一、背景
传统方式应用部署是通过插件和脚本来安装应用,是将所有应用直接部署在同一个物理机器节点上,这样每个App的依赖都是完全相同的,不利于App的更新与回滚,需要实现App之间隔离,可通过创建虚拟机(虚拟化的一种)的方式来将App部署到其中,但这样仍然太过繁重,且不方便在不同的环境和系统中迁移(每一个新的虚拟环境就得重新部署一边应用),故比虚拟机更轻便的Docker技术出现,现在我们通过部署Container容器的技术来部署应用,全部Container运行在容器引擎上即可。
简单总结:传统虚拟技术就是虚拟机中可以创建多个虚拟系统,一个虚拟系统执行一个程序,docker容器就是能够实现在一个系统通过设置多个容器、每个容器包含一个程序的方式来执行,更轻便。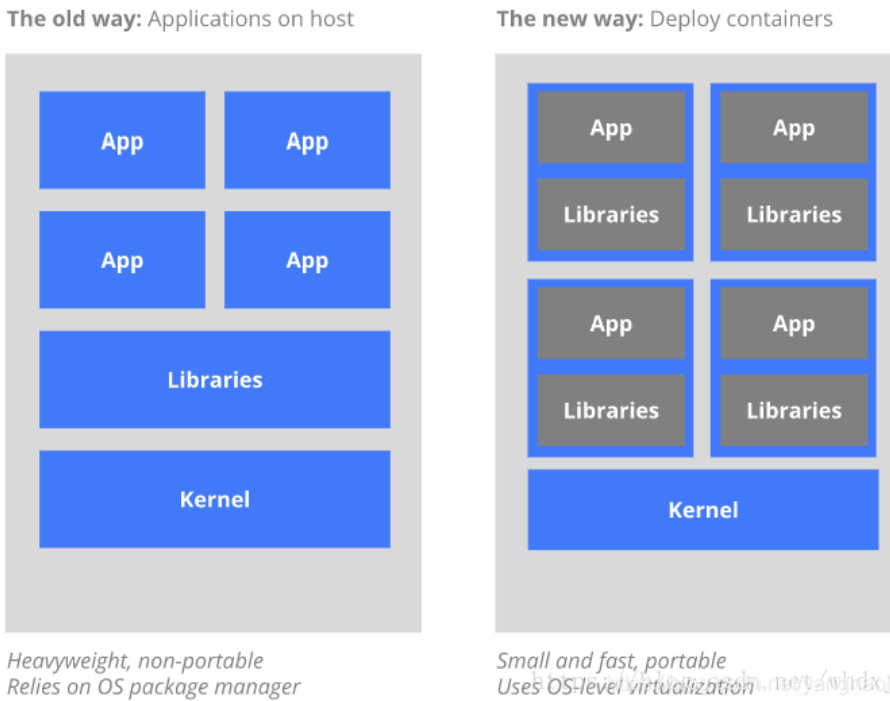
Docker技术的三大核心概念,分别是:
- 镜像(Image)
- 容器(Container)
- 仓库(Repository)
容器用于运行程序,仓库存放Docker镜像,Docker镜像就是一个特殊的文件系统。将容器运行时所需的程序、库、资源、配置等文件以及为运行时准备的一些配置参数(例如环境变量)制作成镜像。再任意虚拟服务器中拉取镜像,就直接实现了应用在此的部署,而不需要重新配置环境了。镜像拉取完成就变成了容器。
既然嫌弃虚拟机繁重,想用Docker,怎么用呢?手动一个一个创建?当然不,故kubernetes技术便出现了,以kubernetes为代表的容器集群管理系统,这时候就该上场表演了
一个K8S系统,通常称为一个K8S集群(即Cluster,Cluster是计算、存储和网络资源的集合,Kubernetes 利用这些资源运行各种基于容器的应用,最简单的 Cluster 可以只有一台主机(它既是 Mater 也是 Node)),这个集群主要包括两个部分:
- 一个Master节点(主节点)
- 一群Node节点(计算节点)
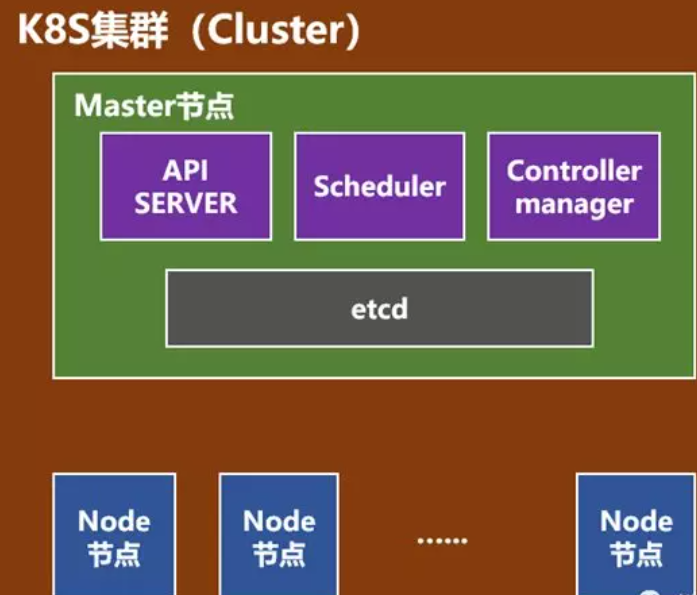
Master节点包括API Server、Scheduler、Controller manager、etcd
1、API Server是整个系统的对外接口,供客户端和其它组件调用,相当于“营业厅”,一个Service可以看作一组提供相同服务的Pod的对外访问接口。
2、Scheduler负责对集群内部的资源进行调度,相当于公交车指挥中心,在合理的时间指挥合适的车运行
3、Controller manager,管理控制器,是在集群上管理和运行容器的对象,一对一的对资源进行控制(后文详细介绍)
4、etcd存储系统,保存集群相关数据
Pod是Kubernetes最基本的操作单元,多进程设计,pod生命周期短暂。它内部封装了一个(即便是只有一个容器,Kubernetes 管理的也是 Pod 而不是直接管理容器)或多个紧密相关的容器,一个容器运行一个应用程序(单进程),容器是共享网络的。
Docker
Kubelet,负责监视指派到它所在Node上的Pod,包括创建、修改、监控、删除等,master派到节点的代表
Kube-proxy,主要负责为Pod对象提供网络代理(负载均衡)
Fluentd,主要负责日志收集、存储与查询
二、yaml文件
三、配置:
配置流程跟着文档走,sudo rke up/sudo rke remove————rke启停
管理员用户(root)和系统用户(zx为例)是两个用户,在搭建k8s集群时设置节点扮演controlplane、etcd、worker的角色是通过用户名进行相互间的访问申请依据的,一般在一个节点中用系统用户名申请,不用管理员用户。在查看和访问一些文件是是需要通过sudo指令以管理员身份访问的。或者通过sudo su指令直接切换成管理员身份进行访问。
