数组
go的数组与C的数组不同,C的数组名表示第一个元素的地址,go数组是值语义,一个数组名表示整个数组,不是指向第一个元素的指针,一个数组变量被赋值或传递的时候,实际上会复制整个数组,为避免复制可自定义指向数组的指针数组字面值。
b := [2]string{"Penn", "Teller"} //自己指定长度b := [...]string{"Penn", "Teller"} //编译器自动指定长度
数组[]内的长度表达式必须为常数,比如:
var a intvar [a] int // 错误,长度表达式必须为常数
数组的用法:
type Currency intconst (USD Currency = iota // 美元EUR // 欧元GBP // 英镑RMB // 人民币)symbol := [...]string{USD: "$", EUR: "€", GBP: "£", RMB: "¥"}fmt.Println(RMB, symbol[RMB]) // "3 ¥"
数组的元素类型是可以相互比较的,那么数组类型也是可以相互比较的,这时候我们可以直接通过==比较运算符来比较两个数组:
a := [2]int{1, 2}b := [...]int{1, 2}c := [2]int{1, 3}fmt.Println(a == b, a == c, b == c) // "true false false"d := [3]int{1, 2}fmt.Println(a == d) // compile error: cannot compare [2]int == [3]int
结构体
// 结构体创建type Employee struct {ID intName stringAddress stringDoB time.TimePosition stringSalary intManagerID int}// 结构体访问var dilbert Employeedilbert.Salary -= 5000var employeeOfTheMonth *Employee = &dilbertemployeeOfTheMonth.Position += " (proactive team player)"// 等价于 (*employeeOfTheMonth).Position += " (proactive team player)"// 初始化type Point struct{ X, Y int }p := Point{1, 2} // 方式1p := Point{Y:1} // 方式2,X自动为0值
匿名成员
只声明一个成员对应的数据类型而不指名成员的名字;这类成员就叫匿名成员。匿名成员的数据类型必须是命名的类型或指向一个命名的类型的指针。下面的代码中,Circle和Wheel各自都有一个匿名成员。我们可以说Point类型被嵌入到了Circle结构体,同时Circle类型被嵌入到了Wheel结构体。
type Point struct {X, Y int}type Circle struct {PointRadius int}type Wheel struct {CircleSpokes int}// 得益于匿名嵌入的特性,我们可以直接访问叶子属性而不需要给出完整的路径var w Wheelw.X = 8 // equivalent to w.Circle.Point.X = 8w.Y = 8 // equivalent to w.Circle.Point.Y = 8w.Radius = 5 // equivalent to w.Circle.Radius = 5w.Spokes = 20
空结构体
什么是空结构体?
就是内容为空的结构体,举例:
type cat struct {}
空结构体大小是多少?如何存储?
举例:
type cat struct{}func main() {c0, c1 := cat{}, cat{}fmt.Println(unsafe.Sizeof(c0), unsafe.Sizeof(c1))fmt.Printf("%p\n%p\n", &c0, &c1)}
运行结果: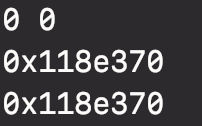
说明空结构体大小为 0,且统一使用一个地址。事实上,所有大小为 0 的变量的地址都为同一个,即 runtime/malloc.go中的:
// base address for all 0-byte allocationsvar zerobase uintptr
空结构体什么时候使用?
