编辑距离

思路
- 两个字符串的题目考虑使用 双指针
四种操作:增删改跳

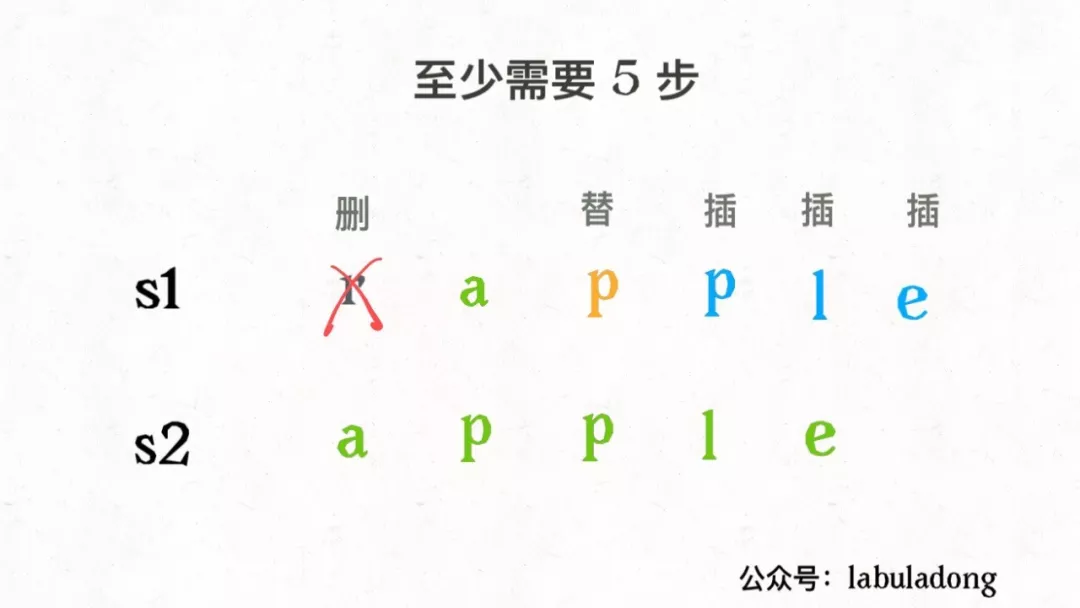
- 几种情况
- 两个字符相同
- j走完s2时,如果i还没走完s1
- i走完s1时j还没走完了s2
代码详解:暴力解法
- 梳理思路
- base case:i走完s1或j走完s2,可以直接返回另一个字符串剩下的长度。
对于每对子字符s1[i]和s2[j],可以由四种操作:

「三选一」到底该怎么选择呢?很简单,全试一遍,哪个操作最后得到的编辑距离最小,就选谁。这里需要递归技巧,理解需要点技巧,先看下代码:

理解递归代码(注意理解四种操作 在 dp函数 中的含义)
base case 不必解释
我们这里 dp(i, j) 函数的定义是这样的:
** def** **dp**(i, j) -> int<br /> # 返回 s1[0..i] 和 s2[0..j] 的最小编辑距离<br />1)**if** s1[i] == s2[j]: **return** dp(i - 1, j - 1) # 啥都不做<br />2)dp(i, j - 1) + 1, # 插入<br />3)dp(i - 1, j) + 1, # 删除<br />4)dp(i - 1, j - 1) + 1 # 替换
重叠子问题
- 快速发现重叠子问题:对于子问题dp(i-1,j-1),如何通过原问题dp(i,j)得到呢?有不止一条路径,比如dp(i,j)->#1和dp(i,j)->#2->#3。一旦发现一条重复路径,就说明存在巨量重复路径(重叠子问题)。
- 解决重叠子问题:备忘录 / DPtable
1)备忘录:注意备忘录是怎么设置参数的,参数代表什么含义

