索引数据结构
数据例子:
| (内存地址) | col1 | col2 |
|---|---|---|
| 0x13 | 1 | 34 |
| 0x65 | 2 | 77 |
| 0x45 | 3 | 5 |
| 0x17 | 4 | 19 |
| 0x66 | 5 | 22 |
| 0x78 | 6 | 89 |
| 0x99 | 7 | 23 |
无数据结构
我们要查询col1=6的数据,需要把在整个表中去一行行遍历,最后的查询次数是6次
二叉树
二叉树左边的节点比父节点小,右边节点比父节点大。
我们要查询col1=6的数据,因为在主键递增的情况下,二叉树变成了链表,这种要查询col=6的,也是要经过6次查。速度慢
红黑树
红黑树是二叉树的一种,红黑树是可以自动平衡的二叉树,也叫平衡二叉树。
我们要查询col1=6的数据,在红黑数中,先从根节点开始找,6比2大,去搜索右子树,右子树是4,6比4大,继续搜索4的右子树,然后找到了6,查询次数是3次。
Hash
对索引的key进行一次hash计算,定位出数据存储的位置。
通过hash(key)查找元素可能只要一次,但如果hash(key)的位置存在多个元素,要遍历去查询。
B-Tree
- 叶节点具有相同的深度,叶节点的指针为空
- 所有索引元素不重复
- 节点中的数据索引从左到右递增排列

B+Tree
- 非叶子节点不保存data,只存储索引,可以存放更多的索引。(非叶子节点:还有子节点的节点叫做非叶子节点)
- 叶子节点包含所有的索引字段,叶子节点中的数据索引从左到右递增排列
- 叶子节点用指针链接,提高区间访问总能

