1、L1正则和L2正则总结
损失函数形式
所说的正则化,其实就是在原损失函数的基础上添加惩罚项进行约束。我们以线性回归为例,L1、L2的具体形式如下所示:
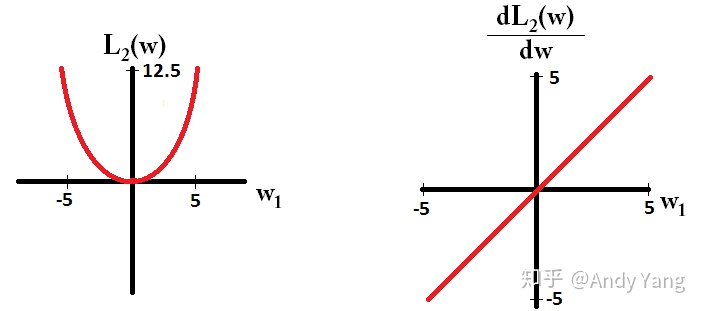
可以看出,L1正则项是是参数权重的绝对值之和。L2正则项是参数权重的平方和。
导数形式
|X|即绝对值X的图像和X2 的图像、以及二者的导数图像如下图所示: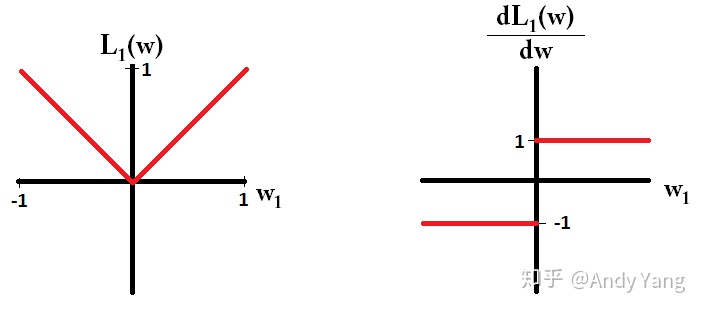
为什么正则项可以避免过拟合?
其实正则项可以看作是结构风险最小化的一种手段。
如果损失函数中不包含正则项,那么学习好的模型虽然能够保证经验风险最小,但是很可能得到的是一个复杂的模型,其泛化能力并不够好。那么加入正则项后的损失函数,不仅考虑了模型的经验误差还考虑了模型自身的复杂程度,这样就可以在二者之间做权衡。最终得到相对简单、泛化能力较好的模型。从而符合奥卡姆剃刀原则。降低模型复杂度,得到更小的泛化误差、缓解过拟合的程度。
L1正则化使得模型参数具有稀疏性的原理?
所谓稀疏性,就是获得参数多为0。
网上的解释有很多种,此处总结最为经典的解释:解空间形状。
我们先给出结论图: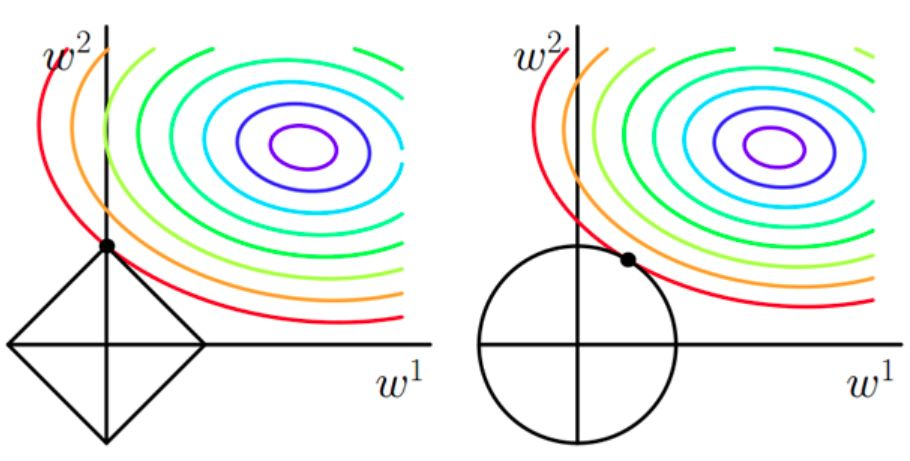
在二维的情况下,菱形部分是添加L1正则约束后的解空间,圆形部分是添加L2正则约束后的解空间,彩色的圆圈是目标函数的等高线,显然,L1的多边形解空间更容易在尖角处与等高线碰撞出稀疏解,因为此时w1为0。如果拓展到多维,则会产生很多0值。而L2正则的解空间则更容易在靠近坐标轴的位置与等高线相切,此处w的值倾向于0,但不为0。也就是说权重很小但不是0。
网上还有很多其他解释,但是感觉都不是很容易懂。目前记录这些~~~
2、深度学习中优化算法、优化器总结?