Linux内核在启动或者运行的时候,能接收某些命令行选项或参数。当内核不能识别某些硬件进而不能设置硬件参数或者为了避免内核更改某些参数的值,可以通过手动将这些参数传递给内核。流程中一样需要对k8s系统进行内核参数配置: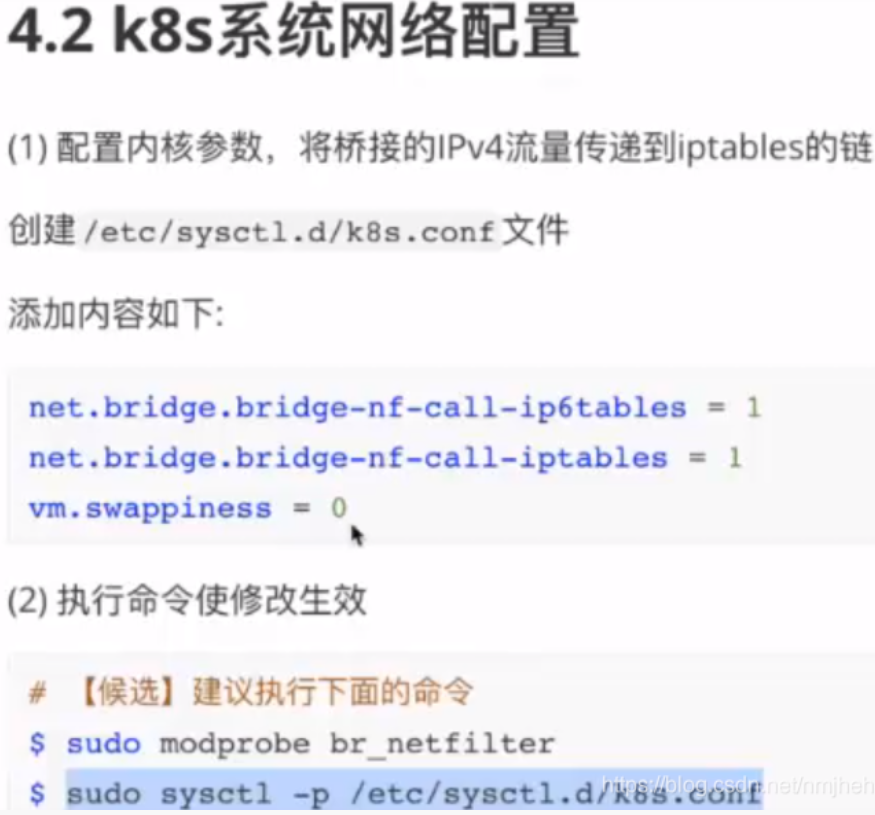
或者:
sysctl命令被用于在内核运行时动态地修改内核的运行参数,可用的内核参数在目录/proc/sys中。它包含一些TCP / ip和虚拟内存系统的高级选项,用sysctl可以读取设置超过五百个系统变量。-p命令是指默认从配置文件“/etc/sysctl.conf”加载内核参数设置,可以指定其他文件。
四、cluster.yml文件
和上面提到的yaml文件格式一样,但是功能不一样,yaml文件是在真正部署资源应用时所需要配置的文件,而cluster是在搭建k8s节点的为各个节点信息所配置的文件,这是rancher特有的k8s搭建所提供的配置文件,在cluster.yml配置好并rkeup后会生成相匹配kube_config_cluster.yml文件,并在之后的kubectl命令中以该配置文件作为附加FLAG执行相关指令。
五、Namespace&&name
Namespace类似于Linux系统中用户的概念,当团队或项目中有许多用户时,可考虑使用Namespace来区分,它可以将一个物理的Cluster逻辑上划分成多个虚拟Cluster,每个Cluster就是一个Namespace。
