第一小节 课程内容介绍
大数据技术解决的是什么问题?
大数据技术解决的主要是海量数据的存储和计算。
Hadoop的广义和狭义之分
狭义的Hadoop指的是一个框架,Hadoop是由三部分组成:HDFS:分布式文件系统--》存储; MapReduce:分布式离线计算框架--》计算; Yarn:资源调度框架<br /> 广义的Hadoop是不仅仅包含Hadoop框架,除了Hadoop框架以外还有一些辅助框架。Flume:日志数据采集,Sqoop:关系型数据库数据的采集;<br />Hive:深度依赖Hadoop框架完成计算(sql), Hbase:大数据领域的数据库(mysql)。<br />Sqoop:数据的导出。<br />**广义的Hadoop指的是一个生态圈**。
第二小节 大数据定义及应用场景
大数据的定义
大数据是指无法在一定时间范围内用常规软件工具进行捕捉、管理和处理的数据集合,是需要新处理模式才能具有更强的决策力、洞察发现力流程优化能力的海量、高增长率和多样化的信息资产。
大数据的特点
大数据的特点可以用IBM曾经提出的“5V”来描述。如下:
大量
采集、存储和计算的数据量都非常大。<br />计算机存储单位一般用B,KB,MB,GB,TB,PB,EB,ZB,YB,BB,NB,DB来表示,它们之间的关系是<br />1GB = 1024MB<br /> 1TB = 1024GB<br />1PB = 1024 TB<br />1EB = 1024 PB<br />1ZB = 1024 EB<br />1YB = 1024 ZB<br />1BB = 1024 YB<br />1NB = 1024 BB<br />1DB = 1024 NB<br />** 以PB为例,PB级数据量有多大?是怎样的一个概念?**<br />假如手机播放MP3的速度为平局每分钟1MB,而1首歌的平均时长为4分钟,那么1PB存量的歌曲可以连续播放2000年。
高速
在大数据时代,数据的创建、存储、分析都要求被高速处理,比如电商网站的个性化推荐尽可能要求实时完成推荐,这也是大数据区别于传统数据挖掘的显著特征。
- 多样
数据形式和来源多样化。包括结构化、半结构化和非结构化数据,具体表现为网络日志、音频、视频、图片、地理位置信息等等,多类型的数据对数据的处理能力提出了更高的要求。
- 真实
确保数据的真实性,才能保证数据分析的正确性。
- 低价值
数据价值密度相对较低,或者说是浪里淘沙却又弥足珍贵。互联网发展催生了大量数据,信息海量,但价值密度较低,如何结合业务逻辑并通过强大的机器算法来挖掘数据价值,是大数据时代最需要解决的问题,也是一个有难度的课题。
第四小节 Hadoop简介
什么是Hadoop?
Hadoop是一个适合大数据的分布式存储和计算平台。
如前所述,狭义上说Hadoop就是一个框架平台,广义上讲Hadoop代表大数据的一个技术生态圈,包括很多其他软件框架。
 Hadoop的起源
Hadoop的起源
Hadoop的发展历程可以用如下过程概述:
Nutch—>Google论文(GFS、MapReduce)
—> Hadoop产生
—> 成为Apache顶级项目
—> Cloudera公司成立(Hadoop快速发展)
Hadoop最早起源于Nutch,Nutch的创始人是Doug Cutting
Nutch是一个开源Java实现的搜索引擎。它提供了我们运行自己的搜索引擎所需的全部工具。包括全文搜索和web爬虫,但随着抓取网页数量的增加,遇到了严重的可扩展性问题—如何解决数十亿网页的存储和索引问题。
2003年、2004年谷歌发表的两篇论文为该问题提供了可行的解决方案。GFS,可用于处理海量网页的存储;MapReduce,可用于处理海量网页的索引计算问题。
Google的三篇论文(三驾马车)
GFS:Google的分布式文件系统(Google File System)
MapReduce:Google的分布式计算框架
BigTable:大型分布式数据库
发展演变关系:
GFS —> HDFS
Google MapReduce —> Hadoop MapReduce
BigTable —> HBase
 Hadoop的发行版本
Hadoop的发行版本
