当我们构建一个应用,总是希望它是响应迅速,成本低廉的。而在实际中,我们的系统却面临各种各样的挑战,例如不可预测的流量高峰,依赖的下游服务变得缓慢,少量请求却消耗大量 CPU/内存资源。这些因素常常导致整个系统被拖慢,甚至不能响应请求。为了让应用服务总是响应迅速,很多时候不得不预留更多的计算资源,但大部分时候,这些计算资源都是闲置的。一种更好的做法是将耗时缓慢,或者需要消耗大量资源的处理逻辑从请求处理主逻辑中剥离出来,交给更具资源弹性的系统异步执行,不但让请求能够被迅速处理返回给用户,也节省了成本。
一般来说,长耗时,消耗大量资源,或者容易出错的逻辑,非常适合从请求主流程中剥离出来,异步执行。例如新用户注册,注册成功后,系统通常会发送一封欢迎邮件。发送欢迎邮件的动作就可以从注册流程中剥离出来。另一个例子是用户上传图片,图片上传后通常需要生成不同大小的缩略图。但图片处理的过程不必包含在图片上传处理流程中,用户上传图片成功后就可以结束流程,生成缩略图等处理逻辑可以作为异步任务执行。这样应用服务器避免被图片处理等计算密集型任务压垮,用户也能更快的得到响应。常见的异步执行任务包括:
- 发送电子邮件/即时消息
- 检查垃圾邮件
- 文档处理(转换格式,导出,……)
- 音视频,图片处理(生成缩略图,加水印,鉴黄,转码,……)
- 调用外部的三方服务
- 重建搜索索引
- 导入/导出大量数据
- 网页爬虫
- 数据清洗
- ……
Slack,Pinterest,Facebook 等公司都广泛的使用异步任务,实现更好的服务可用性,更低的成本。根据Dropbox 统计,他们的业务场景中一共有超过100种不同类型的异步任务。一个功能完备的异步任务处理系统能带来显著的收益:
- 更快的系统响应时间。将长耗时的,重资源消耗的逻辑从请求处理流程中剥离,在别的地方异步执行,能有效的降低请求响应延时,带来更好的用户体验。
- 更好的处理大量突发性请求。在电商等很多场景下,常常有大量突发性请求对系统造成冲击。同样的,如果将重资源消耗逻辑从请求处理流程中剥离,在别的地方异步执行,那么相同资源容量的系统能响应更大峰值的请求流量。
- 更低的成本。异步任务的执行时长通常在数百毫秒到数小时之间,根据不同的任务类型,合理的选择任务执行时间和更弹性的使用资源,就能实现更低的成本。
- 更完善的重试策略和错误处理能力。任务保证被可靠的执行(at-least-once),并且按照配置的重试策略进行重试,从而实现更好的容错能力。例如调用第三方的下游服务,如果能变成异步任务,设置合理的重试策略,即使下游服务偶尔不稳定,也不影响任务的成功率。
- 更快的完成任务处理。多个任务的执行是高度并行化的。通过伸缩异步任务处理系统的资源,海量的任务能够在合理的成本内更快的完成。
- 更好的任务优先级管理和流控。任务根据类型,通常按照不同的优先级处理。异步任务管理系统能帮助用户更好的隔离不同优先级的任务,既让高优先级任务能更快的被处理,又让低优先级任务不至于被饿死。
- 更多样化的任务触发方式。任务的触发方式是多种多样的,例如通过 API 直接提交任务,或是通过事件触发,或是定时执行等等。
- 更好的可观测性。异步任务处理系统通常会提供任务日志,指标,状态查询,链路追踪等能力,让异步任务更好的被观测、更容易诊断问题。
- 更高的研发效率。用户专注于任务处理逻辑的实现,任务调度,资源扩缩容,高可用,流控,任务优先级等功能都由任务处理系统完成,研发效率大幅提高。
一 任务处理系统架构
