G : groutine 协程本身
M:线程,真正干活的
P:代表一个虚拟的 Processor,它维护一个处于 Runnable 状态的 g 队列,m 需要获得 p 才能运行 g
协程之所以可以大量并发,要得益于 M:N模型,也就是 M 个线程会承载 N 个协程的运行。
M:N 模型
我们都知道,Go runtime 会负责 goroutine 的生老病死,从创建到销毁,都一手包办。Runtime 会在程序启动的时候,创建 M 个线程(CPU 执行调度的单位),之后创建的 N 个 goroutine 都会依附在这 M 个线程上执行。这就是 M:N 模型:
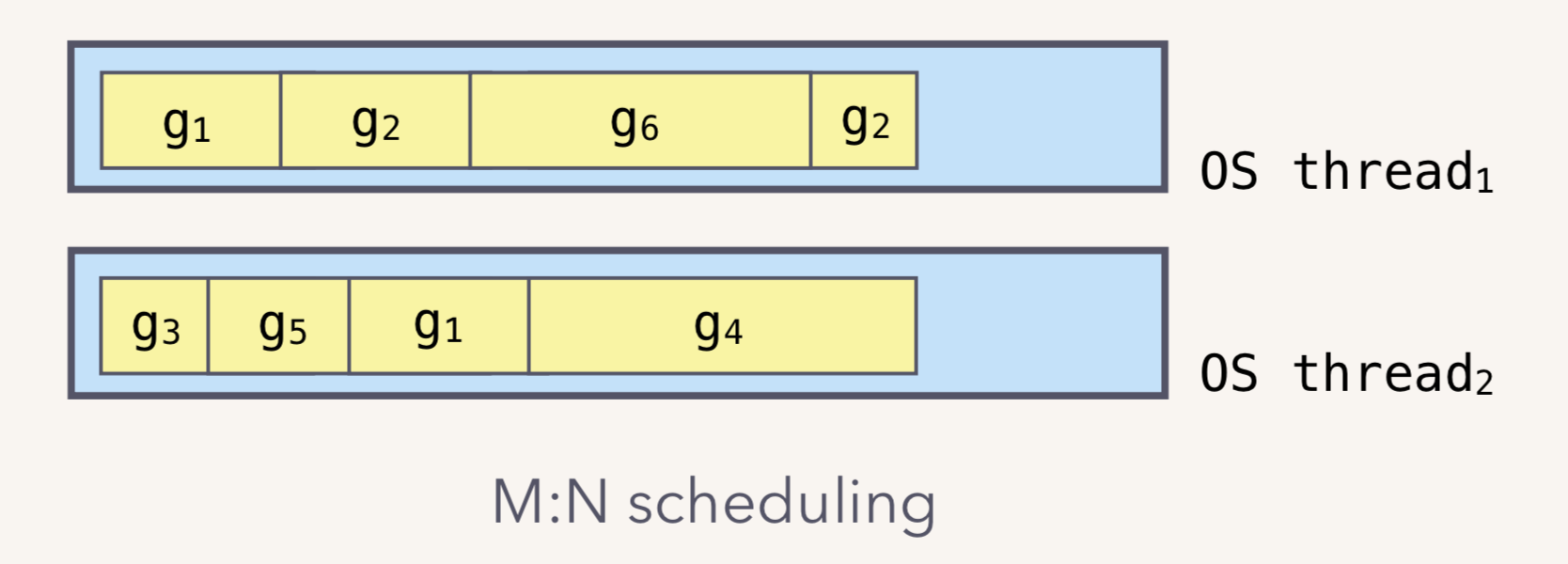
在协程阻塞的时候,调度器会将当前的 groutine 调度走,然后执行其他的 groutine,保证榨干 CPU 的所有油水。
Golang 的调度器
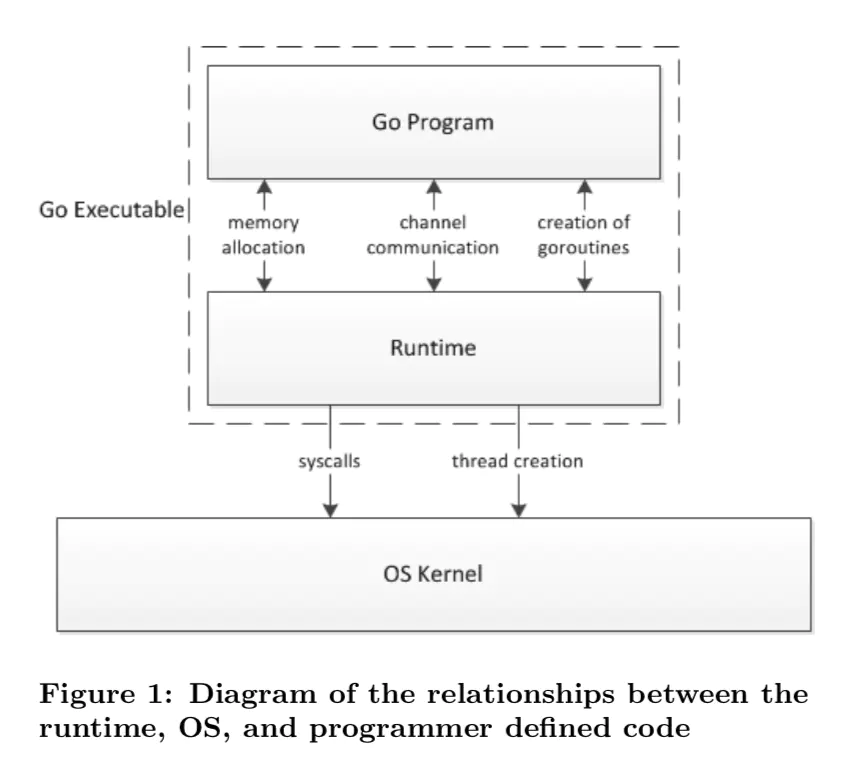
这张图展示了在 go 的世界里,一个程序的整体运行分布和架构,所有的资源创建和调度都是有 Runtime 层拦截去和内核进行打交道,所以 Runtime 层会帮助我们进行调度和垃圾回收等等一系列工作。
调度器的底层实现原理
Runtime 起始时会启动一些 G:垃圾回收的 G,执行调度的 G,运行用户代码的 G;并且会创建一个 M 用来开始 G 的运行。随着时间的推移,更多的 G 会被创建出来,更多的 M 也会被创建出来。
当然,在 Go 的早期版本,并没有 p 这个结构体,m 必须从一个全局的队列里获取要运行的 g,因此需要获取一个全局的锁,当并发量大的时候,锁就成了瓶颈。后来在大神 Dmitry Vyokov 的实现里,加上了 p 结构体。每个 p 自己维护一个处于 Runnable 状态的 g 的队列,解决了原来的全局锁问题。
Go scheduler 的核心思想是:
- reuse threads;
