一、同步控制
1、synchronized 扩展:重入锁
ReentrantLock
重要方法:
lock():获得锁,如果锁已经被占用,则等待lockInterruptibly():获得锁,优先响应中断tryLock():尝试获得锁,成功返回TRUE,失败返回FALSE。该方法不会等待,立即返回tryLock(long time,TimeUnit unit):在给定时间内获得锁unlock():释放锁ReentrantLock(boolean fair)可申请一个公平锁
概念:同一个线程可以反复获取这个锁
简单案例
lock.lock();lock.lock();try{i++;}finnally{lock.unlock();lock.unlock();}
2、重入锁的好搭档:Condition
Condition的作用与Object.wait()与Object.notify()作用大致相同。与ReentrantLock相关联
创建:
可通过lock接口的Conditon newCondition()方法生成一个与之关联的Condition实例
关键方法:
await()使当前线程等待,并释放锁。与Object.await()相似singal()与singalAll():唤醒一个等待中的线程;唤醒所有等待中的线程。awaitUninterruptibly():与await()类似,但在等待时不会响应中断
注意:
使用时,必须持有相关的重入锁
参考:
JDK中的ArrayBlockingQueue的put与take方法
3、信号量(Semaphore)
信号量允许多个线程同时访问同一个资源
构造方法:
public Semaphore(int permits)可指定准入数public Semaphore(int permits,boolean fair)可指定准入数与是否公平
关键方法:
public void acquire()尝试获取准入许可(可以理解为令牌),如无法获得则会等待public void acquireUninterruptibly()不响应中断public void tryAcquire()不会等待,立即返回public void tryAcquire(long timeout,TimeUnit unit)不会等待,会等待一段时间public void release()释放一个许可
4、读写锁 ReadAndWriteLock
读写锁,对一个资源访问时,读与写可分离
读写锁的访问约束情况:
| 读 | 写 | |
|---|---|---|
| 读 | 非阻塞 | 阻塞 |
| 写 | 阻塞 | 阻塞 |
在系统中,如果读远大于写的操作,则读写锁可以发挥最大的功效
创建:
ReentrantReadAndWriteLock reentrantReadAndWriteLock = new ReentrantReadAndWriteLock();Lock readLock = reentrantReadAndWriteLock.readLock();Lock writeLock = reentrantReadAndWriteLock.writeLock();
从创建方法可以看出是是实现了Lock接口,所以使用与ReentrantLock相似。使用时注意区分读锁与写锁
5、倒计数器 CountDownLatch
Latch:门闩,可以理解为此。将所有线程关在门闩里,直到达到数量条件即开启门闩
场景:火箭发射
在火箭发射前,需要对各项指标进行检查,检查完毕后才可发射
构造:public CountDownLatch(int count) 接收一个参数作为计数器计数个数
重要方法:
与CountDownLatch类似,也可以实现线程间的技术等待。比CountDownLatch功能强大
循环之意,即为可以反复使用。此为一个可以反复使用的倒计数器
构造:public CyclicBarrier(int parties,Runnable barrierAction)
可接收一个Runnable作为参数,是计数器完成一次计数时,所做的动作。
parties是计数总数,也是参与的线程总数
方法:
await()阻塞等待,直到计数器完成一次计数,才往下执行。与上文CountDownLatch方法使用上有些许不同。执行的方法即为构造方法中的barrierAction
7、线程阻塞类 LockSupport
可以让线程在任意位置阻塞。弥补了resume() 方法导致线程无法执行的情况,也不需要像Object.wait()方法需要先获得某个对象的锁,也不会抛出InterruptedException异常
resume() :唤醒线程,但如果使用在suspend() 之前,则会永远阻塞线程。 suspend() :使线程挂起,但其不会释放任何资源,并且其挂起的状态仍然为Runnble
重要方法:
park()阻塞unpark()唤醒
LockSupport类使用的是类似于信号量的机制。它为每个线程准备了一个许可,如果可用,park()会马上返回,并消费这个许可。如果不可用则会阻塞。unpark()会使一个许可变成可用。