**
任务处理系统通常包括三部分:任务 API 和可观测,任务分发和任务执行。我们首先介绍这三个子系统的功能,然后再讨论整个系统面临的技术挑战和解决方案。

1 任务 API/Dashboard
该子系统提供一组任务相关的 API,包括任务创建、查询、删除等等。用户通过 GUI,命令行工具,后者直接调用 API 的方式使用系统功能。以 Dashboard 等方式呈现的可观测能力也非常重要。好的任务处理系统应当包括以下可观测能力:
- 日志:能够收集和展示任务日志,用户能够快速查询指定任务的日志。
- 指标:系统需要提供排队任务数等关键指标,帮助用户快速判断任务的执行情况。
- 链路追踪:任务从提交到执行过程中,各个环节的耗时。比如在队列中排队的时间,实际执行的时间等等。下图展示了 Netflix Cosmos 平台的 tracing 能力。
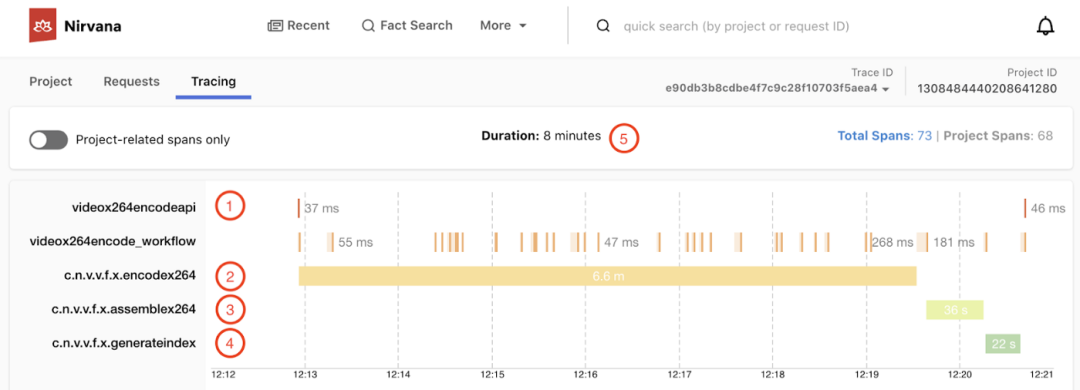
2 任务分发
任务分发负责任务的调度分发。一个能应用于生产环境的任务分发系统通常要具备以下功能:
- 任务的可靠分发:任务一旦提交成功后,无论遇到任何情况,系统都应当保证该任务被调度执行。
- 任务的定时/延时分发:很多类型的任务,希望在指定的时间执行,例如定时发送邮件/消息,或者定时生成数据报表。另一种情况是任务可以延时较长一段时间执行也没问题,例如下班前提交的数据分析任务在第二天上班前完成即可,这类任务可以放到凌晨资源消耗低峰的时候执行,通过错峰执行降低成本。
- 任务去重:我们总是不希望任务被重复执行。除了造成资源浪费,任务重复执行可能造成更严重的后果。比如一个计量任务因为重复执行算错了账单。要做到任务只执行一次(exactly-once),需要在任务提交,分发,执行全链路上的每个环节都做到,包括用户在实现任务处理代码时也要在执行成功,执行失败等各种情况下,做到 exactly-once。如何实现完整的 exactly-once 比较复杂,超出了本文的讨论范围。很多时候,系统提供一个简化的语义也很有价值,即任务只成功执行一次。任务去重需要用户在提交任务时指定任务 ID,系统通过 ID来判断该任务是否已经被提交和成功执行过。
- 任务错误重试:合理的任务重试策略对高效、可靠的完成任务非常关键。任务的重试要考虑几个因素:1)要匹配下游任务执行系统的处理能力。比如收到下游任务执行系统的流控错误,或者感知到任务执行成为瓶颈,需要指数退避重试。不能因为重试反而加大了下游系统的压力,压垮下游;2)重试的策略要简单清晰,易于用户理解和配置。首先要对错误进行分类,区分不可重试错误,可重试错误,流控错误。不可重试错误是指确定性失败的错误,重试没有意义,比如参数错误,权限问题等等。可重试错误是指导致任务失败的因素具有偶然性,通过重试任务最终会成功,比如网络超时等系统内部错误。流控错误是一种比较特殊的可重试错误,通常意味着下游已经满负荷,重试需要采用退避模式,控制发送给下游的请求量。
- 任务的负载均衡:任务的执行时间变化很大,短的几百毫秒,长的数十小时。简单的 round-robin 方式分发任务,会导致执行节点负载不均。实践中常见的模式是将任务放置到队列中,执行节点根据自身任务执行情况主动拉取任务。使用队列保存任务,让根据节点的负载把任务分发到合适的节点上,让节点的负载均衡。任务负载均衡通常需要分发系统和执行子系统配合实现。
