- 二叉树:
- 红黑树:
- B-Tree:
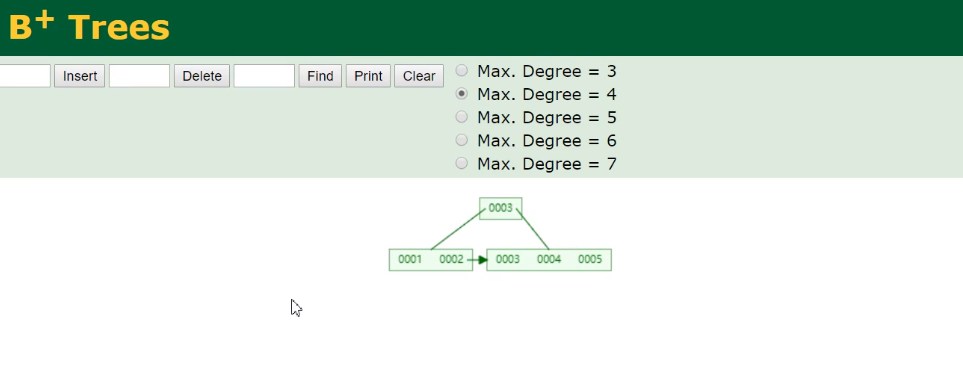
- B+Tree:
 ">
">



 ">hash索引:数组+链表的方式,数组存储的是hashcode
">hash索引:数组+链表的方式,数组存储的是hashcode
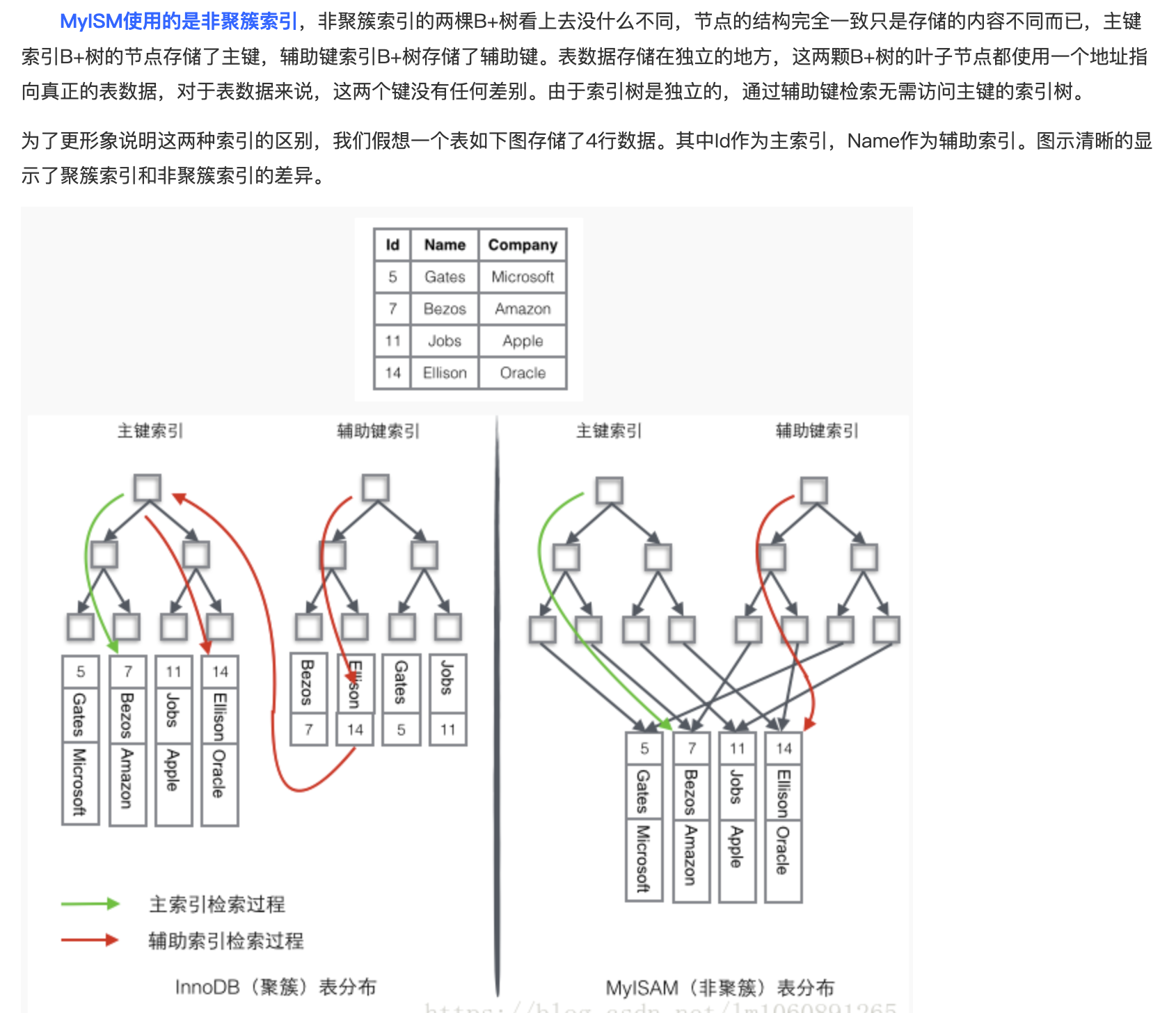
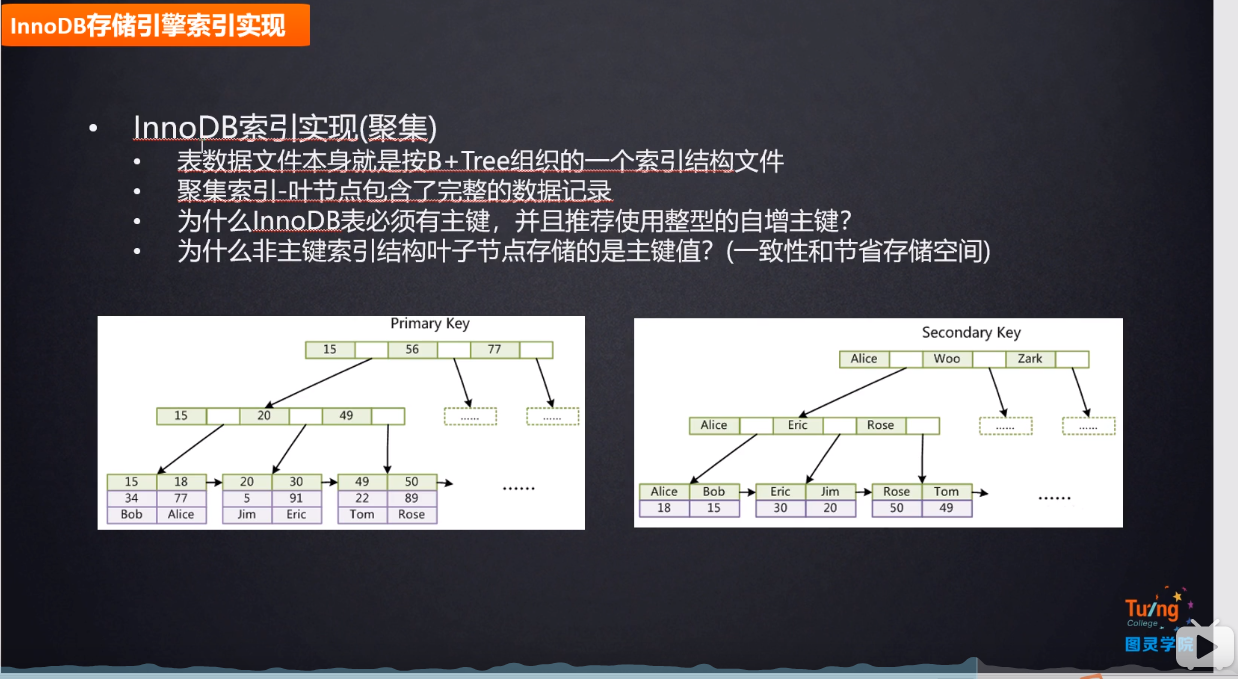
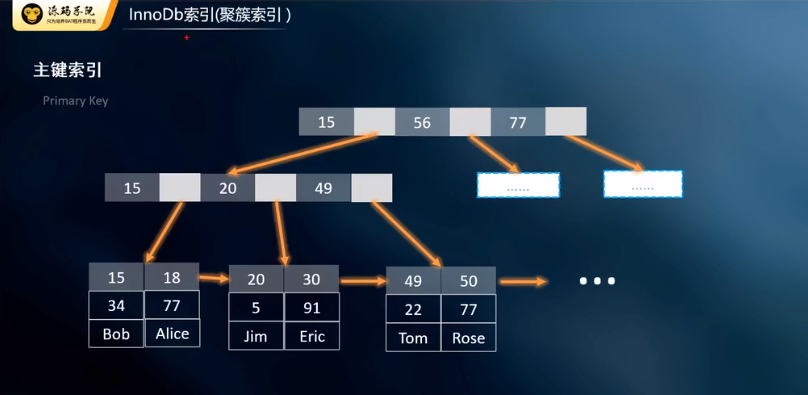
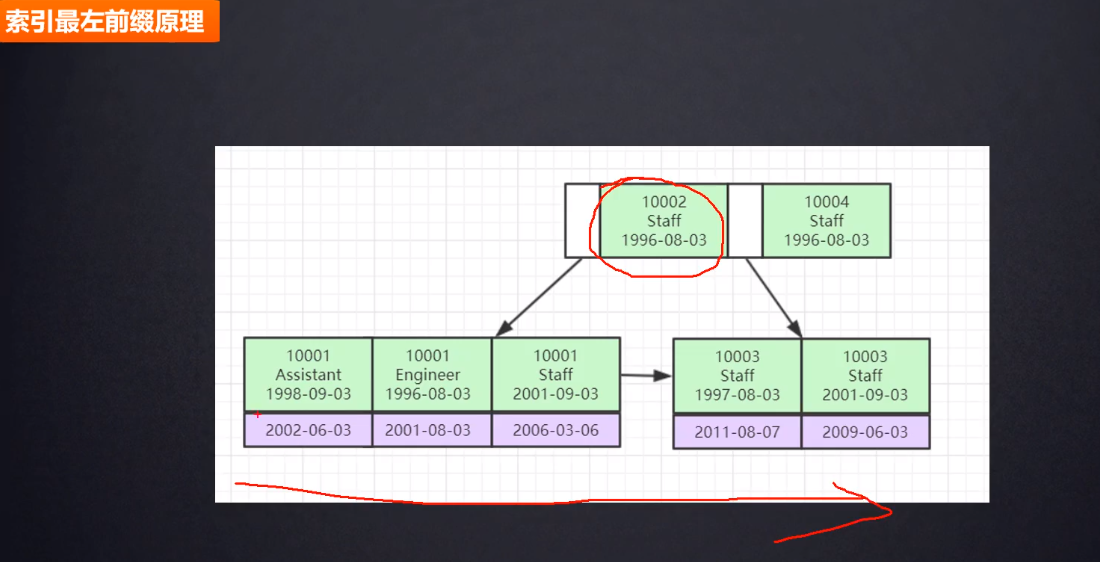
- 聚簇索引和非聚簇索引的区别:
- ">
- ">
- ">

 ">
">
 ">frm存储的是框架信息frame,ibd文件存储的是索引信息和数据信息