空结构体的主要用途为节约空间,比如用 go map 实现一个类似 set 的结构(go 没有 set):
m := make(map[int]struct{})m[1], m[0] = struct{}{}, struct{}{}
slice
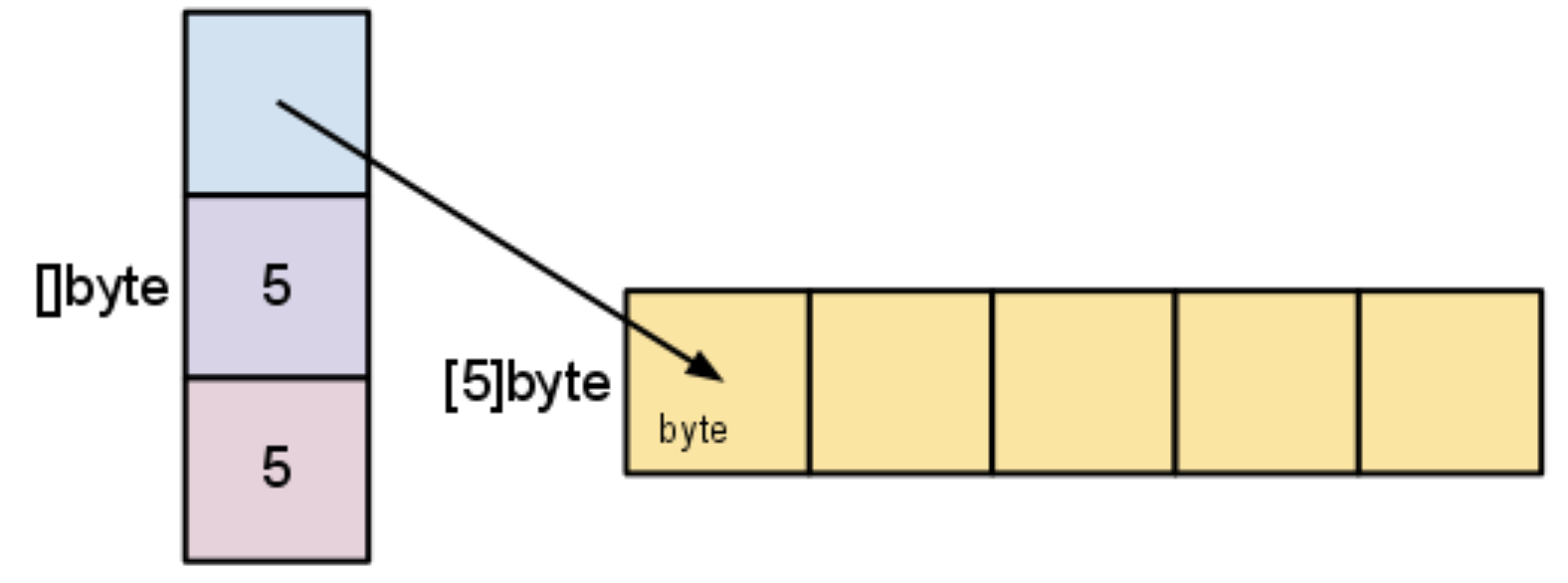
slice是一个轻量级的数据结构,由三部分构成:底层数组某个元素的指针、长度和容量。
长度 len 为指针指向的元素到切片指定的尾元素的长度;
长度 cap 为指针指向的元素到数组末尾的长度。
举例:
var arr = [5]int{1, 2, 3, 4, 5}slice := arr[1:3] // 两边的范围值为左闭右开// 此时slice底层指针指向数组的第二个元素,len(slice) = 2, cap(slice) = 4slice1 := slice[1:]// 此时slice1的指针指向数组的第三个元素,len(slice1) = 1, cap(slice1) = 3
切片的底层结构
type slice struct {array unsafe.Pointerlen intcap int}
slice 的创建
根据字面量创建
package mainimport "fmt"func main() {s := []int{1, 2, 3}fmt.Println(s)}
通过生成 plan9 汇编分析:go build -gcflags -S main.go
可以看出 slice 的创建过程为:
- 对已知数组的引用
- 使用 make 方法,实际调用的是 rumtime/malloc.go 中的 makeslice 方法
append
由于底层数组容量有限,使用内置的append增加切片元素时,可能需要重新分配一个更大的底层数组。
测试:
func main() {var slice []intfor i := 0; i < 10; i++ {slice = append(slice, i)fmt.Printf("%d cap = %d \t%v\n", i, cap(slice), slice)}}// 运行结果:// 0 cap = 1 [0]// 1 cap = 2 [0 1]// 2 cap = 4 [0 1 2]// 3 cap = 4 [0 1 2 3]// 4 cap = 8 [0 1 2 3 4]// 5 cap = 8 [0 1 2 3 4 5]// 6 cap = 8 [0 1 2 3 4 5 6]// 7 cap = 8 [0 1 2 3 4 5 6 7]// 8 cap = 16 [0 1 2 3 4 5 6 7 8]// 9 cap = 16 [0 1 2 3 4 5 6 7 8 9]
扩容逻辑
func growslice(et *_type, old slice, cap int) slice {......newcap := old.capdoublecap := newcap + newcapif cap > doublecap { //newcap = cap} else {if old.cap < 1024 { // 如果小于 1024 则翻倍newcap = doublecap} else {// 如果大于 1024 每次扩 1/4for 0 < newcap && newcap < cap {newcap += newcap / 4}// 如果越界if newcap <= 0 {newcap = cap}}}......}
string
string定义
标准库buildin的描述 :
// string is the set of all strings of 8-bit bytes, conventionally but not// necessarily representing UTF-8-encoded text. A string may be empty, but// not nil. Values of string type are immutable.type string string
可总结特点如下:
- string是一系列字节(byte/unit8)的集合;
- string可以为空,但是不能为nil;
- string对象不可更改;
string 底层结构
所以 string 类型的大小永远为指针大小加上 int 的大小(在64位计算机下为 8 + 8 = 16)。type stringStruct struct {str unsafe.Pointer // 指向一个 byte 数组len int}
如何获取底层数组长度?
