1.checkpoint是什么?
checkpoint的目的是用来指定程序从某一个工作任务状态下进行恢复,而这个“一系列状态”存储在状态后端。这里不得不提到状态一致性。也就是说,它可以作为我们flink任务的一个“起点”,往后继续运行程序。它的目的就是保证我们程序的结果一致性!!咱们先说一下状态一致性:
2.状态一致性
2.1什么是状态一致性?
什么是状态一致性?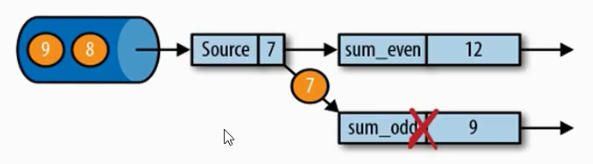
- 有状态的流处理,内部每个算子任务都可以有自己的状态。
- 对于流处理器内部来说,所谓的状态的一致性,其实就是我们所说的计算结果要保证准确。
- 一条数据不应该丢失,也不应该重复计算。
- 在遇到故障时可以恢复状态,恢复以后的重新计算,结果应该也是完成正确的。
2.2状态一致性分类
AT-MOST-ONCE(最多一次)
当任务故障时,最简单的做法就是什么都不干,既不恢复丢失的状态,也不重播丢失的数据。他的含义是最多处理一次事件。针对没有checkpoint的开销,对一些任务准确性不高,延迟一定要低的任务。
AT-LEAST-ONCE(至少一次)
在大多数的真实应用场景,我们希望不丢失事件。这种类型的保障成为AT-LEAST-ONCE,意思就是所有的事件都得到了处理,而一些事件还可能被处理多次。
EXACTLY-ONCE (精准一次)
恰好处理一次是最严格的保证,也是最难实现的。恰好处理一次语义不仅仅意味着没有事件丢失,还意味着针对每一个数据,内部状态仅仅更新一次。
2.3一致性检查点(checkpoints)
- Flink使用了一种轻量级快照机制———检查点(checkpoint)来保证exactly-once语义
- 有状态流应用的一致检查点,其实就是:所有任务的一个状态,在某一个时刻的快照。而这个时间点,应该是所有任务都恰好处理完一个相同输入数据的时候。
- 应用状态的一致性检查点,是Flink故障恢复机制的核心。
2.4端到端(end-to-end)的状态一致性
除了Flink本身 ,还要考虑source和sink
- 目前我们看到的一致性保证都由流处理器实现的,也就是说都是在Flinkj流处理器内部保证的;而在真实应用中,流处理应用除了流处理器之外还包含了数据源(例如kafka)和输出到持久化系统。
- 端到端的一致性保证,意味着结果的正确性贯穿了整个流处理的始终;每一个组件都保证了它自己的一致性
- 整个端到端的一致性级别取决于所有组件中一致性最弱的组件
内部保证———checkpoint
source端———可重设数据的读取位置,就是偏移量
sink端———从故障恢复时,数据不会重复写入外部系统
其中,sink端是我们需要自己实现的,不然可能会有重复数据,两种方式实现
幂等写入:
所谓幂等操作,是说一个操作,可以重复执行很多次,但是只导致一次结果更改,也就是说,后面再重复执行就不生效了,如图
例如 hashMap的多次相同key的写入,mysql等等。有一定问题,会出现“情景再现”。例如温度计监控会出现10->15->20->10->15->20->25
事务写入:
事务(Transaction)
应用程序中一系列严密的操作,所有操作必须成功完成,否则在每个操作中所做的修改都会被撤销
具有原子性:一个事务中的一系列操作要么全部成功,要么全部失败回滚。
实现思想:
构建的事务对应着checkpoint,等到checkpoint真正完成的时候,才把所有对应的结果写入sink系统中。checkpoint完成时候是所有操作都完成的时候,保证数据一致
