分类
- 二分搜索树(Binary Search Tree)
- 红黑树、AVL
- 字典树、前缀树
构建二叉树
private class Node{public E e;public Node left;public Node right;public Node(E e){this.e = e;left = null;right = null;}}
二分搜索树
二分搜索树是二叉树,二分搜索树的每个节点的值满足
- 大于其左子树的所有结点的值
- 小于其右子树的所有结点的值
- 每个子树也是一个二分搜索树
特点:每个节点的key值大于左节点 小于右节点
结论:
- 二叉搜索树的最小节点是根节点左边子树的最左子树
- 二叉搜索树的最大节点是根节点右边子树的最右子树
插入操作

public void add(E e){if(root == null){root = new Node(e);size++;}elseadd(root, e);}//向以node为根的二分搜索树中插入元素Eprivate void add(Node node, E e){if(e.equals(node.e)){ //终止条件return;}else if(e.compareTo(node.e) <0 && node.left == null){node.left = new Node(e);size++;return ;}else if(e.compareTo(node.e) >0 && node.right == null){node.right = new Node(e);size++;return;}if(e.compareTo(node.e) < 0)add(node.left, e);elseadd(node.right, e);}
简化版
//添加元素public void add(E e){root = add(root, e);}//向以node为根的二分搜索树中插入元素Eprivate Node add(Node node, E e){if(node == null){size++;return new Node(e);}//比较插入的元素与node节点的大小if(e.compareTo(node.e) < 0){node.left = add(node.left,e);//}else if(e.compareTo(node.e)>0){node.right = add(node.right,e);}return node;}
查询元素
/*查询元素*/public boolean contains(E e){return contains(root, e);}private boolean contains(Node node, E e){if(node == null)//终止条件return false;if(e.compareTo(node.e) == 0)return true; //找到了else if(e.compareTo(node.e) <0)return contains(node.left, e);elsereturn contains(node.right, e);}
遍历操作
- 前序遍历(根、左、右)
- 中序遍历(左、根、右)
- 后序遍历(左、右、根)
/*前序遍历*/public void preOrder(){preOrder(root);}private void preOrder(Node node){if(node == null)return;System.out.println(node.e);preOrder(node.left);//访问左preOrder(node.right);//访问右}
/*中序遍历*/public void midOrder(){midOrder(root);}public void midOrder(Node node){if(node == null)return;midOrder(node.left);System.out.println(node.e);midOrder(node.right);}
惊奇的是这样的树经过中序遍历后元素是经过排过序的
/*后序遍历*/public void postOrder(){postOrder(root);}private void postOrder(Node node){if(node == null)return;postOrder(node.left);postOrder(node.right);System.out.println(node.e);}
二分搜索树的层序遍历
也是对树的bfs
public void bfs(){//借助队列的数据结构Queue<Node> q = new ArrayDeque<>();//首先添加root结点q.add(root);while(!q.isEmpty()){Node cur = q.remove();System.out.print(cur.e);if(cur.left != null) //添加左孩子与右孩子q.add(cur.left);if(cur.right != null)q.add(cur.right);}}
删除操作
首先确立二分搜索树的最大值与最小值
最小值一定会在根元素左的最左边。如果最小值拥有右子树,删除本节点右子树代替当前位置
最大值一定会在根元素的右的最右边。如果是一个叶子节点直接删除如果拥有左子树,则删除本节点 本节点的左子树代替当前位置。
先看一下如何查找元素

