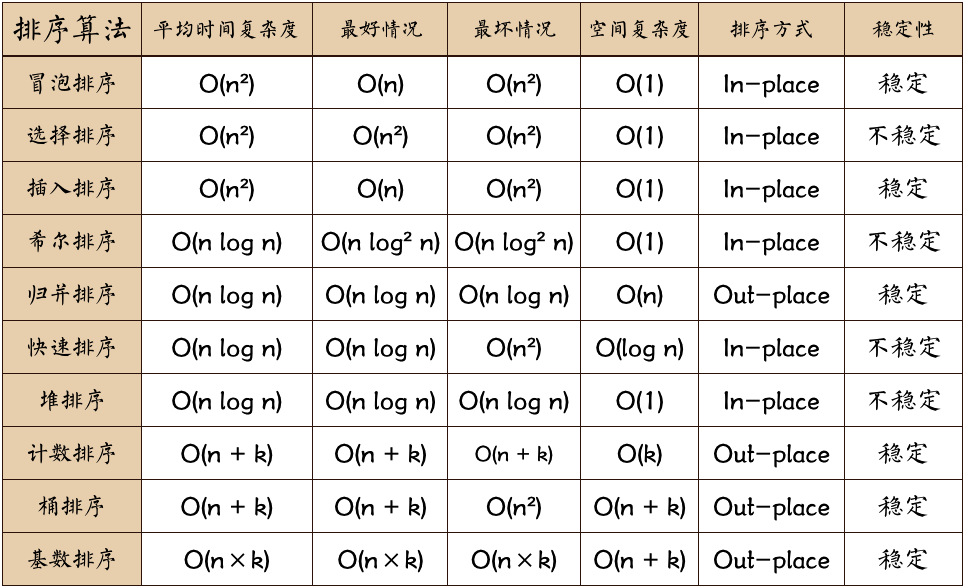
- k:“桶”的个数
- In-place:占用常数内存,不占用额外内存
- Out-place:占用额外内存
排序分类
步骤
- 比较相邻的元素,如果第一个比第二个大,就交换
- 对每一对相邻元素作同样的工作,从开始第一对到结尾的最后一对,最后的元素应该是最大的数
- 针对所有元素重复以上的步骤,除最后一个
- 重复步骤 1~3,直到排序完成

public static int[] bubbleSort(int[] array) {if (array.length == 0)return array;for (int i = 0; i < array.length; i++)for (int j = 0; j < array.length - 1 - i; j++)if (array[j + 1] < array[j]) {int temp = array[j + 1];array[j + 1] = array[j];array[j] = temp;}return array;}
优化:
- 对冒泡排序常见的改进方法是加入标志性变量 exchange ,用于标志某一趟排序过程中是否有数据交换
- 若进行某一趟排序没有进行数据交换,则说明数据已经有序,可立即结束排序,避免不必要的比较过程
public void bubbleSort_2(int[] list) {int temp = 0; // 用来交换的临时数boolean bChange = false; // 交换标志// 要遍历的次数for (int i = 0; i < list.length - 1; i++) {bChange = false;// 从后向前依次的比较相邻两个数的大小,遍历一次后,把数组中第i小的数放在第i个位置上for (int j = list.length - 1; j > i; j--) {// 比较相邻的元素,如果前面的数大于后面的数,则交换if (list[j - 1] > list[j]) {temp = list[j - 1];list[j - 1] = list[j];list[j] = temp;bChange = true;}}// 如果标志为false,说明本轮遍历没有交换,已经是有序数列,可以结束排序if (false == bChange){break;}System.out.format("第 %d 趟:\t", i);printAll(list);}}
2、快速排序
步骤
- 从数列中挑出一个元素,称为 “基准”(pivot )
- 重新排序数列,所有元素比基准值小的摆放在基准前面,所有元素比基准值大的摆在基准的后面(相同数可任一边)。在这个分区退出后,基准处于数列中间,称为分区(partition)
- 递归地把小于基准值元素的子数列和大于基准值元素的子数列排序

public static int[] QuickSort(int[] array, int start, int end) {if (array.length<1 || start<0 || end>=array.length || start>end) return null;int smallIndex = partition(array, start, end);if (smallIndex > start)QuickSort(array, start, smallIndex - 1);if (smallIndex < end)QuickSort(array, smallIndex + 1, end);return array;}//分区 partitionpublic static int partition(int[] array, int start, int end) {int pivot = (int) (start + Math.random() * (end - start + 1));int smallIndex = start - 1;swap(array, pivot, end);for (int i = start; i <= end; i++)if (array[i] <= array[end]) {smallIndex++;if (i > smallIndex)swap(array, i, smallIndex);}return smallIndex;}//交换数组内两个元素public static void swap(int[] array, int i, int j) {int temp = array[i];array[i] = array[j];array[j] = temp;}
3、插入排序
- 步骤
- 从第一个元素开始,该元素可以认为已经被排序
- 取出下一个元素,在已经排序的元素序列中从后向前扫描
- 如果该元素(已排序)大于新元素,将该元素移到下一位置
- 重复步骤 3,直到找到已排序的元素小于或者等于新元素的位置
- 将新元素插入到该位置后
- 重复步骤 2~5

