为什么会出现大数据技术
海量数据本身存在商业价值。
随着互联网发展,现在大量的数据由机器或者通过网络产生,比如点击链接广告、搜索词条等行为都会产生数据,数据量是十分庞大的。以谷歌为例,谷歌每秒处理4w条的搜索,相当于每天35亿条,光是存储用户搜索记录每天就可以产生几十、上百TB的数据,甚至达到PB级别。
传统的数据处理无论是存储数据的能力还是处理数据的能力都存在明显瓶颈。
大数据的战略意义不在于掌握庞大的数据信息,而是对这些含有意义的数据进行专业化处理。将海量价值密度低数据进行”处理”,实现盈利;
大数据定义
IBM最早提出了大数据的3V定义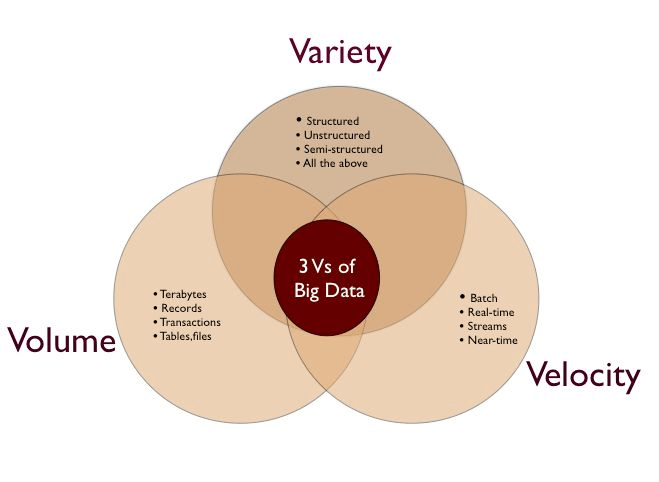
首先是Volume,这个比较好理解,大数据本身就很明确的代表了数据量很大。
第二个特征是Variety,多样化。
第三个特征是Velocity,这个主要是指数据生成的速度。
大数据处理的基本流程
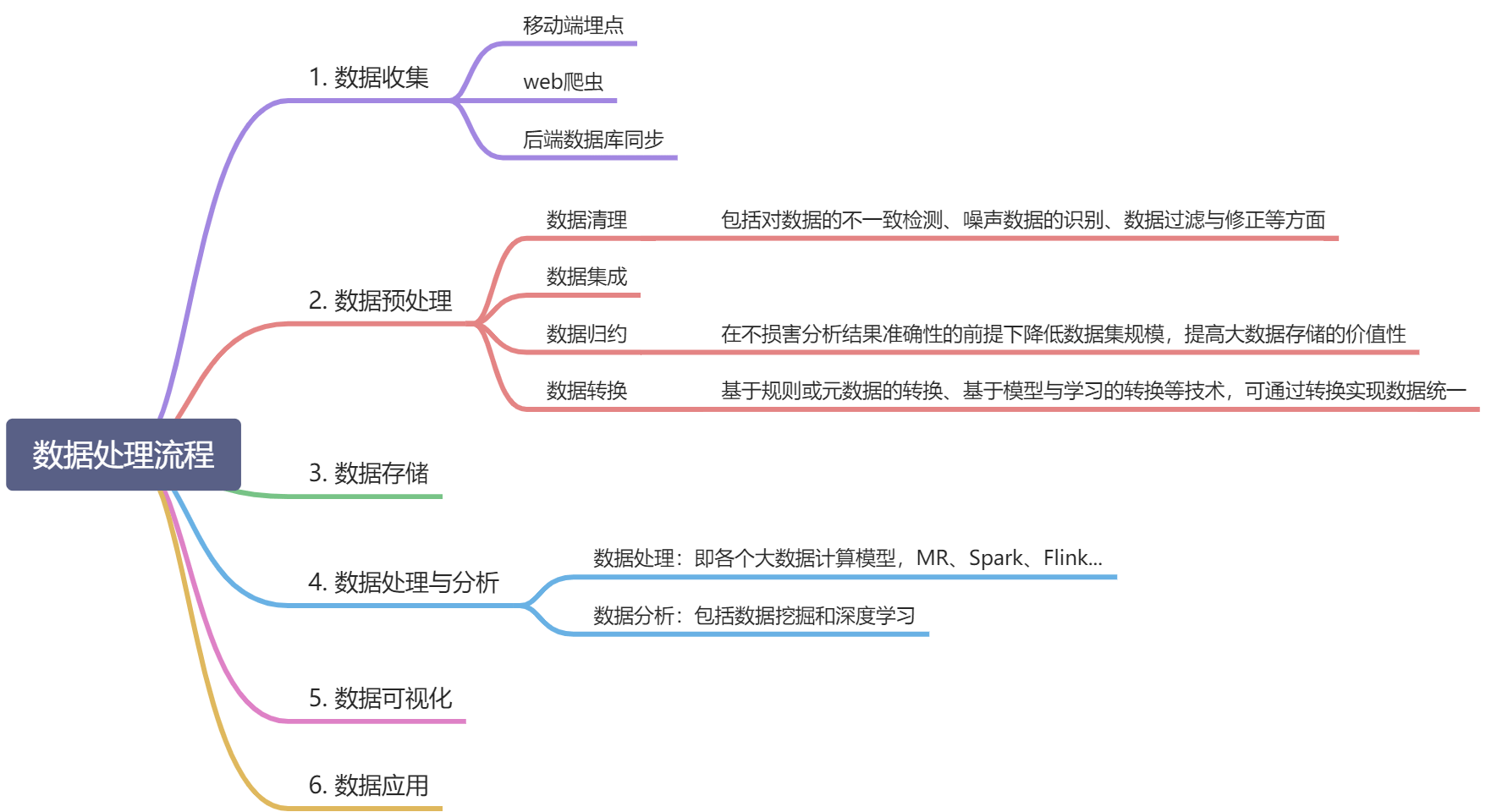
大数据技术
大数据技术核心问题是要解决海量数据的存储、计算问题。
奠定基石-Hadoop
基于google的三大论文,《Google-File-System》《Google-Mapreduce》《Google-Bigtable》作为理论基础,Hadoop应运而生。
Hadoop1.X包含MR、HDFS、Common(辅助工具)三部分。《Google-File-System》是Hadoop HDFS的理论基础,《Google-Mapreduce》是MR的理论基础,《Google-Bigtable》提供大表的设计思路,把所有数据存入一张表,空间换时间,HBase是Hadoop生态圈中大表的体现;
我们有时候说的hadoop,指的可能是hadoop的生态圈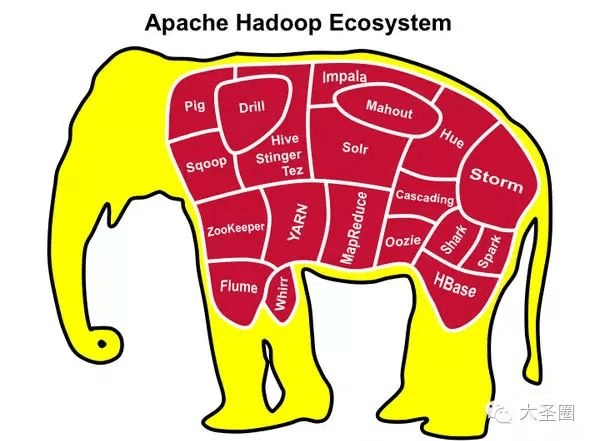
Sprak