2)DP table
dp数组的含义,dp数组是二维数组, dp[i][j]的含义和之前的 dp 函数类似:
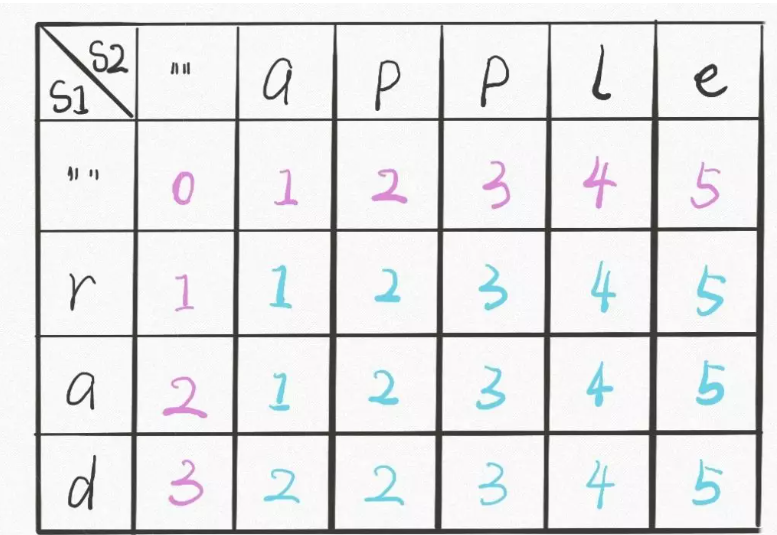
dp函数的base case:i,j等于 -1,而数组索引至少是 0,所以 dp 数组会偏移一位,dp[..][0]和dp[0][..]对应 base case。(偏移一位的含义:慢慢一位一位移动去dp[0][0])
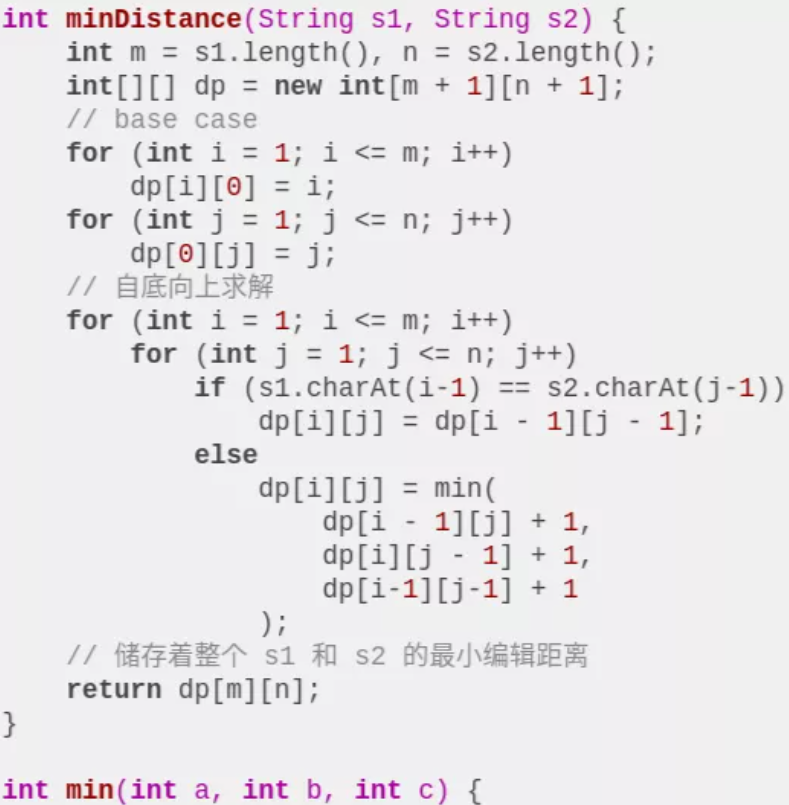
既然 dp 数组和递归 dp 函数含义一样,也就可以直接套用之前的思路写代码,唯一不同的是,DP table 是自底向上求解,递归解法是自顶向下求解:
扩展延伸
一般来说,处理两个字符串的动态规划问题,都是按本文的思路处理,建立 DP table。
- 为什么呢,因为易于找出状态转移的关系,比如编辑距离的 DP table:
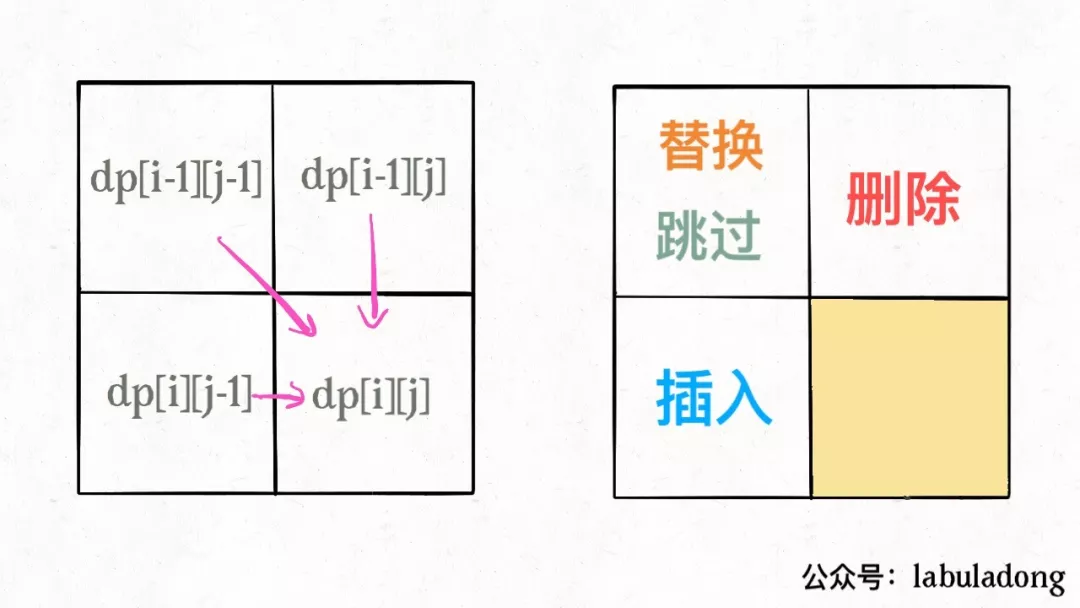
- 还有一个细节,既然每个dp[i][j]只和它附近的三个状态有关,空间复杂度是可以压缩成 O(min(M,N)) 的(M,N 是两个字符串的长度)。
只求最小的编辑距离,那具体操作是什么?
其实很简单,代码稍加修改,给 dp 数组增加额外的信息即可:val属性就是之前的 dp 数组的数值,choice属性代表操作。在做最优选择时,顺便把操作记录下来,然后就从结果反推具体操作。