实现方式:
预写日志(Write-Ahead-Log,WAL):
- 把结果数据先当成状态保存,然后在收到checkpoint完成的通知时,一次性写入sink系统- 简单易于实现,由于数据提前在状态后端中做了缓存,所以无论什么sink系统,都能用这种方式一批搞定- DataStream API提供了一个模板类:GenericWriteAheadSink,来实现这种事务性sink
有问题:第一:变成了批处理,可能时间很短,但还是批处理一次写入。延迟性增大
第二:有一些外部系统,做到一半失败了。下一次写入会出现重复数据
两阶段提交:**(最完美的方式)**
- 对于每一个checkpoint,sink任务会启动一个事务,并将接下来所有接受的数据添加到事务里- 然后将这些数据写入外部sink系统,但不提交他们------这时只是“预提交”- 当它收到checkpoint完成的通知时,他才正式提交事务,实现结果的真正写入
这种方式真正实现了exactly-once,他需要一个提供事务支持的外部sink系统。Flink提供了TwoPhaseCommitSinkFunction接口。
2PC对外部sink系统的要求,如果想自定义实现的话。目前Flink内部支持kafka
- 外部sink系统必须支持提供事务支持,或者sink任务必须能够模拟外部系统上的事务
- 在chekpoint的间隔期里,必须能够开启一个事务并接受数据的写入
- 在收到checkpoint完成的通知之前,事务必须是“等待提交”的状态。在故障恢复的情况下,这时候需要一些时间。如果这个时候sink系统关闭事务(例如超时了),那么未提交的数据就会丢失
- sink任务必须能够在进程失败后恢复事务
- 提交事务必须是幂等操作
2.5不同的Source和Sink的一致性保证
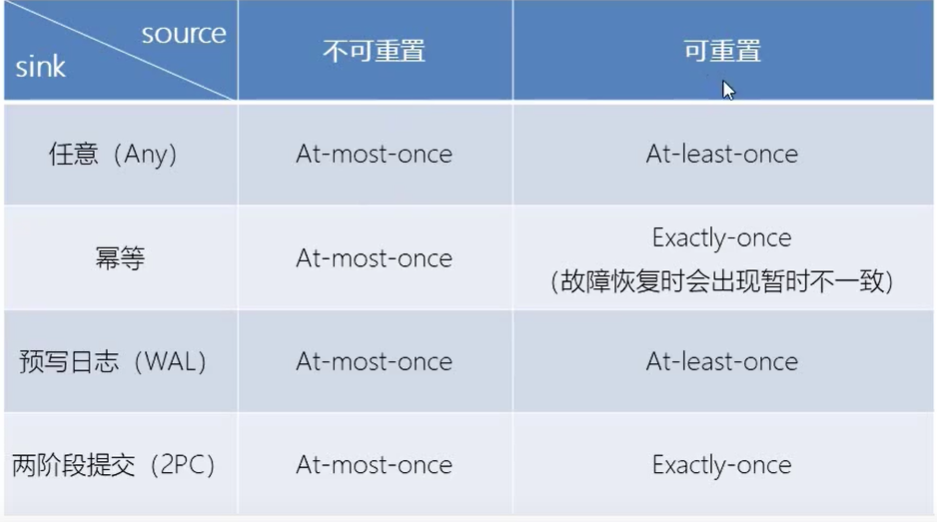
Flink+kafka端到端状态一致性的保证
- 内部———利用checkpoint机制,把状态存盘,发生故障的时候可以恢复,保证内部的状态的一致性。
- source———kafka consumer作为source,可以将偏移量保存下来,如果后续任务出现了故障,恢复的时候可以由连接器重置偏移量,重新消费数据,保证一致性。
- sink———kafka producer作为sink,采用两阶段提交sink,需要实现一个TwoPhaseCommitSinkFunction
Exactly-once两阶段提交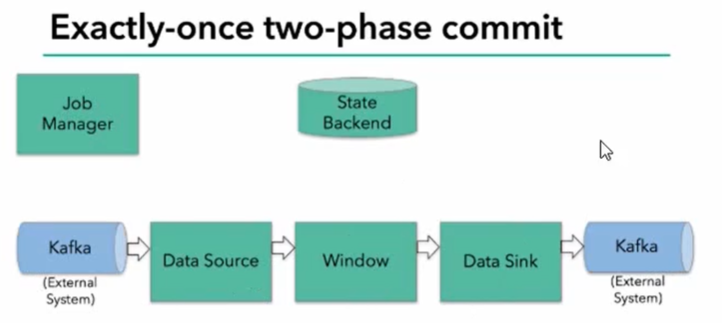
- JobManager协调各个TaskManager进行checkpoint存储
- checkpoint保存在StateBackend中,默认StateBackend是内存级别的,墙裂推荐文件级别的进行持久化保存
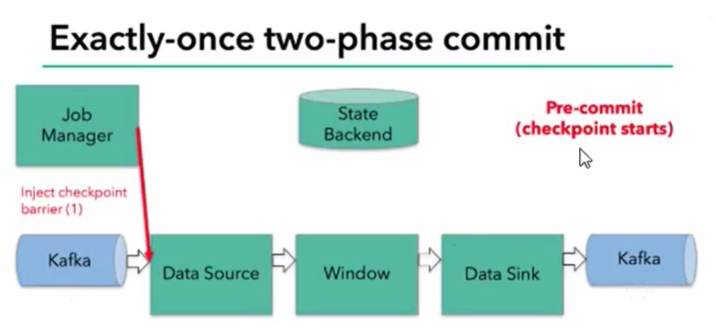
- 当checkpoint启动时,JobManager会将检查点分界线(barrier)注入数据流
- barrier会在算子间传递下去
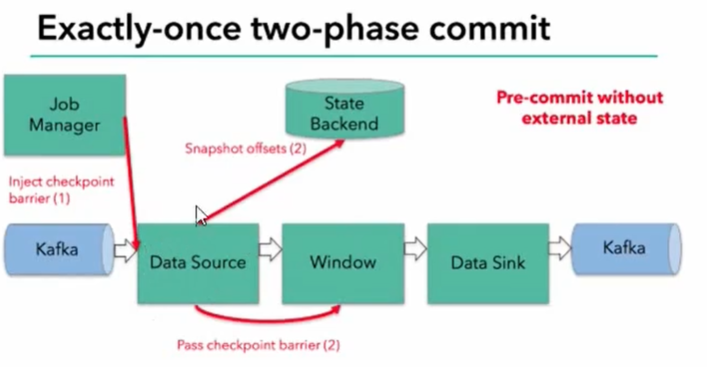
- 每个算子会对当前的状态做个快照,保存到状态后端
- checkpoint机制可以保证内部的状态一致性
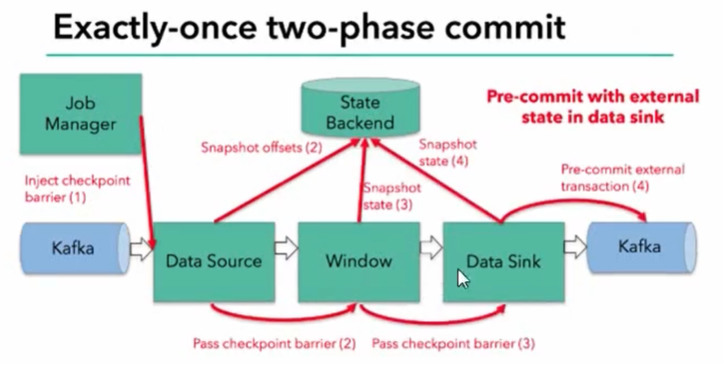
- 每个内部的transform任务遇到barrier时,都会把状态存到checkpoint里