目前Hadoop发行版非常多,有Cloudera发行版(CDH)、Hortonworks发行版、华为发行版、Intel发行版等,所有这些发行版均是基于Apache Hadoop衍生出来的,之所以有这么多的版本,是由Apache Hadoop的开源协议决定的(任何人可以对其进行修改,并作为开源或商业产品发布/销售)。
企业中主要用到的三个版本分别是:Apache Hadoop版本(最原始的,所有的发行版均基于这个版本进行改进)、Cloudera版本(Cloudera’s Distribution Including Apache Hadoop 简称”CDH“)、Hortonworks版本(Hortonworks Data Platform,简称”HDP“)。
Apache Hadoop原始版本
优点:拥有全世界的开源贡献,代码更新版本比较快。<br /> 缺点:版本的升级,版本的维护,以及版本之间的兼容性,学习非常方便。
软件收费版本 ClouderaManager CDH版本—生产环境使用
- 免费开源版本HortonWorks HDP版本—生产环境使用
Hadoop的优缺点
Hadoop的优点
- Hadoop具有存储和处理数据能力的高可靠性。
- Hadoop通过可用的计算机集群分配数据,完成存储和计算任务,这些集群可以方便的扩展到数以千计的节点中,具有高扩展性。
- Hadoop能够在节点之间进行动态地移动数据,并保证各个节点的动态平衡,处理速度非常快,具有高效性。
- Hadoop能够自动保存数据的多个副本,并且能够自动将失败的任务重新分配,具有高容错性。
Hadoop的缺点
- Hadoop不适用于低延迟数据访问。—把数据存储在Hadoop里面,如果你想快速的得到数据,这个延迟是非常高的,不能做到快速的返回数据。
- Hadoop不能高效存储大量小文件。
- Hadoop不支持多用户写入并任意修改文件。
Hadoop重要组成之HDFS及MapReduce概述
Hadoop = HDFS(分布式文件系统) + Mapreduce(分布式计算框架) + Yarn(资源协调框架) + Common模块
1.Hadoop HDFS:(Hadoop Distribute File System) 一个高可靠、高吞吐量的分布式文件系统。
比如:100T数据存储, “分而治之”
分:拆分 —> 数据切割,100T数据拆分为10G一个数据块由一个节点存储这个数据库。
数据切割、制作副本、分散储存。
主节点NameNode做的是一个管理工作,真正存储数据块的是从节点DataNode。
图中涉及到几个角色
NameNode(nn):存储文件的元数据,比如文件名、文件目录结构、文件属性(生成时间、副本数、文件权限),以及每个文件的块列表和块所在的DataNode等。
SecondaryNameNode(2nn):辅助NameNode更好的工作,用来监控HDFS状态的辅助后台程序,每隔一段时间获取HDFS元数据快照。
DataNode(dn):在本地文件系统存储文件块数据,以及块数据的校验。
注意:NN、2NN,DN这些既是角色名称,进程名称,代指电脑节点名称!!
Hadoop MapReduce:一个分布式的离线并行计算框架。
拆解任务、分散处理、汇整结果
MapReduce计算= Map阶段+Reduce阶段
Map阶段就是“分”的阶段,并行处理输入数据;
Reduce阶段就是“合”的阶段,对Map阶段结果进行汇总;
Hadoop YARN:作业调度与集群资源管理的框架
计算资源协调
Yarn中有如下几个重要角色,同样,及时角色名也是进程名,也指代所在计算机节点名称。
ResourceManager(rm):处理客户端请求、启动/监控ApplicationMaster、监控NodeManager、资源分配与调度;
NodeManager(nm):单个节点上的资源管理、处理来自ResourceManger的命令、处理来自ApplicationManager的命令;
ApplicationManger(am):数据切分、为应用程序申请资源,并分配给内部任务、任务监控与容错。
Container:对任务运行环境的抽象,封装了CPU、内存等多维资源以及环境变量、启动命令等任务运行相关的信息。
ResourceManger是老大,NodeManager是小弟,ApplicationManager是计算任务专员。
Hadoop Common:支持其他模块的工具模块(Configuration、RPC、序列化机制、日志操作)。