- 任务按优先级分发:任务处理系统通常对接很多的业务场景,他们的任务类型和优先级各不相同。位于业务核心体验相关的任务执行优先级要高于边缘任务。即使同样是消息通知,淘宝上买家收到一个商品评论通知的重要性肯定低于新冠疫情中的核酸检测通知。但另一方面,系统也要保持一定程度的公平,不要让高优先级任务总是抢占资源,而饿死低优先级任务。
- 任务流控:任务流控典型的使用场景是削峰填谷,比如用户一次性提交数十万的任务,期望在几个小时内慢慢处理。因此系统需要限制任务的分发速率,匹配下游任务执行的能力。任务流控也是保证系统可靠性的重要手段,某类任务提交量突然爆发式增长,系统要通过流控限制其对系统的冲击,减小对其他任务的影响。
- 批量暂停和删除任务:在实际生产环境,提供任务批量暂停和删除非常重要。用户总是会出现各种状况,比如任务的执行出现了某些问题,最好能暂停后续任务的执行,人工检查没有问题后,再恢复执行;或者临时暂停低优先级任务,释放计算资源用于执行更高优先级的任务。另一种情况是提交的任务有问题,执行没有意义。因此系统要能让用户非常方便的删除正在执行和排队中的任务。任务的暂停和删除需要分发和执行子系统配合实现。
任务分发的架构可分为拉模式和推模式。拉模式通过任务队列分发任务。执行任务的实例主动从任务队列中拉取任务,处理完毕后再拉取新任务。相对于拉模式,推模式增加了一个分配器的角色。分配器从任务队列中读取任务,进行调度,推送给合适的任务执行实例。
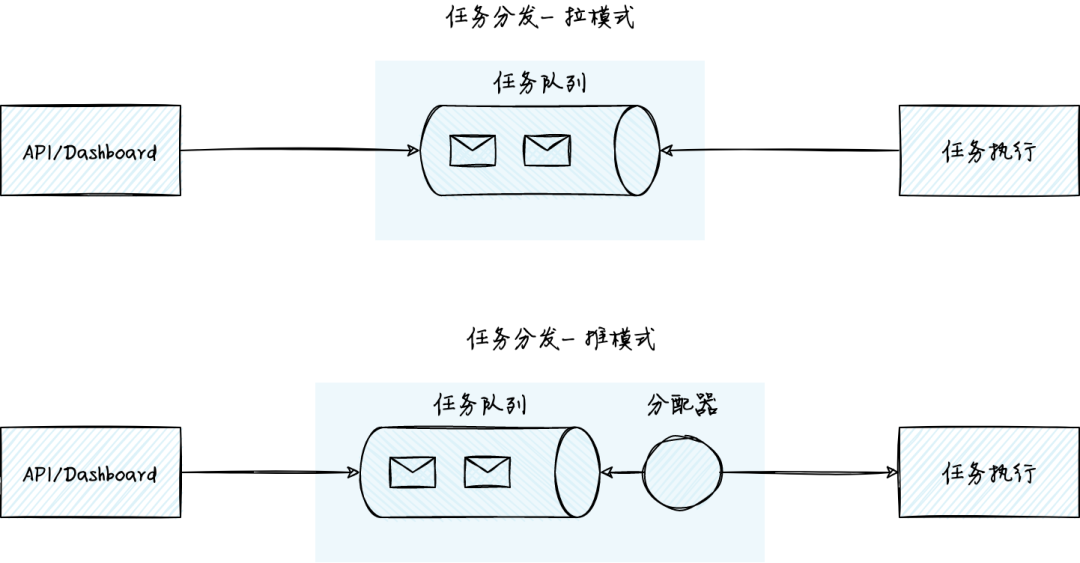
拉模式的架构清晰,基于 Redis 等流行软件可以快速搭建任务分发系统,在简单任务场景下表现良好。但如果要支持任务去重,任务优先级,批量暂停或删除,弹性的资源扩缩容等复杂业务场景需要的功能,拉模式的实现复杂度会迅速增加。实践中,拉模式面临以下一些主要的挑战:
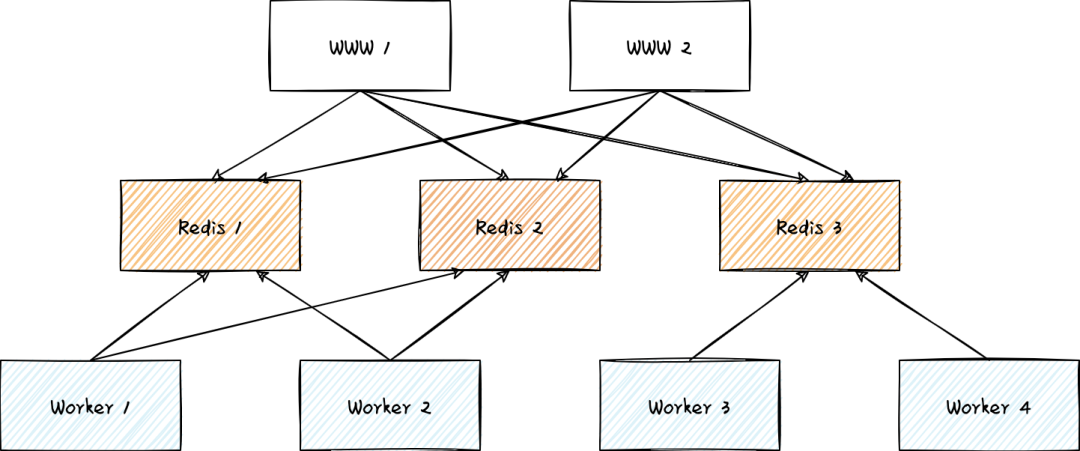
- 资源自动伸缩和负载均衡复杂。任务执行实例和任务队列建立连接,拉取任务。当任务执行实例规模较大时,对任务队列的连接资源会造成很大的压力。因此需要一层映射和分配,任务实例只和对应的任务队列连接。下图是 Slack 公司的异步任务处理系统架构。Worker 节点只和部分 Redis 实例相连。这解决了 worker 节点大规模扩展的能力,但是增加了调度和负载均衡的复杂度。
- 从支持任务优先级,隔离和流控等需求的角度考虑,最好能使用不同的队列。但队列过多,又增加了管理和连接资源消耗,如何平衡很有挑战。
- 任务去重,任务批量暂停或者删除等功能依赖消息队列功能,但很少有消息类产品能满足所有需求,常常需要自行开发。例如从可扩展性的角度,通常做不到每一类任务都对应单独的任务队列。当任务队列中包含多种类型的任务时,要批量暂停或者删除其中某一类的任务,是比较复杂的。
- 任务队列的任务类型和任务处理逻辑耦合。如果任务队列中包含多种类型的任务,要求任务处理逻辑也要实现相应的处理逻辑,对用户不友好。在实践中,A 用户的任务处理逻辑不会预期接收到别的用户任务,因此任务队列通常由用户自行管理,进一步增加了用户的负担。
推模式的核心思想是将任务队列和任务执行实例解耦,平台侧和用户的边界更加清晰。用户只需要专注于任务处理逻辑的实现,而任务队列,任务执行节点资源池的管理都由平台负责。推模式的解耦也让任务执行节点的扩容不再受任务队列的连接资源等方面的限制,能够实现更高的弹性。但推模式也引入了很多的复杂度,任务的优先级管理,负载均衡,调度分发,流控等都由分配器负责,分配器需要和上下游系统联动。
总的来说,当任务场景变得复杂后,无论拉还是推模式,系统复杂度都不低。但推模式让平台和用户的边界更清晰,简化了用户的使用复杂度,因此有较强技术实力的团队,实现平台级的任务处理系统时,通常会选择推模式。