8、RateLimiter
RateLimiter是Guava中的一款限流工具,可以限制访问的速率。采用的是令牌桶算法。
扩展知识:
限流算法:
1、一种简单的限流算法,就是在一个单位时间内设定一定的请求数量。比如,在一秒之内允许10个请求。则可能会出现,在一秒内的前半秒没有请求,而这秒的后半秒和下一秒的前半秒共有20个请求。这对于其算法是合法的,但违反了我们使用其的基本需求。
2、漏桶算法
设置一个缓存区。当有请求进入时,无论其请求速率,都先保存在缓存区中,然后以固定的速率对其进行处理。其特点是无论外部压力如何,它总是以固定的速率处理数据。桶的容积和流出速率是该算法的重要参数
3、令牌桶算法
在令牌桶中,存放着一定数量的令牌,请求需要先拿到令牌才能进行处理。如果桶中没有可用的令牌,要么丢弃请求,要么等待。为了达到限流的目的,该算法在每个单位时间产生一定量的令牌存入桶中。比如,我们要求1秒内只能处理一个请求,则一秒只会产生一个令牌。当然,如果在单位时间内令牌没有被消耗,令牌下一秒不会再产生令牌,只能累积规定有限的令牌。
RateLimiter采用的则是令牌桶算法
创建:RateLimiter limiter = RateLimiter.create(2) 创建一个每秒只能处理两个请求的RateLimiter对象
重要方法:
limiter.acquire()用于控制流量,没有获得令牌的请求会阻塞在此处limiter.tryAcquire()不会阻塞,直接抛弃过载的请求
二、线程复用:线程池
1、概念
个人理解:线程池可以形象的理解为,有一个池子,存放了若干了线程。若我们需要,不必进行创建,只需要从池子里拿出一个现成的,已经创建好的线程去使用。当我们使用完了,不需要自行销毁,只需要将其归还给线程池即可。这样可以避免我们频繁的创建和销毁资源,造成资源浪费。
2、JDK对线程池的支持
在JDK并发包中,给我们提供了几个不同类型的线程池。主要提供了以下的工厂方法:
public static ExecutorService newFixedThreadPool(int nThreads)返回一个固定线程数量的线程池public static ExecutorService newSingleThreadPool()返回一个只有一个线程的线程池public static ExecutorService newCachedThreadPool()返回一个可以根据实际情况自动调整线程数量的线程池public static ScheduledExecutorService newSingleThreadScheduledExecutor()返回一个ScheduledExecutorService 对象,线程池大小为1。可以在某个固定延时后执行public static ScheduledExecutorService newScheduledThreadPool(int corePoolSise)可以指定线程池数量
创建:
以newFixedThreadPool()为例:Executors.newFixedThreadPool(10) 创建一个线程数为10的线程池
特别说明:**newScheduledThreadPool()**
主要方法:
public ScheduledFuture<?> schedule(Runnable command, long delay, TimeUnit unit);在给定时间后,对任务进行一次调度public ScheduledFuture<?> scheduleAtFixedRate(Runnable command,long initialDelay,long period,TimeUnit unit);对任务进行周期性调度,以上一个任务开始时的时间为时间间隔开始public ScheduledFuture<?> scheduleWithFixedDelay(Runnable command,long initialDelay,long delay,TimeUnit unit);对任务进行周期性调度,以上一个任务结束时的时间为时间间隔开始注:如果任务执行时间大于间隔时间,则任务结束后会立即执行下一次任务。如果没有进行异常处理,则一个任务抛出异常,后面的所有执行都会被中断。
3、核心线程池的内部实现
JDK提供的返回ExecutorService对象的工厂方法,其实都是对ThreadPoolExecutor类的封装。(返回ScheduledExecutorService对象的则是封装了ScheduledThreadPoolExecutor对象,而ScheduledThreadPoolExecutor对象也是继承了ThreadPoolExecutor对象)
构造方法:
public ThreadPoolExecutor(int corePoolSize,int maximumPoolSize,long keepAliveTime,TimeUnit unit,BlockingQueue<Runnable> workQueue,ThreadFactory threadFactory,RejectedExecutionHandler handler)