Spark对标的是Hadoop中的MR,他没有提供文件存储能力,所以他必须和分布式文件存储系统集成才能用(比如Hadoop中的HDFS,或者HBase甚至mysql数据库)。
Spark数据处理速度秒杀Hadoop的MR,这也是他特别火的一个原因。
Spark是由于Hadoop中MR效率低下而产生的高效率快速计算引擎,批处理速度比MR快近10倍,内存中的数据分析速度比Hadoop快近100倍(源自官网描述);
作为主流跑批(离线计算)的计算引擎,也有自己的生态圈(生态圈定义并不绝对)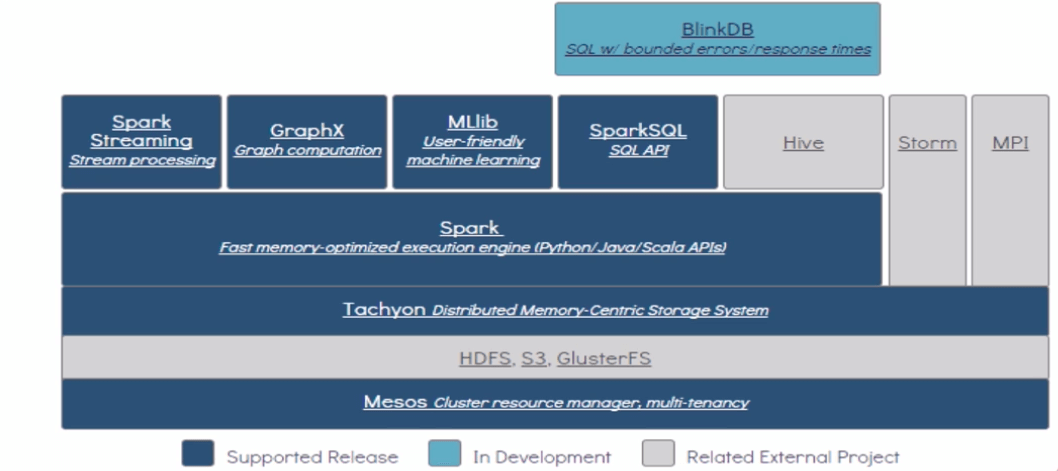
自底向上,资源调度器、分布式存储系统、基于内存存储系统、Sprak Core、不同应用场景下开发的Spark模块
Flink
尽管Spark提供Spark-Streaming实时计算,较早之前也有Storm;但spark是利用微批来模拟流处理数据的,并不是真正的实时计算;Storm已日暮西山,flink与之相比具有高吞吐、低延迟、高可靠和精确计算等特性,对事件窗口有很好的支持,越来越多的企业替换掉了storm;
目前企业应用越来越关注数据时效性,实时计算重要性相比离线计算越来越突出;Flink近几年风头也是盖过了Spark,社区活跃程度也是相当高,是实时计算的首要选择方式;
大数据架构模式
Lambda架构
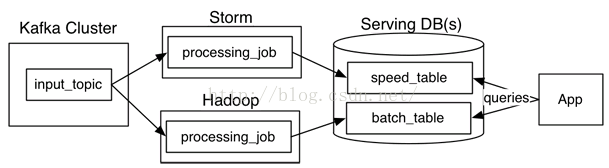
Kappa架构
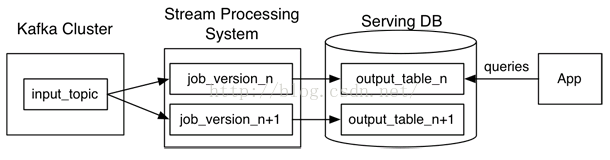
利用流计算系统对全量数据进行重新计算,步骤如下:
1、用Kafka或类似的分布式队列保存数据,需要几天数据量就保存几天。
2、当需要全量计算时,重新起一个流计算实例,从头开始读取数据进行处理,并输出到一个结果存储中。
3、当新的实例完成后,停止老的流计算实例,并把老的一引起结果删除。
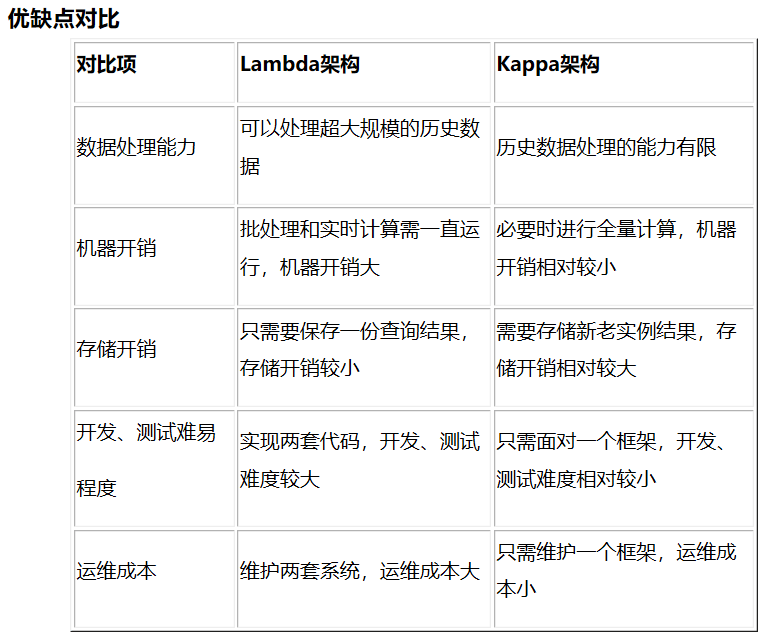