3 任务执行
任务执行子系统管理一批执行任务的 worker 节点,以弹性、可靠的方式执行任务。典型的任务执行子系统需具备如下功能:
- 任务的可靠执行。任务一旦提交成功,无论任何情况,系统应当保证任务被执行。例如执行任务的节点宕机,任务应当调度到其他的节点执行。任务的可靠执行通常是任务分发和任务执行子系统共同配合实现。
- 共享资源池。不同类型的任务处理资源共享统一的资源池,这样才能削峰填谷,提高资源利用效率,降低成本。例如把计算密集,io密集等不同类型的任务调度到同一台 worker 节点上,就能更充分的利用节点上的CPU,内存,网络等多个维度的资源。共享资源池对容量管理,任务资源配额管理,任务优先级管理,资源隔离提出了更高的要求。
- 资源弹性伸缩。系统能根据负载的执行情况伸缩执行节点资源,降低成本。伸缩的时机和数量非常关键。常见的根据任务执行节点的 CPU,内存等资源水位情况伸缩,时间较长,不能满足实时性要求高的场景。很多系统也使用排队任务数等指标进行伸缩。另一个值得关注的点是执行节点的扩容需要匹配上下游系统的能力。例如当任务分发子系统使用队列来分发任务时,worker 节点的扩容要匹配队列的连接能力。
- 任务资源隔离。在 worker 节点上执行多个不同的任务时,资源是相互隔离的。通常使用容器的隔离机制实现。
- 任务资源配额。用户的使用场景多样,常常包含多种任务类型和优先级。系统要支持用户为不同优先级的任务或者处理函数设置资源配额,为高优先级任务预留资源,或者限制低优先级任务能使用的资源。
- 简化任务处理逻辑的编码。好的任务处理系统,能够让用户专注于实现单个任务处理逻辑,系统自动并行、弹性、可靠的执行任务。
- 平滑升级。底层系统的升级不要中断长时任务的执行。
- 执行结果通知。实时通知任务执行状态和结果。对于执行失败的任务,任务的输入被保存到死信队列中,方便用户随时手动重试。
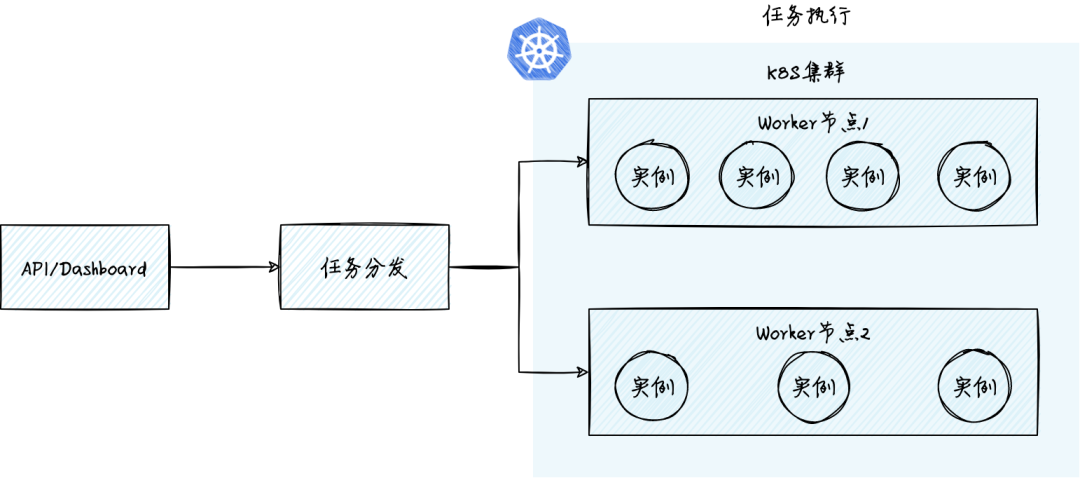
任务执行子系统通常使用 K8s 管理的容器集群作为资源池。K8s 能够管理节点,将执行任务的容器实例调度到合适的节点上。K8s 也内置了作业(Jobs)和定时作业(Cron Jobs)的支持,简化了用户使用 Job 负载的难度。K8s 有助于实现共享资源池管理,任务资源隔离等功能。但 K8s 主要能力还是在POD/实例管理上,很多时候需要开发更多的功能来满足异步任务场景的需求。例如:
- K8s 的 HPA 一般难以满足任务场景下的自动伸缩。Keda 等开源项目提供了按排队任务数等指标伸缩的模式。AWS 也结合 CloudWatch 提供了类似的解决方案。
- K8s 一般需要配合队列来实现异步任务,队列资源的管理需要用户自行负责。
- K8s 原生的作业调度和启动时间比较慢,而且提交作业的 tps 一般小于 200,所以不适合高 tps,短延时的任务。
注意:K8s 中的作业(Job)和本文讨论的任务(task)有一些区别。K8s 的 Job 通常包含处理一个或者多个任务。本文的任务是一个原子的概念,单个任务只在一个实例上执行。执行时长从几十毫秒到数小时不等。
**
二 大规模多租户异步任务处理系统实践
**
接下来,笔者以阿里云函数计算的异步任务处理系统为例,探讨大规模多租户异步任务处理系统的一些技术挑战和应对策略。在阿里云函数计算平台上,用户只需要创建任务处理函数,然后提交任务即可。整个异步任务的处理是弹性、高可用的,具备完整的可观测能力。在实践中,我们采用了多种策略来实现多租户环境的隔离、伸缩、负载均衡和流控,平滑处理海量用户的高度动态变化的负载。