">frm存储的是框架信息frame,ibd文件存储的是索引信息和数据信息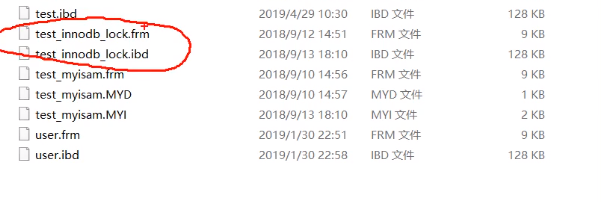
- ">非聚簇索引:叶子结点存储的主键索引的ID 先从非主键索引中找到主键索引的ID,再去主键索引(上表)中去查找数据
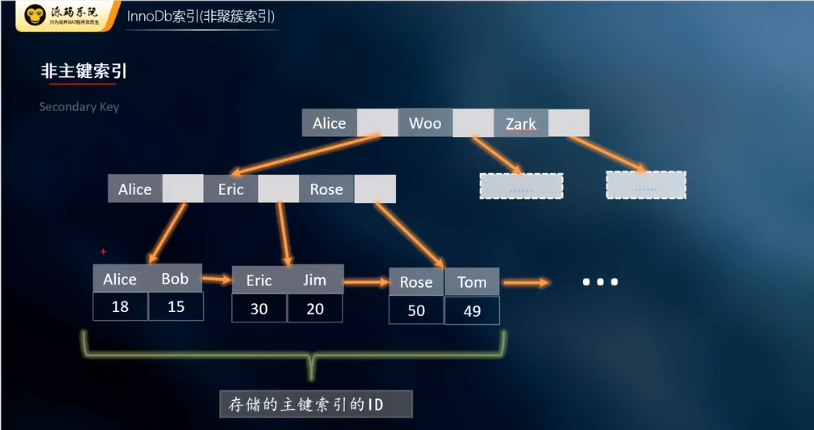
- 为什么非主键索引结构叶子结点存储的是主键值而不是数据?
- 为什么推荐使用整形的自增主键?(为什么innodb表必须有主键,并且推荐使用整型的自增主键?)
 Myisam索引(非聚簇索引)的数据结构形式:叶子节点存储的并不是数据,而是数据的地址。
Myisam索引(非聚簇索引)的数据结构形式:叶子节点存储的并不是数据,而是数据的地址。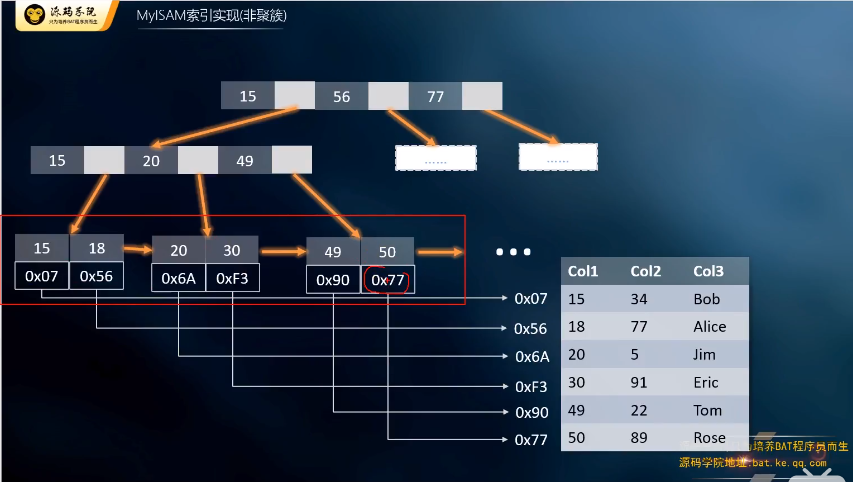
 ">