通过 reflect 包提供的结构:
示例:// StringHeader is the runtime representation of a string.// It cannot be used safely or portably and its representation may// change in a later release.// Moreover, the Data field is not sufficient to guarantee the data// it references will not be garbage collected, so programs must keep// a separate, correctly typed pointer to the underlying data.type StringHeader struct {Data uintptrLen int}
func main() {s := "hello, 富贵猪"// 先转为万能指针 usafe.Pointer 再转为 reflec.StringHeader 指针strHeader := (*reflect.StringHeader)(unsafe.Pointer(&s))fmt.Println(strHeader.Len)}
其实使用 builtin 包提供的 len() 就可以获取底层数组长度,这里只是理解一下源码。
为什么 string 不可更改?
为了节约 string 相关操作的成本,因为 string 不可更改,所以 string 对应的底层数据也是不可更改的。所以对应的底层操作就可以简化,比如:
- 拷贝操作:复制一下底层指针和判断一下长度就行了;
-
字符串面值
"hello, world",将一系列字节序列包含在双引号内就是一个字符串面值。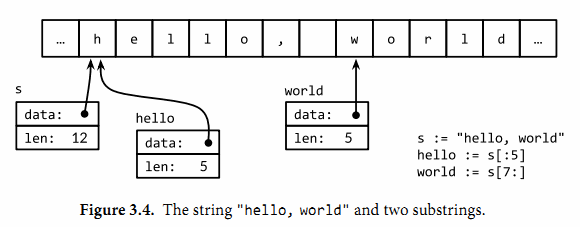
由于Go源文件默认用UTF-8编码,所以字符串面值可以存放Unicode码点。
注意:UTF-8中一个中文字符占 3 字节。string 遍历
注意比较两种遍历方式的异同:
func main() {s := "hello, 富贵猪"for _, v := range s {fmt.Printf("%v ", v)}fmt.Println()for i := 0; i < len(s); i++ {fmt.Printf("%v ", s[i])}}
输出:

出现这样结果的原因是: 使用下标遍历时,输出的是 byte 数组每个字节的大小(一个中文 3 字节)。
使用 range 遍历字符串时,在编译时
runtime/uft8.go中的 utf8 解析器会被调用。“” 与 `` 包含的字符串有什么不同?
""包含的字符串面值中,可以用以反斜杠\开头的转义符:\a 响铃\b 退格\f 换页\n 换行\r 回车\t 制表符\v 垂直制表符\' 单引号(只用在 '\'' 形式的rune符号面值中)\" 双引号(只用在 "..." 形式的字符串面值中)\\ 反斜杠
<a name="VqWOv"></a>## string 和 []byte字符串和字节slice之间可以相互转换:```gos := "abc"b := []byte(s)s2 := string(b)
