,每一项等于前两项的和1,1,2,3,5,8,13
// 普通实现const fibonaci = n => {if (n <= 1) {return 1}return fibonaci(n - 1) + fibonaci(n - 2);}console.log(fibonaci(50));
// 尾递归实现
const fibonaci = (n, ac1 = 1, ac2 = 1) => {
if (n <= 1) {
return ac2;
}
return fibonaci(n - 1,ac2,ac1+ac2);
}
/*
重复计算的问题
n=5,fibonaci(4)+fibonaci(3)
n=4,fibonaci(3)+fibonaci(2)
...
递归需要同时保存成百上千个调用帧,很容易就会发生栈溢出
但是对于尾递归来说,由于只存在一个调用栈,所以永远不会发生栈溢出错误
*/
console.log(fibonaci(50));

若有收获,就点个赞吧
0 人点赞