1 动态队列资源伸缩和流量路由
如前所述,异步任务系统通常需要队列实现任务的分发。当任务处理中台对应很多业务方,那么为每一个应用/函数,甚至每一个用户都分配单独的队列资源就不再可行。因为绝大多数应用都是长尾的,调用低频,会造成大量队列,连接资源的浪费。并且轮询大量队列也降低了系统的可扩展性。
但如果所有用户都共享同一批队列资源,则会面临多租户场景中经典的“noisy neighbor”问题,A 应用突发式的负载挤占队列的处理能力,影响其他应用。
实践中,函数计算构建了动态队列资源池。一开始资源池内会预置一些队列资源,并将应用哈希映射到部分队列上。如果某些应用的流量快速增长时,系统会采取多种策略:
- 如果应用的流量持续保持高位,导致队列积压,系统将为他们自动创建单独的队列,并将流量分流到新的队列上。
- 将一些延时敏感,或者优先级高的应用流量迁移到其他队列上,避免被高流量应用产生的队列积压影响。
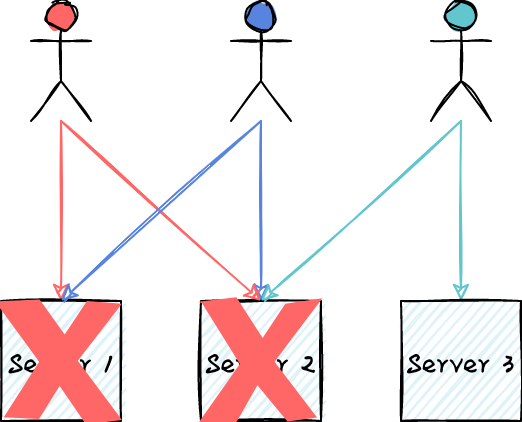
在一个多租环境中,防止“破坏者”对系统造成灾难性的破坏是系统设计的最大挑战。破坏者可能是被 DDoS 攻击的用户,或者在某些 corner case 下正好触发了系统 bug 的负载。下图展示了一种非常流行的架构,所有用户的流量以 round-robin 的方式均匀的发送给多台服务器。当所有用户的流量符合预期时,系统工作得很好,每台服务器的负载均匀,而且部分服务器宕机也不影响整体服务的可用性。但当出现“破坏者”后,系统的可用性将出现很大的风险。

如下图所示,假设红色的用户被 DDoS 攻击或者他的某些请求可能触发服务器宕机的 bug,那么他的负载将可能打垮所有的服务器,造成整个服务不可用。

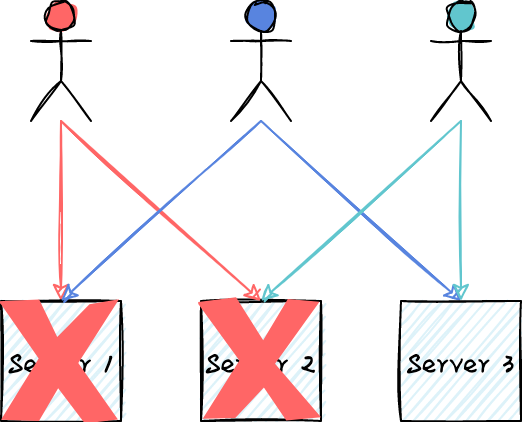
上述问题的本质是任何用户的流量都会被路由到所有服务器上,这种没有任何负载隔离能力的模式在面临“破坏者”时相当脆弱。对于任何一个用户,如果他的负载只会被路由到部分服务器上,能不能解决这个问题?如下图所示,任何用户的流量最多路由到2台服务器上,即使造成两台服务器宕机,绿色用户的请求仍然不受影响。这种将用户的负载映射到部分而非全部服务器的负载分片模式,能够很好的实现负载隔离,降低服务不可用的风险。代价则是系统需要准备更多的冗余资源。
接下来,让我们调整下用户负载的映射方式。如下图所示,每个用户的负载均匀的映射到两台服务器上。不但负载更加均衡,更棒的是,即使两台服务器宕机,除红色之外的用户负载都不受影响。如果我们把分区的大小设为2,那么从3台服务器中选择2台服务器的组合方式有 C{3}^{2}=3 种,即3种可能的分区方式。通过随机算法,我们将负载均匀的映射到分区上,那么任意一个分区不可服务,则最多影响1/3的负载。假设我们有100台服务器,分区的大小仍然是2,那么分区的方式有C{100}{2}=4950种,单个分区不可用只会影响1/4950=0.2%的负载。随着服务器的增多,随机分区的效果越明显。对负载随机分区是一个非常简洁却强大的模式,在保障多租系统的可用性中起到了关键的作用。
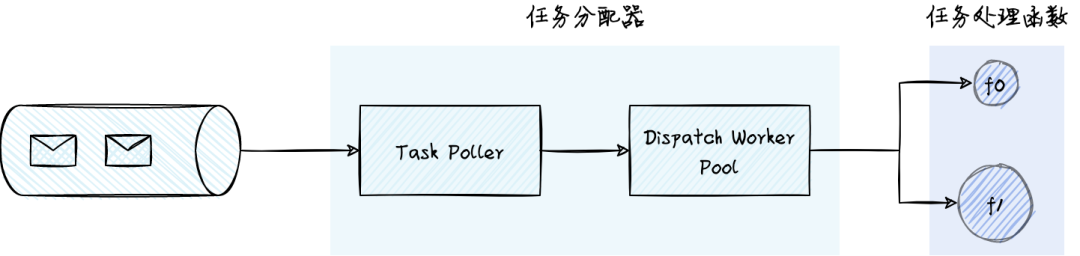
3 自适应下游处理能力的任务分发
