1,AQS
全称AbstractQueuedSynchronizer,抽象队列同步器。
当然我看了文章【https://www.cnblogs.com/waterystone/p/4920797.html】,写的真好。
架构图,我们借用下网上的图:

我们这里从使用到源码的方式入手来解析AQS。每个方法的作用及其实现原理。
1.1 独占锁
这里用ReentrantLock分析:
先上测试代码:
public class ReentrantLockTest {private static List<Integer> data = new ArrayList<>(50000);@Testpublic void test1() throws InterruptedException {Thread thread1 = new WithOutThread1();Thread thread2 = new WithOutThread2();thread1.start();thread2.start();Thread.sleep(3000);System.out.println(data.size());}public static void main(String args[]) throws InterruptedException {ReentrantLock reentrantLoc = new ReentrantLock();Thread thread1 = new ReentrantLockThread1(reentrantLoc);Thread thread2 = new ReentrantLockThread2(reentrantLoc);thread1.start();thread2.start();Thread.sleep(2000);System.out.println(data.size());}static class ReentrantLockThread1 extends Thread {private ReentrantLock reentrantLock;public ReentrantLockThread1(ReentrantLock reentrantLock) {this.reentrantLock = reentrantLock;}@Overridepublic void run() {reentrantLock.lock();try {for (int i = 1; i <= 10000; i++) {data.add(i);}doSomeThing();} finally {reentrantLock.unlock();}}private void doSomeThing() {reentrantLock.lock();try {for (int i = 10001; i <= 20000; i++) {data.add(i);}} finally {reentrantLock.unlock();}}}static class ReentrantLockThread2 extends Thread {private ReentrantLock reentrantLock;public ReentrantLockThread2(ReentrantLock reentrantLoc) {this.reentrantLock = reentrantLoc;}public ReentrantLockThread2(String name) {super(name);}@Overridepublic void run() {reentrantLock.lock();try {Thread.sleep(40000);for (int i = 1; i <= 10000; i++) {data.add(i);}doSomeThing();} catch (InterruptedException e) {e.printStackTrace();} finally {reentrantLock.unlock();}}private void doSomeThing() {reentrantLock.lock();try {for (int i = 10001; i <= 20000; i++) {data.add(i);}} finally {reentrantLock.unlock();}}}class WithOutThread1 extends Thread {@Overridepublic void run() {for (int i = 10001; i <= 20000; i++) {data.add(i);}}}class WithOutThread2 extends Thread {@Overridepublic void run() {for (int i = 1; i <= 10000; i++) {data.add(i);}}}}
有两个线程模拟并发处理的场景。
lock()方法,获取锁,从这里为入口进入源码分析:
public void lock() {sync.acquire(1);}
这里没什么讲的,进入acquire方法:
此方法是独占模式下线程获取共享资源的顶层入口。如果获取到资源,线程直接返回,否则进入等待队列,直到获取到资源为止,且整个过程忽略中断的影响。这也正是lock()的语义,当然不仅仅只限于lock()。获取到资源后,线程就可以去执行其临界区代码了。
public final void acquire(int arg) {//非公平锁体现在这里,当一个新的线程请求锁的时候,不是先放到队列里面,而是直接先进行抢占,其实就是//强插队,插队没插上就乖乖的去后面排队了(进入等待队列)。tryAcquire返回true说明拿到锁了,//可以执行临界去的代码了,如果返回false说明获取锁失败,需要进入等待队列,进入// acquireQueued(addWaiter(Node.EXCLUSIVE), arg))逻辑,这里的Node.EXCLUSIVE//表示独占模式if (!tryAcquire(arg) &&acquireQueued(addWaiter(Node.EXCLUSIVE), arg))selfInterrupt();}
tryAcquire最终调用的是ReentrantLock非公平锁ReentrantLock的nonfairTryAcquire(int acquires)方法
tryAcquire就是通过CAS机制去更改锁内部维护的state变量的值
但是因为这里是一个可重入锁,就是如果当前线程已经获取锁,但是调用的方法又获取锁,就会进入else if逻辑,
就不用通过CAS机制去设置state的值了。
final boolean nonfairTryAcquire(int acquires) {final Thread current = Thread.currentThread();int c = getState();if (c == 0) {if (compareAndSetState(0, acquires)) {setExclusiveOwnerThread(current);return true;}}else if (current == getExclusiveOwnerThread()) {int nextc = c + acquires;if (nextc < 0) // overflowthrow new Error("Maximum lock count exceeded");setState(nextc);return true;}return false;}
mode有两种:EXCLUSIVE(独占)和SHARED(共享)可以看内部类Node源码
/** Marker to indicate a node is waiting in shared mode */static final Node SHARED = new Node();/** Marker to indicate a node is waiting in exclusive mode */static final Node EXCLUSIVE = null;
第一次进入该方法(也就是第一个获取锁失败的线程会进入该方法)的时候队列是空的(队头,队尾都是空的)
首先会 new Node(Thread.currentThread(), mode);
Node(Thread thread, Node mode) { // Used by addWaiterthis.nextWaiter = mode;this.thread = thread;}
然后就会走initializeSyncQueue()方法
通过CAS机制将队头设为new Node(),如果设置成功,队尾也为new Node()
执行完initializeSyncQueue()方法之后,tail就不是null了,就会执行if里面的逻辑
然后将和当前线程绑定的节点node添加到队尾
private Node addWaiter(Node mode) {//创建当前线程节点Node node = new Node(Thread.currentThread(), mode);//尝试快速方式直接放到队尾。// Try the fast path of enq; backup to full enq on failure//尾节点 为啥这样写的原因https://www.zhihu.com/question/411529864Node pred = tail;//如果尾节点不为nullif (pred != null) {//将新建的node加入队尾node.prev = pred;//cas操作tail改为node成功返回if (compareAndSetTail(pred, node)) {pred.next = node;return node;}}enq(node);return node;}/*** Inserts node into queue, initializing if necessary. See picture above.* @param node the node to insert* @return node's predecessor*/private Node enq(final Node node) {//不断重试for (;;) {//每次循环开始重新拿一次Node t = tail;if (t == null) { // Must initialize tail为null说明还未初始化 需要先初始化//是直接new的,不关联线程,不参与抢占锁if (compareAndSetHead(new Node()))tail = head;} else {node.prev = t;if (compareAndSetTail(t, node)) {t.next = node;return t;}}}}
当addWaiter(Node mode)执行完成之后,会将和当前线程绑定的node返回执行acquireQueued(final Node node, int arg)方法了
虽说这里是通过自旋去获取锁,但是这里不是一直无休止的执行,后面当前线程会休息,且看
shouldParkAfterFailedAcquire(p, node)和parkAndCheckInterrupt()方法
final boolean acquireQueued(final Node node, int arg) {//初始值 trueboolean failed = true;try {boolean interrupted = false;//自旋//当然这里不是一直无休止的执行,后面当前线程会休息,这个休息就是阻塞当前线程,做到无法//执行临界区代码的目的for (;;) {//每次获取当前线程node的前驱final Node p = node.predecessor();//先抢占锁//如果前驱为队头,则当前结点就有资格去获取锁了(这里是需要被唤醒的,//可能是老大释放完资源//唤醒自己的,当然也可能被interrupt了)if (p == head && tryAcquire(arg)) {//拿到资源后,将head指向该结点。所以head所指的标杆结点,就是当前//获取到资源的那个结点或null。setHead(node);//help GC setHead中node.prev已置为null,此处再将上一个头节点的//next置为null,因为上一个节点已释放了锁//为了方便GC回收以前的head结点。也就意味着之前拿完资源的结点出队了!p.next = null;return interrupte;}//如果自己可以休了,就通过park()进入waiting状态,直到被unpark()。//如果不可中断的情况下被中断了,那么会从park()中醒过来,发现拿不到资源,//从而继续进入park()等待。if (shouldParkAfterFailedAcquire(p, node) &&parkAndCheckInterrupt())interrupted = true;}} finally {// 如果等待过程中没有成功获取资源(如timeout,或者可中断的情况下被中断了),//那么取消结点在队列中的等待。if (failed)cancelAcquire(node);}}private void setHead(Node node) {head = node;node.thread = null;node.prev = null;}
shouldParkAfterFailedAcquire(p, node)方法
waiteStatus有5中状态:
- CANCELLED(1):表示当前结点已取消调度。当timeout或被中断(响应中断的情况下),会触发变更为此状态,进入该状态后的结点将不会再变化。
- SIGNAL(-1):表示后继结点在等待当前结点唤醒。后继结点入队时,会将前继结点的状态更新为SIGNAL。
- CONDITION(-2):表示结点等待在Condition上,当其他线程调用了Condition的signal()方法后,CONDITION状态的结点将从等待队列转移到同步队列中,等待获取同步锁。
- PROPAGATE(-3):共享模式下,前继结点不仅会唤醒其后继结点,同时也可能会唤醒后继的后继结点。
- 0:新结点入队时的默认状态。
private static boolean shouldParkAfterFailedAcquire(Node pred, Node node) {//拿到前驱的状态int ws = pred.waitStatus;if (ws == Node.SIGNAL)//如果已经告诉前驱拿完号后通知自己一下,那就可以安心休息了。//我们看下面的else方法pred.compareAndSetWaitStatus(ws, Node.SIGNAL);//其实循环第二次还没拿到锁,且前面的执行的线程没有取消的情况就会将前驱的状态设置为//Node.SIGNALreturn true;if (ws > 0) {//如果前驱放弃了,那就一直往前找,直到找到最近一个正常等待的状态,并排在它的后边。//注意:那些放弃的结点,由于被自己“加塞”到它们前边,它们相当于形成一个无引用链,//稍后就会被保安大叔赶走了(GC回收)!do {node.prev = pred = pred.prev;} while (pred.waitStatus > 0);pred.next = node;} else {//如果前驱正常,那就把前驱的状态设置成SIGNAL,告诉它拿完号后通知自己一下。//有可能失败,人家说不定刚刚释放完呢!compareAndSetWaitStatus(pred, ws, Node.SIGNAL);}return false;}
parkAndCheckInterrupt()方法
private final boolean parkAndCheckInterrupt() {//调用park()使线程进入waiting状态LockSupport.park(this);//如果被唤醒,查看自己是不是被中断的 并且会清理中断状态return Thread.interrupted();}
到此lock就被剖析完了,流程大概如下:

不过需要提一下tryLock()和tryLock(long timeout,TimeUnit timeUnit)方法
tryLocK()直接调用tryAcquire()方法,如果获取到锁直接返回true如果没获取到返回false。
tryLock(long timeout,TimeUnit timeUnit)给定一个超时时间,如果获取到锁直接返回true如果没获取到返回false。
这两个方法没有拿到锁不会加入等待队列,所以使用的时候需要注意,如果返回false就不应该执行临界去的代码了。只尝试一次
接下来就是lock.unLock()方法了,字面意思释放锁,其实就是修改锁内部维护的state状态。
这段不用讲了,进入realese(1)逻辑
public void unlock() {sync.release(1);}
如果tryRelease返回true,说明锁释放成功,需要唤醒放在队列中休息的待执行的线程。
首先拿到队列头,如果头不为空,且waitStatus!=0 ,waitStatus正常应该为-1SIGNAL状态,说明后续有线程入队。
且看unparkSuccessor(h)方法
public final boolean release(int arg) {if (tryRelease(arg)) {Node h = head;if (h != null && h.waitStatus != 0)unparkSuccessor(h);return true;}return false;}
这里每次c=getState-1,判断当前线程是否为持有锁的线程,如果不是抛出异常。
然后如果c==0说明释放成功了,返回true。如果c!=0返回false,且state设为c。
因为可重入锁的state不一定为1,重入一次就会+1,所以释放的时候也需要多次释放。
因为是当前线程持有锁,所以不需要cas操作
protected final boolean tryRelease(int releases) {int c = getState() - releases;if (Thread.currentThread() != getExclusiveOwnerThread())throw new IllegalMonitorStateException();boolean free = false;if (c == 0) {free = true;setExclusiveOwnerThread(null);}setState(c);return free;}
unparkSuccessor(Node node)方法,node为队列头
private void unparkSuccessor(Node node) {/** If status is negative (i.e., possibly needing signal) try* to clear in anticipation of signalling. It is OK if this* fails or if status is changed by waiting thread.*///获取队列头结点状态 一般为当前线程所在结点int ws = node.waitStatus;if (ws < 0)compareAndSetWaitStatus(node, ws, 0);//置零当前线程所在的结点状态,允许失败。//找到下一个需要唤醒的结点sNode s = node.next;//如果为空或已取消if (s == null || s.waitStatus > 0) {s = null;// 获取队列尾部,从后向前找,因为没有break,所以会一直找到最前面那个有效的结点,for (Node p = tail; p != node && p != null; p = p.prev)//从这里可以看出,<=0的结点,都是还有效的结点。if (p.waitStatus <= 0)s = p;}if (s != null)//唤醒LockSupport.unpark(s.thread);}
到这里释放锁过程就剖析完了。
一句话概括:用unpark()唤醒等待队列中最前边的那个未放弃线程,这里我们也用s来表示吧。此时,再和acquireQueued()联系起来,s被唤醒后,进入if (p == head && tryAcquire(arg))的判断(即使p!=head也没关系,它会再进入shouldParkAfterFailedAcquire()寻找一个安全点。这里既然s已经是等待队列中最前边的那个未放弃线程了,那么通过shouldParkAfterFailedAcquire()的调整,s也必然会跑到head的next结点,下一次自旋p==head就成立啦),然后s把自己设置成head标杆结点,表示自己已经获取到资源了,acquire()也返回了!!
我们来讲一下ReentrantLock,它有公平锁和非公平锁,默认为非公平锁。
在使用new ReentrantLock(true)生成的就是公平锁。
看一下公平锁的实现
相比非公平锁,多了个hasQueuedPredecessors()判断。
判断队列中是否有有效的待执行的线程,如果有返回true,否则返回false。
如果返回true,而且不是当前线程拿到锁,那么就直接返回false。
static final class FairSync extends Sync {private static final long serialVersionUID = -3000897897090466540L;/*** Fair version of tryAcquire. Don't grant access unless* recursive call or no waiters or is first.*/@ReservedStackAccessprotected final boolean tryAcquire(int acquires) {final Thread current = Thread.currentThread();int c = getState();if (c == 0) {if (!hasQueuedPredecessors() &&compareAndSetState(0, acquires)) {setExclusiveOwnerThread(current);return true;}}else if (current == getExclusiveOwnerThread()) {int nextc = c + acquires;if (nextc < 0)throw new Error("Maximum lock count exceeded");setState(nextc);return true;}return false;}}
相比非公平锁,多了个hasQueuedPredecessors()判断。
判断队列中是否有有效的待执行的线程,如果有返回true,否则返回false。
public final boolean hasQueuedPredecessors() {//尾节点Node t = tail; // Read fields in reverse initialization order//头节点Node h = head;//头节点的下一个节点Node s;return h != t &&((s = h.next) == null || s.thread != Thread.currentThread());}
结果一: 返回false,不需要排队
情况一: h != t返回false,那么短路与判断就会直接返回false
说明:当头节点和尾节点相等时,才会返回false。
头节点和尾节点都为null,表示队列都还是空的,甚至都没完成初始化,那么自然返回fasle,无需排队。
头节点和尾节点不为null但是相等,说明头节点和尾节点都指向一个元素,表示队列中只有一个节点,这时候自然无需排队,因为队列中的第一个节点是不参与排队的,它持有着同步状态,那么第二个进来的节点就无需排队,因为它的前继节点就是头节点,所以第二个进来的节点就是第一个能正常获取同步状态的节点,第三个节点才需要排队,等待第二个节点释放同步状态。
情况二:h != t返回true,(s = h.next) == null返回false以及s.thread !=
Thread.currentThread()返回false
说明:h != t返回true表示队列中至少有两个不同节点存在。
(s = h.next) == null返回false表示头节点是有后继节点的。
s.thread != Thread.currentThread()返回fasle表示着当前线程和后继节点的线程是相同的,那就说明已经轮到这个线程相关的节点去尝试获取同步状态了,自然无需排队,直接返回fasle。
结果二.返回true
情况一: h != t返回true,(s = h.next) == null返回true
h != t返回true表示队列中至少有两个不同节点存在。
(s = h.next) == null返回true,说明头节点之后是没有后继节点的,这情况可能发生在如下情景:有另一个线程已经执行到初始化队列的操作了,介于compareAndSetHead(new Node())与tail = head之间,如下图:这时候头节点不为null,而尾节点tail还没有被赋值,所以值为null,所以会满足h != t结果为true的判断,以及头节点的后继节点还是为null的判断,这时候可以直接返回true,表示要排队了,因为在当前线程还在做尝试获取同步状态的操作时,已经有另一个线程准备入队了,当前线程慢人一步,自然就得去排队。

情况二:h != t返回true,(s = h.next) == null返回false,s.thread !=
Thread.currentThread()返回true。
h != t返回true表示队列中至少有两个不同节点存在。
(s = h.next) == null返回false表示首节点是有后继节点的。
s.thread != Thread.currentThread()返回true表示后继节点的相关线程不是当前线程,所以首节点虽然有后继节点,但是后继节点相关的线程却不是当前线程,那当前线程自然得老老实实的去排队。
1.2 共享锁
下面我们来讲一下共享锁:
以CountDownLatch来分析
测试类
public class CountDownLatchTest {public static void main(String[] args) throws InterruptedException {CountDownLatch countDownLatch = new CountDownLatch(5);Thread thread = new Thread(()->{for (int i = 5; i > 0; i--) {try {Thread.sleep(1000);} catch (InterruptedException e) {e.printStackTrace();}System.out.println(i);countDownLatch.countDown();}});thread.start();countDownLatch.await();System.out.println("hahahha");}}
先看一下CountDownLatch构造方法:
又实例化了一个内部同步类Sync,我们知道Sync继承了AbstractQueuedSynchronizer
public CountDownLatch(int count) {if (count < 0) throw new IllegalArgumentException("count < 0");this.sync = new Sync(count);}
可以看出state=count
实现了AbstractQueuedSynchronizer的tryAcquireShared(int acquires),tryReleaseShared(int releases)方法
tryAcquireShared(int acquires) 返回负值代表获取失败;0代表获取成功,但没有剩余资源;正数表示获取成功,还有剩余资源,其他线程还可以去获取。
private static final class Sync extends AbstractQueuedSynchronizer {private static final long serialVersionUID = 4982264981922014374L;Sync(int count) {setState(count);}int getCount() {return getState();}//返回值只有 1和-1protected int tryAcquireShared(int acquires) {return (getState() == 0) ? 1 : -1;}protected boolean tryReleaseShared(int releases) {// Decrement count; signal when transition to zero//自旋for (;;) {int c = getState();//如果状态为0,说明没有在执行的线程了返回falseif (c == 0)return false;int nextc = c - 1;//CAS设置stateif (compareAndSetState(c, nextc))//如果nextc==0说明,本次线程执行完之后,就没有可执行的线程了,返回true//相当于释放锁return nextc == 0;}}}
我们知道CountDownLatch的await()方法可以阻塞主线程,我们来看看
public void await() throws InterruptedException {sync.acquireSharedInterruptibly(1);}
最终调用的是tryAcquireShared(arg)方法,之后getState!=0都会返回-1,就是只要还有正在运行的线程就会返回-1。然后就会执行doAcquireSharedInterruptibly(arg)
public final void acquireSharedInterruptibly(int arg)throws InterruptedException {if (Thread.interrupted())throw new InterruptedException();if (tryAcquireShared(arg) < 0)doAcquireSharedInterruptibly(arg);}
看到这个代码就有点熟悉,parkAndCheckInterrupt()会使线程睡眠,所以主线程会睡眠,就相当于阻塞了。
private void doAcquireSharedInterruptibly(int arg)throws InterruptedException {final Node node = addWaiter(Node.SHARED);try {//自旋for (;;) {final Node p = node.predecessor();if (p == head) {int r = tryAcquireShared(arg);if (r >= 0) {setHeadAndPropagate(node, r);p.next = null; // help GCreturn;}}if (shouldParkAfterFailedAcquire(p, node) &&parkAndCheckInterrupt())throw new InterruptedException();}} catch (Throwable t) {cancelAcquire(node);throw t;}
我们再看一下CountDownLatch的countDown()方法
public void countDown() {sync.releaseShared(1);}
这里又调用到内部类Sync的tryReleaseShared(arg)方法了
当执行完最后一个线程并调用countDown()之后tryReleaseShared(arg)返回true,说明要释放锁了
执行doReleaseShared()方法
public final boolean releaseShared(int arg) {if (tryReleaseShared(arg)) {doReleaseShared();return true;}return false;}
doReleaseShared()方法
我们看到unparkSuccessor(h)会释放唤醒主线程,主线程就会继续执行了
private void doReleaseShared() {//自旋for (;;) {Node h = head;if (h != null && h != tail) {int ws = h.waitStatus;if (ws == Node.SIGNAL) {if (!h.compareAndSetWaitStatus(Node.SIGNAL, 0))continue; // loop to recheck casesunparkSuccessor(h);}else if (ws == 0 &&!h.compareAndSetWaitStatus(0, Node.PROPAGATE))continue; // loop on failed CAS}if (h == head) // loop if head changedbreak;}}
1.3 AQS和synchronized 区别
Java中每一个对象都可以作为锁,这是synchronized实现同步的基础:
- 普通同步方法,锁是当前实例对象
- 静态同步方法,锁是当前类的class对象
- 同步方法块,锁是括号里面的对象

- 来源:
lock是一个接口,而synchronized是java的一个关键字,synchronized是内置的语言实现; - 异常是否释放锁:
synchronized在发生异常时候会自动释放占有的锁,因此不会出现死锁;而lock发生异常时候,不会主动释放占有的锁,必须手动unlock来释放锁,可能引起死锁的发生。(所以最好将同步代码块用try catch包起来,finally中写入unlock,避免死锁的发生。) - 是否响应中断
lock等待锁过程中可以用interrupt来中断等待,而synchronized只能等待锁的释放,不能响应中断; - 是否知道获取锁
Lock可以通过trylock来知道有没有获取锁,而synchronized不能; - Lock可以提高多个线程进行读操作的效率。(可以通过readwritelock实现读写分离)
- 在性能上来说,如果竞争资源不激烈,两者的性能是差不多的,而当竞争资源非常激烈时(即有大量线程同时竞争),此时Lock的性能要远远优于synchronized。所以说,在具体使用时要根据适当情况选择。
- synchronized使用Object对象本身的wait 、notify、notifyAll调度机制,而Lock可以使用Condition进行线程之间的调度
- Lock可以实现公平锁和非公平锁,synchronized为非公平锁。
2 红黑树
参考博客【https://juejin.im/post/6844904205526777864】
AVL树的特点:
- 具有二叉查找树的特点(左子树任一节点小于父节点,右子树任一节点大于父节点),任何一个节点的左子树与右子树都是平衡二叉树
- 任一节点的左右子树高度差小于1,即平衡因子为范围为[-1,1]
AVL树比红黑树更加平衡,但AVL树可能在插入和删除过程中引起更多旋转。因此,如果应用程序涉及许多频繁的插入和删除操作,则应首选Red Black树(如 Java 1.8中的HashMap)。如果插入和删除操作的频率较低,而搜索操作的频率较高,则AVL树应优先于红黑树。
红黑树是一种自平衡二叉搜索树(BST),且红黑树节点遵循以下规则:
- 每个节点只能是红色或黑色
- 根节点总是黑色的
- 红色节点的父或子节点都必然是黑色的(两个红色的节点不会相连)
- 从任一节点到其每个叶子的所有路径都包含相同数目的黑色节点。
说白了红黑树的平衡就是为了满足以上的规则。
在讲解插入和删除之前先声明几个概念:

红黑树中真正的叶子结点为nil结点,是黑色,其实所有的叶子结点都指向同一个nil结点,如下图。

左旋右旋:
左旋:以某个结点作为支点(旋转结点),其右子结点变为旋转结点的父结点,右子结点的左子结点变为旋转结点的右子结点,左子结点保持不变。
右旋:以某个结点作为支点(旋转结点),其左子结点变为旋转结点的父结点,左子结点的右子结点变为旋转结点的左子结点,右子结点保持不变

红黑树的插入,删除都分了很多情景,具体的代码操作都是根据这些场景划分去实现的。
2.1 插入
首先需要明白新插入的结点应该是什么颜色?红色还是黑色。
答案:红色。为什么呢?红色在父结点(如果存在)为黑色结点时,红黑树的黑色平衡没被破坏,不需要做自平衡操作。但如果插入结点是黑色,那么插入位置所在的子树黑色结点总是多1,必须做自平衡。
插入场景:
红黑树为空树,插入结点设为根结点,并改为黑色
插入结点已存在,相当于更新,原来结点的值改为插入结点的值
插入结点的的父结点为黑色,直接插入,不需要调整,因为不影响树的平衡
插入结点的父结点为红色,其实主要就是分析这种场景,因为父结点为红色,插入结点为红色所以不满足性质3,需要重新调整树,使其平衡。
可以访问:【https://www.liuchengtu.com/lct/#R19a31f234576b12a21d1e5bcab5fc3ba】
看下图:
2.2 删除
删除的相对插入的更复杂一些。
当我们删除一个结点的时候,我们需要从左子树找到一个最大值或者右子树中找到一个最小值,即前继结点或者后继结点 来进行替换。那么不就相当于删除替换结点。所以有以下结论:
删除结点被替代后,在不考虑结点的键值的情况下,对于树来说,可以认为删除的是替代结点!
那么问题来了,如果没有左子树或者右子树怎么办?那么它本身就相当于替换结点。删除即可。
所有以下场景:
当替换结点为红色的时候,直接删除,不会影响树的平衡
当替换结点为黑色的时候,会破坏红黑树的平衡,需要重新平衡。这里面又分了多种情况,看下图
图片看不清,可以访问【https://www.liuchengtu.com/lct/#R0aa349b388897f1f799e5366cdac32f6】
3 HashMap
源博客【https://www.jianshu.com/p/c658df4f4c77】
我这里完全是copy这个博客的,因为讲的实在很好。
主要从以下几点讲解:
- HashMap 的存储结构
- 常用变量说明,如加载因子等
- HashMap 的四个构造函数
- tableSizeFor()方法及作用
- put()方法详解
- hash()方法,以及避免哈希碰撞的原理
- resize()扩容机制及原理
- get()方法
- 为什么HashMap链表会形成死循环,JDK1.8做了哪些优化
- 链表升级为红黑树分析
说明:本篇主要以JDK1.8的源码来分析,顺带讲下和JDK1.7的一些区别。
3.1 HashMap存储结构
这里需要区分一下,JDK1.7和 JDK1.8之后的 HashMap 存储结构。在JDK1.7及之前,是用数组加链表的方式存储的。
但是,众所周知,当链表的长度特别长的时候,查询效率将直线下降,查询的时间复杂度为 O(n)。因此,JDK1.8 把它设计为达到一个特定的阈值之后,就将链表转化为红黑树。
这里简单说下红黑树的特点:
- 每个节点只有两种颜色:红色或者黑色
- 根节点必须是黑色
- 每个叶子节点(NIL)都是黑色的空节点
- 从根节点到叶子节点,不能出现两个连续的红色节点
- 从任一节点出发,到它下边的子节点的路径包含的黑色节点数目都相同
由于红黑树,是一个自平衡的二叉搜索树,因此可以使查询的时间复杂度降为O(logn)。(红黑树不是本文重点,不了解的童鞋可自行查阅相关资料哈)
HashMap 结构示意图:

3.1 常用的变量
在 HashMap源码中,比较重要的常用变量,主要有以下这些。还有两个内部类来表示普通链表的节点和红黑树节点。
//默认的初始化容量为16,必须是2的n次幂static final int DEFAULT_INITIAL_CAPACITY = 1 << 4; // aka 16//最大容量为 2^30static final int MAXIMUM_CAPACITY = 1 << 30;//默认的加载因子0.75,乘以数组容量得到的值,用来表示元素个数达到多少时,需要扩容。//为什么设置 0.75 这个值呢,简单来说就是时间和空间的权衡。//若小于0.75如0.5,则数组长度达到一半大小就需要扩容,空间使用率大大降低,//若大于0.75如0.8,则会增大hash冲突的概率,影响查询效率。static final float DEFAULT_LOAD_FACTOR = 0.75f;//刚才提到了当链表长度过长时,会有一个阈值,超过这个阈值8就会转化为红黑树static final int TREEIFY_THRESHOLD = 8;//当红黑树上的元素个数,减少到6个时,就退化为链表static final int UNTREEIFY_THRESHOLD = 6;//链表转化为红黑树,除了有阈值的限制,还有另外一个限制,需要数组容量至少达到64,才会树化。//这是为了避免,数组扩容和树化阈值之间的冲突。static final int MIN_TREEIFY_CAPACITY = 64;//存放所有Node节点的数组transient Node<K,V>[] table;//存放所有的键值对transient Set<Map.Entry<K,V>> entrySet;//map中的实际键值对个数,即数组中元素个数transient int size;//每次结构改变时,都会自增,fail-fast机制,这是一种错误检测机制。//当迭代集合的时候,如果结构发生改变,则会发生 fail-fast,抛出异常。transient int modCount;//数组扩容阈值int threshold;//加载因子final float loadFactor;//普通单向链表节点类static class Node<K,V> implements Map.Entry<K,V> {//key的hash值,put和get的时候都需要用到它来确定元素在数组中的位置final int hash;final K key;V value;//指向单链表的下一个节点Node<K,V> next;Node(int hash, K key, V value, Node<K,V> next) {this.hash = hash;this.key = key;this.value = value;this.next = next;}}//转化为红黑树的节点类static final class TreeNode<K,V> extends LinkedHashMap.Entry<K,V> {//当前节点的父节点TreeNode<K,V> parent;//左孩子节点TreeNode<K,V> left;//右孩子节点TreeNode<K,V> right;//指向前一个节点TreeNode<K,V> prev; // needed to unlink next upon deletion//当前节点是红色或者黑色的标识boolean red;TreeNode(int hash, K key, V val, Node<K,V> next) {super(hash, key, val, next);}}
3.2 HashMap 构造函数
HashMap有四个构造函数可供我们使用,一起来看下:
//默认无参构造,指定一个默认的加载因子public HashMap() {this.loadFactor = DEFAULT_LOAD_FACTOR;}//可指定容量的有参构造,但是需要注意当前我们指定的容量并不一定就是实际的容量,下面会说public HashMap(int initialCapacity) {//同样使用默认加载因子this(initialCapacity, DEFAULT_LOAD_FACTOR);}//可指定容量和加载因子,但是笔者不建议自己手动指定非0.75的加载因子public HashMap(int initialCapacity, float loadFactor) {if (initialCapacity < 0)throw new IllegalArgumentException("Illegal initial capacity: " +initialCapacity);if (initialCapacity > MAXIMUM_CAPACITY)initialCapacity = MAXIMUM_CAPACITY;if (loadFactor <= 0 || Float.isNaN(loadFactor))throw new IllegalArgumentException("Illegal load factor: " +loadFactor);this.loadFactor = loadFactor;//这里就是把我们指定的容量改为一个大于它的的最小的2次幂值,如传过来的容量是14,则返回16//注意这里,按理说返回的值应该赋值给 capacity,即保证数组容量总是2的n次幂,为什么这里赋值给了 threshold 呢?//先卖个关子,等到 resize 的时候再说this.threshold = tableSizeFor(initialCapacity);}//可传入一个已有的mappublic HashMap(Map<? extends K, ? extends V> m) {this.loadFactor = DEFAULT_LOAD_FACTOR;putMapEntries(m, false);}//把传入的map里边的元素都加载到当前mapfinal void putMapEntries(Map<? extends K, ? extends V> m, boolean evict) {int s = m.size();if (s > 0) {if (table == null) { // pre-sizefloat ft = ((float)s / loadFactor) + 1.0F;int t = ((ft < (float)MAXIMUM_CAPACITY) ?(int)ft : MAXIMUM_CAPACITY);if (t > threshold)threshold = tableSizeFor(t);}else if (s > threshold)resize();for (Map.Entry<? extends K, ? extends V> e : m.entrySet()) {K key = e.getKey();V value = e.getValue();//put方法的具体实现,后边讲putVal(hash(key), key, value, false, evict);}}}
3.3 tableSizeFor()
上边的第三个构造函数中,调用了 tableSizeFor 方法,这个方法是怎么实现的呢?
static final int tableSizeFor(int cap) {int n = cap - 1;n |= n >>> 1;n |= n >>> 2;n |= n >>> 4;n |= n >>> 8;n |= n >>> 16;return (n < 0) ? 1 : (n >= MAXIMUM_CAPACITY) ? MAXIMUM_CAPACITY : n + 1;}
我们以传入参数为14 来举例,计算这个过程。
首先,14传进去之后先减1,n此时为13。然后是一系列的无符号右移运算。
//13的二进制0000 0000 0000 0000 0000 0000 0000 1101//无右移1位,高位补00000 0000 0000 0000 0000 0000 0000 0110//然后把它和原来的13做或运算得到,此时的n值0000 0000 0000 0000 0000 0000 0000 1111//再以上边的值,右移2位0000 0000 0000 0000 0000 0000 0000 0011//然后和第一次或运算之后的 n 值再做或运算,此时得到的n值0000 0000 0000 0000 0000 0000 0000 1111...//我们会发现,再执行右移 4,8,16位,同样n的值不变//当n小于0时,返回1,否则判断是否大于最大容量,是的话返回最大容量,否则返回 n+1return (n < 0) ? 1 : (n >= MAXIMUM_CAPACITY) ? MAXIMUM_CAPACITY : n + 1;//很明显我们这里返回的是 n+1 的值,0000 0000 0000 0000 0000 0000 0000 1111+ 10000 0000 0000 0000 0000 0000 0001 0000
将它转为十进制,就是 2^4 = 16 。我们会发现一个规律,以上的右移运算,最终会把最低位的值都转化为 1111 这样的结构,然后再加1,就是1 0000 这样的结构,它一定是 2的n次幂。因此,这个方法返回的就是大于当前传入值的最小(最接近当前值)的一个2的n次幂的值。
3.4 put()方法详解
//put方法,会先调用一个hash()方法,得到当前key的一个hash值,//用于确定当前key应该存放在数组的哪个下标位置//这里的 hash方法,我们姑且先认为是key.hashCode(),其实不是的,一会儿细讲public V put(K key, V value) {return putVal(hash(key), key, value, false, true);}//把hash值和当前的key,value传入进来//这里onlyIfAbsent如果为true,表明不能修改已经存在的值,因此我们传入false//evict只有在方法 afterNodeInsertion(boolean evict) { }用到,可以看到它是一个空实现,因此不用关注这个参数final V putVal(int hash, K key, V value, boolean onlyIfAbsent,boolean evict) {Node<K,V>[] tab; Node<K,V> p; int n, i;//判断table是否为空,如果空的话,会先调用resize扩容if ((tab = table) == null || (n = tab.length) == 0)n = (tab = resize()).length;//根据当前key的hash值找到它在数组中的下标,判断当前下标位置是否已经存在元素,//若没有,则把key、value包装成Node节点,直接添加到此位置。// i = (n - 1) & hash 是计算下标位置的,为什么这样算,后边讲if ((p = tab[i = (n - 1) & hash]) == null)tab[i] = newNode(hash, key, value, null);else {//如果当前位置已经有元素了,分为三种情况。Node<K,V> e; K k;//1.当前位置元素的hash值等于传过来的hash,并且他们的key值也相等,//则把p赋值给e,跳转到①处,后续需要做值的覆盖处理if (p.hash == hash &&((k = p.key) == key || (key != null && key.equals(k))))e = p;//2.如果当前是红黑树结构,则把它加入到红黑树else if (p instanceof TreeNode)e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);else {//遍历链表//3.说明此位置已存在元素,并且是普通链表结构,则采用尾插法,把新节点加入到链表尾部for (int binCount = 0; ; ++binCount) {if ((e = p.next) == null) {//如果头结点的下一个节点为空,则插入新节点p.next = newNode(hash, key, value, null);//如果在插入的过程中,链表长度超过了8,则转化为红黑树if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1sttreeifyBin(tab, hash);//插入成功之后,跳出循环,跳转到①处break;}//若在链表中找到了相同key的话,直接退出循环,跳转到①处if (e.hash == hash &&((k = e.key) == key || (key != null && key.equals(k))))break;//链表遍历p = e;}}//说明发生了碰撞,e代表的是旧值,因此节点位置不变,但是需要替换为新值if (e != null) { // existing mapping for keyV oldValue = e.value;//用新值替换旧值,并返回旧值。//如果用户值替换或者oldValue为空,说明e的旧值本来就是空的,因为hashmap可存空值if (!onlyIfAbsent || oldValue == null)e.value = value;//看方法名字即可知,这是在node被访问之后需要做的操作。其实此处是一个空实现,//只有在 LinkedHashMap才会实现,用于实现根据访问先后顺序对元素进行排序,hashmap不提供排序功能// Callbacks to allow LinkedHashMap post-actions//void afterNodeAccess(Node<K,V> p) { }afterNodeAccess(e);return oldValue;}}//fail-fast机制++modCount;//如果当前数组中的元素个数超过阈值,则扩容if (++size > threshold)resize();//同样的空实现afterNodeInsertion(evict);return null;}
3.5 hash()计算原理
前面 put 方法中说到,需要先把当前key进行哈希处理,我们看下这个方法是怎么实现的。
static final int hash(Object key) {int h;return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);}
这里,会先判断key是否为空,若为空则返回0。这也说明了hashMap是支持key传 null 的。若非空,则先计算key的hashCode值,赋值给h,然后把h右移16位,并与原来的h进行异或处理。为什么要这样做,这样做有什么好处呢?
我们知道,hashCode()方法继承自父类Object,它返回的是一个 int 类型的数值,可以保证同一个应用单次执行的每次调用,返回结果都是相同的(这个说明可以在hashCode源码上找到),这就保证了hash的确定性。在此基础上,再进行某些固定的运算,肯定结果也是可以确定的。
我随便运行一段程序,把它的 hashCode的二进制打印出来,如下。
public static void main(String[] args) {Object o = new Object();int hash = o.hashCode();System.out.println(hash);System.out.println(Integer.toBinaryString(hash));}//1836019240//1101101011011110110111000101000
然后,进行 (h = key.hashCode()) ^ (h >>> 16) 这一段运算。
//h原来的值0110 1101 0110 1111 0110 1110 0010 1000//无符号右移16位,其实相当于把低位16位舍去,只保留高16位0000 0000 0000 0000 0110 1101 0110 1111//然后高16位和原 h进行异或运算0110 1101 0110 1111 0110 1110 0010 1000^0000 0000 0000 0000 0110 1101 0110 1111=0110 1101 0110 1111 0000 0011 0100 0111
可以看到,其实相当于,我们把高16位值和当前h的低16位进行了混合,这样可以尽量保留高16位的特征,从而降低哈希碰撞的概率。
思考一下,为什么这样做,就可以降低哈希碰撞的概率呢?先别着急,我们需要结合 i = (n - 1) & hash 这一段运算来理解。
(n-1) & hash 作用
//②//这是 put 方法中用来根据hash()值寻找在数组中的下标的逻辑,//n为数组长度, hash为调用 hash()方法混合处理之后的hash值。i = (n - 1) & hash
我们知道,如果给定某个数值,去找它在某个数组中的下标位置时,直接用模运算就可以了(假设数组值从0开始递增)。如,我找 14 在数组长度为16的数组中的下标,即为 14 % 16,等于14 。 18的位置即为 18%16,等于2。
而②中,就是取模运算的位运算形式。以18%16为例
//18的二进制0001 0010//16 -1 即 15的二进制0000 1111//与运算之后的结果为0000 0010// 可以看到,上边的结果转化为十进制就是 2 。//其实我们会发现一个规律,因为n是2的n次幂,因此它的二进制表现形式肯定是类似于0001 0000//这样的形式,只有一个位是1,其他位都是0。而它减 1 之后的形式就是类似于0000 1111//这样的形式,高位都是0,低位都是1,因此它和任意值进行与运算,结果值肯定在这个区间内0000 0000 ~ 0000 1111//也就是0到15之间,(以n为16为例)//因此,这个运算就可以实现取模运算,而且位运算还有个好处,就是速度比较快。
为什么高低位异或运算可以减少哈希碰撞
我们想象一下,假如用 key 原来的hashCode值,直接和 (n-1) 进行与运算来求数组下标,而不进行高低位混合运算,会产生什么样的结果。
//例如我有另外一个h2,和原来的 h相比较,高16位有很大的不同,但是低16位相似度很高,甚至相同的话。//原h值0110 1101 0110 1111 0110 1110 0010 1000//另外一个h2值0100 0101 1110 1011 0110 0110 0010 1000// n -1 ,即 15 的二进制0000 0000 0000 0000 0000 0000 0000 1111//可以发现 h2 和 h 的高位不相同,但是低位相似度非常高。//他们分别和 n -1 进行与运算时,得到的结果却是相同的。(此处n假设为16)//因为 n-1 的高16位都是0,不管 h 的高 16 位是什么,与运算之后,都不影响最终结果,高位一定全是 0//因此,哈希碰撞的概率就大大增加了,并且 h 的高16 位特征全都丢失了。
爱思考的同学可能就会有疑问了,我进行高低16位混合运算,是可以的,这样可以保证尽量减少高区位的特征。那么,为什么选择用异或运算呢,我用与、或、非运算不行吗?
这是有一定的道理的。我们看一个表格,就能明白了。

