背景
哈喽,大家好,我是asong。今天我们一起来看看Go语言中的rune数据类型,首先从一道面试题入手,你能很快说出下面这道题的答案吗?
func main() {str := "Golang梦工厂"fmt.Println(len(str))fmt.Println(len([]rune(str)))}
运行结果是15和15还是15和9呢?先思考一下,一会揭晓答案。
其实这并不是一道面试题,是我在日常开发中遇到的一个问题,当时场景是这样的:后端要对前端传来的字符串做字符校验,产品的需求是限制为200字符,然后我在后端做校验时直接使用len(str) > 200来做判断,结果出现了bug,前端字符校验没有超过200字符,调用后端接口确一直是参数错误,改成使用len([]rune(str)) > 200成功解决了这个问题。具体原因我们在文中揭晓。
Unicode和字符编码
在介绍rune类型之前,我们还是要从一些基础知识开始。 ——— Unicode和字符编码。
- 什么是Unicode?
我们都知道计算机只能处理数字,如果想要处理文本需要转换为数字才能处理,早些时候,计算机在设计上采用8bit作为一个byte,一个byte表示的最大整数就是255,想表示更大的整数,就需要更多的byte。显然,一个字节表示中文,是不够的,至少需要两个字节,而且还不能和ASCII编码冲突,所以,我国制定了GB2312编码,用来把中文编进去。但是世界上有很多语言,不同语言制定一个编码,就会不可避免地出现冲突,所以unicode字符就是来解决这个痛点的。Unicode把所有语言都统一到一套编码里。总结来说:”unicode其实就是对字符的一种编码方式,可以理解为一个字符—-数字的映射机制,利用一个数字即可表示一个字符。“
- 什么是字符编码?
虽然unicode把所有语言统一到一套编码里了,但是他却没有规定字符对应的二进制码是如何存储。以汉字“汉”为例,它的 Unicode 码点是 0x6c49,对应的二进制数是 110110001001001,二进制数有 15 位,这也就说明了它至少需要 2 个字节来表示。可以想象,在 Unicode 字典中往后的字符可能就需要 3 个字节或者 4 个字节,甚至更多字节来表示了。
这就导致了一些问题,计算机怎么知道你这个 2 个字节表示的是一个字符,而不是分别表示两个字符呢?这里我们可能会想到,那就取个最大的,假如 Unicode 中最大的字符用 4 字节就可以表示了,那么我们就将所有的字符都用 4 个字节来表示,不够的就往前面补 0。这样确实可以解决编码问题,但是却造成了空间的极大浪费,如果是一个英文文档,那文件大小就大出了 3 倍,这显然是无法接受的。
于是,为了较好的解决 Unicode 的编码问题, UTF-8 和 UTF-16 两种当前比较流行的编码方式诞生了。UTF-8 是目前互联网上使用最广泛的一种 Unicode 编码方式,它的最大特点就是可变长。它可以使用 1 - 4 个字节表示一个字符,根据字符的不同变换长度。在UTF-8编码中,一个英文为一个字节,一个中文为三个字节。
Go语言中的字符串
基本概念
先来看一下官方对string的定义:
// string is the set of all strings of 8-bit bytes, conventionally but not// necessarily representing UTF-8-encoded text. A string may be empty, but// not nil. Values of string type are immutable.type string string
人工翻译:
string是8位字节的集合,通常但不一定代表UTF-8编码的文本。string可以为空,但不能为nil。string的值是不能改变的
说得通俗一点,其实字符串实际上是只读的字节切片,对于字符串底层而言就是一个byte数组,不过这个数组是只读的,不允许修改。
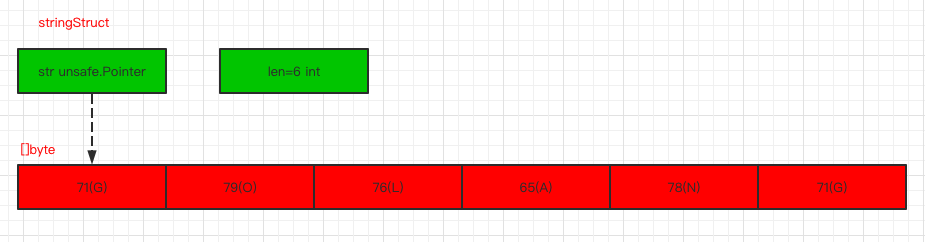
写个例子验证一下:
func main() {byte1 := []byte("Hl Asong!")byte1[1] = 'i'str1 := "Hl Asong!"str1[1] = 'i'}
对于byte的操作是可行,而string操作会直接报错:
cannot assign to str1[1]
所以说string修改操作是不允许的,仅仅支持替换操作。
根据前面的分析,我们也可以得出我们将字符存储在字符串中时,也就是按字节进行存储的,所以最后存储的其实是一个数值。
Go语言的字符串编码
上面我们介绍了字符串的基本概念,接下来我们看一下Go语言中的字符串编码是怎样的。
Go 源代码为 UTF-8 编码格式的,源代码中的字符串直接量是 UTF-8 文本。所以Go语言中字符串是UTF-8编码格式的。
Go语言字符串循环