最终结果不是dp[m][n]吗,这里的val存着最小编辑距离,choice存着最后一个操作,比如说是插入操作,那么就可以左移一格:
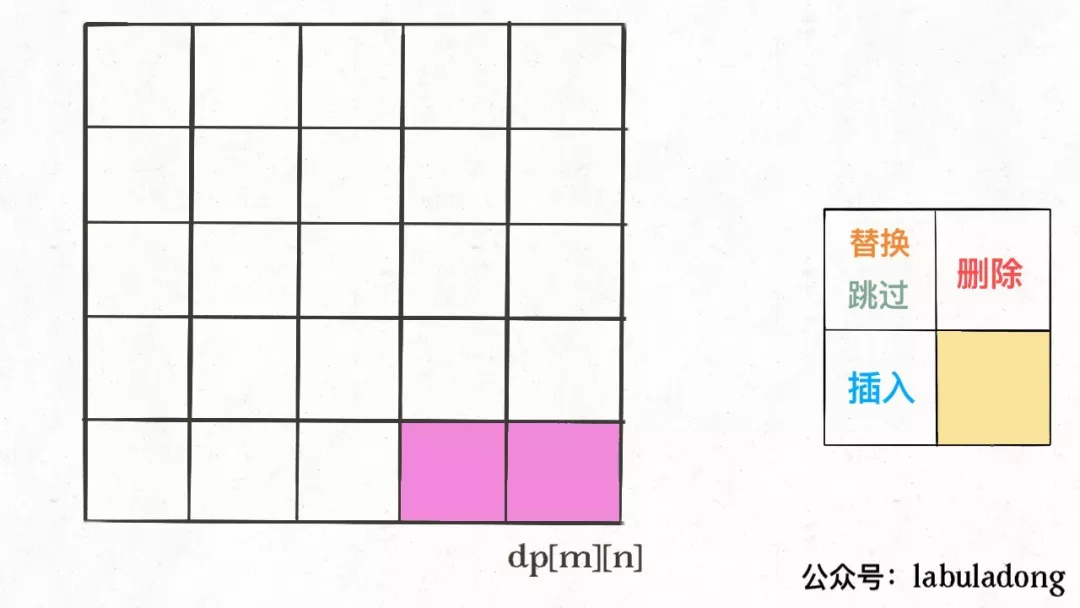
- 重复此过程,可以一步步回到起点dp[0][0],形成一条路径,按这条路径上的操作编辑对应索引的字符,就是最佳方案:
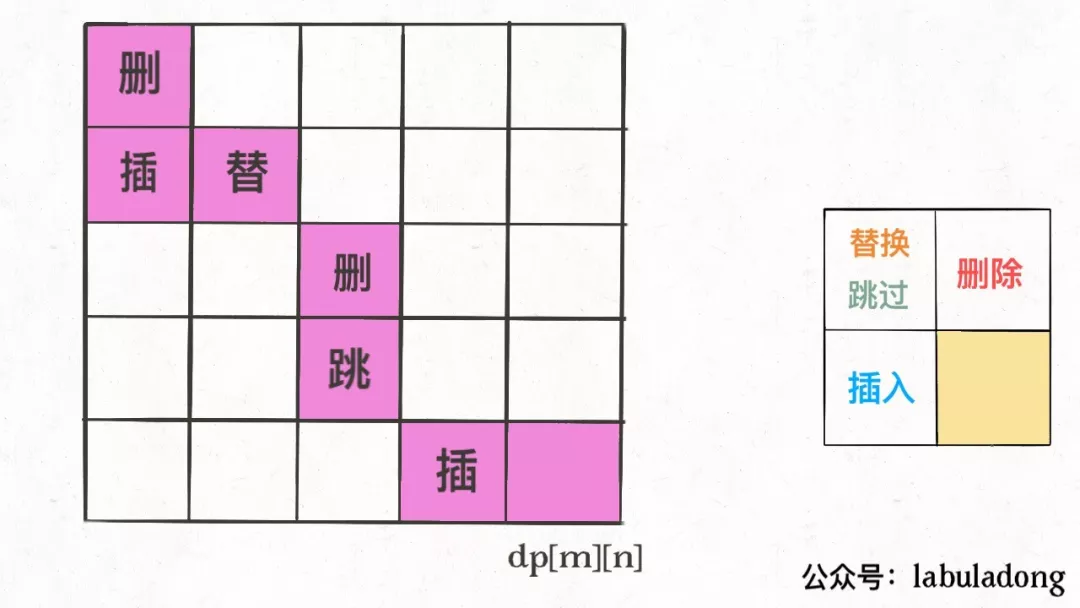
最长递增子序列
学会如何推状态转移方程
找到了问题的「状态」,明确了dp数组/函数的含义,定义了 base case;但是不知道如何确定「选择」,也就是不到状态转移的关系,依然写不出动态规划解法,怎么办?
- 数学归纳思想