梯度下降法
梯度下降法中主要包括三种算法,分别是批量梯度下降法(BGD)、随机梯度下降法(SGD)、小批量梯度下降法(Mini-Batch GD)。
三者的总结和优缺点见下表:
| 算法 | 原理 | 优点 | 缺点 |
|---|---|---|---|
| 批量梯度下降法(BGD) | 使用全部数据集样本来更新梯度 | 每次更新都是按照全局最优的方向更新 | 内存消耗大、在大数据的情况下基本不可行 |
| 随机梯度下降法(SGD) | 每次仅使用单个样本对梯度进行更新 | 内存友好,适合于数据源源不断的在线更新场景 | 震荡剧烈、迭代不稳定 |
| 小批量梯度下降法(Mini-Batch GD) | 每次使用batch大小的数据子集更新梯度 | 降低了随即梯度的方差、迭代算法稳定、充分利用高度优化的矩阵运算 | 需要设置batchsize、需要shuffle |
再总结优化器之前,需要明确一个问题:
随即梯度下降法(SGD)为什么会失效?
由于随机梯度下降法每次只选择一个样本对梯度进行更新,单单一个样本是无法来近似全局样本集的分布的。也就是在梯度更新的时候,每一步所能依赖的信息太有限了,导致每一步的更新的梯度常常出现偏差,也就是梯度的方差太大,目标函数曲线抖动剧烈,有的时候将会出现不收敛的情况。也就是九曲黄河十八弯~~
深度学习中经典的优化器
| 优化器 | 原理 | 优点 | 缺点 |
|---|---|---|---|
| Momentum | 当前梯度更新的步伐不仅和当前的梯度有关,还要结合上一步梯度更新的步伐信息。也就是保持上一步伐的惯性信息。 | 减少震荡、收敛速度更快、收敛曲线更加稳定 | 所有参数的更新步伐都是一致的,没有考虑到自适应参数更新 |
| AdaGrad | 利用历史梯度的平方和,自适应的更新参数。也就是实现了退火算法。前期历史梯度小更新快、后期历史梯度累加大,梯度更新慢 | 可以实现参数的自适应的更新,模拟了退火的过程。 | 中后期的时候,由于梯度累加和较大,导致参数的更新较慢,甚至到最后不更新,提前结束学习,造成无法学习。 |
| Adam | 利用过往梯度和当前梯度的平均保持惯性 利用过往梯度平方和当前梯度平方的平均,对不同的参数实现自适应的学习速率。 |
结合了上述二者的优点 |
3、激活函数总结
激活函数的作用
激活函数可以给神经网络模型引入非线性因素,以至于令网络更加复杂强大,以避免多层神经网络等效于单层线性函数,从而获得强大的学习和拟合能力。
常见的激活函数有哪些?