- sink任务首先把数据写入外部kafka,这些数据都属于预提交的事务;遇到barrier时,把状态保存到状态后端,并开启新的预提交事务
遇到一个barrier之后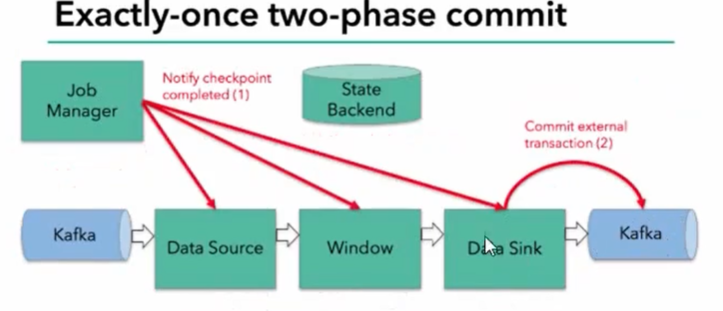
- 当所有算子任务的快照完成,也就是这次的checkpoint完成时,JobManager会向所有任务发通知,确认这次checkpoint完成
- sink任务收到确认通知,正式提交之前的事务,kafka中未确认数据改为“已确认”
Exactly-once两阶段提交步骤
- 第一条数据来了之后,开始一个kafka事务,正常写入kafka分区但是标记为未提交,这就是“预提交”
- jobmanager触发checkpoint操作,barrier从source开始向下传递,遇到barrier的算子将状态存入状态后端,并通知jobmanager
- sink连接器收到barrrier,保存当前状态,存入checkpoint,通知jobmanager,并开启下一阶段吧事务,用于提交下个检查点的数据
- jobmanager收到所有任务的通知,发出确认信息,表示checkpoint完成
- sink任务收到jobmanager的确认消息,正式提交这段时间的数据
- 外部kafka关闭事务,提交的数据可以正常消费了
3.代码演示
说了这么多理论知识,那么在实际程序中,它是如何实现的呢?参考官网Flink-checkpoint
3.1前提条件(上面提过,省略)
3.2开启与配置 Checkpoint
默认情况下 checkpoint 是禁用的。通过调用 StreamExecutionEnvironment 的 enableCheckpointing(n) 来启用 checkpoint,里面的n是进行 checkpoint 的间隔,单位毫秒。
val chkpConfig = env.getCheckpointConfig//多久一次Checkpoint 10s,jobManager给source任务的间隔。这个是触发的时间chkpConfig.setCheckpointInterval(10000L)//状态一致性的级别。默认就是EXACTLY_ONCEchkpConfig.setCheckpointingMode(CheckpointingMode.EXACTLY_ONCE)//一分钟超时时间,超过就丢弃chkpConfig.setCheckpointTimeout(60000L)//一般配置以上三个即可//最大并行Checkpoints数量2.最多允许两个checkpoint在当前任务里chkpConfig.setMaxConcurrentCheckpoints(2)//两次checkpoint的最小间隔时间。第一次的尾和第二次的头chkpConfig.setMinPauseBetweenCheckpoints(500L)//是否更倾向于用checkpoint做故障恢复,还有savepoint。默认是falsechkpConfig.setPreferCheckpointForRecovery(true)//可容忍checkpoint故障次数,0容忍chkpConfig.setTolerableCheckpointFailureNumber(0)
3.3选择一个状态后端 State Backend
有的小可爱们就要问了,什么是状态后端?他能干嘛?别急,我来一一道来。