mysql的数据结构是B+Tree
- 为什么不选择二叉树数据结构
- 因为二叉树有可能变成链表的情况,链表过长,不合适查询
- 为什么不选择红黑数数据结构
- 红黑树会自平衡,无法确认树的高度,可能会随着数据增多,树的高度不可控,而树的高度影响了查找的速度
- 为什么不选择Hash
- hash索引查找高效,但是只能满足“=”值查询,不支持“IN”范围查询
- 还会有hash冲突的问题
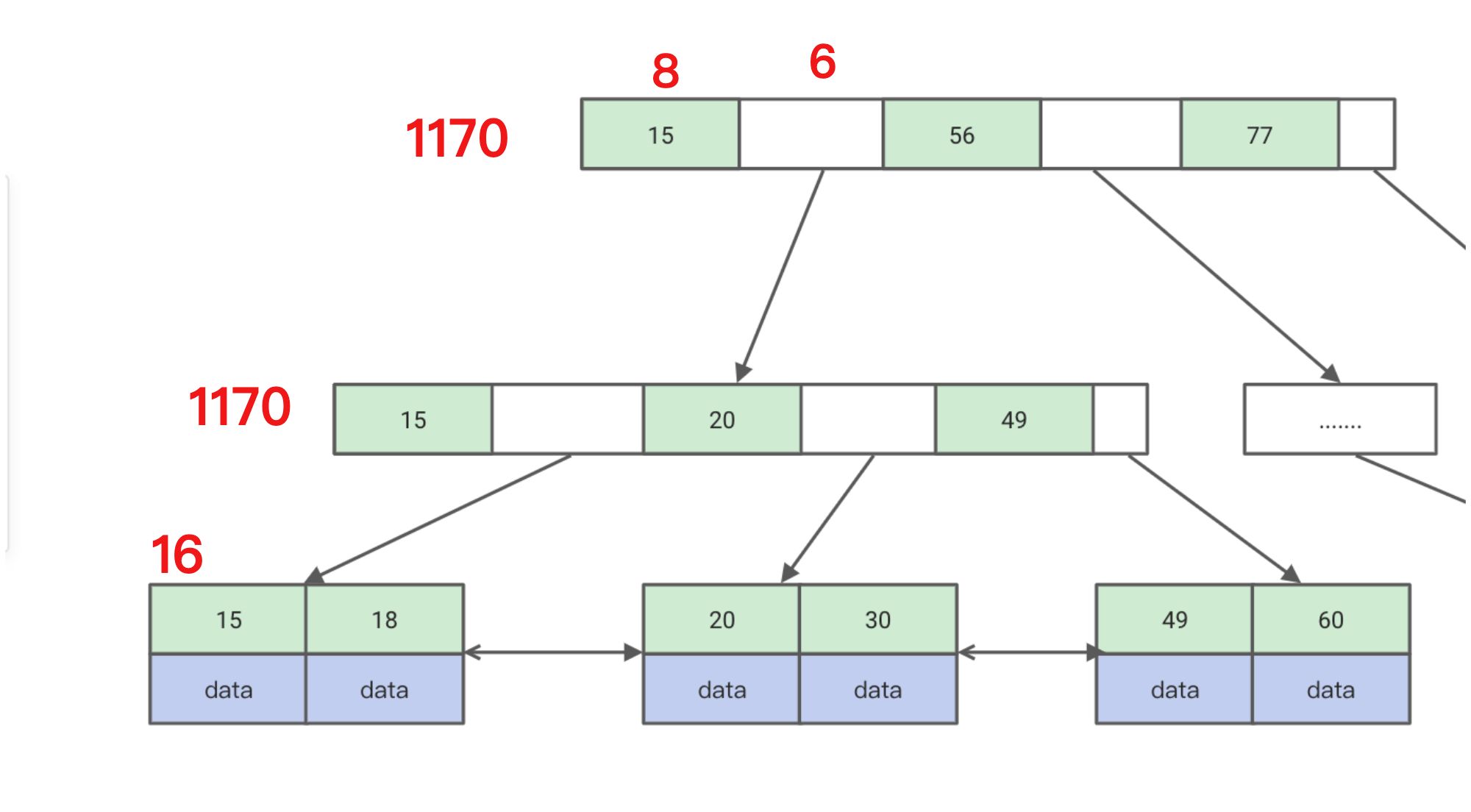
B+Tree的一次查找过程
- 例如要查找的内容为30
- 从根节点开始查找,先把根节点的内容加载到内存,然后用30跟内存的节点去匹配,查找落在那个区间,在15到56的区间,15到56区间存的是15的数据页地址(白色的区间)
- 然后把15的数据页地址也加载到内存,然后再用30再去匹配,发现落在20到49的区间,20到49的区间存放的是20的数据页地址(白色区间)
- 然后再把20的数据页地址加载到内存,这里能查询到我们想要的值30的磁盘文件地址,然后再通过30的磁盘文件地址去磁盘找元素
- 只是进行了3次查找
B+Tree能存多少数据
- mysql是根据数据页来存放数据的,默认的一个数据页大小是16kb
- 用B+Tree构建,假设索引是bigint(8个字节),下一个节点的磁盘文件地址为6字节(白色区间),那根节点能存放的数据量是(16kb*1024/(8b+6b)=1170(大概),就根节点最多存放1170个索引。因为数据页的大小是16kb,假设叶子节点的每个元素是1kb,那就是可以存放16个元素。
- 那么在一颗高度为3的B+Tree的情况下,一张表至少可以存:1170117016=2000多w的数据
mysql为什么选择B+Tree,而不是B-Tree
- 在树的结构中,影响树的查询速度的是树的高度
- 在B+Tree中高度为3,已经可以存放2000W的数据。而在B-Tree中,因为B-Tree的索引包括数据的内容,假设每个索引的大小为1kb,那就是每个节点的能存放16个索引,用B-Tree来存放2000W的数据,那么B-Tree的高度是7(16的7次方)
- B+Tree的子节点维护了一个指针,指向下一个节点或者上一个节点的指针,因为B+Tree的节点都是排好的序,所以可以更好的支持范围查询。而B-Tree没有这个指针。
mysql数据库引擎
MyISAM
MyISAM索引文件和数据文件是分离的(非聚集),叶子节点存放的是数据的地址
- frm(frame)文件是存放数据表信息的
- MYD(MyIsAM Data)文件,存放数据的
- MYI(MyIsAM Index)文件,存放索引的