主节点ResourceManager只负责管理工作,真正拥有资源的是从节点NodeManger,真正提供CPU,提供内存的是NodeManager,而且提供者是container。
针对每一个提交过来的任务会运行一个APPMaster。(注:任务在后面统一称为应用)
第七小节 Hadoop完全分布式集群搭建之虚拟机环境准备
软件和操作系统版本
Hadoop框架是采用Java语言编写,需要Java环境(jvm)
JDK 版本:JDK8版本
集群:
知识点学习:统一使用VMware虚拟机三台linux节点,linux操作系统:centos7
项目阶段:统一使用云服务器,5台云服务器节点。
Hadoop搭建方式
单机模式:单节点模式,非集群,生产不会使用这种方式
单机伪分布式模式:单节点,多线程模拟集群的效果,生产不会使用这种方式
完全分布式模式:多台节点,真正的分布式Hadoop集群的搭建(生产环境建议使用这种模式)
第一节:虚拟机环境准备
1.三台虚拟机(静态ip,关闭防火墙,修改主机名,配置免密登陆,集群时间同步)
三台机器配置免密登陆:
第一步:配置hostname与IP映射
命令:vi /etc/hosts(三台机器上都配置红框里的内容)
第二步:在所有主机上创建目录并赋予权限(三台机器上都需要创建目录并赋予权限)
mkdir /root/.ssh
chmod 700 /root/.ssh
第三步,在三台机器执行以下命令,生成公钥和私钥。
cd ~ #进入用户目录
ssh-keygen -t rsa -P “” #是生成ssh密码的命令,-t 参数表示生成算法,有rsa和dsa两种;-P表示使用的密码,这里使用””空字符串表示无密码。
cd ~/.ssh 进入.ssh
cat id_rsa.pub >> authorized_keys #这个命令将id_rsa.pub的内容追加到了authorized_keys的内容后面 第四步,复制第一台机器的认证到其他机器
第四步,复制第一台机器的认证到其他机器
scp authorized_keys linux121:/root/.ssh/
scp authorized_keys linux123:/root/.ssh/
在linux122机器上执行:
在linux121机器上执行:
在linux123机器上执行:
scp authorized_keys linux121:/root/.ssh/
scp authorized_keys linux122:/root/.ssh/
密码传输过程中只使用一次,以后再使用ssh linux121或ssh linux123既不在需要密码,实现免密登陆。
2.在/opt目录下创建文件夹
mkdir -p /opt/lagou/software —软件安装包存放目录
mkdir -p /opt/lagou/serviers —软件安装目录
3.Hadoop下载地址:https://archive.apache.org/dist/hadoop/common/hadoop-2.9.2/
Hadoop官网地址:
http://hadoop.apache.org/
4.上传hadoop安装文件到/opt/lagou/software
第二节 集群规划
| 框架 | linux121 | linux122 | linux123 |
|---|---|---|---|
| HDFS | NameNode、DataNode | DataNode | SecondaryNameNode、DataNode |
| YARN | NodeManager | NodeManager | NodeManager、ResourceManager |
第三节 安装Hadoop
- 登录linux121节点;进入/opt/lagou/software,解压安装文件到/opt/lagou/servers
tar -xzvf hadoop-2.9.2.tar.gz -C /opt/lagou/servers
- 查看是否解压成功
ll /opt/lagou/servers/hadoop-2.9.2
- 添加Hadoop到环境变量 vim /etc/profile
HADOOP_HOME
export HADOOP_HOME=/opt/lagou/servers/hadoop-2.9.2
export PATH=$PATH:$HADOOP_HOME/bin
export PATH=$PATH:$HADOOP_HOME/sbin
- 使环境变量生效
source /etc/profile
- 验证hadoop
hadoop version
校验结果:
hadoop目录
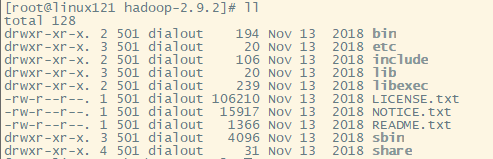<br /> bin目录:对hadoop进行操作的相关命令,如hadoop,hdfs等<br />** etc目录**:Hadoop的配置文件目录,如:hdfs-site.xml,core-site.xml等<br /> lib目录:hadoop本地库(解压缩的依赖)<br /> sbin目录:存放的是Hadoop集群启动停止相关脚本,命令。<br /> share目录:hadoop的一些jar,官方案例jar,文档等<br />**集群配置**<br />Hadoop集群配置 = HDFS集群配置 + MapReduce集群配置 + Yarn集群配置
HDFS集群配置
1.将JDK路径明确配置给HDFS(修改hadoop-env.sh)
2.指定NameNode节点以及数据存储目录(修改core-site.xml)
3.指定SecondaryNameNode节点(修改hdfs-site.xml)
4.指定DataNode从节点(修改etc/hadoop/slaves文件,每个节点配置信息占一行)
- MapReduce集群配置
1.将JDK路径明确配置给MapReduce(修改mapred-env.sh)
2.指定MapReduce计算框架运行Yarn资源调度框架(修改mapred-site.xml)
- Yarn集群配置
1.将JDK路径明确配置给Yarn(修改yarn-env.sh)
2.指定ResourceManager老大节点所在计算机节点(修改yarn-site.xml)
3.指定NodeManager节点(会通过slaves文件内容确定)
集群配置具体步骤:
HDFS集群配置
cd /opt/lagou/servers/hadoop-2.9.2/etc/hadoop
- 配置:hadoop-env.sh
将JDK路径明确配置给HDFS
vi hadoop-env.sh
export JAVA_HOME=/opt/lagou/servers/jdk1.8.0_231
查看JAVA_HOME所在路径:echo $JAVA_HOME
- 指定NameNode节点以及数据存储目录(修改core-site.xml)
vi core-site.xml
注意:1.一定要放到configuration标签里面;2.注意name标签和value标签的格式
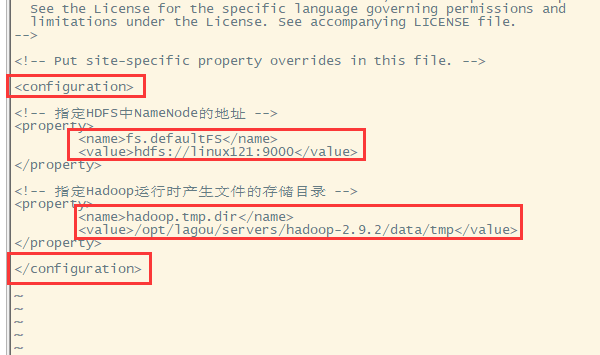
core-site.xml的默认配置:
https://hadoop.apache.org/docs/r2.9.2/hadoop-project-dist/hadoop-common/core-default.xml
指定secondarynamenode节点(修改hdfs-site.xml)
vi hdfs-site.xml
官方默认配置
https://hadoop.apache.org/docs/r2.9.2/hadoop-project-dist/hadoop-hdfs/hdfs-default.xml
指定datanode从节点(修改slaves文件,每个节点配置信息占一行)
vim slaves
linux121
linux122
linux123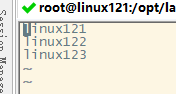
注意:该文件中添加的内容结尾不允许有空格,文件中不允许有空行,不要写ip地址。
MapReduce集群配置
- 指定MapReduce使用的jdk路径(修改mapred-env.sh)
vi mapred-env.sh
export JAVA_HOME=/opt/lagou/servers/jdk1.8.0_231
指定MapReduce计算框架运行Yarn资源调度框架(修改mapred-site.xml)