七个参数含义如下:
- corePoolSize:指定线程池中线程的数量(核心线程数)
- maximumPoolSize:指定线程池中最大的线程数量
- keepAliveTime:当线程数超过corePoolSize时,多余的空闲线程的存活时间
- unit:KeepAliveTime的单位
- workQueue:任务队列,被提交但尚未被执行的任务
- threadFactory:线程工厂,用于创建线程。一般使用默认的即可
- handler:拒绝策略。任务过多无法处理时采用的策略
队列中workQueue可使用的几种BlockingQueue:
- 直接提交的队列 SynchronousQueue:是一个特殊的BlockingQueue,它没有容量,每一个插入操作都要等一个删除操作,反之,每一个删除操作都要等待一个对应的插入操作。如果使用此队列,则提交的任务不会被真实保存,而是将新任务立即提交给线程执行。如果没有空闲的线程,则会创建新的线程。
- 有界的任务队列 ArrayBlockingQueue:此队列必须有一个容量参数,表示该队列的最大容量。如果创建的线程已经达到corePoolSize并没有空闲线程,则新提交的任务会先保存在此队列中。如果此队列也存满了任务,则会创建新的线程去处理任务。最多可以创建maximumPoolSize个线程。如果maximumPoolSize个线程仍然处理不了过量的任务,则会执行拒绝策略。
- 无界的任务队列 LinkedBlockingQueue:除非资源耗尽,否则不会出现任务入列失败的情况。
- 优先任务队列 PriorityBlockingQueue:它可以控制任务执行的先后顺序,它是一个特殊的无界队列。可以根据任务自身的优先级顺序先后执行
4、拒绝策略:
- AbortPolicy:直接抛出异常,阻止系统正常工作
- CallerRunsPolicy:只要线程池未关闭,该策略直接在调用者线程中执行被丢弃的任务。
- DiscardOldestPolicy:丢弃最老的(即将被执行的)一个任务,并尝试提交当前任务
- DiscardPolicy:默默丢弃无法处理的任务,不予任何处理。
拒绝策略都实现了RejectedExecutionHandler接口
可以自己自定义拒绝策略:
例子:
new ThreadPoolExecutor(5, 5,0L, TimeUnit.SECONDS,new LinkedBlockingDeque<>(), new RejectedExecutionHandler() {@Overridepublic void rejectedExecution(Runnable r, ThreadPoolExecutor executor) {System.out.println(r.toString() + "is discard");}});
5、自定义线程创建:ThreadFactory
ThreadFactory是一个接口,他只有一个方法:Thread newThread_(_Runnable r_)_; 当线程池需要创建新线程时,就会掉用这个方法。
自定义线程工厂可以帮我们跟踪线程池中线程的数量,自定义线程的名称,组,以及优先级等信息。或者可以将所有线程都设置为守护线程。
例子:
new ThreadPoolExecutor(5, 5, 0L, TimeUnit.MILLISECONDS,new SynchronousQueue<>(), new ThreadFactory() {@Overridepublic Thread newThread(Runnable r) {Thread thread = new Thread(r);thread.setDaemon(true);System.out.println("create:"+thread);return thread;}});
6、扩展线程池
ThreadPoolExecutor是一个可以扩展的线程池,它提供了beforeExecute()、afterExecute()、terminated()三个接口来对线程池进行控制。
ThreadPoolExecutor.Worker 是 ThreadPoolExecutor 的内部类,它是一个实现了 Runnable接口的类。ThreadPoolExecutor线程池中的工作线程也正是Worker实例。Worker.run()方法会调用上述 ThreadPoolExecutor. runWorker(Worker w)实现每一个工作线程的固有工作。

进入runWorker()方法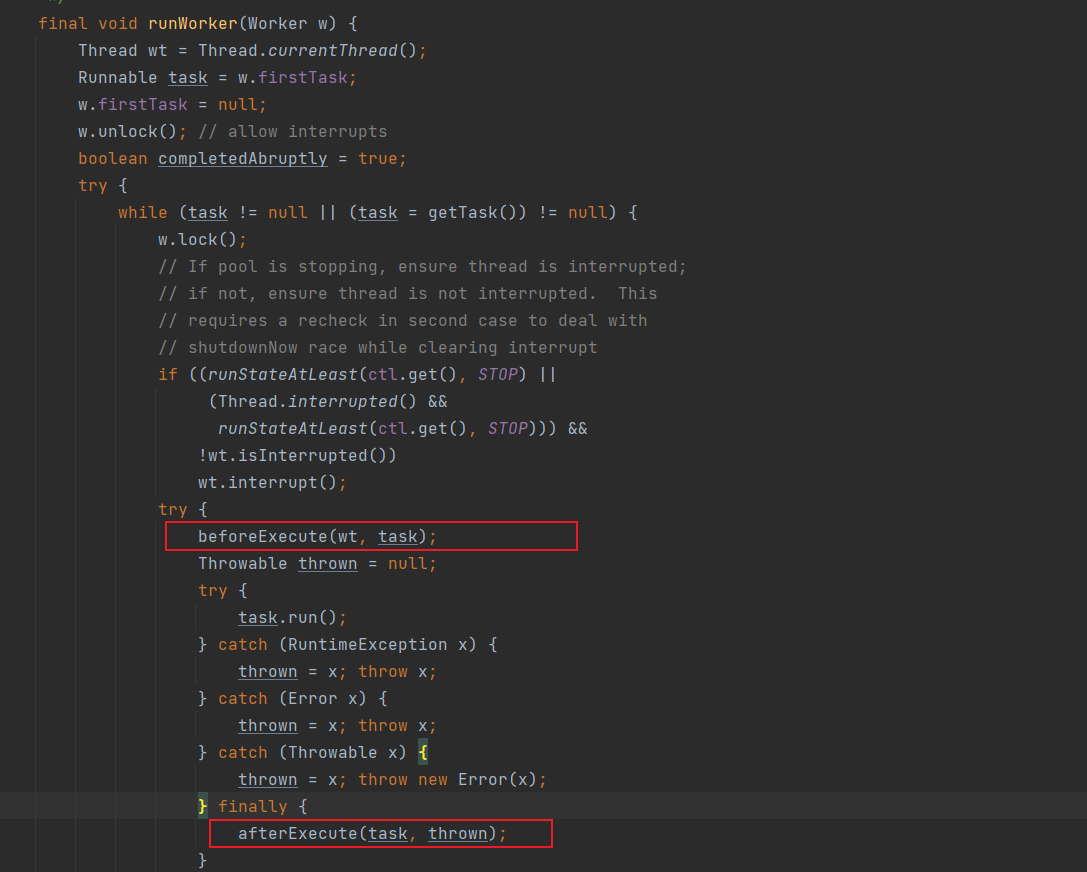