以B+Tree树组织的MyISAM的MYI文件结构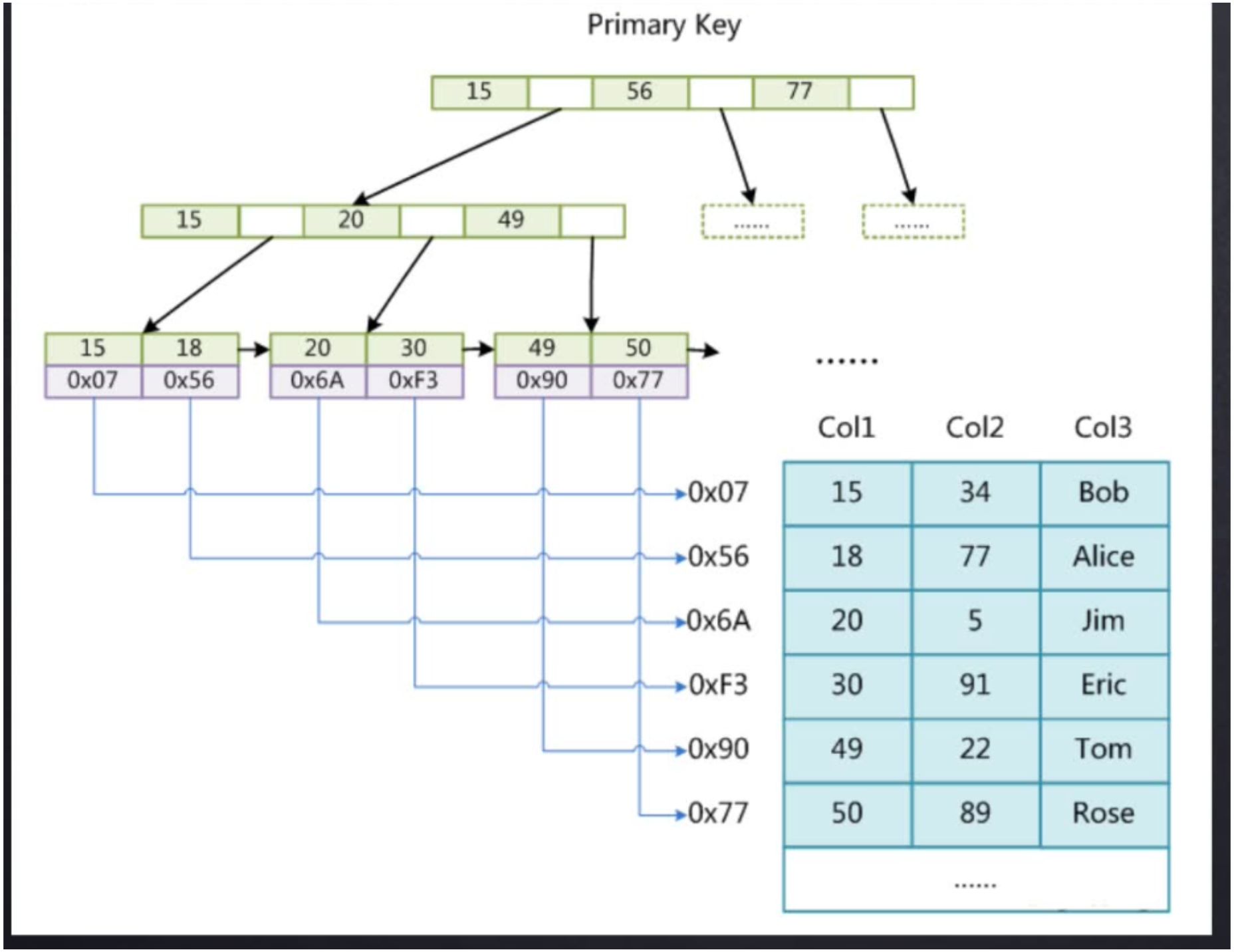
- 以查找col1=30为例子
- 先从MYI文件的根节点开始查找,找到30的位置为0xF3
-
InnoDB
InnoDB是聚集索引
ibd文件就是存放了个数据表的数据的,这个数据表文件是按照B+Tree的结构组织的。

- 叶节点存放的是整行的记录

什么是聚集索引和非聚集索引
- 聚集索引,叶子节点记录了整行的数据表记录,索引和数据是放在同一个文件的。
- 非聚集索引,MyISAM就是非聚集索引,它的叶子节点只存放了数据的地址,而且索引文件和数据文件都是单独存放的。
- 索引和数据文件分开存放的就是非聚集索引。一起存放则是聚集索引。
聚集索引和非聚集索引那个查询速度快
- 聚集索引会快,因为聚集索引的叶子节点记录了数据表完整的记录,也就是找到了对应的索引就相当找到了数据内容
- 而非聚集索引要先从MYI文件找到地址,再通过MYD文件去找到数据记录。
为什么建议InnoDB表必须建主键,并且推荐使用整型的自增主键?
- InnoDB的数据文件本来就是以B+Tree结构组织的文件,如果自带自增主键的话,可以很好的组织。如果没有主键,InnoDB会从表里面找出一列数据都不重复的列来构建这个B+Tree,如果在表中找不到不重复的列,那么InnoDB会创建一个隐藏列(类似RowId,这个隐藏列会帮你维护唯一的id)来构建B+Tree。
- 在InnoDB查找索引,是根据比大小来确定的,所以在查找过程中,可能会经历几次的比大小,如果是整型可以很好的比较。如果是字符串(UUID),字符串只能是通过逐位来做比较,按照ASCII码比较,字符串很长的情况下逐位来比较,会有影响。
- 整型会比一串字符串占用的空间小,也就是整型索引占用的空间会小。
- 主键不是自增的情况下,因为B+Tree是按顺序排列的,所以如果id不是自增,当你后面存放的数据比前面的要小,按么B+Tree会进行调整成排好序的顺序。如果是自增的,那么B+Tree只管排列数据就行了。
为什么非主键索引结构叶子节点存储的是主键值?

