MySQL 万字精华总结 + 面试100 问,吊打面试官绰绰有余
MySQL 的查询流程具体是?or 一条SQL语句在MySQL中如何执行的?
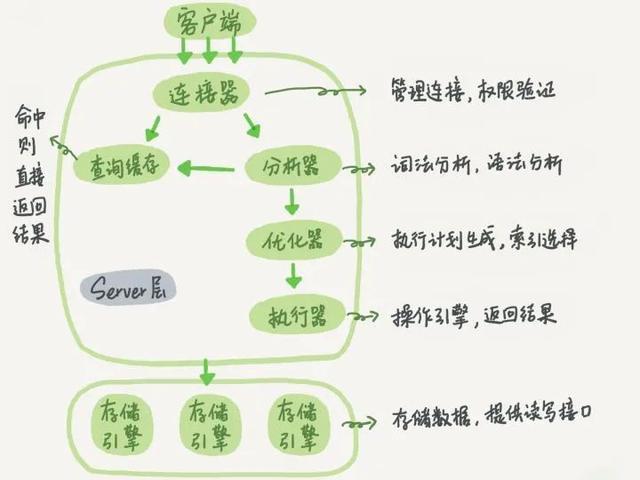
客户端请求 —-> 连接器(验证用户身份,给予权限) —-> 查询缓存(存在缓存则直接返回,不存在则执行后续操作) —-> 分析器(对SQL进行词法分析和语法分析操作) —-> 优化器(主要对执行的sql优化选择最优的执行方案方法) —-> 执行器(执行时会先看用户是否有执行权限,有才去使用这个引擎提供的接口) —-> 去引擎层获取数据返回(如果开启查询缓存则会缓存查询结果)
说说MySQL有哪些存储引擎?都有哪些区别?
常见的存储引擎就 InnoDB、MyISAM、Memory、NDB。
InnoDB 现在是 MySQL 默认的存储引擎,支持事务、行级锁定和外键
**
- InnoDB 支持事务,MyISAM 不支持事务。这是 MySQL 将默认存储引擎从 MyISAM 变成 InnoDB 的重要原因之一;
- InnoDB 支持外键,而 MyISAM 不支持。对一个包含外键的 InnoDB 表转为 MYISAM 会失败;
- InnoDB 是聚簇索引,MyISAM 是非聚簇索引。聚簇索引的文件存放在主键索引的叶子节点上,因此 InnoDB 必须要有主键,通过主键索引效率很高。但是辅助索引需要两次查询,先查询到主键,然后再通过主键查询到数据。因此,主键不应该过大,因为主键太大,其他索引也都会很大。而 MyISAM 是非聚集索引,数据文件是分离的,索引保存的是数据文件的指针。主键索引和辅助索引是独立的。
- InnoDB 不保存表的具体行数,执行select count(*) from table 时需要全表扫描。而 MyISAM 用一个变量保存了整个表的行数,执行上述语句时只需要读出该变量即可,速度很快;
- InnoDB 最小的锁粒度是行锁,MyISAM 最小的锁粒度是表锁。一个更新语句会锁住整张表,导致其他查询和更新都会被阻塞,因此并发访问受限。这也是 MySQL 将默认存储引擎从 MyISAM 变成 InnoDB 的重要原因之一;
说你对 MySQL 索引的理解?
数据库索引的原理,为什么要用 B+树,为什么不用二叉树?
聚集索引与非聚集索引的区别?
InnoDB引擎中的索引策略,了解过吗?
创建索引的方式有哪些?
聚簇索引/非聚簇索引,mysql索引底层实现,为什么不用B-tree,为什么不用hash,叶子结点存放的是数据还是指向数据的内存地址,使用索引需要注意的几个地方?
MySQL索引分类
数据结构角度
- B+树索引
- Hash索引
- Full-Text全文索引
-
从物理存储角度
聚集索引(clustered index)
非聚集索引(non-clustered index),也叫辅助索引(secondary index)聚集索引和非聚集索引都是B+树结构
从逻辑角度
主键索引:主键索引是一种特殊的唯一索引,不允许有空值
- 普通索引或者单列索引:每个索引只包含单个列,一个表可以有多个单列索引
- 多列索引(复合索引、联合索引):复合索引指多个字段上创建的索引,只有在查询条件中使用了创建索引时的第一个字段,索引才会被使用。使用复合索引时遵循最左前缀集合
- 唯一索引或者非唯一索引
- 空间索引:空间索引是对空间数据类型的字段建立的索引,MYSQL中的空间数据类型有4种,分别是GEOMETRY、POINT、LINESTRING、POLYGON。MYSQL使用SPATIAL关键字进行扩展,使得能够用于创建正规索引类型的语法创建空间索引。创建空间索引的列,必须将其声明为NOT NULL,空间索引只能在存储引擎为MYISAM的表中创建
为什么推荐使用整型自增主键而不是选择UUID?
- UUID是字符串,比整型消耗更多的存储空间;
- 在B+树中进行查找时需要跟经过的节点值比较大小,整型数据的比较运算比字符串更快速;
- 自增的整型索引在磁盘中会连续存储,在读取一页数据时也是连续;UUID是随机产生的,读取的上下两行数据存储是分散的,不适合执行where id > 5 && id < 20的条件查询语句。
- 在插入或删除数据时,整型自增主键会在叶子结点的末尾建立新的叶子节点,不会破坏左侧子树的结构;UUID主键很容易出现这样的情况,B+树为了维持自身的特性,有可能会进行结构的重构,消耗更多的时间。

若有收获,就点个赞吧
0 人点赞