new ThreadPoolExecutor(5,5,0L,TimeUnit.MILLISECONDS,new LinkedBlockingQueue<Runnable>()){@Overrideprotected void beforeExecute(Thread t, Runnable r) {System.out.println("准备执行:"+t.getName());super.beforeExecute(t, r);}@Overrideprotected void afterExecute(Runnable r, Throwable t) {System.out.println("执行完成:");super.afterExecute(r, t);}@Overrideprotected void terminated() {System.out.println("线程池退出");super.terminated();}};
7、优化线程池线程数量
对于估算线程池的最优大小,可以参考《Java Concurrency in Practice》 一书中给出的估算公式:
Ncpu = CPU数量
Ucpu = 目标CPU的使用率,0≤Ucpu≤1
W/C = 等待时间与计算时间的比率
获取可用CPU数量:Runtime.getRuntime().availableProcessors()
8、在线程池中寻找堆栈(幽灵错误)
案例:
public class Demo implements Runnable{int a,b;public Demo(int a ,int b){this.a =a;this.b =b;}@Overridepublic void run(){double re = a/b;System.out.println(re);}public static void main(String[] args) throws Exception{ExecutorService executorService = Executors.newFixedThreadPool(5);for (int j = 0; j < 5; j++) {executorService.submit(new Demo(100,i)); // 注意,这里j为0时分母将会为0}}}
执行后,结果会少一个。但没有任何错误提示。
解决:
- 最简单的方法就是用
execute()代替submit()方法。 ```java executorService.execute(new Demo(100,i)) //或者
Future re = executorService.submit(new Demo(100,i)) re.get();
这两种都可以获得部分堆栈信息。只能获取到异常是在哪里抛出的(a/b),但不知道是在哪里提交这个任务的。我们可以通过改造线程池,让它在调度任务之前,保存提交任务线程的堆栈信息:```javapublic class TraceThreadPoolExecutor extends ThreadPoolExecutor {public TraceThreadPoolExecutor(int corePoolSize, int maximumPoolSize, long keepAliveTime, TimeUnit unit, BlockingQueue<Runnable> workQueue) {super(corePoolSize, maximumPoolSize, keepAliveTime, unit, workQueue);}@Overridepublic void execute(Runnable command) {super.execute(command);}@Overridepublic Future<?> submit(Runnable task) {return super.submit(wrap(task,clientTrace(),Thread.currentThread().getName()));}private Exception clientTrace(){return new Exception("Client stack trace");}private Runnable wrap(final Runnable task,final Exception exception,String threadName){return new Runnable() {@Overridepublic void run() {try {task.run();}catch (Exception e){exception.printStackTrace();throw e;}}};}}
使用改造后的ThreadPoolExecutor就可以得到比较全面的堆栈信息了
9、分而治之:Fork/Join框架
假如我们需要处理1000个数据,但我们一次只能处理10个,我们可以将其拆分为100个,分阶段处理100次,最后将其结果进行合成,最终得到我们想要的结果。这就是Fork/Join框架做的事情。
方法:
fork()可以创建一个子线程来分割任务。join()等待其他线程执行完毕

由于线程池的优化,线程(ForkJoinWorkerThread)与任务并不是一对一的关系,通常一个线程需要处理多个逻辑任务。所以每个线程都拥有一个任务队列(work queue)。如果线程A已经把所有任务都执行完了,但线程B还有一堆任务,这是线程A就会从B的任务队列中拿一个过来处理。
