一个关系型数据库的结构
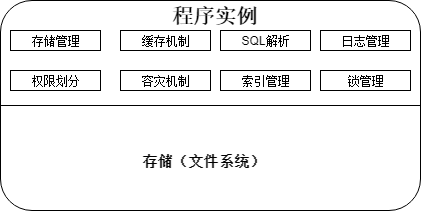
存储为块或页
索引
为什么要使用索引?
全表扫描: 小数据量,全表加载到内存进行查询
数据量大时使用索引可以实现快速查询,避免全表扫描
什么样的信息能成为索引?
索引的数据结构
二叉查找树,B树, B+树
Hash
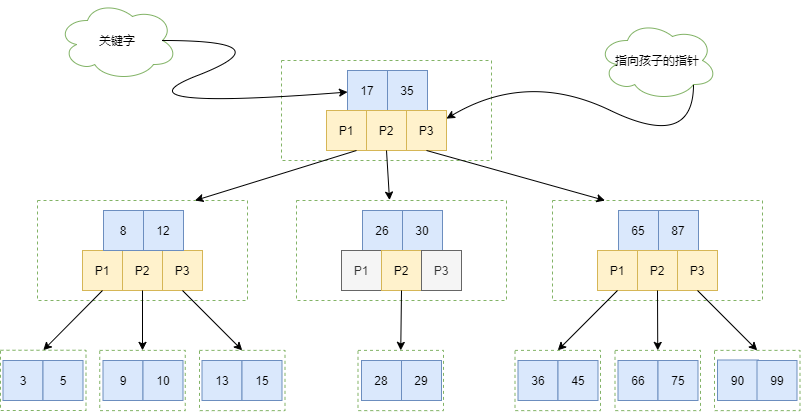
B-Tree
B-Tree的特征(为了让每个索引块存储尽可能多的关键字,减少查找io):
- 根节点至少包括两个孩子
- 树中每个节点最多含有m个孩子(m>=2)
- 除根节点和叶节点外,其他每个节点至少有m/2(向上取整) 个孩子
- 所有叶子节点都位于同一层
有新数据增加时,B-Tree可以通过分裂,合并,上移,下移来保持特征。
搜索可能不在叶子节点结束
B+Tree
可以存储更多的关键字
非叶子节点仅用来做叶子节点的索引,只有叶子节点存储关键字
搜索在叶子节点结束,加快查询效率
所有的叶子节点都有一个链指针指向下一个叶子节点,便于进行区间查找
相较于B-Tree只适合随机检索,B+Tree支持顺序检索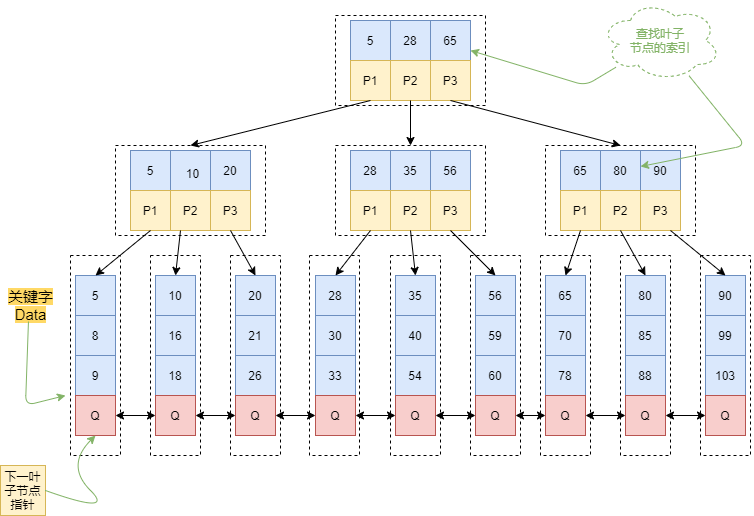
Hash
查找快
仅能满足”=”, “in”,不能使用范围查询
无法排序,hash后的值大小和元数据不一定匹配
无法使用组合索引查询,会hash组合后数据
密集索引和稀疏索引的区别
密集索引文件中的每个搜索码值都对应一个索引值
叶子节点 不仅保存了键值,还保存了位于同一行记录里的其他列的信息,由于密集索引决定了一张表的物理排列顺序,所以一张表只能有一个密集索引
稀疏索引文件只为索引码的某些值建立索引
Mysql的两种引擎 InnoDB, MyISAM在索引上的区别:
InnoDB必须有一个密集索引,一般为主键,若改表没有主键则使用第一个非空的唯一索引作为密集索引 ,若以上条件都不满足则InnoDB内部会生成一个隐藏主键作为密集索引,该隐藏主键是一个6字节的自增id。
InnoDB的索引为聚簇索引:非主键索引存储相关键位和其对应的主键值,包含两次查找,第一次查找非主键索自身,第二次查找其对应的主键。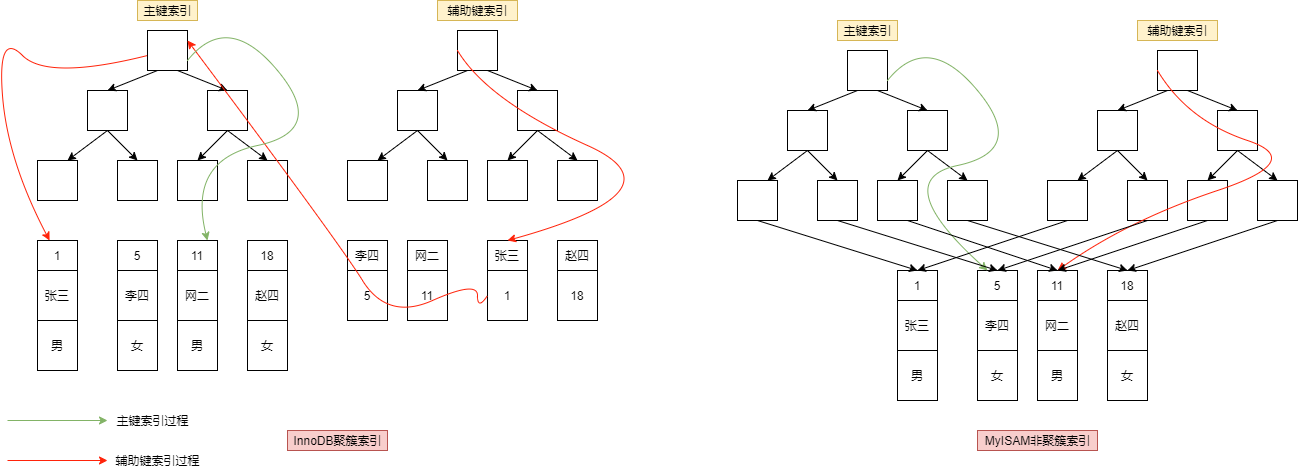
MyISAM引擎使用的都是稀疏索引
MyISAM的非聚簇索引:索引一次查找既能完成
InnoDB和MyISAM的存储文件对比:
- 表结构都是存储在.frm文件中
- InnoDB的索引和数据存储在一块,都在.idb文件内, 而MyISAM的索引和数据是分开存储的,索引在.MYI文件中,数据在.MYD文件中。

若有收获,就点个赞吧
0 人点赞