函数计算的任务分发采用了推模式,这样用户只需要专注于任务处理逻辑的开发,平台和用户的边界也很清晰。在推模式中,有一个任务分配器的角色,负责从任务队列拉取任务并分配到下游的任务处理实例上。任务分配器要能根据下游处理能力,自适应的调整任务分发速度。当用户的队列产生积压时,我们希望不断增加 dispatch worker pool 的任务分发能力;当达到下游处理能力的上限后,worker pool 要能感知到该状态,保持相对稳定的分发速度;当任务处理完毕后,work pool 要缩容,将分发能力释放给其他任务处理函数。
在实践中,我们借鉴了 tcp 拥塞控制算法的思想,对 worker pool 的扩缩容采取 AIMD 算法(Additive Increase Multiplicative Decrease,和性增长,乘性降低)。当用户短时间内提交大量任务时,分配器不会立即向下游发送大量任务,而是按照“和性增长”策略,线性增加分发速度,避免对下游服务的冲击。当收到下游服务的流控错误后,采用“乘性减少”的策略来,按照一定的比例来缩容 worker pool。其中流控错误需要满足错误率和错误数的阈值后才触发缩容,避免 worker pool 的频繁扩缩容。
4 向上游的任务生产方发送背压(back pressure)
如果任务的处理能力长期落后于任务的生产能力,队列中积压的任务会越来越多,虽然可以使用多个队列并进行流量路由来减小租户之间的相互影响。但任务积压超过一定阈值后,应当更积极的向上游的任务生产方反馈这种压力,例如开始流控任务提交的请求。在多租共享资源的场景下,背压的实施会更加有挑战。例如A,B应用共享任务分发系统的资源,如果A应用的任务积压,如何做到:
- 公平。尽可能流控A而不是B应用。流控本质是一个概率问题,为每一个对象计算流控概率,概率越准确,流控越公平。
- 及时。背压要传递到系统最外层,例如在任务提交时就对A应用流控,这样对系统的冲击最小。
如何在多租场景中识别到需要流控的对象很有挑战,我们在实践中借鉴了Sample and Hold算法,取得了较好的效果。感兴趣的读者可以参考相关论文。
三 异步任务处理系统的能力分层
**
根据前述对异步任务处理系统的架构和功能的分析,我们将异步任务处理系统的能力分为以下三层:
- Level 1:一般需 1-5 人研发团队,系统是通过整合 K8s 和消息队列等开源软件/云服务的能力搭建的。系统的能力受限于依赖的开源软件/云服务,难以根据业务需求进行定制。资源的使用偏静态,不具备资源伸缩,负载均衡的能力。能够承载的业务规模有限,随着业务规模和复杂度增长,系统开发和维护的代价会迅速增加。
- Level 2:一般需 5-10人研发团队,在开源软件/云服务的基础之上,具备一定的自主研发能力,满足常见的业务需求。不具备完整的任务优先级、隔离、流控的能力,通常是为不同的业务方配置不同的队列和计算资源。资源的管理比较粗放,缺少实时资源伸缩和容量管理能力。系统缺乏可扩展性,资源精细化管理能力,难以支撑大规模复杂业务场景。
- Level 3:一般需 10+ 人研发团队,能够打造平台级的系统。具备支撑大规模,复杂业务场景的能力。采用共享资源池,在任务调度,隔离流控,负载均衡,资源伸缩等方面能力完备。平台和用户界限清晰,业务方只需要专注于任务处理逻辑的开发。具备完整的可观测能力。
|
| Level 1 | Level 2 | Level 3 | |
|---|---|---|---|
| 任务的可靠分发 | 支持 | 支持 | 支持 |