可以看到两个值进行与运算,结果会趋向于0;或运算,结果会趋向于1;而只有异或运算,0和1的比例可以达到1:1的平衡状态。(非呢?别扯犊子了,两个值怎么做非运算。。。)
所以,异或运算之后,可以让结果的随机性更大,而随机性大了之后,哈希碰撞的概率当然就更小了。
以上,就是为什么要对一个hash值进行高低位混合,并且选择异或运算来混合的原因。
3.6 resize() 扩容机制
在上边 put 方法中,我们会发现,当数组为空的时候,会调用 resize 方法,当数组的 size 大于阈值的时候,也会调用 resize方法。 那么看下 resize 方法都做了哪些事情吧。
final Node<K,V>[] resize() {//旧数组Node<K,V>[] oldTab = table;//旧数组的容量int oldCap = (oldTab == null) ? 0 : oldTab.length;//旧数组的扩容阈值,注意看,这里取的是当前对象的 threshold 值,下边的第2种情况会用到。int oldThr = threshold;//初始化新数组的容量和阈值,分三种情况讨论。int newCap, newThr = 0;//1.当旧数组的容量大于0时,说明在这之前肯定调用过 resize扩容过一次,才会导致旧容量不为0。//为什么这样说呢,之前我在 tableSizeFor 卖了个关子,需要注意的是,它返回的值是赋给了 threshold 而不是 capacity。//我们在这之前,压根就没有在任何地方看到过,它给 capacity 赋初始值。if (oldCap > 0) {//容量达到了最大值if (oldCap >= MAXIMUM_CAPACITY) {threshold = Integer.MAX_VALUE;return oldTab;}//新数组的容量和阈值都扩大原来的2倍else if ((newCap = oldCap << 1) < MAXIMUM_CAPACITY &&oldCap >= DEFAULT_INITIAL_CAPACITY)newThr = oldThr << 1; // double threshold}//2.到这里,说明 oldCap <= 0,并且 oldThr(threshold) > 0,这就是 map 初始化的时候,第一次调用 resize的情况//而 oldThr的值等于 threshold,此时的 threshold 是通过 tableSizeFor 方法得到的一个2的n次幂的值(我们以16为例)。//因此,需要把 oldThr 的值,也就是 threshold ,赋值给新数组的容量 newCap,以保证数组的容量是2的n次幂。//所以我们可以得出结论,当map第一次 put 元素的时候,就会走到这个分支,把数组的容量设置为正确的值(2的n次幂)//但是,此时 threshold 的值也是2的n次幂,这不对啊,它应该是数组的容量乘以加载因子才对。别着急,这个会在③处理。else if (oldThr > 0) // initial capacity was placed in thresholdnewCap = oldThr;//3.到这里,说明 oldCap 和 oldThr 都是小于等于0的。也说明我们的map是通过默认无参构造来创建的,//于是,数组的容量和阈值都取默认值就可以了,即 16 和 12。else { // zero initial threshold signifies using defaultsnewCap = DEFAULT_INITIAL_CAPACITY;newThr = (int)(DEFAULT_LOAD_FACTOR * DEFAULT_INITIAL_CAPACITY);}//③ 这里就是处理第2种情况,因为只有这种情况 newThr 才为0,//因此计算 newThr(用 newCap即16 乘以加载因子 0.75,得到 12) ,并把它赋值给 thresholdif (newThr == 0) {float ft = (float)newCap * loadFactor;newThr = (newCap < MAXIMUM_CAPACITY && ft < (float)MAXIMUM_CAPACITY ?(int)ft : Integer.MAX_VALUE);}//赋予 threshold 正确的值,表示数组下次需要扩容的阈值(此时就把原来的 16 修正为了 12)。threshold = newThr;@SuppressWarnings({"rawtypes","unchecked"})Node<K,V>[] newTab = (Node<K,V>[])new Node[newCap];table = newTab;//如果原来的数组不为空,那么我们就需要把原来数组中的元素重新分配到新的数组中//如果是第2种情况,由于是第一次调用resize,此时数组肯定是空的,因此也就不需要重新分配元素。if (oldTab != null) {//遍历旧数组for (int j = 0; j < oldCap; ++j) {Node<K,V> e;//取到当前下标的第一个元素,如果存在,则分三种情况重新分配位置if ((e = oldTab[j]) != null) {oldTab[j] = null;//1.如果当前元素的下一个元素为空,则说明此处只有一个元素//则直接用它的hash()值和新数组的容量取模就可以了,得到新的下标位置。if (e.next == null)newTab[e.hash & (newCap - 1)] = e;//2.如果是红黑树结构,则拆分红黑树,必要时有可能退化为链表else if (e instanceof TreeNode)((TreeNode<K,V>)e).split(this, newTab, j, oldCap);//3.到这里说明,这是一个长度大于 1 的普通链表,则需要计算并//判断当前位置的链表是否需要移动到新的位置//同一个数组里面的链表的hash值都是一样的,所以只需要移动头部就可以else { // preserve order// loHead 和 loTail 分别代表链表旧位置的头尾节点Node<K,V> loHead = null, loTail = null;// hiHead 和 hiTail 分别代表链表移动到新位置的头尾节点Node<K,V> hiHead = null, hiTail = null;Node<K,V> next;do {next = e.next;//如果当前元素的hash值和oldCap做与运算为0,则原位置不变if ((e.hash & oldCap) == 0) {if (loTail == null)loHead = e;elseloTail.next = e;loTail = e;}//否则,需要移动到新的位置else {if (hiTail == null)hiHead = e;elsehiTail.next = e;hiTail = e;}} while ((e = next) != null);//原位置不变的一条链表,数组下标不变if (loTail != null) {loTail.next = null;newTab[j] = loHead;}//移动到新位置的一条链表,数组下标为原下标加上旧数组的容量if (hiTail != null) {hiTail.next = null;newTab[j + oldCap] = hiHead;}}}}}return newTab;}
上边还有一个非常重要的运算,我们没有讲解。就是下边这个判断,它用于把原来的普通链表拆分为两条链表,位置不变或者放在新的位置。
if ((e.hash & oldCap) == 0) {} else {}
我们以原数组容量16为例,扩容之后容量为32。说明下为什么这样计算。
还是用之前的hash值举例。
//e.hash值0110 1101 0110 1111 0110 1110 0010 1000//oldCap值,即160000 0000 0000 0000 0000 0000 0001 0000//做与运算,我们会发现结果不是0就是非0,//而且它取决于 e.hash 二进制位的倒数第五位是 0 还是 1,//若倒数第五位为0,则结果为0,若倒数第五位为1,则结果为非0。//那这个和新数组有什么关系呢?//别着急,我们看下新数组的容量是32,如果求当前hash值在新数组中的下标,则为// e.hash &( 32 - 1) 这样的运算 ,即 hash 与 31 进行与运算,0110 1101 0110 1111 0110 1110 0010 1000&0000 0000 0000 0000 0000 0000 0001 1111=0000 0000 0000 0000 0000 0000 0000 1000//接下来,我们对比原来的下标计算结果和新的下标结果,看图
看下面的图,我们观察,hash值和旧数组进行与运算的结果 ,跟新数组的与运算结果有什么不同。

会发现一个规律:
若hash值的倒数第五位是0,则新下标与旧下标结果相同,都为 0000 1000
若hash值的倒数第五位是1,则新下标(0001 1000)与旧下标(0000 1000)结果值相差了 16 。
因此,我们就可以根据 (e.hash & oldCap == 0) 这个判断的真假来决定,当前元素应该在原来的位置不变,还是在新的位置(原位置 + 16)。
如果,上边的推理还是不明白的话,我再举个简单的例子。
18%16=2 18%32=1834%16=2 34%32=250%16=2 50%32=18
怎么样,发现规律没,有没有那个感觉了?
计算中的18,34 ,50 其实就相当于 e.hash 值,和新旧数组做取模运算,得到的结果,要么就是原来的位置不变,要么就是原来的位置加上旧数组的长度。
3.7 get()方法
有了前面的基础,get方法就比较简单了。
public V get(Object key) {Node<K,V> e;//如果节点为空,则返回null,否则返回节点的value。这也说明,hashMap是支持value为null的。//因此,我们就明白了,为什么hashMap支持Key和value都为nullreturn (e = getNode(hash(key), key)) == null ? null : e.value;}final Node<K,V> getNode(int hash, Object key) {Node<K,V>[] tab; Node<K,V> first, e; int n; K k;//首先要确保数组不能为空,然后取到当前hash值计算出来的下标位置的第一个元素if ((tab = table) != null && (n = tab.length) > 0 &&(first = tab[(n - 1) & hash]) != null) {//若hash值和key都相等,则说明我们要找的就是第一个元素,直接返回if (first.hash == hash && // always check first node((k = first.key) == key || (key != null && key.equals(k))))return first;//如果不是的话,就遍历当前链表(或红黑树)if ((e = first.next) != null) {//如果是红黑树结构,则找到当前key所在的节点位置if (first instanceof TreeNode)return ((TreeNode<K,V>)first).getTreeNode(hash, key);//如果是普通链表,则向后遍历查找,直到找到或者遍历到链表末尾为止。do {if (e.hash == hash &&((k = e.key) == key || (key != null && key.equals(k))))return e;} while ((e = e.next) != null);}}//否则,说明没有找到,返回nullreturn null;}
3.8 为什么HashMap链表会形成死循环
准确的讲应该是 JDK1.7 的 HashMap 链表会有死循环的可能,因为JDK1.7是采用的头插法,在多线程环境下有可能会使链表形成环状,从而导致死循环。JDK1.8做了改进,用的是尾插法,不会产生死循环。
那么,链表是怎么形成环状的呢?
关于这一点的解释,我发现网上文章抄来抄去的,而且都来自左耳朵耗子,更惊奇的是,连配图都是一模一样的。(别问我为什么知道,因为我也看过耗子的文章,哈哈。然而,菜鸡的我,那篇文章,并没有看懂。。。)
我实在看不下去了,于是一怒之下,就有了这篇文章。我会照着源码一步一步的分析变量之间的关系怎么变化的,并有配图哦。
我们从 put()方法开始,最终找到线程不安全的那个方法。这里省略中间不重要的过程,我只把方法的跳转流程贴出来:
//添加元素方法 -> 添加新节点方法 -> 扩容方法 -> 把原数组元素重新分配到新数组中put() --> addEntry() --> resize() --> transfer()
问题就发生在 transfer 这个方法中。

图1
我们假设,原数组容量只有2,其中一条链表上有两个元素 A,B,如下图

现在,有两个线程都执行 transfer 方法。每个线程都会在它们自己的工作内存生成一个newTable 的数组,用于存储变化后的链表,它们互不影响(这里互不影响,指的是两个新数组本身互不影响)。但是,需要注意的是,它们操作的数据却是同一份。
因为,真正的数组中的内容在堆中存储,它们指向的是同一份数据内容。就相当于,有两个不同的引用 X,Y,但是它们都指向同一个对象 Z。这里 X、Y就是两个线程不同的新数组,Z就是堆中的A,B 等元素对象。
假设线程一执行到了上图1中所指的代码①处,恰好 CPU 时间片到了,线程被挂起,不能继续执行了。 记住此时,线程一中记录的 e = A , e.next = B。
然后线程二正常执行,扩容后的数组长度为 4, 假设 A,B两个元素又碰撞到了同一个桶中。然后,通过几次 while 循环后,采用头插法,最终呈现的结构如下:

此时,线程一解挂,继续往下执行。注意,此时线程一,记录的还是 e = A,e.next = B,因为它还未感知到最新的变化。
我们主要关注图1中标注的①②③④处的变量变化:
/*** next = e.next* e.next = newTable[i]* newTable[i] = e;* e = next;*///第一次循环,(伪代码)e=A;next=B;e.next=null //此时线程一的新数组刚初始化完成,还没有元素newTab[i] = A->null //把A节点头插到新数组中e=B; //下次循环的e值
第一次循环结束后,线程一新数组的结构如下图:

然后,由于 e=B,不为空,进入第二次循环。
//第二次循环e=B;next=A; //此时A,B的内容已经被线程二修改为 B->A->null,然后被线程一读到,所以B的下一个节点指向Ae.next=A->null // A->null 为第一次循环后线程一新数组的结构newTab[i] = B->A->null //新节点B插入之后,线程一新数组的结构e=A; //下次循环的 e 值
第二次循环结束后,线程一新数组的结构如下图:

此时,由于 e=A,不为空,继续循环。
//第三次循环e=A;next=null; // A节点后边已经没有节点了e.next= B->A->null // B->A->null 为第二次循环后线程一新数组的结构//我们把A插入后,抽象的表达为 A->B->A->null,但是,A只能是一个,不能分身啊//因此实际上是 e(A).next指向发生了变化,A的 next 由指向 null 改为指向了 B,//而 B 本身又指向A,因此A和B互相指向,成环newTab[i] = A->B 且 B->Ae=next=null; //e此时为空,结束循环
第三次循环结束后,看下图,A的指向由 null ,改为指向为 B,因此 A 和 B 之间成环。

这时,有的同学可能就会问了,就算他们成环了,又怎样,跟死循环有什么关系?
我们看下 get() 方法(最终调用 getEntry 方法),

可以看到查找元素时,只要 e 不为空,就会一直循环查找下去。若有某个元素 C 的 hash 值也落在了和 A,B元素同一个桶中,则会由于, A,B互相指向,e.next 永远不为空,就会形成死循环。
3.9 链表升级为红黑树分析
在putVal方法里面
for (int binCount = 0; ; ++binCount) {if ((e = p.next) == null) {p.next = newNode(hash, key, value, null);//当链表的长度>=8的时候转化为红黑树if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1sttreeifyBin(tab, hash);break;}if (e.hash == hash &&((k = e.key) == key || (key != null && key.equals(k))))break;p = e;}
treeifyBin分析
所以,链表的长度大于8的时候不一定会扩容,还要看数组的长度是否小于64,如果小于64是进行扩容而不是升级为红黑树
final void treeifyBin(Node<K,V>[] tab, int hash) {int n, index; Node<K,V> e;//当数组为空,或者数组的长度小于64的时候扩容if (tab == null || (n = tab.length) < MIN_TREEIFY_CAPACITY)resize();//根据hash值取出链表头else if ((e = tab[index = (n - 1) & hash]) != null) {TreeNode<K,V> hd = null, tl = null;do {//将Node对象转化为TreeNode对象 其实TreeNode继承NodeTreeNode<K,V> p = replacementTreeNode(e, null);//第一次t1为nullif (tl == null)//链表头给hdhd = p;else {//前一个结点p.prev = tl;//后一个结点tl.next = p;}tl = p;//从头取出链表中的数据} while ((e = e.next) != null);//上面的代码还没转成红黑树,只是转成TreeNode而已,并且也是一个双向链表的结构//将数组tab[index]位置的数据改为hd//然后将hd转成红黑树if ((tab[index] = hd) != null)hd.treeify(tab);}}TreeNode<K,V> replacementTreeNode(Node<K,V> p, Node<K,V> next) {//将Node里面的值取出来,转化为TreeNode对象return new TreeNode<>(p.hash, p.key, p.value, next);}
treeify()方法
final void treeify(Node<K,V>[] tab) {TreeNode<K,V> root = null;//从头遍历TreeNode,这时TreeNode还是一个双向链表for (TreeNode<K,V> x = this, next; x != null; x = next) {//下一个结点next = (TreeNode<K,V>)x.next;//左子,右子x.left = x.right = null;//第一次时root为null,然后将根结点设为链表头部,并设为黑色if (root == null) {x.parent = null;//设为黑色x.red = false;//根结点设为链表头部root = x;}else {//取出结点的key,hash值K k = x.key;int h = x.hash;Class<?> kc = null;//这里相当于while(true)//循环找到叶结点插入 其实就是树的遍历,找到插入位置for (TreeNode<K,V> p = root;;) {//这里的dir应该是direction的缩写int dir, ph;//父结点的keyK pk = p.key;//结点的hash值和父结点比较 如果小于父结点hash值 dir=-1if ((ph = p.hash) > h)dir = -1;//如果大于父结点的hash值 dir=1else if (ph < h)dir = 1;//上面两种情况如果通过链表直接升级为红黑树是不会出现的,因为hash值出现了//碰撞才会放在链表中呀,hash值都是一样的,所以比较就没意思了//是添加的数据的时候,在数组中存储的为红黑树根结点时才会出现//这里会判断HashMap的key是否实现了Comparable接口//如果没有实现或者实现了但是调用compareTo方法的时候key相等就会//进入dir = tieBreakOrder(k, pk);逻辑else if ((kc == null &&(kc = comparableClassFor(k)) == null) ||(dir = compareComparables(kc, k, pk)) == 0)//先比较全类名字符串,如果是同一个类,再比较全类名的identityHashCodedir = tieBreakOrder(k, pk);//p赋给xpTreeNode<K,V> xp = p;//这里会将父结点的左子或者右子赋给p,不断轮询,直到//如果dir<=0即当前结点的hash值小于父结点的hash值 判断父结点左子是否存在//如果dir>0即当前结点的hash值大于父结点的hash值 判断父结点右子是否存在//目的:循环找到叶结点插入 其实就是树的遍历,找到插入位置if ((p = (dir <= 0) ? p.left : p.right) == null) {//当前结点的父结点为xpx.parent = xp;if (dir <= 0)//左子设为xxp.left = x;else//右子设为xxp.right = x;//插入并自平衡//平衡后的父结点root = balanceInsertion(root, x);break;}}}}moveRootToFront(tab, root);}static int tieBreakOrder(Object a, Object b) {int d;if (a == null || b == null ||(d = a.getClass().getName().compareTo(b.getClass().getName())) == 0)d = (System.identityHashCode(a) <= System.identityHashCode(b) ?-1 : 1);return d;}
balanceInsertion()方法分析完之后,这里就是2.1红黑树插入解析的代码实现,不管是插入平衡,还是左旋右旋。完全符合上面分析的场景。
如果后面要用到代码实现红黑树,可以直接用这里的代码。不过这里的源码很多都是在判断的地方赋值,看着有点头晕。自己看源码的时候可以分为多步操作。
static <K,V> TreeNode<K,V> balanceInsertion(TreeNode<K,V> root,TreeNode<K,V> x) {//插入结点为红色x.red = true;//x插入结点,xp父结点,xpp祖父结点,xpp1祖父结点左子,xppr祖父结点右子//循环for (TreeNode<K,V> xp, xpp, xppl, xppr;;) {//x.parent赋给xp,如果插入结点的父结点为空,说明树为空x设为根结点if ((xp = x.parent) == null) {x.red = false;return x;}//如果父结点为黑色结点或者父结点为根结点else if (!xp.red || (xpp = xp.parent) == null)return root;//以上为红黑树的前两种场景,因为没有对树进行平衡处理,所以根结点不会变//下面是父结点为红色的场景 五种情况 看上面红黑树2.1的插入分析//如果父结点为祖父结点的左子if (xp == (xppl = xpp.left)) {//如果父结点的兄弟结点不为空,并且是红色if ((xppr = xpp.right) != null && xppr.red) {//父结点,父结点的兄弟结点设为黑丝,祖父结点设为红色xppr.red = false;xp.red = false;xpp.red = true;//因为将祖父结点设为红色,所以需要将祖父结点当作一个新插入的结点来处理x = xpp;}//这种情况其实是父结点的兄弟结点不存在else {//如果插入结点为父结点的右子结点if (x == xp.right) {//以父结点xp为轴先左旋//root = rotateLeft(root, x = xp);//代码可以改为//x = xp; 左旋之后xp//root = rotateLeft(root,xp);//xp=x.parent; 这里xp变为原来的x了//判断祖父结点是否为空,如果不为空//xpp = xp == null? null : xp.parent;xpp = (xp = x.parent) == null ? null : xp.parent;}//如果父结点不为nullif (xp != null) {//父结点变为黑色xp.red = false;if (xpp != null) {//祖父结点变为红色xpp.red = true;//以祖父结点xpp为轴右旋root = rotateRight(root, xpp);}}}}//如果父结点为祖父结点的右子else {//如果父结点的兄弟结点不为空,并且是红色if (xppl != null && xppl.red) {//父结点,父结点的兄弟结点设为黑丝,祖父结点设为红色xppl.red = false;xp.red = false;xpp.red = true;//因为将祖父结点设为红色,所以需要将祖父结点当作一个新插入的结点来处理x = xpp;}else {//如果插入结点为父结点的左子结点if (x == xp.left) {//先右旋root = rotateRight(root, x = xp);xpp = (xp = x.parent) == null ? null : xp.parent;}//如果父结点不为nullif (xp != null) {//父结点设为黑色xp.red = false;if (xpp != null) {//祖父结点变为红色xpp.red = true;//左旋root = rotateLeft(root, xpp);}}}}}}
左旋代码实现

static <K,V> TreeNode<K,V> rotateLeft(TreeNode<K,V> root,TreeNode<K,V> p) {TreeNode<K,V> r, pp, rl;if (p != null && (r = p.right) != null) {if ((rl = p.right = r.left) != null)rl.parent = p;if ((pp = r.parent = p.parent) == null)(root = r).red = false;else if (pp.left == p)pp.left = r;elsepp.right = r;r.left = p;p.parent = r;}return root;}
右旋代码实现

static <K,V> TreeNode<K,V> rotateRight(TreeNode<K,V> root,TreeNode<K,V> p) {TreeNode<K,V> l, pp, lr;if (p != null && (l = p.left) != null) {if ((lr = p.left = l.right) != null)lr.parent = p;if ((pp = l.parent = p.parent) == null)(root = l).red = false;else if (pp.right == p)pp.right = l;elsepp.left = l;l.right = p;p.parent = l;}return root;}
3.10 总结
HashMap的capacity(容量)为2的n次方。如果初始设为3那么真实capacity为4,如果设为5那么真实capacity为8,就是大于等于传入的初始容量的最小2的n次幂。
扩容阈值为真实capacity*加载因子(默认0.75,通常不需要修改),当往HashMap中放入数据之后会判断size是否大于threshold(阈值),如果大于threshold会进行扩容。扩容是很浪费时间的,扩容不光是对数组进行扩容,还要进行数据的迁移。类似于数据库分片之后,增加数据库结点需要对数据迁移。
默认的加载因子0.75,乘以数组容量得到的值,用来表示元素个数达到多少时,需要扩容。
为什么设置 0.75 这个值呢,简单来说就是时间和空间的权衡。
若小于0.75如0.5,则数组长度达到一半大小就需要扩容,空间使用率大大降低,
若大于0.75如0.8,则会增大hash冲突的概率,影响查询效率。当对数组进行扩容的时候capacity会变为原来的两倍,threshold也变为原来的两倍
所以当使用HashMap的时候,如果大致知道需要放多少数据,最好通过计算怎么让HashMap在插入过程中不需要进行扩容。其实大一点比较好。newCapacity = oldCapacity;newThr=oldThr*2;
HashMap第一次插入数据的时候,会执行resize()方法进行扩容,数组初始化为真实capacity。
如果HashMap中只放一条记录,也一定不要new HashMap(1);这样threshold就为0。第一次插入完成就会进行扩容。(可以new HashMap(2))
我们发现当链表结构的长度大于8的时候需要调用方法treeifyBin(Node
if (tab == null || (n = tab.length) < MIN_TREEIFY_CAPACITY)resize();
3.11 LinkedHashMap
LinkedHashMap 主要是维护了一份加入节点的双向链表。在遍历的时候可以按照这一份双向链表去顺序遍历。使用的是尾插法。
LinkedHashMap 继承了HashMap并且重写了HahsMap的一些方法
插入的时候主要用到了这三个重写的方法:
new Node(..)
Node<K,V> newNode(int hash, K key, V value, Node<K,V> e) {// LinkedHashMap.Entry 继承了Hash.NodeLinkedHashMap.Entry<K,V> p =new LinkedHashMap.Entry<K,V>(hash, key, value, e);linkNodeLast(p);return p;}private void linkNodeLast(LinkedHashMap.Entry<K,V> p) {//放到尾部LinkedHashMap.Entry<K,V> last = tail;tail = p;if (last == null)head = p;else {p.before = last;last.after = p;}}
afterNodeAccess(e)方法,这个HashMap没有实现,LinkedHashMap实现了。这个方法的意思是节点访问处理。
当key存在的时候,会调用这个方法。主要就是为了将这个节点移动的末尾。当然前提是acceessOrder为true,默认是为false的。将访问之后的节点放到后面就是为了实现LRU吧。
当调用get方法的时候也会调用该方法。
void afterNodeAccess(Node<K,V> e) { // move node to lastLinkedHashMap.Entry<K,V> last;if (accessOrder && (last = tail) != e) {LinkedHashMap.Entry<K,V> p =(LinkedHashMap.Entry<K,V>)e, b = p.before, a = p.after;p.after = null;if (b == null)head = a;elseb.after = a;if (a != null)a.before = b;elselast = b;if (last == null)head = p;else {p.before = last;last.after = p;}tail = p;++modCount;}}
afterNodeInsertion(boolean evict)方法 HashMap也未实现 LinkedHashMap实现,看方法的名字是节点插入的之后要做什么。
evict的意思是移除。removeEldestEntry(first) 这个方法LinkedHashMap是返回的false 就是不移除。其实是为了给LinkedHahsMap子类用的,利用这个方法可以做到LRU,移除头部节点。
void afterNodeInsertion(boolean evict) { // possibly remove eldestLinkedHashMap.Entry<K,V> first;if (evict && (first = head) != null && removeEldestEntry(first)) {K key = first.key;removeNode(hash(key), key, null, false, true);}}
删除key
LinkedHashMap实现了HashMap的afterNodeRemoval方法,就是移除之后,LinkedHashMap也需要Unlink,从链表中移除这个节点。
void afterNodeRemoval(Node<K,V> e) { // unlinkLinkedHashMap.Entry<K,V> p =(LinkedHashMap.Entry<K,V>)e, b = p.before, a = p.after;p.before = p.after = null;if (b == null)head = a;elseb.after = a;if (a == null)tail = b;elsea.before = b;}
4 ConcurrentHashMap
这篇文章,我打算从以下几个方面来讲。
1)多线程下的 HashMap 有什么问题?
2)怎样保证线程安全,为什么选用 ConcurrentHashMap?
3)ConcurrentHashMap 1.7 源码解析
- 底层存储结构
- 常用变量
- 构造函数
- put() 方法
- ensureSegment() 方法
- scanAndLockForPut() 方法
- rehash() 扩容机制
- get() 获取元素方法
- remove() 方法
- size() 方法是怎么统计元素个数的
4)ConcurrentHashMap 1.8 源码解析
- put()方法详解
- initTable()初始化表
- addCount()方法
- fullAddCount()方法
- transfer()是怎样扩容和迁移元素的
- helpTransfer()方法帮助迁移元素
多线程下 HashMap 有什么问题?
在上一篇文章中,已经讲解了 HashMap 1.7 死循环的成因,也正因为如此,我们才说 HashMap 在多线程下是不安全的。但是,在JDK1.8 的 HashMap 改为采用尾插法,已经不存在死循环的问题了,为什么也会线程不安全呢?
我们以 put 方法为例(1.8),

假如现在有两个线程都执行到了上图中的划线处。当线程一判断为空之后,CPU 时间片到了,被挂起。线程二也执行到此处判断为空,继续执行下一句,创建了一个新节点,插入到此下标位置。然后,线程一解挂,同样认为此下标的元素为空,因此也创建了一个新节点放在此下标处,因此造成了元素的覆盖。
所以,可以看到不管是 JDK1.7 还是 1.8 的 HashMap 都存在线程安全的问题。那么,在多线程环境下,应该怎样去保证线程安全呢?
怎样保证线程安全,为什么选用 ConcurrentHashMap?
首先,你可能想到,在多线程环境下用 Hashtable 来解决线程安全的问题。这样确实是可以的,但是同样的它也有缺点,我们看下最常用的 put 方法和 get 方法。

Hashtable-put

Hatable-get
可以看到,不管是往 map 里边添加元素还是获取元素,都会用 synchronized 关键字加锁。当有多个元素之前存在资源竞争时,只能有一个线程可以获取到锁,操作资源。更不能忍的是,一个简单的读取操作,互相之间又不影响,为什么也不能同时进行呢?因为可能存在其他线程增删改呀
所以,hashtable 的缺点显而易见,它不管是 get 还是 put 操作,都是锁住了整个 table,效率低下,因此 并不适合高并发场景。
也许,你还会想起来一个集合工具类 Collections,生成一个SynchronizedMap。其实,它和 Hashtable 差不多,同样的原因,锁住整张表,效率低下。

所以,思考一下,既然锁住整张表的话,并发效率低下,那我把整张表分成 N 个部分,并使元素尽量均匀的分布到每个部分中,分别给他们加锁,互相之间并不影响,这种方式岂不是更好 。这就是在 JDK1.7 中 ConcurrentHashMap 采用的方案,被叫做锁分段技术,每个部分就是一个 Segment(段)。
但是,在JDK1.8中,完全重构了,采用的是 Synchronized + CAS ,把锁的粒度进一步降低,而放弃了 Segment 分段。(此时的 Synchronized 已经升级了,效率得到了很大提升,锁升级可以了解一下)
ConcurrentHashMap 1.7 源码解析
我们看下在 JDK1.7中 ConcurrentHashMap 是怎么实现的。墙裂建议,在本文之前了解一下多线程的基本知识,如JMM内存模型,volatile关键字作用,CAS和自旋,ReentranLock重入锁。
底层存储结构
在 JDK1.7中,本质上还是采用链表+数组的形式存储键值对的。但是,为了提高并发,把原来的整个 table 划分为 n 个 Segment 。所以,从整体来看,它是一个由 Segment 组成的数组。然后,每个 Segment 里边是由 HashEntry 组成的数组,每个 HashEntry之间又可以形成链表。我们可以把每个 Segment 看成是一个小的 HashMap,其内部结构和 HashMap 是一模一样的。

当对某个 Segment 加锁时,如图中 Segment2,并不会影响到其他 Segment 的读写。每个 Segment 内部自己操作自己的数据。这样一来,我们要做的就是尽可能的让元素均匀的分布在不同的 Segment中。最理想的状态是,所有执行的线程操作的元素都是不同的 Segment,这样就可以降低锁的竞争。
废话了这么多,还是来看底层源码吧,因为所有的思想都在代码里体现。借用 Linus的一句话,“No BB . Show me the code ” (改编版,哈哈)
常用变量
先看下 1.7 中常用的变量和内部类都有哪些,这有助于我们了解 ConcurrentHashMap 的整体结构。
//默认初始化容量,这个和 HashMap中的容量是一个概念,表示的是整个 Map的容量static final int DEFAULT_INITIAL_CAPACITY = 16;//默认加载因子static final float DEFAULT_LOAD_FACTOR = 0.75f;//默认的并发级别,这个参数决定了 Segment 数组的长度static final int DEFAULT_CONCURRENCY_LEVEL = 16;//最大的容量static final int MAXIMUM_CAPACITY = 1 << 30;//每个Segment中table数组的最小长度为2,且必须是2的n次幂。//由于每个Segment是懒加载的,用的时候才会初始化,因此为了避免使用时立即调整大小,设定了最小容量2static final int MIN_SEGMENT_TABLE_CAPACITY = 2;//用于限制Segment数量的最大值,必须是2的n次幂static final int MAX_SEGMENTS = 1 << 16; // slightly conservative//在size方法和containsValue方法,会优先采用乐观的方式不加锁,直到重试次数达到2,才会对所有Segment加锁//这个值的设定,是为了避免无限次的重试。后边size方法会详讲怎么实现乐观机制的。static final int RETRIES_BEFORE_LOCK = 2;//segment掩码值,用于根据元素的hash值定位所在的 Segment 下标。后边会细讲final int segmentMask;//和 segmentMask 配合使用来定位 Segment 的数组下标,后边讲。final int segmentShift;// Segment 组成的数组,每一个 Segment 都可以看做是一个特殊的 HashMapfinal Segment<K,V>[] segments;//Segment 对象,继承自 ReentrantLock 可重入锁。//其内部的属性和方法和 HashMap 神似,只是多了一些拓展功能。static final class Segment<K,V> extends ReentrantLock implements Serializable {//这是在 scanAndLockForPut 方法中用到的一个参数,用于计算最大重试次数//获取当前可用的处理器的数量,若大于1,则返回64,否则返回1。static final int MAX_SCAN_RETRIES =Runtime.getRuntime().availableProcessors() > 1 ? 64 : 1;//用于表示每个Segment中的 table,是一个用HashEntry组成的数组。transient volatile HashEntry<K,V>[] table;//Segment中的元素个数,每个Segment单独计数(下边的几个参数同样的都是单独计数)transient int count;//每次 table 结构修改时,如put,remove等,此变量都会自增transient int modCount;//当前Segment扩容的阈值,同HashMap计算方法一样也是容量乘以加载因子//需要知道的是,每个Segment都是单独处理扩容的,互相之间不会产生影响transient int threshold;//加载因子final float loadFactor;//Segment构造函数Segment(float lf, int threshold, HashEntry<K,V>[] tab) {this.loadFactor = lf;this.threshold = threshold;this.table = tab;}...// put(),remove(),rehash() 方法都在此类定义}// HashEntry,存在于每个Segment中,它就类似于HashMap中的Node,用于存储键值对的具体数据和维护单向链表的关系static final class HashEntry<K,V> {//每个key通过哈希运算后的结果,用的是 Wang/Jenkins hash 的变种算法,此处不细讲,感兴趣的可自行查阅相关资料final int hash;final K key;//value和next都用 volatile 修饰,用于保证内存可见性和禁止指令重排序volatile V value;//指向下一个节点volatile HashEntry<K,V> next;HashEntry(int hash, K key, V value, HashEntry<K,V> next) {this.hash = hash;this.key = key;this.value = value;this.next = next;}}
构造函数
ConcurrentHashMap 有五种构造函数,但是最终都会调用同一个构造函数,所以只需要搞明白这一个核心的构造函数就可以了。
PS: 文章注释中 (1)(2)(3) 等序号都是用来方便做标记,不是计算值
public ConcurrentHashMap(int initialCapacity,float loadFactor, int concurrencyLevel) {//检验参数是否合法。值得说的是,并发级别一定要大于0,否则就没办法实现分段锁了。if (!(loadFactor > 0) || initialCapacity < 0 || concurrencyLevel <= 0)throw new IllegalArgumentException();//并发级别不能超过最大值if (concurrencyLevel > MAX_SEGMENTS)concurrencyLevel = MAX_SEGMENTS;// Find power-of-two sizes best matching arguments//偏移量,是为了对hash值做位移操作,计算元素所在的Segment下标,put方法详讲int sshift = 0;//用于设定最终Segment数组的长度,必须是2的n次幂int ssize = 1;//这里就是计算 sshift 和 ssize 值的过程 (1)while (ssize < concurrencyLevel) {++sshift;ssize <<= 1;}this.segmentShift = 32 - sshift;//Segment的掩码this.segmentMask = ssize - 1;if (initialCapacity > MAXIMUM_CAPACITY)initialCapacity = MAXIMUM_CAPACITY;//c用于辅助计算cap的值 (2) 可能不被整除//比如initialCapacity=63 ssize=16int c = initialCapacity / ssize;if (c * ssize < initialCapacity)++c;// cap 用于确定某个Segment的容量,即Segment中HashEntry数组的长度int cap = MIN_SEGMENT_TABLE_CAPACITY;//(3)while (cap < c)cap <<= 1;// create segments and segments[0]//这里用 loadFactor做为加载因子,cap乘以加载因子作为扩容阈值,创建长度为cap的HashEntry数组,//三个参数,创建一个Segment对象,保存到S0对象中。后边在 ensureSegment 方法会用到S0作为原型对象去创建对应的Segment。Segment<K,V> s0 =new Segment<K,V>(loadFactor, (int)(cap * loadFactor),(HashEntry<K,V>[])new HashEntry[cap]);//创建出长度为 ssize 的一个 Segment数组Segment<K,V>[] ss = (Segment<K,V>[])new Segment[ssize];//把S0存到Segment数组中去。在这里,我们就可以发现,此时只是创建了一个Segment数组,//但是并没有把数组中的每个Segment对象创建出来,仅仅创建了一个Segment用来作为原型对象。//s0放在ss[0]位置UNSAFE.putOrderedObject(ss, SBASE, s0); // ordered write of segments[0]this.segments = ss;}
上边的注释中留了 (1)(2)(3) 三个地方还没有细说。我们现在假设一组数据,把涉及到的几个变量计算出来,就能明白这些参数的含义了。
//假设调用了默认构造,都用的是默认参数,即 initialCapacity 和 concurrencyLevel 都是16//(1) sshift 和 ssize 值的计算过程为,每次循环,都会把 sshift 自增1,并且 ssize 左移一位,即乘以2,//直到 ssize 的值大于等于 concurrencyLevel 的值 16。sshfit=0,1,2,3,4ssize=1,2,4,8,16//可以看到,初始他们的值分别是0和1,最终结果是4和16//sshfit是为了辅助计算segmentShift值,ssize是为了确定Segment数组长度。//(2) 此时,计算c的值,c = 16/16 = 1;//判断 c * 16 < 16 是否为真,真的话 c 自增1,此处为false,因此 c的值为1不变。//(3) 此时,由于c为1, cap为2 ,因此判断 cap < c 为false,最终cap为2。//总结一下,以上三个步骤,最终都是为了确定以下几个关键参数的值,//确定 segmentShift ,这个用于后边计算hash值的偏移量,此处即为 32-4=28,//确定 ssize,必须是一个大于等于 concurrencyLevel 的一个2的n次幂值//确定 cap,必须是一个大于等于2的一个2的n次幂值//感兴趣的小伙伴,还可以用另外几组参数来计算上边的参数值,可以加深理解参数的含义。//例如initialCapacity和concurrencyLevel分别传入10和5,或者传入33和16
put()方法
put 方法的总体流程是,
- 通过哈希算法计算出当前 key 的 hash 值
- 通过这个 hash 值找到它所对应的 Segment 数组的下标
- 再通过 hash 值计算出它在对应 Segment 的 HashEntry数组 的下标
- 找到合适的位置插入元素
//这是Map的put方法public V put(K key, V value) {Segment<K,V> s;//不支持value为空if (value == null)throw new NullPointerException();//通过 Wang/Jenkins 算法的一个变种算法,计算出当前key对应的hash值int hash = hash(key);//上边我们计算出的 segmentShift为28,因此hash值右移28位,说明此时用的是hash的高4位,//然后把它和掩码15进行与运算,得到的值一定是一个 0000 ~ 1111 范围内的值,即 0~15 。int j = (hash >>> segmentShift) & segmentMask;//这里是用Unsafe类的原子操作找到Segment数组中j下标的 Segment 对象if ((s = (Segment<K,V>)UNSAFE.getObject // nonvolatile; recheck(segments, (j << SSHIFT) + SBASE)) == null) // in ensureSegment//初始化j下标的Segments = ensureSegment(j);//在此Segment中添加元素return s.put(key, hash, value, false);}
上边有一个这样的方法, UNSAFE.getObject (segments, (j << SSHIFT) + SBASE。它是为了通过Unsafe这个类,找到 j 最新的实际值。这个计算 (j << SSHIFT) + SBASE ,在后边非常常见,我们只需要知道它代表的是 j 的一个偏移量,通过偏移量,就可以得到 j 的实际值。可以类比,AQS 中的 CAS 操作。 Unsafe中的操作,都需要一个偏移量,看下图,