/*寻找最大值与最小值*/public E findMax(){if(size==0)throw new IllegalArgumentException("Is Empty!");return findMax(root).e;}private Node findMax(Node node){if(node.right == null)return node;return findMax(node.right);}public E findMin(){if(size==0)throw new IllegalArgumentException("Is Empty!");return findMin(root).e;}private Node findMin(Node node){if(node.left == null)return node;return findMin(node.left);}// 删除最大值与最小值//删除以node为根的二分搜索树中的最大节点 返回删除节点后新的二分搜索树的根public E removeMax(){E res = findMax();root = removeMax(root);return res;}private Node removeMax(Node node){ //传入结点if(node.right == null){//已经递归到底Node leftNode = node.left; //接住结点的左树node.left = null;size--;return leftNode;}node.right = removeMax(node.right);return node;}
删除单个节点的分类
- 拥有一个左子树
- 拥有一个右子树
- 是一个叶子节点
- 拥有左右两个子树(难点)
删除左右都有孩子的节点d。找到s = min(d->right) s是d的后继
s->right = delMin(d->right) 删除节点的右子树
s->left = d->left 删除节点的左子树
删除d,s是新的子树的根

/*删除元素节点*/public void remove(E e){root = remove(root,e);}private Node remove(Node node,E e){if(node == null)return null; //没找着if(e.compareTo(node.e) <0){node.left = remove(node.left , e);return node;}else if(e.compareTo(node.e)>0){node.right = remove(node.right,e);return node;}else{// e == node.eif(node.left == null){ //如果删除节点左子树为空Node rightNode = node.right;node.right = null;size--;return rightNode;}if(node.right == null){//如果删除节点右子树为空Node leftNode = node.left;node.left = null;size--;return leftNode;}//如果删除节点左右均不为空Node successor = findMin(node.right);successor.right = removeMin(node.right);successor.left = node.left;node.left = node.right = null;return successor;}}
完整代码
import java.util.ArrayDeque;import java.util.LinkedList;import java.util.Queue;public class BST<E extends Comparable<E>> {/*** 结点*/private class Node{public E e;public Node left;public Node right;public Node(E e){this.e = e;left = null;right = null;}}private Node root;private int size;public BST(){root = null;size=0;}public int size(){return size;}public boolean isEmppty(){return size==0;}/*添加元素*/public void add(E e){root = add(root, e);}//向以node为根的二分搜索树中插入元素Eprivate Node add(Node node, E e){if(node == null){size++;return new Node(e);}if(e.compareTo(node.e) < 0){node.left = add(node.left,e);//}else if(e.compareTo(node.e)>0){node.right = add(node.right,e);}return node;}/*查询元素*/public boolean contains(E e){return contains(root, e);}private boolean contains(Node node, E e){if(node == null)//终止条件return false;if(e.compareTo(node.e) == 0)return true; //找到了else if(e.compareTo(node.e) <0)return contains(node.left, e);elsereturn contains(node.right, e);}/*前序遍历*/public void preOrder(){preOrder(root);}private void preOrder(Node node){if(node == null)return;System.out.println(node.e);preOrder(node.left);//访问左preOrder(node.right);//访问右}/*中序遍历*/public void