每一趟将一个待排序的记录,按照其关键字的大小插入到有序队列的合适位置里,直到全部插入完成
public static int[] insertionSort(int[] array) {if (array.length == 0)return array;int current;for (int i = 0; i < array.length - 1; i++) {current = array[i + 1];int preIndex = i;while (preIndex >= 0 && current < array[preIndex]) {array[preIndex + 1] = array[preIndex];preIndex--;}array[preIndex + 1] = current;}return array;}
4、希尔排序(缩小增量排序)
插入排序加强版
步骤
- 选择一个增量序列 t1,t2,…,tk,其中 ti>tj,tk=1
- 按增量序列个数 k,对序列进行 k 趟排序
- 每趟排序,根据对应的增量 ti,将待排序列分割成若干长度为 m 的子序列,分别对各子表进行直接插入排序。增量因子为 1 时,整个序列作为一个表来处理,表长度即为整个序列的长度

public static int[] ShellSort(int[] array) {int len = array.length;int temp, gap = len / 2;while (gap > 0) {for (int i = gap; i < len; i++) {temp = array[i];int preIndex = i - gap;while (preIndex >= 0 && array[preIndex] > temp) {array[preIndex + gap] = array[preIndex];preIndex -= gap;}array[preIndex + gap] = temp;}gap /= 2;}return array;}
插入排序和希尔排序比较:
步骤
- 初始状态:无序区为R[1…n],有序区为空
- 第 i 趟排序(i=1,2,3…n-1)开始时,当前有序区和无序区分别为 R[1…i-1] 和 R[i…n]。该趟排序从当前无序区中选出关键字最小的记录 R[k],将它与无序区的第 1 个记录 R 交换,使 R[1…i] 和 R[i+1…n] 分别变为记录个数增加 1 个的新有序区和记录个数减少 1 个的新无序区
- n-1 趟结束,数组有序化

public static int[] selectionSort(int[] array) {if (array.length == 0)return array;for (int i = 0; i < array.length; i++) {int minIndex = i;for (int j = i; j < array.length; j++) {if (array[j] < array[minIndex]) //找到最小的数minIndex = j; //将最小数的索引保存}int temp = array[minIndex];array[minIndex] = array[i];array[i] = temp;}return array;}
6、堆排序
堆积是一个近似完全二叉树的结构,满足堆积性质:子结点键值或索引总小于(或者大于)它的父节点
- 步骤
- 将初始待排序关键字序列(R1,R2….Rn)构建成大顶堆,此堆为初始的无序区
- 将堆顶元素 R[1] 与最后一个元素 R[n] 交换,得到新无序区(R1,R2,……Rn-1)和新的有序区(Rn),且满足 R[1,2…n-1] <= R[n]
- 由于交换后新堆顶 R[1] 可能违反堆性质,需要对当前无序区(R1,R2,……Rn-1)调整为新堆,然后再次将 R[1] 与无序区最后一个元素交换,得到新无序区(R1,R2….Rn-2)和新有序区(Rn-1,Rn))
- 不断重复步骤 3 直到有序区的元素个数为 n-1,排序过程完成

//声明全局变量,用于记录数组array的长度;static int len;public static int[] HeapSort(int[] array) {len = array.length;if (len < 1) return array;buildMaxHeap(array); //构建一个最大堆//循环将堆首位(最大值)与末位交换,然后在重新调整最大堆while (len > 0) {swap(array, 0, len - 1);len--;adjustHeap(array, 0);}return array;}//建立最大堆public static void buildMaxHeap(int[] array) {//从最后一个非叶子节点开始向上构造最大堆,for循环这样写好点:i的左子树和右子树分别2i+1和2(i+1)for (int i = (len/2- 1); i >= 0; i--) {adjustHeap(array, i);}}//调整成最大堆public static void adjustHeap(int[] array, int i) {int maxIndex = i;//如果有左子树,且左子树大于父节点,则将最大指针指向左子树if (i 2 < len && array[i 2] > array[maxIndex])maxIndex = i * 2 + 1;//如果有右子树,且右子树大于父节点,则将最大指针指向右子树if (i 2 + 1 < len && array[i 2 + 1] > array[maxIndex])maxIndex = i * 2 + 2;//如果父节点不是最大值,则将父节点与最大值交换,并且递归调整与父节点交换的位置。if (maxIndex != i) {swap(array, maxIndex, i);adjustHeap(array, maxIndex);}}
7、归并排序
- 步骤
- 把长度为 n 的输入序列分成两个长度为 n/2 的子序列
- 对这两个子序列分别采用归并排序
- 将两个排序好的子序列合并成一个最终的排序序列