- 限制同时运行(不包含阻塞)的线程数为 N,N 等于 CPU 的核心数目;
- 线程私有的 runqueues,并且可以从其他线程 stealing goroutine 来运行,线程阻塞后,可以将 runqueues 传递给其他线程。
为什么需要 P 这个组件,直接把 runqueues 放到 M 不行吗?
You might wonder now, why have contexts at all? Can’t we just put the runqueues on the threads and get rid of contexts? Not really. The reason we have contexts is so that we can hand them off to other threads if the running thread needs to block for some reason. An example of when we need to block, is when we call into a syscall. Since a thread cannot both be executing code and be blocked on a syscall, we need to hand off the context so it can keep scheduling
也就是当一个线程阻塞的时候,将和它绑定的 P 上的 goroutines 转移到其他线程。
Go scheduler 会启动一个后台线程 sysmon,用来检测长时间(超过 10 ms)运行的 goroutine,将其调度到 global runqueues。这是一个全局的 runqueue,优先级比较低,以示惩罚
Go 程序启动后,会给每个逻辑核心分配一个 P(Logical Processor);同时,会给每个 P 分配一个 M(Machine,表示内核线程),这些内核线程仍然由 OS scheduler 来调度
在初始化时,Go 程序会有一个 G(initial Goroutine),执行指令的单位。G 会在 M 上得到执行,内核线程是在 CPU 核心上调度,而 G 则是在 M 上进行调度。
G、P、M 都说完了,还有两个比较重要的组件没有提到: 全局可运行队列(GRQ)和本地可运行队列(LRQ)。 LRQ 存储本地(也就是具体的 P)的可运行 goroutine,GRQ 存储全局的可运行 goroutine,这些 goroutine 还没有分配到具体的 P。
Go scheduler 使用 M:N 模型,在任一时刻,M 个 goroutines(G) 要分配到 N 个内核线程(M),这些 M 跑在个数最多为 GOMAXPROCS 的逻辑处理器(P)上。每个 M 必须依附于一个 P,每个 P 在同一时刻只能运行一个 M。如果 P 上的 M 阻塞了,那就将 M 从 绑定的 P 上摘开,其他的 M 会来和 P 绑定,来运行 P 的 LRQ 里的 goroutines。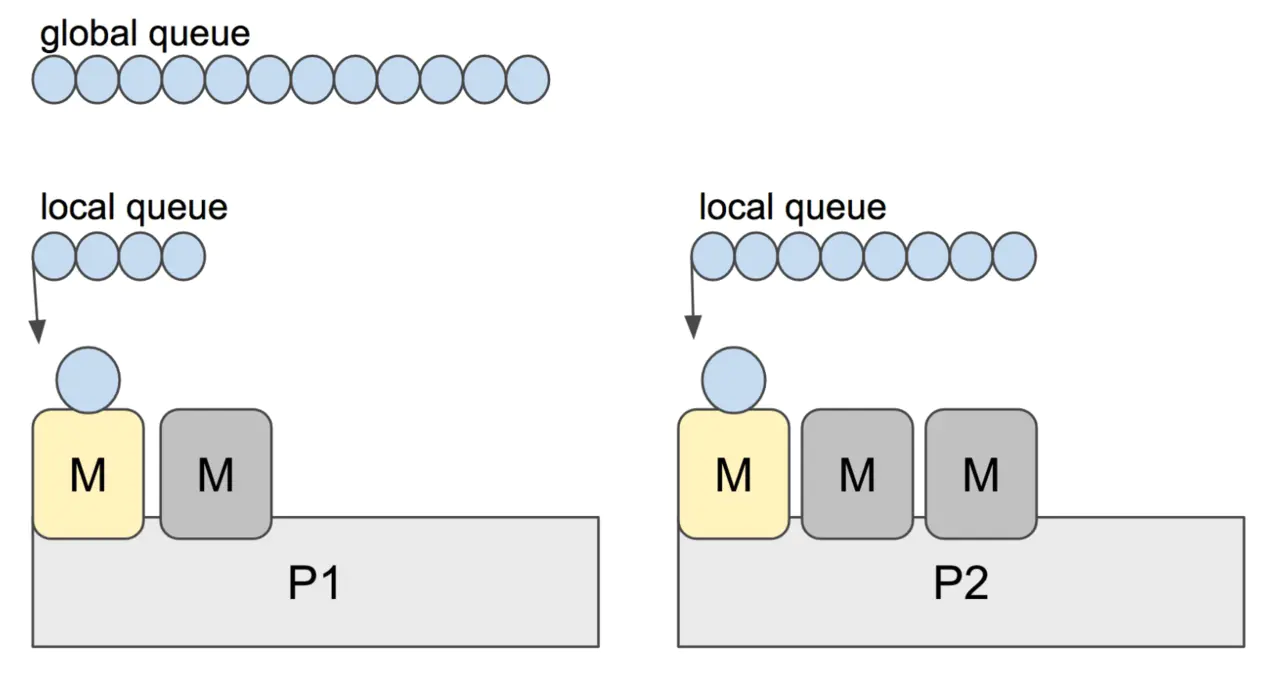
当 P2 上的一个 G 执行结束,它就会去 LRQ 获取下一个 G 来执行。如果 LRQ 已经空了,就是说本地可运行队列已经没有 G 需要执行,并且这时 GRQ 也没有 G 了。这时,P2 会随机选择一个 P(称为 P1),P2 会从 P1 的 LRQ “偷”过来一半的 G。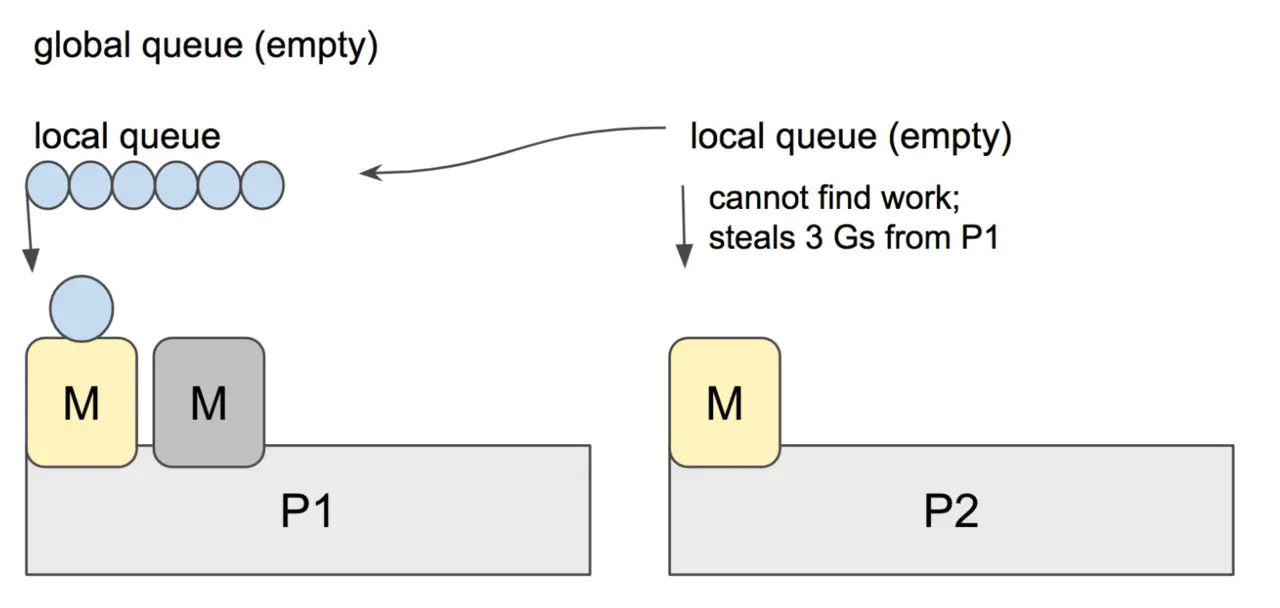
这样做的好处是,有更多的 P 可以一起工作,加速执行完所有的 G
同步/异步系统调用
当 G 需要进行系统调用时,根据调用的类型,它所依附的 M 有两种情况:同步和异步。
对于同步的情况,M 会被阻塞,进而从 P 上调度下来,P 可不养闲人,G 仍然依附于 M。之后,一个新的 M 会被调用到 P 上,接着执行 P 的 LRQ 里嗷嗷待哺的 G 们。一旦系统调用完成,G 还会加入到 P 的 LRQ 里,M 则会被“雪藏”,待到需要时再“放”出来。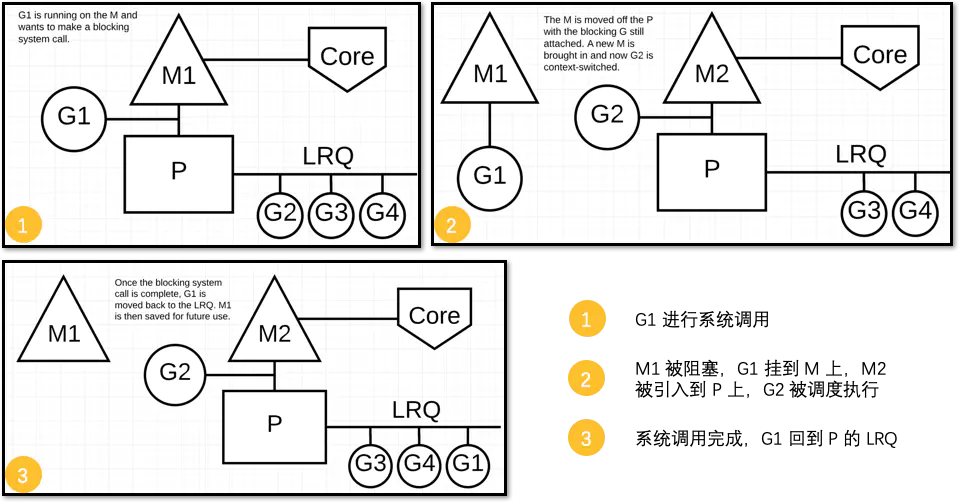