构造:
public ForkJoinPool(int parallelism,ForkJoinWorkerThreadFactory factory,UncaughtExceptionHandler handler,boolean asyncMode)
- parallelism:可并行级别,Fork/Join框架将依据这个并行级别的设定,决定框架内并行执行的线程数量。并行的每一个任务都会有一个线程进行处理,但是千万不要将这个属性理解成Fork/Join框架中最多存在的线程数量,也不要将这个属性和ThreadPoolExecutor线程池中的corePoolSize、maximumPoolSize属性进行比较,因为ForkJoinPool的组织结构和工作方式与后者完全不一样。而后续的讨论中,读者还可以发现Fork/Join框架中可存在的线程数量和这个参数值的关系并不是绝对的关联(有依据但并不全由它决定)。
- 当asyncMode设置为ture的时候,队列采用先进先出方式工作;反之则是采用后进先出的方式工作,该值默认为false
使用:
- 接口:
public <T> ForkJoinTask<T> submit(ForkJoinTask<T> task)
可以想ForkJoinPool线程池提交一个ForkJoinTask任务。ForkJoinTask任务就是支持fork()和join()的任务。ForkJoinTask有两个重要的子类。RecursiveAction类(带返回值)与RecursiveTask类(不带返回值)
案例可参考 https://blog.csdn.net/tyrroo/article/details/81390202
ForkJoin 使用一个无锁的栈来管理空闲线程。如果线程没有可用的任务,就可能被挂起,被压入由线程池维护的栈中。
10、Guava中对线程池的扩展
对线程池的扩展类:MoreExecutors
- DirectExecutor 没有创建或使用额外的线程,总是将任务在当前线程中直接执行。
MoreExecutors.directExecutor()
文中描述:
对于线程池来说,其技术目的是为了复用线程以提高运行效率,但其业务需求却是去异步执行一段业务指令。但是有时候,异步并不是必要的。因此,当我们剥去线程池的技术细节,仅关注其使用场景时便不难发现,任何一个可以运行Runnable实例的模块都可以被视为线程池,即便它没有真正创建线程。这样就可以将异步执行和同步执行进行统一,使用统一的编码风格来处理同步和异步调用,进而简化设计。
- Daemon 线程池
MoreExecutors.getExitingExecutorService(ThreadPoolExecutor executor)
此方法可以使普通线程池传唤为守护线程池。
三、JDK并发容器
1、简介
这里主要介绍:
- ConcurrentHashMap:高效并发的HashMap
- CopyOnWriteArrayList:这是一个List,适合读多写少的场合
- ConcurrentLinkedQueue:高效并发队列,使用链表实现。可以看做一个线程安全的LinkedList
- BlockingQueue:这是一个接口,实现了很多子类集合。适合作为数据共享的通道
- ConcurrentSkipListMap:跳表,是一个Map,适合快速查找
除此之外,还有Vector、HashTable等数据结构是线程安全的,但是在性能上是弱很多的。另外,Collections工具类可以将任意集合包装成线程安全的集合。
2、线程安全的HashMap
1、可以使用Collections.synchronizedMap()方法包装我们的HashMap。如下:public static Map m = Collections.synchronizedMap(new HashMap());
会返回一个SynchronizedMap的Map。具体实现原理如下:
public static <K,V> Map<K,V> synchronizedMap(Map<K,V> m) {return new SynchronizedMap<>(m);}/*** @serial include*/private static class SynchronizedMap<K,V>implements Map<K,V>, Serializable {private static final long serialVersionUID = 1978198479659022715L;private final Map<K,V> m; // Backing Mapfinal Object mutex; // Object on which to synchronize// get方法public V get(Object key) {synchronized (mutex) {return m.get(key);}}
除了包装了一个Map用于实现基本的Map的功能,还有一个mutex。所有方法都需要去获得mutex锁,以此来保证线程安全。