(j << SSHIFT) + SBASE 就相当于图中的 stateOffset偏移量。只不过图中是 CAS 设置新值,而我们这里是取 j 的最新值。 后边很多这样的计算方式,就不赘述了。接着看 s.put 方法,这才是最终确定元素位置的方法。
//Segment中的 put 方法final V put(K key, int hash, V value, boolean onlyIfAbsent) {//这里通过tryLock尝试加锁,如果加锁成功,返回null,否则执行 scanAndLockForPut方法//这里说明一下,tryLock 和 lock 是 ReentrantLock 中的方法,//区别是 tryLock 不会阻塞,抢锁成功就返回true,失败就立马返回false,//而 lock 方法是,抢锁成功则返回,失败则会进入同步队列,阻塞等待获取锁。HashEntry<K,V> node = tryLock() ? null :scanAndLockForPut(key, hash, value);V oldValue;try {//当前Segment的table数组HashEntry<K,V>[] tab = table;//这里就是通过hash值,与tab数组长度取模,找到其所在HashEntry数组的下标int index = (tab.length - 1) & hash;//当前下标位置的第一个HashEntry节点HashEntry<K,V> first = entryAt(tab, index);for (HashEntry<K,V> e = first;;) {//如果第一个节点不为空if (e != null) {K k;//并且第一个节点,就是要插入的节点,则替换value值,否则继续向后查找if ((k = e.key) == key ||(e.hash == hash && key.equals(k))) {//替换旧值oldValue = e.value;if (!onlyIfAbsent) {e.value = value;++modCount;}break;}e = e.next;}//说明当前index位置不存在任何节点,此时first为null,//或者当前index存在一条链表,并且已经遍历完了还没找到相等的key,此时first就是链表第一个元素else {//如果node不为空,则直接头插if (node != null)node.setNext(first);//否则,创建一个新的node,并头插elsenode = new HashEntry<K,V>(hash, key, value, first);int c = count + 1;//如果当前Segment中的元素大于阈值,并且tab长度没有超过容量最大值,则扩容if (c > threshold && tab.length < MAXIMUM_CAPACITY)rehash(node);//否则,就把当前node设置为index下标位置新的头结点elsesetEntryAt(tab, index, node);++modCount;//更新count值count = c;//这种情况说明旧值肯定为空oldValue = null;break;}}} finally {//需要注意ReentrantLock必须手动解锁unlock();}//返回旧值return oldValue;}
这里说明一下计算 Segment 数组下标和计算 HashEntry 数组下标的不同点:
//下边的hash值是通过哈希运算后的hash值,不是hashCode//计算 Segment 下标(hash >>> segmentShift) & segmentMask//计算 HashEntry 数组下标(tab.length - 1) & hash
思考一下,为什么它们的算法不一样呢? 计算 Segment 数组下标是用的 hash值高几位(这里以高 4 位为例)和掩码做与运算,而计算 HashEntry 数组下标是直接用的 hash 值和数组长度减1做与运算。
我的理解是,这是为了尽量避免当前 hash 值计算出来的 Segment 数组下标和计算出来的 HashEntry 数组下标趋于相同。简单说,就是为了避免分配到同一个 Segment 中的元素扎堆现象,即避免它们都被分配到同一条链表上,导致链表过长。同时,也是为了减少并发。下面做一个运算,帮助理解一下(假设不用高 4 位运算,而是正常情况都用低位做运算)。
//我们以并发级别16,HashEntry数组容量 4 为例,则它们参与运算的掩码分别为 15 和 3//hash值0110 1101 0110 1111 0110 1110 0010 0010//segmentMask = 15 ,标记为 (1)0000 0000 0000 0000 0000 0000 0000 1111//tab.length - 1 = 3 ,标记为 (2)0000 0000 0000 0000 0000 0000 0000 0011//用 hash 分别和 15 ,3 做与运算,会发现得到的结果是一样,都是十进制 2.//这表明,当前 hash值被分配到下标为 2 的 Segment 中,同时,被分配到下标为 2 的 HashEntry 数组中//现在若有另外一个 hash 值 h2,和第一个hash值,高位不同,但是低4位相同,1010 1101 0110 1111 0110 1110 0010 0010//我们会发现,最后它也会被分配到下标为 2 的 Segment 和 HashEntry 数组,就会和第一个元素形成链表。//所以,为了避免这种扎堆现象,让元素尽量均匀分配,就让 hash 的高 4 位和 (1)处做与 运算,而用低位和 (2)处做与运算//这样计算后,它们所在的Segment下标分别为 6(0110), 10(1010),即使它们在HashEntry数组中的下标都为 2(0010),也无所谓//因为它们并不在一个 Segment 中,也就不会在同一个 HashEntry 数组中,更不会形成链表。//更重要的是,它们不会有并发,因为在各自不同的 Segment 自己操作自己的加锁解锁,互不影响
可能有的小伙伴就会打岔了,那如果两个 hash 值,低位和高位都相同,怎么办呢。如果是这样,我只能说,这个 hash 算法也太烂了吧。(这里的 hash 算法也会尽量避免这种情况,当然只是减少几率,并不能杜绝)
我有个大胆的想法,这里的高低位不同的计算方式,是不是后边 1.8 HashMap 让 hash 高低位做异或运算的引子呢?不得而知。。
put 方法比较简单,只要能看懂 HashMap 中的 put 方法,这里也没问题。主要是它调用的子方法比较复杂,下边一个一个讲解。
ensureSegment()方法
回到 Map的 put 方法,判断 j 下标的 Segment为空后,则需要调用此方法,初始化一个 Segment 对象,以确保拿到的对象一定是不为空的,否则无法执行s.put了。
//k为 (hash >>> segmentShift) & segmentMask 算法计算出来的值private Segment<K,V> ensureSegment(int k) {final Segment<K,V>[] ss = this.segments;//u代表 k 的偏移量,用于通过 UNSAFE 获取主内存最新的实际 K 值long u = (k << SSHIFT) + SBASE; // raw offsetSegment<K,V> seg;//从内存中取到最新的下标位置的 Segment 对象,判断是否为空,(1)if ((seg = (Segment<K,V>)UNSAFE.getObjectVolatile(ss, u)) == null) {//之前构造函数说了,s0是作为一个原型对象,用于创建新的 Segment 对象Segment<K,V> proto = ss[0]; // use segment 0 as prototype//容量int cap = proto.table.length;//加载因子float lf = proto.loadFactor;//扩容阈值int threshold = (int)(cap * lf);//把 Segment 对应的 HashEntry 数组先创建出来HashEntry<K,V>[] tab = (HashEntry<K,V>[])new HashEntry[cap];//再次检查 K 下标位置的 Segment 是否为空, (2)if ((seg = (Segment<K,V>)UNSAFE.getObjectVolatile(ss, u))== null) { // recheck//此处把 Segment 对象创建出来,并赋值给 s,Segment<K,V> s = new Segment<K,V>(lf, threshold, tab);//循环检查 K 下标位置的 Segment 是否为空, (3)//若不为空,则说明有其它线程抢先创建成功,并且已经成功同步到主内存中了,//则把它取出来,并返回while ((seg = (Segment<K,V>)UNSAFE.getObjectVolatile(ss, u))== null) {//CAS,若当前下标的Segment对象为空,就把它替换为最新创建出来的 s 对象。//若成功,就跳出循环,否则,就一直自旋直到成功,或者 seg 不为空(其他线程成功导致)。if (UNSAFE.compareAndSwapObject(ss, u, null, seg = s))break;}}}return seg;}
可以发现,我标注了上边 (1)(2)(3) 个地方,每次都判断最新的Segment是否为空。可能有的小伙伴就会迷惑,为什么做这么多次判断,我直接去自旋不就好了,反正最后都要自旋的。
我的理解是,在多线程环境下,因为不确定是什么时候会有其它线程 CAS 成功,有可能发生在以上的任意时刻。所以,只要发现一旦内存中的对象已经存在了,则说明已经有其它线程把Segment对象创建好,并CAS成功同步到主内存了。此时,就可以直接返回,而不需要往下执行了。这样做,是为了代码执行效率考虑。
scanAndLockForPut()方法
put 方法第一步抢锁失败之后,就会执行此方法,
private HashEntry<K,V> scanAndLockForPut(K key, int hash, V value) {//根据hash值定位到它对应的HashEntry数组的下标位置,并找到链表的第一个节点//注意,这个操作会从主内存中获取到最新的状态,以确保获取到的first是最新值HashEntry<K,V> first = entryForHash(this, hash);HashEntry<K,V> e = first;HashEntry<K,V> node = null;//重试次数,初始化为 -1int retries = -1; // negative while locating node//如果tryLock成功,拿到锁直接不走下面逻辑了。tryLock失败,会一直循环while (!tryLock()) {HashEntry<K,V> f; // to recheck first below//1.若 retries 小于0,if (retries < 0) {if (e == null) {//若 e 节点和 node 都为空,则创建一个 node 节点。这里只是预测性的创建一个node节点if (node == null) // speculatively create nodenode = new HashEntry<K,V>(hash, key, value, null);retries = 0;}//如当前遍历到的 e 节点不为空,则判断它的key是否等于传进来的key,若是则把 retries 设为0else if (key.equals(e.key))retries = 0;//否则,继续向后遍历节点elsee = e.next;}//2.若是重试次数超过了最大尝试次数,则调用lock方法加锁。表明不再重试,我下定决心了一定要获取到锁。//要么当前线程可以获取到锁,要么获取不到就去排队等待获取锁。获取成功后,再 break。else if (++retries > MAX_SCAN_RETRIES) {lock();break;}//3.若 retries 的值为偶数,并且从内存中再次获取到最新的头节点,判断若不等于first//则说明有其他线程修改了当前下标位置的头结点,于是需要更新头结点信息。else if ((retries & 1) == 0 &&(f = entryForHash(this, hash)) != first) {//更新头结点信息,并把重试次数重置为 -1,继续下一次循环,从最新的头结点遍历当前链表。e = first = f; // re-traverse if entry changedretries = -1;}}return node;}
这个方法逻辑比较复杂,会一直循环尝试获取锁,若获取成功,则返回。否则的话,每次循环时,都会同时遍历当前链表。若遍历完了一次,还没找到和key相等的节点,就会预先创建一个节点。注意,这里只是预测性的创建一个新节点,也有可能在这之前,就已经获取锁成功了。
同时,当重试次每偶数次时,就会检查一次当前最新的头结点是否被改变。因为若有变化的话,还需要从最新的头结点开始遍历链表。
还有一种情况,就是循环次数达到了最大限制,则停止循环,用阻塞的方式去获取锁。这时,也就停止了遍历链表的动作,当前线程也不会再做其他预热(warm up)的事情。
关于为什么预测性的创建新节点,源码中原话是这样的:
Since traversal speed doesn’t matter, we might as well help warm up the associated code and accesses as well.
解释一下就是,因为遍历速度无所谓,所以,我们可以预先(warm up)做一些相关联代码的准备工作。这里相关联代码,指的就是循环中,在获取锁成功或者调用 lock 方法之前做的这些事情,当然也包括创建新节点。
在put 方法中可以看到,有一句是判断 node 是否为空,若创建了,就直接头插。否则的话,它也会自己创建这个新节点。头插法

scanAndLockForPut 这个方法可以确保返回时,当前线程一定是获取到锁的状态。
rehash()方法
当 put 方法时,发现元素个数超过了阈值,则会扩容。需要注意的是,每个Segment只管它自己的扩容,互相之间并不影响。换句话说,可以出现这个 Segment的长度为2,另一个Segment的长度为4的情况(只要是2的n次幂)。
//node为创建的新节点private void rehash(HashEntry<K,V> node) {//当前Segment中的旧表HashEntry<K,V>[] oldTable = table;//旧的容量int oldCapacity = oldTable.length;//新容量为旧容量的2倍int newCapacity = oldCapacity << 1;//更新新的阈值threshold = (int)(newCapacity * loadFactor);//用新的容量创建一个新的 HashEntry 数组HashEntry<K,V>[] newTable =(HashEntry<K,V>[]) new HashEntry[newCapacity];//当前的掩码,用于计算节点在新数组中的下标int sizeMask = newCapacity - 1;//遍历旧表for (int i = 0; i < oldCapacity ; i++) {HashEntry<K,V> e = oldTable[i];//如果e不为空,说明当前链表不为空if (e != null) {HashEntry<K,V> next = e.next;//计算hash值再新数组中的下标位置int idx = e.hash & sizeMask;//如果e不为空,且它的下一个节点为空,则说明这条链表只有一个节点,//直接把这个节点放到新数组的对应下标位置即可if (next == null) // Single node on listnewTable[idx] = e;//否则,处理当前链表的节点迁移操作else { // Reuse consecutive sequence at same slot//记录上一次遍历到的节点HashEntry<K,V> lastRun = e;//对应上一次遍历到的节点在新数组中的新下标int lastIdx = idx;for (HashEntry<K,V> last = next;last != null;last = last.next) {//计算当前遍历到的节点的新下标int k = last.hash & sizeMask;//若 k 不等于 lastIdx,则说明此次遍历到的节点和上次遍历到的节点不在同一个下标位置//需要把 lastRun 和 lastIdx 更新为当前遍历到的节点和下标值。//若相同,则不处理,继续下一次 for 循环。if (k != lastIdx) {lastIdx = k;lastRun = last;}}//把和 lastRun 节点的下标位置相同的链表最末尾的几个连续的节点放到新数组的对应下标位置newTable[lastIdx] = lastRun;//再把剩余的节点,复制到新数组//从旧数组的头结点开始遍历,直到 lastRun 节点,因为 lastRun节点后边的节点都已经迁移完成了。for (HashEntry<K,V> p = e; p != lastRun; p = p.next) {V v = p.value;int h = p.hash;int k = h & sizeMask;HashEntry<K,V> n = newTable[k];//用的是复制节点信息的方式,并不是把原来的节点直接迁移,区别于lastRun处理方式newTable[k] = new HashEntry<K,V>(h, p.key, v, n);}}}}//所有节点都迁移完成之后,再处理传进来的新的node节点,把它头插到对应的下标位置int nodeIndex = node.hash & sizeMask; // add the new node//头插node节点node.setNext(newTable[nodeIndex]);newTable[nodeIndex] = node;//更新当前Segment的table信息table = newTable;}
上边的迁移过程和 lastRun 和 lastIdx 变量可能不太好理解,我画个图就明白了。以其中一条链表处理方式为例。

从头结点开始向后遍历,找到当前链表的最后几个下标相同的连续的节点。如上图,虽然开头出现了有两个节点的下标都是 k2, 但是中间出现一个不同的下标 k1,打断了下标连续相同,因此从下一个k2,又重新开始算。好在后边三个连续的节点下标都是相同的,因此倒数第三个节点被标记为 lastRun,且变量无变化。
从lastRun节点到尾结点的这部分就可以整体迁移到新数组的对应下标位置了,因为它们的下标都是相同的,可以这样统一处理。
另外从头结点到 lastRun 之前的节点,无法统一处理,只能一个一个去复制了。且注意,这里不是直接迁移,而是复制节点到新的数组,旧的节点会在不久的将来,因为没有引用指向,被 JVM 垃圾回收处理掉。
(不知道为啥这个方法名起为 rehash,其实扩容时 hash 值并没有重新计算,变化的只是它们所在的下标而已。我猜测,可能是,借用了 1.7 HashMap 中的说法吧。。。)
get()
put 方法搞明白了之后,其实 get 方法就很好理解了。也是先定位到 Segment,然后再定位到 HashEntry 。
public V get(Object key) {Segment<K,V> s; // manually integrate access methods to reduce overheadHashEntry<K,V>[] tab;//计算hash值int h = hash(key);//同样的先定位到 key 所在的Segment ,然后从主内存中取出最新的节点long u = (((h >>> segmentShift) & segmentMask) << SSHIFT) + SBASE;if ((s = (Segment<K,V>)UNSAFE.getObjectVolatile(segments, u)) != null &&(tab = s.table) != null) {//若Segment不为空,且链表也不为空,则遍历查找节点for (HashEntry<K,V> e = (HashEntry<K,V>) UNSAFE.getObjectVolatile(tab, ((long)(((tab.length - 1) & h)) << TSHIFT) + TBASE);e != null; e = e.next) {K k;//找到则返回它的 value 值,否则返回 nullif ((k = e.key) == key || (e.hash == h && key.equals(k)))return e.value;}}return null;}
remove()
remove 方法和 put 方法类似,也不用做过多特殊的介绍,
public V remove(Object key) {int hash = hash(key);//定位到SegmentSegment<K,V> s = segmentForHash(hash);//若 s为空,则返回 null,否则执行 removereturn s == null ? null : s.remove(key, hash, null);}public boolean remove(Object key, Object value) {int hash = hash(key);Segment<K,V> s;return value != null && (s = segmentForHash(hash)) != null &&s.remove(key, hash, value) != null;}final V remove(Object key, int hash, Object value) {//尝试加锁,若失败,则执行 scanAndLock ,此方法和 scanAndLockForPut 方法类似if (!tryLock())scanAndLock(key, hash);V oldValue = null;try {HashEntry<K,V>[] tab = table;int index = (tab.length - 1) & hash;//从主内存中获取对应 table 的最新的头结点HashEntry<K,V> e = entryAt(tab, index);HashEntry<K,V> pred = null;while (e != null) {K k;HashEntry<K,V> next = e.next;//匹配到 keyif ((k = e.key) == key ||(e.hash == hash && key.equals(k))) {V v = e.value;// value 为空,或者 value 也匹配成功if (value == null || value == v || value.equals(v)) {if (pred == null)setEntryAt(tab, index, next);elsepred.setNext(next);++modCount;--count;oldValue = v;}break;}pred = e;e = next;}} finally {unlock();}return oldValue;}
size()
size 方法需要重点说明一下。爱思考的小伙伴可能就会想到,并发情况下,有可能在统计期间,数组元素个数不停的变化,而且,整个表还被分成了 N个 Segment,怎样统计才能保证结果的准确性呢? 我们一起来看下吧。
public int size() {// Try a few times to get accurate count. On failure due to// continuous async changes in table, resort to locking.//segment数组final Segment<K,V>[] segments = this.segments;//统计所有Segment中元素的总个数int size;//如果size大小超过32位,则标记为溢出为trueboolean overflow;//统计每个Segment中的 modcount 之和long sum;//上次记录的 sum 值long last = 0L;//重试次数,初始化为 -1int retries = -1;try {for (;;) {//如果超过重试次数,则不再重试,而是把所有Segment都加锁,再统计 sizeif (retries++ == RETRIES_BEFORE_LOCK) {for (int j = 0; j < segments.length; ++j)//强制加锁ensureSegment(j).lock(); // force creation}sum = 0L;size = 0;overflow = false;//遍历所有Segmentfor (int j = 0; j < segments.length; ++j) {Segment<K,V> seg = segmentAt(segments, j);//若当前遍历到的Segment不为空,则统计它的 modCount 和 count 元素个数if (seg != null) {//累加当前Segment的结构修改次数,如put,remove等操作都会影响modCountsum += seg.modCount;int c = seg.count;//若当前Segment的元素个数 c 小于0 或者 size 加上 c 的结果小于0,则认为溢出//因为若超过了 int 最大值,就会返回负数if (c < 0 || (size += c) < 0)overflow = true;}}//当此次尝试,统计的 sum 值和上次统计的值相同,则说明这段时间内,//并没有任何一个 Segment 的结构发生改变,就可以返回最后的统计结果if (sum == last)break;//不相等,则说明有 Segment 结构发生了改变,则记录最新的结构变化次数之和 sum,//并赋值给 last,用于下次重试的比较。last = sum;}} finally {//如果超过了指定重试次数,则说明表中的所有Segment都被加锁了,因此需要把它们都解锁if (retries > RETRIES_BEFORE_LOCK) {for (int j = 0; j < segments.length; ++j)segmentAt(segments, j).unlock();}}//若结果溢出,则返回 int 最大值,否则正常返回 size 值return overflow ? Integer.MAX_VALUE : size;}
其实源码中前两行的注释也说的非常清楚了。我们先采用乐观的方式,认为在统计 size 的过程中,并没有发生 put, remove 等会改变 Segment 结构的操作。 但是,如果发生了,就需要重试。如果重试2次都不成功(执行三次,第一次不能叫做重试),就只能强制把所有 Segment 都加锁之后,再统计了,以此来得到准确的结果。
ConcurrentHashMap 1.8 源码分析
原博客【https://www.jianshu.com/p/433c7154f65a】
需要说明的是,JDK 1.8 的 CHM(ConcurrentHashMap) 实现,完全重构了 1.7 。不再有 Segment 的概念,只是为了兼容 1.7 才申明了一下,并没有用到。因此,不再使用分段锁,而是给数组中的每一个头节点(为了方便,以后都叫桶)都加锁,锁的粒度降低了。并且,用的是 Synchronized 锁。
可能有的小伙伴就有疑惑了,不是都说同步锁是重量级锁吗,这样不是会影响并发效率吗?
确实之前同步锁是一个重量级锁,但是在 JDK1.6 之后进行了各种优化之后,它已经不再那么重了。引入了偏向锁,轻量级锁,以及锁升级的概念,而且,据说在更细粒度的代码层面上,同步锁已经可以媲美 Lock 锁,甚至是赶超了。 除此之外,它还有很多优点,这里不再展开了。感兴趣的可以自行查阅同步锁的锁升级过程,以及它和 Lock 锁的区别。
在 1.8 CHM 中,底层存储结构和 1.8 的 HashMap 是一样的,都是数组+链表+红黑树。不同的就是,多了一些并发的处理。
文章开头我们提到了,在 1.8 HashMap 中的线程安全问题,就是因为在多个线程同时操作同一个桶的头结点时,会发生值的覆盖情况。那么,顺着这个思路,我们看一下在 CHM 中它是怎么避免这种情况发生的吧。
PS: 由于1.8的 CHM 和 HashMap 结构和基本属性变量,还有初始化逻辑都差不多,只是多了一些并发情况需要用到的参数和内部类,因此,不再单独拎出来介绍。在方法中用到的时候,再详细解释。
put()方法
因此,从 put 方法开始,我们看下,它在插入新元素的时候,是怎么保证线程安全的吧。
public V put(K key, V value) {return putVal(key, value, false);}final V putVal(K key, V value, boolean onlyIfAbsent) {//可以看到,在并发情况下,key 和 value 都是不支持为空的。if (key == null || value == null) throw new NullPointerException();//这里和1.8 HashMap 的hash 方法大同小异,只是多了一个操作,如下//( h ^ (h >>> 16)) & HASH_BITS; HASH_BITS = 0x7fffffff;// 0x7fffffff ,二进制为 0111 1111 1111 1111 1111 1111 1111 1111 。//所以,hash值除了做了高低位异或运算,还多了一步,保证最高位的 1 个 bit 位总是0。//这里,我并没有明白它的意图,仅仅是保证计算出来的hash值不超过 Integer 最大值,且不为负数吗。//同 HashMap 的hash 方法对比一下,会发现连源码注释都是相同的,并没有多说明其它的。//我个人认为意义不大,因为最后 hash 是为了和 capacity -1 做与运算,而 capacity 最大值为 1<<30,//即 0100 0000 0000 0000 0000 0000 0000 0000 ,减1为 0011 1111 1111 1111 1111 1111 1111 1111。//即使 hash 最高位为 1(无所谓0),也不影响最后的结果,最高位也总会是0.int hash = spread(key.hashCode());//用来计算当前链表上的元素个数int binCount = 0;for (Node<K,V>[] tab = table;;) {Node<K,V> f; int n, i, fh;//如果表为空,则说明还未初始化。if (tab == null || (n = tab.length) == 0)//初始化表,只有一个线程可以初始化成功。tab = initTable();//若表已经初始化,则找到当前 key 所在的桶,并且判断是否为空else if ((f = tabAt(tab, i = (n - 1) & hash)) == null) {//若当前桶为空,则通过 CAS 原子操作,把新节点插入到此位置,//这保证了只有一个线程可以 CAS 成功,其它线程都会失败。if (casTabAt(tab, i, null,new Node<K,V>(hash, key, value, null)))break; // no lock when adding to empty bin}//若所在桶不为空,则判断节点的 hash 值是否为 MOVED(值是-1)else if ((fh = f.hash) == MOVED)//若为-1,说明当前数组正在进行扩容,则需要当前线程帮忙迁移数据tab = helpTransfer(tab, f);else {V oldVal = null;//这里用加同步锁的方式,来保证线程安全,给桶中第一个节点对象加锁synchronized (f) {//recheck 一下,保证当前桶的第一个节点无变化,后边很多这样类似的操作,不再赘述if (tabAt(tab, i) == f) {//如果hash值大于等于0,说明是正常的链表结构if (fh >= 0) {binCount = 1;//从头结点开始遍历,每遍历一次,binCount计数加1for (Node<K,V> e = f;; ++binCount) {K ek;//如果找到了和当前 key 相同的节点,则用新值替换旧值if (e.hash == hash &&((ek = e.key) == key ||(ek != null && key.equals(ek)))) {oldVal = e.val;if (!onlyIfAbsent)e.val = value;break;}Node<K,V> pred = e;//若遍历到了尾结点,则把新节点尾插进去if ((e = e.next) == null) {pred.next = new Node<K,V>(hash, key,value, null);break;}}}//否则判断是否是树节点。这里提一下,TreeBin只是头结点对TreeNode的再封装else if (f instanceof TreeBin) {Node<K,V> p;binCount = 2;if ((p = ((TreeBin<K,V>)f).putTreeVal(hash, key,value)) != null) {oldVal = p.val;if (!onlyIfAbsent)p.val = value;}}}}//注意下,这个判断是在同步锁外部,因为 treeifyBin内部也有同步锁,并不影响if (binCount != 0) {//如果节点个数大于等于 8,则转化为红黑树if (binCount >= TREEIFY_THRESHOLD)treeifyBin(tab, i);//把旧节点值返回if (oldVal != null)return oldVal;break;}}}//给元素个数加 1,并有可能会触发扩容,比较复杂,稍后细讲addCount(1L, binCount);return null;}
initTable()方法
先看下当数组为空时,是怎么初始化表的。
private final Node<K,V>[] initTable() {Node<K,V>[] tab; int sc;//循环判断表是否为空,直到初始化成功为止。while ((tab = table) == null || tab.length == 0) {//sizeCtl 这个值有很多情况,默认值为0,//当为 -1 时,说明有其它线程正在对表进行初始化操作//当表初始化成功后,又会把它设置为扩容阈值//当为一个小于 -1 的负数,用来表示当前有几个线程正在帮助扩容(后边细讲)if ((sc = sizeCtl) < 0)//若 sc 小于0,其实在这里就是-1,因为此时表是空的,不会发生扩容,sc只能为正数或者-1//因此,当前线程放弃 CPU 时间片,只是自旋。Thread.yield(); // lost initialization race; just spin//通过 CAS 把 sc 的值设置为-1,表明当前线程正在进行表的初始化,其它失败的线程就会自旋else if (U.compareAndSwapInt(this, SIZECTL, sc, -1)) {try {//重新检查一下表是否为空if ((tab = table) == null || tab.length == 0) {//如果sc大于0,则为sc,否则返回默认容量 16。//当调用有参构造创建 Map 时,sc的值是大于0的。int n = (sc > 0) ? sc : DEFAULT_CAPACITY;@SuppressWarnings("unchecked")//创建数组Node<K,V>[] nt = (Node<K,V>[])new Node<?,?>[n];table = tab = nt;//n减去 1/4 n ,即为 0.75n ,表示扩容阈值sc = n - (n >>> 2);}} finally {//更新 sizeCtl 为扩容阈值sizeCtl = sc;}//若当前线程初始化表成功,则跳出循环。其它自旋的线程因为判断数组不为空,也会停止自旋break;}}return tab;}
addCount()方法
若 put 方法元素插入成功之后,则会调用此方法,传入参数为 addCount(1L, binCount)。这个方法的目的很简单,就是把整个 table 的元素个数加 1 。但是,实现比较难。
我们先思考一下,如果让我们自己去实现这样的统计元素个数,怎么实现?
类比 1.8 的 HashMap ,我们可以搞一个 size 变量来存储个数统计。但是,这是在多线程环境下,需要考虑并发的问题。因此,可以把 size 设置为 volatile 的,保证可见性,然后通过 CAS 乐观锁来自增 1。
这样虽然也可以实现。但是,设想一下现在有非常多的线程,都在同一时间操作这个 size 变量,将会造成特别严重的竞争。所以,基于此,这里做了更好的优化。让这些竞争的线程,分散到不同的对象里边,单独操作它自己的数据(计数变量),用这样的方式尽量降低竞争。到最后需要统计 size 的时候,再把所有对象里边的计数相加就可以了。
上边提到的 size ,在此用 baseCount 表示。分散到的对象用 CounterCell 表示,对象里边的计数变量用 value 表示。注意这里的变量都是 volatile 修饰的。
当需要修改元素数量时,线程会先去 CAS 修改 baseCount 加1,若成功即返回。若失败,则线程被分配到某个 CounterCell ,然后操作 value 加1。若成功,则返回。否则,给当前线程重新分配一个 CounterCell,再尝试给 value 加1。(这里简略的说,实际更复杂)
CounterCell 会组成一个数组,也会涉及到扩容问题。所以,先画一个示意图帮助理解一下。

image
//线程被分配到的格子@sun.misc.Contended static final class CounterCell {//此格子内记录的 value 值volatile long value;CounterCell(long x) { value = x; }}//用来存储线程和线程生成的随机数的对应关系static final int getProbe() {return UNSAFE.getInt(Thread.currentThread(), PROBE);}// x为1,check代表链表上的元素个数private final void addCount(long x, int check) {CounterCell[] as; long b, s;//此处要进入if有两种情况//1.数组不为空,说明数组已经被创建好了。//2.若数组为空,说明数组还未创建,很有可能竞争的线程非常少,因此就直接 CAS 操作 baseCount//若 CAS 成功,则方法跳转到 (2)处,若失败,则需要考虑给当前线程分配一个格子(指CounterCell对象)if ((as = counterCells) != null ||!U.compareAndSwapLong(this, BASECOUNT, b = baseCount, s = b + x)) {CounterCell a; long v; int m;//字面意思,是无竞争,这里先标记为 true,表示还没有产生线程竞争boolean uncontended = true;//这里有三种情况,会进入 fullAddCount 方法//1.若数组为空,进方法 (1)//2.ThreadLocalRandom.getProbe() 方法会给当前线程生成一个随机数(可以简单的认为也是一个hash值)//然后用随机数与数组长度取模,计算它所在的格子。若当前线程所分配到的格子为空,进方法 (1)。//3.若数组不为空,且线程所在格子不为空,则尝试 CAS 修改此格子对应的 value 值加1。//若修改成功,则跳转到 (3),若失败,则把 uncontended 值设为 fasle,说明产生了竞争,然后进方法 (1)if (as == null || (m = as.length - 1) < 0 ||(a = as[ThreadLocalRandom.getProbe() & m]) == null ||!(uncontended =U.compareAndSwapLong(a, CELLVALUE, v = a.value, v + x))) {//方法(1), 这个方法的目的是让当前线程一定把 1 加成功。情况更多,更复杂,稍后讲。fullAddCount(x, uncontended);return;}//(3)能走到这,说明数组不为空,且修改 baseCount失败,//且线程被分配到的格子不为空,且修改 value 成功。//但是这里没明白为什么小于等于1,就直接返回了,这里我怀疑之前的方法漏掉了binCount=0的情况。//而且此处若返回了,后边怎么判断扩容?(存疑)if (check <= 1)return;//计算总共的元素个数s = sumCount();}//(2)这里用于检查是否需要扩容(下边这部分很多逻辑不懂的话,等后边讲完扩容,再回来看就理解了)if (check >= 0) {Node<K,V>[] tab, nt; int n, sc;//若元素个数达到扩容阈值,且tab不为空,且tab数组长度小于最大容量while (s >= (long)(sc = sizeCtl) && (tab = table) != null &&(n = tab.length) < MAXIMUM_CAPACITY) {//这里假设数组长度n就为16,这个方法返回的是一个固定值,用于当做一个扩容的校验标识//可以跳转到最后,看详细计算过程,0000 0000 0000 0000 1000 0000 0001 1011int rs = resizeStamp(n);//若sc小于0,说明正在扩容if (sc < 0) {//sc的结构类似这样,1000 0000 0001 1011 0000 0000 0000 0001//sc的高16位是数据校验标识,低16位代表当前有几个线程正在帮助扩容,RESIZE_STAMP_SHIFT=16//因此判断校验标识是否相等,不相等则退出循环//sc == rs + 1,sc == rs + MAX_RESIZERS 这两个应该是用来判断扩容是否已经完成,但是计算方法存疑//感兴趣的可以看这个地址,应该是一个 bug ,// https://bugs.java.com/bugdatabase/view_bug.do?bug_id=JDK-8214427//nextTable=null 说明需要扩容的新数组还未创建完成//transferIndex这个参数小于等于0,说明已经不需要其它线程帮助扩容了,//但是并不说明已经扩容完成,因为有可能还有线程正在迁移元素。稍后扩容细讲就明白了。if ((sc >>> RESIZE_STAMP_SHIFT) != rs || sc == rs + 1 ||sc == rs + MAX_RESIZERS || (nt = nextTable) == null ||transferIndex <= 0)break;//到这里说明当前线程可以帮助扩容,因此sc值加一,代表扩容的线程数加1if (U.compareAndSwapInt(this, SIZECTL, sc, sc + 1))transfer(tab, nt);}//当sc大于0,说明sc代表扩容阈值,因此第一次扩容之前肯定走这个分支,用于初始化新表 nextTable//rs<<16//1000 0000 0001 1011 0000 0000 0000 0000//+2//1000 0000 0001 1011 0000 0000 0000 0010//这个值,转为十进制就是 -2145714174,用于标识,这是扩容时,初始化新表的状态,//扩容时,需要用到这个参数校验是否所有线程都全部帮助扩容完成。else if (U.compareAndSwapInt(this, SIZECTL, sc,(rs << RESIZE_STAMP_SHIFT) + 2))//扩容,第二个参数代表新表,传入null,则说明是第一次初始化新表(nextTable)transfer(tab, null);s = sumCount();}}}//计算表中的元素总个数final long sumCount() {CounterCell[] as = counterCells; CounterCell a;//baseCount,以这个值作为累加基准long sum = baseCount;if (as != null) {//遍历 counterCells 数组,得到每个对象中的value值for (int i = 0; i < as.length; ++i) {if ((a = as[i]) != null)//累加 value 值sum += a.value;}}//此时得到的就是元素总个数return sum;}//扩容时的校验标识static final int resizeStamp(int n) {return Integer.numberOfLeadingZeros(n) | (1 << (RESIZE_STAMP_BITS - 1));}//Integer.numberOfLeadingZeros方法的作用是返回 n 的最高位为1的前面的0的个数//n=16,0000 0000 0000 0000 0000 0000 0001 0000//前面有27个0,即270000 0000 0000 0000 0000 0000 0001 1011//RESIZE_STAMP_BITS为16,然后 1<<(16-1),即 1<<150000 0000 0000 0000 1000 0000 0000 0000//它们做或运算,得到 rs 的值0000 0000 0000 0000 1000 0000 0001 1011
fullAddCount()方法
上边的 addCount 方法还没完,别忘了有可能元素个数加 1 的操作还未成功,就走到 fullAddCount 这个方法了。看方法名,就知道了,全力增加计数值,一定要成功(奥利给)。 这个方法和扩容迁移方法是最难的,保持耐心~
//传过来的参数分别为 1 , falseprivate final void fullAddCount(long x, boolean wasUncontended) {int h;//如果当前线程的随机数为0,则强制初始化一个值if ((h = ThreadLocalRandom.getProbe()) == 0) {ThreadLocalRandom.localInit(); // force initializationh = ThreadLocalRandom.getProbe();//此时把 wasUncontended 设为true,认为无竞争wasUncontended = true;}//用来表示比 contend(竞争)更严重的碰撞,若为true,表示可能需要扩容,以减少碰撞冲突boolean collide = false; // True if last slot nonempty//循环内,外层if判断分三种情况,内层判断又分为六种情况for (;;) {CounterCell[] as; CounterCell a; int n; long v;//1. 若counterCells数组不为空。 建议先看下边的2和3两种情况,再回头看这个。if ((as = counterCells) != null && (n = as.length) > 0) {// (1) 若当前线程所在的格子(CounterCell对象)为空if ((a = as[(n - 1) & h]) == null) {if (cellsBusy == 0) {//若无锁,则乐观的创建一个 CounterCell 对象。CounterCell r = new CounterCell(x);//尝试加锁if (cellsBusy == 0 &&U.compareAndSwapInt(this, CELLSBUSY, 0, 1)) {boolean created = false;//加锁成功后,再 recheck 一下数组是否不为空,且当前格子为空try {CounterCell[] rs; int m, j;if ((rs = counterCells) != null &&(m = rs.length) > 0 &&rs[j = (m - 1) & h] == null) {//把新创建的对象赋值给当前格子rs[j] = r;created = true;}} finally {//手动释放锁cellsBusy = 0;}//若当前格子创建成功,且上边的赋值成功,则说明加1成功,退出循环if (created)break;//否则,继续下次循环continue; // Slot is now non-empty}}//若cellsBusy=1,说明有其它线程抢锁成功。或者若抢锁的 CAS 操作失败,都会走到这里,//则当前线程需跳转到(9)重新生成随机数,进行下次循环判断。collide = false;}/***后边这几种情况,都是数组和当前随机到的格子都不为空的情况。*且注意每种情况,若执行成功,且不break,continue,则都会执行(9),重新生成随机数,进入下次循环判断*/// (2) 到这,说明当前方法在被调用之前已经 CAS 失败过一次,若不明白可回头看下 addCount 方法,//为了减少竞争,则跳转到⑨处重新生成随机数,并把 wasUncontended 设置为true ,认为下一次不会产生竞争else if (!wasUncontended) // CAS already known to failwasUncontended = true; // Continue after rehash// (3) 若 wasUncontended 为 true 无竞争,则尝试一次 CAS。若成功,则结束循环,若失败则判断后边的 (4)(5)(6)。else if (U.compareAndSwapLong(a, CELLVALUE, v = a.value, v + x))break;// (4) 结合 (6) 一起看,(4)(5)(6)都是 wasUncontended=true,且CAS修改value失败的情况。//若数组有变化,或者数组长度大于等于当前CPU的核心数,则把 collide 改为 false//因为数组若有变化,说明是由扩容引起的;长度超限,则说明已经无法扩容,只能认为无碰撞。//这里很有意思,认真思考一下,当扩容超限后,则会达到一个平衡,即 (4)(5) 反复执行,直到 (3) 中CAS成功,跳出循环。else if (counterCells != as || n >= NCPU)collide = false; // At max size or stale// (5) 若数组无变化,且数组长度小于CPU核心数时,且 collide 为 false,就把它改为 true,说明下次循环可能需要扩容else if (!collide)collide = true;// (6) 若数组无变化,且数组长度小于CPU核心数时,且 collide 为 true,说明冲突比较严重,需要扩容了。else if (cellsBusy == 0 &&U.compareAndSwapInt(this, CELLSBUSY, 0, 1)) {try {//recheckif (counterCells == as) {// Expand table unless stale//创建一个容量为原来两倍的数组CounterCell[] rs = new CounterCell[n << 1];//转移旧数组的值for (int i = 0; i < n; ++i)rs[i] = as[i];//更新数组counterCells = rs;}} finally {cellsBusy = 0;}//认为扩容后,下次不会产生冲突了,和(4)处逻辑照应collide = false;//当次扩容后,就不需要重新生成随机数了continue; // Retry with expanded table}// (9),重新生成一个随机数,进行下一次循环判断h = ThreadLocalRandom.advanceProbe(h);}//2.这里的 cellsBusy 参数非常有意思,是一个volatile的 int值,用来表示自旋锁的标志,//可以类比 AQS 中的 state 参数,用来控制锁之间的竞争,并且是独占模式。简化版的AQS。//cellsBusy 若为0,说明无锁,线程都可以抢锁,若为1,表示已经有线程拿到了锁,则其它线程不能抢锁。else if (cellsBusy == 0 && counterCells == as &&U.compareAndSwapInt(this, CELLSBUSY, 0, 1)) {boolean init = false;try {//这里再重新检测下 counterCells 数组引用是否有变化if (counterCells == as) {//初始化一个长度为 2 的数组CounterCell[] rs = new CounterCell[2];//根据当前线程的随机数值,计算下标,只有两个结果 0 或 1,并初始化对象rs[h & 1] = new CounterCell(x);//更新数组引用counterCells = rs;//初始化成功的标志init = true;}} finally {//别忘了,需要手动解锁。cellsBusy = 0;}//若初始化成功,则说明当前加1的操作也已经完成了,则退出整个循环。if (init)break;}//3.到这,说明数组为空,且 2 抢锁失败,则尝试直接去修改 baseCount 的值,//若成功,也说明加1操作成功,则退出循环。else if (U.compareAndSwapLong(this, BASECOUNT, v = baseCount, v + x))break; // Fall back on using base}}
不得不佩服 Doug Lea 大神,思维这么缜密,如果是我的话,直接一个 CAS 完事。(手动摊手~)
transfer()方法
需要说明的一点是,虽然我们一直在说帮助扩容,其实更准确的说应该是帮助迁移元素。因为扩容的第一次初始化新表(扩容后的新表)这个动作,只能由一个线程完成。其他线程都是在帮助迁移元素到新数组。
这里还是先看下迁移的示意图,帮助理解。