public static int[] MergeSort(int[] array) {if (array.length < 2) return array;int mid = array.length / 2;int[] left = Arrays.copyOfRange(array, 0, mid);int[] right = Arrays.copyOfRange(array, mid, array.length);return merge(MergeSort(left), MergeSort(right));}//归并排序——将两段排序好的数组结合成一个排序数组public static int[] merge(int[] left, int[] right) {int[] result = new int[left.length + right.length];for (int index = 0, i = 0, j = 0; index < result.length; index++) {if (i >= left.length)result[index] = right[j++];else if (j >= right.length)result[index] = left[i++];else if (left[i] > right[j])result[index] = right[j++];elseresult[index] = left[i++];}return result;}
- 若子表个数为奇数,最后一个子表无须和其他子表归并(即本趟处理轮空)
若子表个数为偶数,最后一对子表中后一个子表区间的上限为 n-1
8、基数排序
步骤
- 取得数组中的最大数,并取得位数
- arr 为原始数组,从最低位开始取每个位组成 radix 数组
- 对 radix 进行计数排序(利用计数排序适用于小范围数的特点)

public static int[] RadixSort(int[] array) {if (array == null || array.length < 2)return array;//先算出最大数的位数;int max = array[0];for (int i = 1; i < array.length; i++) {max = Math.max(max, array[i]);}int maxDigit = 0;while (max != 0) {max /= 10;maxDigit++;}int mod = 10, div = 1;ArrayList<ArrayList> bucketList = new ArrayList<ArrayList>();for (int i = 0; i < 10; i++)bucketList.add(new ArrayList());for (int i = 0; i < maxDigit; i++, mod = 10, div = 10) {for (int j = 0; j < array.length; j++) {int num = (array[j] % mod) / div;bucketList.get(num).add(array[j]);}int index = 0;for (int j = 0; j < bucketList.size(); j++) {for (int k = 0; k < bucketList.get(j).size(); k++)array[index++] = bucketList.get(j).get(k);bucketList.get(j).clear();}}return array;}
MSD 从高位开始进行排序 LSD 从低位开始进行排序
算法分析:
基数排序的效率和初始序列是否有序无关
步骤
- 找出待排序的数组中最大和最小的元素
- 统计数组中每个值为 i 的元素出现的次数,存入数组 C 的第 i 项
- 对所有计数累加(从 C 中第一个元素开始,每一项和前一项相加)
- 反向填充目标数组:将每个元素 i 放在新数组的第 C(i) 项,每放一个元素就将 C(i) 减去 1

public static int[] CountingSort(int[] array) {if (array.length == 0) return array;int bias, min = array[0], max = array[0];for (int i = 1; i < array.length; i++) {if (array[i] > max)max = array[i];if (array[i] < min)min = array[i];}bias = 0 - min;int[] bucket = new int[max - min + 1];Arrays.fill(bucket, 0);for (int i = 0; i < array.length; i++) {bucket[array[i] + bias];}int index = 0, i = 0;while (index < array.length) {if (bucket[i] != 0) {array[index] = i - bias;bucket[i]--;index;} elsei++;}return array;}
10、桶排序
计数排序升级版
- 步骤
- 人为设置一个 BucketSize,作为每个桶所能放置多少个不同数值(当 BucketSize==5 时,可以存放{1,2,3,4,5}这几种数字,但容量不限,即可存放 100 个 3)
- 遍历输入数据,把数据一个一个放到对应的桶里去
- 对每个不是空的桶进行排序,可以使用其它排序方法,也可以递归使用桶排序
- 从不是空的桶里把排好序的数据拼接起来

public static ArrayList BucketSort(ArrayList array, int bucketSize) {if (array == null || array.size() < 2)return array;int max = array.get(0), min = array.get(0);// 找到最大值最小值for (int i = 0; i < array.size(); i++) {if (array.get(i) > max)max = array.get(i);if (array.get(i) < min)min = array.get(i);}int bucketCount = (max - min) / bucketSize + 1;ArrayList<ArrayList> bucketArr = new ArrayList<>(bucketCount);ArrayList resultArr = new ArrayList<>();for (int i = 0; i < bucketCount; i++) {bucketArr.add(new ArrayList());}for (int i = 0; i < array.size(); i++) {bucketArr.get((array.get(i) - min) / bucketSize).add(array.get(i));}for (int i = 0; i < bucketCount; i++) {if (bucketSize == 1) { // 如果带排序数组中有重复数字时for (int j = 0; j < bucketArr.get(i).size(); j++)resultArr.add(bucketArr.get(i).get(j));} else {if (bucketCount == 1)bucketSize--;ArrayList temp = BucketSort(bucketArr.get(i), bucketSize);for (int j = 0; j < temp.size(); j++)resultArr.add(temp.get(j));}}return resultArr;}
- 基数排序 vs 计数排序 vs 桶排序
- 都利用桶的概念
- 基数排序: 根据键值的每位数字来分配桶
- 计数排序: 每个桶只存储单一键值
- 桶排序: 每个桶存储一定范围的数值

若有收获,就点个赞吧
0 人点赞