| 任务定时/延时发送 | 取决于选择的消息队列能力。一般支持定时任务,但不支持延时任务 | 支持 | 支持 |
| 任务去重 | 不支持 | 支持 | 支持 |
| 任务错误自动重试 | 有限支持。一般依赖于 K8s Jobs 内置的重试策略。对于未使用 K8s Jobs 的任务,则需用户在任务处理逻辑中自行实现 | 有限支持。一般依赖于 K8s Jobs 内置的重试策略。对于未使用 K8s Jobs 的任务,则需用户在任务处理逻辑中自行实现 | 支持。平台和用户界限清晰,根据用户设定的策略重试 |
| 任务负载均衡 | 有限支持。在任务执行实例规模小的情况下通过消息队列实现 | 有限支持。在任务执行实例规模小的情况下通过消息队列实现 | 支持。系统具备大规模节点的负载均衡能力 |
| 任务优先级 | 不支持 | 有限支持。允许用户为高优先级任务预留资源,或者限制低优先级任务的资源使用 | 支持。高优先级任务可抢占低优先级任务资源,同时系统会兼顾公平,避免低优先级任务被饿死 |
| 任务流控 | 不支持 | 不支持。一般是为不同任务类型或者业务方配置独立的队列和计算资源 | 在系统的每个环节具备流控能力,系统不会因为任务爆发式提交雪崩 |
| 任务批量暂停/删除 | 不支持 | 有限支持。取决于是否为不同任务类型或者业务方配置独立的队列和计算资源 | 支持 |
| 共享资源池 | 有限支持。依赖 K8s 的调度能力。一般是为各个业务方搭建不同的集群 | 有限支持。依赖 K8s 的调度能力。一般是为各个业务方搭建不同的集群 | 支持。不同类型的任务,不同业务场景共享同一个资源池 |
| 资源弹性伸缩 | 不支持。K8s 的 HPA 通常难以满足任务场景下的伸缩要求 | 不支持。K8s 的 HPA 通常难以满足任务场景下的伸缩要求 | 支持。根据排队任务数,节点资源利用率等多维度实时伸缩 |
| 任务资源隔离 | 支持。依赖容器的资源隔离能力 | 支持。依赖容器的资源隔离能力 | 支持。依赖容器的资源隔离能力 |
| 任务资源配额 | 不支持 | 支持 | 支持 |
| 简化任务处理逻辑编码 | 不支持。任务处理逻辑需要自行拉取任务,执行任务 | 不支持。任务处理逻辑需要自行拉取任务,执行任务 | 支持 |
| 系统平滑升级 | 不支持 | 不支持 | 支持 |
| 执行结果通知 | 不支持 | 不支持 | 支持 |
| 可观测性 | 依赖 K8s,消息队列等开源软件自身的可观测能力。具备基本的任务状态查询 | 依赖 K8s,消息队列等开源软件自身的可观测能力。具备基本的任务状态查询 | 具备从任务到系统各个层面的完整可观测能力 |
四 结论
**
异步任务是构建弹性、高可用,响应迅速应用的重要手段。本文对异步任务的适用场景和收益进行了介绍,并讨论了典型异步任务系统的架构、功能和工程实践。要实现一个能够满足多种业务场景需求,弹性可扩展的异步任务处理平台具有较高的复杂度。而阿里云函数计算 FC 为用户提供了开箱即用的,接近于Level ß3能力的异步任务处理服务。用户只需要创建任务处理函数,通过控制台,命令行工具,API/SDK,事件触发等多种方式提交任务,就可以弹性、可靠、可观测完备的方式处理任务。函数计算异步任务覆盖任务处理时长从毫秒到24小时的场景,被阿里云数据库自制服务 DAS,支付宝小程序压测平台,网易云音乐,新东方,分众传媒,米连等集团内外客户广泛应用。
附录
- 函数计算异步任务和 K8S Jobs 的能力对比。
| 对比项 | 函数计算异步任务 | K8S Jobs |