扩容
为了方便,上边以原数组长度 8 为例。在元素迁移的时候,所有线程都遵循从后向前推进的规则,即如图A线程是第一个进来的线程,会从下标为7的位置,开始迁移数据。
而且当前线程迁移时会确定一个范围,限定它此次迁移的数据范围,如图 A 线程只能迁移 bound=6到 i=7 这两个数据。
此时,其它线程就不能迁移这部分数据了,只能继续向前推进,寻找其它可以迁移的数据范围,且每次推进的步长为固定值 stride(此处假设为2)。如图中 B线程发现 A 线程正在迁移6,7的数据,因此只能向前寻找,然后迁移 bound=4 到 i=5 的这两个数据。
当每个线程迁移完成它的范围内数据时,都会继续向前推进。那什么时候是个头呢?
这就需要维护一个全局的变量 transferIndex,来表示所有线程总共推进到的元素下标位置。如图,线程 A 第一次迁移成功后又向前推进,然后迁移2,3 的数据。此时,若没有其他线程在帮助迁移,则 transferIndex 即为2。
剩余部分等待下一个线程来迁移,或者有任何的 A 和B线程已经迁移完成,也可以推进到这里帮助迁移。直到 transferIndex=0 。(会做一些其他校验来判断是否迁移全部完成,看代码)。
//这个类是一个标志,用来代表当前桶(数组中的某个下标位置)的元素已经全部迁移完成static final class ForwardingNode<K,V> extends Node<K,V> {final Node<K,V>[] nextTable;ForwardingNode(Node<K,V>[] tab) {//把当前桶的头结点的 hash 值设置为 -1,表明已经迁移完成,//这个节点中并不存储有效的数据super(MOVED, null, null, null);this.nextTable = tab;}}//迁移数据private final void transfer(Node<K,V>[] tab, Node<K,V>[] nextTab) {int n = tab.length, stride;//根据当前CPU核心数,确定每次推进的步长,最小值为16.(为了方便我们以2为例)if ((stride = (NCPU > 1) ? (n >>> 3) / NCPU : n) < MIN_TRANSFER_STRIDE)stride = MIN_TRANSFER_STRIDE; // subdivide range//从 addCount 方法,只会有一个线程跳转到这里,初始化新数组if (nextTab == null) { // initiatingtry {@SuppressWarnings("unchecked")//新数组长度为原数组的两倍Node<K,V>[] nt = (Node<K,V>[])new Node<?,?>[n << 1];nextTab = nt;} catch (Throwable ex) { // try to cope with OOMEsizeCtl = Integer.MAX_VALUE;return;}//用 nextTable 指代新数组nextTable = nextTab;//这里就把推进的下标值初始化为原数组长度(以16为例)transferIndex = n;}//新数组长度int nextn = nextTab.length;//创建一个标志类ForwardingNode<K,V> fwd = new ForwardingNode<K,V>(nextTab);//是否向前推进的标志boolean advance = true;//是否所有线程都全部迁移完成的标志boolean finishing = false; // to ensure sweep before committing nextTab//i 代表当前线程正在迁移的桶的下标,bound代表它本次可以迁移的范围下限for (int i = 0, bound = 0;;) {Node<K,V> f; int fh;//需要向前推进while (advance) {int nextIndex, nextBound;// (1) 先看 (3) 。i每次自减 1,直到 bound。若超过bound范围,或者finishing标志为true,则不用向前推进。//若未全部完成迁移,且 i 并未走到 bound,则跳转到 (7),处理当前桶的元素迁移。if (--i >= bound || finishing)advance = false;// (2) 每次执行,都会把 transferIndex 最新的值同步给 nextIndex//若 transferIndex小于等于0,则说明原数组中的每个桶位置,都有线程在处理迁移了,//于是,需要跳出while循环,并把 i设为 -1,以跳转到④判断在处理的线程是否已经全部完成。else if ((nextIndex = transferIndex) <= 0) {i = -1;advance = false;}// (3) 第一个线程会先走到这里,确定它的数据迁移范围。(2)处会更新 nextIndex为 transferIndex 的最新值//因此第一次 nextIndex=n=16,nextBound代表当次迁移的数据范围下限,减去步长即可,//所以,第一次时,nextIndex=16,nextBound=16-2=14。后续,每次都会间隔一个步长。else if (U.compareAndSwapInt(this, TRANSFERINDEX, nextIndex,nextBound = (nextIndex > stride ?nextIndex - stride : 0))) {//bound代表当次数据迁移下限bound = nextBound;//第一次的i为15,因为长度16的数组,最后一个元素的下标为15i = nextIndex - 1;//表明不需要向前推进,只有当把当前范围内的数据全部迁移完成后,才可以向前推进advance = false;}}// (4)if (i < 0 || i >= n || i + n >= nextn) {int sc;//若全部线程迁移完成if (finishing) {nextTable = null;//更新table为新表table = nextTab;//扩容阈值改为原来数组长度的 3/2 ,即新长度的 3/4,也就是新数组长度的0.75倍sizeCtl = (n << 1) - (n >>> 1);return;}//到这,说明当前线程已经完成了自己的所有迁移(无论参与了几次迁移),//则把 sc 减1,表明参与扩容的线程数减少 1。if (U.compareAndSwapInt(this, SIZECTL, sc = sizeCtl, sc - 1)) {//在 addCount 方法最后,我们强调,迁移开始时,会设置 sc=(rs << RESIZE_STAMP_SHIFT) + 2//每当有一个线程参与迁移,sc 就会加 1,每当有一个线程完成迁移,sc 就会减 1。//因此,这里就是去校验当前 sc 是否和初始值是否相等。相等,则说明全部线程迁移完成。if ((sc - 2) != resizeStamp(n) << RESIZE_STAMP_SHIFT)return;//只有此处,才会把finishing 设置为true。finishing = advance = true;//这里非常有意思,会把 i 从 -1 修改为16,//目的就是,让 i 再从后向前扫描一遍数组,检查是否所有的桶都已被迁移完成,参看 (6)i = n; // recheck before commit}}// (5) 若i的位置元素为空,则说明当前桶的元素已经被迁移完成,就把头结点设置为fwd标志。else if ((f = tabAt(tab, i)) == null)advance = casTabAt(tab, i, null, fwd);// (6) 若当前桶的头结点是 ForwardingNode ,说明迁移完成,则向前推进else if ((fh = f.hash) == MOVED)advance = true; // already processed//(7) 处理当前桶的数据迁移。else {synchronized (f) { //给头结点加锁if (tabAt(tab, i) == f) {Node<K,V> ln, hn;//若hash值大于等于0,则说明是普通链表节点if (fh >= 0) {int runBit = fh & n;//这里是 1.7 的 CHM 的 rehash 方法和 1.8 HashMap的 resize 方法的结合体。//会分成两条链表,一条链表和原来的下标相同,另一条链表是原来的下标加数组长度的位置//然后找到 lastRun 节点,从它到尾结点整体迁移。//lastRun前边的节点则单个迁移,但是需要注意的是,这里是头插法。//另外还有一点和1.7不同,1.7 lastRun前边的节点是复制过去的,而这里是直接迁移的,没有复制操作。//所以,最后会有两条链表,一条链表从 lastRun到尾结点是正序的,而lastRun之前的元素是倒序的,//另外一条链表,从头结点开始就是倒叙的。看下图。Node<K,V> lastRun = f;for (Node<K,V> p = f.next; p != null; p = p.next) {int b = p.hash & n;if (b != runBit) {runBit = b;lastRun = p;}}if (runBit == 0) {ln = lastRun;hn = null;}else {hn = lastRun;ln = null;}for (Node<K,V> p = f; p != lastRun; p = p.next) {int ph = p.hash; K pk = p.key; V pv = p.val;if ((ph & n) == 0)ln = new Node<K,V>(ph, pk, pv, ln);elsehn = new Node<K,V>(ph, pk, pv, hn);}setTabAt(nextTab, i, ln);setTabAt(nextTab, i + n, hn);setTabAt(tab, i, fwd);advance = true;}//树节点else if (f instanceof TreeBin) {TreeBin<K,V> t = (TreeBin<K,V>)f;TreeNode<K,V> lo = null, loTail = null;TreeNode<K,V> hi = null, hiTail = null;int lc = 0, hc = 0;for (Node<K,V> e = t.first; e != null; e = e.next) {int h = e.hash;TreeNode<K,V> p = new TreeNode<K,V>(h, e.key, e.val, null, null);if ((h & n) == 0) {if ((p.prev = loTail) == null)lo = p;elseloTail.next = p;loTail = p;++lc;}else {if ((p.prev = hiTail) == null)hi = p;elsehiTail.next = p;hiTail = p;++hc;}}ln = (lc <= UNTREEIFY_THRESHOLD) ? untreeify(lo) :(hc != 0) ? new TreeBin<K,V>(lo) : t;hn = (hc <= UNTREEIFY_THRESHOLD) ? untreeify(hi) :(lc != 0) ? new TreeBin<K,V>(hi) : t;setTabAt(nextTab, i, ln);setTabAt(nextTab, i + n, hn);setTabAt(tab, i, fwd);advance = true;}}}}}}
迁移后的新数组链表方向示意图,以 runBit =0 为例。

image
helpTransfer()方法
最后再看 put 方法中的这个方法,就比较简单了。
final Node<K,V>[] helpTransfer(Node<K,V>[] tab, Node<K,V> f) {Node<K,V>[] nextTab; int sc;//头结点为 ForwardingNode ,并且新数组已经初始化if (tab != null && (f instanceof ForwardingNode) &&(nextTab = ((ForwardingNode<K,V>)f).nextTable) != null) {int rs = resizeStamp(tab.length);while (nextTab == nextTable && table == tab &&(sc = sizeCtl) < 0) {//若校验标识失败,或者已经扩容完成,或推进下标到头,则退出if ((sc >>> RESIZE_STAMP_SHIFT) != rs || sc == rs + 1 ||sc == rs + MAX_RESIZERS || transferIndex <= 0)break;//当前线程需要帮助迁移,sc值加1if (U.compareAndSwapInt(this, SIZECTL, sc, sc + 1)) {transfer(tab, nextTab);break;}}return nextTab;}return table;}
JDK1.8 的 CHM 最主要的逻辑基本上都讲完了,其它方法原理类同。1.8 的 ConcurrentHashMap 实现原理还是比较简单的,但是代码实现比较复杂。相对于 1.7 来说,锁的粒度降低了,效率也提高了
5 HashTable
HashTable是通过synchronized关键字来保证线程安全的 get(),put(),containsKey(),size()…一些列方法都加了synchronized关键字。
HashTable是通过数组+链表的方式来存储数据的,HashTable不能存储值为null的数据
默认的加载因子(initialCapacity)也是0.75。
HashTable在构造方法中就完成了数组的初始化,threshold=initialCapacity*loadFactory。
在插入新数据的时候会判断size是否大于等于threshold。如果是会扩容(rehash())方法。
newCapacity=oldCapacity*2 + 1;newThr=newCpacity*loadFactory
不过数组的最大长度为Integer.MAX_VALUE - 8。threshold最大值为Integer.MAX_VALUE - 8+1。
- HashTable的链表插入方式为头插法。
6 ThreadLocal
https://www.jianshu.com/p/3c5d7f09dfbd
6.1.ThreadLocal简介
网上看到一些文章,提到关于ThreadLocal可能引起的内存泄露,搞得都不敢在代码里随意使用了,于是来研究下,看看到底ThreadLocal会不会导致内存泄露,什么情况下会导致泄露。
ThreadLocal,顾名思义,其存储的内容是线程私本地的/私有的,我们常使用ThreadLocal来存储/维护一些资源或者变量,以避免线程争用或者同步问题,例如使用ThreadLocal来为每个线程维持一个redis连接(生产中这也许不是一个好的方式,还是推荐专业的连接池)或者维持一些线程私有的变量等。
例如,假设我们在一个线程应用中需要对时间做格式化,我们很容易想到的是使用SimpleDateFormat这个工具类,但是SimpleDateFormat不是线程安全的,那么我们通常用两种做法:
- 每次用到的时候new一个SimpleDateFormat对象,使用完丢弃,交给gc
- 每个线程维护一个SimpleDateFormat实例,线程运行期间不重复创建
那么无论从执行效率还是内存占用方面,我们都倾向于使用后者,即线程私有一个SimpleDateFormat对象,这时候,ThreadLocal就是很好的应用,示例代码如下:
import java.text.SimpleDateFormat;import java.util.Date;public class TestTask implements Runnable {private boolean stop = false;private ThreadLocal<SimpleDateFormat> sdfHolder = new ThreadLocal<SimpleDateFormat>() {@Overrideprotected SimpleDateFormat initialValue() {return new SimpleDateFormat("yyyyMMdd");}};@Overridepublic void run() {while (!stop) {String formatedDateStr = sdfHolder.get().format(new Date());System.out.println("formated date str:" + formatedDateStr);//may be sleep for a while to avoid high cpu cost}sdfHolder.remove();}//something else}
代码中模拟了一个需要反复执行的Task,其run方法中,while条件除非stop是true,否则就一直运转下去。在该示例中通过ThreadLocal为每个线程实例化了一个SimpleDateFormat对象,当需要的时候,通过get()获取即可,实现了每个线程全程只有一个SimpleDateFormat对象。同时在stop为true时使用ThreadLocal的remove方法删除当前线程使用的SimpleDateFormat对象,以便于垃圾回收。
仅演示ThreadLocal用法,暂不讨论代码设计
6.2 ThreadLocal内存模型
上面我们简单介绍了ThreadLocal的概念和使用,下面看下ThreadLocal的内存模型。
私有变量存储在哪里
在代码中,我们使用ThreadLocal实例提供的set/get方法来存储/使用value,但ThreadLocal实例其实只是一个引用,真正存储值的是一个Map,其key实ThreadLocal实例本身,value是我们设置的值,分布在堆区。这个Map的类型是ThreadLocal.ThreadLocalMap(ThreadLocalMap是ThreadLocal的内部类),其key的类型是ThreadLocal,value是Object,类定义如下:
static class ThreadLocalMap {ThreadLocalMap(ThreadLocal firstKey, Object firstValue) {table = new Entry[INITIAL_CAPACITY];int i = firstKey.threadLocalHashCode & (INITIAL_CAPACITY - 1);table[i] = new Entry(firstKey, firstValue);size = 1;setThreshold(INITIAL_CAPACITY);}static class Entry extends WeakReference<ThreadLocal> {/** The value associated with this ThreadLocal. */Object value;Entry(ThreadLocal k, Object v) {super(k);value = v;}}}
那么当我们重写init或者调用set/get的时候,内部的逻辑是怎样的呢,按照上面的说法,应该是将value存储到了ThreadLocalMap中,或者从已有的ThreadLocalMap中获取value,我们来通过代码分析一下。
ThreadLocal.set(T value)
set的逻辑比较简单,就是获取当前线程的ThreadLocalMap,然后往map里添加KV,K是this,也就是当前ThreadLocal实例,V是我们传入的value。
/*** Sets the current thread's copy of this thread-local variable* to the specified value. Most subclasses will have no need to* override this method, relying solely on the {@link #initialValue}* method to set the values of thread-locals.** @param value the value to be stored in the current thread's copy of* this thread-local.*/public void set(T value) {Thread t = Thread.currentThread();ThreadLocalMap map = getMap(t);if (map != null)map.set(this, value);elsecreateMap(t, value);}
其内部实现首先需要获取关联的Map,我们看下getMap和createMap的实现
/*** Get the map associated with a ThreadLocal. Overridden in* InheritableThreadLocal.** @param t the current thread* @return the map*/ThreadLocalMap getMap(Thread t) {return t.threadLocals;}/*** Create the map associated with a ThreadLocal. Overridden in* InheritableThreadLocal.** @param t the current thread* @param firstValue value for the initial entry of the map* @param map the map to store.*/void createMap(Thread t, T firstValue) {t.threadLocals = new ThreadLocalMap(this, firstValue);}
可以看到,getMap就是返回了当前Thread实例的map(t.threadLocals),create也是创建了Thread的map(t.threadLocals),也就是说对于一个Thread实例,ThreadLocalMap是其内部的一个属性,在需要的时候,可以通过ThreadLocal创建或者获取,然后存放相应的值。我们看下Thread类的关键代码
public class Thread implements Runnable {/* ThreadLocal values pertaining to this thread. This map is maintained* by the ThreadLocal class. */ThreadLocal.ThreadLocalMap threadLocals = null;//省略了其他代码}
可以看到,Thread中定义了属性threadLocals,但其初始化和使用的过程,都是通过ThreadLocal这个类来执行的。
ThreadLocal.get()
get是获取当前线程的对应的私有变量,是我们之前set或者通过initialValue指定的变量,其代码如下
/*** Returns the value in the current thread's copy of this* thread-local variable. If the variable has no value for the* current thread, it is first initialized to the value returned* by an invocation of the {@link #initialValue} method.** @return the current thread's value of this thread-local*/public T get() {Thread t = Thread.currentThread();ThreadLocalMap map = getMap(t);if (map != null) {ThreadLocalMap.Entry e = map.getEntry(this);if (e != null)return (T)e.value;}return setInitialValue();}/*** Variant of set() to establish initialValue. Used instead* of set() in case user has overridden the set() method.** @return the initial value*/private T setInitialValue() {T value = initialValue();Thread t = Thread.currentThread();ThreadLocalMap map = getMap(t);if (map != null)map.set(this, value);elsecreateMap(t, value);return value;}
可以看到,其逻辑也比较简单清晰:
- 获取当前线程的ThreadLocalMap实例
- 如果不为空,以当前ThreadLocal实例为key获取value
- 如果ThreadLocalMap为空或者根据当前ThreadLocal实例获取的value为空,则执行setInitialValue()
setInitialValue()内部如下:
- 调用我们重写的initialValue得到一个value
- 将value放入到当前线程对应的ThreadLocalMap中
- 如果map为空,先实例化一个map,然后赋值KV
关键设计小结
代码分析到这里,其实对于ThreadLocal的内部主要设计以及其和Thread的关系比较清楚了:
- 每个线程,是一个Thread实例,其内部拥有一个名为threadLocals的实例成员,其类型是ThreadLocal.ThreadLocalMap
- 通过实例化ThreadLocal实例,我们可以对当前运行的线程设置一些线程私有的变量,通过调用ThreadLocal的set和get方法存取
- ThreadLocal本身并不是一个容器,我们存取的value实际上存储在ThreadLocalMap中,ThreadLocal只是作为TheadLocalMap的key
- 每个线程实例都对应一个TheadLocalMap实例,我们可以在同一个线程里实例化很多个ThreadLocal来存储很多种类型的值,这些ThreadLocal实例分别作为key,对应各自的value
- 当调用ThreadLocal的set/get进行赋值/取值操作时,首先获取当前线程的ThreadLocalMap实例,然后就像操作一个普通的map一样,进行put和get
当然,这个ThreadLocalMap并不是一个普通的Map(比如常用的HashMap),而是一个特殊的,key为弱引用的map,这个我们后面再详谈
ThreadLocalMap 内部维护了一个Entry[] table。用户存储线程不同的ThreadLocal实例值。通过ThreadLocal实列的threadLocalHashCode&(table.length-1)拿到下标。
通过上一节的分析,其实我们已经很清楚ThreadLocal的相关设计了,对数据存储的具体分布也会有个比较清晰的概念。下面的图是网上找来的常见到的示意图,我们可以通过该图对ThreadLocal的存储有个更加直接的印象。

TheadLocal内存模型
我们知道Thread运行时,线程的的一些局部变量和引用使用的内存属于Stack(栈)区,而普通的对象是存储在Heap(堆)区。根据上图,基本分析如下:
- 线程运行时,我们定义的TheadLocal对象被初始化,存储在Heap,同时线程运行的栈区保存了指向该实例的引用,也就是图中的ThreadLocalRef
- 当ThreadLocal的set/get被调用时,虚拟机会根据当前线程的引用也就是CurrentThreadRef找到其对应在堆区的实例,然后查看其对用的TheadLocalMap实例是否被创建,如果没有,则创建并初始化。
- Map实例化之后,也就拿到了该ThreadLocalMap的句柄,然后如果将当前ThreadLocal对象作为key,进行存取操作
- 图中的虚线,表示key对ThreadLocal实例的引用是个弱引用
6.3 插曲:强引用/弱引用
java中的引用分为四种,按照引用强度不同,从强到弱依次为:强引用、软引用、弱引用和虚引用,如果不是专门做jvm研究,对其概念很难清晰的定义,我们大致可以理解为,引用的强度,代表了对内存占用的能力大小,具体体现在GC的时候,会不会被回收,什么时候被回收。
ThreadLocal被用作TheadLocalMap的弱引用key,这种设计也是ThreadLocal被讨论内存泄露的热点问题,因此有必要了解一下什么是弱引用。
强引用
强引用虽然在开发过程中并不怎么提及,但是无处不在,例如我们在一个对象中通过如下代码实例化一个StringBuffer对象
StringBuffer buffer = new StringBuffer();
我们知道StringBuffer的实例通常是被创建在堆中的,而当前对象持有该StringBuffer对象的引用,以便后续的访问,这个引用,就是一个强引用。
对GC知识比较熟悉的可以知道,HotSpot JVM目前的垃圾回收算法一般默认是可达性算法,即在每一轮GC的时候,选定一些对象作为GC ROOT,然后以它们为根发散遍历,遍历完成之后,如果一个对象不被任何GC ROOT引用,那么它就是不可达对象,则在接下来的GC过程中很可能会被回收。
强引用最重要的就是它能够让引用变得强(Strong),这就决定了它和垃圾回收器的交互。具体来说,如果一个对象通过一串强引用链接可到达(Strongly reachable),它是不会被回收的。如果你不想让你正在使用的对象被回收,这就正是你所需要的。
软引用
软引用是用来描述一些还有用但是并非必须的对象。对于软引用关联着的对象,在系统将要发生内存溢出异常之前,将会把这些对象列进回收返回之后进行第二次回收。如果这次回收还没有足够的内存,才会抛出内存溢出异常。JDK1.2之后提供了SoftReference来实现软引用。
相对于强引用,软引用在内存充足时可能不会被回收,在内存不够时会被回收。
弱引用
弱引用也是用来描述非必须的对象的,但它的强度更弱,被弱引用关联的对象只能生存到下一次GC发生之前,也就是说下一次GC就会被回收。JDK1.2之后,提供了WeakReference来实现弱引用。
虚引用
虚引用也成为幽灵引用或者幻影引用,它是最弱的一种引用关系。一个瑞祥是否有虚引用的存在,完全不会对其生存时间造成影响,也无法通过虚引用来取得一个对象的实例。为一个对象设置虚引用关联的唯一目的就是在这个对象被GC时收到一个系统通知。JDK1.2之后提供了PhantomReference来实现虚引用
6.4 可能的内存泄露分析
了解了ThreadLocal的内部模型以及弱引用,接下来可以分析一下是否有内存泄露的可能以及如何避免。
内存泄露分析
根据上一节的内存模型图我们可以知道,由于ThreadLocalMap是以弱引用的方式引用着ThreadLocal,换句话说,就是ThreadLocal是被ThreadLocalMap以弱引用的方式关联着,因此如果ThreadLocal没有被ThreadLocalMap以外的对象引用,则在下一次GC的时候,ThreadLocal实例就会被回收,那么此时ThreadLocalMap里的一组KV的K就是null了,因此在没有额外操作的情况下,此处的V便不会被外部访问到,而且只要Thread实例一直存在,Thread实例就强引用着ThreadLocalMap,因此ThreadLocalMap就不会被回收,那么这里K为null的V就一直占用着内存。
综上,发生内存泄露的条件是
- ThreadLocal实例没有被外部强引用,比如我们假设在提交到线程池的task中实例化的ThreadLocal对象,当task结束时,ThreadLocal的强引用也就结束了
- ThreadLocal实例被回收,但是在ThreadLocalMap中的V没有被任何清理机制有效清理
- 当前Thread实例一直存在,则会一直强引用着ThreadLocalMap,也就是说ThreadLocalMap也不会被GC
也就是说,如果Thread实例还在,但是ThreadLocal实例却不在了,则ThreadLocal实例作为key所关联的value无法被外部访问,却还被强引用着,因此出现了内存泄露。
也就是说,我们回答了文章开头的第一个问题,ThreadLocal如果使用的不当,是有可能引起内存泄露的,虽然触发的场景不算很容易。
这里要额外说明一下,这里说的内存泄露,是因为对其内存模型和设计不了解,且编码时不注意导致的内存管理失联,而不是有意为之的一直强引用或者频繁申请大内存。比如如果编码时不停的人为塞一些很大的对象,而且一直持有引用最终导致OOM,不能算作ThreadLocal导致的“内存泄露”,只是代码写的不当而已!
TheadLocal本身的优化
进一步分析ThreadLocalMap的代码,可以发现ThreadLocalMap内部也是做了一定的优化的
/*** Set the value associated with key.** @param key the thread local object* @param value the value to be set*/private void set(ThreadLocal key, Object value) {// We don't use a fast path as with get() because it is at// least as common to use set() to create new entries as// it is to replace existing ones, in which case, a fast// path would fail more often than not.Entry[] tab = table;int len = tab.length;int i = key.threadLocalHashCode & (len-1);for (Entry e = tab[i];e != null;e = tab[i = nextIndex(i, len)]) {ThreadLocal k = e.get();if (k == key) {e.value = value;return;}if (k == null) {replaceStaleEntry(key, value, i);return;}}tab[i] = new Entry(key, value);int sz = ++size;if (!cleanSomeSlots(i, sz) && sz >= threshold)rehash();}
可以看到,在set值的时候,有一定的几率会执行replaceStaleEntry(key, value, i)方法,其作用就是将当前的值替换掉以前的key为null的值,重复利用了空间。
6.5 ThreadLocal使用建议
通过前面几节的分析,我们基本弄清楚了ThreadLocal相关设计和内存模型,对于是否会发生内存泄露做了分析,下面总结下几点建议:
- 当需要存储线程私有变量的时候,可以考虑使用ThreadLocal来实现
- 当需要实现线程安全的变量时,可以考虑使用ThreadLocal来实现
- 当需要减少线程资源竞争的时候,可以考虑使用ThreadLocal来实现
注意Thread实例和ThreadLocal实例的生存周期,因为他们直接关联着存储数据的生命周期
- 如果频繁的在线程中new ThreadLocal对象,在使用结束时,最好调用ThreadLocal.remove来释放其value的引用,避免在ThreadLocal被回收时value无法被访问却又占用着内存
- 当线程归还线程池的时候,线程内维护的threadLocals不会被清空。所以在使用完之后,一定要ThreadLocal.remove来释放,不然可能造成上值重用。
https://www.jianshu.com/p/1a5d288bdaee
6.6 底层结构
著作权归https://pdai.tech所有。链接:https://www.pdai.tech/md/java/thread/java-thread-x-theorty.htmlpublic class ThreadLocalExample1 {public static void main(String[] args) {ThreadLocal threadLocal1 = new ThreadLocal();ThreadLocal threadLocal2 = new ThreadLocal();Thread thread1 = new Thread(() -> {threadLocal1.set(1);threadLocal2.set(1);});Thread thread2 = new Thread(() -> {threadLocal1.set(2);threadLocal2.set(2);});thread1.start();thread2.start();}}

7 强弱软虚
在java中提供4个级别的引用:强引用、软引用、弱引用和虚引用。除了强引用外,其他3中引用均可以在java.lang.ref包中找到对应的类。开发人员可以在应用程序中直接使用他们。
1 强引用
强引用就是程序中一般使用的引用类型,强引用的对象是可触及的,不会被回收。相对的,软引用、弱引用和虚引用的对象是软可触及的、弱可触及的和虚可触及的,在一定条件下,都是可以被回收的。
强引用示例:StringBuffer str = new StringBuffer(“Hello world”);
假设以上代码是在函数体内运行的,那么局部变量str将被分配在栈上,而对象StringBuffer实例被分配在堆上。局部变量str指向StringBuffer实例所在堆空间,通过str可以操作该实例,那么str就是StringBuffer实例的强引用。
此时,如果再运行一个赋值语句:
StringBuffer str1 = str;
则str所指向的对象也将被str1所指向,同时在局部变量表上会分配空间存放str1变量。此时该StringBuffer实例就有两个引用。对引用的“==”操作用于表示两操作数所指向的堆空间地址是否相同,不表示两操作数所指的对象是否相同。
强引用的特点:
强引用可以直接访问目标对象 强引用所指向的对象在任何时候都不会被系统回收,虚拟机宁愿抛出OOM异常,也不会回收强引用所指的对象。 强引用可能导致内存泄漏
2 软引用——可被回收的引用
软引用是比强引用弱一点的引用类型,一个对象只持有软引用,那么当堆空间不足时,就会被回收。软引用使用java.lang.ref.SoftReference类型
import java.lang.ref.SoftReference;public class SoftRef {public static class User {public User(int id, String name) {this.id = id;this.name = name;}public int id;public String name;@Overridepublic String toString() {return "[id=" + String.valueOf(id) + ",name=" + name + "]";}}public static void main(String[] args) {User u = new User(1, "gim");SoftReference<User> userSoftRef = new SoftReference<User>(u);//创建引用给定对象的新的软引用 u = null; //去除强引用System.out.println(userSoftRef.get());System.gc();System.out.println("After GC:");System.out.println(userSoftRef.get());byte[] b = new byte[1024 * 925 * 7];//分配7M左右,使内存空间紧张System.gc();System.out.println(userSoftRef.get());}}
如果虚拟机不加参数设置堆内存限制,则打印出:
[id=1,name=gim] After GC: [id=1,name=gim] [id=1,name=gim]
因为虚拟机的内存总量是九十多兆,且虚拟机企图使用的最大内存总量是这个的十几倍。故不会出现资源紧张,也不会产生内存溢出现象。
如果使用-Xmx10m运行上述代码,可以得到:
[id=1,name=gim](第一次从软引用中获取数据) After GC: [id=1,name=gim](GC没有清除软引用) null(由于内存紧张,软引用被清除)
结论:GC未必会回收软引用的对象,但是当内存资源紧张时,软引用对象会被回收,所以软引用对象不会引起内存溢出。
3 弱引用——-发现即回收
弱引用是一种比软引用较弱的引用类型。在系统GC时,只要发现弱引用,不管系统堆空间使用情况如何,都会将对象进行回收。但是由于垃圾回收器的优先级通常很低,因此,并不一定能很快的发现持有弱引用的对象。在这种情况下,弱引用对象可以存在较长的时间,一旦一个弱引用对象被垃圾回收器回收,便会加入一个注册的引用队列(这一点和软引用很像)。弱引用使用java.lang.ref.WeakReference类实现。
实例2:展示弱引用的特点
import java.lang.ref.WeakReference;public class WeakRef {public static class User {public User(int id, String name) {this.id = id;this.name = name;}public int id;public String name;@Overridepublic String toString() {return "[id=" + String.valueOf(id) + ",name=" + name + "]";}}public static void main(String[] args) {User u = new User(1, "gim");WeakReference<User> userReference = new WeakReference<User>(u);u = null;System.out.println(userReference.get());System.gc();System.out.println("After GC:");System.out.println(userReference.get());}}
不用设置虚拟机参数,直接运行代码打印出:
[id=1,name=gim] After GC: null
可以看书,GC之后,弱引用对象立即被清除。弱引用和软引用一样,在构造弱引用时,也可以指定一个引用队列,当弱引用对象被回收时,就会加入指定的引用队列,通过这个队列可以跟踪对象的回收情况。
注意:软引用、弱引用都非常适合来保存那些可有可无的缓存数据(应用场景)。如果这么做,当系统内存不足时,这些缓存数据会被回收,不会导致内存的溢出,而当内存资源充足时,这些缓存又可以存在相当长的时间,从而起到加速系统的作用。
4 虚引用——对象回收跟踪
一个持有虚引用的对象,和没有引用几乎一样。随时都可能被垃圾回收器回收,当试图通过虚引用的get()方法取得强引用时,总是会失败。
并且,虚引用必须和引用队列一起使用,它的作用主要是跟踪垃圾回收过程
当垃圾回收器准备回收一个对象时,如果发现它还有虚引用,就会在回收对象后,将这个虚引用加入引用队列,以通知引用程序对象的回收情况。
实例3 :使用虚引用跟踪一个可复活对象的回收
import java.lang.ref.PhantomReference;import java.lang.ref.ReferenceQueue;public class TraceCanReliveObj {public static TraceCanReliveObj obj; //可以复活对象static ReferenceQueue<TraceCanReliveObj> phantomQueue = null;public static class CheckRefQueue extends Thread {@Overridepublic void run() {while (true) {if (phantomQueue != null) {PhantomReference<TraceCanReliveObj> objt = null;try {objt = (PhantomReference<TraceCanReliveObj>) phantomQueue.remove();} catch (InterruptedException e) {e.printStackTrace();}if (objt != null) {System.out.println("TraceCanReliveObj is delete by GC");}}}}}@Overrideprotected void finalize() throws Throwable {super.finalize();System.out.println("CanReliveObj finalize called");obj = this; //使得对象复活}public String toString() {return "I am CanReliveObj";}public static void main(String[] args) throws InterruptedException {Thread t = new CheckRefQueue();t.setDaemon(true);//守护线程t.start();phantomQueue = new ReferenceQueue<TraceCanReliveObj>();obj = new TraceCanReliveObj();//构造了TraceCanReliveObj对象的虚引用,并指定了引用队列。PhantomReference<TraceCanReliveObj> phantomRef = new PhantomReference<TraceCanReliveObj>(obj, phantomQueue);obj = null; //将强引用去除System.gc(); //第一次进行GC,由于对象可复活,GC无法回收该对象。Thread.sleep(1000);if (obj == null) {System.out.println("obj 是 null");} else {System.out.println("obj 可用");}System.out.println("第二次GC");obj = null;System.gc(); //第二次进行GC,由于finalize()只会被调用一次,因此第2次GC会回收对象,同时其引用队列应该也会捕获到对象的回收Thread.sleep(1000);if (obj == null) {System.out.println("obj 是 null");} else {System.out.println("obj 可用");}}}
直接运行代码打印:
CanReliveObj finalize called (对象复活) obj 可用 第二次GC (第2次,对象无法复活) TraceCanReliveObj is delete by GC (引用队列捕获到对象被回收) obj 是 null
由于虚引用可以跟踪对象的回收时间,因此,也可以将一些资源释放操作放置在虚引用中执行和记录。
在程序设计中一般很少使用弱引用与虚引用,使用软引用的情况较多,这是因为软引用可以加速 JVM 对垃圾内存的回收速度,可以维护系统的运行安全,防止内存溢出(OutOfMemory)等问题的产生。
8 volatile
volatile这个关键字可能很多朋友都听说过,或许也都用过。在Java 5之前,它是一个备受争议的关键字,因为在程序中使用它往往会导致出人意料的结果。在Java 5之后,volatile关键字才得以重获生机。
volatile关键字虽然从字面上理解起来比较简单,但是要用好不是一件容易的事情。由于volatile关键字是与Java的内存模型有关的,因此在讲述volatile关键之前,我们先来了解一下与内存模型相关的概念和知识,然后分析了volatile关键字的实现原理,最后给出了几个使用volatile关键字的场景。
以下是本文的目录大纲:
一.内存模型的相关概念
二.并发编程中的三个概念
三.Java内存模型
四..深入剖析volatile关键字
五.使用volatile关键字的场景
若有不正之处请多多谅解,并欢迎批评指正。
请尊重作者劳动成果,转载请标明原文链接:
http://www.cnblogs.com/dolphin0520/p/3920373.html
8.1 内存模型的相关概念
大家都知道,计算机在执行程序时,每条指令都是在CPU中执行的,而执行指令过程中,势必涉及到数据的读取和写入。由于程序运行过程中的临时数据是存放在主存(物理内存)当中的,这时就存在一个问题,由于CPU执行速度很快,而从内存读取数据和向内存写入数据的过程跟CPU执行指令的速度比起来要慢的多,因此如果任何时候对数据的操作都要通过和内存的交互来进行,会大大降低指令执行的速度。因此在CPU里面就有了高速缓存。
也就是,当程序在运行过程中,会将运算需要的数据从主存复制一份到CPU的高速缓存当中,那么CPU进行计算时就可以直接从它的高速缓存读取数据和向其中写入数据,当运算结束之后,再将高速缓存中的数据刷新到主存当中。举个简单的例子,比如下面的这段代码:
i = i + 1;
当线程执行这个语句时,会先从主存当中读取i的值,然后复制一份到高速缓存当中,然后CPU执行指令对i进行加1操作,然后将数据写入高速缓存,最后将高速缓存中i最新的值刷新到主存当中。
这个代码在单线程中运行是没有任何问题的,但是在多线程中运行就会有问题了。在多核CPU中,每条线程可能运行于不同的CPU中,因此每个线程运行时有自己的高速缓存(对单核CPU来说,其实也会出现这种问题,只不过是以线程调度的形式来分别执行的)。本文我们以多核CPU为例。
比如同时有2个线程执行这段代码,假如初始时i的值为0,那么我们希望两个线程执行完之后i的值变为2。但是事实会是这样吗?
可能存在下面一种情况:初始时,两个线程分别读取i的值存入各自所在的CPU的高速缓存当中,然后线程1进行加1操作,然后把i的最新值1写入到内存。此时线程2的高速缓存当中i的值还是0,进行加1操作之后,i的值为1,然后线程2把i的值写入内存。
最终结果i的值是1,而不是2。这就是著名的缓存一致性问题。通常称这种被多个线程访问的变量为共享变量。
也就是说,如果一个变量在多个CPU中都存在缓存(一般在多线程编程时才会出现),那么就可能存在缓存不一致的问题。
为了解决缓存不一致性问题,通常来说有以下2种解决方法:
1)通过在总线加LOCK#锁的方式
2)通过缓存一致性协议
这2种方式都是硬件层面上提供的方式。
在早期的CPU当中,是通过在总线上加LOCK#锁的形式来解决缓存不一致的问题。因为CPU和其他部件进行通信都是通过总线来进行的,如果对总线加LOCK#锁的话,也就是说阻塞了其他CPU对其他部件访问(如内存),从而使得只能有一个CPU能使用这个变量的内存。比如上面例子中 如果一个线程在执行 i = i +1,如果在执行这段代码的过程中,在总线上发出了LCOK#锁的信号,那么只有等待这段代码完全执行完毕之后,其他CPU才能从变量i所在的内存读取变量,然后进行相应的操作。这样就解决了缓存不一致的问题。
但是上面的方式会有一个问题,由于在锁住总线期间,其他CPU无法访问内存,导致效率低下。
所以就出现了缓存一致性协议。最出名的就是Intel 的MESI协议,MESI协议保证了每个缓存中使用的共享变量的副本是一致的。它核心的思想是:当CPU写数据时,如果发现操作的变量是共享变量,即在其他CPU中也存在该变量的副本,会发出信号通知其他CPU将该变量的缓存行置为无效状态,因此当其他CPU需要读取这个变量时,发现自己缓存中缓存该变量的缓存行是无效的,那么它就会从内存重新读取。
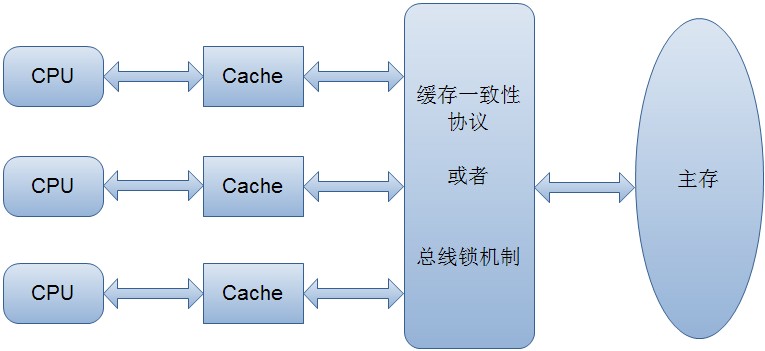
8.2 并发编程中的三个概念
在并发编程中,我们通常会遇到以下三个问题:原子性问题,可见性问题,有序性问题。我们先看具体看一下这三个概念:
1.原子性
原子性:即一个操作或者多个操作 要么全部执行并且执行的过程不会被任何因素打断,要么就都不执行。
一个很经典的例子就是银行账户转账问题:
比如从账户A向账户B转1000元,那么必然包括2个操作:从账户A减去1000元,往账户B加上1000元。
试想一下,如果这2个操作不具备原子性,会造成什么样的后果。假如从账户A减去1000元之后,操作突然中止。然后又从B取出了500元,取出500元之后,再执行 往账户B加上1000元 的操作。这样就会导致账户A虽然减去了1000元,但是账户B没有收到这个转过来的1000元。
所以这2个操作必须要具备原子性才能保证不出现一些意外的问题。
同样地反映到并发编程中会出现什么结果呢?
举个最简单的例子,大家想一下假如为一个32位的变量赋值过程不具备原子性的话,会发生什么后果?
i = 9;
假若一个线程执行到这个语句时,我暂且假设为一个32位的变量赋值包括两个过程:为低16位赋值,为高16位赋值。
那么就可能发生一种情况:当将低16位数值写入之后,突然被中断,而此时又有一个线程去读取i的值,那么读取到的就是错误的数据。
2.可见性
可见性是指当多个线程访问同一个变量时,一个线程修改了这个变量的值,其他线程能够立即看得到修改的值。
举个简单的例子,看下面这段代码:
//线程1执行的代码int i = 0;i = 10;//线程2执行的代码j = i;
假若执行线程1的是CPU1,执行线程2的是CPU2。由上面的分析可知,当线程1执行 i =10这句时,会先把i的初始值加载到CPU1的高速缓存中,然后赋值为10,那么在CPU1的高速缓存当中i的值变为10了,却没有立即写入到主存当中。
此时线程2执行 j = i,它会先去主存读取i的值并加载到CPU2的缓存当中,注意此时内存当中i的值还是0,那么就会使得j的值为0,而不是10.
这就是可见性问题,线程1对变量i修改了之后,线程2没有立即看到线程1修改的值。
3.有序性
有序性:即程序执行的顺序按照代码的先后顺序执行。举个简单的例子,看下面这段代码:
int i = 0;boolean flag = false;i = 1; //语句1flag = true; //语句2
上面代码定义了一个int型变量,定义了一个boolean类型变量,然后分别对两个变量进行赋值操作。从代码顺序上看,语句1是在语句2前面的,那么JVM在真正执行这段代码的时候会保证语句1一定会在语句2前面执行吗?不一定,为什么呢?这里可能会发生指令重排序(Instruction Reorder)。
下面解释一下什么是指令重排序,一般来说,处理器为了提高程序运行效率,可能会对输入代码进行优化,它不保证程序中各个语句的执行先后顺序同代码中的顺序一致,但是它会保证程序最终执行结果和代码顺序执行的结果是一致的。
比如上面的代码中,语句1和语句2谁先执行对最终的程序结果并没有影响,那么就有可能在执行过程中,语句2先执行而语句1后执行。
但是要注意,虽然处理器会对指令进行重排序,但是它会保证程序最终结果会和代码顺序执行结果相同,那么它靠什么保证的呢?再看下面一个例子:
int a = 10; //语句1int r = 2; //语句2a = a + 3; //语句3r = a*a; //语句4
这段代码有4个语句,那么可能的一个执行顺序是:

那么可不可能是这个执行顺序呢: 语句2 语句1 语句4 语句3
不可能,因为处理器在进行重排序时是会考虑指令之间的数据依赖性,如果一个指令Instruction 2必须用到Instruction 1的结果,那么处理器会保证Instruction 1会在Instruction 2之前执行。
虽然重排序不会影响单个线程内程序执行的结果,但是多线程呢?下面看一个例子:
//线程1:context = loadContext(); //语句1inited = true; //语句2//线程2:while(!inited ){sleep()}doSomethingwithconfig(context);
上面代码中,由于语句1和语句2没有数据依赖性,因此可能会被重排序。假如发生了重排序,在线程1执行过程中先执行语句2,而此是线程2会以为初始化工作已经完成,那么就会跳出while循环,去执行doSomethingwithconfig(context)方法,而此时context并没有被初始化,就会导致程序出错。
从上面可以看出,指令重排序不会影响单个线程的执行,但是会影响到线程并发执行的正确性。
也就是说,要想并发程序正确地执行,必须要保证原子性、可见性以及有序性。只要有一个没有被保证,就有可能会导致程序运行不正确。
8.3 Java内存模型
在前面谈到了一些关于内存模型以及并发编程中可能会出现的一些问题。下面我们来看一下Java内存模型,研究一下Java内存模型为我们提供了哪些保证以及在java中提供了哪些方法和机制来让我们在进行多线程编程时能够保证程序执行的正确性。
在Java虚拟机规范中试图定义一种Java内存模型(Java Memory Model,JMM)来屏蔽各个硬件平台和操作系统的内存访问差异,以实现让Java程序在各种平台下都能达到一致的内存访问效果。那么Java内存模型规定了哪些东西呢,它定义了程序中变量的访问规则,往大一点说是定义了程序执行的次序。注意,为了获得较好的执行性能,Java内存模型并没有限制执行引擎使用处理器的寄存器或者高速缓存来提升指令执行速度,也没有限制编译器对指令进行重排序。也就是说,在java内存模型中,也会存在缓存一致性问题和指令重排序的问题。
Java内存模型规定所有的变量都是存在主存当中(类似于前面说的物理内存),每个线程都有自己的工作内存(类似于前面的高速缓存)。线程对变量的所有操作都必须在工作内存中进行,而不能直接对主存进行操作。并且每个线程不能访问其他线程的工作内存。
举个简单的例子:在java中,执行下面这个语句:
i = 10;
执行线程必须先在自己的工作线程中对变量i所在的缓存行进行赋值操作,然后再写入主存当中。而不是直接将数值10写入主存当中。
那么Java语言 本身对 原子性、可见性以及有序性提供了哪些保证呢?
1.原子性
在Java中,对基本数据类型的变量的读取和赋值操作是原子性操作,即这些操作是不可被中断的,要么执行,要么不执行。
上面一句话虽然看起来简单,但是理解起来并不是那么容易。看下面一个例子i:
请分析以下哪些操作是原子性操作:
x = 10; //语句1y = x; //语句2x++; //语句3x = x + 1; //语句4
咋一看,有些朋友可能会说上面的4个语句中的操作都是原子性操作。其实只有语句1是原子性操作,其他三个语句都不是原子性操作。
语句1是直接将数值10赋值给x,也就是说线程执行这个语句的会直接将数值10写入到工作内存中。
语句2实际上包含2个操作,它先要去读取x的值,再将x的值写入工作内存,虽然读取x的值以及 将x的值写入工作内存 这2个操作都是原子性操作,但是合起来就不是原子性操作了。
同样的,x++和 x = x+1包括3个操作:读取x的值,进行加1操作,写入新的值。
所以上面4个语句只有语句1的操作具备原子性。
也就是说,只有简单的读取、赋值(而且必须是将数字赋值给某个变量,变量之间的相互赋值不是原子操作)才是原子操作。
不过这里有一点需要注意:在32位平台下,对64位数据的读取和赋值是需要通过两个操作来完成的,不能保证其原子性。但是好像在最新的JDK中,JVM已经保证对64位数据的读取和赋值也是原子性操作了。
从上面可以看出,Java内存模型只保证了基本读取和赋值是原子性操作,如果要实现更大范围操作的原子性,可以通过synchronized和Lock来实现。由于synchronized和Lock能够保证任一时刻只有一个线程执行该代码块,那么自然就不存在原子性问题了,从而保证了原子性。
2.可见性
对于可见性,Java提供了volatile关键字来保证可见性。
当一个共享变量被volatile修饰时,它会保证修改的值会立即被更新到主存,当有其他线程需要读取时,它会去内存中读取新值。
而普通的共享变量不能保证可见性,因为普通共享变量被修改之后,什么时候被写入主存是不确定的,当其他线程去读取时,此时内存中可能还是原来的旧值,因此无法保证可见性。
另外,通过synchronized和Lock也能够保证可见性,synchronized和Lock能保证同一时刻只有一个线程获取锁然后执行同步代码,并且在释放锁之前会将对变量的修改刷新到主存当中。因此可以保证可见性。
3.有序性
在Java内存模型中,允许编译器和处理器对指令进行重排序,但是重排序过程不会影响到单线程程序的执行,却会影响到多线程并发执行的正确性。
在Java里面,可以通过volatile关键字来保证一定的“有序性”(具体原理在下一节讲述)。另外可以通过synchronized和Lock来保证有序性,很显然,synchronized和Lock保证每个时刻是有一个线程执行同步代码,相当于是让线程顺序执行同步代码,自然就保证了有序性。
另外,Java内存模型具备一些先天的“有序性”,即不需要通过任何手段就能够得到保证的有序性,这个通常也称为 happens-before 原则。如果两个操作的执行次序无法从happens-before原则推导出来,那么它们就不能保证它们的有序性,虚拟机可以随意地对它们进行重排序。
下面就来具体介绍下happens-before原则(先行发生原则):
- 程序次序规则:一个线程内,按照代码顺序,书写在前面的操作先行发生于书写在后面的操作
- 锁定规则:一个unLock操作先行发生于后面对同一个锁lock操作
- volatile变量规则:对一个变量的写操作先行发生于后面对这个变量的读操作
- 传递规则:如果操作A先行发生于操作B,而操作B又先行发生于操作C,则可以得出操作A先行发生于操作C
- 线程启动规则:Thread对象的start()方法先行发生于此线程的每个一个动作
- 线程中断规则:对线程interrupt()方法的调用先行发生于被中断线程的代码检测到中断事件的发生
- 线程终结规则:线程中所有的操作都先行发生于线程的终止检测,我们可以通过Thread.join()方法结束、Thread.isAlive()的返回值手段检测到线程已经终止执行
- 对象终结规则:一个对象的初始化完成先行发生于他的finalize()方法的开始
这8条原则摘自《深入理解Java虚拟机》。
这8条规则中,前4条规则是比较重要的,后4条规则都是显而易见的。
下面我们来解释一下前4条规则:
对于程序次序规则来说,我的理解就是一段程序代码的执行在单个线程中看起来是有序的。注意,虽然这条规则中提到“书写在前面的操作先行发生于书写在后面的操作”,这个应该是程序看起来执行的顺序是按照代码顺序执行的,因为虚拟机可能会对程序代码进行指令重排序。虽然进行重排序,但是最终执行的结果是与程序顺序执行的结果一致的,它只会对不存在数据依赖性的指令进行重排序。因此,在单个线程中,程序执行看起来是有序执行的,这一点要注意理解。事实上,这个规则是用来保证程序在单线程中执行结果的正确性,但无法保证程序在多线程中执行的正确性。
第二条规则也比较容易理解,也就是说无论在单线程中还是多线程中,同一个锁如果出于被锁定的状态,那么必须先对锁进行了释放操作,后面才能继续进行lock操作。
第三条规则是一条比较重要的规则,也是后文将要重点讲述的内容。直观地解释就是,如果一个线程先去写一个变量,然后一个线程去进行读取,那么写入操作肯定会先行发生于读操作。
第四条规则实际上就是体现happens-before原则具备传递性。
8.4 深入剖析volatile关键字
在前面讲述了很多东西,其实都是为讲述volatile关键字作铺垫,那么接下来我们就进入主题。
1.volatile关键字的两层语义
一旦一个共享变量(类的成员变量、类的静态成员变量)被volatile修饰之后,那么就具备了两层语义:
1)保证了不同线程对这个变量进行操作时的可见性,即一个线程修改了某个变量的值,这新值对其他线程来说是立即可见的。
2)禁止进行指令重排序。
先看一段代码,假如线程1先执行,线程2后执行:
//线程1boolean stop = false;while(!stop){doSomething();}//线程2stop = true;
这段代码是很典型的一段代码,很多人在中断线程时可能都会采用这种标记办法。但是事实上,这段代码会完全运行正确么?即一定会将线程中断么?不一定,也许在大多数时候,这个代码能够把线程中断,但是也有可能会导致无法中断线程(虽然这个可能性很小,但是只要一旦发生这种情况就会造成死循环了)。
下面解释一下这段代码为何有可能导致无法中断线程。在前面已经解释过,每个线程在运行过程中都有自己的工作内存,那么线程1在运行的时候,会将stop变量的值拷贝一份放在自己的工作内存当中。
那么当线程2更改了stop变量的值之后,但是还没来得及写入主存当中,线程2转去做其他事情了,那么线程1由于不知道线程2对stop变量的更改,因此还会一直循环下去。
但是用volatile修饰之后就变得不一样了:
第一:使用volatile关键字会强制将修改的值立即写入主存;
第二:使用volatile关键字的话,当线程2进行修改时,会导致线程1的工作内存中缓存变量stop的缓存行无效(反映到硬件层的话,就是CPU的L1或者L2缓存中对应的缓存行无效);
第三:由于线程1的工作内存中缓存变量stop的缓存行无效,所以线程1再次读取变量stop的值时会去主存读取。
那么在线程2修改stop值时(当然这里包括2个操作,修改线程2工作内存中的值,然后将修改后的值写入内存),会使得线程1的工作内存中缓存变量stop的缓存行无效,然后线程1读取时,发现自己的缓存行无效,它会等待缓存行对应的主存地址被更新之后,然后去对应的主存读取最新的值。
那么线程1读取到的就是最新的正确的值。
2.volatile保证原子性吗?
从上面知道volatile关键字保证了操作的可见性,但是volatile能保证对变量的操作是原子性吗?
下面看一个例子:
public class Test {public volatile int inc = 0;public void increase() {inc++;}public static void main(String[] args) {final Test test = new Test();for(int i=0;i<10;i++){new Thread(){public void run() {for(int j=0;j<1000;j++)test.increase();};}.start();}while(Thread.activeCount()>1) //保证前面的线程都执行完Thread.yield();System.out.println(test.inc);}}
大家想一下这段程序的输出结果是多少?也许有些朋友认为是10000。但是事实上运行它会发现每次运行结果都不一致,都是一个小于10000的数字。
可能有的朋友就会有疑问,不对啊,上面是对变量inc进行自增操作,由于volatile保证了可见性,那么在每个线程中对inc自增完之后,在其他线程中都能看到修改后的值啊,所以有10个线程分别进行了1000次操作,那么最终inc的值应该是1000*10=10000。
这里面就有一个误区了,volatile关键字能保证可见性没有错,但是上面的程序错在没能保证原子性。可见性只能保证每次读取的是最新的值,但是volatile没办法保证对变量的操作的原子性。
在前面已经提到过,自增操作是不具备原子性的,它包括读取变量的原始值、进行加1操作、写入工作内存。那么就是说自增操作的三个子操作可能会分割开执行,就有可能导致下面这种情况出现:
假如某个时刻变量inc的值为10,
线程1对变量进行自增操作,线程1先读取了变量inc的原始值,然后线程1被阻塞了;
然后线程2对变量进行自增操作,线程2也去读取变量inc的原始值,由于线程1只是对变量inc进行读取操作,而没有对变量进行修改操作,所以不会导致线程2的工作内存中缓存变量inc的缓存行无效,所以线程2会直接去主存读取inc的值,发现inc的值时10,然后进行加1操作,并把11写入工作内存,最后写入主存。
然后线程1接着进行加1操作,由于已经读取了inc的值,注意此时在线程1的工作内存中inc的值仍然为10,所以线程1对inc进行加1操作后inc的值为11,然后将11写入工作内存,最后写入主存。
那么两个线程分别进行了一次自增操作后,inc只增加了1。
解释到这里,可能有朋友会有疑问,不对啊,前面不是保证一个变量在修改volatile变量时,会让缓存行无效吗?然后其他线程去读就会读到新的值,对,这个没错。这个就是上面的happens-before规则中的volatile变量规则,但是要注意,线程1对变量进行读取操作之后,被阻塞了的话,并没有对inc值进行修改。然后虽然volatile能保证线程2对变量inc的值读取是从内存中读取的,但是线程1没有进行修改,所以线程2根本就不会看到修改的值。
根源就在这里,自增操作不是原子性操作,而且volatile也无法保证对变量的任何操作都是原子性的。:
在java 1.5的java.util.concurrent.atomic包下提供了一些原子操作类,即对基本数据类型的 自增(加1操作),自减(减1操作)、以及加法操作(加一个数),减法操作(减一个数)进行了封装,保证这些操作是原子性操作。atomic是利用CAS来实现原子性操作的(Compare And Swap),CAS实际上是利用处理器提供的CMPXCHG指令实现的,而处理器执行CMPXCHG指令是一个原子性操作。
3.volatile能保证有序性吗?
在前面提到volatile关键字能禁止指令重排序,所以volatile能在一定程度上保证有序性。
volatile关键字禁止指令重排序有两层意思:
1)当程序执行到volatile变量的读操作或者写操作时,在其前面的操作的更改肯定全部已经进行,且结果已经对后面的操作可见;在其后面的操作肯定还没有进行;
2)在进行指令优化时,不能将在对volatile变量访问的语句放在其后面执行,也不能把volatile变量后面的语句放到其前面执行。
可能上面说的比较绕,举个简单的例子:
//x、y为非volatile变量//flag为volatile变量x = 2; //语句1y = 0; //语句2flag = true; //语句3x = 4; //语句4y = -1; //语句5
由于flag变量为volatile变量,那么在进行指令重排序的过程的时候,不会将语句3放到语句1、语句2前面,也不会讲语句3放到语句4、语句5后面。但是要注意语句1和语句2的顺序、语句4和语句5的顺序是不作任何保证的。
并且volatile关键字能保证,执行到语句3时,语句1和语句2必定是执行完毕了的,且语句1和语句2的执行结果对语句3、语句4、语句5是可见的。
那么我们回到前面举的一个例子:
//线程1:context = loadContext(); //语句1inited = true; //语句2//线程2:while(!inited ){sleep()}doSomethingwithconfig(context);
前面举这个例子的时候,提到有可能语句2会在语句1之前执行,那么久可能导致context还没被初始化,而线程2中就使用未初始化的context去进行操作,导致程序出错。
这里如果用volatile关键字对inited变量进行修饰,就不会出现这种问题了,因为当执行到语句2时,必定能保证context已经初始化完毕。
4.volatile的原理和实现机制
前面讲述了源于volatile关键字的一些使用,下面我们来探讨一下volatile到底如何保证可见性和禁止指令重排序的。
下面这段话摘自《深入理解Java虚拟机》:
“观察加入volatile关键字和没有加入volatile关键字时所生成的汇编代码发现,加入volatile关键字时,会多出一个lock前缀指令”
lock前缀指令实际上相当于一个内存屏障(也成内存栅栏),内存屏障会提供3个功能:
1)它确保指令重排序时不会把其后面的指令排到内存屏障之前的位置,也不会把前面的指令排到内存屏障的后面;即在执行到内存屏障这句指令时,在它前面的操作已经全部完成;
2)它会强制将对缓存的修改操作立即写入主存;
3)如果是写操作,它会导致其他CPU中对应的缓存行无效。
8.5 使用volatile关键字的场景
synchronized关键字是防止多个线程同时执行一段代码,那么就会很影响程序执行效率,而volatile关键字在某些情况下性能要优于synchronized,但是要注意volatile关键字是无法替代synchronized关键字的,因为volatile关键字无法保证操作的原子性。通常来说,使用volatile必须具备以下2个条件:
1)对变量的写操作不依赖于当前值
2)该变量没有包含在具有其他变量的不变式中
实际上,这些条件表明,可以被写入 volatile 变量的这些有效值独立于任何程序的状态,包括变量的当前状态。
事实上,我的理解就是上面的2个条件需要保证操作是原子性操作,才能保证使用volatile关键字的程序在并发时能够正确执行。
下面列举几个Java中使用volatile的几个场景。
1.状态标记量
volatile boolean flag = false;while(!flag){doSomething();}public void setFlag() {flag = true;}
volatile boolean inited = false;//线程1:context = loadContext();inited = true;//线程2:while(!inited ){sleep()}doSomethingwithconfig(context);
2.double check
class Singleton{private volatile static Singleton instance = null;private Singleton() {}public static Singleton getInstance() {if(instance==null) {synchronized (Singleton.class) {if(instance==null)instance = new Singleton();}}return instance;}}
至于为何需要这么写请参考:
《Java 中的双重检查(Double-Check)》https://www.cnblogs.com/whalefalles/p/11264439.html
和http://www.iteye.com/topic/652440
参考资料:
《Java编程思想》
《深入理解Java虚拟机》
http://jiangzhengjun.iteye.com/blog/652532
http://blog.sina.com.cn/s/blog_7bee8dd50101fu8n.html
http://blog.csdn.net/ccit0519/article/details/11241403
http://blog.csdn.net/ns_code/article/details/17101369
http://www.cnblogs.com/kevinwu/archive/2012/05/02/2479464.html
http://www.cppblog.com/elva/archive/2011/01/21/139019.html
http://ifeve.com/volatile-array-visiblity/
http://www.bdqn.cn/news/201312/12579.shtml
http://exploer.blog.51cto.com/7123589/1193399
http://www.cnblogs.com/Mainz/p/3556430.html
9 垃圾回收
原博客【https://blog.csdn.net/laomo_bible/article/details/83112622】
也可以参考【https://blog.csdn.net/hao134838/article/details/103344650】
垃圾收集 Garbage Collection 通常被称为“GC”,本文详细讲述Java垃圾回收机制。
导读:
1、什么是GC
2、GC常用算法
3、垃圾收集器
4、finalize()方法详解
5、总结—根据GC原理来优化代码
正式阅读之前需要了解相关概念:
Java 堆内存分为新生代和老年代,新生代中又分为1个 Eden 区域 和 2个 Survivor 区域。
一、什么是GC:
每个程序员都遇到过内存溢出的情况,程序运行时,内存空间是有限的,那么如何及时的把不再使用的对象清除将内存释放出来,这就是GC要做的事。
理解GC机制就从:“GC的区域在哪里”,“GC的对象是什么”,“GC的时机是什么”,“GC做了哪些事”几方面来分析。
1、需要GC的内存区域
jvm 中,程序计数器、虚拟机栈、本地方法栈都是随线程而生随线程而灭,栈帧随着方法的进入和退出做入栈和出栈操作,实现了自动的内存清理,因此,我们的内存垃圾回收主要集中于 java 堆和方法区中,在程序运行期间,这部分内存的分配和使用都是动态的。

2、GC的对象
需要进行回收的对象就是已经没有存活的对象,判断一个对象是否存活常用的有两种办法:引用计数和可达分析。
(1)引用计数:每个对象有一个引用计数属性,新增一个引用时计数加1,引用释放时计数减1,计数为0时可以回收。此方法简单,无法解决对象相互循环引用的问题。
(2)可达性分析(Reachability Analysis):从GC Roots开始向下搜索,搜索所走过的路径称为引用链。当一个对象到GC Roots没有任何引用链相连时,则证明此对象是不可用的。不可达对象。
在Java语言中,GC Roots包括:
虚拟机栈中引用的对象。
方法区中类静态属性实体引用的对象。
方法区中常量引用的对象。
本地方法栈中JNI引用的对象。
3、什么时候触发GC
(1)程序调用System.gc时可以触发
(2)系统自身来决定GC触发的时机(根据Eden区和From Space区的内存大小来决定。当内存大小不足时,则会启动GC线程并停止应用线程)
GC又分为 minor GC 和 Full GC (也称为 Major GC )
Minor GC触发条件:当Eden区满时,触发Minor GC。
Full GC触发条件:
a.调用System.gc时,系统建议执行Full GC,但是不必然执行
b.老年代空间不足
c.方法区空间不足
d.通过Minor GC后进入老年代的平均大小大于老年代的可用内存
e.由Eden区、From Space区向To Space区复制时,对象大小大于To Space可用内存,则把该对象转存到老年代,且老年代的可用内存小于该对象大小
4、GC做了什么事
主要做了清理对象,整理内存的工作。Java堆分为新生代和老年代,采用了不同的回收方式。(回收方式即回收算法详见后文)
二、GC常用算法
GC常用算法有:标记-清除算法,标记-压缩算法,复制算法,分代收集算法。
目前主流的JVM(HotSpot)采用的是分代收集算法。
1、标记-清除算法
标记清除(Mark-Sweep)算法,包含“标记”和“清除”两个阶段:首先标记出所有需要回收的对象,在标记完成后统一回收掉所有被标记的对象。
标记清除算法是最基础的收集算法,后续的收集算法都是基于该思路并对其缺点进行改进而得到的。

主要缺点:一个是效率问题,标记和清除过程的效率都不高;另外是空间问题,标记清除之后会产生大量不连续的内存碎片,空间碎片太多可能会导致,当程序在以后的运行过程中需要分配较大对象时无法找到足够的连续内存而不得不提前触发另一次垃圾收集动作。
2、复制算法
该算法将内存平均分成两部分,然后每次只使用其中的一部分,当这部分内存满的时候,将内存中所有存活的对象复制到另一个内存中,然后将之前的内存清空,只使用这部分内存,循环下去。

看下面的就知道 从from和to两个空间换来换去。
每次对半区内存回收时、内存分配时就不用考虑内存碎片等复杂情况,只要移动堆顶指针,按顺序分配内存即可,实现简单,运行高效。
缺点:将内存缩小为一半,性价比低,持续复制长生存期的对象则导致效率低下。
JVM堆中新生代便采用复制算法。回到最初推分配结构图。

在GC回收过程中,当Eden区满时,还存活的对象会被复制到其中一个Survivor区;当回收时,会将Eden和使用的Survivor区还存活的对象,复制到另外一个Survivor区,然后对Eden和用过的Survivor区进行清理。
如果另外一个Survivor区没有足够的内存存储时,则会进入老年代。
这里针对哪些对象会进入老年代有这样的机制:对象每经历一次复制,年龄加1,达到晋升年龄阈值后,转移到老年代。
在这整个过程中,由于Eden中的对象属于像浮萍一样“瞬生瞬灭”的对象,所以并不需要1:1的比例来分配内存,而是采用了8:1:1的比例来分配。
而针对那些像“水熊虫”一样,历经多次清理依旧存活的对象,则会进入老年代,而老年的清理算法则采用下面要讲到的“标记整理算法”。
3、标记-压缩算法(标记-整理)
标记整理(Mark-Compact)算法:标记过程与“标记-清除”算法一样,但后续步骤不是直接对可回收对象进行清理,而是让所有存活的对象都向一端移动,然后直接清理掉端边界以外的内存。

这种算法不既不用浪费50%的内存,也解决了复制算法在对象存活率较高时的效率低下问题。
4、分代收集算法
现在的虚拟机垃圾收集大多采用这种方式,它根据对象的生存周期,将堆分为新生代(Young)和老年代(Tenure)。在新生代中,由于对象生存期短,每次回收都会有大量对象死去,那么这时就采用复制算法。老年代里的对象存活率较高,没有额外的空间进行分配担保,所以可以使用标记-整理 或者 标记-清除。
具体过程:新生代(Young)分为Eden区,From区与To区

当系统创建一个对象的时候,总是在Eden区操作,当这个区满了,那么就会触发一次YoungGC,也就是年轻代的垃圾回收。一般来说这时候不是所有的对象都没用了,所以就会把还能用的对象复制到From区。

这样整个Eden区就被清理干净了,可以继续创建新的对象,当Eden区再次被用完,就再触发一次YoungGC,然后呢,注意,这个时候跟刚才稍稍有点区别。这次触发YoungGC后,会将Eden区与From区还在被使用的对象复制到To区,

再下一次YoungGC的时候,则是将Eden区与To区中的还在被使用的对象复制到From区。

经过若干次YoungGC后,有些对象在From与To之间来回游荡,这时候From区与To区亮出了底线(阈值),这些家伙要是到现在还没挂掉,对不起,一起滚到(复制)老年代吧。

老年代经过这么几次折腾,也就扛不住了(空间被用完),好,那就来次集体大扫除(Full GC),也就是全量回收。如果Full GC使用太频繁的话,无疑会对系统性能产生很大的影响。所以要合理设置年轻代与老年代的大小,尽量减少Full GC的操作。
三、垃圾收集器
如果说收集算法是内存回收的方法论,垃圾收集器就是内存回收的具体实现
1.Serial收集器
串行收集器是最古老,最稳定以及效率高的收集器
可能会产生较长的停顿,只使用一个线程去回收
-XX:+UseSerialGC
- 新生代、老年代使用串行回收
- 新生代复制算法
- 老年代标记-压缩

2.并行收集器
2.1 ParNew
-XX:+UseParNewGC(new代表新生代,所以适用于新生代)
- 新生代并行
- 老年代串行
Serial收集器新生代的并行版本
在新生代回收时使用复制算法
多线程,需要多核支持
-XX:ParallelGCThreads 限制线程数量

2.2 Parallel收集器
类似ParNew
新生代复制算法
老年代标记-压缩
更加关注吞吐量
-XX:+UseParallelGC
- 使用Parallel收集器+ 老年代串行
-XX:+UseParallelOldGC
- 使用Parallel收集器+ 老年代并行

2.3 其他GC参数
-XX:MaxGCPauseMills
- 最大停顿时间,单位毫秒
- GC尽力保证回收时间不超过设定值
-XX:GCTimeRatio
- 0-100的取值范围
- 垃圾收集时间占总时间的比
- 默认99,即最大允许1%时间做GC
这两个参数是矛盾的。因为停顿时间和吞吐量不可能同时调优
3. CMS收集器
- Concurrent Mark Sweep 并发标记清除(应用程序线程和GC线程交替执行)
- 使用标记-清除算法
- 并发阶段会降低吞吐量(停顿时间减少,吞吐量降低)
- 老年代收集器(新生代使用ParNew)
- -XX:+UseConcMarkSweepGC
CMS运行过程比较复杂,着重实现了标记的过程,可分为
- 初始标记(会产生全局停顿)
- 根可以直接关联到的对象
- 速度快
- 并发标记(和用户线程一起)
- 主要标记过程,标记全部对象
- 重新标记 (会产生全局停顿)
- 由于并发标记时,用户线程依然运行,因此在正式清理前,再做修正
- 并发清除(和用户线程一起)
- 基于标记结果,直接清理对象

这里就能很明显的看出,为什么CMS要使用标记清除而不是标记压缩,如果使用标记压缩,需要多对象的内存位置进行改变,这样程序就很难继续执行。但是标记清除会产生大量内存碎片,不利于内存分配。
CMS收集器特点:
尽可能降低停顿
会影响系统整体吞吐量和性能
- 比如,在用户线程运行过程中,分一半CPU去做GC,系统性能在GC阶段,反应速度就下降一半
清理不彻底
- 因为在清理阶段,用户线程还在运行,会产生新的垃圾,无法清理
因为和用户线程一起运行,不能在空间快满时再清理(因为也许在并发GC的期间,用户线程又申请了大量内存,导致内存不够)
- -XX:CMSInitiatingOccupancyFraction设置触发GC的阈值
- 如果不幸内存预留空间不够,就会引起concurrent mode failure
一旦 concurrent mode failure产生,将使用串行收集器作为后备。
CMS也提供了整理碎片的参数:
-XX:+ UseCMSCompactAtFullCollection Full GC后,进行一次整理
- 整理过程是独占的,会引起停顿时间变长
-XX:+CMSFullGCsBeforeCompaction
- 设置进行几次Full GC后,进行一次碎片整理
-XX:ParallelCMSThreads
- 设定CMS的线程数量(一般情况约等于可用CPU数量)
CMS的提出是想改善GC的停顿时间,在GC过程中的确做到了减少GC时间,但是同样导致产生大量内存碎片,又需要消耗大量时间去整理碎片,从本质上并没有改善时间。
4. G1收集器
G1是目前技术发展的最前沿成果之一,HotSpot开发团队赋予它的使命是未来可以替换掉JDK1.5中发布的CMS收集器。
与CMS收集器相比G1收集器有以下特点:
(1) 空间整合,G1收集器采用标记整理算法,不会产生内存空间碎片。分配大对象时不会因为无法找到连续空间而提前触发下一次GC。
(2)可预测停顿,这是G1的另一大优势,降低停顿时间是G1和CMS的共同关注点,但G1除了追求低停顿外,还能建立可预测的停顿时间模型,能让使用者明确指定在一个长度为N毫秒的时间片段内,消耗在垃圾收集上的时间不得超过N毫秒,这几乎已经是实时Java(RTSJ)的垃圾收集器的特征了。
上面提到的垃圾收集器,收集的范围都是整个新生代或者老年代,而G1不再是这样。使用G1收集器时,Java堆的内存布局与其他收集器有很大差别,它将整个Java堆划分为多个大小相等的独立区域(Region),虽然还保留有新生代和老年代的概念,但新生代和老年代不再是物理隔阂了,它们都是一部分(可以不连续)Region的集合。
G1的新生代收集跟ParNew类似,当新生代占用达到一定比例的时候,开始出发收集。
和CMS类似,G1收集器收集老年代对象会有短暂停顿。
步骤:
(1)标记阶段,首先初始标记(Initial-Mark),这个阶段是停顿的(Stop the World Event),并且会触发一次普通Mintor GC。对应GC log:GC pause (young) (inital-mark)
(2)Root Region Scanning,程序运行过程中会回收survivor区(存活到老年代),这一过程必须在young GC之前完成。
(3)Concurrent Marking,在整个堆中进行并发标记(和应用程序并发执行),此过程可能被young GC中断。在并发标记阶段,若发现区域对象中的所有对象都是垃圾,那个这个区域会被立即回收(图中打X)。同时,并发标记过程中,会计算每个区域的对象活性(区域中存活对象的比例)。

(4)Remark, 再标记,会有短暂停顿(STW)。再标记阶段是用来收集 并发标记阶段 产生新的垃圾(并发阶段和应用程序一同运行);G1中采用了比CMS更快的初始快照算法:snapshot-at-the-beginning (SATB)。
(5)Copy/Clean up,多线程清除失活对象,会有STW。G1将回收区域的存活对象拷贝到新区域,清除Remember Sets,并发清空回收区域并把它返回到空闲区域链表中。

(6)复制/清除过程后。回收区域的活性对象已经被集中回收到深蓝色和深绿色区域。
5 ZGC
ZGC 收集器是 JDK 11 中新增的垃圾收集器,它是由 Oracle 官方开发的,并且支持 TB 级别的堆内存管理,而且 ZGC 收集器也非常高效,可以做到 10ms 以内完成垃圾收集。
在 ZGC 收集器中没有新生代和老生代的概念,它只有一代。ZGC 收集器采用的着色指针技术,利用指针中多余的信息位来实现着色标记,并且 ZGC 使用了读屏障来解决 GC 线程和应用线程可能存在的并发(修改对象状态的)问题,从而避免了Stop The World(全局停顿),因此使得 GC 的性能大幅提升。
ZGC 的执行流程和 CMS 比较相似,首先是进行 GC Roots 标记,然后再通过指针进行并发着色标记,之后便是对标记为死亡的对象进行回收(被标记为橘色的对象),最后是重定位,将 GC 之后存活的对象进行移动,以解决内存碎片的问题。
四、finalize()方法详解
1. finalize的作用
(1)finalize()是Object的protected方法,子类可以覆盖该方法以实现资源清理工作,GC在回收对象之前调用该方法。
(2)finalize()与C中的析构函数不是对应的。C中的析构函数调用的时机是确定的(对象离开作用域或delete掉),但Java中的finalize的调用具有不确定性
(3)不建议用finalize方法完成“非内存资源”的清理工作,但建议用于:① 清理本地对象(通过JNI创建的对象);② 作为确保某些非内存资源(如Socket、文件等)释放的一个补充:在finalize方法中显式调用其他资源释放方法。其原因可见下文[finalize的问题]
2. finalize的问题
(1)一些与finalize相关的方法,由于一些致命的缺陷,已经被废弃了,如System.runFinalizersOnExit()方法、Runtime.runFinalizersOnExit()方法
(2)System.gc()与System.runFinalization()方法增加了finalize方法执行的机会,但不可盲目依赖它们
(3)Java语言规范并不保证finalize方法会被及时地执行、而且根本不会保证它们会被执行
(4)finalize方法可能会带来性能问题。因为JVM通常在单独的低优先级线程中完成finalize的执行
(5)对象再生问题:finalize方法中,可将待回收对象赋值给GC Roots可达的对象引用,从而达到对象再生的目的
(6)finalize方法至多由GC执行一次(用户当然可以手动调用对象的finalize方法,但并不影响GC对finalize的行为)
3. finalize的执行过程(生命周期)
(1) 首先,大致描述一下finalize流程:当对象变成(GC Roots)不可达时,GC会判断该对象是否覆盖了finalize方法,若未覆盖,则直接将其回收。否则,若对象未执行过finalize方法,将其放入F-Queue队列,由一低优先级线程执行该队列中对象的finalize方法。执行finalize方法完毕后,GC会再次判断该对象是否可达,若不可达,则进行回收,否则,对象“复活”。
(2) 具体的finalize流程:
对象可由两种状态,涉及到两类状态空间,一是终结状态空间 F = {unfinalized, finalizable, finalized};二是可达状态空间 R = {reachable, finalizer-reachable, unreachable}。各状态含义如下:
- unfinalized: 新建对象会先进入此状态,GC并未准备执行其finalize方法,因为该对象是可达的
- finalizable: 表示GC可对该对象执行finalize方法,GC已检测到该对象不可达。正如前面所述,GC通过F-Queue队列和一专用线程完成finalize的执行
- finalized: 表示GC已经对该对象执行过finalize方法
- reachable: 表示GC Roots引用可达
- finalizer-reachable(f-reachable):表示不是reachable,但可通过某个finalizable对象可达
- unreachable:对象不可通过上面两种途径可达
状态变迁图:

变迁说明:
(1)新建对象首先处于[reachable, unfinalized]状态(A)
(2)随着程序的运行,一些引用关系会消失,导致状态变迁,从reachable状态变迁到f-reachable(B, C, D)或unreachable(E, F)状态
(3)若JVM检测到处于unfinalized状态的对象变成f-reachable或unreachable,JVM会将其标记为finalizable状态(G,H)。若对象原处于[unreachable, unfinalized]状态,则同时将其标记为f-reachable(H)。
(4)在某个时刻,JVM取出某个finalizable对象,将其标记为finalized并在某个线程中执行其finalize方法。由于是在活动线程中引用了该对象,该对象将变迁到(reachable, finalized)状态(K或J)。该动作将影响某些其他对象从f-reachable状态重新回到reachable状态(L, M, N)
(5)处于finalizable状态的对象不能同时是unreahable的,由第4点可知,将对象finalizable对象标记为finalized时会由某个线程执行该对象的finalize方法,致使其变成reachable。这也是图中只有八个状态点的原因
(6)程序员手动调用finalize方法并不会影响到上述内部标记的变化,因此JVM只会至多调用finalize一次,即使该对象“复活”也是如此。程序员手动调用多少次不影响JVM的行为
(7)若JVM检测到finalized状态的对象变成unreachable,回收其内存(I)
(8)若对象并未覆盖finalize方法,JVM会进行优化,直接回收对象(O)
(9)注:System.runFinalizersOnExit()等方法可以使对象即使处于reachable状态,JVM仍对其执行finalize方法
五、总结
根据GC的工作原理,我们可以通过一些技巧和方式,让GC运行更加有效率,更加符合应用程序的要求。一些关于程序设计的几点建议:
1.最基本的建议就是尽早释放无用对象的引用。大多数程序员在使用临时变量的时候,都是让引用变量在退出活动域(scope)后,自动设置为 null.我们在使用这种方式时候,必须特别注意一些复杂的对象图,例如数组,队列,树,图等,这些对象之间有相互引用关系较为复杂。对于这类对象,GC 回收它们一般效率较低。如果程序允许,尽早将不用的引用对象赋为null.这样可以加速GC的工作。
2.尽量少用finalize函数。finalize函数是Java提供给程序员一个释放对象或资源的机会。但是,它会加大GC的工作量,因此尽量少采用finalize方式回收资源。
3.如果需要使用经常使用的图片,可以使用soft应用类型。它可以尽可能将图片保存在内存中,供程序调用,而不引起OutOfMemory.
4.注意集合数据类型,包括数组,树,图,链表等数据结构,这些数据结构对GC来说,回收更为复杂。另外,注意一些全局的变量,以及一些静态变量。这些变量往往容易引起悬挂对象(dangling reference),造成内存浪费。
5.当程序有一定的等待时间,程序员可以手动执行System.gc(),通知GC运行,但是Java语言规范并不保证GC一定会执行。使用增量式GC可以缩短Java程序的暂停时间。
大对象直接进入老年代?
大对象就是需要大量连续内存空间的对象(比如:字符串、数组)。
为什么要这样呢?
为了避免为大对象分配内存时由于分配担保机制带来的复制而降低效率。
如何判断一个类是无用的类?
方法区主要回收的是无用的类,那么如何判断一个类是无用的类的呢?
判定一个常量是否是“废弃常量”比较简单,而要判定一个类是否是“无用的类”的条件则相对苛刻许多。类需要同时满足下面 3 个条件才能算是 “无用的类” :
- 该类所有的实例都已经被回收,也就是 Java 堆中不存在该类的任何实例。
- 加载该类的
ClassLoader已经被回收。 - 该类对应的
java.lang.Class对象没有在任何地方被引用,无法在任何地方通过反射访问该类的方法。
虚拟机可以对满足上述 3 个条件的无用类进行回收,这里说的仅仅是“可以”,而并不是和对象一样不使用了就会必然被回收。
不可达的对象并非“非死不可”
即使在可达性分析法中不可达的对象,也并非是“非死不可”的,这时候它们暂时处于“缓刑阶段”,要真正宣告一个对象死亡,至少要经历两次标记过程;可达性分析法中不可达的对象被第一次标记并且进行一次筛选,筛选的条件是此对象是否有必要执行 finalize 方法。当对象没有覆盖 finalize 方法,或 finalize 方法已经被虚拟机调用过时,虚拟机将这两种情况视为没有必要执行。
被判定为需要执行的对象将会被放在一个队列中进行第二次标记,除非这个对象与引用链上的任何一个对象建立关联,否则就会被真的回收。
10 线程池
【https://www.cnblogs.com/captainad/p/10943091.html】
定时任务 延时对垒DelayedWorkQueue分析(最小堆的利用)【https://blog.csdn.net/nobody_1/article/details/99684009】
10.1 使用线程池的好处
池化技术相比大家已经屡见不鲜了,线程池、数据库连接池、Http 连接池等等都是对这个思想的应用。池化技术的思想主要是为了减少每次获取资源的消耗,提高对资源的利用率。
线程池提供了一种限制和管理资源(包括执行一个任务)。 每个线程池还维护一些基本统计信息,例如已完成任务的数量。
这里借用《Java 并发编程的艺术》提到的来说一下使用线程池的好处:
- 降低资源消耗。通过重复利用已创建的线程降低线程创建和销毁造成的消耗。
- 提高响应速度。当任务到达时,任务可以不需要的等到线程创建就能立即执行。
- 提高线程的可管理性。线程是稀缺资源,如果无限制的创建,不仅会消耗系统资源,还会降低系统的稳定性,使用线程池可以进行统一的分配,调优和监控。
10.2 处理流程

当提交一个新任务到线程池时,线程池的处理流程如下
- 线程池判断核心线程池里是的线程是否都在执行任务,如果不是,则创建一个新的工作线程来执行任务。如果核心线程池里的线程都在执行任务,则进入下一个流程
- 线程池判断工作队列是否已满。如果工作队列没有满,则将新提交的任务储存在这个工作队列里。如果工作队列满了,则进入下一个流程。
- 线程池判断其内部线程是否都处于工作状态。如果没有,则创建一个新的工作线程来执行任务。如果已满了,则交给饱和策略来处理这个任务。
线程池在执行excute()方法时,主要有以下四种情况:

1、如果当前运行的线程少于corePoolSize,则创建新线程来执行任务(需要获得全局锁);
2、如果运行的线程等于或多于corePoolSize ,则将任务加入BlockingQueue;
3、如果无法将任务加入BlockingQueue(队列已满并且正在运行的线程数量小于 maximumPoolSize),则创建新的线程来处理任务(需要获得全局锁)
4、如果创建新线程将使当前运行的线程超出maxiumPoolSize(队列已满并且正在运行的线程数量大于或等于 maximumPoolSize),任务将被拒绝,并调用RejectedExecutionHandler.rejectedExecution()方法(线程池会抛出异常,告诉调用者”我不能再接受任务了”);
线程池采取上述的流程进行设计是为了减少获取全局锁的次数。在线程池完成预热(当前运行的线程数大于或等于corePoolSize)之后,几乎所有的excute方法调用都执行步骤2;
5、当一个线程完成任务时,它会从队列中取下一个任务来执行;
6、当一个线程无事可做,超过一定的时间(keepAliveTime)时,线程池会判断,如果当前运行的线程数大于 corePoolSize,那么这个线程就被停掉。所以线程池的所有任务完成后,它最终会收缩到 corePoolSize 的大小
任务的管理是一件比较容易的事,复杂的是线程的管理,这会涉及线程数量、等待/唤醒、同步/锁、线程创建和死亡等问题。ThreadPoolExecutor与线程相关的几个成员变量是:keepAliveTime、allowCoreThreadTimeOut、poolSize、corePoolSize、maximumPoolSize,它们共同负责线程的创建和销毁。
10.3 主要属性
corePoolSize:
核心线程池大小,即在没有任务需要执行的时候线程池的大小,并且只有在工作队列满了的情况下才会创建超出这个数量的线程。这里需要注意的是:在刚刚创建ThreadPoolExecutor的时候,线程并不会立即创建,而是要等到有任务提交时才会创建,除非调用了prestartCoreThread/prestartAllCoreThreads事先创建核心线程。再考虑到keepAliveTime和allowCoreThreadTimeOut超时参数(executor.allowCoreThreadTimeOut(true))的影响,所以没有任务需要执行的时候,线程池的大小不一定是corePoolSize。
maximumPoolSize:
线程池中允许创建的最大线程数,线程池中的当前线程数目不会超过该值。如果队列中任务已满,并且当前线程个数(poolSize)小于maximumPoolSize,那么会创建新的线程来执行任务。这里值得一提的是largestPoolSize,该变量记录了线程池在整个生命周期中曾经出现的最大线程个数。为什么说是曾经呢?因为线程池创建之后,可以调用setMaximumPoolSize()改变运行的最大线程的数目。
poolSize:
线程池中当前线程的数量,当该值为0的时候,意味着没有任何线程,线程池会终止;同一时刻,poolSize不会超过maximumPoolSize。
其他常见参数:
keepAliveTime:当线程池中的线程数量大于corePoolSize的时候,如果这时没有新的任务提交,核心线程外的线程不会立即销毁,而是会等待,直到等待的时间超过了keepAliveTime才会被回收销毁;unit:keepAliveTime参数的时间单位。threadFactory:executor 创建新线程的时候会用到。handler:饱和策略。关于饱和策略下面单独介绍一下。
10.4 Executors创建线程池的弊端
Executors 返回线程池对象的弊端如下:
FixedThreadPool和SingleThreadExecutor: 允许请求的队列长度为 Integer.MAX_VALUE,可能堆积大量的请求,从而导致 OOM。因为队列使用的是链表结构。- CachedThreadPool 和 ScheduledThreadPool : 允许创建的线程数量为 Integer.MAX_VALUE ,可能会创建大量线程,从而导致 OOM。
10.5 原理分析
execute方法:
public void execute(Runnable command) {if (command == null)throw new NullPointerException();int c = ctl.get();// 当前工作的线程数小于核心线程数if (workerCountOf(c) < corePoolSize) {// 创建新的线程执行此任务if (addWorker(command, true))return;c = ctl.get();}// 检查线程池是否处于运行状态,如果是则把任务添加到队列if (isRunning(c) && workQueue.offer(command)) {int recheck = ctl.get();// 再出检查线程池是否处于运行状态,防止在第一次校验通过后线程池关闭// 如果是非运行状态,则将刚加入队列的任务移除if (! isRunning(recheck) && remove(command))reject(command);// 如果线程池的线程数为 0 时(当 corePoolSize 设置为 0 时会发生)else if (workerCountOf(recheck) == 0)addWorker(null, false); // 新建线程执行任务}// 核心线程都在忙且队列都已爆满,尝试新启动一个线程执行失败else if (!addWorker(command, false))// 执行拒绝策略reject(command);}
其中 addWorker(Runnable firstTask, boolean core) 方法的参数说明如下:
- firstTask,线程应首先运行的任务,如果没有则可以设置为 null;
- core,判断是否可以创建线程的阀值(最大值),如果等于 true 则表示使用 corePoolSize 作为阀值,false 则表示使用 maximumPoolSize 作为阀值。
10.6 知识扩展
execute() VS submit()
execute() 和 submit() 都是用来执行线程池任务的,它们最主要的区别是,submit() 方法可以接收线程池执行的返回值,而 execute() 不能接收返回值。
ThreadPoolExecutor executor = new ThreadPoolExecutor(2, 10, 10L,TimeUnit.SECONDS, new LinkedBlockingQueue(20));// execute 使用executor.execute(new Runnable() {@Overridepublic void run() {System.out.println("Hello, execute.");}});// submit 使用Future<String> future = executor.submit(new Callable<String>() {@Overridepublic String call() throws Exception {System.out.println("Hello, submit.");return "Success";}});System.out.println(future.get());
从以上结果可以看出 submit() 方法可以配合 Futrue 来接收线程执行的返回值。它们的另一个区别是 execute() 方法属于 Executor 接口的方法,而 submit() 方法则是属于 ExecutorService 接口的方法
线程池的拒绝策略
当线程池中的任务队列已经被存满,再有任务添加时会先判断当前线程池中的线程数是否大于等于线程池的最大值,如果是,则会触发线程池的拒绝策略。
Java 自带的拒绝策略有 4 种:
- AbortPolicy,终止策略,线程池会抛出异常并终止执行,它是默认的拒绝策略;但是不会影响前面线程的执行。正在执行的任务不会终止,当拒绝策略使用默认的 AbortPolicy 时,当有任务执行不过来时,新增的这个任务会终止执行,其他的任务还会继续执行
- CallerRunsPolicy,把任务交给当前线程来执行;
- DiscardPolicy,忽略此任务(最新的任务);
- DiscardOldestPolicy,忽略最早的任务(最先加入队列的任务)。
ThreadPoolExecutor executor = new ThreadPoolExecutor(1, 3, 10,TimeUnit.SECONDS, new LinkedBlockingQueue<>(2),new ThreadPoolExecutor.AbortPolicy()); // 添加 AbortPolicy 拒绝策略for (int i = 0; i < 6; i++) {executor.execute(() -> {System.out.println(Thread.currentThread().getName());});}
以上程序的执行结果:
pool-1-thread-1pool-1-thread-1pool-1-thread-1pool-1-thread-3pool-1-thread-2Exception in thread "main" java.util.concurrent.RejectedExecutionException: Task com.lagou.interview.ThreadPoolExample$$Lambda$1/1096979270@448139f0 rejected from java.util.concurrent.ThreadPoolExecutor@7cca494b[Running, pool size = 3, active threads = 3, queued tasks = 2, completed tasks = 0]at java.util.concurrent.ThreadPoolExecutor$AbortPolicy.rejectedExecution(ThreadPoolExecutor.java:2063)at java.util.concurrent.ThreadPoolExecutor.reject(ThreadPoolExecutor.java:830)at java.util.concurrent.ThreadPoolExecutor.execute(ThreadPoolExecutor.java:1379)at com.lagou.interview.ThreadPoolExample.rejected(ThreadPoolExample.java:35)at com.lagou.interview.ThreadPoolExample.main(ThreadPoolExample.java:26)
可以看出当第 6 个任务来的时候,线程池则执行了 AbortPolicy 拒绝策略,抛出了异常。因为队列最多存储 2 个任务,最大可以创建 3 个线程来执行任务(2+3=5),所以当第 6 个任务来的时候,此线程池就“忙”不过来
自定义拒绝策略
自定义拒绝策略只需要新建一个 RejectedExecutionHandler 对象,然后重写它的 rejectedExecution() 方法即可,如下代码所示:
ThreadPoolExecutor executor = new ThreadPoolExecutor(1, 3, 10,TimeUnit.SECONDS, new LinkedBlockingQueue<>(2),new RejectedExecutionHandler() { // 添加自定义拒绝策略@Overridepublic void rejectedExecution(Runnable r, ThreadPoolExecutor executor) {// 业务处理方法System.out.println("执行自定义拒绝策略");}});for (int i = 0; i < 6; i++) {executor.execute(() -> {System.out.println(Thread.currentThread().getName());});}
ThreadPoolExecutor 扩展
ThreadPoolExecutor 的扩展主要是通过重写它的 beforeExecute() 和 afterExecute() 方法实现的,我们可以在扩展方法中添加日志或者实现数据统计,比如统计线程的执行时间,如下代码所示:
public class ThreadPoolExtend {public static void main(String[] args) throws ExecutionException, InterruptedException {// 线程池扩展调用MyThreadPoolExecutor executor = new MyThreadPoolExecutor(2, 4, 10,TimeUnit.SECONDS, new LinkedBlockingQueue());for (int i = 0; i < 3; i++) {executor.execute(() -> {Thread.currentThread().getName();});}}/*** 线程池扩展*/static class MyThreadPoolExecutor extends ThreadPoolExecutor {// 保存线程执行开始时间private final ThreadLocal<Long> localTime = new ThreadLocal<>();public MyThreadPoolExecutor(int corePoolSize, int maximumPoolSize, long keepAliveTime,TimeUnit unit, BlockingQueue<Runnable> workQueue) {super(corePoolSize, maximumPoolSize, keepAliveTime, unit, workQueue);}/*** 开始执行之前* @param t 线程* @param r 任务*/@Overrideprotected void beforeExecute(Thread t, Runnable r) {Long sTime = System.nanoTime(); // 开始时间 (单位:纳秒)localTime.set(sTime);System.out.println(String.format("%s | before | time=%s",t.getName(), sTime));super.beforeExecute(t, r);}/*** 执行完成之后* @param r 任务* @param t 抛出的异常*/@Overrideprotected void afterExecute(Runnable r, Throwable t) {Long eTime = System.nanoTime(); // 结束时间 (单位:纳秒)Long totalTime = eTime - localTime.get(); // 执行总时间System.out.println(String.format("%s | after | time=%s | 耗时:%s 毫秒",Thread.currentThread().getName(), eTime, (totalTime / 1000000.0)));super.afterExecute(r, t);}}}
执行结果:
pool-1-thread-1 | before | time=4570298843700pool-1-thread-2 | before | time=4570298840000pool-1-thread-1 | after | time=4570327059500 | 耗时:28.2158 毫秒pool-1-thread-2 | after | time=4570327138100 | 耗时:28.2981 毫秒pool-1-thread-1 | before | time=4570328467800pool-1-thread-1 | after | time=4570328636800 | 耗时:0.169 毫秒
小结
最后我们总结一下:线程池的使用必须要通过 ThreadPoolExecutor 的方式来创建,这样才可以更加明确线程池的运行规则,规避资源耗尽的风险。同时,也介绍了 ThreadPoolExecutor 的七大核心参数,包括核心线程数和最大线程数之间的区别,当线程池的任务队列没有可用空间且线程池的线程数量已经达到了最大线程数时,则会执行拒绝策略,Java 自动的拒绝策略有 4 种,用户也可以通过重写 rejectedExecution() 来自定义拒绝策略,我们还可以通过重写 beforeExecute() 和 afterExecute() 来实现 ThreadPoolExecutor 的扩展功能。
11 线程的状态有哪些?它是如何工作的?
线程(Thread)是并发编程的基础,也是程序执行的最小单元,它依托进程而存在。一个进程中可以包含多个线程,多线程可以共享一块内存空间和一组系统资源,因此线程之间的切换更加节省资源、更加轻量化,也因此被称为轻量级的进程。
看源码就知道有哪些状态:
public enum State {/*** 新建状态,线程被创建出来,但尚未启动时的线程状态*/NEW,/*** 就绪状态,表示可以运行的线程状态,但它在排队等待来自操作系统的 CPU 资源*/RUNNABLE,/*** 阻塞等待锁的线程状态,表示正在处于阻塞状态的线程* 正在等待监视器锁,比如等待执行 synchronized 代码块或者* 使用 synchronized 标记的方法*/BLOCKED,/*** 等待状态,一个处于等待状态的线程正在等待另一个线程执行某个特定的动作。* 例如,一个线程调用了 Object.wait() 它在等待另一个线程调用* Object.notify() 或 Object.notifyAll()*/WAITING,/*** 计时等待状态,和等待状态 (WAITING) 类似,只是多了超时时间,比如* 调用了有超时时间设置的方法 Object.wait(long timeout) 和* Thread.join(long timeout) 就会进入此状态*/TIMED_WAITING,/*** 终止状态,表示线程已经执行完成*/TERMINATED;}
线程的工作模式是,首先先要创建线程并指定线程需要执行的业务方法,然后再调用线程的 start() 方法,此时线程就从 NEW(新建)状态变成了 RUNNABLE(就绪)状态,此时线程会判断要执行的方法中有没有 synchronized 同步代码块,如果有并且其他线程也在使用此锁,那么线程就会变为 BLOCKED(阻塞等待)状态,当其他线程使用完此锁之后,线程会继续执行剩余的方法。
当遇到 Object.wait() 或 Thread.join() 方法时,线程会变为 WAITING(等待状态)状态,如果是带了超时时间的等待方法,那么线程会进入 TIMED_WAITING(计时等待)状态,当有其他线程执行了 notify() 或 notifyAll() 方法之后,线程被唤醒继续执行剩余的业务方法,直到方法执行完成为止,此时整个线程的流程就执行完了,执行流程如下图所示:
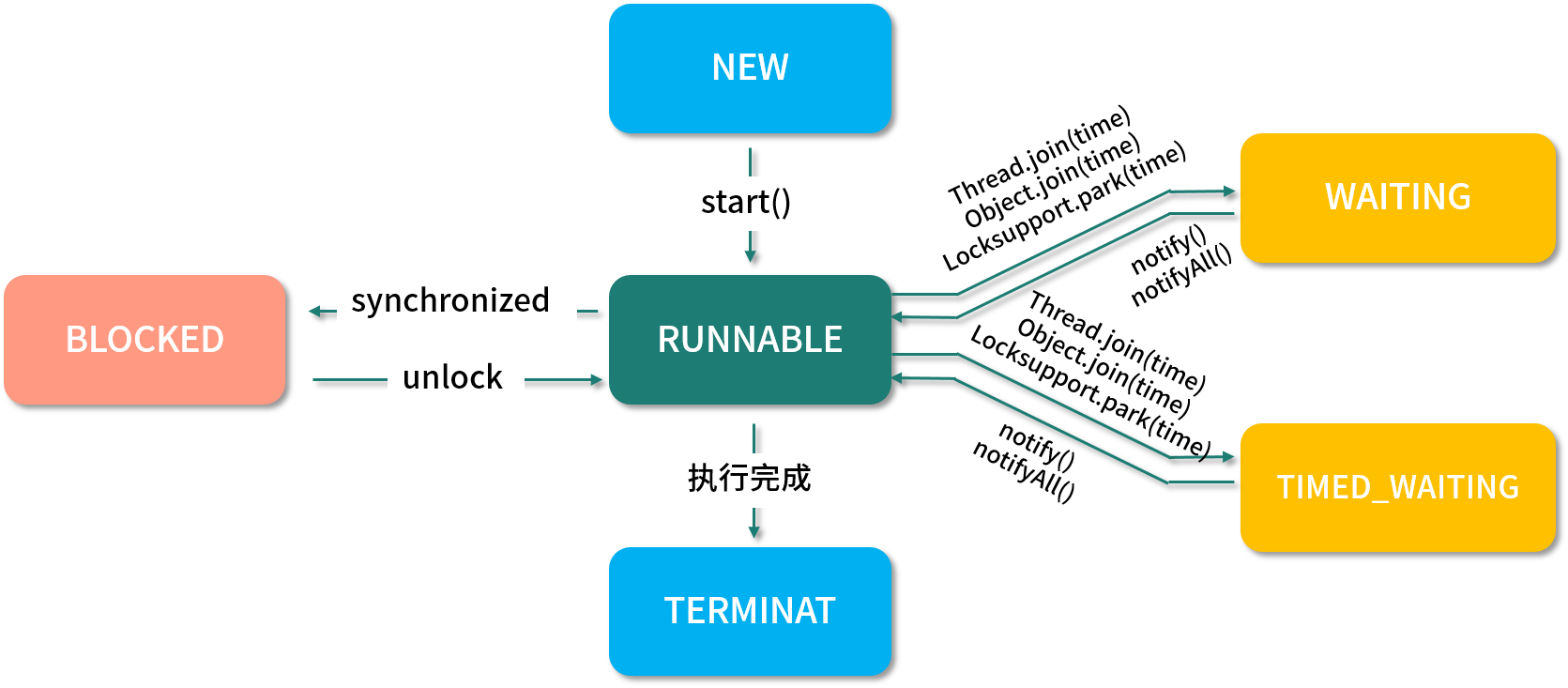
扩展知识:
1.BLOCKED 和 WAITING 的区别
虽然 BLOCKED 和 WAITING 都有等待的含义,但二者有着本质的区别,首先它们状态形成的调用方法不同,其次 BLOCKED 可以理解为当前线程还处于活跃状态,只是在阻塞等待其他线程使用完某个锁资源;而 WAITING 则是因为自身调用了 Object.wait() 或着是 Thread.join() 又或者是 LockSupport.park() 而进入等待状态,只能等待其他线程执行某个特定的动作才能被继续唤醒,比如当线程因为调用了 Object.wait() 而进入 WAITING 状态之后,则需要等待另一个线程执行 Object.notify() 或 Object.notifyAll() 才能被唤醒。
2.start() 和 run() 的区别
首先从 Thread 源码来看,start() 方法属于 Thread 自身的方法,并且使用了 synchronized 来保证线程安全,源码如下:
复制代码
public synchronized void start() {// 状态验证,不等于 NEW 的状态会抛出异常if (threadStatus != 0)throw new IllegalThreadStateException();// 通知线程组,此线程即将启动group.add(this);boolean started = false;try {start0();started = true;} finally {try {if (!started) {group.threadStartFailed(this);}} catch (Throwable ignore) {// 不处理任何异常,如果 start0 抛出异常,则它将被传递到调用堆栈上}}}
run() 方法为 Runnable 的抽象方法,必须由调用类重写此方法,重写的 run() 方法其实就是此线程要执行的业务方法,源码如下:
复制代码
public class Thread implements Runnable {// 忽略其他方法......private Runnable target;@Overridepublic void run() {if (target != null) {target.run();}}}@FunctionalInterfacepublic interface Runnable {public abstract void run();}
从执行的效果来说,start() 方法可以开启多线程,让线程从 NEW 状态转换成 RUNNABLE 状态,而 run() 方法只是一个普通的方法。
其次,它们可调用的次数不同,start() 方法不能被多次调用,否则会抛出 java.lang.IllegalStateException;而 run() 方法可以进行多次调用,因为它只是一个普通的方法而已。
3.线程优先级
在 Thread 源码中和线程优先级相关的属性有 3 个:
复制代码
// 线程可以拥有的最小优先级public final static int MIN_PRIORITY = 1;// 线程默认优先级public final static int NORM_PRIORITY = 5;// 线程可以拥有的最大优先级public final static int MAX_PRIORITY = 10
线程的优先级可以理解为线程抢占 CPU 时间片的概率,优先级越高的线程优先执行的概率就越大,但并不能保证优先级高的线程一定先执行。
在程序中我们可以通过 Thread.setPriority() 来设置优先级,setPriority() 源码如下:
复制代码
public final void setPriority(int newPriority) {ThreadGroup g;checkAccess();// 先验证优先级的合理性if (newPriority > MAX_PRIORITY || newPriority < MIN_PRIORITY) {throw new IllegalArgumentException();}if((g = getThreadGroup()) != null) {// 优先级如果超过线程组的最高优先级,则把优先级设置为线程组的最高优先级if (newPriority > g.getMaxPriority()) {newPriority = g.getMaxPriority();}setPriority0(priority = newPriority);}}
4.线程的常用方法
线程的常用方法有以下几个。
(1)join()
在一个线程中调用 other.join() ,这时候当前线程会让出执行权给 other 线程,直到 other 线程执行完或者过了超时时间之后再继续执行当前线程,join() 源码如下:
复制代码
public final synchronized void join(long millis)throws InterruptedException {long base = System.currentTimeMillis();long now = 0;// 超时时间不能小于 0if (millis < 0) {throw new IllegalArgumentException("timeout value is negative");}// 等于 0 表示无限等待,直到线程执行完为之if (millis == 0) {// 判断子线程 (其他线程) 为活跃线程,则一直等待while (isAlive()) {wait(0);}} else {// 循环判断while (isAlive()) {long delay = millis - now;if (delay <= 0) {break;}wait(delay);now = System.currentTimeMillis() - base;}}}
从源码中可以看出 join() 方法底层还是通过 wait() 方法来实现的。
例如,在未使用 join() 时,代码如下:
复制代码
public class ThreadExample {public static void main(String[] args) throws InterruptedException {Thread thread = new Thread(() -> {for (int i = 1; i < 6; i++) {try {Thread.sleep(1000);} catch (InterruptedException e) {e.printStackTrace();}System.out.println("子线程睡眠:" + i + "秒。");}});thread.start(); // 开启线程// 主线程执行for (int i = 1; i < 4; i++) {try {Thread.sleep(1000);} catch (InterruptedException e) {e.printStackTrace();}System.out.println("主线程睡眠:" + i + "秒。");}}}
程序执行结果为:
复制代码
主线程睡眠:1秒。子线程睡眠:1秒。主线程睡眠:2秒。子线程睡眠:2秒。主线程睡眠:3秒。子线程睡眠:3秒。子线程睡眠:4秒。子线程睡眠:5秒。
从结果可以看出,在未使用 join() 时主子线程会交替执行。
然后我们再把 join() 方法加入到代码中,代码如下:
复制代码
public class ThreadExample {public static void main(String[] args) throws InterruptedException {Thread thread = new Thread(() -> {for (int i = 1; i < 6; i++) {try {Thread.sleep(1000);} catch (InterruptedException e) {e.printStackTrace();}System.out.println("子线程睡眠:" + i + "秒。");}});thread.start(); // 开启线程thread.join(2000); // 等待子线程先执行 2 秒钟// 主线程执行for (int i = 1; i < 4; i++) {try {Thread.sleep(1000);} catch (InterruptedException e) {e.printStackTrace();}System.out.println("主线程睡眠:" + i + "秒。");}}}
程序执行结果为:
复制代码
子线程睡眠:1秒。子线程睡眠:2秒。// thread.join(2000); 等待 2 秒之后,主线程和子线程再交替执行主线程睡眠:1秒。子线程睡眠:3秒。主线程睡眠:2秒。子线程睡眠:4秒。子线程睡眠:5秒。主线程睡眠:3秒。
从执行结果可以看出,添加 join() 方法之后,主线程会先等子线程执行 2 秒之后才继续执行。
(2)yield()
看 Thread 的源码可以知道 yield() 为本地方法,也就是说 yield() 是由 C 或 C++ 实现的,源码如下:
复制代码
public static native void yield();
yield() 方法表示给线程调度器一个当前线程愿意出让 CPU 使用权的暗示,但是线程调度器可能会忽略这个暗示。
比如我们执行这段包含了 yield() 方法的代码,如下所示:
复制代码
public static void main(String[] args) throws InterruptedException {Runnable runnable = new Runnable() {@Overridepublic void run() {for (int i = 0; i < 10; i++) {System.out.println("线程:" +Thread.currentThread().getName() + " I:" + i);if (i == 5) {Thread.yield();}}}};Thread t1 = new Thread(runnable, "T1");Thread t2 = new Thread(runnable, "T2");t1.start();t2.start();}
当我们把这段代码执行多次之后会发现,每次执行的结果都不相同,这是因为 yield() 执行非常不稳定,线程调度器不一定会采纳 yield() 出让 CPU 使用权的建议,从而导致了这样的结果。
小结
本课时我们介绍了线程的 6 种状态以及线程的执行流程,还介绍了 BLOCKED(阻塞等待)和 WAITING(等待)的区别,start() 方法和 run() 方法的区别,以及 join() 方法和 yield() 方法的作用,但我们不能死记硬背,要多动手实践才能真正的理解这些知识点。
12 JVM
【https://blog.csdn.net/sinat_42483341/category_10210903.html】
常见面试题:
- 介绍下 Java 内存区域(运行时数据区)
- Java 对象的创建过程(五步,建议能默写出来并且要知道每一步虚拟机做了什么)
- 对象的访问定位的两种方式(句柄和直接指针两种方式)
扩展问题:
- String 类和常量池
- 8 种基本类型的包装类和常量池
12.1 运行时数据区域

线程私有的:
- 程序计数器
- 虚拟机栈
- 本地方法栈
线程共享的:
- 堆
- 方法区
- 直接内存 (非运行时数据区的一部分)
程序计数器
程序计数器是一块较小的内存空间,可以看作是当前线程所执行的字节码的行号指示器。字节码解释器工作时通过改变这个计数器的值来选取下一条需要执行的字节码指令,分支、循环、跳转、异常处理、线程恢复等功能都需要依赖这个计数器来完成。
另外,为了线程切换后能恢复到正确的执行位置,每条线程都需要有一个独立的程序计数器,各线程之间计数器互不影响,独立存储,我们称这类内存区域为“线程私有”的内存。
从上面的介绍中我们知道程序计数器主要有两个作用:
- 字节码解释器通过改变程序计数器来依次读取指令,从而实现代码的流程控制,如:顺序执行、选择、循环、异常处理。
- 在多线程的情况下,程序计数器用于记录当前线程执行的位置,从而当线程被切换回来的时候能够知道该线程上次运行到哪儿了。
注意:程序计数器是唯一一个不会出现 OutOfMemoryError 的内存区域,它的生命周期随着线程的创建而创建,随着线程的结束而死亡。
虚拟机栈
与程序计数器一样,Java 虚拟机栈也是线程私有的,它的生命周期和线程相同,描述的是 Java 方法执行的内存模型,每次方法调用的数据都是通过栈传递的。
Java 内存可以粗糙的区分为堆内存(Heap)和栈内存 (Stack),其中栈就是现在说的虚拟机栈,或者说是虚拟机栈中局部变量表部分。 (实际上,Java 虚拟机栈是由一个个栈帧组成,而每个栈帧中都拥有:局部变量表、操作数栈、动态链接、方法出口信息。)
局部变量表主要存放了编译期可知的各种数据类型(boolean、byte、char、short、int、float、long、double)、对象引用(reference 类型,它不同于对象本身,可能是一个指向对象起始地址的引用指针,也可能是指向一个代表对象的句柄或其他与此对象相关的位置)。
Java 虚拟机栈会出现两种错误:StackOverFlowError 和 OutOfMemoryError。
StackOverFlowError: 若 Java 虚拟机栈的内存大小不允许动态扩展,那么当线程请求栈的深度超过当前 Java 虚拟机栈的最大深度的时候,就抛出 StackOverFlowError 错误。OutOfMemoryError: 若 Java 虚拟机堆中没有空闲内存,并且垃圾回收器也无法提供更多内存的话。就会抛出 OutOfMemoryError 错误。
Java 虚拟机栈也是线程私有的,每个线程都有各自的 Java 虚拟机栈,而且随着线程的创建而创建,随着线程的死亡而死亡。
扩展:那么方法/函数如何调用?
Java 栈可用类比数据结构中栈,Java 栈中保存的主要内容是栈帧,每一次函数调用都会有一个对应的栈帧被压入 Java 栈,每一个函数调用结束后,都会有一个栈帧被弹出。
Java 方法有两种返回方式:
- return 语句。
- 抛出异常。
不管哪种返回方式都会导致栈帧被弹出。
本地方法栈
和虚拟机栈所发挥的作用非常相似,区别是: 虚拟机栈为虚拟机执行 Java 方法 (也就是字节码)服务,而本地方法栈则为虚拟机使用到的 Native 方法服务。 在 HotSpot 虚拟机中和 Java 虚拟机栈合二为一。
本地方法被执行的时候,在本地方法栈也会创建一个栈帧,用于存放该本地方法的局部变量表、操作数栈、动态链接、出口信息。
方法执行完毕后相应的栈帧也会出栈并释放内存空间,也会出现 StackOverFlowError 和 OutOfMemoryError 两种错误。
堆
Java 虚拟机所管理的内存中最大的一块,Java 堆是所有线程共享的一块内存区域,在虚拟机启动时创建。此内存区域的唯一目的就是存放对象实例,几乎所有的对象实例以及数组都在这里分配内存。
Java世界中“几乎”所有的对象都在堆中分配,但是,随着JIT编译期的发展与逃逸分析技术逐渐成熟,栈上分配、标量替换优化技术将会导致一些微妙的变化,所有的对象都分配到堆上也渐渐变得不那么“绝对”了。从jdk 1.7开始已经默认开启逃逸分析,如果某些方法中的对象引用没有被返回或者未被外面使用(也就是未逃逸出去),那么对象可以直接在栈上分配内存。
在《Java虚拟机规范》中对Java堆的描述是:“所有 的对象实例以及数组都应当在堆上分配”,而这里笔者写的“几乎”是指从实现角度来看,随着Java语 言的发展,现在已经能看到些许迹象表明日后可能出现值类型的支持,即使只考虑现在,由于即时编 译技术的进步,尤其是逃逸分析技术的日渐强大,栈上分配、标量替换优化手段已经导致一些微妙 的变化悄然发生,所以说Java对象实例都分配在堆上也渐渐变得不是那么绝对了。
通过逃逸分析可以让变量或者是对象直接在栈上分配,从而极大地降低了垃圾回收的次数,以及堆分配对象的压力,进而提高了程序的整体运行效率。
Java 堆是垃圾收集器管理的主要区域,因此也被称作GC 堆(Garbage Collected Heap).从垃圾回收的角度,由于现在收集器基本都采用分代垃圾收集算法,所以 Java 堆还可以细分为:新生代和老年代:再细致一点有:Eden 空间、From Survivor、To Survivor 空间等。进一步划分的目的是更好地回收内存,或者更快地分配内存。
新生代:Eden,From,To Eden:From:To默认比列为8:1:1 -XX:SurvivorRatio
老年代
新生代:老年代 默认比列为2:1 -XX:NewRatio
大部分情况,对象都会首先在 Eden 区域分配,在一次新生代垃圾回收后,如果对象还存活,则会进入 s0 或者 s1,并且对象的年龄还会加 1(Eden 区->Survivor 区后对象的初始年龄变为 1)。Hotspot遍历所有对象时,按照年龄从小到大对其所占用的大小进行累积,当累积的某个年龄大小超过了survivor区的一半时,取这个年龄和MaxTenuringThreshold中更小的一个值,作为新的晋升年龄阈值。-XX:MaxTenuringThreshold设置值
动态年龄计算的代码如下uint ageTable::compute_tenuring_threshold(size_t survivor_capacity) {//survivor_capacity是survivor空间的大小size_t desired_survivor_size = (size_t)((((double) survivor_capacity)*TargetSurvivorRatio)/100);size_t total = 0;uint age = 1;while (age < table_size) {total += sizes[age];//sizes数组是每个年龄段对象大小if (total > desired_survivor_size) break;age++;}uint result = age < MaxTenuringThreshold ? age : MaxTenuringThreshold;...}
堆这里最容易出现的就是 OutOfMemoryError 错误,并且出现这种错误之后的表现形式还会有几种,比如:
OutOfMemoryError: GC Overhead Limit Exceeded: 当JVM花太多时间执行垃圾回收并且只能回收很少的堆空间时,就会发生此错误。java.lang.OutOfMemoryError: Java heap space:假如在创建新的对象时, 堆内存中的空间不足以存放新创建的对象, 就会引发java.lang.OutOfMemoryError: Java heap space错误。(和本机物理内存无关,和你配置的内存大小有关!
方法区
方法区与 Java 堆一样,是各个线程共享的内存区域,它用于存储已被虚拟机加载的类信息、常量、静态变量、即时编译器编译后的代码等数据。虽然 Java 虚拟机规范把方法区描述为堆的一个逻辑部分,但是它却有一个别名叫做 Non-Heap(非堆),目的应该是与 Java 堆区分开来。
方法区也被称为永久代。很多人都会分不清方法区和永久代的关系,为此我也查阅了文献。
《Java 虚拟机规范》只是规定了有方法区这么个概念和它的作用,并没有规定如何去实现它。那么,在不同的 JVM 上方法区的实现肯定是不同的了。 方法区和永久代的关系很像 Java 中接口和类的关系,类实现了接口,而永久代就是 HotSpot 虚拟机对虚拟机规范中方法区的一种实现方式。 也就是说,永久代是 HotSpot 的概念,方法区是 Java 虚拟机规范中的定义,是一种规范,而永久代是一种实现,一个是标准一个是实现,其他的虚拟机实现并没有永久代这一说法。
JDK 1.8 之前永久代还没被彻底移除的时候通常通过下面这些参数来调节方法区大小
-XX:PermSize=N //方法区 (永久代) 初始大小-XX:MaxPermSize=N //方法区 (永久代) 最大大小,超过这个值将会抛出 OutOfMemoryError 异常:java.lang.OutOfMemoryError: PermGen
相对而言,垃圾收集行为在这个区域是比较少出现的,但并非数据进入方法区后就“永久存在”了。
JDK 1.8 的时候,方法区(HotSpot 的永久代)被彻底移除了(JDK1.7 就已经开始了),取而代之是元空间,元空间使用的是直接内存。
下面是一些常用参数:
-XX:MetaspaceSize=N //设置 Metaspace 的初始(和最小大小)-XX:MaxMetaspaceSize=N //设置 Metaspace 的最大大小
与永久代很大的不同就是,如果不指定大小的话,随着更多类的创建,虚拟机会耗尽所有可用的系统内存。
为什么要将永久代 (PermGen) 替换为元空间 (MetaSpace) 呢?
1.字符串存在永久代中,容易出现性能问题和内存溢出。
2.永久代会为 GC 带来不必要的复杂度,并且回收效率偏低。
3.在 JDK8,合并 HotSpot 和 JRockit 的代码时, JRockit 从来没有一个叫永久代的东西, 合并之后就没有必要额外的设置这么一个永久代的地方了。
4.整个永久代有一个 JVM 本身设置固定大小上限,无法进行调整,而元空间使用的是直接内存,受本机可用内存的限制,虽然元空间仍旧可能溢出,但是比原来出现的几率会更小。
运行时常量池
运行时常量池是方法区的一部分。Class 文件中除了有类的版本、字段、方法、接口等描述信息外,还有常量池表用于存放编译期生成的各种字面量与符号引用,这部分内容将在类加载后存放到方法区的运行时常量池中。
既然运行时常量池是方法区的一部分,自然受到方法区内存的限制,当常量池无法再申请到内存时会抛出 OutOfMemoryError 错误。
- JDK1.7之前运行时常量池逻辑包含字符串常量池存放在方法区, 此时hotspot虚拟机对方法区的实现为永久代
- JDK1.7 字符串常量池,静态变量被从方法区拿到了堆中, 这里没有提到运行时常量池,也就是说字符串常量池被单独拿到堆,运行时常量池剩下的东西还在方法区, 也就是hotspot中的永久代 。(字符串常量池底层实现其实是c++的HashMap)。
- JDK1.8 hotspot移除了永久代用元空间(Metaspace)取而代之, 这时候字符串常量池,静态变量还在堆, 运行时常量池还在方法区, 只不过方法区的实现从永久代变成了元空间(Metaspace)
直接内存
直接内存并不是虚拟机运行时数据区的一部分,也不是虚拟机规范中定义的内存区域,但是这部分内存也被频繁地使用。而且也可能导致 OutOfMemoryError 错误出现。
JDK1.4 中新加入的 NIO(New Input/Output) 类,引入了一种基于通道(Channel) 与缓存区(Buffer) 的 I/O 方式,它可以直接使用 Native 函数库直接分配堆外内存,然后通过一个存储在 Java 堆中的 DirectByteBuffer 对象作为这块内存的引用进行操作。这样就能在一些场景中显著提高性能,因为避免了在 Java 堆和 Native 堆之间来回复制数据。
显然,本机直接内存的分配不会受到Java堆大小的限制,但是,既然是内存,则肯定还是会受到 本机总内存(包括物理内存、SWAP分区或者分页文件)大小以及处理器寻址空间的限制,一般服务 器管理员配置虚拟机参数时,会根据实际内存去设置-Xmx等参数信息,但经常忽略掉直接内存,使得 各个内存区域总和大于物理内存限制(包括物理的和操作系统级的限制),从而导致动态扩展时出现 OutOfMemoryError异常。
12.2 HotSpot虚拟机对象探秘
对象创建