优缺点比较
应用场景
Kappa架构
场景1:基于StreamSQL引擎的智慧交通,实时监控和预警;
场景2:数据量不够TB级别,但是传统关系型查询又不能满足要求;
Lamdba架构
场景1:海量数据分析,需要长时间批处理计算并且有实时计算的场景
场景2:保留传统数据仓库的最佳实践,又需要批处理和实时处理的业务场景
我的选型
技术选型从整体角度考虑主要是机器和服务成本、运维成本、开发成本、扩展性
主要是架构模式和技术选型两个方向的选择;架构模式,根据业务需求显然是Lambda架构更适合;而技术选型方面采用了市面上比较成熟的flume+kafka作为埋点数据收集、spark作为计算引擎、hbase作为ODS、mysql作为ADS、sqoop作为数据抽取工具、Yarn作为资源调度器;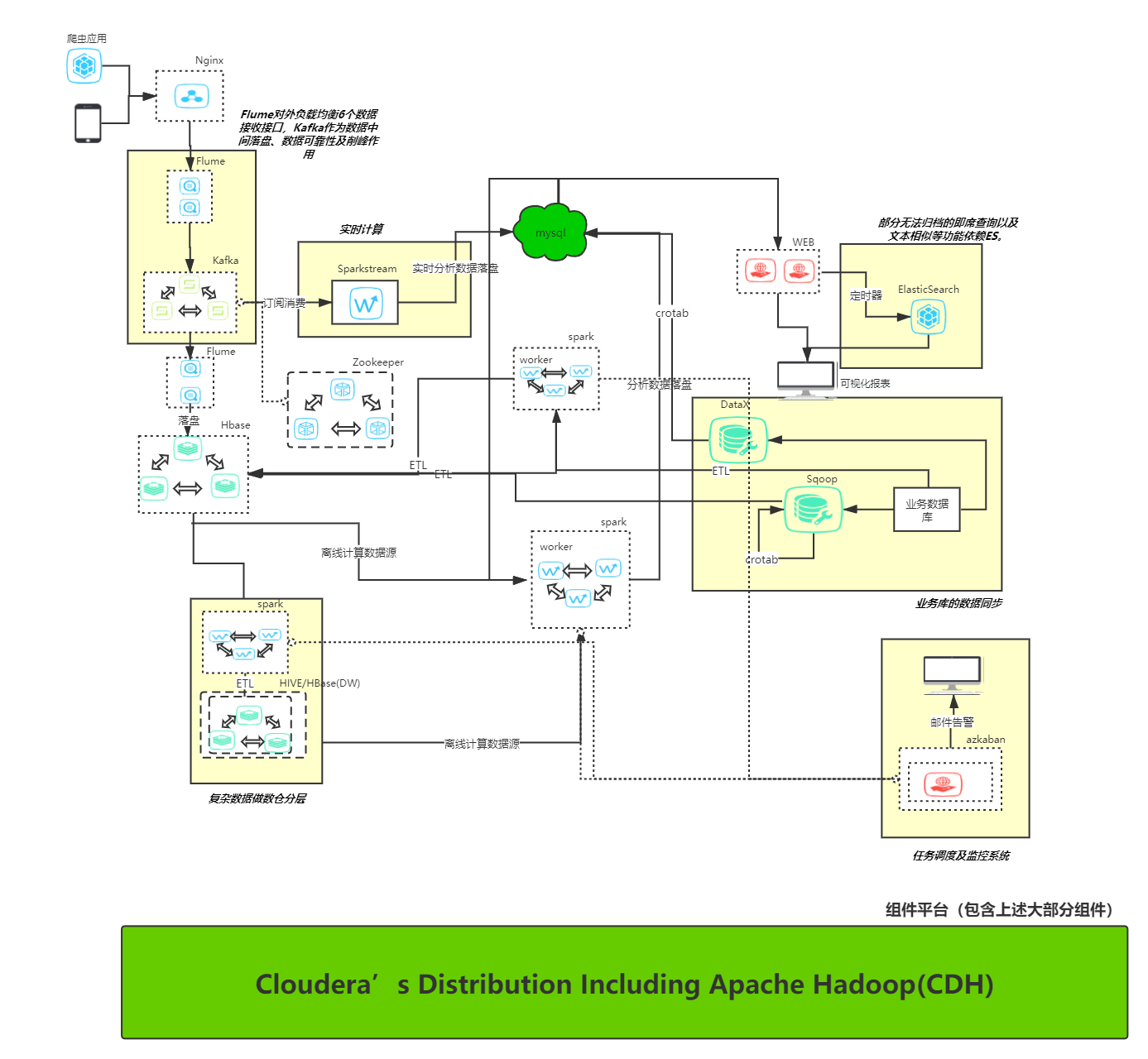
数据收集
数据收集阶段采用了flume-kafka-flume-hbase数据流转方式
选用flume作为埋点采集的原因
- flume支持多种数据源和多种收集方式(包括http)进行数据收集;
- flume动态扩展source非常方便,支持并发度很高
- flume支持自定义souce和sink,可支持数据转换和清洗(解压缩以及解码埋点数据、过滤掉无效appid和不是当天的时间戳等)
- flume在接收数据后,输出到下游之前支持持久化和内存两种方式中间态数据存储,内存方式吞吐量大、效率高,文件持久化方式数据可靠、重启数据可恢复;
- 另种方式,采用比如logstash收集nginx日志,写入到kafka,采用配置方式,灵活度较低;另外存储空间需要扩1倍,需要存放nginx日志数据
第一个flume后接入kafka原因
- 尽管flume的channel也能起到削峰作用,但无法作为后续的流计算引擎的上游数据源,组件间不支持
- kafka作为一个大数据通用化的分布式消息系统,不仅本身所需功能齐全且兼容众多组件