在启动 CheckPoint 机制时,状态会随着 CheckPoint 而持久化,以防止数据丢失、保障恢复时的一致性。 状态内部的存储格式、状态在 CheckPoint 时如何持久化以及持久化在哪里均取决于选择的 State Backend。也就是说,checkpoint是我们当前任务的状态数据集合,而这个数据保存到哪里和我们选择哪个状态后端有关。
3.3.1 可用的State Backends
Flink 内置了以下这些开箱即用的 state backends :
- MemoryStateBackend
- FsStateBackend
- RocksDBStateBackend
如果不设置,默认使用 MemoryStateBackend。由于内存断电即失。墙裂不建议使用!!!不然打屁股╭(╯^╰)╮。想仔细了解它的推荐看官网Flink-state backend。
3.3.2选择最合适的状态后端
我们来说说FsStateBackend和RocksDBStateBackend
- FsStateBackend
FsStateBackend 需要配置一个文件系统的 URL(类型、地址、路径),例如:”hdfs://127.0.0.1:9000/flink/checkpoints” 或 “file:///data/flink/checkpoints”。一般我们都会配置在分布式文件系统中,选用hdfs。如果你的项目部署和hdfs在同一个服务器,可以简写成“hdfs:///flink/checkpoints”,注意三个斜线“///”不要丢!!!idea maven开发的时候别忘记导入 hadoop依赖,我这里导入的是
<dependency><groupId>org.apache.hadoop</groupId><artifactId>hadoop-client</artifactId><version>2.7.4</version></dependency>
亲测能用!!可能会有多余依赖,暂时没考虑这么多,O(∩_∩)O哈哈~。
FsStateBackend 将正在运行中的状态数据保存在 TaskManager 的内存中。CheckPoint 时,将状态快照写入到配置的文件系统目录中。 少量的元数据信息存储到 JobManager 的内存中(高可用模式下,将其写入到 CheckPoint 的元数据文件中)。
FsStateBackend 默认使用异步快照来防止 CheckPoint 写状态时对数据处理造成阻塞。 用户可以在实例化 FsStateBackend 的时候,将相应布尔类型的构造参数设置为 false 来关闭异步快照,例如:
new FsStateBackend(path, false);
FsStateBackend 适用场景:
- 状态比较大、窗口比较长、key/value 状态比较大的 Job。
- 所有高可用的场景。
建议同时将 managed memory 设为0,以保证将最大限度的内存分配给 JVM 上的用户代码。
- RocksDBStateBackend
同样的,RocksDBStateBackend 也需要配置一个文件系统的 URL (类型、地址、路径),例如:”hdfs://namenode:40010/flink/checkpoints” 或 “file:///data/flink/checkpoints”。
这么来看,好像它与FsStateBackend 也没区别呀?
**
RocksDBStateBackend 将正在运行中的状态数据保存在 RocksDB 数据库中,RocksDB 数据库默认将数据存储在 TaskManager 的数据目录。 CheckPoint 时,整个 RocksDB 数据库被 checkpoint 到配置的文件系统目录中。 少量的元数据信息存储到 JobManager 的内存中(高可用模式下,将其存储到 CheckPoint 的元数据文件中)。