先把这个文件修改下名字
mv mapred-site.xml.template mapred-site.xml
vi mapred-site.xml
</property
mapred-site.xml默认配置
https://hadoop.apache.org/docs/r2.9.2/hadoop-mapreduce-client/hadoop-mapreduce-
client-core/mapred-default.xml
Yarn集群配置
- 指定JDK路径
vi yarn-env.sh
export JAVA_HOME=/opt/lagou/servers/jdk1.8.0_231
指定ResourceManager的master节点信息(修改yarn-site.xml)
vi yarn-site.xml
yarn-site.xml的默认配置
https://hadoop.apache.org/docs/r2.9.2/hadoop-yarn/hadoop-yarn-common/yarn-
default.xml
指定NodeManager节点(slaves文件已修改)(NodeManager节点和DataNode从节点共有一个slaves节点,已经在DataNode节点上修改了slaves文件,所以这里不用动了)
注意:
Hadoop安装目录所属用户和所属用户组信息,默认是501 dialout,而我们操作Hadoop集群的用户使用的是虚拟机的root用户,所以为了避免出现信息混乱,修改Hadoop安装目录所属用户和用户组!
chown -R root:root /opt/lagou/servers/hadoop-2.9.2
分发配置
编写集群分发脚本rsync-script
- rsync远程同步工具
rsync主要用于备份和镜像。具有速度快、避免复制相同内容和支持符号链接的优点。
rsync和scp区别:用rsync做文件的复制要比scp的速度快,rsync只对差异文件做更新。scp是把所有文件都复制过去。
1.基本语法
rsync -rvl $pdir/$fname $user@$host:$pdir/$fname
命令 选项参数 要拷贝的文件路径/名称 目的用户@主机:目的路径/名称
2.选项参数说明
表2-2
| 选项 | 功能 |
|---|---|
| -r | 递归 |
| -v | 显示复制过程 |
| -l | 拷贝符号连接 |
- rsync案例
1.三台虚拟机安装rsync(执行安装需要保证机器联网)
yum install -y rsync
2.把linux121机器上的/opt/lagou/software目录同步到linux122服务器的 root用户下的/opt/目录。
rsync -rvl /opt/lagou/software root@linux122:/opt/lagou/software
集群分发脚本编写
1.需求:循环复制文件到集群所有节点的相同目录下
rsync命令原始拷贝:
rsync -rvl /opt/module root@linux123:/opt/
2.期望脚本
脚本+要同步的文件名称
3.说明:在/usr/local/bin这个目录下存放的脚本,root用户可以在系统任何地方直接执行。
4.脚本实现
(1)在/usr/local/bin目录下创建文件rsync-script,文件内容如下:
touch rsync-script
vi rsync-script—-为什么不直接使用vi命令直接创建了rsync-script文件