string 转化为 []byte 是会发生内存拷贝的,理论上任何的强制类型转换都会发生内存拷贝。
bytes 和 strings 包提供的实用函数
func Contains(s, substr string) boolfunc Count(s, sep string) intfunc Fields(s string) []stringfunc HasPrefix(s, prefix string) boolfunc Index(s, sep string) intfunc Join(a []string, sep string) stringfunc Contains(b, subslice []byte) boolfunc Count(s, sep []byte) intfunc Fields(s []byte) [][]bytefunc HasPrefix(s, prefix []byte) boolfunc Index(s, sep []byte) intfunc Join(s [][]byte, sep []byte) []byte
string 和 数字
整数转string:
x := 123y := fmt.Sprintf("%d", x)fmt.Println(y, strconv.Itoa(x)) // "123 123"// 转化为不同进制fmt.Println(strconv.FormatInt(int64(x), 2)) // "1111011"s := fmt.Sprintf("x=%b", x) // "x=1111011", 还有%d、%o和%x等参数可以用
字符串解析为整数(注意可能发生错误,因为字符串对应的不一定是数字:
x, err := strconv.Atoi("123") // x is an inty, err := strconv.ParseInt("123", 10, 64) // base 10, up to 64 bits
string 拼接
当需要拼接少量字符串时,直接使用+号拼接,速度最快。
当需要拼接大量字符串时,使用bytes.buffer,使用缓冲区加快拼接。
var str1 bytes.Bufferstr1.WriteString("hello ")str1.WriteString("world")fmt.Println("buffer :", str1.String())
Map
在Go中,map是对一个哈希表的引用:
- Key:只能是可以比较大小的元素,因为map要判断给定key和已存储key是否相等来确定是否存在哈希表中;
- Value:可为任意类型;
map操作
```go // 初始化 ages := make(map[string]int)
ages := map[string]int{}
ages := map[string]int{ “alice”: 31, “charlie”: 34, }
// delete delete(ages, “alice”)
// 判断key是否存在 if age, ok := ages[“bob”]; !ok { / … / }