midOrder(){midOrder(root);}public void midOrder(Node node){if(node == null)return;midOrder(node.left);System.out.println(node.e);midOrder(node.right);}/*后序遍历*/public void postOrder(){postOrder(root);}private void postOrder(Node node){if(node == null)return;postOrder(node.left);postOrder(node.right);System.out.println(node.e);}/*寻找最大值与最小值*/public E findMax(){if(size==0)throw new IllegalArgumentException("Is Empty!");return findMax(root).e;}private Node findMax(Node node){if(node.right == null)return node;return findMax(node.right);}public E findMin(){if(size==0)throw new IllegalArgumentException("Is Empty!");return findMin(root).e;}private Node findMin(Node node){if(node.left == null)return node;return findMin(node.left);}// 删除最大值与最小值//删除以node为根的二分搜索树中的最大节点 返回删除节点后新的二分搜索树的根public E removeMax(){E res = findMax();root = removeMax(root);return res;}private Node removeMax(Node node){ //传入结点if(node.right == null){//已经递归到底Node leftNode = node.left; //接住结点的左树node.left = null;size--;return leftNode;}node.right = removeMax(node.right);return node;}private Node removeMin(Node node){ //传入结点if(node.left == null){//已经递归到底Node rightNode = node.right; //接住结点的左树node.right = null;size--;return rightNode;}node.left = removeMin(node.left);return node;}/*删除元素*/public void remove(E e){root = remove(root,e);}private Node remove(Node node,E e){if(node == null)return null; //没找着if(e.compareTo(node.e) <0){node.left = remove(node.left , e);return node;}else if(e.compareTo(node.e)>0){node.right = remove(node.right,e);return node;}else{// e == node.eif(node.left == null){ //如果删除节点左子树为空Node rightNode = node.right;node.right = null;size--;return rightNode;}if(node.right == null){//如果删除节点右子树为空Node leftNode = node.left;node.left = null;size--;return leftNode;}//如果删除节点左右均不为空Node successor = findMin(node.right);successor.right = removeMin(node.right);successor.left = node.left;node.left = node.right = null;return successor;}}@Overridepublic String toString() {StringBuilder res = new StringBuilder();BSTString(root,0,res);return res.toString();}// 生成以node为根结点 深度为depth的二叉树的字符串private void BSTString(Node node, int depth, StringBuilder res){if(node == null){res.append(BSTString(depth)+"null\n");return;}res.append(BSTString(depth) + node.e + "\n");BSTString(node.left, depth+1, res);BSTString(node.right, depth+1, res);}private String BSTString(int depth){StringBuilder res = new StringBuilder();for(int i=0; i<depth; i++)res.append("--");return res.toString();}}
Tree 前缀树
Trie是一个树形结构。是一种专门处理字符串匹配的数据结构,用来解决字符串集合中快速查找字符串的问题。
Trie也成为前缀树
Trie查询每条条目的事件复杂度与字典中一共多少条数目无关。
时间复杂度O(w),w为查询单词的长度。
核心思想:通过最大限度地减少字符串比较,用空间换时间,利用共同前缀提高查询效率
Trie特点
- 根节点没有任何字符,除根节点外每一个节点都只包含一个字符
- 根节点开始到某一结点路径上经过的字符连接起来就是搜索的字符串
构造
每个节点有若干指向下个节点的指针
class Node{char c;Map<char,Node> next;}
插入元素