在文件中编写shell代码




查看是否启动成功:jps —jps是在linux里面查看Java进程的命令

在linux121、linux122以及linux123上分别启动DataNode(注意先去linux122和linux123上配置下Java的环境变量和Hadoop的环境变量)

web端查看HDFS界面
NameNode所在节点 + 50070端口
如果要用主机名+端口号的方式访问的话,需要在windows的hosts文件配置ip和主机名映射。(C:\Windows\System32\drivers\etc)
查看HDFS集群正常节点:
ntpdate -u cn.pool.ntp.org :网络时间同步命令
Yarn集群单节点启动:
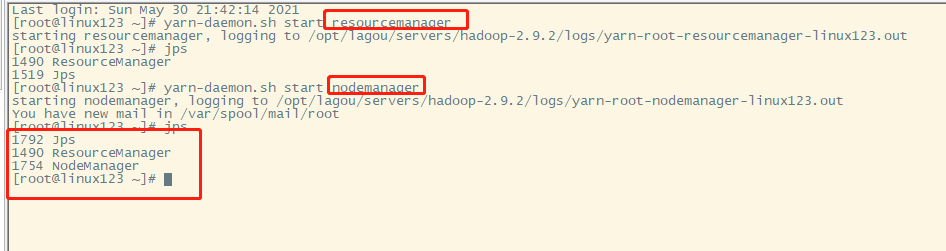
linux123主机:yarn-daemon.sh start resourcemanager —主节点
linux121主机:yarn-daemon.sh start nodemanager —从节点
jps linux122主机:yarn-daemon.sh start nodemanager
linux122主机:yarn-daemon.sh start nodemanager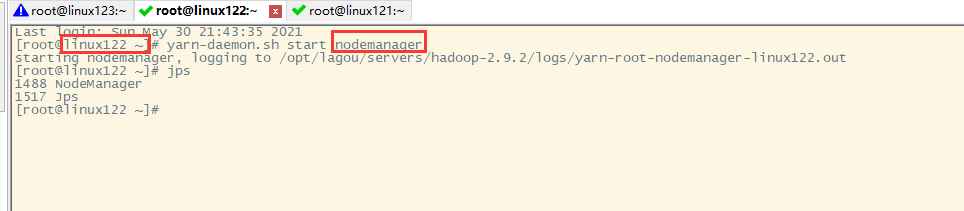
集群群起
如果已经单节点方式启动了Hadoop,可以先停止之前启动的Namenode与DataNode进程,如果之前Namenode没有执行格式化,这里需要执行格式化,但是如果之前执行过格式化,这里千万不能再格式化了!!!
先停止之前启动的namenode、DataNode、resourcemanager、NodeManager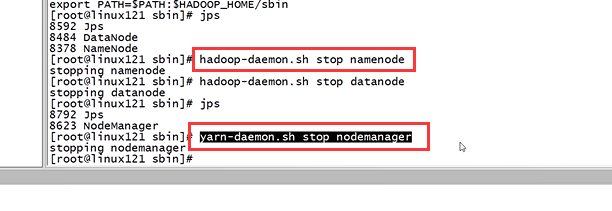