当然,还有一个更加专业的HashMap,concurrentHashMap。
concurrentHashMap 在JDK1.7与JDK1.8中的实现并不相同。
1.7中使用 数组+链表的实现方式。其采用的是分段锁技术来实现线程安全的。它将内部分为了很多个小段(segment), 默认情况下为16段。如果需要新增一个元素,先根据hashcode得到元素应该放在哪个段中,然后对该段加锁。也就是说,最多可以接受16个线程同事插入。
1.8中使用数组+链表+红黑树的结构(类似于1.8HashMap)。抛弃了原来的Segment分段锁,采用CAS + synchronized来保证并发安全性。将HashEntry改为Node。如果要加入一个元素,需要根据key计算出hashcode,再判断其是否需要初始化,后根据key定位出的Node,如果为空表示当前位置可以写入数据,利用CAS尝试写入,失败则自旋。如果都失败了,则会利用synchronized锁写入数据。
3、有关List的线程安全
1、Vector
2、可以使用Collections.synchronizedList()方法包装
4、高效读写队列:ConcurrentLinkedQueue类
算是高并发环境中性能最好的队列

其对Node进行操作时,使用了CAS。
ConcurrentLinkedQueue类内部有两个重要的字段,head和tail,分别表示头部和尾部。
具体实现请参考https://blog.csdn.net/u013991521/article/details/53068549
5、高效读取:不变模式下的CopyOnWriteArrayList
在读的操作远大于写操作的场景中,CopyOnWriteArrayList是一个非常好的选择。它不仅读读不会阻塞,读写也是不会相互阻塞的,只有写写会需要等待。
其实现原理是,当我需要进行写操作时,需要进行一次自我复制,然后对其副本进行修改,再用修改后的数据替换掉原来的数据。
读操作是没有任何同步控制与锁操作的,因为写操作是会被另一个替换,可以保证数据安全。另外,array变量是volatile类型,可以保证修改后,读取线程可以读取到这次修改。
6、数据共享通道:BlockingQueue
BlockingQueue是一个接口,它有一些具体实现,如下:
主要学习ArrayBlockingQueue类和LinkedBlockingQueue类。
ArrayBlockingQueue是基于数组的,适合做有界队列,而LinkedBlockingQueue适合做无界队列。
向队列压入元素:offer():如果当前队列已经满了,它会立即返回FALSE,如果没有满则正常进行入队操作。put():如果队列满了,它会一直等待,直到队列中有空闲的位置。
弹出元素:poll():从队列头部弹出一个元素,如果队列为空,则返回nulltake():如果队列为空,此方法会等待,直到队列内有可用元素
所以put()和take()才能体现Blocking的关键。
在ArrayBlockingQueue中有这样的实现
当进行take()操作时,如果队列为空,则让当前线程在notEmpty上等待,如果有新元素入队,则进行notEmpty上的通知。
public E take() throws InterruptedException {final ReentrantLock lock = this.lock;lock.lockInterruptibly();try {while (count == 0)notEmpty.await();return dequeue();} finally {lock.unlock();}}
当有元素入队时,调用put或offer方法,会在方法内部调用enqueue方法。:
private void enqueue(E x) {// assert lock.getHoldCount() == 1;// assert items[putIndex] == null;final Object[] items = this.items;items[putIndex] = x; // putIndex表示尾部元素在数组中的位置if (++putIndex == items.length)putIndex = 0;count++;notEmpty.signal(); // 唤醒在notEmpty上等待的代码}
同理,调用put()方法时也会有同样的阻塞。
ArrayBlockingQueue是一个环形队列,当头元素到达数组的尾部时,会判断数组的头部是否存在元素,如果不存在,则头部的下标会归零,回到数组头部。

7、跳表
跳表是一种可以对元素进行快速查找的结构。并且在对其进行插入或删除操作时,只需要一个部分锁即可。
跳表的本质是维护了多个链表,并且链表是分层的。每上面一层链表都是下面一层链表的子集。
跳表内的所有链表的元素都是排序的。查找时,可以从顶级链表开始找。如果发现查找的元素大于当前链表中的值,就会转入下一层继续寻找。实际上是一种使用空间换时间的算法。
四、JMH性能测试

若有收获,就点个赞吧
0 人点赞