- 一致性
- 数据的一致性,如果每个索引都保存完整的数据记录,当我们要插入一条记录时,要先在主键索引插入成功,然后要在非主键索引去插入成功。但是如果非主键索引只保留主键的索引值,那么只要主键索引插入成功,然后把主键的引用地址放入非聚集索引即可,不用维护多个数据的副本。
节省存储空间
先在非聚集索引或者二级索引的B+Tree中找到主键的索引,然后回表通过主键的索引找到对应的记录
联合索引
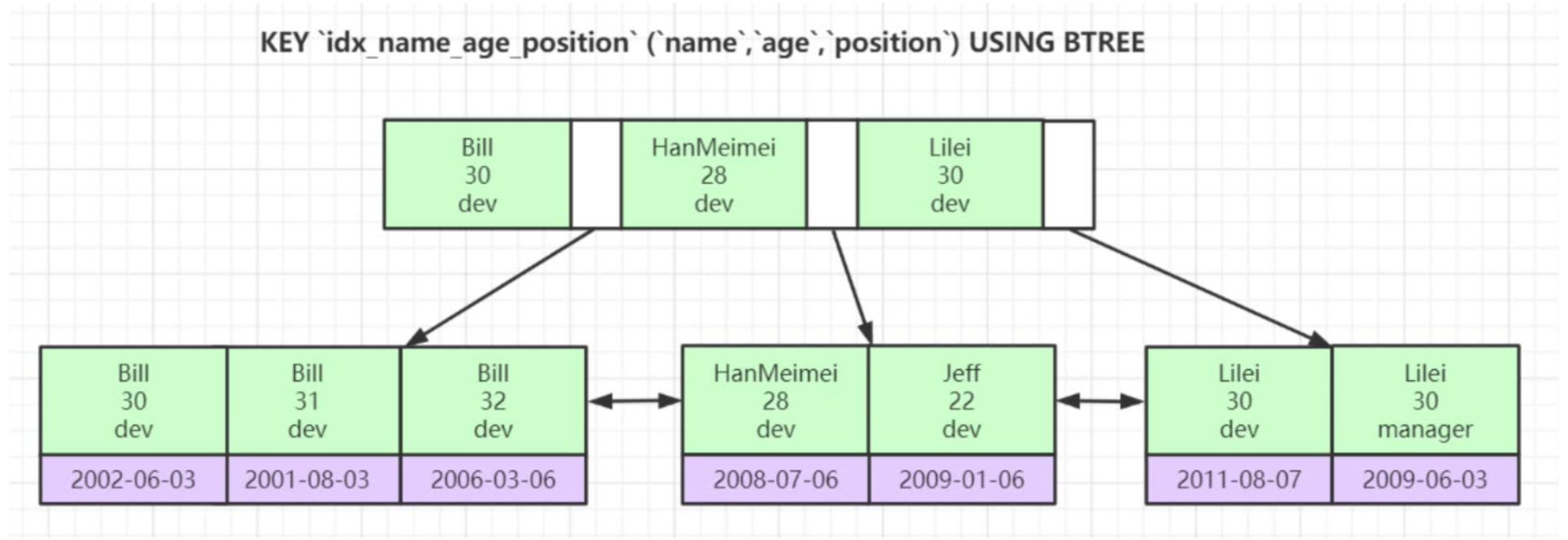
- B+Tree是排好序的结构,因为你的联合索引的顺序是name,然后是age,最后是position,所以会先根据name去构建,如果name一致,再根据age的大小去构建,如果age一致,最后根据position去构建。
- 所以在最左匹配原理里面,能走索引的是“name”,或者 “name”和“age”,或者是“name”“和”age“和”position“,最左匹配原则就是不能跳过前面去直接匹配后面的。

若有收获,就点个赞吧
0 人点赞