只需要在主节点上执行群起命令(老大在那台机器上就在那台机器上执行群起脚本)
启动HDFS:
在linux121机器上启动start-dfs.sh
启动YARN:
在linux123机器上启动start-yarn.sh
注意:NameNode和ResourceManger不是在同一台机器,不能在NameNode上启动 YARN,应该在ResouceManager所在的机器上启动YARN。
Hadoop集群启动停止命令汇总**
1.各个服务组件逐一启动/停止
(1)分别启动/停止HDFS组件
hadoop-daemon.sh start / stop namenode / datanode / secondarynamenode
(2) 启动/停止YARN
yarn-daemon.sh start / stop resourcemanager / nodemanager
2.各个模块分开启动 / 停止 (配置ssh是前提)常用
(1)整体启动/停止HDFS
start-dfs.sh / stop-dfs.sh
(2)整体启动/停止YARN
start-yarn.sh / stop-yarn.sh
集群测试
1.HDFS分布式存储初体验
从linux本地文件系统上传下载文件验证HDFS集群工作正常
hdfs dfs -mkdir -p /test/input —创建一个hdfs文件夹,执行完这个命令后会在浏览器的Browse Directory目录下看到创建的hdfs目录。



执行上传linux文件到hdfs的命令:
hdfs dfs -put /root/test.txt /test/input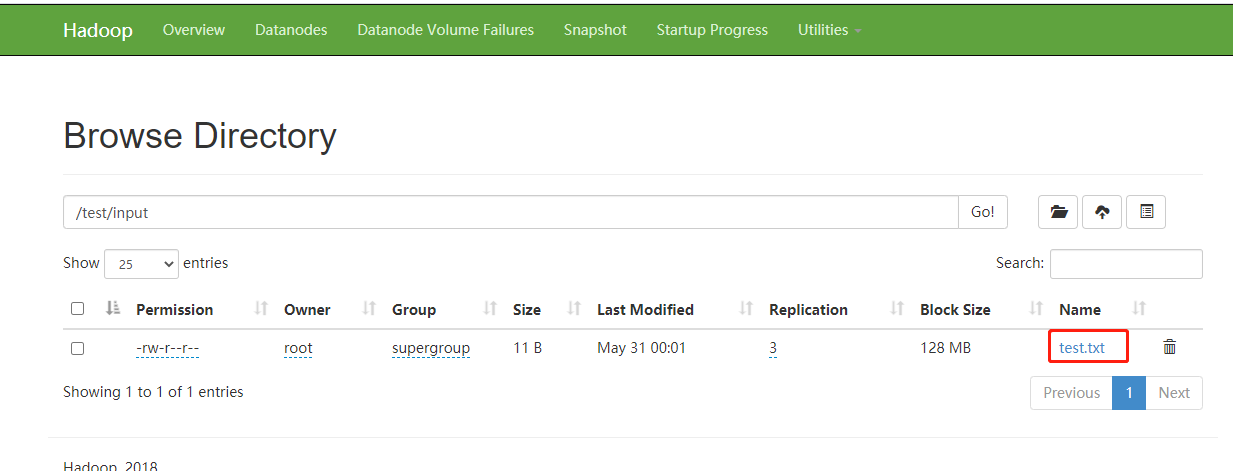
执行完hdfs dfs -put /root/test.txt /test/input命令后会看到/test/input目录下多了一个test.txt文件,点击这个文件会出现如下界面:
点击“download”,会下载到本地