动态规划解法
- dp数组
- dp[i] 表示以 nums[i] 这个数结尾的最长递增子序列的长度。
- nums[5] = 3,既然是递增子序列,我们只要找到前面那些结尾比 3 小的子序列,然后把 3 接到最后,新的子序列长度加一。显然,可能形成很多种新的子序列,但是只把最长子序列的长度作为 dp[5] 的值即可。
二分查找解法

- 我作了首诗,保你闭着眼睛也能写对二分查找 详细介绍了二分查找的细节及变体
信封嵌套问题
很多算法都需要排序技巧,其难点不在于排序本身,而是需要巧妙地排序进行预处理,将算法问题进行转换,为之后的操作打下基础。
- 信封嵌套问题就需要先按特定的规则排序,之后就转换为一个最长递增子序列问题
每次合法的嵌套是大的套小的,相当于找一个最长递增的子序列,其长度就是最多能嵌套的信封个数。
- 但难点在于,标准的 LIS 算法只能在数组中寻找最长子序列,而我们的信封是由(w,h)这样的二维数对形式表示的,如何把 LIS 算法运用过来呢?
思路
- 先对宽度w进行升序排序,如果遇到w相同的情况,则按照高度h降序排序。
- 之后把所有的h作为一个数组,在这个数组上计算 LIS 的长度就是答案。
- 这个解法的关键:对于宽度w相同的数对,要对其高度h降序排序。因为两个宽度相同的信封不能相互包含,而逆序排序保证在w相同的数对中最多只选一个计入 LIS —— 导致宽度相同的信封相互包含。
代码
- 为了清晰,我将代码分为了两个函数, 你也可以合并,这样可以节省下height数组的空间。
- 时间复杂度为O(NlogN),因为排序和计算 LIS 各需要 O(NlogN)的时间。
- 空间复杂度为O(N),因为计算 LIS 的函数中需要一个top数组。