<a name="qATwD"></a>## map 的底层结构go 的 map 底层是对一个使用拉链法的 hashmap 的引用。```go// A header for a Go map.type hmap struct {count int // 总键值对的数量,即 len()flags uint8B uint8 // buckets 的数量为 2^Bnoverflow uint16 // 溢出的 buckets 数目的近似值; see incrnoverflow for detailshash0 uint32 // hash seedbuckets unsafe.Pointer // 长度为 2^B 的 Buckets 数组,count == 0 则为 niloldbuckets unsafe.Pointer // 扩容时 oldbuckets 数组的指针nevacuate uintptr // buckets 地址小于该值表示迁移完成extra *mapextra // optional fields}......// A bucket for a Go map.type bmap struct {// tophash 存储哈希值的第一个字节(前八位),每个 bucket 存储 bucketCnt(8)个键值对。// 如果 tophash[0] < minTopHash, tophash[0] 表示该桶以搬迁完毕。tophash [bucketCnt]uint8// tophash 后面的是 key 数组和 elem 数组// NOTE: 使用 key/key/key.../elem/elem/elem...的格式存储// 而不是 key/elem/key/elem/...// 这样可以节约字节对齐的开销,比如 map[int64]int8// 最后有一个溢出指针}
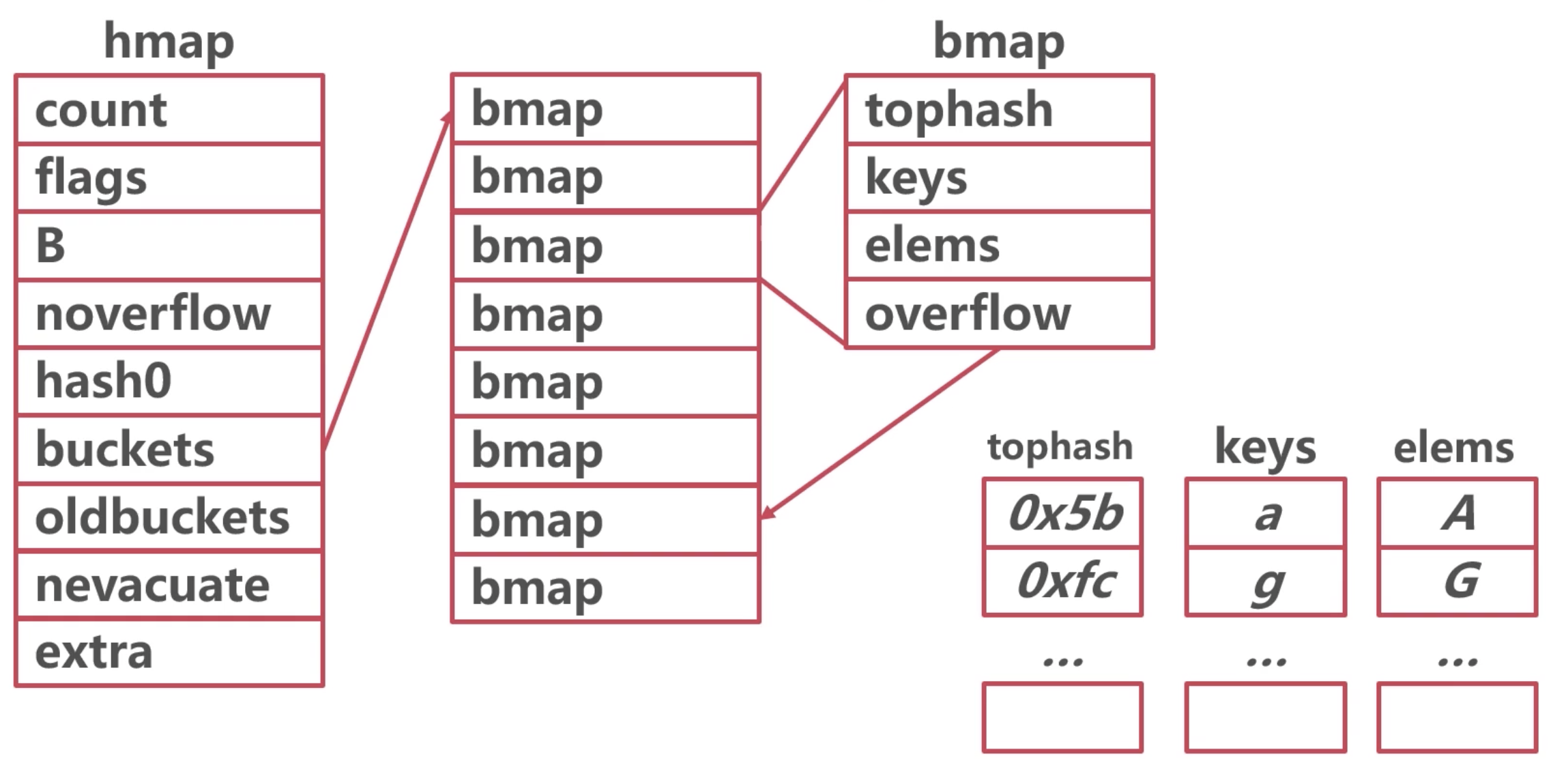
注意事项
为什么不能对map的元素进行取址?
原因是map可能随着元素数量的增长而重新分配更大的内存空间,从而可能导致之前的地址无效。
为什么map每次遍历的顺序都不一致?
这是故意的,每次都使用随机的遍历顺序可以强制要求程序不会依赖具体的哈希函数实现。因为每次扩容、缩容的时候可能发生rehash,导致原有的次序改变,所以这种次序是不可靠的,go干脆就故意随机每次的遍历顺序来避免程序员利用这个不可靠的点。
想要有序的遍历,参考如下实现:
import "sort"names := make([]string, 0, len(ages))for name := range ages {names = append(names, name)}sort.Strings(names)for _, name := range names {fmt.Printf("%s\t%d\n", name, ages[name])}
map类型的零值?
map类型的零值是nil,也就是没有引用任何哈希表。
注意:在使用map读和存的时候,必须保证其不为空(保证底层引用了哈希表)
map 初始化
使用 make 初始化