"> Myisam索引(非聚簇索引)的数据结构形式:叶子节点存储的并不是数据,而是数据的地址。
Myisam索引(非聚簇索引)的数据结构形式:叶子节点存储的并不是数据,而是数据的地址。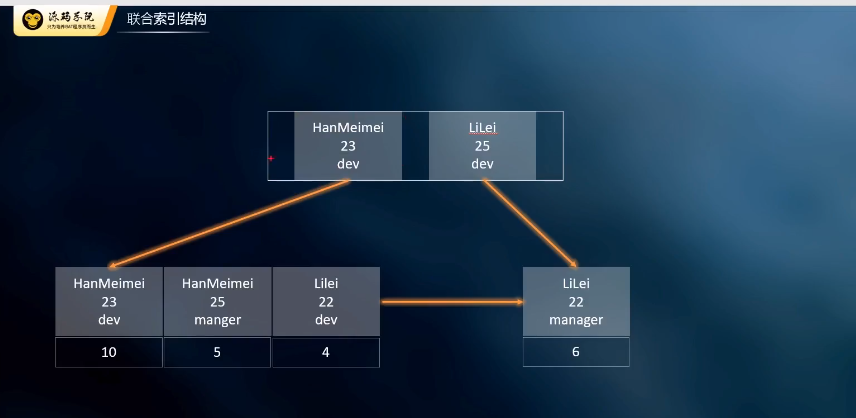
 ">如果是非主键索引的话(secondary key),叶子节点存储的只是主键索引的主键信息,然后再去主键索引中去查找数据,这么做的目的是为了一致性和节省存储空间,而主键索引存储的是一列的数据。
">如果是非主键索引的话(secondary key),叶子节点存储的只是主键索引的主键信息,然后再去主键索引中去查找数据,这么做的目的是为了一致性和节省存储空间,而主键索引存储的是一列的数据。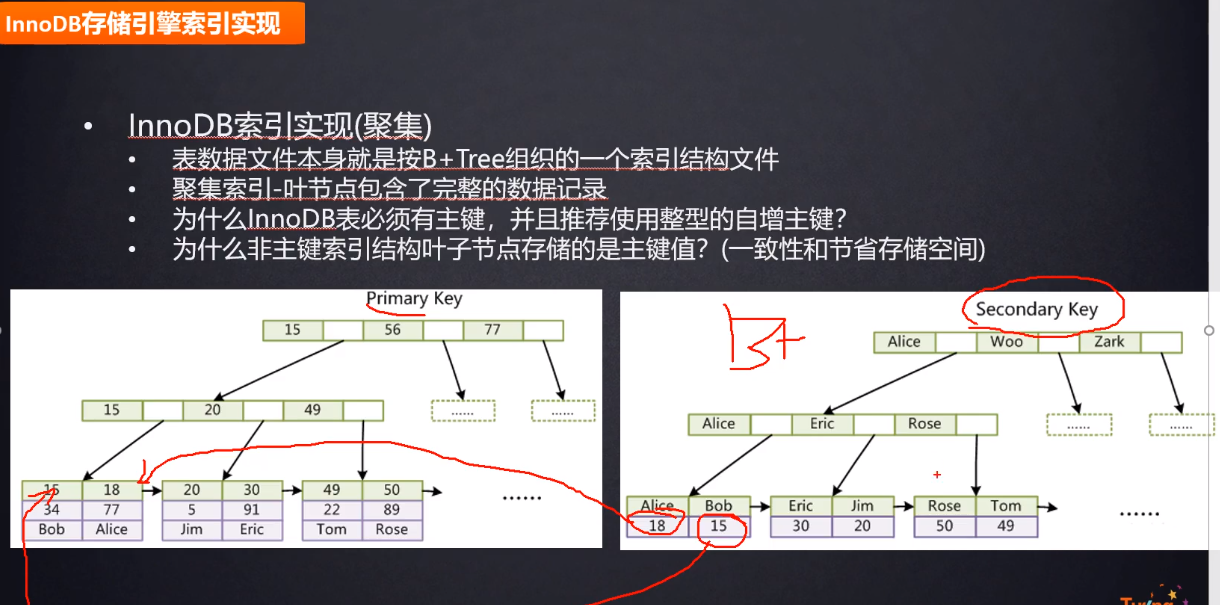
二叉树:
如果插入的数据都是按照顺序插入的,那么二叉树将退化成为线性链表。查询节点6将进行6次磁盘IO操作,引出红黑树。