从hdfs下载文件到linux本地
hdfs dfs -get /test/input/test.txt(下载之前先把之前Linux本地创建的test.txt文件删除)
2.MapReduce分布式计算初体验
- 在HDFS文件系统根目录下面创建一个wcinput文件夹
hdfs dfs -mkdir /wcinput
- 在/root/目录下创建一个wc.txt文件(本地文件系统)
cd /root
touch wc.txt
- 编辑wc.txt文件
vi wc.txt
- 在文件中输入如下内容
hadoop mapreduce yarn
hdfs hadoop mapreduce
mapreduce yarn lagou
lagou
lagou
- 保存退出
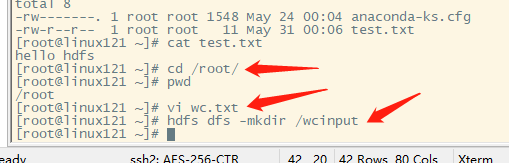

- 上传wc.txt到hdfs目录/wcinput下
hdfs dfs -put wc.txt /wcinput
- 回到hadoop目录/opt/lagou/servers/hadoop-2.9.2
- 执行程序
hadoop jar /opt/lagou/servers/hadoop-2.9.2/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.9.2.jar wordcount /wcinput /wcoutput 

- 查看结果:

yarn集群所在界面:
配置历史服务器
在yarn中运行的任务产生的日志数据不能查看,为了查看程序的历史运行情况,需要配置一下历史日志服务器。具体配置步骤如下:
1.配置mapred-stie.xml
在该文件里面增加如下配置
2.分发mapred-site.xml到其它节点
rsync-script mapred-site.xml
3.启动历史服务器(注:因为配置在linux121机器上,所以要去linux121机器上启动)
4.查看历史服务器是否启动
jps
5.查看JobHistory
http://linux121:19888/jobhistory
[root@linux123 hadoop]# raync-script yarn-site.xml 





hadoop jar hadoop-mapreduce-examples-2.9.2.jar wordcount /wcinput /wcoutput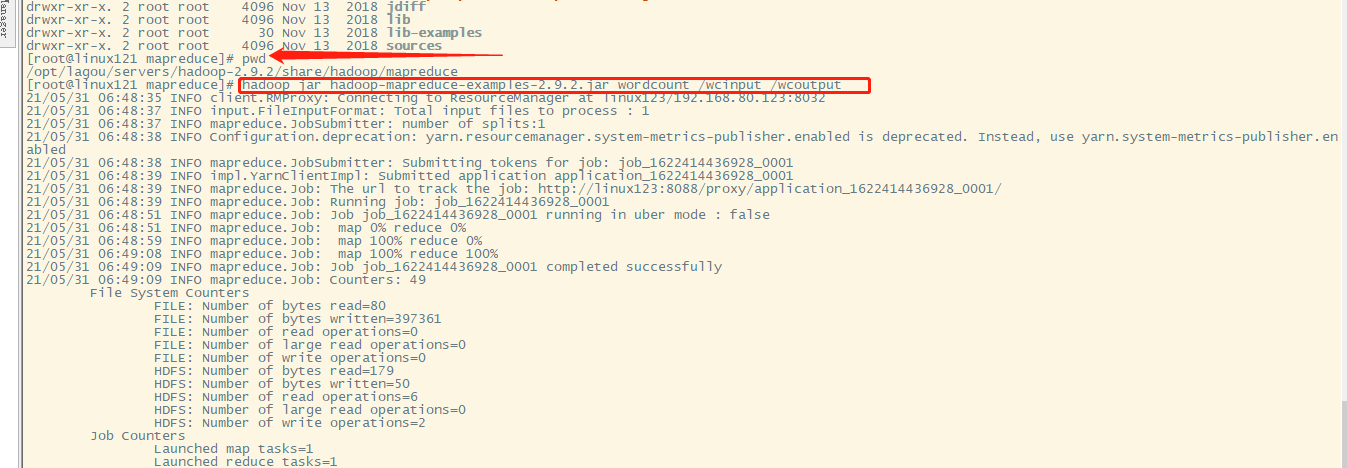




若有收获,就点个赞吧
0 人点赞