- ss和flink都天然支持以kafka作为数据上流
- 作为清洗后的上流数据源,kafka基于消息订阅模式以及offset等消费设计方式,保留了后续的扩展性和结偶,比如后续新华社后端业务也需要埋点数据,直接接入kafka即可,而不需要从数仓(hbase)拉取,并且还是实时的;
- kafka本身比较强大,无论是吞吐量还是可用性都强于flume,将flume作为上流数据源还是kafka更可靠;
- 构建Lambda架构模式,跑批和实时流计算需要消费相同数据,kafka本身支持,而flume做不到
kafka后再接入flume原因
- kafka作为数据源总是”临时”的,分区数据会过期,持久化存储不够可靠、数据查询也不方便
- 写一个消费者程序运行也可以替代第二个flume,但存在手动维护程序的麻烦,加重运维任务,如果是搭建消费者集群就更麻烦了。flume是基于cdh平台搭建的,自带监控、日志等功能,可视化界面搭建、启动、配置
- flume自定义sink和自己起的消费者程序功能无异
数据存储
主要是hbase和hive之间选型
- hbase和hive技术选型,从写流程来看,hbase本身的写速度远高于hive的,以目前业务的流量不会成为瓶颈;而hive的hql都是基于mr的;
- hbase作为业界比较通用的组件,计算引擎基本都支持,包括spark
- 基于hdfs,机器硬件要求低、扩展性好、数据可存储量大
- nosql存储,埋点数据类型有几十种,如果分表存储,每加一种埋点就得建一张表;
- 路经分析需求需要埋点顺序,分表存储打乱时间顺序会比较麻烦(后来发现这个这个理由站不住脚,还是绕不开内存重排)
计算引擎
离线计算引擎
主要是mr和spark之间选择
- mr速度慢于spark
- spark的计算逻辑代码编写比mr的程序编写方便,基于数据集(rdd)的操作,支持许多种算子,mr过于底层都要自己实现
- spark更为主流,社区活跃度高,问题解决等各方面更有保障