Step1:类加载检查
虚拟机遇到一条 new 指令时,首先将去检查这个指令的参数是否能在常量池中定位到这个类的符号引用,并且检查这个符号引用代表的类是否已被加载过、解析和初始化过。如果没有,那必须先执行相应的类加载过程。(new ,clone,反射,反序列化)。
Step2:分配内存
在类加载检查通过后,接下来虚拟机将为新生对象分配内存。对象所需的内存大小在类加载完成后便可确定,为对象分配空间的任务等同于把一块确定大小的内存从 Java 堆中划分出来。分配方式有 “指针碰撞” 和 “空闲列表” 两种,选择哪种分配方式由 Java 堆是否规整决定,而 Java 堆是否规整又由所采用的垃圾收集器是否带有压缩整理功能决定。
内存分配的两种方式:(补充内容,需要掌握)
选择以上两种方式中的哪一种,取决于 Java 堆内存是否规整。而 Java 堆内存是否规整,取决于 GC 收集器的算法是”标记-清除”,还是”标记-整理”(也称作”标记-压缩”),值得注意的是,复制算法内存也是规整的

内存分配并发问题(补充内容,需要掌握)
在创建对象的时候有一个很重要的问题,就是线程安全,因为在实际开发过程中,创建对象是很频繁的事情,即使仅仅修改一个指针所指向的位置,在并发情况下也并不是线程安全的,可能出现正在给对象 A分配内存,指针还没来得及修改,对象B又同时使用了原来的指针来分配内存的情况。作为虚拟机来说,必须要保证线程是安全的,通常来讲,虚拟机采用两种方式来保证线程安全:
CAS+失败重试: CAS 是乐观锁的一种实现方式。所谓乐观锁就是,每次不加锁而是假设没有冲突而去完成某项操作,如果因为冲突失败就重试,直到成功为止。虚拟机采用 CAS 配上失败重试的方式保证更新操作的原子性。
TLAB: 为每一个线程预先在 Eden 区分配一块儿内存,JVM 在给线程中的对象分配内存时,首先在 TLAB 分配,当对象大于 TLAB 中的剩余内存或 TLAB 的内存已用尽时,再采用上述的 CAS 进行内存分配
虚拟机是否使用TLAB,可以通过-XX:+/-UseTLAB参数来 设定。
Step3:初始化零值
内存分配完成后,虚拟机需要将分配到的内存空间都初始化为零值(不包括对象头),这一步操作保证了对象的实例字段在 Java 代码中可以不赋初始值就直接使用,程序能访问到这些字段的数据类型所对应的零值。
Step4:设置对象头
初始化零值完成之后,虚拟机要对对象进行必要的设置,例如这个对象是哪个类的实例、如何才能找到类的元数据信息、对象的哈希码、对象的 GC 分代年龄等信息。 这些信息存放在对象头中。 另外,根据虚拟机当前运行状态的不同,如是否启用偏向锁等,对象头会有不同的设置方式。synchronized 就利用了MarkWord做锁的的升级过程。
Step5:执行 init 方法
在上面工作都完成之后,从虚拟机的视角来看,一个新的对象已经产生了,但从 Java 程序的视角来看,对象创建才刚开始,init 方法还没有执行,所有的字段都还为零。所以一般来说,执行 new 指令之后会接着执行 init 方法,把对象按照程序员的意愿进行初始化,这样一个真正可用的对象才算完全产生出来。
对象的内存布局
在 Hotspot 虚拟机中,对象在内存中的布局可以分为 3 块区域:对象头(Header)、实例数据(Instance Data)和对齐填充(Padding)。
HotSpot虚拟机对象的对象头部分包括两类信息。第一类是用于存储对象自身的运行时数据,如哈希码(HashCode)、GC分代年龄、锁状态标志、线程持有的锁、偏向线程ID、偏向时间戳等,这部 分数据的长度在32位和64位的虚拟机(未开启压缩指针)中分别为32个比特和64个比特,官方称它 为“Mark Word”。对象需要存储的运行时数据很多,其实已经超出了32、64位Bitmap结构所能记录的 最大限度,但对象头里的信息是与对象自身定义的数据无关的额外存储成本,考虑到虚拟机的空间效 率,Mark Word被设计成一个有着动态定义的数据结构,以便在极小的空间内存储尽量多的数据,根 据对象的状态复用自己的存储空间。例如在32位的HotSpot虚拟机中,如对象未被同步锁锁定的状态 下,Mark Word的32个比特存储空间中的25个比特用于存储对象哈希码,4个比特用于存储对象分代年 龄,2个比特用于存储锁标志位,1个比特固定为0,在其他状态(轻量级锁定、重量级锁定、GC标 记、可偏向)

对象头的另外一部分是类型指针,即对象指向它的类型元数据的指针,Java虚拟机通过这个指针 来确定该对象是哪个类的实例。并不是所有的虚拟机实现都必须在对象数据上保留类型指针,换句话 说,查找对象的元数据信息并不一定要经过对象本身,这点我们会在下一节具体讨论。此外,如果对 象是一个Java数组,那在对象头中还必须有一块用于记录数组长度的数据,因为虚拟机可以通过普通 Java对象的元数据信息确定Java对象的大小,但是如果数组的长度是不确定的,将无法通过元数据中的 信息推断出数组的大小。
接下来实例数据部分是对象真正存储的有效信息,即我们在程序代码里面所定义的各种类型的字 段内容,无论是从父类继承下来的,还是在子类中定义的字段都必须记录起来。这部分的存储顺序会 受到虚拟机分配策略参数(-XX:FieldsAllocationStyle参数)和字段在Java源码中定义顺序的影响。 HotSpot虚拟机默认的分配顺序为longs/doubles、ints、shorts/chars、bytes/booleans、oops(Ordinary Object Pointers,OOPs),从以上默认的分配策略中可以看到,相同宽度的字段总是被分配到一起存 放,在满足这个前提条件的情况下,在父类中定义的变量会出现在子类之前。如果HotSpot虚拟机的 +XX:CompactFields参数值为true(默认就为true),那子类之中较窄的变量也允许插入父类变量的空 隙之中,以节省出一点点空间。
对象的第三部分是对齐填充,这并不是必然存在的,也没有特别的含义,它仅仅起着占位符的作 用。由于HotSpot虚拟机的自动内存管理系统要求对象起始地址必须是8字节的整数倍,换句话说就是 任何对象的大小都必须是8字节的整数倍。对象头部分已经被精心设计成正好是8字节的倍数(1倍或者 2倍),因此,如果对象实例数据部分没有对齐的话,就需要通过对齐填充来补全。
对象的访问定位
建立对象就是为了使用对象,我们的 Java 程序通过栈上的 reference 数据来操作堆上的具体对象。对象的访问方式由虚拟机实现而定,目前主流的访问方式有①使用句柄和②直接指针两种:
句柄: 如果使用句柄的话,那么 Java 堆中将会划分出一块内存来作为句柄池,reference 中存储的就是对象的句柄地址,而句柄中包含了对象实例数据与类型数据各自的具体地址信息;
A a = new A();
a.method()

直接指针: 如果使用直接指针访问,那么 Java 堆对象的布局中就必须考虑如何放置访问类型数据的相关信息,而 reference 中存储的直接就是对象的地址。
new A().method();

这两种对象访问方式各有优势,使用句柄来访问的最大好处就是reference中存储的是稳定句柄地 址,在对象被移动(垃圾收集时移动对象是非常普遍的行为)时只会改变句柄中的实例数据指针,而 reference本身不需要被修改。
使用直接指针访问方式最大的好处就是速度快,它节省了一次指针定位的时间开销。
12.3 String类和常量池
String 对象的两种创建方式:
String str1 = "abcd";//先检查字符串常量池中有没有"abcd",如果字符串常量池中没有,则创建一个,然后 str1 指向字符串常量池中的对象,如果有,则直接将 str1 指向"abcd"";String str2 = new String("abcd");//堆中创建一个新的对象String str3 = new String("abcd");//堆中创建一个新的对象System.out.println(str1==str2);//falseSystem.out.println(str2==str3);//false
这两种不同的创建方法是有差别的。
- 第一种方式是在常量池中拿对象;
- 第二种方式是直接在堆内存空间创建一个新的对象
记住一点:只要使用 new 方法,便需要创建新的对象。

String 类型的常量池比较特殊。它的主要使用方法有两种:
- 直接使用双引号声明出来的 String 对象会直接存储在常量池中。
- 如果不是用双引号声明的 String 对象,可以使用 String 提供的 intern 方法。String.intern() 是一个 Native 方法,它的作用是:如果运行时常量池中已经包含一个等于此 String 对象内容的字符串,则返回常量池中该字符串的引用;如果没有,JDK1.7之前(不包含1.7)的处理方式是在常量池中创建与此 String 内容相同的字符串,并返回常量池中创建的字符串的引用,JDK1.7以及之后的处理方式是在常量池中记录此字符串的引用,并返回该引用。
String s1 = new String("计算机");String s2 = s1.intern();String s3 = "计算机";System.out.println(s2);//计算机System.out.println(s1 == s2);//false,因为一个是堆内存中的 String 对象一个是常量池中的 String 对象,System.out.println(s3 == s2);//true,因为两个都是常量池中的 String 对象
字符串拼接:
String str1 = "str";String str2 = "ing";String str3 = "str" + "ing";//常量池中的对象String str4 = str1 + str2; //在堆上创建的新的对象String str5 = "string";//常量池中的对象System.out.println(str3 == str4);//falseSystem.out.println(str3 == str5);//trueSystem.out.println(str4 == str5);//false

尽量避免多个字符串拼接,因为这样会重新创建对象。如果需要改变字符串的话,可以使用 StringBuilder 或者 StringBuffer。
String s1 = new String(“abc”);这句话创建了几个字符串对象?
将创建 1 或 2 个字符串。如果池中已存在字符串常量“abc”,则只会在堆空间创建一个字符串常量“abc”。如果池中没有字符串常量“abc”,那么它将首先在池中创建,然后在堆空间中创建,因此将创建总共 2 个字符串对象
String s1 = new String("abc");// 堆内存的地址值String s2 = "abc";System.out.println(s1 == s2);// 输出 false,因为一个是堆内存,一个是常量池的内存,故两者是不同的。System.out.println(s1.equals(s2));// 输出 true
8 种基本类型的包装类和常量池
Java 基本类型的包装类的大部分都实现了常量池技术,即 Byte,Short,Integer,Long,Character,Boolean;前面 4 种包装类默认创建了数值[-128,127] 的相应类型的缓存数据,Character创建了数值在[0,127]范围的缓存数据,Boolean 直接返回True Or False。如果超出对应范围仍然会去创建新的对象。 为啥把缓存设置为[-128,127]区间?(参见issue/461)性能和资源之间的权衡。
public static Boolean valueOf(boolean b) {return (b ? TRUE : FALSE);}
private static class CharacterCache {private CharacterCache(){}static final Character cache[] = new Character[127 + 1];static {for (int i = 0; i < cache.length; i++)cache[i] = new Character((char)i);}}
两种浮点数类型的包装类 Float,Double 并没有实现常量池技术。
Integer i1 = 33;Integer i2 = 33;Integer i3 = Integer.valueOf("33");System.out.println(i1 == i2);// 输出 trueSystem.out.println(i1 == i3);// 输出 trueInteger i11 = 333;Integer i22 = 333;System.out.println(i11 == i22);// 输出 falseDouble i3 = 1.2;Double i4 = 1.2;System.out.println(i3 == i4);// 输出 false
Integer 缓存源代码:
public static Integer valueOf(int i) {if (i >= IntegerCache.low && i <= IntegerCache.high)return IntegerCache.cache[i + (-IntegerCache.low)];return new Integer(i);}
应用场景:
- Integer i1=40;Java 在编译的时候会直接将代码封装成 Integer i1=Integer.valueOf(40);,从而使用常量池中的对象。
- Integer i1 = new Integer(40);这种情况下会创建新的对象。
Integer i1 = 40;Integer i2 = new Integer(40);System.out.println(i1==i2);//输出 false
Integer i1 = 40;Integer i2 = 40;Integer i3 = 0;Integer i4 = new Integer(40);Integer i5 = new Integer(40);Integer i6 = new Integer(0);System.out.println("i1=i2 " + (i1 == i2));System.out.println("i1=i2+i3 " + (i1 == i2 + i3));System.out.println("i1=i4 " + (i1 == i4));System.out.println("i4=i5 " + (i4 == i5));System.out.println("i4=i5+i6 " + (i4 == i5 + i6));System.out.println("40=i5+i6 " + (40 == i5 + i6));
结果
i1=i2 truei1=i2+i3 truei1=i4 falsei4=i5 falsei4=i5+i6 true40=i5+i6 true
解释:
语句 i4 == i5 + i6,因为+这个操作符不适用于 Integer 对象,首先 i5 和 i6 进行自动拆箱操作,进行数值相加,即 i4 == 40。然后 Integer 对象无法与数值进行直接比较,所以 i4 自动拆箱转为 int 值 40,最终这条语句转为 40 == 40 进行数值比较。
深入理解String 【https://tech.meituan.com/2014/03/06/in-depth-understanding-string-intern.html】
13 符号引用和直接引用
在JVM中,类从被加载到虚拟机内存中开始,到卸载出内存为止,它的整个生命周期包括:加载、验证、准备、解析、初始化、使用和卸载7个阶段。而解析阶段即是虚拟机将常量池内的符号引用替换为直接引用的过程。
符号引用(Symbolic References):符号引用以一组符号来描述所引用的目标,符号可以是任何形式的字面量,只要使用时能够无歧义的定位到目标即可。例如,在Class文件中它以CONSTANT_Class_info、CONSTANT_Fieldref_info、CONSTANT_Methodref_info等类型的常量出现。符号引用与虚拟机的内存布局无关,引用的目标并不一定加载到内存中。在Java中,一个java类将会编译成一个class文件。在编译时,java类并不知道所引用的类的实际地址,因此只能使用符号引用来代替。比如org.simple.People类引用了org.simple.Language类,在编译时People类并不知道Language类的实际内存地址,因此只能使用符号org.simple.Language(假设是这个,当然实际中是由类似于CONSTANT_Class_info的常量来表示的)来表示Language类的地址。各种虚拟机实现的内存布局可能有所不同,但是它们能接受的符号引用都是一致的,因为符号引用的字面量形式明确定义在Java虚拟机规范的Class文件格式中。
直接引用: 直接引用可以是
(1)直接指向目标的指针(比如,指向“类型”【Class对象】、类变量、类方法的直接引用可能是指向方法区的指针)
(2)相对偏移量(比如,指向实例变量、实例方法的直接引用都是偏移量)
(3)一个能间接定位到目标的句柄
14 JDK监控和故障处理
JDK 命令行工具
这些命令在 JDK 安装目录下的 bin 目录下:
jps(JVM Process Status): 类似 UNIX 的ps命令。用户查看所有 Java 进程的启动类、传入参数和 Java 虚拟机参数等信息;jstat( JVM Statistics Monitoring Tool): 用于收集 HotSpot 虚拟机各方面的运行数据;jinfo(Configuration Info for Java) : Configuration Info forJava,显示虚拟机配置信息;jmap(Memory Map for Java) :生成堆转储快照;jhat(JVM Heap Dump Browser ) : 用于分析 heapdump 文件,它会建立一个 HTTP/HTML 服务器,让用户可以在浏览器上查看分析结果;jstack(Stack Trace for Java):生成虚拟机当前时刻的线程快照,线程快照就是当前虚拟机内每一条线程正在执行的方法堆栈的集合。- jconsole 可视化窗口监视程序运行时信息
jps:查看所有 Java 进程
jps(JVM Process Status) 命令类似 UNIX 的 ps 命令。
jps:显示虚拟机执行主类名称以及这些进程的本地虚拟机唯一 ID(Local Virtual Machine Identifier,LVMID)。jps -q :只输出进程的本地虚拟机唯一 ID。
C:\Users\SnailClimb>jps7360 NettyClient2173967972 Launcher16504 Jps17340 NettyServer
jps -l:输出主类的全名,如果进程执行的是 Jar 包,输出 Jar 路径。
C:\Users\SnailClimb>jps -l7360 firstNettyDemo.NettyClient2173967972 org.jetbrains.jps.cmdline.Launcher16492 sun.tools.jps.Jps17340 firstNettyDemo.NettyServer
jps -v:输出虚拟机进程启动时 JVM 参数。
jps -m:输出传递给 Java 进程 main() 函数的参数。
jstat: 监视虚拟机各种运行状态信息
jstat(JVM Statistics Monitoring Tool) 使用于监视虚拟机各种运行状态信息的命令行工具。 它可以显示本地或者远程(需要远程主机提供 RMI 支持)虚拟机进程中的类信息、内存、垃圾收集、JIT 编译等运行数据,在没有 GUI,只提供了纯文本控制台环境的服务器上,它将是运行期间定位虚拟机性能问题的首选工具。
jstat 命令使用格式:
jstat -<option> [-t] [-h<lines>] <vmid> [<interval> [<count>]]
比如 jstat -gc -h3 31736 1000 10表示分析进程 id 为 31736 的 gc 情况,每隔 1000ms 打印一次记录,打印 10 次停止,每 3 行后打印指标头部。
常见的 option 如下:
jstat -class vmid:显示 ClassLoader 的相关信息;jstat -compiler vmid:显示 JIT 编译的相关信息;jstat -gc vmid:显示与 GC 相关的堆信息;jstat -gccapacity vmid:显示各个代的容量及使用情况;jstat -gcnew vmid:显示新生代信息;jstat -gcnewcapcacity vmid:显示新生代大小与使用情况;jstat -gcold vmid:显示老年代和永久代的行为统计,从jdk1.8开始,该选项仅表示老年代,因为永久代被移除了;jstat -gcoldcapacity vmid:显示老年代的大小;jstat -gcpermcapacity vmid:显示永久代大小,从jdk1.8开始,该选项不存在了,因为永久代被移除了;jstat -gcutil vmid:显示垃圾收集信息;
另外,加上 -t参数可以在输出信息上加一个 Timestamp 列,显示程序的运行时间。
D:\develop\workspace_idea\hrh-erp>jps11060 Bootstrap21380 ErpAppBoot4036 Launcher10664 Launcher13864 Launcher17432 Jps20620 Launcher8556D:\develop\workspace_idea\hrh-erp>


jinfo: 实时地查看和调整虚拟机各项参数
这里都是copy别人博客的。
jinfo vmid :输出当前 jvm 进程的全部参数和系统属性 (第一部分是系统的属性,第二部分是 JVM 的参数)。
jinfo -flag name vmid :输出对应名称的参数的具体值。比如输出 MaxHeapSize、查看当前 jvm 进程是否开启打印 GC 日志 ( -XX:PrintGCDetails :详细 GC 日志模式,这两个都是默认关闭的)。
C:\Users\SnailClimb>jinfo -flag MaxHeapSize 17340-XX:MaxHeapSize=2124414976C:\Users\SnailClimb>jinfo -flag PrintGC 17340-XX:-PrintGC
使用 jinfo 可以在不重启虚拟机的情况下,可以动态的修改 jvm 的参数。尤其在线上的环境特别有用,请看下面的例子:
jinfo -flag [+|-]name vmid 开启或者关闭对应名称的参数。
C:\Users\SnailClimb>jinfo -flag PrintGC 17340-XX:-PrintGCC:\Users\SnailClimb>jinfo -flag +PrintGC 17340C:\Users\SnailClimb>jinfo -flag PrintGC 17340-XX:+PrintGC
D:\develop\workspace_idea\hrh-erp>jinfo -flag MetaspaceSize 21380-XX:MetaspaceSize=21807104
jmap:生成堆转储快照
jmap(Memory Map for Java)命令用于生成堆转储快照。 如果不使用 jmap 命令,要想获取 Java 堆转储,可以使用 “-XX:+HeapDumpOnOutOfMemoryError” 参数,可以让虚拟机在 OOM 异常出现之后自动生成 dump 文件,Linux 命令下可以通过 kill -3 发送进程退出信号也能拿到 dump 文件。
jmap 的作用并不仅仅是为了获取 dump 文件,它还可以查询 finalizer 执行队列、Java 堆和永久代的详细信息,如空间使用率、当前使用的是哪种收集器等。和jinfo一样,jmap有不少功能在 Windows 平台下也是受限制的。
查看堆信息,jdk11不能用jmap -heap了 8还可以用
D:\develop\jdk\jdk1.8.0_111\bin>jmap -heap 18024Attaching to process ID 18024, please wait...Debugger attached successfully.Server compiler detected.JVM version is 25.111-b14using thread-local object allocation.Parallel GC with 8 thread(s)Heap Configuration:MinHeapFreeRatio = 0MaxHeapFreeRatio = 100MaxHeapSize = 4208984064 (4014.0MB)NewSize = 88080384 (84.0MB)MaxNewSize = 1402994688 (1338.0MB)OldSize = 176160768 (168.0MB)NewRatio = 2SurvivorRatio = 8MetaspaceSize = 21807104 (20.796875MB)CompressedClassSpaceSize = 1073741824 (1024.0MB)MaxMetaspaceSize = 17592186044415 MBG1HeapRegionSize = 0 (0.0MB)Heap Usage:PS Young GenerationEden Space:capacity = 536346624 (511.5MB)used = 104423048 (99.58557891845703MB)free = 431923576 (411.91442108154297MB)19.469321391682705% usedFrom Space:capacity = 11010048 (10.5MB)used = 10994864 (10.485519409179688MB)free = 15184 (0.0144805908203125MB)99.86208961123512% usedTo Space:capacity = 22544384 (21.5MB)used = 0 (0.0MB)free = 22544384 (21.5MB)0.0% usedPS Old Generationcapacity = 198705152 (189.5MB)used = 34805864 (33.193458557128906MB)free = 163899288 (156.3065414428711MB)17.516336969461165% used31307 interned Strings occupying 3265744 bytes.
示例:将指定应用程序的堆快照输出到桌面。后面,可以通过 jhat、Visual VM 等工具分析该堆文件。
C:\Users\buqingyishi>jmap -dump:format=b,file=C:\Users\buqingyishi\Desktop\heap.hprof 21380Dumping heap to C:\Users\buqingyishi\Desktop\heap.hprof ...Heap dump file created
jhat: 分析 heapdump 文件
jhat 用于分析 heapdump 文件,它会建立一个 HTTP/HTML 服务器,让用户可以在浏览器上查看分析结果。
D:\develop\jdk\jdk1.8.0_111\bin>jhat C:\Users\buqingyishi\Desktop\heap.hprofReading from C:\Users\buqingyishi\Desktop\heap.hprof...Dump file created Thu Nov 12 10:23:38 CST 2020Snapshot read, resolving...Resolving 3334676 objects...Chasing references, expect 666 dots..........................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................Eliminating duplicate references..........................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................Snapshot resolved.Started HTTP server on port 7000Server is ready.
jstack :生成虚拟机当前时刻的线程快照
jstack(Stack Trace for Java)命令用于生成虚拟机当前时刻的线程快照。线程快照就是当前虚拟机内每一条线程正在执行的方法堆栈的集合.
生成线程快照的目的主要是定位线程长时间出现停顿的原因,如线程间死锁、死循环、请求外部资源导致的长时间等待等都是导致线程长时间停顿的原因。线程出现停顿的时候通过jstack来查看各个线程的调用堆栈,就可以知道没有响应的线程到底在后台做些什么事情,或者在等待些什么资源。
下面是一个线程死锁的代码。我们下面会通过 jstack 命令进行死锁检查,输出死锁信息,找到发生死锁的线程。
public class DeadLockDemo {private static Object resource1 = new Object();//资源 1private static Object resource2 = new Object();//资源 2public static void main(String[] args) {new Thread(() -> {synchronized (resource1) {System.out.println(Thread.currentThread() + "get resource1");try {Thread.sleep(1000);} catch (InterruptedException e) {e.printStackTrace();}System.out.println(Thread.currentThread() + "waiting get resource2");synchronized (resource2) {System.out.println(Thread.currentThread() + "get resource2");}}}, "线程 1").start();new Thread(() -> {synchronized (resource2) {System.out.println(Thread.currentThread() + "get resource2");try {Thread.sleep(1000);} catch (InterruptedException e) {e.printStackTrace();}System.out.println(Thread.currentThread() + "waiting get resource1");synchronized (resource1) {System.out.println(Thread.currentThread() + "get resource1");}}}, "线程 2").start();}}
线程 A 通过 synchronized (resource1) 获得 resource1 的监视器锁,然后通过Thread.sleep(1000);让线程 A 休眠 1s 为的是让线程 B 得到执行然后获取到 resource2 的监视器锁。线程 A 和线程 B 休眠结束了都开始企图请求获取对方的资源,然后这两个线程就会陷入互相等待的状态,这也就产生了死锁。
运行结果
Thread[线程 1,5,main]get resource1Thread[线程 2,5,main]get resource2Thread[线程 1,5,main]waiting get resource2Thread[线程 2,5,main]waiting get resource1
D:\develop\workspace_idea\learn\java-base\target\classes>jps14288 Main11060 Bootstrap21380 ErpAppBoot4036 Launcher10824 DeadLockDemo13864 Launcher22440 Launcher20620 Launcher24620 Jps8556D:\develop\workspace_idea\learn\java-base\target\classes>jstack 108242020-11-12 10:34:05Full thread dump Java HotSpot(TM) 64-Bit Server VM (25.111-b14 mixed mode):"DestroyJavaVM" #14 prio=5 os_prio=0 tid=0x0000000003312800 nid=0x42bc waiting on condition [0x0000000000000000]java.lang.Thread.State: RUNNABLE"线程 2" #13 prio=5 os_prio=0 tid=0x000000001f9d3800 nid=0x6148 waiting for monitor entry [0x000000002038e000]java.lang.Thread.State: BLOCKED (on object monitor)at DeadLockDemo.lambda$main$1(DeadLockDemo.java:31)- waiting to lock <0x000000076c792390> (a java.lang.Object)- locked <0x000000076c7923a0> (a java.lang.Object)at DeadLockDemo$$Lambda$2/1149319664.run(Unknown Source)at java.lang.Thread.run(Thread.java:745)"线程 1" #12 prio=5 os_prio=0 tid=0x000000001f9d2800 nid=0x26e0 waiting for monitor entry [0x000000002028f000]java.lang.Thread.State: BLOCKED (on object monitor)at DeadLockDemo.lambda$main$0(DeadLockDemo.java:16)- waiting to lock <0x000000076c7923a0> (a java.lang.Object)- locked <0x000000076c792390> (a java.lang.Object)at DeadLockDemo$$Lambda$1/1747585824.run(Unknown Source)at java.lang.Thread.run(Thread.java:745)"Service Thread" #11 daemon prio=9 os_prio=0 tid=0x000000001ecdc000 nid=0x570c runnable [0x0000000000000000]java.lang.Thread.State: RUNNABLE"C1 CompilerThread3" #10 daemon prio=9 os_prio=2 tid=0x000000001ec36800 nid=0x1244 waiting on condition [0x0000000000000000]java.lang.Thread.State: RUNNABLE"C2 CompilerThread2" #9 daemon prio=9 os_prio=2 tid=0x000000001ec2e000 nid=0x5688 waiting on condition [0x0000000000000000]java.lang.Thread.State: RUNNABLE"C2 CompilerThread1" #8 daemon prio=9 os_prio=2 tid=0x000000001ec26800 nid=0x1c60 waiting on condition [0x0000000000000000]java.lang.Thread.State: RUNNABLE"C2 CompilerThread0" #7 daemon prio=9 os_prio=2 tid=0x000000001ec22800 nid=0x56f8 waiting on condition [0x0000000000000000]java.lang.Thread.State: RUNNABLE"Monitor Ctrl-Break" #6 daemon prio=5 os_prio=0 tid=0x000000001ec15800 nid=0x568 runnable [0x000000001f38e000]java.lang.Thread.State: RUNNABLEat java.net.SocketInputStream.socketRead0(Native Method)at java.net.SocketInputStream.socketRead(SocketInputStream.java:116)at java.net.SocketInputStream.read(SocketInputStream.java:170)at java.net.SocketInputStream.read(SocketInputStream.java:141)at sun.nio.cs.StreamDecoder.readBytes(StreamDecoder.java:284)at sun.nio.cs.StreamDecoder.implRead(StreamDecoder.java:326)at sun.nio.cs.StreamDecoder.read(StreamDecoder.java:178)- locked <0x000000076c8c5c30> (a java.io.InputStreamReader)at java.io.InputStreamReader.read(InputStreamReader.java:184)at java.io.BufferedReader.fill(BufferedReader.java:161)at java.io.BufferedReader.readLine(BufferedReader.java:324)- locked <0x000000076c8c5c30> (a java.io.InputStreamReader)at java.io.BufferedReader.readLine(BufferedReader.java:389)at com.intellij.rt.execution.application.AppMainV2$1.run(AppMainV2.java:64)"Attach Listener" #5 daemon prio=5 os_prio=2 tid=0x000000001ebbb800 nid=0x231c waiting on condition [0x0000000000000000]java.lang.Thread.State: RUNNABLE"Signal Dispatcher" #4 daemon prio=9 os_prio=2 tid=0x000000001eb69000 nid=0x6390 runnable [0x0000000000000000]java.lang.Thread.State: RUNNABLE"Finalizer" #3 daemon prio=8 os_prio=1 tid=0x000000000340e800 nid=0x575c in Object.wait() [0x000000001f02e000]java.lang.Thread.State: WAITING (on object monitor)at java.lang.Object.wait(Native Method)- waiting on <0x000000076c608e98> (a java.lang.ref.ReferenceQueue$Lock)at java.lang.ref.ReferenceQueue.remove(ReferenceQueue.java:143)- locked <0x000000076c608e98> (a java.lang.ref.ReferenceQueue$Lock)at java.lang.ref.ReferenceQueue.remove(ReferenceQueue.java:164)at java.lang.ref.Finalizer$FinalizerThread.run(Finalizer.java:209)"Reference Handler" #2 daemon prio=10 os_prio=2 tid=0x0000000003407800 nid=0x3064 in Object.wait() [0x000000001eb2e000]java.lang.Thread.State: WAITING (on object monitor)at java.lang.Object.wait(Native Method)- waiting on <0x000000076c606b40> (a java.lang.ref.Reference$Lock)at java.lang.Object.wait(Object.java:502)at java.lang.ref.Reference.tryHandlePending(Reference.java:191)- locked <0x000000076c606b40> (a java.lang.ref.Reference$Lock)at java.lang.ref.Reference$ReferenceHandler.run(Reference.java:153)"VM Thread" os_prio=2 tid=0x000000001cc29800 nid=0x2d70 runnable"GC task thread#0 (ParallelGC)" os_prio=0 tid=0x0000000003327800 nid=0x5ba4 runnable"GC task thread#1 (ParallelGC)" os_prio=0 tid=0x0000000003329000 nid=0x5c94 runnable"GC task thread#2 (ParallelGC)" os_prio=0 tid=0x000000000332b000 nid=0xe00 runnable"GC task thread#3 (ParallelGC)" os_prio=0 tid=0x000000000332c800 nid=0x4bfc runnable"GC task thread#4 (ParallelGC)" os_prio=0 tid=0x000000000332f800 nid=0x5560 runnable"GC task thread#5 (ParallelGC)" os_prio=0 tid=0x0000000003331000 nid=0x2c60 runnable"GC task thread#6 (ParallelGC)" os_prio=0 tid=0x0000000003334000 nid=0x205c runnable"GC task thread#7 (ParallelGC)" os_prio=0 tid=0x0000000003335000 nid=0x5fa0 runnable"VM Periodic Task Thread" os_prio=2 tid=0x000000001ed35000 nid=0x6094 waiting on conditionJNI global references: 336Found one Java-level deadlock:============================="线程 2":waiting to lock monitor 0x000000000340df68 (object 0x000000076c792390, a java.lang.Object),which is held by "线程 1""线程 1":waiting to lock monitor 0x000000000340b788 (object 0x000000076c7923a0, a java.lang.Object),which is held by "线程 2"Java stack information for the threads listed above:==================================================="线程 2":at DeadLockDemo.lambda$main$1(DeadLockDemo.java:31)- waiting to lock <0x000000076c792390> (a java.lang.Object)- locked <0x000000076c7923a0> (a java.lang.Object)at DeadLockDemo$$Lambda$2/1149319664.run(Unknown Source)at java.lang.Thread.run(Thread.java:745)"线程 1":at DeadLockDemo.lambda$main$0(DeadLockDemo.java:16)- waiting to lock <0x000000076c7923a0> (a java.lang.Object)- locked <0x000000076c792390> (a java.lang.Object)at DeadLockDemo$$Lambda$1/1747585824.run(Unknown Source)at java.lang.Thread.run(Thread.java:745)Found 1 deadlock.
jconsole jdk自带的可视化分析工具
关于已使用,已提交
used Heap: jvm中活动对象占用的内存,当used 接近committed的时候,heap就会grow up,-Xmx设置了Commit上限。
Commited: 表示可供java虚拟机使用的内存量,提交的内存可能会随时间的推移而变化(增加或者减少)。JVM可能会向OS释放内存,同时已提交的内存可能小于Init,已提交的内存将始终大于或等于Used Heap(ORACLE 官方文档中可以看到)。init是启动时后JVM向OS申请的内存,max是能够使用的最大边界值。注意这里说的都是虚拟内存,所以理论上整个操作系统commited的内存为物理内存加上交换空间的大小,换句话说如果commited超过物理内存的话,多余的部分就会被换出到磁盘。这也就是为什么jvm提交的内存可能会比实际进程占用的内存更大的原因。
JDK 1.8中默认的GC收集器为Parallel GC,这个GC收集器在GC之后不会将内存返还给OS,所以GC之后进程内存占用不会降低。
Visual VM:多合一故障处理工具
VisualVM 提供在 Java 虚拟机 (Java Virutal Machine, JVM) 上运行的 Java 应用程序的详细信息。在 VisualVM 的图形用户界面中,您可以方便、快捷地查看多个 Java 应用程序的相关信息。Visual VM 官网:https://visualvm.github.io/ 。Visual VM 中文文档:https://visualvm.github.io/documentation.html。
模拟GC
import java.io.IOException;public class GcTest {public static void main(String[] args) throws IOException {int size = 1024 * 1000;Integer[] arr = new Integer[size];for (int i = 0; i < size; i++) {arr[i] = i;}System.in.read();}}
设置堆参数 -Xms10m -Xmx10m -XX:+PrintGCDetails
运行
[Full GC (Ergonomics) [PSYoungGen: 2048K->2048K(2560K)] [ParOldGen: 7034K->7034K(7168K)] 9082K->9082K(9728K), [Metaspace: 3474K->3474K(1056768K)], 0.0306816 secs] [Times: user=0.17 sys=0.02, real=0.03 secs][Full GC (Ergonomics) [PSYoungGen: 2048K->2048K(2560K)] [ParOldGen: 7035K->7035K(7168K)] 9083K->9083K(9728K), [Metaspace: 3474K->3474K(1056768K)], 0.0292119 secs] [Times: user=0.25 sys=0.00, real=0.03 secs][Full GC (Ergonomics) [PSYoungGen: 2048K->2048K(2560K)] [ParOldGen: 7036K->7036K(7168K)] 9084K->9084K(9728K), [Metaspace: 3474K->3474K(1056768K)], 0.0282951 secs] [Times: user=0.14 sys=0.00, real=0.03 secs][Full GC (Ergonomics) [PSYoungGen: 2048K->2048K(2560K)] [ParOldGen: 7037K->7037K(7168K)] 9085K->9085K(9728K), [Metaspace: 3474K->3474K(1056768K)], 0.0280142 secs] [Times: user=0.22 sys=0.00, real=0.03 secs]Exception in thread "main" java.lang.OutOfMemoryError: GC overhead limit exceeded[Full GC (Ergonomics) [PSYoungGen: 2048K->0K(2560K)] [ParOldGen: 7054K->642K(7168K)] 9102K->642K(9728K), [Metaspace: 3500K->3500K(1056768K)], 0.0043817 secs] [Times: user=0.00 sys=0.00, real=0.01 secs]at java.lang.Integer.valueOf(Integer.java:832)at GcTest.main(GcTest.java:10)HeapPSYoungGen total 2560K, used 52K [0x00000000ffd00000, 0x0000000100000000, 0x0000000100000000)eden space 2048K, 2% used [0x00000000ffd00000,0x00000000ffd0d300,0x00000000fff00000)from space 512K, 0% used [0x00000000fff80000,0x00000000fff80000,0x0000000100000000)to space 512K, 0% used [0x00000000fff00000,0x00000000fff00000,0x00000000fff80000)ParOldGen total 7168K, used 642K [0x00000000ff600000, 0x00000000ffd00000, 0x00000000ffd00000)object space 7168K, 8% used [0x00000000ff600000,0x00000000ff6a0ad8,0x00000000ffd00000)Metaspace used 3507K, capacity 4500K, committed 4864K, reserved 1056768Kclass space used 389K, capacity 392K, committed 512K, reserved 1048576K
[GC (Allocation Failure) [PSYoungGen: 309876K->19429K(381440K)] 327624K->44294K(515584K), 0.0160240 secs] [Times: user=0.00 sys=0.02, real=0.02 secs]
2020-11-12 13:43:30.094 INFO 18024 --- [nio-8090-exec-1] o.a.c.c.C.[Tomcat].[localhost].[/] : Initializing Spring DispatcherServlet 'dispatcherServlet'
2020-11-12 13:43:30.094 INFO 18024 --- [nio-8090-exec-1] o.s.web.servlet.DispatcherServlet : Initializing Servlet 'dispatcherServlet'
2020-11-12 13:43:30.109 INFO 18024 --- [nio-8090-exec-1] o.s.web.servlet.DispatcherServlet : Completed initialization in 15 ms
[GC (Metadata GC Threshold) [PSYoungGen: 114259K->2070K(386560K)] 139124K->44308K(520704K), 0.0107186 secs] [Times: user=0.11 sys=0.02, real=0.01 secs]
[Full GC (Metadata GC Threshold) [PSYoungGen: 2070K->0K(386560K)] [ParOldGen: 42237K->33966K(194048K)] 44308K->33966K(580608K), [Metaspace: 56197K->56197K(1099776K)], 0.1802416 secs] [Times: user=0.84 sys=0.01, real=0.18 secs]
2020-11-12 13:43:30.383 INFO 18024 --- [nio-8090-exec-1] io.lettuce.core.EpollProvider : Starting without optional epoll library
2020-11-12 13:43:30.384 INFO 18024 --- [nio-8090-exec-1] io.lettuce.core.KqueueProvider : Starting without optional kqueue library
看一下各个参数含义
可以参考博客【https://blog.csdn.net/zc19921215/article/details/83029952】
GC:
表明进行了一次垃圾回收,前面没有Full修饰,表明这是一次Minor GC ,注意它不表示只GC新生代,并且现有的不管是新生代还是老年代都会STW。
Allocation Failure:
表明本次引起GC的原因是因为在年轻代中没有足够的空间能够存储新的数据了。
Metadata GC Threshold:
这个见名知意是因为 元空间(Metaspace)扩容或者缩容引起的GC。 我们可以通过pinfo -flag MetaspaceSize PID来查看初始元空间大小。当元空间不够用时会触发GC。我们可以可以下面几个参数。
-XX:MaxMetaspaceSize=N
这个参数用于限制Metaspace增长的上限,防止因为某些情况导致Metaspace无限的使用本地内存,影响到其他程序。在本机上该参数的默认值为4294967295B(大约4096MB)。
-XX:MinMetaspaceFreeRatio=N
当进行过Metaspace GC之后,会计算当前Metaspace的空闲空间比,如果空闲比小于这个参数,那么虚拟机将增长Metaspace的大小。在本机该参数的默认值为40,也就是40%。设置该参数可以控制Metaspace的增长的速度,太小的值会导致Metaspace增长的缓慢,Metaspace的使用逐渐趋于饱和,可能会影响之后类的加载。而太大的值会导致Metaspace增长的过快,浪费内存。
-XX:MaxMetasaceFreeRatio=N
当进行过Metaspace GC之后, 会计算当前Metaspace的空闲空间比,如果空闲比大于这个参数,那么虚拟机会释放Metaspace的部分空间。在本机该参数的默认值为70,也就是70%。
-XX:MaxMetaspaceExpansion=N
Metaspace增长时的最大幅度。在本机上该参数的默认值为5452592B(大约为5MB)。
-XX:MinMetaspaceExpansion=N
Metaspace增长时的最小幅度。在本机上该参数的默认值为340784B(大约330KB为)。
我们可以设置 MetaspaceSize相对大一点,来避免频繁的GC。
ParNew:
表明本次GC发生在年轻代并且使用的是ParNew垃圾收集器。ParNew是一个Serial收集器的多线程版本,会使用多个CPU和线程完成垃圾收集工作(默认使用的线程数和CPU数相同,可以使用-XX:ParallelGCThreads参数限制)。该收集器采用复制算法回收内存,期间会停止其他工作线程,即Stop The World。
YounagGC