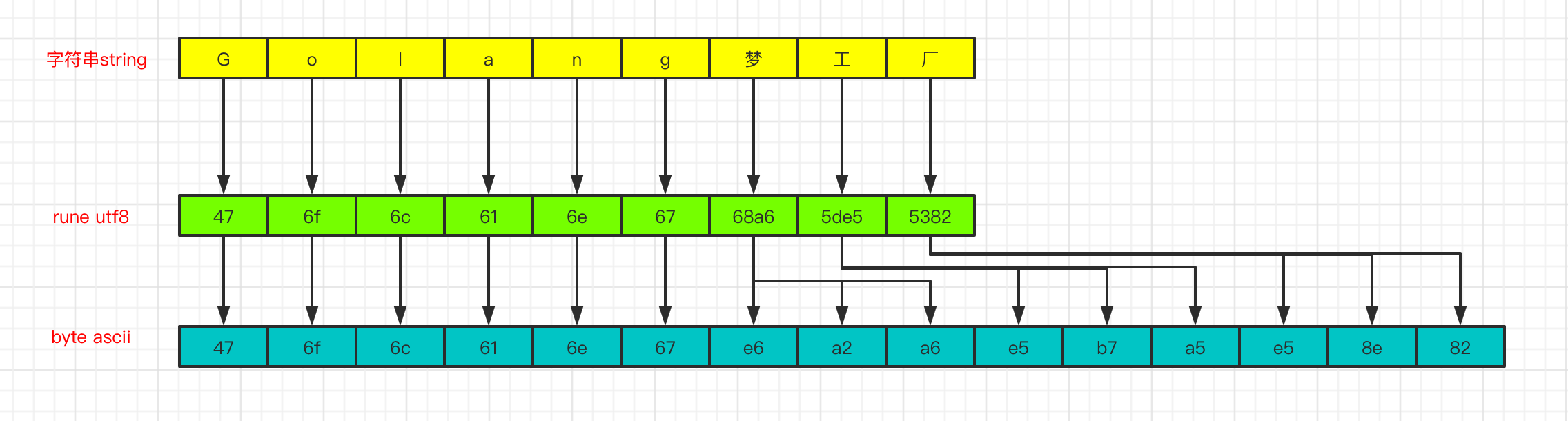
Go语言中字符串可以使用range循环和下标循环。我们写一个例子,看一下两种方式循环有什么区别:
func main() {str := "Golang梦工厂"for k,v := range str{fmt.Printf("v type: %T index,val: %v,%v \n",v,k,v)}for i:=0 ; i< len(str) ; i++{fmt.Printf("v type: %T index,val:%v,%v \n",str[i],i,str[i])}}
运行结果:
v type: int32 index,val: 0,71v type: int32 index,val: 1,111v type: int32 index,val: 2,108v type: int32 index,val: 3,97v type: int32 index,val: 4,110v type: int32 index,val: 5,103v type: int32 index,val: 6,26790v type: int32 index,val: 9,24037v type: int32 index,val: 12,21378v type: uint8 index,val:0,71v type: uint8 index,val:1,111v type: uint8 index,val:2,108v type: uint8 index,val:3,97v type: uint8 index,val:4,110v type: uint8 index,val:5,103v type: uint8 index,val:6,230v type: uint8 index,val:7,162v type: uint8 index,val:8,166v type: uint8 index,val:9,229v type: uint8 index,val:10,183v type: uint8 index,val:11,165v type: uint8 index,val:12,229v type: uint8 index,val:13,142v type: uint8 index,val:14,130
根据运行结果我们可以得出如下结论:
使用下标遍历获取的是ASCII字符,而使用Range遍历获取的是Unicode字符。
什么是rune数据类型
官方对rune的定义如下:
// rune is an alias for int32 and is equivalent to int32 in all ways. It is// used, by convention, to distinguish character values from integer values.type rune = int32
人工翻译:
rune是int32的别名,在所有方面都等同于int32,按照约定,它用于区分字符值和整数值。
说的通俗一点就是rune一个值代表的就是一个Unicode字符,因为一个Go语言中字符串编码为UTF-8,使用1-4字节就可以表示一个字符,所以使用int32类型范围就可以完美适配。
答案揭晓
前面说了这么多知识点,确实有点乱了,我们现在就根据开始的那道题来做一个总结。为了方便查看,在贴一下这道题:
func main() {str := "Golang梦工厂"fmt.Println(len(str))fmt.Println(len([]rune(str)))}
这道题的正确答案是15和9。
具体原因:
len()函数是用来获取字符串的字节长度,rune一个值代表的就是一个Unicode字符,所以求rune切片的长度就是字符个数。因为在utf-8编码中,英文占1个字节,中文占3个字节,所以最终结果就是15和9。
贴个图,方便理解:
unicode/utf8库
如果大家对rune的使用不是很明确,可以学习使用一下Go标准库unicode/utf8,其中提供了多种关于rune的使用方法。比如上面这道题,我们就可以使用utf8.RuneCountInString方法获取字符个数。更多库函数使用方法请自行解锁,本篇就不做过多介绍了。
总结
针对全文,我们做一个总结:
- Go语言源代码始终为UTF-8
- Go语言的字符串可以包含任意字节,字符底层是一个只读的byte数组。
- Go语言中字符串可以进行循环,使用下表循环获取的acsii字符,使用range循环获取的unicode字符。
- Go语言中提供了rune类型用来区分字符值和整数值,一个值代表的就是一个Unicode字符。
- Go语言中获取字符串的字节长度使用len()函数,获取字符串的字符个数使用utf8.RuneCountInString函数或者转换为rune切片求其长度,这两种方法都可以达到预期结果。

若有收获,就点个赞吧
0 人点赞