实时计算引擎
主要是ss和flink之间选择,flink各方面都优于ss,并且ss还是伪实时的,但最后还是选择了ss
- 目前需对实时计算要求并不高,数据秒级更新即可,所以ss或flink都可
- flink集成较为麻烦,cdh数据平台未涵盖fink,需要单独安装环境;而ss是spark自带的模块
- flink学习成本较高,项目紧张,时间不够,而ss不需要额外学习
数据平台
以上组件如果不使用现成数据平台,一个个手动安装维护,运维工作基本不可能,组件过多,且是集群方式(服务*3)
数据平台选择并不多,cdh或者maxcomputer,数据平台技术选型
作业调度器
主要是azkaban和ozzie的选择,此处没做过多纠结,ozzie比较重,功能复杂齐全,但azkaban功能已经够用,且使用web操作,日志也是web页面查看,较为方便,上手也比较简单;
即席查询
目前即席查询主要涉及到UV统计点以及用户分类分析模块。用户分类分析目前暂时效果不理想,实践了es+mysql、spark窗口函数效果都不太理想,最后用了impala试验阶段无论是功能实现还是返回速度都能接受,但没上线;
UV采用的ES来解决,原因是其他即席查询搭建较重,内存吃的较多,学习成本较大,比如Presto、Impala、Druid等。如果用传统的mysql进行实时统计,千万条数据去重统计速度过慢;但ES本身也有个问题,ES去重统计是存在误差的,数据百万情况下误差在2-5%内,还是挺大的。
另一套独立方案 Kudu
这套方案缺点在于不是主流解决方案,遇到问题排查难度大;对硬件配置较高,依赖Impala,官方参考低配节点 24c 96G;本身还存在tablet不会自动均衡的问题,需要运维手动维护;搭建过程遇到了许多坑,解决方法也不好找;
大厂选型
美团外卖离线数仓建设实践
Flink数仓|基于Flink+Hive构建流批一体准实时数仓
遇到的问题和未来规划

若有收获,就点个赞吧
0 人点赞