// makemap implements Go map creation for make(map[k]v, hint).// If the compiler has determined that the map or the first bucket// can be created on the stack, h and/or bucket may be non-nil.// If h != nil, the map can be created directly in h.// If h.buckets != nil, bucket pointed to can be used as the first bucket.func makemap(t *maptype, hint int, h *hmap) *hmap {mem, overflow := math.MulUintptr(uintptr(hint), t.bucket.size)if overflow || mem > maxAlloc {hint = 0}// initialize Hmapif h == nil {h = new(hmap)}h.hash0 = fastrand()// Find the size parameter B which will hold the requested # of elements.// For hint < 0 overLoadFactor returns false since hint < bucketCnt.B := uint8(0)for overLoadFactor(hint, B) {B++}h.B = B// allocate initial hash table// if B == 0, the buckets field is allocated lazily later (in mapassign)// If hint is large zeroing this memory could take a while.if h.B != 0 {var nextOverflow *bmaph.buckets, nextOverflow = makeBucketArray(t, h.B, nil)if nextOverflow != nil {h.extra = new(mapextra)h.extra.nextOverflow = nextOverflow}}return h}
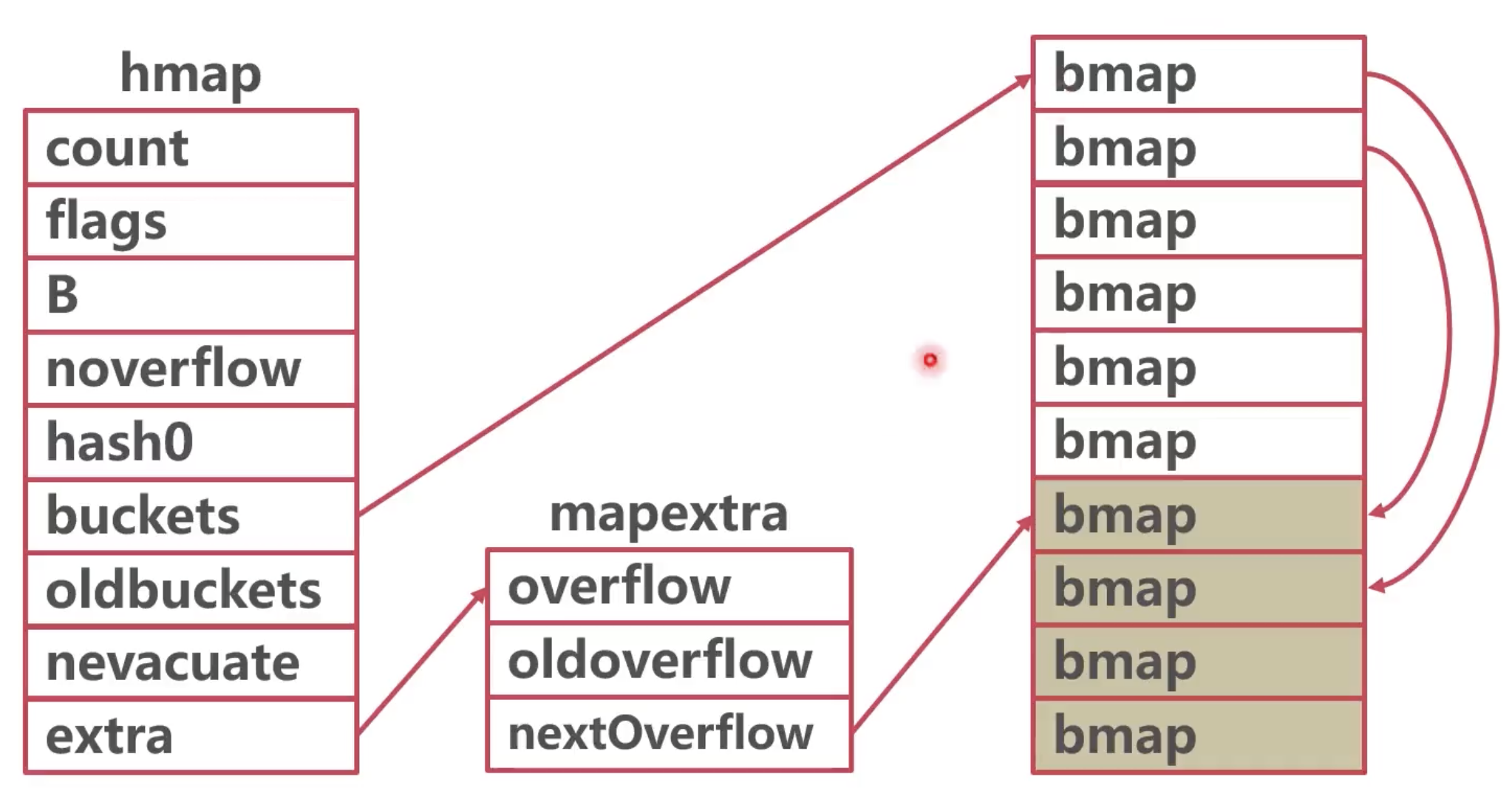
使用字面量初始化
使用字面量初始化的步骤为:
- 创建一个对应大小的 map;
- 将字面量值依次赋值给 map;
- 元素少于25时转化为简单赋值

- 元素大于25时转化为循环赋值

map 的访问步骤
- 使用 key 和 hash0 通过哈希函数得到哈希值;
- 计算在哪个 bucket:例如 m.B == 3,那么说明有 2^3 个 buckets(编号为0~7),使用哈希值的后 3 位即可确定在哪个桶,例如后三位为 010,就说明桶号为 2;
- 计算在桶中的位置:取哈希值的前八位得到 tophash ;
- 如果该桶或对应的溢出桶存在匹配了 tophash 且对应的 key 为访问的 key 的值,则返回 key 对应的 value;
- 如果不存在该 tophash 或者不存在对应的 key,则表示 map 中没有这个元素;
map 的写入步骤
和 map 的访问步骤类似,区别是如果不存在该 key,则直接添加一个键值对。map 的扩容问题
为什么 map 需要扩容?