拓展
其实这种问题还可以拓展到三维,比如说嵌套箱子,每个箱子有长宽高三个维度,算算最多能嵌套几个箱子?
- 我们可能会这样想,先把前两个维度(长和宽)按信封嵌套的思路求一个嵌套序列,最后在这个序列的第三个维度(高度)找一下 LIS,应该能算出答案。
- 实际上,这个思路是错误的。这类问题叫做「偏序问题」,上升到三维会使难度巨幅提升,需要借助一种高级数据结构「树状数组」
补充
Arrays.sort()
最大子数组和
思路
- 不能用滑动窗口算法
- 存在负数:这种情况下不知道什么时机去收缩左侧窗口,也就无法求出「最大子数组和」。
运用动态规划技巧
1)dp数组的定义:nums[0..i]中的「最大的子数组和」为dp[i]。
问:利用数学归纳法,不能用dp[i]推出dp[i+1]
- 实际上是不行的,因为子数组一定是连续的,按照我们当前dp数组定义,并不能保证nums[0..i]中的最大子数组与nums[i+1]是相邻的,也就没办法从dp[i]推导出dp[i+1]。
所以说我们这样定义dp数组是不正确的,无法得到合适的状态转移方程。对于这类子数组问题,我们就要重新定义dp数组的含义:
2)dp数组的定义:以nums[i]为结尾的「最大子数组和」为dp[i]。
想得到整个nums数组的「最大子数组和」,不能直接返回dp[n-1],而需要遍历整个dp数组:
<br />问:依然使用数学归纳法来找状态转移关系:假设我们算出了dp[i-1],如何推导出dp[i]呢?
可以做到,dp[i]有两种「选择」,要么与前面的相邻子数组连接,形成一个和更大的子数组;要么不与前面的子数组连接,自成一派,自己作为一个子数组。

状态压缩优化
时间复杂度是 O(N),空间复杂度也是 O(N),较暴力解法已经很优秀了。
- 不过注意到dp[i]仅仅和dp[i-1]的状态有关,那么我们可以进行「状态压缩」,将空间复杂度降低:
最长公共子序列
- 暴力算法不选用:把s1和s2的所有子序列都穷举出来,然后看看有没有公共的,然后在所有公共子序列里面再寻找一个长度最大的。
- 正确思路:不要考虑整个字符串,而是细化到s1和s2的每个字符。前文 子序列解题模板 中总结的一个规律:对于两个字符串求子序列的问题,都是用两个指针i和j分别在两个字符串上移动,大概率是动态规划思路。最长公共子序列的问题也可以遵循这个规律。
dp函数定义
// 定义:计算 s1[i..] 和 s2[j..] 的最长公共子序列长度
int dp(String s1, int i, String s2, int j)
- 这个dp函数的定义是:dp(s1, i, s2, j)计算s1[i..]和s2[j..]的最长公共子序列长度。
根据这个定义,那么我们想要的答案就是dp(s1, 0, s2, 0)
base case
base case :i == len(s1)或j == len(s2)时,因为这时s1[i..]或s2[j..]就相当于空串,最长公共子序列的长度0:

接下来,不要看s1和s2两个字符串,而是要具体到每一个字符,思考每个字符该做什么。
- 我们只看s1[i]和s2[j],如果s1[i] == s2[j],说明这个字符一定在lcs中:
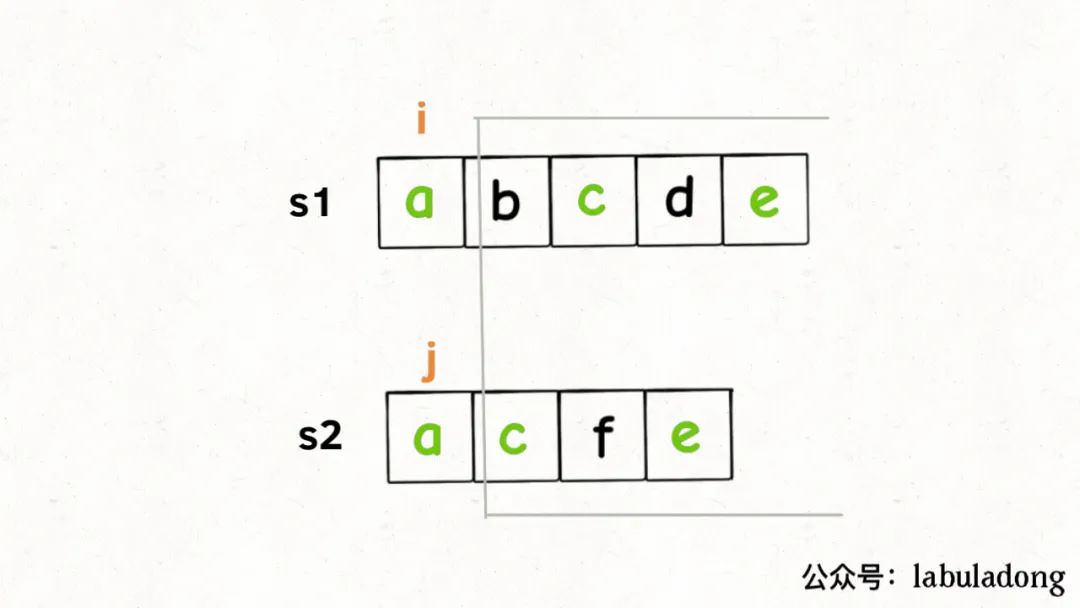
这样,就找到了一个lcs中的字符,根据dp函数的定义,我们可以完善一下代码:

- 但s1[i] != s2[j],应该怎么办呢?s1[i] != s2[j]意味着,s1[i]和s2[j]中至少有一个字符不在lcs中:
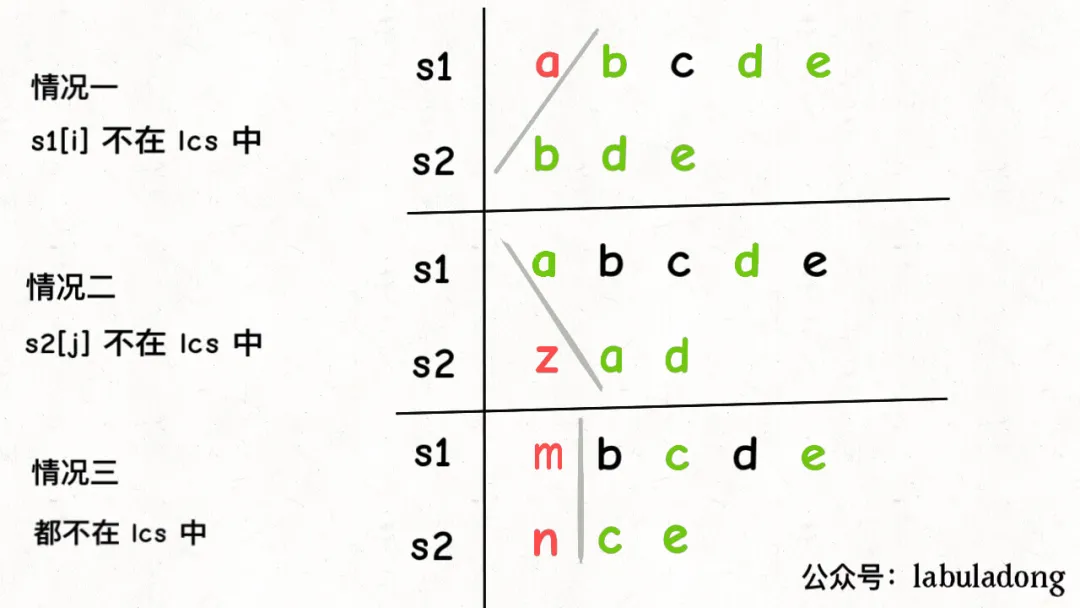
如上图,总共可能有三种情况,我怎么知道具体是那种情况呢?

因为我们在求最大值嘛,情况三在计算s1[i+1..]和s2[j+1..]的lcs长度,这个长度肯定是小于等于情况二s1[i..]和s2[j+1..]中的lcs长度的,因为s1[i+1..]比s1[i..]短嘛,那从这里面算出的lcs当然也不可能更长嘛。同理情况一。说白了,情况三被情况一和情况二包含了,所以可以直接忽略掉情况三,完整代码如下:

- 自底向上的解法
- 和递归解法有一点差异,而且由于数组索引从 0 开始,有索引偏移,不过思路和递归解法完全相同

- 自底向上的解法可以通过我们前文讲过的 动态规划状态压缩技巧
字符串的删除操作
最小ASCII删除和

若有收获,就点个赞吧
0 人点赞