对于常见的激活函数,百面上面只给出了sigmoid、tanh、relu三种,看了知乎的一些文章,另外在总结一下leakyRelu、PRelu、ELU、Maxout。
分别来看一下:
Sigmoid
函数形式、图像、导数形式、图像: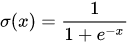 、
、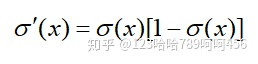
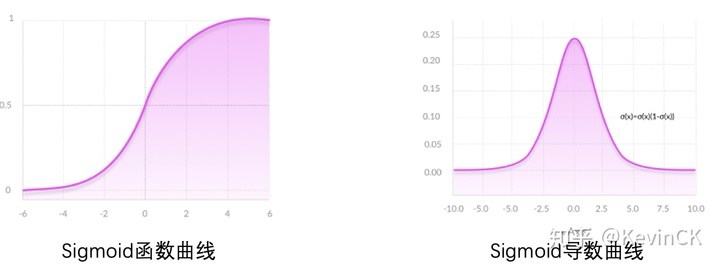
优点:
- 该函数输出在0-1之间,适合概率值的输出。
- 连续函数,便于求导。
缺点:
- 双侧饱和现象:sigmoid的输入如果在[-∞,-6]或者在[6,+∞]之间时,sigmoid的函数图像趋近于平稳,也就是说在反向传播的时候,这样的输入将导致梯度为0,参数的权重根本不会更新,很容易出现梯度消失问题,从而无法完成深层网络的训练。这也跟sigmoid的导数范围是0-0.25的小数是一个道理。
- 非0均值问题:sigmoid的函数图像并不是以0为中心对称的,而是以0.5为中心。那么也就是说sigmoid的输出不是0均值的,这将会导致原0均值的输入数据经过sigmoid后变成0.5均值的,如果随着网络层数的增加,输入数据的原始分布将会被改变。
- 指数计算问题:sigmoid原函数、导函数的计算都包含指数计算,这将是非常消耗时间。
Tanh
Tanh又称双曲正切函数,函数值域为[-1,1]。
函数公式、导函数公式、二者图像如下: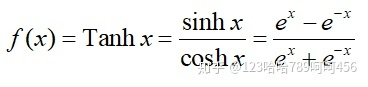
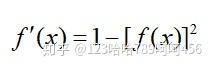
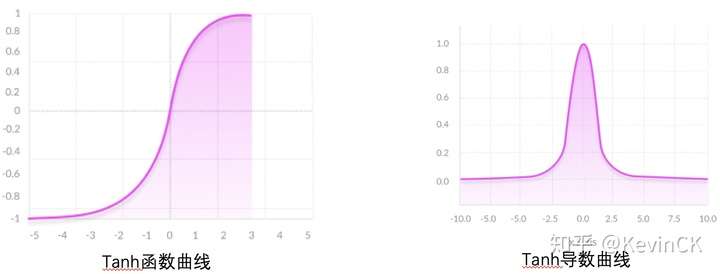
优点:**
- 相比入sigmoid,tanh是0均值的,在传播的过程中,其输出不会改变数据的原始分布
- tanh的导数范围在[0,1]之间,对比于sigmoid的[0,0.25],梯度消失问题可以得到缓解,但并不能完全解决。
Relu
Relu的函数图像和导函数图像: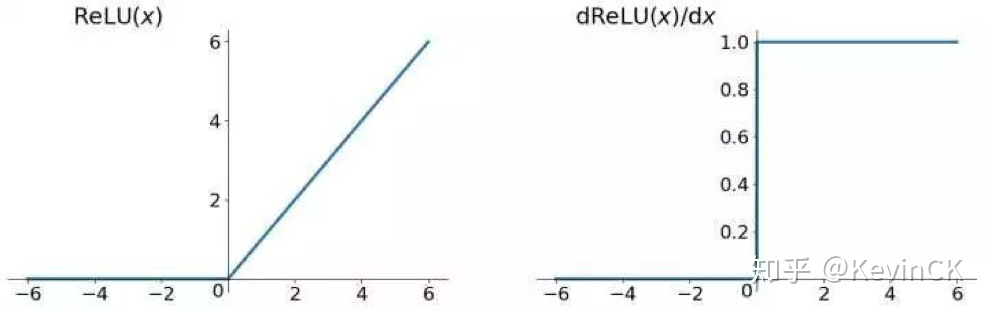
分段考虑Relu
X>0
当x大于0的时候,relu的函数表示为y=x。并且导数恒为1。这个好处就是,在输入大于0的情况下,relu不会出现梯度消失的问题,并且梯度的大小将完全取决于参数权重的大小,因为relu的导数恒为1,那么这样也可能会出现梯度爆炸的问题,但是我认为主要原因还是参数初始化过大的原因导致的。