|---|---|---|
| 适用场景 | 适合任务执行时长数十毫秒的实时任务和任务执行时长几十小时的离线任务 | 适合任务提交速度要求不高,任务负载比较固定,任务实时性要求不高的离线任务 |
| 任务可观测能力 | 支持。提供日志,任务排队数等指标,任务链路耗时,任务状态查询等丰富可观测能力 | 自行整合开源软件实现。 |
| 任务实例自动扩缩容 | 支持。根据任务排队数,实例资源使用率自动扩缩容 | 不支持。一般通过任务队列,自行实现自动扩缩容和实例负载均衡,复杂度高 |
| 任务实例伸缩速度 | 毫秒级 | 分钟级 |
| 任务实例资源利用率 | 用户只需要选择合适的实例规格,实例自动伸缩,按实际处理任务的时长计量,资源利用率高 | 需在作业(Job)提交时确定实例的规格和数目。实例难以自动伸缩和负载均衡,资源利用率低 |
| 任务提交速度 | 单个用户支持每秒提交数万任务 | 整个集群每秒最多启动数百作业(Jobs) |
| 任务定时/延时提交 | 支持 | 支持定时任务,不支持延时任务 |
| 任务去重 | 支持 | 不支持 |
| 暂停/恢复任务执行 | 支持 | Alpha 状态(K8S v1.21) |
| 终止指定任务 | 支持 | 有限支持。通过终止任务实例间接实现 |
| 任务流控 | 支持。可在用户,任务处理函数等不同粒度进行流控 | 不支持 |
| 任务结果自动回调 | 支持 | 不支持 |
| 开发运维成本 | 只需要实现任务的处理逻辑 | 需维护K8S集群 |
网易云音乐 Serverless Jobs 实践,音频处理算法业务落地速度10x提升
其他异步任务案例
参考链接:
[1] slack engineering:https://slack.engineering/scaling-slacks-job-queue/
[2] Facebook:https://engineering.fb.com/2020/08/17/production-engineering/async/
[3] Dropbox 统计:https://dropbox.tech/infrastructure/asynchronous-task-scheduling-at-dropbox
[4] Netflix Cosmos 平台:https://netflixtechblog.com/the-netflix-cosmos-platform-35c14d9351ad
[5] keda:https://keda.sh/
[6] Autoscaling Asynchronous Job Queues :https://d1.awsstatic.com/architecture-diagrams/ArchitectureDiagrams/autoscaling-asynchronous-job-queues.pdf
[7] 异步任务:https://help.aliyun.com/document_detail/372531.html
[8] Sample and Hold 算法:https://dl.acm.org/doi/10.1145/633025.633056
[9] 网易云音乐音视频算法的 Serverless 探索之路: https://developer.aliyun.com/article/801501
[10] 其它异步任务案例:https://developer.aliyun.com/article/815182

若有收获,就点个赞吧
0 人点赞