溢出桶过多,使得 kv 操作效率大幅降低,此时需要进行扩容操作。map 何时扩容?
```go func mapassign(t maptype, h hmap, key unsafe.Pointer) unsafe.Pointer { … // If we hit the max load factor or we have too many overflow buckets, // and we’re not already in the middle of growing, start growing. if !h.growing() && (overLoadFactor(h.count+1, h.B) || tooManyOverflowBuckets(h.noverflow, h.B)) { hashGrow(t, h) goto again // Growing the table invalidates everything, so try again } … }
…
func overLoadFactor(count int, B uint8) bool {
return count > bucketCnt && uintptr(count) >
loadFactorNum*(bucketShift(B)/loadFactorDen)
}
…
func tooManyOverflowBuckets(noverflow uint16, B uint8) bool {
// 当桶总数 < 2 ^ 15 时,如果溢出桶总数 >= 桶总数,则认为溢出桶过多。
// 当桶总数 >= 2 ^ 15 时,直接与 2 ^ 15 比较,当溢出桶总数 >= 2 ^ 15 时,
// 即认为溢出桶太多了。
if B > 15 {
B = 15
}
return noverflow >= uint16(1)<<(B&15)
}
分析源码可知,两种情况下 map 需要扩容:1. 每个哈希值对应的 key 大于某个固定值(装载因子超过6.5);1. 溢出桶过多,溢出桶数量大于普通桶;<a name="p2esf"></a>### map 怎样扩容?```gofunc hashGrow(t *maptype, h *hmap) {bigger := uint8(1) // h.B 如果 +1,则 buckets 数量翻倍// 装载因子不超过 6.5 进行等量扩容if !overLoadFactor(h.count+1, h.B) {bigger = 0h.flags |= sameSizeGrow}oldbuckets := h.buckets // oldbuckets 指向原来的桶数组newbuckets, nextOverflow := makeBucketArray(t, h.B+bigger, nil)flags := h.flags &^ (iterator | oldIterator)if h.flags&iterator != 0 {flags |= oldIterator}// commit the grow (atomic wrt gc)h.B += biggerh.flags = flagsh.oldbuckets = oldbucketsh.buckets = newbucketsh.nevacuate = 0 // 搬迁进度为0h.noverflow = 0 // 溢出桶为0// 更新溢出桶if h.extra != nil && h.extra.overflow != nil {// 老的溢出桶不为空说明之前的扩容还未搬迁完成if h.extra.oldoverflow != nil {throw("oldoverflow is not nil")}h.extra.oldoverflow = h.extra.overflowh.extra.overflow = nil}if nextOverflow != nil {if h.extra == nil {h.extra = new(mapextra)}h.extra.nextOverflow = nextOverflow}// 真正的元素搬迁发生在 growWork() 和 evacuate().}
map 扩容的方式有两种:
- 等量扩容:count 不多但是溢出桶太多(情况可能是原来 count 多但是 delete 了大量元素),该情况使用等量的桶来作为存储的新桶;
- 翻倍扩容:装载因子超过 6.5;
注意:hashGrow中只分配了新桶,并没有操作迁移旧桶的数据,go map 采用的是渐进式扩容方式,如果旧桶中的数据被操作时,才将旧桶的数据迁移到新桶。
渐进式扩容
比如在 map 的 assign (修改/添加)操作时
func mapassign(t *maptype, h *hmap, key unsafe.Pointer) unsafe.Pointer {...again:bucket := hash & bucketMask(h.B) // 获取当前桶的编号if h.growing() { // 如果 map 正在扩容搬迁growWork(t, h, bucket) //}...}...func growWork(t *maptype, h *hmap, bucket uintptr) {// 保证当前使用的桶的旧桶迁移完毕evacuate(t, h, bucket&h.oldbucketmask())// 保证每次操作至少搬运一个桶if h.growing() {evacuate(t, h, h.nevacuate)}}
参考资料

若有收获,就点个赞吧
0 人点赞
