汇总数据层以分析的主题对象作为建模驱动,基于上层的应用和产品的指标需求构建公共粒度的汇总表。汇总数据层的一个表通常会对应一个统计粒度(维度或维度组合)及该粒度下若干派生指标。
命名规范
命名规则:{project_name}.dws{业务缩写/pub}{数据域缩写}{数据粒度缩写}[{自定义表命名标签缩写}]{统计时间周期范围缩写}{刷新周期标识}{单分区增量全量标识}。
命名说明:
- 在默认情况下,离线计算应该包括最近一天(1d)、最近N天(nd)和历史截至当天(td)三个表。如果nd表的字段过多,需要拆分时,只允许以一个统计周期单元作为原子拆分,即一个统计周期拆分一个表。例如,最近7天(1w)拆分一个表,不允许拆分出来的一个表存储多个统计周期。
- 对于{刷新周期标识}和{单分区增量全量标识}在汇总层不做强制要求。单分区增量全量标识:i表示增量,f表示全量。
- 对于小时表不管是按天刷新还是按小时刷新,都用_hh来表示。
- 对于分钟表不管是按天刷新还是按小时刷新,都用_mm来表示。
汇总表设计原则
聚集是指针对原始明细粒度的数据进行汇总。DWS汇总数据层是面向分析对象的主题聚集建模。在本教程中,最终的分析目标为:最近一天某个类目(例如,厨具)商品在各省的销售总额、该类目销售额Top10的商品名称、各省用户购买力分布。因此,我们可以以最终交易成功的商品、类目、买家等角度对最近一天的数据进行汇总。
数据聚集的注意事项如下:
聚集是不跨越事实的
聚集是针对原始星形模型进行的汇总。为获取和查询与原始模型一致的结果,聚集的维度和度量必须与原始模型保持一致,因此聚集是不跨越事实的,所以原子指标只能基于一张事实表定义,但是支持原子指标组合为衍生原子指标
聚集会带来查询性能的提升,但聚集也会增加ETL维护的难度
当子类目对应的一级类目发生变更时,先前存在的、已经被汇总到聚集表中的数据需要被重新调整。
此外,进行DWS层设计时还需遵循数据公用性原则。数据公用性需要考虑汇总的聚集是否可以提供给第三方使用。您可以思考,基于某个维度的聚集是否经常用于数据分析中。如果答案是肯定的,就有必要把明细数据经过汇总沉淀到聚集表中。
数据存储及生命周期管理规范
CDM汇总层的表的类型为事实表,存储方式为按天分区。
事务型事实表一般会永久保存。周期快照型事实表根据业务需求设置生命周期管理。您可依据3个月内的最大需要访问的跨度设置保留策略,具体计算方式如下:
- 当3个月内的最大访问跨度小于或等于4天时,建议将保留天数设为7天。
- 当3个月内的最大访问跨度小于或等于12天时,建议将保留天数设为15天。
- 当3个月内的最大访问跨度小于或等于30天时,建议将保留天数设为33天。
- 当3个月内的最大访问跨度小于或等于90天时,建议将保留天数设为93天。
- 当3个月内的最大访问跨度小于或等于180天时,建议将保留天数设为183天。
创建汇总逻辑表
组成汇总表的统计指标有两种来源,具体如下:
1.系统按照相同统计粒度,自动汇聚。派生指标提交后,系统会自动生成新的汇总表。如下图所示。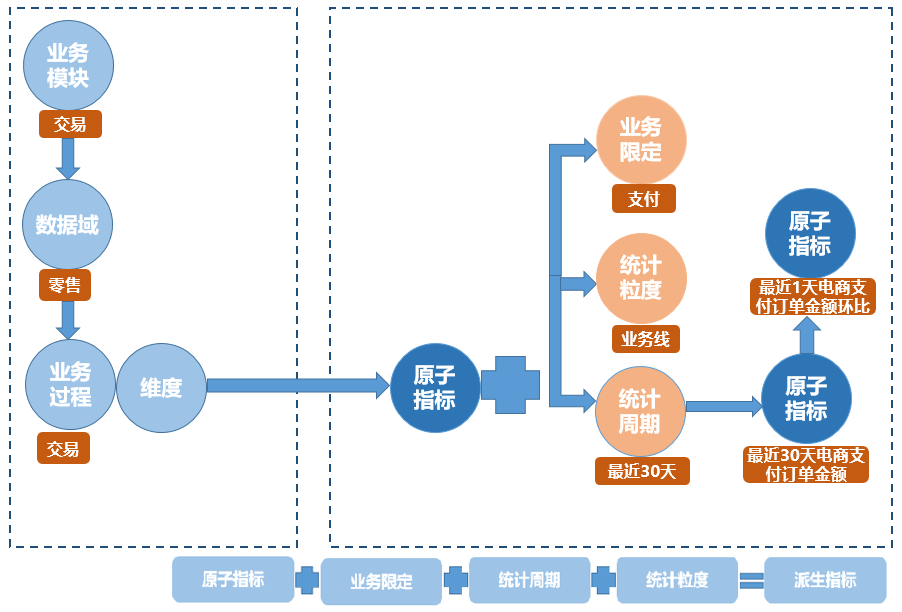
2.通过非派生指标的方式,创建汇总逻辑表

若有收获,就点个赞吧
0 人点赞