对于异步的情况,M 不会被阻塞,G 的异步请求会被“代理人” network poller 接手,G 也会被绑定到 network poller,等到系统调用结束,G 才会重新回到 P 上。M 由于没被阻塞,它因此可以继续执行 LRQ 里的其他 G。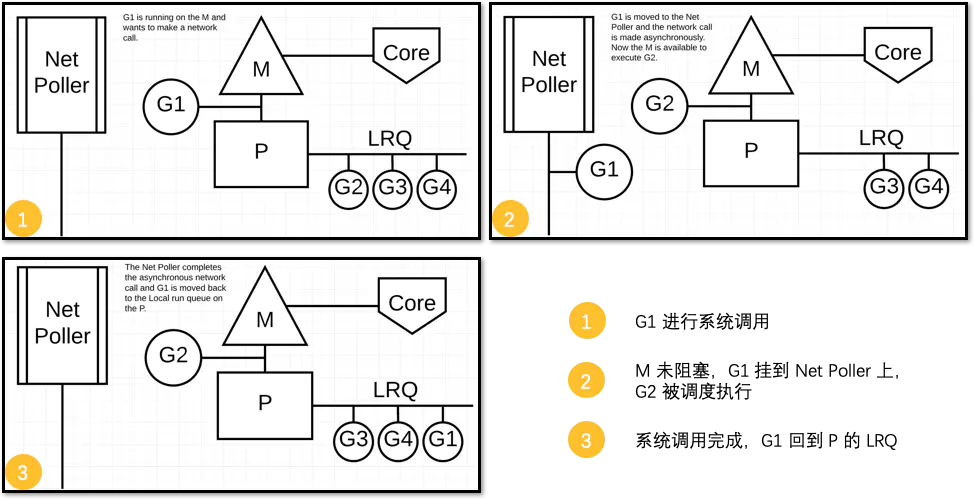
可以看到,异步情况下,通过调度,Go scheduler 成功地将 I/O 的任务转变成了 CPU 任务,或者说将内核级别的线程切换转变成了用户级别的 goroutine 切换,大大提高了效率。
scheduler 的陷阱
由于 Go 语言是协作式的调度,不会像线程那样,在时间片用完后,由 CPU 中断任务强行将其调度走。对于 Go 语言中运行时间过长的 goroutine,Go scheduler 有一个后台线程在持续监控,一旦发现 goroutine 运行超过 10 ms,会设置 goroutine 的“抢占标志位”,之后调度器会处理。但是设置标志位的时机只有在函数“序言”部分,对于没有函数调用的就没有办法了。
Golang implements a co-operative partially preemptive scheduler.
所以在某些极端情况下,会掉进一些陷阱。下面这个例子来自参考资料【scheduler 的陷阱】。
func main() {var x intthreads := runtime.GOMAXPROCS(0)for i := 0; i < threads; i++ {go func() {for { x++ }}()}time.Sleep(time.Second)fmt.Println("x =", x)}
运行结果是:在死循环里出不来,不会输出最后的那条打印语句。