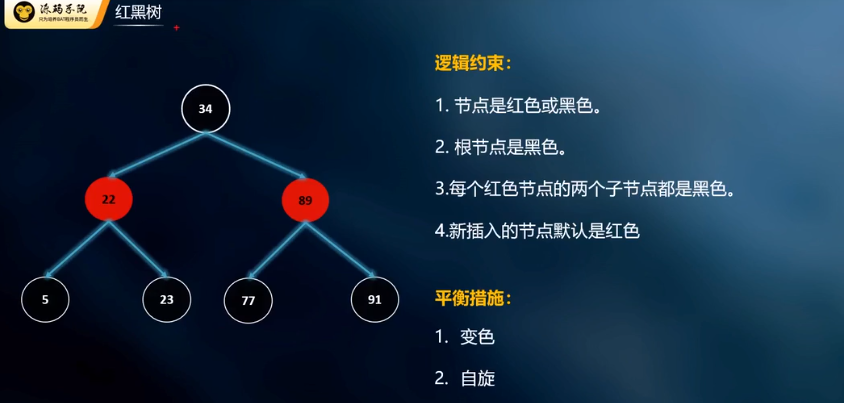
红黑树:
为了优化二叉树的问题加入了更多的约束,查询到结点6进行3次磁盘IO操作。缺点:mysql预读16k的数据,但是根节点中的数据比较少,浪费空间,引出B树。

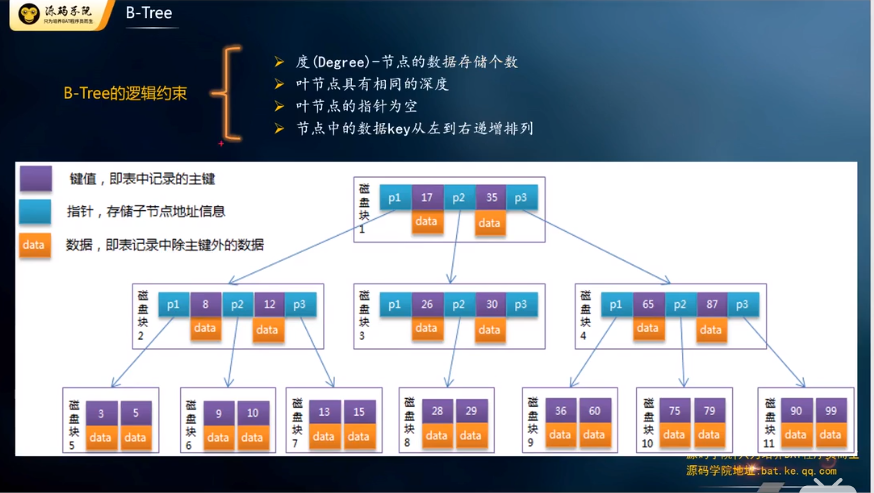
B-Tree:
https://blog.csdn.net/a519640026/article/details/106940115
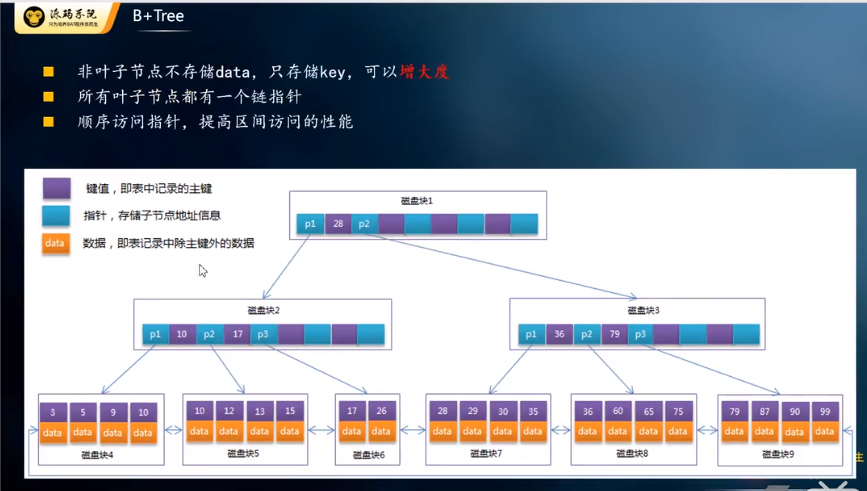
也就做B树:度是图中紫色的区域。数据越大,度的个数越小。
缺点:如果数据很多的话,树的高度将不可控,意味着磁盘IO的次数不可控。
B+Tree:
https://blog.csdn.net/luoyang_java/article/details/92781164
空白区域存的是下一个节点的地址,为6B(字节),15、56、77等占8B,16k/14B=1170,假设第三层存放的数据为1K大小,总共可以存放1170117016=21902400约2千2百万个数据。
主键ID为bigint类型,长度为8字节,长度为8字节,而指针大小在InnoDB源码中设置为6字节,这样一共14字节
hash索引:数组+链表的方式,数组存储的是hashcode
聚簇索引和非聚簇索引的区别:
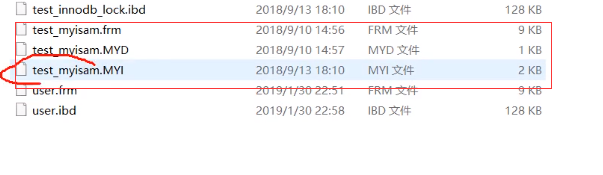
fm文件存储的是框架信息(frame),MYD文件,MY的myisam的前两个字母,D是date,MYI中的i是index,是索引信息。
总结的挺不错:https://www.cnblogs.com/jiawen010/p/11805241.html
frm存储的是框架信息frame,ibd文件存储的是索引信息和数据信息
非聚簇索引:叶子结点存储的主键索引的ID 先从非主键索引中找到主键索引的ID,再去主键索引(上表)中去查找数据
为什么非主键索引结构叶子结点存储的是主键值而不是数据?
1、若每个非主键索引都存储一下数据,那么将非常浪费存储空间,因为相同的数据可能要存很多次,虽然IO次数增多,但是减少了存储容量,以时间换空间。
2、若是存储很多次,那么在进行数据库的更新操作时将更新多个索引结构。
重要:https://www.cnblogs.com/williamjie/p/11081081.html
MyISAM与InnoDB 的区别:
https://blog.csdn.net/qq_35642036/article/details/82820178
为什么推荐使用整形的自增主键?(为什么innodb表必须有主键,并且推荐使用整型的自增主键?)
1、innodb表就是靠主键来维护数据结构的,所以必须要有主键,如果没有,innodb会自动选一列数据没有重复的列来当主键,如果没有找到一列数据是唯一的,则innodb会自动生成一个uuid列来作为主键来维护表的结构。(uuid不是整型,也不是自增的,是一个字符串)
2、使用uuid形式的数据大,占用存储空间,如果使用整型,可以使一个节点(16K)装下更多的数据
3、索引查找时,使用整形比较会比较快。(比较1<2的速度比sef123
Myisam索引(非聚簇索引)的数据结构形式:叶子节点存储的并不是数据,而是数据的地址。
如果是非主键索引的话(secondary key),叶子节点存储的只是主键索引的主键信息,然后再去主键索引中去查找数据,这么做的目的是为了一致性和节省存储空间,而主键索引存储的是一列的数据。

若有收获,就点个赞吧
0 人点赞