X<0**
当x小于0的时候,relu的输出恒为0,导数也恒为0。
深度学习的目标我们可以认为是从大量的样本中学习到稀疏特征,而这些稀疏特征则是关键特征,那么也就是需要在大量的数据特征中去除掉噪声。而relu的左半部分,可以看成是特征筛选、剔除噪声的作用。用百面的话来讲,就是relu具备单侧抑制能力,可以给网络提供较好的稀疏表达能力。
优点:
- 运算速度快、没有指数运算
- 具有非饱和性、可解决梯度消失问题
- 单侧抑制能力,可以提供较好的网络稀疏表达能力
缺点:
- deadrelu 问题
什么是dead relu问题?如何解决?
dead relu指的是由于relu的左半部分单侧抑制,对于负数的输入,relu对应的导数为0,那么在反向传播链式求导的过程中,由于连乘的存在,导致对应输入为负数的参数权重的梯度均为0,权重无法更新,也就是所说的神经元假死问题。
这种问题如何出现的?
- relu的使用,单侧抑制的缺点
- 学习率较大,造成权重的更新波动较大,一旦某些参数更新之后为负值,那么经过relu之后,梯度全为0,连乘之后,也还是0,造成这部分参数无法更新。
解决办法:
- 对于负数的输入,不要关闭激活,而是给一个小的激活值,例如:leaky relu、elu、random relu
- 避免使用过大的学习率,降低波动带来的影响
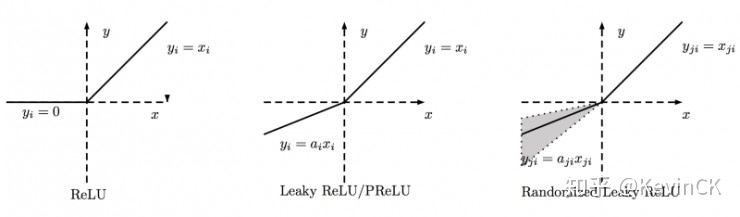
leaky reku
Leaky ReLU中的 为常数,一般设置 0.01。这个函数通常比 Relu 激活函数效果要好,但是效果不是很稳定,所以在实际中 Leaky ReLu 使用的并不多。
为常数,一般设置 0.01。这个函数通常比 Relu 激活函数效果要好,但是效果不是很稳定,所以在实际中 Leaky ReLu 使用的并不多。
PRelu
 作为一个可学习的参数,会在训练的过程中进行更新。
作为一个可学习的参数,会在训练的过程中进行更新。
Random Relu
也是Leaky ReLU的一个变体。在RReLU中,负值的斜率在训练中是随机的,在之后的测试中就变成了固定的了。RReLU的亮点在于,在训练环节中,aji是从一个均匀的分布U(I,u)中随机抽取的数值。
4、梯度消失和梯度爆炸问题
梯度消失和梯度爆炸产生的原因?