不同 Namespace 里的资源是完全隔离的。同一Namespace下的Kubenetes对象的Name必须唯一,常见的 pod,service,replication controller 和 deployment 等都是属于某一个 namespace ,而 node,persistent volume,namespace 等资源则不属于任何 namespace。
Kubernetes 默认创建了两个 Namespace:
- default:创建资源时如果不指定任何namespace(指令不加任何限制条件),那么将被放到这个 Namespace 中。
- kube-system:Kubernetes 自己创建的系统资源将放到这个 Namespace 中,通常包含如kube-dns,kube-proxy,kubernetes-dashboard之类的Pod,以及诸如fluentd,heapster,ingress等之类的东西。
关于name和namespace:
Name是创建一个Kubernetes对象时必须指定的,无论是Pod,ReplicaSet或者Deployment等等。在同一个命名空间下,同种类型的对象,其Name必须唯一。
六、Flannel原理
Flannel是CoreOS团队针对Kubernetes设计的一个网络规划服务,简单来说,它的功能是让集群中的不同节点主机创建的Docker容器都具有全集群唯一的虚拟IP地址。但在默认的Docker配置中,每个Node的Docker服务会分别负责所在节点容器的IP分配。Node内部得容器之间可以相互访问,但是跨主机(Node)网络相互间是不能通信。Flannel设计目的就是为集群中所有节点重新规划IP地址的使用规则,从而使得不同节点上的容器能够获得”同属一个内网”且”不重复的”IP地址,并让属于不同节点上的容器能够直接通过内网IP通信。具体见这里
七、流程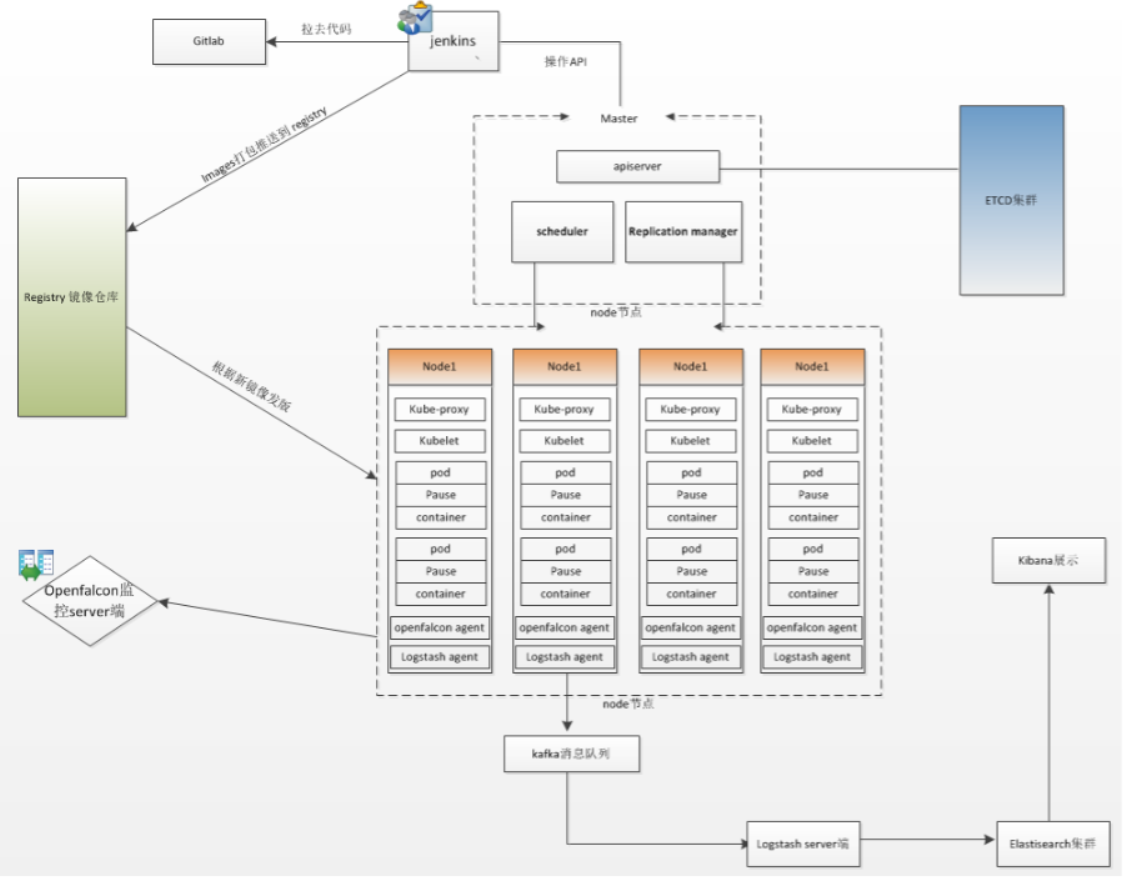

若有收获,就点个赞吧
0 人点赞