FullGC

JVM 参数
堆内存相关
Java 虚拟机所管理的内存中最大的一块,Java 堆是所有线程共享的一块内存区域,在虚拟机启动时创建。此内存区域的唯一目的就是存放对象实例,几乎所有的对象实例以及数组都在这里分配内存。
显式指定堆内存–Xms和-Xmx
与性能有关的最常见实践之一是根据应用程序要求初始化堆内存。如果我们需要指定最小和最大堆大小(推荐显示指定大小),以下参数可以帮助你实现:
-Xms<heap size>[unit]
-Xmx<heap size>[unit]
- heap size 表示要初始化内存的具体大小。
- unit 表示要初始化内存的单位。单位为“ g” (GB) 、“ m”(MB)、“ k”(KB)。
举个栗子🌰,如果我们要为JVM分配最小2 GB和最大5 GB的堆内存大小,我们的参数应该这样来写:
-Xms2G -Xmx5G
显式新生代内存(Young Ceneration)
根据Oracle官方文档,在堆总可用内存配置完成之后,第二大影响因素是为 Young Generation 在堆内存所占的比例。
一共有两种指定 新生代内存(Young Ceneration)大小的方法:
1.通过-XX:NewSize和-XX:MaxNewSize指定
-XX:NewSize=<young size>[unit]
-XX:MaxNewSize=<young size>[unit]
举个栗子🌰,如果我们要为 新生代分配 最小256m 的内存,最大 1024m的内存我们的参数应该这样来写:
-XX:NewSize=256m
-XX:MaxNewSize=1024m
2.通过-Xmn[unit]指定
举个栗子🌰,如果我们要为 新生代分配256m的内存(NewSize与MaxNewSize设为一致),我们的参数应该这样来写:
-Xmn256m
GC 调优策略中很重要的一条经验总结是这样说的:
将新对象预留在新生代,由于 Full GC 的成本远高于 Minor GC,因此尽可能将对象分配在新生代是明智的做法,实际项目中根据 GC 日志分析新生代空间大小分配是否合理,适当通过“-Xmn”命令调节新生代大小,最大限度降低新对象直接进入老年代的情况。
另外,你还可以通过-XX:NewRatio=来设置新生代和老年代内存的比值。
比如下面的参数就是设置新生代(包括Eden和两个Survivor区)与老年代的比值为1。也就是说:新生代与老年代所占比值为1:1,新生代占整个堆栈的 1/2。默认为2 表示新生代:老年代=1:2
-XX:NewRatio=1
-XX:MaxTenuringThreshold,设置新生代对象经过一定的次数晋升到老生代;默认为15。从eden空间转移到survivor时年龄为1。
-XX:PretrnureSizeThreshold,设置大对象的值阈值。默认值为0,不管多大都现在eden中分配内存。
只有在-XX:+UseConcMarkSweepGC(默认会开启-XX:+UseParNewGC),
或者-XX:+UseSerialGC -XX:+UseG1GC才有效有两种清情况新建的对象会直接分配到老年代 1、如果在新生代分配失败且对象是一个不含任何对象引用的大数组,可被直接分配到老年代 2、XX:PretenureSizeThreshold=<字节大小>可以设分配到新生代对象的大小限制。 任何比这个大的对象都不会尝试在新生代分配,将在老年代分配内存
-XX:NewRatio,设置分代垃圾回收器新生代和老生代内存占比;
-XX:SurvivorRatio,设置新生代 Eden、Form Survivor、To Survivor 占比。默认为8 即8:1:1
默认为8,也就是说Eden占新生代的8/10,From幸存区和To幸存区各占新生代的1/10假设1:Eden区域设置太大 新生成的对象会被分配在Eden区,Eden空间不足时会触发MinorGC。理想状态下,如果所有对象在这个阶段全部被回收,Eden区域被清空,不会出什么问题。如果GC后还存在一部分幸存的对象,则会被复制到To Survivor区域,此时因为Survivor区域空间太小无法容纳这些对象,结果大部分幸存对象只在进行一次或很少次的GC后就会被移动到老年代,也就是说从某种程度上来讲失去了MinorGC的初衷,这种情况是肯定不被允许的 假设2:Eden区域设置太小 接着分析,Eden区域设置太小,意味着其空间很快就会被占满,也就是说增加了新生代的GC次数,而频繁的GC会降低整体JVM性能
我们要根据自己的业务场景和硬件配置来设置这些值。例如,当我们的业务场景会有很多大的临时对象产生时,因为这些大对象只有很短的生命周期,因此需要把“-XX:MaxNewSize”的值设置的尽量大一些,否则就会造成大量短生命周期的大对象进入老生代,从而很快消耗掉了老生代的内存,这样就会频繁地触发 full gc,从而影响了业务的正常运行。
显示指定永久代/元空间的大小
从Java 8开始,如果我们没有指定 Metaspace 的大小,随着更多类的创建,虚拟机会耗尽所有可用的系统内存(永久代并不会出现这种情况)。
JDK 1.8 之前永久代还没被彻底移除的时候通常通过下面这些参数来调节方法区大小
-XX:PermSize=N //方法区 (永久代) 初始大小
-XX:MaxPermSize=N //方法区 (永久代) 最大大小,超过这个值将会抛出 OutOfMemoryError 异常:java.lang.OutOfMemoryError: PermGen
相对而言,垃圾收集行为在这个区域是比较少出现的,但并非数据进入方法区后就“永久存在”了。
JDK 1.8 的时候,方法区(HotSpot 的永久代)被彻底移除了(JDK1.7 就已经开始了),取而代之是元空间,元空间使用的是直接内存。
下面是一些常用参数:
-XX:MetaspaceSize=N //设置 Metaspace 的初始(和最小大小)
-XX:MaxMetaspaceSize=N //设置 Metaspace 的最大大小,如果不指定大小的话,随着更多类的创建,虚拟机会耗尽所有可用的系统内存。
这个参数用于限制Metaspace增长的上限,防止因为某些情况导致Metaspace无限的使用本地内存,影响到其他程序。在本机上该参数的默认值为4294967295B(大约4096MB)。
-XX:MinMetaspaceFreeRatio=N
当进行过Metaspace GC之后,会计算当前Metaspace的空闲空间比,如果空闲比小于这个参数,那么虚拟机将增长Metaspace的大小。在本机该参数的默认值为40,也就是40%。设置该参数可以控制Metaspace的增长的速度,太小的值会导致Metaspace增长的缓慢,Metaspace的使用逐渐趋于饱和,可能会影响之后类的加载。而太大的值会导致Metaspace增长的过快,浪费内存。
-XX:MaxMetasaceFreeRatio=N
当进行过Metaspace GC之后, 会计算当前Metaspace的空闲空间比,如果空闲比大于这个参数,那么虚拟机会释放Metaspace的部分空间。在本机该参数的默认值为70,也就是70%。
-XX:MaxMetaspaceExpansion=N
Metaspace增长时的最大幅度。在本机上该参数的默认值为5452592B(大约为5MB)。
-XX:MinMetaspaceExpansion=N
Metaspace增长时的最小幅度。在本机上该参数的默认值为340784B(大约330KB为)。
元空间的扩容也会引发GC。导致GC的类型为Metadata GC Threshold:这个见名知意是因为 元空间(Metaspace)扩容或者缩容引起的GC。 我们可以通过pinfo -flag MetaspaceSize PID来查看初始元空间大小。当元空间不够用时会触发GC。
垃圾收集相关
垃圾回收器
jdk 1.8默认垃圾回收器 -XX:+UseParallelGC。选择垃圾收集器为并行收集器。此配置仅对年轻代有效。可以同时并行多个垃圾收集线程,但此时用户线程必须停止。
为了提高应用程序的稳定性,选择正确的垃圾收集算法至关重要。
JVM具有四种类型的GC实现:
- 串行垃圾收集器
- 并行垃圾收集器
- CMS垃圾收集器
- G1垃圾收集器
可以使用以下参数声明这些实现:
-XX:+UseSerialGC
-XX:+UseParallelGC 并行收集器。 指定在 New Generation 使用 parallel collector, 并行收集 ,
暂停 app threads, 同时启动多个垃圾回收 thread, 不能和CMS gc 一起使用。系统吨吐量优先 , 但是会有
较长长 时间的app pause, 后台系统任务可以使用此gc。UseParallelGC是jdk1.7选择parallel 回收器默
认开启的。 关注吞吐量。此时老年代扔使用串行收集器。-XX:ParallelGCThreads={value} 这个参数是指定
并行 GC 线程的数量,一般最好和 CPU 核心数量相当
-XX:+UseParNewGC 并发收集器。设置年轻代为多线程收集。可与CMS收集同时使用。 是 UseParallelGC 的
gc 的升级版本 , 有更好的性能或者优点。关注响应时间。
-XX:+UseConcMarkSweepGC
注意最新的JVM版本,当使用-XX:+UseConcMarkSweepGC时,-XX:+UseParNewGC会自动开启。因此,如果年
轻代的并行GC不想开启,可以通过设置-XX:-UseParNewGC来关掉。
-XX:+UseG1GC
垃圾优先(Garbage-first)是一款服务器算法,主要对大内存,达到实时高效,高吞吐量等目标。就像G1论文
中说的那样,在大内存(>6GB),低延迟(<0.5S)这个场景,我们可以选择G1收集器。G1 不是万能的如果追求
高吞吐量,还是要选Parallel,因为他就是为了吞吐量设计的。
有关垃圾回收实施的更多详细信息,请参见此处。
GC记录
为了严格监控应用程序的运行状况,我们应该始终检查JVM的垃圾回收性能。最简单的方法是以人类可读的格式记录GC活动。
使用以下参数,我们可以记录GC活动:
-XX:+UseGCLogFileRotation
-XX:NumberOfGCLogFiles=< number of log files >
-XX:GCLogFileSize=< file size >[ unit ]
-Xloggc:/path/to/gc.log
下面是RocketMQ broker jvm参数配置
set "JAVA_OPT=%JAVA_OPT% -server -Xms256m -Xmx256m -Xmn128m"
set "JAVA_OPT=%JAVA_OPT% -XX:+UseG1GC -XX:G1HeapRegionSize=16m -XX:G1ReservePercent=25 -XX:InitiatingHeapOccupancyPercent=30 -XX:SoftRefLRUPolicyMSPerMB=0 -XX:SurvivorRatio=8"
set "JAVA_OPT=%JAVA_OPT% -verbose:gc -Xloggc:%USERPROFILE%\mq_gc.log -XX:+PrintGCDetails -XX:+PrintGCDateStamps -XX:+PrintGCApplicationStoppedTime -XX:+PrintAdaptiveSizePolicy"
set "JAVA_OPT=%JAVA_OPT% -XX:+UseGCLogFileRotation -XX:NumberOfGCLogFiles=5 -XX:GCLogFileSize=30m"
set "JAVA_OPT=%JAVA_OPT% -XX:-OmitStackTraceInFastThrow"
set "JAVA_OPT=%JAVA_OPT% -XX:+AlwaysPreTouch"
set "JAVA_OPT=%JAVA_OPT% -XX:MaxDirectMemorySize=15g"
set "JAVA_OPT=%JAVA_OPT% -XX:-UseLargePages -XX:-UseBiasedLocking"
set "JAVA_OPT=%JAVA_OPT% -Djava.ext.dirs=%BASE_DIR%lib"
set "JAVA_OPT=%JAVA_OPT% -cp %CLASSPATH%"
推荐阅读
JVM 故障排除和优化
15 小知识点
final 在 java 中有什么作用?
- final 修饰的类叫最终类,该类不能被继承。
- final 修饰的方法不能被重写。
- final 修饰的变量叫常量,常量必须初始化,初始化之后值就不能被修改。
在 Queue 中 poll()和 remove()有什么区别?
poll() 和 remove() 都是从队列中取出一个元素,但是 poll() 在获取元素失败的时候会返回空,但是 remove() 失败的时候会抛出异常。
poll()和remove()都调用了pollFirst()方法。LinkedBlockingDeque
public E removeFirst() {
E x = pollFirst();
if (x == null) throw new NoSuchElementException();
return x;
}
哪些集合类是线程安全的?
- vector:就比arraylist多了个同步化机制(线程安全),因为效率较低,现在已经不太建议使用。在web应用中,特别是前台页面,往往效率(页面响应速度)是优先考虑的。
- statck:堆栈类,先进后出。
- hashtable:就比hashmap多了个线程安全。
- enumeration:枚举,相当于迭代器。
- ConcurrentHashMap
迭代器 Iterator 是什么?
迭代器是一种设计模式,它是一个对象,它可以遍历并选择序列中的对象,而开发人员不需要了解该序列的底层结构。迭代器通常被称为“轻量级”对象,因为创建它的代价小。
Iterator 怎么使用?有什么特点?
Java中的Iterator功能比较简单,并且只能单向移动:
(1) 使用方法iterator()要求容器返回一个Iterator。第一次调用Iterator的next()方法时,它返回序列的第一个元素。注意:iterator()方法是java.lang.Iterable接口,被Collection继承。
(2) 使用next()获得序列中的下一个元素。
(3) 使用hasNext()检查序列中是否还有元素。
(4) 使用remove()将迭代器新返回的元素删除。
Iterator是Java迭代器最简单的实现,为List设计的ListIterator具有更多的功能,它可以从两个方向遍历List,也可以从List中插入和删除元素。
说一下 runnable 和 callable 有什么区别?
- Runnable接口中的run()方法的返回值是void,它做的事情只是纯粹地去执行run()方法中的代码而已;
- Callable接口中的call()方法是有返回值的,是一个泛型,和Future、FutureTask配合可以用来获取异步执行的结果。
线程有哪些状态?
线程通常都有五种状态,创建、就绪、运行、阻塞和死亡。
- 创建状态。在生成线程对象,并没有调用该对象的start方法,这是线程处于创建状态。
- 就绪状态。当调用了线程对象的start方法之后,该线程就进入了就绪状态,但是此时线程调度程序还没有把该线程设置为当前线程,此时处于就绪状态。在线程运行之后,从等待或者睡眠中回来之后,也会处于就绪状态。
- 运行状态。线程调度程序将处于就绪状态的线程设置为当前线程,此时线程就进入了运行状态,开始运行run函数当中的代码。
- 阻塞状态。线程正在运行的时候,被暂停,通常是为了等待某个时间的发生(比如说某项资源就绪)之后再继续运行。sleep,suspend,wait等方法都可以导致线程阻塞。
- 死亡状态。如果一个线程的run方法执行结束或者调用stop方法后,该线程就会死亡。对于已经死亡的线程,无法再使用start方法令其进入就绪
notify()和 notifyAll()有什么区别?
- 如果线程调用了对象的 wait()方法,那么线程便会处于该对象的等待池中,等待池中的线程不会去竞争该对象的锁。
- 当有线程调用了对象的 notifyAll()方法(唤醒所有 wait 线程)或 notify()方法(只随机唤醒一个 wait 线程),被唤醒的的线程便会进入该对象的锁池中,锁池中的线程会去竞争该对象锁。也就是说,调用了notify后只要一个线程会由等待池进入锁池,而notifyAll会将该对象等待池内的所有线程移动到锁池中,等待锁竞争。
- 优先级高的线程竞争到对象锁的概率大,假若某线程没有竞争到该对象锁,它还会留在锁池中,唯有线程再次调用 wait()方法,它才会重新回到等待池中。而竞争到对象锁的线程则继续往下执行,直到执行完了 synchronized 代码块,它会释放掉该对象锁,这时锁池中的线程会继续竞争该对象锁。
创建线程池有哪几种方式?
使用Executors
①. newFixedThreadPool(int nThreads)
创建一个固定长度的线程池,每当提交一个任务就创建一个线程,直到达到线程池的最大数量,这时线程规模将不再变化,当线程发生未预期的错误而结束时,线程池会补充一个新的线程。核心线程数等于最大线程数。线程池大小固定,当超出nThreads会放在队列里面,队列大小等同于无限大。
②. newCachedThreadPool()
创建一个可缓存的线程池,如果线程池的规模超过了处理需求,将自动回收空闲线程,而当需求增加时,则可以自动添加新线程,线程池的规模不存在任何限制。核心线程大小为0,最大线程数为Integer.MAX,队列为同步队列,存活时间为60s。所以线程池的规模相当于没有限制。
③. newSingleThreadExecutor()
这是一个单线程的Executor,它创建单个工作线程来执行任务,如果这个线程异常结束,会创建一个新的来替代它;它的特点是能确保依照任务在队列中的顺序来串行执行。核心线程1,最大线程数1,队列为无限大,存活时间为0。只有一个线程执行,从队列中取任务,如果任务执行完,线程就会销毁。
④. newScheduledThreadPool(int corePoolSize) 定时任务使用的是堆排序实现的优先队列。
创建了一个固定长度的线程池,而且以延迟或定时的方式来执行任务,类似于Timer。
⑤ 直接实列化 ThreadPoolExecutor(..) 或其子类ScheduledThreadPoolExecutor
线程池都有哪些状态?
线程池有5种状态:Running、ShutDown、Stop、Tidying、Terminated。
线程池各个状态切换框架图:
在 java 程序中怎么保证多线程的运行安全?
线程安全在三个方面体现:
- 原子性:提供互斥访问,同一时刻只能有一个线程对数据进行操作,(atomic,synchronized);
- 可见性:一个线程对主内存的修改可以及时地被其他线程看到,(synchronized,volatile);
- 有序性:一个线程观察其他线程中的指令执行顺序,由于指令重排序,该观察结果一般杂乱无序,(happens-before原则)。
多线程锁的升级原理是什么?
在Java中,锁共有4种状态,级别从低到高依次为:无状态锁,偏向锁,轻量级锁和重量级锁状态,这几个状态会随着竞争情况逐渐升级。锁可以升级但不能降级。

什么是死锁?
死锁是指两个或两个以上的进程在执行过程中,由于竞争资源或者由于彼此通信而造成的一种阻塞的现象,若无外力作用,它们都将无法推进下去。此时称系统处于死锁状态或系统产生了死锁,这些永远在互相等待的进程称为死锁进程。是操作系统层面的一个错误,是进程死锁的简称,最早在 1965 年由 Dijkstra 在研究银行家算法时提出的,它是计算机操作系统乃至整个并发程序设计领域最难处理的问题之一。
怎么防止死锁?
死锁的四个必要条件:
- 互斥条件:进程对所分配到的资源不允许其他进程进行访问,若其他进程访问该资源,只能等待,直至占有该资源的进程使用完成后释放该资源
- 请求和保持条件:进程获得一定的资源之后,又对其他资源发出请求,但是该资源可能被其他进程占有,此事请求阻塞,但又对自己获得的资源保持不放
- 不可剥夺条件:是指进程已获得的资源,在未完成使用之前,不可被剥夺,只能在使用完后自己释放
- 环路等待条件:是指进程发生死锁后,若干进程之间形成一种头尾相接的循环等待资源关系
这四个条件是死锁的必要条件,只要系统发生死锁,这些条件必然成立,而只要上述条件之 一不满足,就不会发生死锁。
理解了死锁的原因,尤其是产生死锁的四个必要条件,就可以最大可能地避免、预防和 解除死锁。
所以,在系统设计、进程调度等方面注意如何不让这四个必要条件成立,如何确 定资源的合理分配算法,避免进程永久占据系统资源。
此外,也要防止进程在处于等待状态的情况下占用资源。因此,对资源的分配要给予合理的规划。
说一下 synchronized 底层实现原理?
synchronized可以保证方法或者代码块在运行时,同一时刻只有一个方法可以进入到临界区,同时它还可以保证共享变量的内存可见性。
Java中每一个对象都可以作为锁,这是synchronized实现同步的基础:
- 普通同步方法,锁是当前实例对象
- 静态同步方法,锁是当前类的class对象
- 同步方法块,锁是括号里面的对象
synchronized 和 volatile 的区别是什么?
- volatile本质是在告诉jvm当前变量在寄存器(工作内存)中的值是不确定的,需要从主存中读取; synchronized则是锁定当前变量,只有当前线程可以访问该变量,其他线程被阻塞住。
- volatile仅能使用在变量级别;synchronized则可以使用在变量、方法、和类级别的。
- volatile仅能实现变量的修改可见性,不能保证原子性;而synchronized则可以保证变量的修改可见性和原子性。
- volatile不会造成线程的阻塞;synchronized可能会造成线程的阻塞。
- volatile标记的变量不会被编译器优化;synchronized标记的变量可以被编译器优化。(优化指指令重排)
synchronized 和 Lock 有什么区别?
- 首先synchronized是java内置关键字,在jvm层面,Lock是个java类;
- synchronized无法判断是否获取锁的状态,Lock可以判断是否获取到锁;
- synchronized会自动释放锁(a 线程执行完同步代码会释放锁 ;b 线程执行过程中发生异常会释放锁),Lock需在finally中手工释放锁(unlock()方法释放锁),否则容易造成线程死锁;
- 用synchronized关键字的两个线程1和线程2,如果当前线程1获得锁,线程2线程等待。如果线程1阻塞,线程2则会一直等待下去,而Lock锁就不一定会等待下去,如果尝试获取不到锁,线程可以不用一直等待就结束了;
- synchronized的锁可重入、不可中断、非公平,而Lock锁可重入、可判断、可公平(两者皆可);
- Lock锁适合大量同步的代码的同步问题,synchronized锁适合代码少量的同步问题。
synchronized 和 ReentrantLock 区别是什么?
synchronized是和if、else、for、while一样的关键字,ReentrantLock是类,这是二者的本质区别。既然ReentrantLock是类,那么它就提供了比synchronized更多更灵活的特性,可以被继承、可以有方法、可以有各种各样的类变量,ReentrantLock比synchronized的扩展性体现在几点上:
- ReentrantLock可以对获取锁的等待时间进行设置,这样就避免了死锁
- ReentrantLock可以获取各种锁的信息
- ReentrantLock可以灵活地实现多路通知
另外,二者的锁机制其实也是不一样的:ReentrantLock底层调用的是Unsafe的park方法加锁,synchronized操作的应该是对象头中mark word。
说一下 atomic 的原理?
Atomic包中的类基本的特性就是在多线程环境下,当有多个线程同时对单个(包括基本类型及引用类型)变量进行操作时,具有排他性,即当多个线程同时对该变量的值进行更新时,仅有一个线程能成功,而未成功的线程可以向自旋锁一样,继续尝试,一直等到执行成功。CAS
Atomic系列的类中的核心方法都会调用unsafe类中的几个本地方法。我们需要先知道一个东西就是Unsafe类,全名为:sun.misc.Unsafe,这个类包含了大量的对C代码的操作,包括很多直接内存分配以及原子操作的调用,而它之所以标记为非安全的,是告诉你这个里面大量的方法调用都会存在安全隐患,需要小心使用,否则会导致严重的后果,例如在通过unsafe分配内存的时候,如果自己指定某些区域可能会导致一些类似C++一样的指针越界到其他进程的问题。
反射
反射主要是指程序可以访问、检测和修改它本身状态或行为的一种能力
Java反射:
在Java运行时环境中,对于任意一个类,能否知道这个类有哪些属性和方法?对于任意一个对象,能否调用它的任意一个方法
Java反射机制主要提供了以下功能:
- 在运行时判断任意一个对象所属的类。
- 在运行时构造任意一个类的对象。
- 在运行时判断任意一个类所具有的成员变量和方法。
- 在运行时调用任意一个对象的方法。
什么是 java 序列化?什么情况下需要序列化?
简单说就是为了保存在内存中的各种对象的状态(也就是实例变量,不是方法),并且可以把保存的对象状态再读出来。虽然你可以用你自己的各种各样的方法来保存object states,但是Java给你提供一种应该比你自己好的保存对象状态的机制,那就是序列化。
什么情况下需要序列化:
a)当你想把的内存中的对象状态保存到一个文件中或者数据库中时候;
b)当你想用套接字在网络上传送对象的时候;
c)当你想通过RMI传输对象的时候;
如何实现对象克隆?
有两种方式:
1). 实现Cloneable接口并重写Object类中的clone()方法;当对象中含有可变的引用类型属性时,在复制得到的新对象对该引用类型属性内容进行修改,原始对象响应的属性内容也会发生变化,这就是”浅拷贝”的现象
2). 实现Serializable接口,通过对象的序列化和反序列化实现克隆,可以实现真正的深度克隆,代码如下:
import java.io.ByteArrayInputStream;
import java.io.ByteArrayOutputStream;
import java.io.ObjectInputStream;
import java.io.ObjectOutputStream;
import java.io.Serializable;
public class MyUtil {
private MyUtil() {
throw new AssertionError();
}
@SuppressWarnings("unchecked")
public static <T extends Serializable> T clone(T obj) throws Exception {
ByteArrayOutputStream bout = new ByteArrayOutputStream();
ObjectOutputStream oos = new ObjectOutputStream(bout);
oos.writeObject(obj);
ByteArrayInputStream bin = new ByteArrayInputStream(bout.toByteArray());
ObjectInputStream ois = new ObjectInputStream(bin);
return (T) ois.readObject();
// 说明:调用ByteArrayInputStream或ByteArrayOutputStream对象的close方法没有任何意义
// 这两个基于内存的流只要垃圾回收器清理对象就能够释放资源,这一点不同于对外部资源(如文件流)的释放
}
}
注意:基于序列化和反序列化实现的克隆不仅仅是深度克隆,更重要的是通过泛型限定,可以检查出要克隆的对象是否支持序列化,这项检查是编译器完成的,不是在运行时抛出异常,这种是方案明显优于使用Object类的clone方法克隆对象。让问题在编译的时候暴露出来总是好过把问题留到运行时。
深拷贝和浅拷贝区别是什么?
- 浅拷贝只是复制了对象的引用地址,两个对象指向同一个内存地址,所以修改其中任意的值,另一个值都会随之变化,这就是浅拷贝(例:assign())
- 深拷贝是将对象及值复制过来,两个对象修改其中任意的值另一个值不会改变,这就是深拷贝(例:JSON.parse()和JSON.stringify(),但是此方法无法复制函数类型)
session 和 cookie 有什么区别?
- 由于HTTP协议是无状态的协议,所以服务端需要记录用户的状态时,就需要用某种机制来识具体的用户,这个机制就是Session.典型的场景比如购物车,当你点击下单按钮时,由于HTTP协议无状态,所以并不知道是哪个用户操作的,所以服务端要为特定的用户创建了特定的Session,用用于标识这个用户,并且跟踪用户,这样才知道购物车里面有几本书。这个Session是保存在服务端的,有一个唯一标识。在服务端保存Session的方法很多,内存、数据库、文件都有。集群的时候也要考虑Session的转移,在大型的网站,一般会有专门的Session服务器集群,用来保存用户会话,这个时候 Session 信息都是放在内存的,使用一些缓存服务比如Memcached之类的来放 Session。
- 思考一下服务端如何识别特定的客户?这个时候Cookie就登场了。每次HTTP请求的时候,客户端都会发送相应的Cookie信息到服务端。实际上大多数的应用都是用 Cookie 来实现Session跟踪的,第一次创建Session的时候,服务端会在HTTP协议中告诉客户端,需要在 Cookie 里面记录一个Session ID,以后每次请求把这个会话ID发送到服务器,我就知道你是谁了。有人问,如果客户端的浏览器禁用了 Cookie 怎么办?一般这种情况下,会使用一种叫做URL重写的技术来进行会话跟踪,即每次HTTP交互,URL后面都会被附加上一个诸如 sid=xxxxx 这样的参数,服务端据此来识别用户。
- Cookie其实还可以用在一些方便用户的场景下,设想你某次登陆过一个网站,下次登录的时候不想再次输入账号了,怎么办?这个信息可以写到Cookie里面,访问网站的时候,网站页面的脚本可以读取这个信息,就自动帮你把用户名给填了,能够方便一下用户。这也是Cookie名称的由来,给用户的一点甜头。所以,总结一下:Session是在服务端保存的一个数据结构,用来跟踪用户的状态,这个数据可以保存在集群、数据库、文件中;Cookie是客户端保存用户信息的一种机制,用来记录用户的一些信息,也是实现Session的一种方式。
说一下 session 的工作原理?
其实session是一个存在服务器上的类似于一个散列表格的文件。里面存有我们需要的信息,在我们需要用的时候可以从里面取出来。类似于一个大号的map吧,里面的键存储的是用户的sessionid,用户向服务器发送请求的时候会带上这个sessionid。这时就可以从中取出对应的值了。
什么是 XSS 攻击,如何避免?
XSS攻击又称CSS,全称Cross Site Script (跨站脚本攻击),其原理是攻击者向有XSS漏洞的网站中输入恶意的 HTML 代码,当用户浏览该网站时,这段 HTML 代码会自动执行,从而达到攻击的目的。XSS 攻击类似于 SQL 注入攻击,SQL注入攻击中以SQL语句作为用户输入,从而达到查询/修改/删除数据的目的,而在xss攻击中,通过插入恶意脚本,实现对用户游览器的控制,获取用户的一些信息。 XSS是 Web 程序中常见的漏洞,XSS 属于被动式且用于客户端的攻击方式。
XSS防范的总体思路是:对输入(和URL参数)进行过滤,对输出进行编码。
什么是 CSRF 攻击,如何避免?
CSRF(Cross-site request forgery)也被称为 one-click attack或者 session riding,中文全称是叫跨站请求伪造。一般来说,攻击者通过伪造用户的浏览器的请求,向访问一个用户自己曾经认证访问过的网站发送出去,使目标网站接收并误以为是用户的真实操作而去执行命令。常用于盗取账号、转账、发送虚假消息等。攻击者利用网站对请求的验证漏洞而实现这样的攻击行为,网站能够确认请求来源于用户的浏览器,却不能验证请求是否源于用户的真实意愿下的操作行为。
如何避免:
- 验证 HTTP Referer 字段
HTTP头中的Referer字段记录了该 HTTP 请求的来源地址。在通常情况下,访问一个安全受限页面的请求来自于同一个网站,而如果黑客要对其实施 CSRF
攻击,他一般只能在他自己的网站构造请求。因此,可以通过验证Referer值来防御CSRF 攻击。
- 使用验证码
关键操作页面加上验证码,后台收到请求后通过判断验证码可以防御CSRF。但这种方法对用户不太友好。
- 在请求地址中添加token并验证
CSRF 攻击之所以能够成功,是因为黑客可以完全伪造用户的请求,该请求中所有的用户验证信息都是存在于cookie中,因此黑客可以在不知道这些验证信息的情况下直接利用用户自己的cookie 来通过安全验证。要抵御 CSRF,关键在于在请求中放入黑客所不能伪造的信息,并且该信息不存在于 cookie 之中。可以在 HTTP 请求中以参数的形式加入一个随机产生的 token,并在服务器端建立一个拦截器来验证这个 token,如果请求中没有token或者 token 内容不正确,则认为可能是 CSRF 攻击而拒绝该请求。这种方法要比检查 Referer 要安全一些,token 可以在用户登陆后产生并放于session之中,然后在每次请求时把token 从 session 中拿出,与请求中的 token 进行比对,但这种方法的难点在于如何把 token 以参数的形式加入请求。
对于 GET 请求,token 将附在请求地址之后,这样 URL 就变成 http://url?csrftoken=tokenvalue。
而对于 POST 请求来说,要在 form 的最后加上 ,这样就把token以参数的形式加入请求了。
- 在HTTP 头中自定义属性并验证
这种方法也是使用 token 并进行验证,和上一种方法不同的是,这里并不是把 token 以参数的形式置于 HTTP 请求之中,而是把它放到 HTTP 头中自定义的属性里。通过 XMLHttpRequest 这个类,可以一次性给所有该类请求加上 csrftoken 这个 HTTP 头属性,并把 token 值放入其中。这样解决了上种方法在请求中加入 token 的不便,同时,通过 XMLHttpRequest 请求的地址不会被记录到浏览器的地址栏,也不用担心 token 会透过 Referer 泄露到其他网站中去。
throw 和 throws 的区别?
throws是用来声明一个方法可能抛出的所有异常信息,throws是将异常声明但是不处理,而是将异常往上传,谁调用我就交给谁处理。而throw则是指抛出的一个具体的异常类型。
final、finally、finalize 有什么区别?
- final可以修饰类、变量、方法,修饰类表示该类不能被继承、修饰方法表示该方法不能被重写、修饰变量表示该变量是一个常量不能被重新赋值。
- finally一般作用在try-catch代码块中,在处理异常的时候,通常我们将一定要执行的代码方法finally代码块中,表示不管是否出现异常,该代码块都会执行,一般用来存放一些关闭资源的代码。
- finalize是一个方法,属于Object类的一个方法,而Object类是所有类的父类,该方法一般由垃圾回收器来调用,当我们调用System的gc()方法的时候,由垃圾回收器调用finalize(),回收垃圾。
http 响应码 301 和 302 代表的是什么?有什么区别?
答:301,302 都是HTTP状态的编码,都代表着某个URL发生了转移。
区别:
- 301 redirect: 301 代表永久性转移(Permanently Moved)。
- 302 redirect: 302 代表暂时性转移(Temporarily Moved )。
forward 和 redirect 的区别?
Forward和Redirect代表了两种请求转发方式:直接转发和间接转发。
直接转发方式(Forward),客户端和浏览器只发出一次请求,Servlet、HTML、JSP或其它信息资源,由第二个信息资源响应该请求,在请求对象request中,保存的对象对于每个信息资源是共享的。
间接转发方式 重定向(Redirect)实际是两次HTTP请求,服务器端在响应第一次请求的时候,让浏览器再向另外一个URL发出请求,从而达到转发的目的。
举个通俗的例子:
直接转发就相当于:“A找B借钱,B说没有,B去找C借,借到借不到都会把消息传递给A”;
间接转发就相当于:”A找B借钱,B说没有,让A去找C借”。
简述 tcp 和 udp的区别?
TCP:transmission control protocol 传输控制协议
UDP:user data protocol 用户数据报协议
- TCP面向连接(如打电话要先拨号建立连接);UDP是无连接的,即发送数据之前不需要建立连接。
- TCP提供可靠的服务。也就是说,通过TCP连接传送的数据,无差错,不丢失,不重复,且按序到达;UDP尽最大努力交付,即不保证可靠交付。
- Tcp通过校验和,重传控制,序号标识,滑动窗口、确认应答实现可靠传输。如丢包时的重发控制,还可以对次序乱掉的分包进行顺序控制。
- UDP具有较好的实时性,工作效率比TCP高,适用于对高速传输和实时性有较高的通信或广播通信。
- 每一条TCP连接只能是点到点的;UDP支持一对一,一对多,多对一和多对多的交互通信。
- TCP对系统资源要求较多,UDP对系统资源要求较少。
tcp 为什么要三次握手,两次不行吗?为什么?
为了实现可靠数据传输, TCP 协议的通信双方, 都必须维护一个序列号, 以标识发送出去的数据包中, 哪些是已经被对方收到的。 三次握手的过程即是通信双方相互告知序列号起始值, 并确认对方已经收到了序列号起始值的必经步骤。
如果只是两次握手, 至多只有连接发起方的起始序列号能被确认, 另一方选择的序列号则得不到确认。
说一下 tcp 粘包是怎么产生的?
①. 发送方产生粘包
采用TCP协议传输数据的客户端与服务器经常是保持一个长连接的状态(一次连接发一次数据不存在粘包),双方在连接不断开的情况下,可以一直传输数据;但当发送的数据包过于的小时,那么TCP协议默认的会启用Nagle算法,将这些较小的数据包进行合并发送(缓冲区数据发送是一个堆压的过程);这个合并过程就是在发送缓冲区中进行的,也就是说数据发送出来它已经是粘包的状态了。

②. 接收方产生粘包
接收方采用TCP协议接收数据时的过程是这样的:数据到底接收方,从网络模型的下方传递至传输层,传输层的TCP协议处理是将其放置接收缓冲区,然后由应用层来主动获取(C语言用recv、read等函数);这时会出现一个问题,就是我们在程序中调用的读取数据函数不能及时的把缓冲区中的数据拿出来,而下一个数据又到来并有一部分放入的缓冲区末尾,等我们读取数据时就是一个粘包。(放数据的速度 > 应用层拿数据速度)

OSI 的七层模型和tcp四层都有哪些?


get 和 post 请求有哪些区别?
- GET在浏览器回退时是无害的,而POST会再次提交请求。
- GET产生的URL地址可以被Bookmark,而POST不可以。
- GET请求会被浏览器主动cache,而POST不会,除非手动设置。
- GET请求只能进行url编码,而POST支持多种编码方式。
- GET请求参数会被完整保留在浏览器历史记录里,而POST中的参数不会被保留。
- GET请求在URL中传送的参数是有长度限制的,而POST么有。
- 对参数的数据类型,GET只接受ASCII字符,而POST没有限制。
- GET比POST更不安全,因为参数直接暴露在URL上,所以不能用来传递敏感信息。
- GET参数通过URL传递,POST放在Request body中。POST也可以将参数暴露在url地址里面。

若有收获,就点个赞吧
0 人点赞