本质上是因为神经网络的更新方法,梯度消失是因为反向传播过程中对梯度的求解会产生sigmoid导数和参数的连乘,sigmoid导数的最大值为0.25,权重一般初始都在0,1之间,乘积小于1,多层的话就会有多个小于1的值连乘,导致靠近输入层的梯度几乎为0,得不到更新。梯度爆炸是也是同样的原因,只是如果初始权重大于1,或者更大一些,多个大于1的值连乘,将会很大或溢出,导致梯度更新过大,模型无法收敛。
以上是来自知乎的回答,总结来看:
- 神经网络本身的参数学习是基于反向传播的梯度下降对局部最优解进行求解,那么反向传播的过程中,由于链式求导法则的存在,梯度的更新将会于激活函数的导数和权重有关系。也就是说,在链式求导连乘式中,包含了激活函数的导数和权重的连乘子式。
- 如果选择了sigmoid或者tanh作为激活函数,因为二者的导函数的值域都是在[0,1]之间的,并且sigmoid是在[0,0.25]之间,更加小。权重初始化的时候,一般都会选择正态分布,也就是0均值,1方差的分布,那么又有很多权重是小数,这样很多小数在一起连乘,将会造成梯度信息越来越小,反传到最初的前几层网络的时候,梯度几乎为0,造成梯度消失、前几层网络更新较慢。
- 梯度爆炸主要可以从权重初始化的角度分析,如果我们初始化的权重较大,存在很多大于1的值,那么在连乘中很可能梯度的更新至趋于无穷大,导致梯度更新较大,模型无法收敛。
各自的解决办法?
梯度爆炸;
合理的权重初始化方式、梯度裁剪
梯度消失:
BN、合理的激活函数、残差结构
BN解决梯度消失的原理?
首先要明确BN的作用(后续会单独总结BN),BN中文可以成为批归一化,其实是通过规范化操作(平移和缩放)将输出数据重新拉回到均值为0,方差为1的正态分布上,从而保证网络的稳定性。
因为在上文的总结中,可以看出sigmoid的导数会出现在连乘式中,如果输入至sigmoid的数据均大于6或者小于-6,那么其对应的导数是接近于零的,那么,也就是数据落入了sigmoid的双侧饱和区,无论数据的变动有多大,反映到梯度上都是接近于0的。但是BN是将输出数据通过缩放和平移将当前分布强行拉回到均值为0、方差为1的正态分布上,那么大多数的数据都将分布于0的左右(联想正态分布图像),恰好这些数值在sigmoid函数上是梯度更新最快的地方,那么也就是说,输入数据的小幅度变化,将换来激活函数输出的大幅度变化,那么损失函数也将得到大的变化。此时梯度更新变大,从而避免梯度消失问题,并且梯度变大,收敛速度加快,大大加速训练速度。
合理的激活函数详见总结3
残差结构如何解决梯度消失?
详细的文章解释可参考:
其主要原因就是,ResNet以及DenseNet引入了Skip connection结构。我们对于传统的神经网络输入输出的公式表达为: ,那么由于梯度需要反向传播和链式求导法则的存在,如果网络层次太深,并且在链式求导的过程中,连乘了很多0-1之间的梯度值,那么当输出层处的梯度反传至输入层处时,梯度值将越来越小,导致靠近输入层的网络层的参数几乎得不到更新。
,那么由于梯度需要反向传播和链式求导法则的存在,如果网络层次太深,并且在链式求导的过程中,连乘了很多0-1之间的梯度值,那么当输出层处的梯度反传至输入层处时,梯度值将越来越小,导致靠近输入层的网络层的参数几乎得不到更新。
但是一旦引入残差结构或者dense结构。那么输入输出的公式表达为: 。
。
可以看到,公式中多了一项x,其实这就是残差结构或者说skip-connection直接传递过来的。那么无论对x怎么求导,其梯度恒为数值1。即使原来的分支由于链式求导出现梯度消失,但是因为存在恒定不变的梯度1,那么反传的梯度无论如何都不会消失。这也就是凯明认为只有显存是限制网络深度的唯一因素。
合理的初始化方式解决梯度爆炸?
5、损失函数总结

若有收获,就点个赞吧
0 人点赞