为什么?上面的例子会启动和机器的 CPU 核心数相等的 goroutine,每个 goroutine 都会执行一个无限循环。
创建完这些 goroutines 后,main 函数里执行一条 time.Sleep(time.Second) 语句。Go scheduler 看到这条语句后,简直高兴坏了,要来活了。这是调度的好时机啊,于是主 goroutine 被调度走。先前创建的 threads 个 goroutines,刚好“一个萝卜一个坑”,把 M 和 P 都占满了。
在这些 goroutine 内部,又没有调用一些诸如 channel,time.sleep 这些会引发调度器工作的事情。麻烦了,只能任由这些无限循环执行下去了。
解决的办法也有,把 threads 减小 1:
func main() {var x intthreads := runtime.GOMAXPROCS(0) - 1for i := 0; i < threads; i++ {go func() {for { x++ }}()}time.Sleep(time.Second)fmt.Println("x =", x)}
运行结果:
x = 0
不难理解了吧,主 goroutine 休眠一秒后,被 go schduler 重新唤醒,调度到 M 上继续执行,打印一行语句后,退出。主 goroutine 退出后,其他所有的 goroutine 都必须跟着退出。所谓“覆巢之下 焉有完卵”,一损俱损。
至于为什么最后打印出的 x 为 0,之前的文章《曹大谈内存重排》里有讲到过,这里不再深究了。
还有一种解决办法是在 for 循环里加一句:
go func() {time.Sleep(time.Second)for { x++ }}()
同样可以让 main goroutine 有机会调度执行。
上面的代码中如果在死循环中 return 或者对 x 加锁的话,x 的值还是会被修改的。

若有收获,就点个赞吧
0 人点赞