从跟节点开始,将单词的每个字母逐一插入 Trie树。插入前先看字母对应的节点是否存在,存在则共享该节点,不存在则创建对应的节点。
//添加一个单词wordpublic void add(String word){Node cur = root;for(int i=0; i<word.length(); i++){//使用循环的方式添加映射char c =word.charAt(i);if(cur.next.get(c)==null){cur.next.put(c,new Node());}cur = cur.next.get(c);}if(!cur.isWord){//如果单词没有存在cur.isWord = true;size++;}}
查询操作
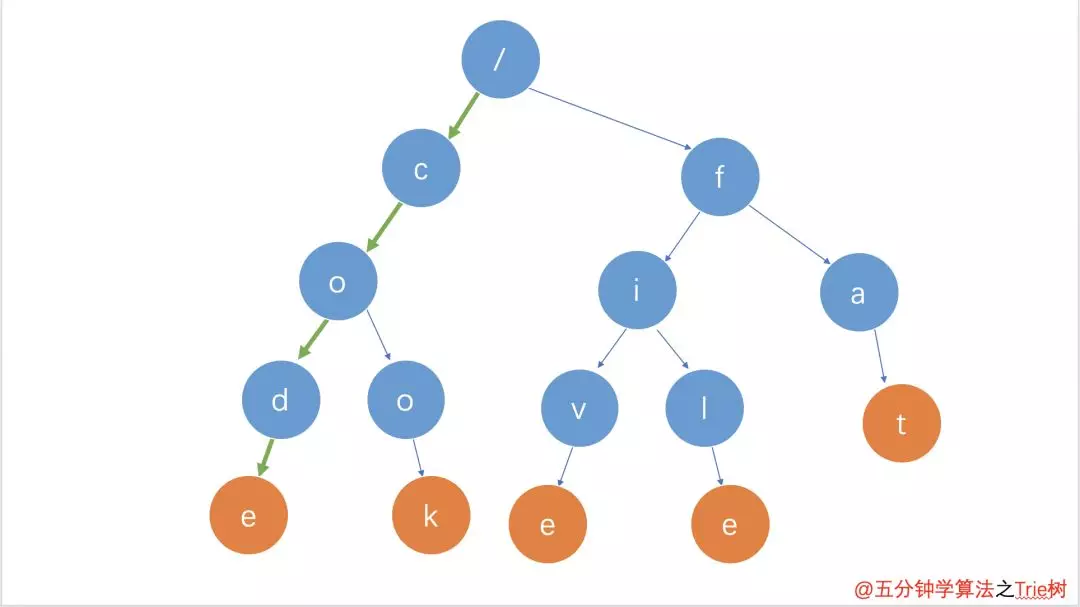
从根节点开始遍历,如果下一个节点不包含直接返回false,需要注意的是最后的返回值不是直接返回true而是cur.isWord,因为比如pan、panda但是只添加了panda如果返回值为true那么pan也会搜索成功。所以应该返回Node的isWord属性
//查询单词wordpublic boolean contains(String word){Node cur = root;for(int i=0; i<word.length(); i++){char c = word.charAt(i);if(cur.next.get(c)==null)return false;cur = cur.next.get(c);}return cur.isWord;//Important}
简单模式匹配
p.. = pan .可以代表任何一个字母
//匹配单词wordpublic boolean search(String word){return match(root,word,0);}/*三个参数节点|单词|单词指针*/private boolean match(Node node, String word, int index){if(index==word.length())return node.isWord;char c = word.charAt(index); //获取当前指针if(c!='.'){if(node.next.get(c) == null) //如果不是.看下一个是不是空 不是空接着下一个节点return false;return match(node.next.get(c),word,index+1);}else{for(char nextChar:node.next.keySet())if(match(node.next.get(nextChar),word,index+1))return true;return false;}}
import java.util.TreeMap;public class Trie {private class Node{public boolean isWord; //是否找到了public TreeMap<Character,Node> next;public Node(boolean isWord){this.isWord = isWord;next = new TreeMap<>();}public Node(){this(false);}}private Node root;private int size;public Trie(){ //构造函数root = new Node();size=0;}public int getSize(){return this.size;}//添加一个单词wordpublic void add(String word){Node cur = root;for(int i=0; i<word.length(); i++){//使用循环的方式添加映射char c =word.charAt(i);if(cur.next.get(c)==null){cur.next.put(c,new Node());}cur = cur.next.get(c);}if(!cur.isWord){//如果单词没有存在cur.isWord = true;size++;}}//查询单词wordpublic boolean contains(String word){Node cur = root;for(int i=0; i<word.length(); i++){char c = word.charAt(i);if(cur.next.get(c)==null)return false;cur = cur.next.get(c);}return cur.isWord;//Important}//匹配单词wordpublic boolean search(String word){return match(root,word,0);}/*三个参数节点|单词|单词指针*/private boolean match(Node node, String word, int index){if(index==word.length())return node.isWord;char c = word.charAt(index); //获取当前指针if(c!='.'){if(node.next.get(c) == null) //如果不是.看下一个是不是空 不是空接着下一个节点return false;return match(node.next.get(c),word,index+1);}else{for(char nextChar:node.next.keySet())if(match(node.next.get(nextChar),word,index+1))return true;return false;}}}
删除操作

应用
前缀匹配

字符串检索
给出 N 个单词组成的熟词表,以及一篇全用小写英文书写的文章,按最早出现的顺序写出所有不在熟词表中的生词。
检索/查询功能是Trie树最原始的功能。给定一组字符串,查找某个字符串是否出现过,思路就是从根节点开始一个一个字符进行比较:
- 如果沿路比较,发现不同的字符,则表示该字符串在集合中不存在。
- 如果所有的字符全部比较完并且全部相同,还需判断最后一个节点的标志位(标记该节点是否代表一个关键字)。

若有收获,就点个赞吧
0 人点赞