RocksDBStateBackend 只支持异步快照。
RocksDBStateBackend 的限制:
- 由于 RocksDB 的 JNI API 构建在 byte[] 数据结构之上, 所以每个 key 和 value 最大支持 2^31 字节。 重要信息: RocksDB 合并操作的状态(例如:ListState)累积数据量大小可以超过 2^31 字节,但是会在下一次获取数据时失败。这是当前 RocksDB JNI 的限制。
RocksDBStateBackend 的适用场景:
- 状态非常大、窗口非常长、key/value 状态非常大的 Job。
- 所有高可用的场景。
注意,你可以保留的状态大小仅受磁盘空间的限制。与状态存储在内存中的 FsStateBackend 相比,RocksDBStateBackend 允许存储非常大的状态。 然而,这也意味着使用 RocksDBStateBackend 将会使应用程序的最大吞吐量降低。 所有的读写都必须序列化、反序列化操作,这个比基于堆内存的 state backend 的效率要低很多。(请熟读并选择你自己的方式)。
官网提供的与RocksDBStateBackend 相关的三个文档,有兴趣可以参考,不在本章讲解。
- 请同时参考 Task Executor 内存配置 中关于 RocksDBStateBackend 的建议。
- RocksDBStateBackend 是目前唯一支持增量 CheckPoint 的 State Backend (见 这里)。
- 可以使用一些 RocksDB 的本地指标(metrics),但默认是关闭的。你能在 这里 找到关于 RocksDB 本地指标的文档。
三种状态后端全家福:
//字节数int 1024mbenv.setStateBackend(new MemoryStateBackend(1024 * 1024, false))env.setStateBackend(new FsStateBackend("hdfs:///flink-checkpoints/xx", true))env.setStateBackend(new RocksDBStateBackend("hdfs:///flink-checkpoints/xx", true))
3.4重启策略
当 Task 发生故障时,Flink 需要重启出错的 Task 以及其他受到影响的 Task ,以使得作业恢复到正常执行状态。
Flink 通过重启策略和故障恢复策略来控制 Task 重启:重启策略决定是否可以重启以及重启的间隔;故障恢复策略决定哪些 Task 需要重启。
详细参考官网Flink-重启策略,我会在之后的章节展开说明。下面是我的配置。意思是5分钟以内,重启5次,每次间隔10秒钟,成功了之后就不往后执行,直到执行完成,5次之后还是失败,就退出。
env.setRestartStrategy(RestartStrategies.failureRateRestart(5, Time.minutes(5), Time.seconds(10)))
4.使用命令进行提交作业和checkpoint恢复
4.1Web UI 和 命令两种方式
Flink有自己的web控制台页面,通过jar上传的形式来提交作业。但是作为一名程序员,在实际工作中还是以命令的形式来提交作业。因为你是程序员!!!
