什么是索引?
MySQL 对索引的官方定义:高效获取数据的数据结构。
索引可简单理解为排好序的快速查找数据结构。
使用索引的目的是为了提高查询效率。作用好比书籍目录。书籍目录本身是需要占据书籍篇幅的,但书籍目录的存在可以提高查询效率。另外书籍内容的改变,目录也要相应地发生改变。
在数据之外,数据库中除了数据表外,还维护了满足特定算法的数据结构,这些数据结构以某种方式指向(引用)数据。
Student s = new Student();s是引用,new Student()是数据。
下图为索引的一个示例: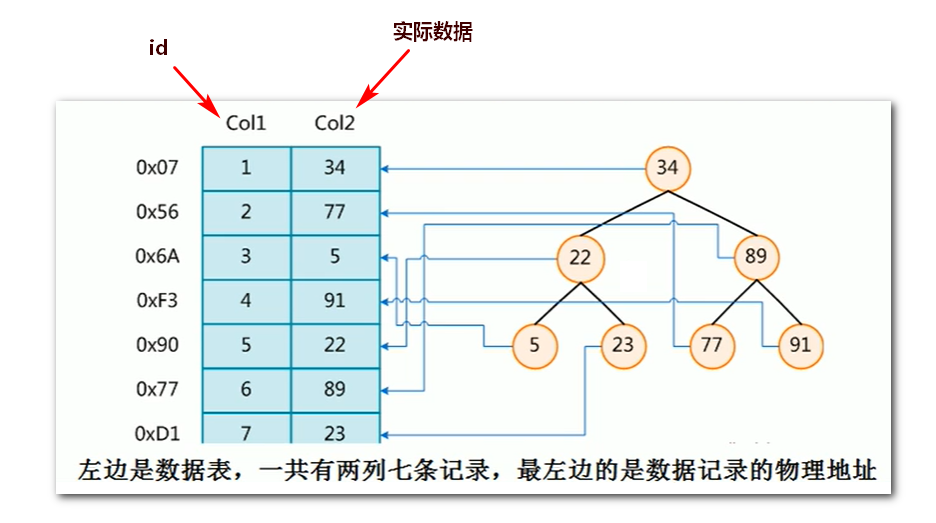
我们要查找 Col2 中的数据,为了加快查询,可以维护一个右边所示的二叉查找树,该树的每个节点包含一个 Col2 中的数据和一个指向对应数据物理地址的指针,这样就可以快速地检索到想要的数据。
一般来说,索引本身也很占空间,不可能全部存在内存中,因此索引往往以索引文件的形式存在磁盘中。
我们平常所说的索引,若没有特别指明,都是指 B 树(多路搜索树,不一定是二叉的)结构。其中,聚集索引、次要索引、复合索引、前缀索引和唯一索引默认都是使用 B+ 树索引,统称索引。除了 B+ 树这种索引以外,还有哈希索引。
为什么频繁删改的数据不适合建索引?
索引的优势:
- 提高数据检索效率
- 通过索引列对数据进行排序,降低数据排序的成本
索引的劣势:
- 索引也是一张表,该表保存了主键和索引字段,并指向实体表的记录,这需要占用空间
- 虽然索引大大提高了查询速度,但却会降低更新(增删改)表的速度。为什么?
- 索引只是提高效率的一个因素,若你的 MySQL 有大数据量的表,就需要花时间建立最优秀的索引,或优化查询语句。
MySQL 索引的分类
单值索引
唯一索引
复合索引
基本语法
创建索引:
-- 方式一create [unique] index index_name on table_name(col_name(length));-- 方式二alter table_name add [unique] index [index_name] on (col_name(length));
删除索引:
drop index [index_name] on table_name;
查看索引:
show index from table_name\G;
创建不同的索引:
-- 添加一个主键(主键其实就是一种唯一索引),该种索引必须是唯一的,且不能为NULLalter table tb_name add primary key (column_list);-- 这条语句创建的索引的值必须是唯一的(除了NULL外,NULL可出现多次)alter table tb_name add unique index_name (column_list);-- 添加普通索引,索引值可重复alter table tb_name add index index_name (column_list);-- 创建全文索引alter table tb_name add fulltext index_name (column_list);
MySQL 索引结构

若有收获,就点个赞吧
0 人点赞