我还是贴上界面操作的方式,百度了下下:
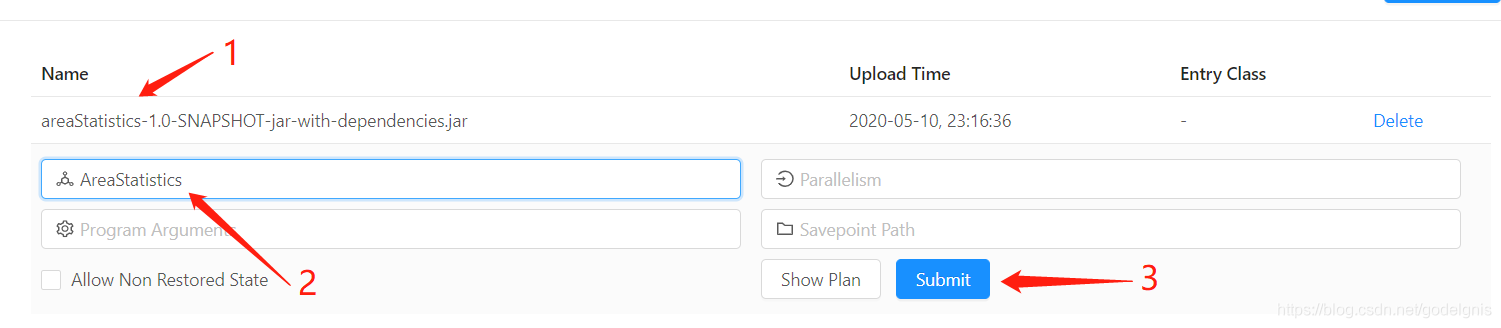
不对图做解释,一目了然。
使用命令,进入Flink安装目录
bin/flink run \-c com.hxonline.test.CDC_01 \-s hdfs://hostName:9000/flink-checkpoints/t_test_to/2465d223b259a3df5c5b9c923689b2ca/chk-1910 \/home/hxonline/project/flink/flink-1.0-SNAPSHOT-jar-with-dependencies.jar
-c :指定mainClass程序
-s:指定checkpoint的位置,后面的2465d223b259a3df5c5b9c923689b2ca是系统随机对当前任务生成uuid,chk-1910表示从哪一次进行恢复。
注意:1.flink的checkpoint路径需要修改权限,否则其他人可能无法访问。
2.路径一定要写对,hdfs://hostName:9000/flink-checkpoints/t_test_to/2465d223b259a3df5c5b9c923689b2ca/chk-1910,不然运行时找不到对应路径,任务不会从checkpoint恢复,而是从最新的位置开始。会丢失数据。
详细的命令解释参考Flink-命令运行
4.2其他注意事项
- 程序打包部署可能会报错,修改flink配置文件。
vim flink-conf.yaml
将classloader.resolve-order: child-first 改成 classloader.resolve-order: parent-first。
错误原因:idea 本地的依赖包和 flink/lib下自带的jar包冲突,这里改成parent-first启动Flink-双亲委派机制,默认是禁止的。
# 类加载解析顺序,是先检查用户代码 jar(“child-first”)还是应用程序类路径(“parent-first”)。 默认设置指示首先从用户代码 jar 加载类classloader.resolve-order: parent-first
- 默认看到的checkpoint是一个。
例如地址:hdfs://hostName:9000/flink-checkpoints/5c5b9c923689b2ca/chk-1。
chk-1会根据你设置的checkpoint的时间规律的变化chk-2,chk-3………..。原因是conf/flink-conf.yaml 中默认设置。
| state.checkpoints.num-retained | 1 | Integer | The maximum number of completed checkpoints to retain |
|---|---|---|---|

若有收获,就点个赞吧
0 人点赞
